CI/CD: Branching, Git Flow y Pull Requests
📚 Serie: CI/CD y la IA: De la teoría a la práctica
Antes de que el pipeline CI/CD se active, el código debe pasar por un proceso estructurado de trabajo con ramas, revisión y aprobación. Este artículo describe cómo organizan ese proceso los equipos profesionales, qué modelos de GitFlow existen, cómo la IA potencia el flujo del desarrollador y qué ocurre durante el Pull Request.
Índice
- Trabajo con ramas (Branching Strategy)
- Modelos de Git Flow
- Flujo moderno del desarrollador con IA
- Pull Request (PR)
Trabajo con ramas (Branching Strategy)
Descripción
Un proyecto de software se divide en ramas principales y de apoyo:
- Ramas principales (tiempo infinito): son
mainydevelop. Estas ramas existen durante toda la vida del proyecto. - Ramas de apoyo (temporales): son todas las demás (
feature/,release/,hotfix/, etc.). A diferencia de las principales, estas tienen un tiempo de vida limitado (se crean para un fin específico y se eliminan al terminar). Se suelen representar con una barra/al final, porque después de la palabra clave (comofeature), se suele poner un identificador o un título descriptivo (por ejemplo:feature/idTitulo).
Lo más importante es que la rama main siempre es la rama maestra (principal) y no solo todas las demás ramas se basan en esta y confluyen (hacen merge) a esta, sino que el código que hay aquí es el que manda y que tras el CD (Continuous Delivery/Deployment, entrega/despliegue continuo) se desplegará en producción.
Cuando en la rama develop u otra más avanzada estuviese estable, se suele mergear (o PR) primero en otra rama llamada release (para separar lo que se va a subir como nueva versión a producción del trabajo diario) y para terminar el responsable haría merge (o PR) a la rama main.
Ramas principales y de apoyo
A continuación se muestra una tabla completa de los tipos de ramas más comunes:
| Rama | Origen | Destino | Uso en CI/CD (Triggers) | Propósito / Cuándo usarla |
|---|---|---|---|---|
main (o master) |
release / hotfix |
– | Deploy Prod: Despliegue automático a producción y Tagging. | Código oficial, estable y en uso por clientes. |
develop |
main |
– | Deploy Staging: Despliegue a entorno de pruebas e integración. | El estado actual del desarrollo para el próximo release. |
feature/ |
develop |
develop |
Test & Lint: Ejecución de pruebas unitarias y calidad de código. | Desarrollo de nuevas funcionalidades (Tickets de Jira). |
release/ |
develop |
main y develop |
Pre-prod Check: Pruebas de regresión y cierre de versión. | Preparación final. Solo se permiten correcciones menores. |
hotfix/ |
main |
main y develop |
Emergency Pipeline: Despliegue urgente de parches. | Errores críticos en producción que deben arreglarse YA. |
fix/ (o bugfix/) |
develop |
develop |
Bug Validation: Verificación de QA en el ciclo de desarrollo. | Errores encontrados en develop que no están en producción. |
refactor/ |
develop |
develop |
Performance Audit: Revisión de que no haya degradación técnica. | Mejorar el código existente sin cambiar su funcionalidad. |
chore/ |
develop |
develop |
Dependency Check: Escaneo de vulnerabilidades en librerías. | Mantenimiento (actualizar npm, linters, configs de build). |
docs/ |
develop |
develop |
Docs Deploy: Actualización del portal de documentación estática. | Cambios exclusivos en README, Wiki o comentarios de API. |
Nota sobre la diferencia entre “fixes”:
fix/(obugfix/) es un error en desarrollo yhotfix/es un error en producción; es decir, el primero es un error que se puede solucionar tranquilamente en desarrollo, pero el segundo es un error a solucionar a prisas en producción (con su alto riesgo).
La mayoría de los equipos modernos utilizan un sistema que vincula directamente el código con la herramienta de gestión de proyectos (como Jira, Linear o Azure DevOps). A nivel profesional la rama no se llama solo mi-rama, sino algo que el resto de personas pueda identificar; además, con el nombre se lanzan procesos automáticos, como la vinculación automática de un tique de Jira con dicha rama.
La estructura típica es: tipo/PROY-123-descripcion-breve
- Tipo: define la naturaleza del cambio (ver tabla arriba).
- ID de Ticket: el código exacto de la tarea en Jira (ej.
PROY-123oFRONT-42). - Descripción: 2-4 palabras en kebab-case (separadas por guiones) que resuman el cambio.
Un ejemplo completo de nombre de rama: feature/DATA-505-nueva-funcionalidad
Para Jira es importante el ID porque:
- Incluir el ID del ticket (ej.
DATA-505) en el nombre de la rama habilita “triggers” automáticos. - En Jira el ticket cambia automáticamente de “To Do” a “In Progress” cuando creas la rama.
- En el Pull Request se genera un enlace directo entre la tarea y el código, facilitando el trabajo al revisor.
- Trazabilidad: si dentro de un año hay un error, puedes ver qué ticket de negocio originó ese cambio de código.
Ejemplos de ramas con su nomenclatura:
| Rama | Dueño / Quién la usa | Contenido |
|---|---|---|
| feature/id-name | Un desarrollador | Trabajo en progreso de un ticket de Jira. |
| develop | Todo el equipo | La suma de todas las tareas terminadas (Beta). |
| release/v1.2.3 | DevOps / Tech Lead | Código listo para producción, en fase de pulido. |
| main | Cliente / Usuario | Código estable y en funcionamiento (Producción). |
Diferencia entre Pull Request y Merge
Pull Request (PR) — “La propuesta de cambios”:
El Pull Request o PR es una funcionalidad que ofrecen algunas plataformas como GitHub, Bitbucket o Azure DevOps; no es un comando Git. Es un proceso de revisión y diálogo, para que otros desarrolladores revisen tu código antes de que se integre.
- Propósito: es una invitación para que otros desarrolladores revisen tu código antes de que se integre. Y dispara tests (muchas veces los tests unitarios como parte del CI).
- Contenido: muestra las diferencias (diffs) entre la rama
feature/ID-ejemploydevelop, permite dejar comentarios en líneas específicas y ejecutar pruebas automáticas (CI/CD). - Estado: un PR puede estar “Abierto” (en revisión), “Cerrado” (rechazado) o “Merged” (aceptado).
Merge — “La acción”:
El Merge es la operación técnica de Git que combina el historial de dos ramas. Es el paso final que ocurre después de que el Pull Request ha sido aprobado.
- Propósito: unificar las líneas de tiempo. Todos los commits que hiciste en
feature/ID-ejemplopasan a formar parte de la historia de la rama a la que se hace el merge (como adevelop). - Mecánica: puede hacerse mediante la consola (
git merge feature/...) o haciendo clic en el botón “Merge” de la plataforma una vez aprobado el PR.
Nota sobre
Merge: El Merge es la operación técnica que unifica las líneas de tiempo. Todos los commits realizados en la rama de la funcionalidad se integran en el historial de la rama de destino (como develop).
Tipos de Merge al cerrar un PR:
- Merge Commit: mantiene todo el historial de commits de la feature.
- Squash and Merge: comprime todos tus commits en uno solo (deja el historial de
developmás limpio). El Squash and Merge es muy popular en equipos grandes porque evita que el historial dedevelopse llene de cientos de mensajes de commit pequeños (comofix typooborrando console.log), dejando solo un commit limpio por cada tarea de Jira. - Rebase and Merge: aplica tus cambios uno a uno sobre la base de
developsin crear un commit de unión.
Flujo profesional completo
El flujo profesional completo suele ser:
- Local: trabajas en tu rama
feature/PROJ-123-nueva-api. - Push: subes la rama al servidor.
- PR: creas el Pull Request de tu rama hacia la rama de
develop. - Review: tus compañeros revisan el código. Si hay errores, subes más commits a la misma rama y el PR se actualiza solo.
- Merge: una vez tienes los “Approve”, se ejecuta el Merge. Tu rama
featureya puede ser borrada porque su código vive ahora en la ramadevelop. - Staging e Integración (en develop): el código se despliega automáticamente en un entorno de Staging (o pruebas). Los analistas de calidad (QA, Quality Assurance) o el responsable de producto prueban tu tarea de Jira en un entorno real con los cambios de los demás compañeros.
- Creación de la rama de
release: cuando el equipo decide que hay suficientes tareas terminadas endeveloppara una nueva versión (ejemplo:v1.5.0), se crea una rama llamadarelease/v1.5.0a partir dedevelop. Congelamiento (Code Freeze): en esta rama ya no se aceptan nuevas funcionalidades y solo se permiten correcciones de errores críticos descubiertos durante las pruebas finales. - Preparación para Producción: durante unos días (el tiempo que dure el ciclo de lanzamiento), la rama de
releasevive de forma independiente. Si se encuentra un fallo de última hora, se arregla (Hotfixes) directamente enrelease/v1.5.0. Estos arreglos también se suelen enviar de vuelta adevelopmediante un PR para que el equipo de desarrollo los tenga (Sincronización). - Doble Merge Final: cuando la rama de
releasees declarada estable, ocurre el despliegue oficial, donde se abre un Pull Request (para nuestro ejemplo:release/v1.5.0) haciamain. Al aprobarse y mezclarse, el CI/CD dispara el despliegue al entorno de Producción. Luego, se crea un “Tag” (etiquetado o Tagging) en Git (ej.v1.5.0) sobre ese commit enmain— esto sirve como una “foto” permanente de lo que hay en producción en ese momento. Para terminar se hace merge adevelop, asegurando quedevelopesté al día con cualquier cambio que se haya hecho en la rama derelease. - Cierre del Ciclo en Jira: tras el despliegue exitoso, se realiza una actualización masiva donde todos los tickets de Jira incluidos en esa versión (como tu
PROJ-123) pasan automáticamente al estado Done/Released. Seguido de una limpieza donde se borra la ramarelease/v1.5.0del servidor, ya que su historial vive ahora enmainy en el Tag.
Nota sobre el “Tag”: Este Tag funciona como una ‘foto’ permanente. Si el despliegue falla, el equipo puede usar ese Tag para identificar exactamente qué versión estable debe restaurar inmediatamente.
Diagrama
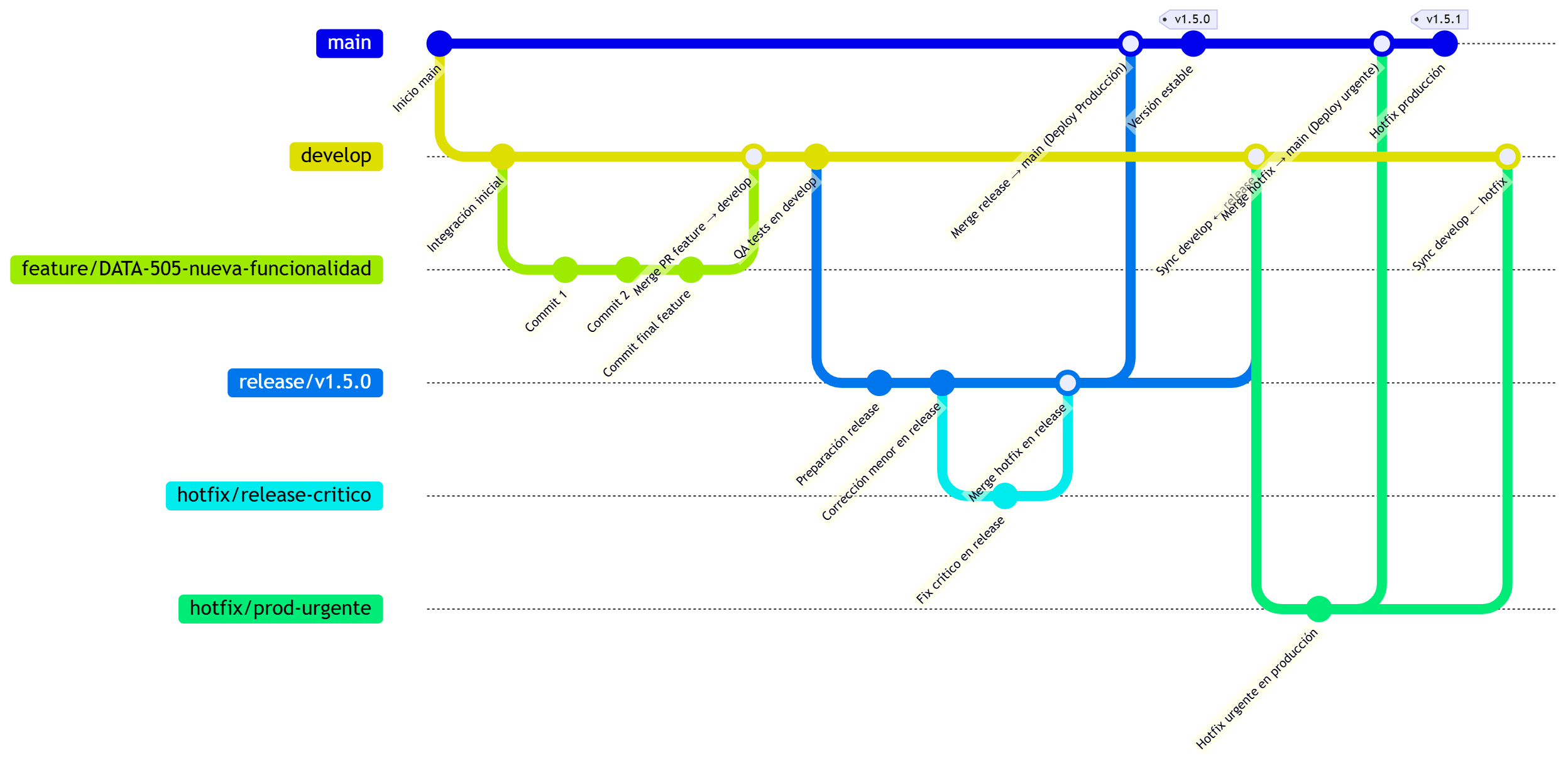
Modelos de Git Flow
Descripción
Existen dos grandes modelos a la hora de ejecutar CI/CD en relación con el momento del merge del Pull Request: el modelo clásico (donde CI/CD se ejecuta después del merge) y el modelo moderno (donde CI/CD se ejecuta antes del merge).
Modelo clásico: CI/CD se ejecuta DESPUÉS del merge del PR
Esta solía ser la manera de trabajo tradicional (y es la opción más simple si no se quiere complicar mucho), donde se esperaba a tener todo en la rama main y después se lanzaba el CI/CD.
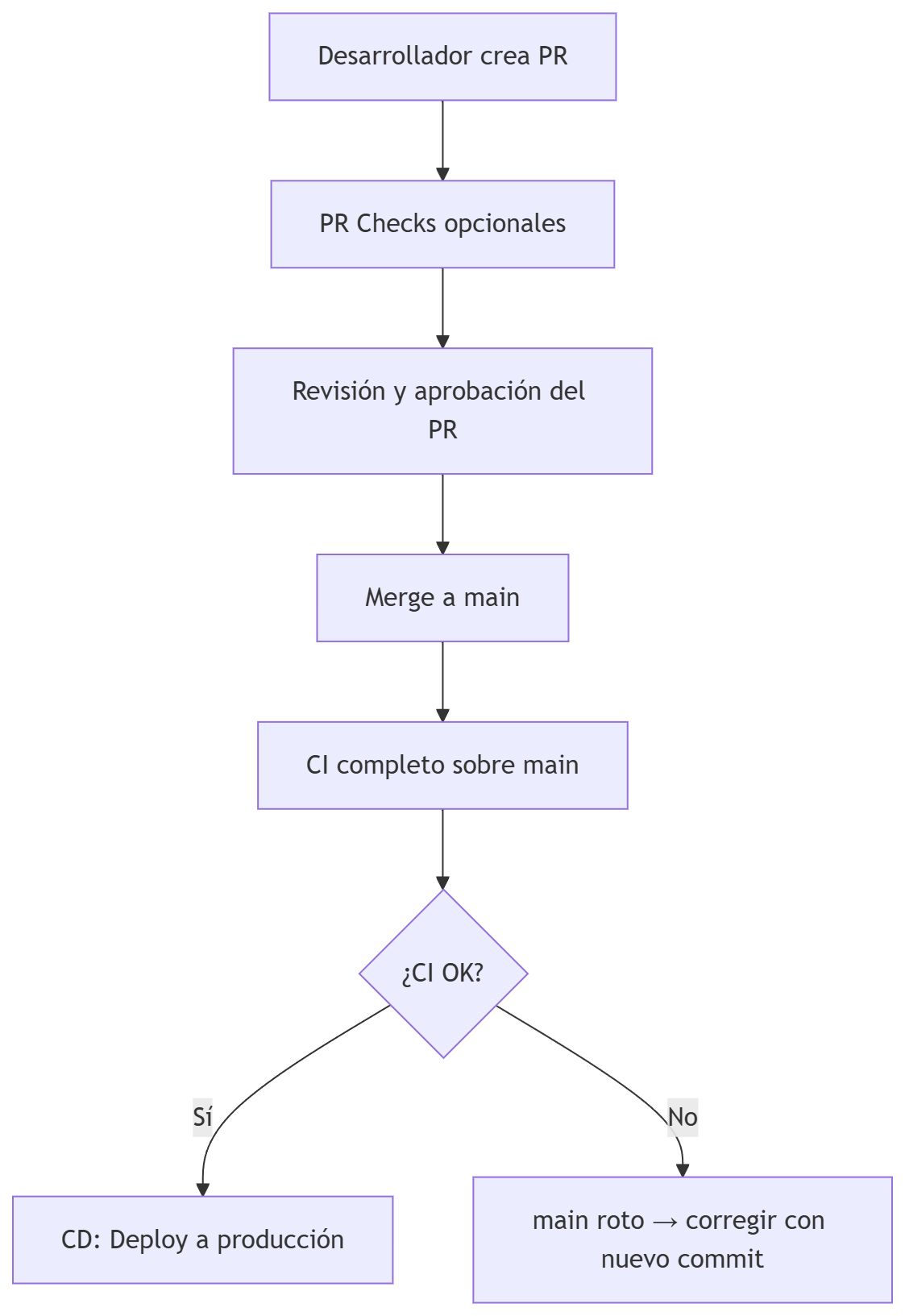
Este es el modelo tradicional:
- El desarrollador abre un PR → se ejecutan PR Checks
- El PR se revisa y se aprueba
- El PR se mergea a main
- El merge dispara el pipeline CI/CD completo
- Si CI/CD pasa → el código llega a producción
- Si CI/CD falla → el merge ya está hecho, pero hay que arreglarlo en
main
Ventaja: simple y tradicional.
Desventaja: si CI/CD falla, main queda roto. Por esto, este modelo está cayendo en desuso en empresas maduras.
Modelo moderno: CI/CD se ejecuta ANTES del merge del PR (recomendado)
En un GitFlow moderno, PR Checks y CI deben ejecutarse en todos los merges hacia develop, release y main.
El CD solo se ejecuta en main.
Esto garantiza que ninguna rama se rompa y que el merge esté siempre protegido por CI.
La máxima es: ninguna rama puede romperse.
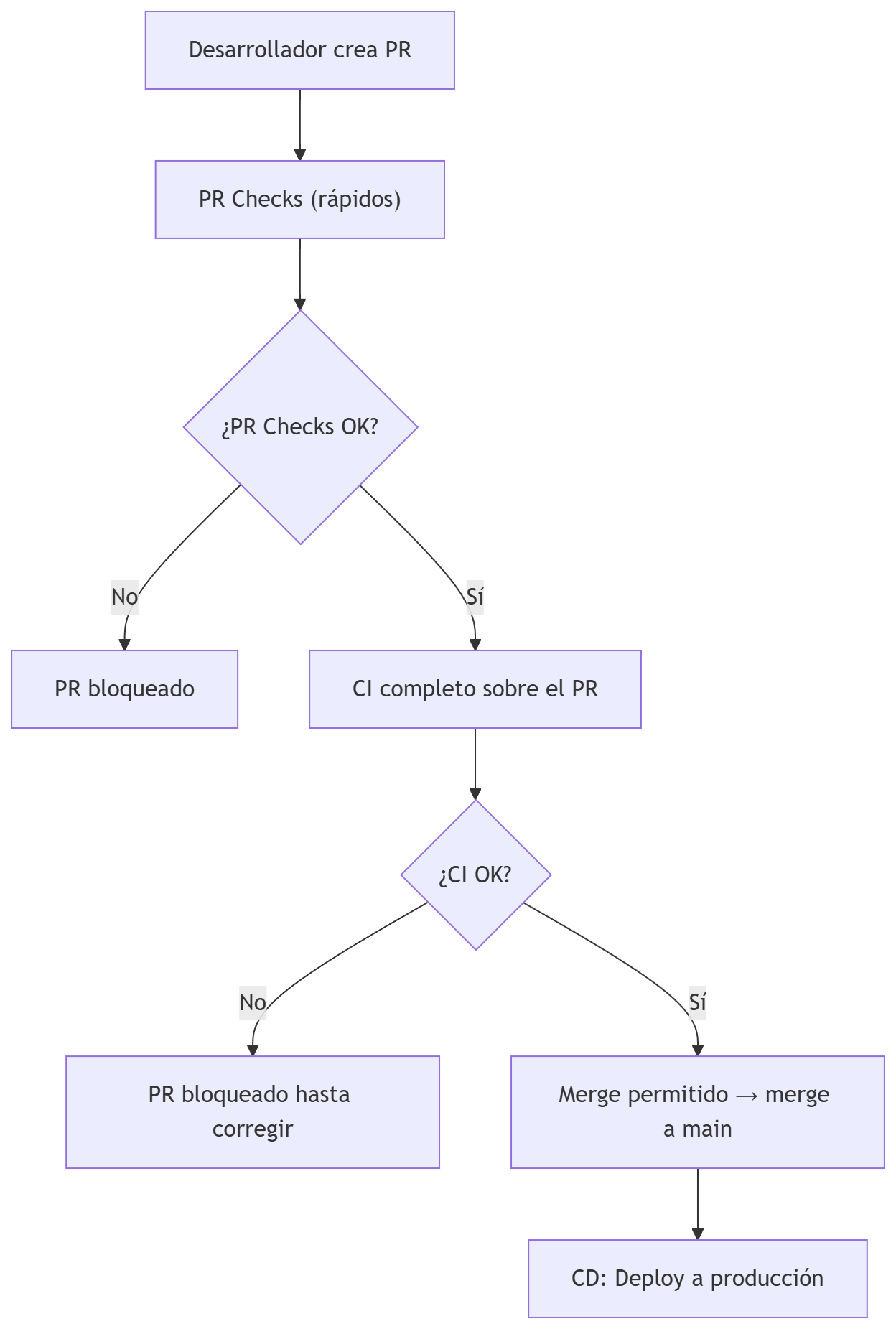
Este es el modelo que usan:
- GitHub (con Required Checks)
- GitLab (con Merge Trains)
- Azure DevOps (con Branch Policies)
- Bitbucket (con Merge Checks)
Flujo real:
- El desarrollador abre un PR
- Se ejecutan PR Checks (rápidos)
- Si pasan → se ejecuta CI completo sobre el PR
- Si CI pasa → el PR queda marcado como “mergeable”
- El merge se permite solo si CI ha pasado
- El merge NO dispara CI otra vez (o solo CD, según configuración)
Ventaja: las ramas nunca se rompen, porque CI se ejecuta ANTES del merge.
Estructura del pipeline recomendada en cada rama:
- PR Checks obligatorios y rápidos antes del CI
- CI completo obligatorio antes del merge (el merge se bloquea si falla)
- CD después del merge de
main(o en merge trains)
¿Se debe ejecutar PR Check y CI en TODOS los merges o solo en main?
La recomendación es ejecutarlo en todas las ramas para que ninguna se rompa, porque si solo ejecutas CI en main:
developpuede rompersereleasepuede romperse- los
hotfixpueden romperse - los merges se vuelven impredecibles
- la calidad deja de estar garantizada
Aunque si una ejecución en todas las ramas es demasiado, lo mínimo es que se protejan las ramas main, develop y release.
¿Por qué CI debe ejecutarse ANTES del merge en develop y release? Porque si no:
developse rompe y bloquea a todo el equiporeleasese rompe y bloquea QA (Quality Assurance; el proceso de asegurar la calidad del software antes de que pase a fases más críticas) y UAT (User Acceptance Testing o Pruebas de Aceptación de Usuario; la fase donde usuarios reales o negocio validan que el software cumple lo que necesitan)mainse vuelve impredecible- Si
developestá roto, no puedes crear unarelease - Si
releaseestá rota, no puedes desplegar
De esta manera, en TODOS los merges a develop, release y main se ejecutan:
- PR Checks (rápidos)
- CI completo (tests, calidad, SAST, SCA, etc.)
Y solo main ejecuta:
- CD (deploy)
Protección por rama
| Rama | PR Checks | CI completo | Merge bloqueado si falla | CD | Propósito |
|---|---|---|---|---|---|
| feature → develop | ✔ Sí | ✔ Sí | ✔ Sí | ❌ No | Integración continua sin romper develop |
| develop → release | ✔ Sí | ✔ Sí | ✔ Sí | ❌ No | Preparar versiones estables para QA/UAT |
| hotfix → release | ✔ Sí | ✔ Sí | ✔ Sí | ❌ No | Corregir release sin romperla |
| release → main | ✔ Sí | ✔ Sí | ✔ Sí | ✔ Sí (después del merge) | Publicar versión estable |
| hotfix → main | ✔ Sí | ✔ Sí | ✔ Sí | ✔ Sí (después del merge) | Deploy urgente a producción |
Lo que se ejecuta en cada rama:

Ejemplo de lo que pasa con las ramas (develop, release, main):
El CI se ejecuta en la rama del PR:
- PR desde
feature/xxx→ haciadevelop - CI se ejecuta en la rama feature
- Si CI aprueba → se permite merge a
develop
Después del merge, se dispara otro CI/CD en la rama destino:
- Merge a
develop→ dispara CI/CD dedevelop - Merge a
release/x.y→ dispara CI/CD de release - Merge a
main→ dispara CI/CD de producción
Soporte multi-modelo
Si se implementa bien el pipeline, soportará al menos estos tres modelos corporativos:
-
Trunk-Based:
- PR → CI
- Merge a
main - CD → producción
-
GitFlow:
- PR → CI
- Merge a
develop - CD → Dev/Staging
- Release branch → CD → Preprod
- Merge a
main→ CD → Producción
-
Release-Branches corporativas:
- PR → CI
- Merge a
release/x.y - CD → entornos regulados
- Merge a
main→ producción
Flujo moderno del desarrollador con IA
Descripción
En este punto se recogen ideas de cómo se puede trabajar con IA en el flujo de trabajo de un desarrollador que usa IA de manera intensiva. No existe una estrategia perfecta y está en constante evolución; lo que se presenta aquí es un punto de partida para captar ideas. Algunas se aplicarán en ciertos casos y no en otros, con mayor o menor intensidad, dependiendo de la necesidad y de la comodidad del desarrollador.
Diagrama

Detalle de cada paso
1) Inicio del Proyecto: Configuración Inteligente del Entorno
-
1.1. Inicialización del proyecto con IA:
- genera la estructura inicial (carpetas, módulos, configuración).
- propone estándares del equipo (naming, arquitectura, linters).
- crea archivos base (
README,CONTRIBUTING,docker-compose,.editorconfig). - configura CI/CD inicial (GitHub Actions, GitLab CI, Azure Pipelines…).
- genera documentación inicial del dominio.
-
1.2. Descarga de prompts corporativos (garantiza que la IA trabaje alineada con la cultura técnica del equipo):
- prompts oficiales de la empresa (estándares de arquitectura, seguridad, estilo).
- políticas internas (naming, patrones, restricciones).
- plantillas de tareas (feature, fix, refactor).
- skills internos (por ejemplo: “validar arquitectura hexagonal”).
-
1.3. Activación de skills del proyecto permiten que la IA:
- entienda el dominio del negocio.
- conozca las reglas internas.
- acceda a documentación interna.
- aplique patrones específicos del proyecto.
Ejemplo:
“Skill: Validar que cualquier endpoint nuevo pase por el módulo de autorización corporativo.”
2) Conexión con Jira, Git y el Repositorio
-
2.1. Trabajar con tareas (por ejemplo, de Jira) desde el IDE (la IA accede a Jira mediante MCPS o skills corporativos); el desarrollador puede pedir:
- “Lee la tarea DATA-505 y dame un resumen técnico”.
- “Actualiza el estado de la tarea a In Progress”.
- “Dime qué dependencias tiene esta tarea”.
-
2.2. Creación automática de la rama con IA y actualización de la tarea (Jira) de forma automática.
-
2.3. Lectura del repositorio remoto, donde la IA puede:
- leer ramas.
- comparar diffs.
- analizar commits.
- revisar historial.
- detectar puntos críticos.
3) Desarrollo con IA: Agentes, MCPS y Automatización
-
3.1. Agentes de IA en el IDE (Multi-Agent Coding Systems). El IDE ejecuta varios agentes simultáneamente:
- genera implementaciones completas.
- propone refactors.
- detecta errores lógicos.
- sugiere patrones de diseño.
- Tipos de agentes:
- Agente de Arquitectura: valida que el cambio respete la arquitectura (DDD, Hexagonal, CQRS), detecta acoplamientos indebidos, propone reorganización de módulos.
- Agente de Seguridad: analiza vulnerabilidades en tiempo real, detecta dependencias inseguras, valida configuraciones (CORS, JWT, roles).
- Agente de Documentación: genera docstrings, actualiza documentación, crea diagramas.
- Agente de Testing: genera tests unitarios y de integración, detecta casos límite, propone mocks y fixtures.
-
3.2. MCPS y sesiones Multi-Contexto, donde la IA entiende todo el proyecto (no solo el archivo actual):
- analiza cientos de archivos simultáneamente.
- detecta inconsistencias entre módulos.
- propone cambios coordinados.
- mantiene memoria del dominio.
Ejemplo real:
“He cambiado el modelo User. Actualiza servicios, controladores, validaciones y tests.”
-
3.3. Generación de Código Guiada por Tareas:
- El desarrollador puede pedir:
- “Planifica la implementación de la tarea DATA-505”.
- “Dame un plan de commits”.
- “Genera el código del servicio y los tests”.
- La IA genera:
- plan técnico.
- subtareas.
- orden de commits.
- código inicial.
- tests.
- documentación.
- El desarrollador puede pedir:
-
3.4. Validación Continua Local (Pre-CI), es decir, antes de hacer commit la IA ejecuta:
- análisis estático.
- validación de arquitectura.
- revisión de seguridad.
- generación de tests faltantes.
- limpieza de código.
- optimización de rendimiento.
- detección de deuda técnica.
4) Interacción con Jira y Git Durante el Desarrollo
-
4.1. Actualización automática de Jira, donde la IA puede:
- actualizar el estado de la tarea (ej.: mover la tarea a “In Progress” o actualizar subtareas).
- actualizar la tarea con los comentarios de la IA o el desarrollador (ej.: añadir comentarios técnicos).
- adjuntar datos (como capturas o logs).
-
4.2. Lectura de ramas remotas, donde el desarrollador puede pedir:
- “Compárame esta rama con develop”.
- “Dime si hay conflictos potenciales”.
- “Dime qué tareas están relacionadas”.
5) Commits Inteligentes — Conventional Commits
La IA genera commits:
- siguiendo Conventional Commits (convención estándar para mensajes de commit).
- con referencia al ticket Jira.
- con resumen técnico.
- con impacto funcional.
- con notas para el revisor.
Ejemplo:
feat(DATA-505): añadir endpoint GET /users con validación y tests
6) Simulación de PR (Pre-PR Review)
Antes de subir la rama, la IA ejecuta una revisión simulada (lo que reduce el tiempo de revisión real):
- analiza el diff.
- detecta riesgos.
- sugiere mejoras.
- identifica partes confusas.
- genera checklist de calidad.
- propone documentación adicional.
- detecta inconsistencias con la arquitectura.
- valida seguridad.
7) Preparación del PR
La IA genera automáticamente:
- título del PR.
- descripción técnica.
- impacto funcional.
- riesgos.
- checklist.
- notas para QA.
- enlaces a Jira.
- diagramas si son necesarios.
Ejemplo:
DATA-505: Nueva API de usuarios
8) Subida de la Rama y Creación del PR
Finalmente, el desarrollador hace (o se lo pide a la IA):
git push --set-upstream origin feature/DATA-505-nueva-api-usuarios
Y la IA:
- crea el PR.
- lo vincula a Jira.
- añade reviewers.
- adjunta documentación generada.
- dispara el CI/CD.
Pull Request (PR)
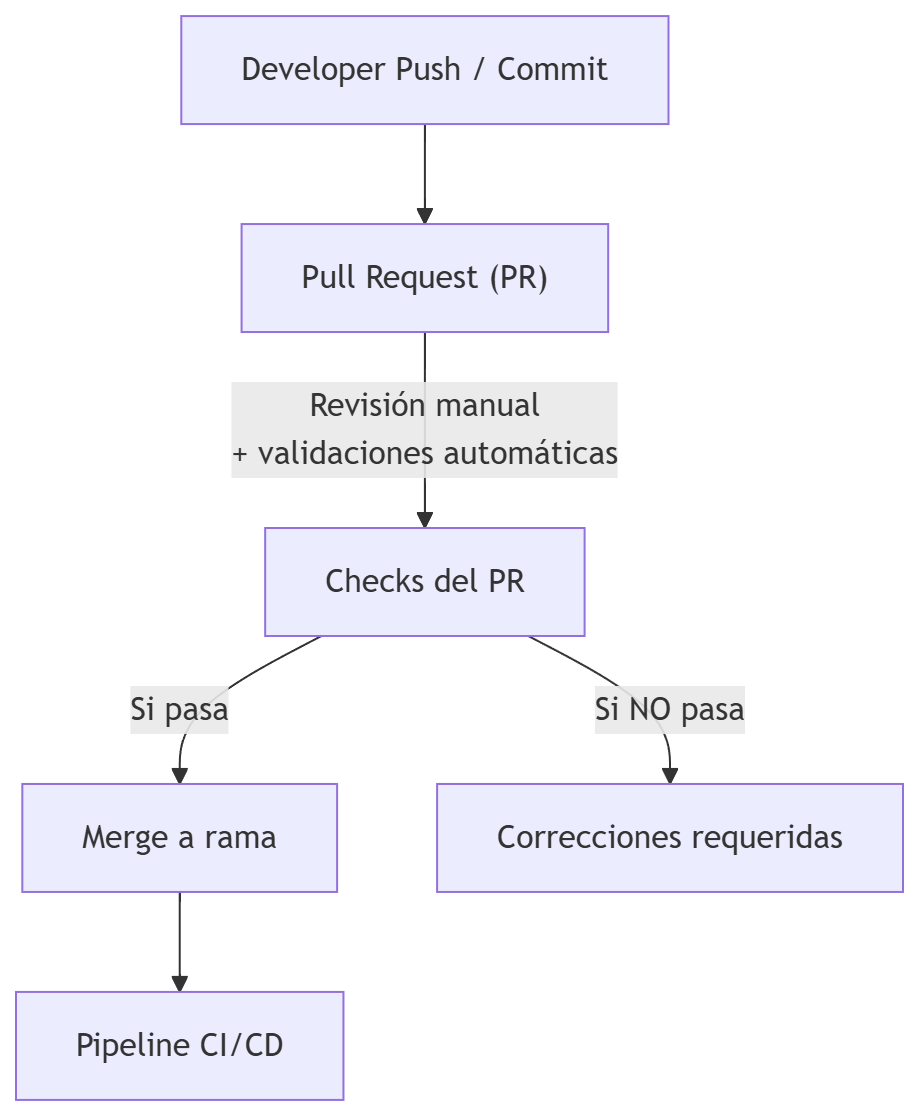
Descripción
Su objetivo es garantizar que el código que entra en la rama cumple los estándares mínimos de calidad, estilo, seguridad y mantenibilidad antes de activar el pipeline de CI/CD.
El PR es el primer filtro de calidad y colaboración del equipo.
Características:
- Es el punto de entrada del código al repositorio principal.
- Incluye revisión humana (peer review) para validar: claridad del código, diseño, mantenibilidad, cumplimiento de estándares internos.
- Incluye validaciones automáticas, como: compilación, linters, formateo, análisis estático ligero, tests unitarios rápidos (opcional según equipo).
- Evita que código incorrecto llegue al pipeline CI/CD, reduciendo fallos posteriores.
- Permite discusión técnica, sugerencias y aprendizaje entre desarrolladores.
- Es obligatorio en la mayoría de organizaciones, especialmente en entornos regulados o de alta criticidad.
Cuándo interesa ejecutarlo: Previo al pipeline CI/CD. Pasar el PR es el desencadenante del pipeline CI/CD.
Revisión humana
- Calidad del código.
- Legibilidad.
- Diseño y arquitectura.
- Correcto uso de patrones.
- Eliminación de código muerto.
- Comentarios innecesarios.
- Nombres claros y semánticos.
- Evitar duplicación.
Checks automatizados
(Para más detalle ver la sección “PR Checks (Pre-CI)” del artículo sobre CI.)
- Compilación correcta.
- Linter (Checkstyle, ESLint, Spotless…).
- Formateo automático.
- Tests unitarios rápidos (opcional).
- Análisis estático básico (sin Quality Gate completo).
- Verificación de dependencias (opcional).
- Políticas de seguridad (secret scanning, branch protection).
IA en esta fase
En los equipos avanzados, el Pull Request ya no es únicamente un punto de revisión humana y unos checks básicos. Es un proceso aumentado por IA, donde agentes inteligentes analizan el código, detectan riesgos, generan documentación, predicen fallos y colaboran con los revisores humanos para garantizar que el código que va a ser mergeado a la rama (normalmente main) es seguro, mantenible y coherente con la arquitectura del proyecto.
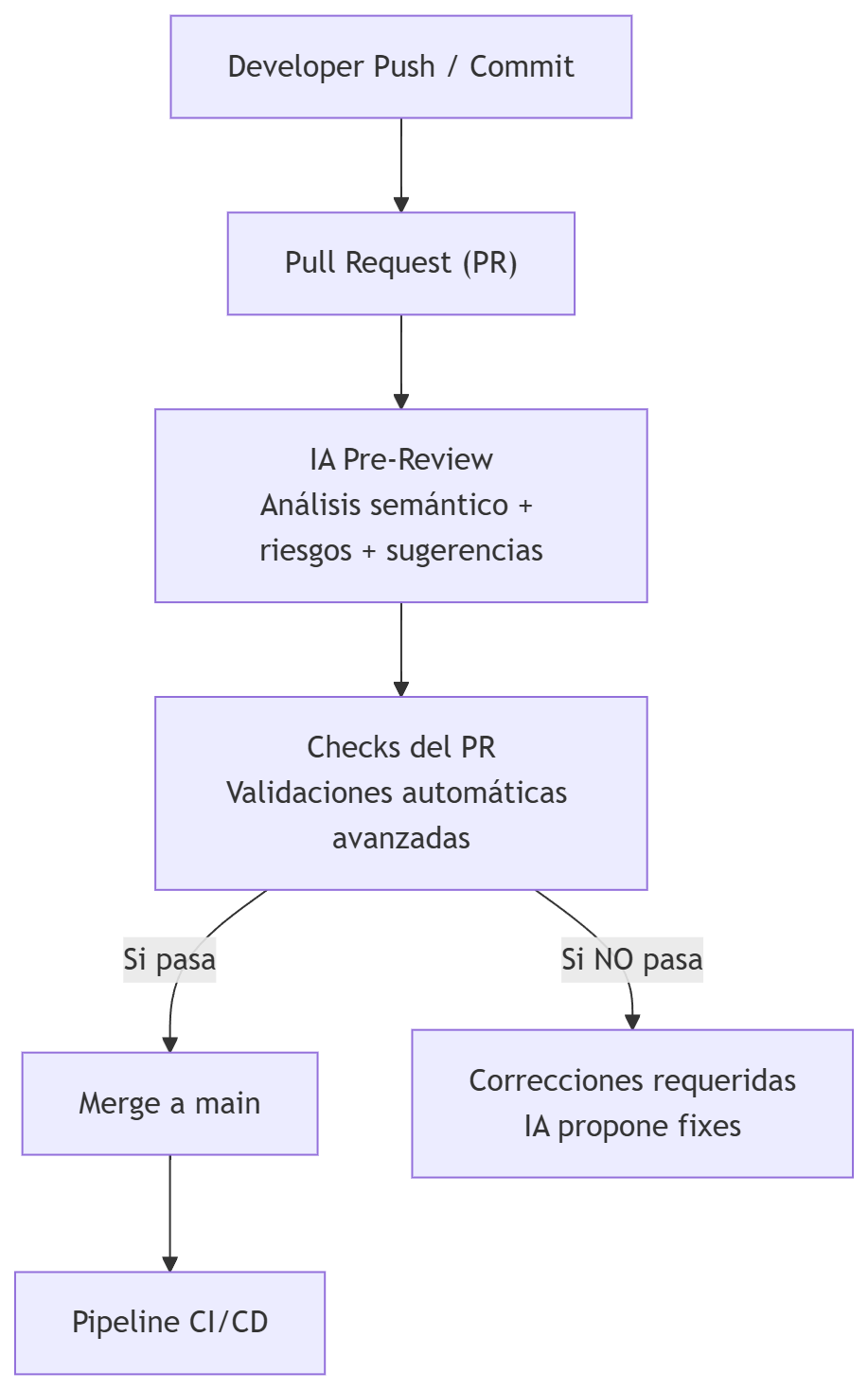
1) IA Pre-Review (antes de la revisión humana)
Cuando se abre el PR, la IA ejecuta una revisión previa que complementa y acelera el trabajo del revisor humano. Realiza:
-
Análisis semántico del diff. La IA no se limita a revisar sintaxis:
- detecta errores lógicos.
- identifica efectos colaterales.
- analiza impacto en módulos relacionados.
- detecta inconsistencias con la arquitectura (DDD, hexagonal, CQRS).
-
Detección de riesgos. La IA detecta:
- duplicación.
- deuda técnica.
- puntos frágiles.
- violaciones de patrones.
- complejidad innecesaria.
-
Sugerencias automáticas. La IA propone:
- refactors.
- simplificaciones.
- mejoras de rendimiento.
- reorganización de módulos.
- nombres más claros.
-
Generación automática de documentación del PR. La IA incluye:
- resumen técnico.
- impacto funcional.
- riesgos.
- cambios relevantes para QA.
- diagramas (ej.: mermaid) si son necesarios.
2) Checks automáticos avanzados (GitHub Actions / Jenkins / GitLab / Azure DevOps)
Las empresas modernas ya no ejecutan solo linters y tests rápidos, sino que ejecutan validaciones inteligentes basadas en IA, como:
-
Seguridad (IA + SAST + SCA):
- detección de vulnerabilidades OWASP.
- análisis de dependencias inseguras.
- detección de secretos (secret scanning inteligente).
- validación de configuraciones (CORS, JWT, roles).
- análisis de permisos y rutas críticas.
-
Testing inteligente:
- generación automática de tests faltantes.
- detección de casos límite no cubiertos.
- análisis de fragilidad de tests.
- ejecución selectiva de tests relevantes (test impact analysis).
-
Arquitectura y diseño:
- cumplimiento de arquitectura (DDD, hexagonal, CQRS).
- acoplamientos indebidos.
- violación de capas.
- dependencias circulares.
- patrones incorrectos.
-
Documentación y trazabilidad:
- generación automática de documentación técnica del PR.
- actualización de diagramas (ej.: mermaid) si son necesarios.
- notas de release preliminares.
- enlaces automáticos a Jira.
-
Análisis de calidad avanzado:
- detección de code smells.
- duplicación.
- complejidad ciclomática.
- funciones demasiado largas.
- nombres poco semánticos.
-
Validación de estándares corporativos:
- convenciones internas.
- políticas de seguridad.
- patrones obligatorios.
- estructura de carpetas.
- convenciones de commits.
3) Interacción con el revisor humano
La IA no sustituye al revisor, sino que lo potencia, con:
-
La IA resume el PR para la toma de decisiones del revisor y le dice:
- qué se ha cambiado.
- por qué.
- impacto.
- riesgos.
- módulos afectados.
-
La IA responde preguntas del revisor, como por ejemplo:
“¿Este cambio afecta al módulo de pagos?” “¿Qué tests cubren este caso?”
-
La IA propone fixes automáticos: si el revisor detecta un problema, la IA puede generar el parche.
4) Correcciones asistidas por IA
Si los checks fallan (el desarrollador solo revisa y confirma lo siguiente):
- la IA explica el error.
- propone la solución.
- genera el código corregido.
- actualiza tests.
- reescribe documentación si es necesario.
5) Cómo se ve esto en un pipeline real (Ejemplos de jobs/stages del PR)
Un pipeline moderno incluye jobs de GitHub Actions como (cada job ejecuta un agente especializado que complementa los checks tradicionales):
ai-pre-reviewai-security-scanai-test-generationai-architecture-checkai-doc-generationai-pr-summary
O stages en el pipeline de Jenkins como:
pipeline {
stages {
stage('AI Pre-Review') { steps { aiPreReview() } }
stage('Security Scan') { steps { aiSecurityScan() } }
stage('Architecture Check') { steps { aiArchitectureCheck() } }
stage('Test Generation') { steps { aiTestGeneration() } }
stage('Quality Analysis') { steps { aiQualityCheck() } }
stage('Documentation') { steps { aiDocGeneration() } }
}
}
6) Beneficios del PR aumentado por IA:
- Menos tiempo de revisión.
- Menos errores en producción.
- Menos deuda técnica.
- Menos inconsistencias arquitectónicas.
- Más seguridad.
- Más trazabilidad.
- Más calidad.
- Más velocidad.
