Curso de Bases de Datos con MySql -Parte V- (Video) «Group By»
Este Curso de bases de datos con MySql esta formado por las siguientes entradas:
- Parte I: Instalación del MySql Server y MySql Workbench
- Parte II: Creacción de Tablas y Relaciones entre tablas (Modelo Entidad-Relación)
- Parte III: Sentencias básicas de MySql (Definition & Manipulation)
- Parte IV: Sentencia «INNER JOIN» para la unión de Tablas
- Parte V: Sentencia «GROUP BY» para la agrupación de datos
Parte V: Sentencia «Group By» para la agrupación de datos
La sentencia «Group By» tiene como finalidad la de agrupar valores idénticos de una tabla. A aplicar esta sentencia a una/s columna/s de la tabla origen, tenemos como resultado una única fila resumen por cada grupo de elementos únicos formados. A esta claúsula le podemos aplicar también una serie de funciones de agregación que nos permiten efectuar operaciones sobre un conjunto de resultados, pero devolviendo un único valor agregado para todos ellos. Alguna de estas funciones de agregación son: COUNT(), SUM(), MAX(), MIN(), AVG(), STDEV(), STDEV(), VAR(), VARP().
Veamos paso por paso un ejemplo sencillo para entender lo que hace esta sentencia. En primer lugar nos vamos a crear una base de datos que tendrá una única tabla ‘coches‘ en la que vamos a aplicar estas sentecias. A continuación copio el script para la creacción de esta base de datos con la tabla coches y una serie de tuplas (si teneis dudas para hacer esto mirar el video o el tutorial «Creacción de Tablas y Relaciones entre tablas (Modelo Entidad-Relación)«):
SET @OLD_UNIQUE_CHECKS=@@UNIQUE_CHECKS, UNIQUE_CHECKS=0; SET @OLD_FOREIGN_KEY_CHECKS=@@FOREIGN_KEY_CHECKS, FOREIGN_KEY_CHECKS=0; SET @OLD_SQL_MODE=@@SQL_MODE, SQL_MODE='TRADITIONAL,ALLOW_INVALID_DATES'; DROP SCHEMA IF EXISTS `miprimerabasededatos` ; CREATE SCHEMA IF NOT EXISTS `miprimerabasededatos` DEFAULT CHARACTER SET utf8 ; SHOW WARNINGS; USE `miprimerabasededatos` ; -- ----------------------------------------------------- -- Table `coches` -- ----------------------------------------------------- DROP TABLE IF EXISTS `coches` ; CREATE TABLE IF NOT EXISTS `coches` ( `id` INT(11) NOT NULL AUTO_INCREMENT , `Marca` VARCHAR(45) NOT NULL , `Modelo` VARCHAR(45) NOT NULL , `kilometros` INT(11) NOT NULL , PRIMARY KEY (`id`) ) ENGINE = InnoDB AUTO_INCREMENT = 10 DEFAULT CHARACTER SET = utf8; SHOW WARNINGS; SET SQL_MODE=@OLD_SQL_MODE; SET FOREIGN_KEY_CHECKS=@OLD_FOREIGN_KEY_CHECKS; SET UNIQUE_CHECKS=@OLD_UNIQUE_CHECKS; INSERT INTO `coches` (`id`,`Marca`,`Modelo`,`kilometros`) VALUES (1,'Renault','Clio',10); INSERT INTO `coches` (`id`,`Marca`,`Modelo`,`kilometros`) VALUES (2,'Renault','Megane',23000); INSERT INTO `coches` (`id`,`Marca`,`Modelo`,`kilometros`) VALUES (3,'Seat','Ibiza',9000); INSERT INTO `coches` (`id`,`Marca`,`Modelo`,`kilometros`) VALUES (4,'Seat','Leon',20); INSERT INTO `coches` (`id`,`Marca`,`Modelo`,`kilometros`) VALUES (5,'Opel','Corsa',999); INSERT INTO `coches` (`id`,`Marca`,`Modelo`,`kilometros`) VALUES (6,'Renault','Clio',34000); INSERT INTO `coches` (`id`,`Marca`,`Modelo`,`kilometros`) VALUES (7,'Seat','Ibiza',2000); INSERT INTO `coches` (`id`,`Marca`,`Modelo`,`kilometros`) VALUES (8,'Seat','Cordoba',99999); INSERT INTO `coches` (`id`,`Marca`,`Modelo`,`kilometros`) VALUES (9,'Renault','Clio',88888);
Una vez creada la tabla, vemos que cada coche está carazterizado por una Marca, un Modelo y tiene una serie de kilometros realizados. Si hiciésemos una agrupación por Marca, tendríamos como resultado todas las Marcas de coche distintas que hay en esta tabla. Veamos nuestra primera query de agrupación y el resultado que obtenemos:
SELECT Marca FROM miprimerabasededatos.coches GROUP BY Marca;
Con esta query hacemos lo siguiente:
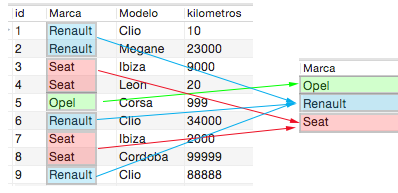
Vemos que en la tabla tenemos 3 Marcas de coche diferentes y por tanto al agruparlas nos dice cuales son. De igual forma podemos hacer una agrupación por más campos; por ejmeplo, podemos ver cuanto coches distintos hay teniendo en cuenta la Marca y el Modelo:
SELECT Marca, Modelo FROM miprimerabasededatos.coches GROUP BY Marca, Modelo;
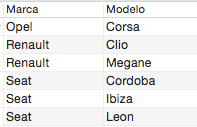
Como se ha dicho en la introducción también podemos aplicar funciones matemáticas a las agrupaciones. Veamos la primera y la más intuitiva, que es la de contar el número de coches que hay con Marcas distintas. Esto lo hacemos aplicando la función ‘COUNT()‘ de la siguiente manera:
SELECT Marca, COUNT(*) FROM miprimerabasededatos.coches GROUP BY Marca;
Si hacemos cuentas antes de ver el resultado, vamos a obtener que hay 4 coches de la Marca Renault y Seat, y que por otro lado hay solo un coche de la Marca Opel:
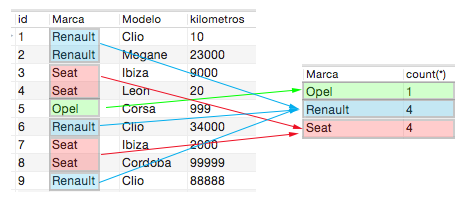
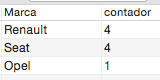
También podemos aplicar una ordenación, para que nos ordene la operación de mayor a menor. Esto se hace de la siguiente forma:
SELECT Marca, COUNT(*) AS contador FROM miprimerabasededatos.coches GROUP BY Marca ORDER BY contador DESC;
Habiendo hecho ya una operación sencilla con la función ‘COUNT()’, puede resultar más o menos intuitivo aplicar el resto de funciones. Por ejemplo vamos ahora a grupar por Marca de coche y vamos ha hacer la suma de los kilometros que han realizado los coches por Marca. Esto lo hacemos pasándole a la función ‘SUM()’ el nombre de la columna sobre la que ha de aplicar esa operación, que en este caso es la columna ‘kilometros’:
SELECT Marca, SUM(kilometros) FROM miprimerabasededatos.coches GROUP BY Marca;
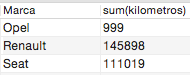
Podemos obtener también el coche por marca que mas kilometros ha realizado o menos, aplicando las funciones ‘MAX()’ y ‘MIN()’
SELECT Marca, MAX(kilometros) FROM miprimerabasededatos.coches GROUP BY Marca; SELECT Marca, MIN(kilometros) FROM miprimerabasededatos.coches GROUP BY Marca;

De esta forma podíamos seguir aplicando todas las funciones que se han comentado al principio para las agregaciones.
CONCLUSIONES:
Este tutorial esta destinado a aquellas personas o estudiantes que están empezando a ver consultas en bases de datos. Es un tutorial muy sencillo que tiene como finalidad mostrar la clausula «GROUP BY» y que esta sea bien entendida para aplicarla posteriormente en queries muchisimo más complejar, ya que los ejemplos puestos aquí son muy sencillos.

interesante, gracias por la ayuda…