Dockerfile avanzado: multietapa, repositorio y trucos
Vamos a explorar más allá de las operaciones básicas en Docker, ya que nos revelará una gran cantidad de trucos que nos convertirán en unos expertos. Por ejemplo, el uso de Dockerfiles de varias etapas, que es un enfoque para optimizar tus imágenes, mejorar el tiempo de construcción y reducir la complejidad de gestión. Asimismo, el manejo eficaz de los repositorios en Docker nos simplificará enormemente la gestión de las imágenes y nos servirá para distribuirlas al resto de la comunidad.
Índice
- Docker básico: Usar imágenes (para todos los públicos).
- Docker Compose: Usar cómodamente imágenes (para todo quien quiera trabajar más cómodamente con Docker).
- Docker Compose en un proyecto: Uso de imágenes en un desarrollo (para aprender de verdad cualquier arquitectura de desarrollo).
- Imágenes Docker: Gestión de imágenes avanzada por consola (para usuarios avanzados).
- Dockerfile: Directivas y Dockerizar proyectos: trabajar con proyectos Dockerizados (para desarrolladores que quieran dockerizar su proyecto)
- Dockerfile avanzado: multietapa, repositorio y trucos: para especializarse en Dockerizacion (para que desarrolladores y managers controlen los detalles)
Git: el código de en este artículo también lo puedes encontrar en https://github.com/Invarato/docker/tree/main/articulos-jarroba/dockerfile-avanzado-multietapa-repositorio-y-trucos
Distribuciones de imágenes base de sistemas operativos
En Docker Hub hay numerosas distribuciones de sistemas operativos, mayormente Linux, que nos servirán de base (para el FROM del Dockerfile) para cualquier necesidad que tengamos. Antes de elegir una de estas, tenemos que ver si no nos satisface nuestra necesidad otro tipo de imagen que ya incluya más software instalado (por ejemplo, si queremos trabajar con Python, pues es mejor usar la imagen de Python que elegir una distribución e instalar a mano Python).
No hay una manera directa para buscar distribuciones, pero podríamos realizar una búsqueda como: https://hub.docker.com/search?q=linux+distribution
Aquí te voy a contar las más populares, para que entiendas todos esos “nombres raros” de las distribuciones:
- Alpine (https://hub.docker.com/_/alpine): pequeño tamaño (alrededor de 5MB) y es comúnmente utilizada en contenedores Docker. Con versiones como 3.19, 3.18 o 3.17 (más versiones en https://alpinelinux.org/releases/ )
- Debian (https://hub.docker.com/_/debian): conocida por su estabilidad y consistencia. Con versiones con nombres como bookworm para Debian 12, bullseye para Debian 11 o búster para Debian 10 (más versiones en https://www.debian.org/releases/ )
- Ubuntu (https://hub.docker.com/_/ubuntu): más conocida, fácil de usar, bien documentada y gran comunidad de usuarios. Con versiones como Noble para Ubuntu 24, Mantic para Ubuntu 23 o Jammy para Ubuntu 22 (más versiones en https://releases.ubuntu.com/ )
- Fedora (https://hub.docker.com/_/fedora): de Red Hat. Con versiones como 41, 40 o 39 (más versiones en https://es.wikipedia.org/wiki/Anexo:Versiones_de_Fedora
- openSUSE: openSUSE ofrece una versión estable (Leap: https://hub.docker.com/r/opensuse/leap) y una versión de lanzamiento continuo (Tumbleweed: https://hub.docker.com/r/opensuse/tumbleweed). Con versiones como 15.6, 15.5 o 15.4 (más versiones en https://en.opensuse.org/openSUSE:Roadmap).
- Amazon Linux (https://hub.docker.com/_/amazonlinux): de Amazon Web Services (AWS) que es comúnmente utilizada en el ecosistema de AWS. Con versiones como 2023, 2 o 1 (más versiones en https://docs.aws.amazon.com/AL2/latest/relnotes/relnotes-al2.html)
Es importante tener en cuenta con respecto a la elección de una buena imagen base:
- Tamaño: Si queremos que nuestra imagen sea lo más liviana posible, lo mejor es usar una distribución que incluya en el tag el sufijo “little”, “slim” o algún sinónimo (por ejemplo, es lo que diferencia entre “debian/bookworm” vs “debian/bookworm-slim”) o de alguna imagen famosa que ya sea ligera de por sí como “Alpine”. La desventaja de usar una imagen ligera es que viene pelada (por eso apenas ocupa nada), es decir, que nos tocará instalar todo lo que necesitemos (quizás no lleve ni “curl” instalado y lo tengamos que instalar antes de descargar lo que queramos).
- Gestión de paquetes: Cambian con los sistemas operativos, por ejemplo, Alpine utiliza “apk” (ligero y rápido), en comparación con Ubuntu que utiliza “apt” (más familiar para muchos usuarios).
- Compatibilidad: No incluyen el mismo software instalado, por ejemplo, Alpine utiliza “musl libc” para su biblioteca C (por ser la más ligera, pero con problemas de compatibilidad), en comparación con Ubuntu que incluye “glibc” (compatible con muchísimo software).
- Facilidad de uso: Ubuntu puede ser más fácil de usar (comunidad de usuarios más grande, más documentación y más paquetes disponibles).
- Arquitectura: la imagen base que elijamos (en general, aunque esta limitación viene por el sistema operativo) nos va a definir sobre cuáles arquitecturas de hardware vamos a poder ejecutarla, pues no es lo mismo una imagen para una arquitectura x86_64 (la mayoría de los PCs) que para una ARM (para algunos móviles). Por ejemplo, Alpine lo tenemos disponibles las siguientes arquitecturas: linux/386, linux/amd64, ,linux/arm/v6, linux/arm/v7, linux/arm64/v8, linux/ppc64le, linux/s390x. Para facilitar esto, Docker permite imágenes multi-arquitectura (multi-arch images), que permite especificar múltiples imágenes para diferentes arquitecturas con un único nombre, así Docker seleccionará automáticamente la imagen correcta basándose en la arquitectura del host donde se esté.
Dockerizar sin proyecto
Además de Dockerizar un proyecto podemos tener un Dockerfile solo (sin código asociado), pues quizás queramos construir una imagen con tecnologías ya existentes.
Para este ejemplo quiero mi propio servidor de Jupyter Lab Notebook (es una aplicación web que permite crear y compartir documentos que contienen código en vivo, ecuaciones, visualizaciones, etc. Más información en https://jarroba.com/instalar-jupyter-notebook-y-jupyterlab-por-consola-desde-cero-y-aprender-a-usarlos/ ). En este ejemplo voy a hacer una imagen personalizada “como me dé la gana y que cubra mis supuestas necesidades”, lo haré utilizando las más directivas que pueda para que te sirvan de ejemplo de uso (si estás buscando un Jupyter preconstruido tienes un montón en https://hub.docker.com/u/jupyter ), intentaré que Jupyter sea lo más estándar posible según la documentación, además, realizaré la instalación a mano de Python (NO usaré la imagen anterior de https://hub.docker.com/_/python, sino que usaré una imagen base limpia) y de todo lo que necesite.
Para Python necesitaré:
- python3: el paquete para el lenguaje de programación Python 3.
- python3-pip: el administrador de paquetes para Python. Lo instalo desde el gestor de paquetes APT porque es una buena práctica que gestione éste todos los paquetes en imágenes de Docker (principalmente por si alguien utiliza esta imagen que estamos construyendo como base, para que pueda ver rápidamente qué has instalado).
- python3-venv: como buena práctica nos servirá para crear «entornos virtuales», donde instalaremos y administraremos paquetes de Python de manera independiente, sin interferir con las bibliotecas del sistema.
Para realizar todo esto haré (aquí resumiré las directivas, están todas en el Dockerfile que sigue a esta explicación):
- Quiero un sistema operativo lo más liviano y actualizado que pueda que tenga de sistema de gestión de paquetes APT: debian:bookworm-20240211-slim
- Como lo voy a montar yo, le pondré LABELs con información como mi nombre y la versión: LABEL authors=»Ramon Invarato»
- Por la documentación de Jupyter sé que su puerto estándar es el 8888 (https://docs.jupyter.org/en/latest/running.html), así que lo documento: EXPOSE 8888
- Me aseguro de ser usuario root para realizar las instalaciones con: USER root
- Actualizo APT e instalo lo que necesito de Python: RUN apt install -y python3 python3-pip python3-venv
- Estableceré las variables de entorno que considere necesarias de Python para que estén disponibles: ENV PIP=/usr/bin/pip3
- Creo un usuario sin derechos root para quitar los permisos root a quien use mi imagen: RUN adduser –disabled-password –gecos » misuarionoroot
- Creo una carpeta y le doy permisos para el usuario NO root: RUN chown -R misuarionoroot:misuarionoroot /usr/src/app
- Crearé un entorno virtual para el usuario, por lo que también le daré permisos y lo estableceré como variable de entorno para facilitarle el trabajo futuro: RUN python3 -m venv /opt/venv
- Cambiaré al usuario sin permisos: USER misuarionoroot
- Le cambiaré el directorio de trabajo al que le di permisos para que pueda trabajar directamente sobre el mismo: WORKDIR /usr/src/app
- Activaré el entorno virtual: RUN . /opt/venv/bin/activate
- Instalaré bibliotecas que necesitamos de Jupyter dentro del entorno virtual las: RUN pip3 install jupyter jupyterlab
- Inicio Jupyter lab: ENTRYPOINT [«jupyter», «lab», «–no-browser», «–port=8888»]
- Además, añado variables por defecto al comando anterior (que el usuario de mi imagen podrá modificar si lo considera): CMD [«–NotebookApp.token=»», «–ip=0.0.0.0»]
El fichero Dockerfile completo:
# Descargamos una imagen base de un sistema operativo pelado
FROM debian:bookworm-20240211-slim
# Documentamos los metadatos que necesitemos
LABEL authors="Ramon Invarato"
LABEL description="Esta es una imagen personalizada de Python con Jupyter "
LABEL maintainer="ramon@jarroba.com"
LABEL version="1.0"
LABEL build_date="2024-03-01"
# Documentamos que exponemos el puerto del servidor Jupyter
EXPOSE 8888
# Nos aseguramos de ser root para realizar las instalaciones
USER root
# Instalamos Python, pip, así como otras dependencias que necesitarán las bibliotecas de Python:
RUN apt update
RUN apt install -y python3 python3-pip python3-venv
# Establecemos las varibles de entorno útiles de Python para quien use nuestra imagen que las tenga disponibles
ENV PYTHON=/usr/bin/python
ENV PIP=/usr/bin/pip3
ENV PATH=$PATH:$PIP:$PYTHON
# Creamos un usuario sin privilegios (sin er root) para quien use la imagen, creamos una carpeta que será donde se pueda trabajar y se la damos a ese usuario
RUN adduser --disabled-password --gecos '' misuarionoroot
RUN mkdir -p /usr/src/app
RUN chown -R misuarionoroot:misuarionoroot /usr/src/app
# Creamos el entorno virtual de Python, le damos permisos al usuario para que lo pueda usar y lo añadimos a la variable de entorno
RUN python3 -m venv /opt/venv
RUN chown -R misuarionoroot:misuarionoroot /opt/venv
ENV PATH="/opt/venv/bin:$PATH"
# Para enviar la salida de manera inmediata a la salida de Docker
ENV PYTHONUNBUFFERED=1
# Cambiamos al usuario sin permisos root
USER misuarionoroot
# Cambiamos el espacio de trabajo
WORKDIR /usr/src/app
# Activamos el entorno virtual de Python
RUN . /opt/venv/bin/activate
# Instalamos las librerías que necesitemos de Python sobre el entorno virtual de Python
RUN pip3 install jupyter jupyterlab
# Establecemos Jupyter como la aplicación por defecto de este contenedor
ENTRYPOINT ["jupyter", "lab", "--no-browser", "--port=8888"]
# Añadimos más argumentos por defecto, que se podrán cambiar si se requieren
CMD ["--NotebookApp.token=''", "--ip=0.0.0.0"]
Con una terminal vamos al directorio de este Dockercompose:
docker build -t mi-imagen-jupyter .Ejecutamos el contenedor de nuestra imagen con el mapeo de puertos a nuestro local de 8888:
docker run --name mi-contenedor-jupyter -p 8888:8888 mi-imagen-jupyterTerminamos probando que funciona en un navegador: http://localhost:8888/lab
Te facilito una captura con todos los pasos que he realizado:
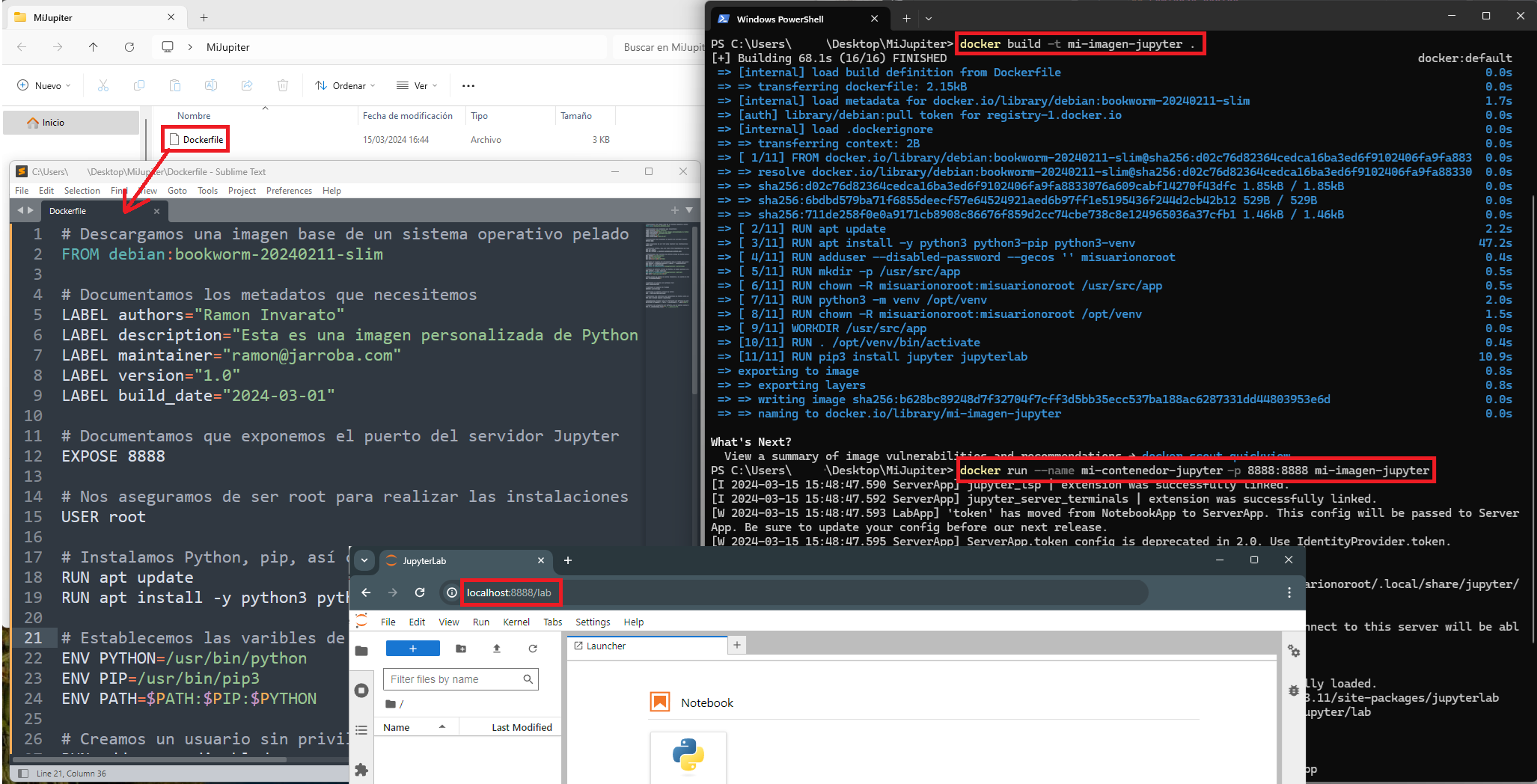
Dockerfile construido con Docker Compose
Si estamos en mitad del desarrollo de nuestros microservicios Dockerizados o Dockerfiles, puede que queramos probarlo en conjunto con otros contenedores. Para ello podemos construir nuestro Dockerfile anterior con un Docker Compose.
Por ejemplo, crearé un “compose.yaml” dentro de la carpeta “MiJupiter” del anterior ejemplo, quedando algo así (el código te lo facilito después de la captura):
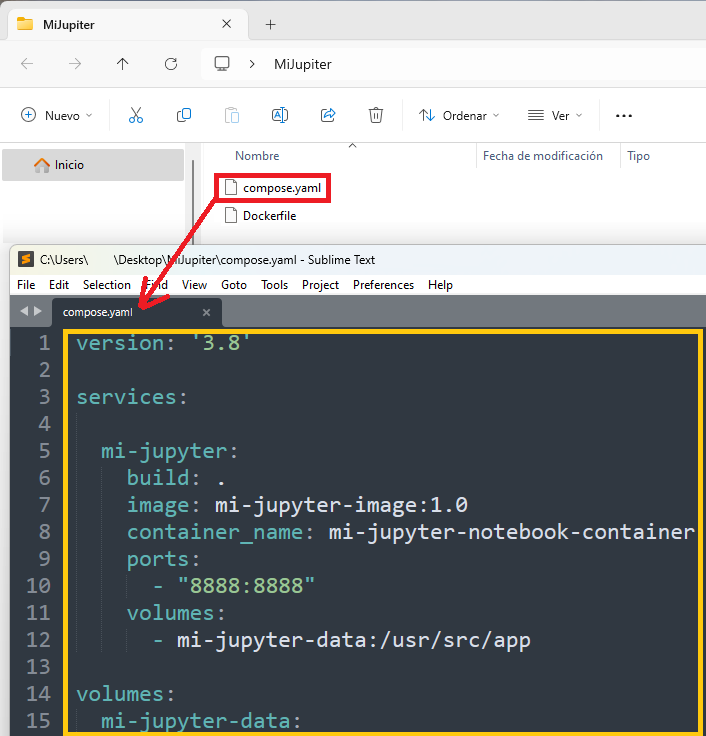
Y le añadiré al “compose.yaml” el siguiente código que me creará la imagen desde mi Dockerfile y la usará en conjunto con el resto del Docker Compose:
version: '3.8'
services:
mi-jupyter:
build: .
image: mi-jupyter-image:1.0
container_name: mi-jupyter-notebook-container
ports:
- "8888:8888"
volumes:
- mi-jupyter-data:/usr/src/app
volumes:
mi-jupyter-data:
En este código hay varias partes nuevas interesantes:
- build: dónde definiremos dónde está el “Dockerfile” que usaremos (“.” Indica que está en la misma ubicación que el “compose.yaml”).
- image: no es obligatorio, pero me gusta poner la versión para invalidar el cacheado de Docker. Pues si ejecutas una vez este “compose.yaml”, luego cambiar el Dockerfile y después vuelves a ejecutar el “compose.yaml”, pues se recuperará del cacheado y no se volverá a compilar el Dockerfile (es decir, los cambios que le hemos hecho no se verán reflejados); al añadir esta imagen versionada, cambiando la versión estoy forzando a que cree nuevas imágenes con dicho tag (eso sí, cada tag nuevo te generará una imagen y ocupará disco duro, habrá que limpiarlas de vez en cuando).
- container_name: siempre me gusta ponerle nombre al contenedor para identificarlo fácilmente.
- ports: mapeo el puerto interno 8888 del Dockerfile con el 8888 de nuestro ordenador local.
- volumes: como hemos creado el Dockerfile sabemos que nuestros datos se guardan en la ruta “/usr/src/app” de nuestro contendor, por lo que si le asignamos un volumen lo tendremos persistido entre reinicios del contenedor.
Como ya hiciéramos en el artículo previo sobre «Docker Compose en un proyecto», levantamos el “compose.yaml” con:
docker compose up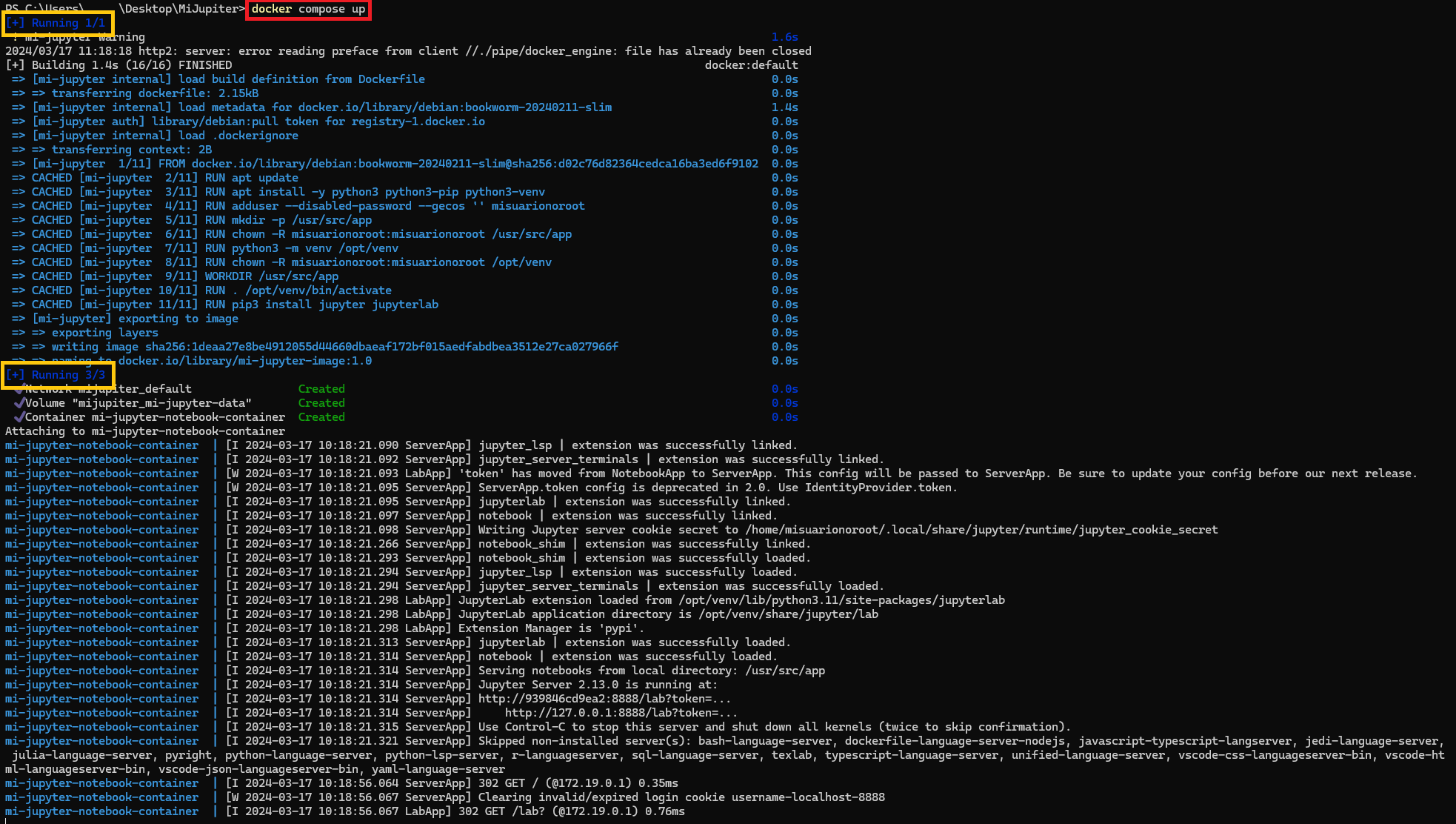
Vemos como en una primera instancia se nos ha compilado el Dockerfile (tal y como hacíamos con build) y, después, ha levantado el contenedor desde esta imagen; es decir, con un solo comando nos lo ha hecho todo (build de la imagen e iniciar el contenedor desde ésta).
Ya podremos usar nuestro Jupyter Notebook si vamos a: http://localhost:8888/lab
Cuando termines, pulsa [CTRL]+[C] para terminar el proceso anterior (docker compose down).
Ahora vamos a modificar nuestro “compose.yaml” para ver un par de detalles importantes más:
version: '3.8'
services:
mi-jupyter:
build:
context: .
dockerfile: Dockerfile
image: mi-jupyter-image:1.1
container_name: mi-jupyter-notebook-container
ports:
- "8888:8888"
volumes:
- mi-jupyter-data:/usr/src/app
command: ["--NotebookApp.token='nuevo_token'", "--ip=0.0.0.0"]
volumes:
mi-jupyter-data:
Fíjate en:
- build: lo he detallado con un “context” que indica la ubicación del fichero Dockerfile y el argumento “dockerfile” es el nombre del fichero que queramos (sigo el estándar de nombrarlo como “Dockerfile”, pero podría haberle llamado “DevDockerfile”, “DockerTest” o como yo quiera), esto viene muy bien para poder trabajar con múltiples entornos.
- image: voy a forzar a recrear la imagen cambiando la versión (en este ejemplo no tiene mucho sentido, puesto que no hemos modificado el Dockerfile, si modificas el Dockerfile entonces esto te ayudará)
- command: ¿Recuerdas el CMD del Dockerfile? Pues con este argumento lo sobrescribimos, en mi ejemplo le voy a añadir un token “nuevo_token” por cambiar algo. Viene bien para permitir modificar parámetros opcionales a quien use nuestra imagen.
Ejecutamos otra vez:
docker compose upNota de forzar recreación de la imagen: existe otra manera de forzar la recreación de la imagen (sin tener que estar enumerando las versiones y tener mil imágenes creadas) que es con el argumento “–force-recreate”. La desventaja de esto es que muchos IDEs que nos ayudan con Docker solo ejecutan “docker compose up” pelado, pero si usas terminal puedes ejecutar:
docker compose up --force-recreateImagen a repositorio
Cuando creamos una imagen suele ser común querer subirla a un repositorio para que más gente se la pueda descargar. Depende de cómo esté configurado, repositorio puede ser público (cualquier persona del mundo tiene acceso) o privado (solo unos pocos con ciertas credenciales tienen acceso). Además, un repositorio podrá estar gestionado por nosotros (por ejemplo, una instalación de Harbor https://goharbor.io/) o por terceros (por ejemplo, el famoso Docker Hub https://hub.docker.com/).
Como ejemplo de imagen y como continuidad con el punto anterior, utilizaremos en este ejemplo la imagen que creamos antes de Jupyter (la del punto “Dockerizar sin proyecto”), por lo que usaremos el Dockerfile anterior. Pero antes vamos a prepararlo todo, para ello vamos a crear nuestro repositorio donde subiremos la imagen, además, necesitaremos el Token para realizar autenticarnos desde la terminar y poder realizar la conexión.
Para ello vamos a https://hub.docker.com/ y pulsamos en “Sign in” si ya tenemos una cuenta (si hiciste el artículo donde te enseño a instalar “Docker Desktop”, entonces ya tendrás una cuenta y podremos utilizar esa), si no tienes cuenta pues tendrás que crear una con “Sign up”.

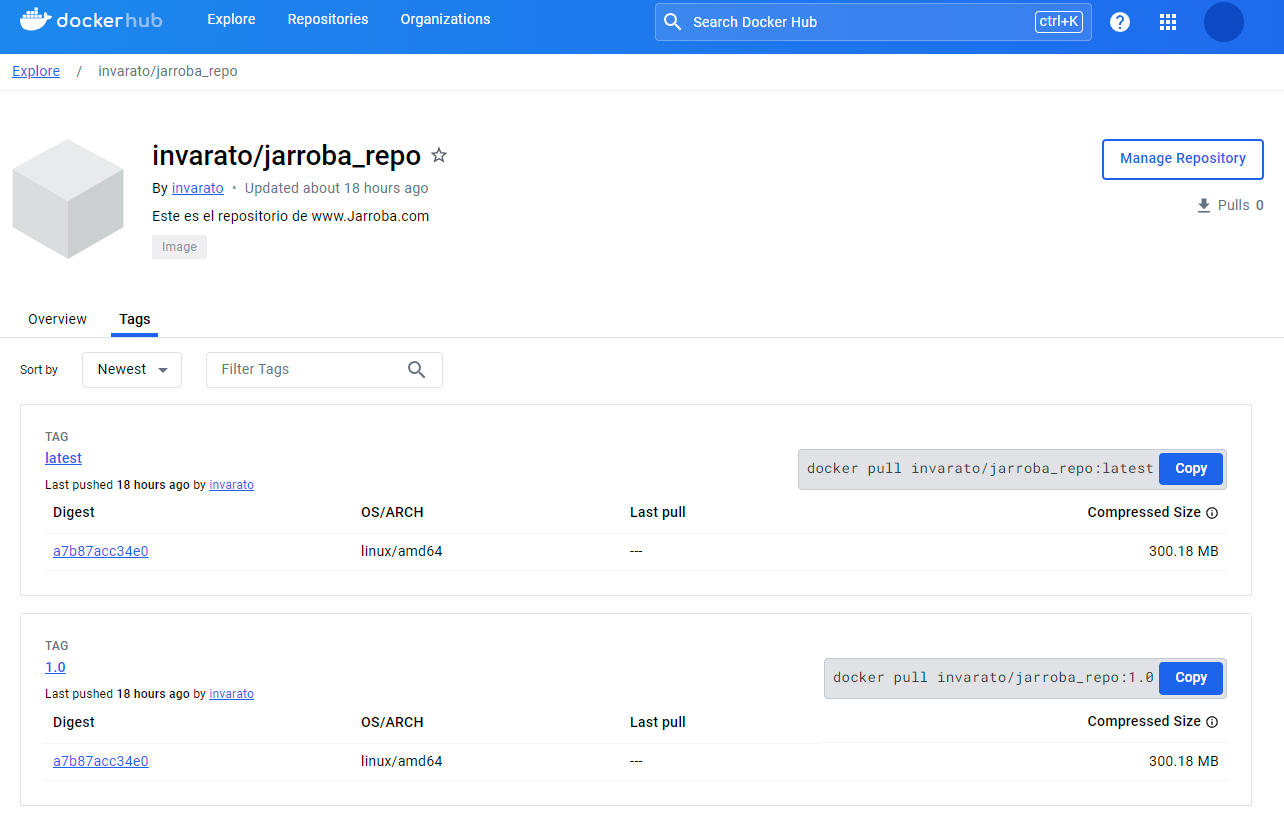
Creamos un nuevo repositorio: en la pestaña “Repositories”, seleccionamos un “espacio de nombres” (por defecto se crea el mismo que la cuenta, ese nos vale para esta prueba) y pulsamos en “Create repository”.
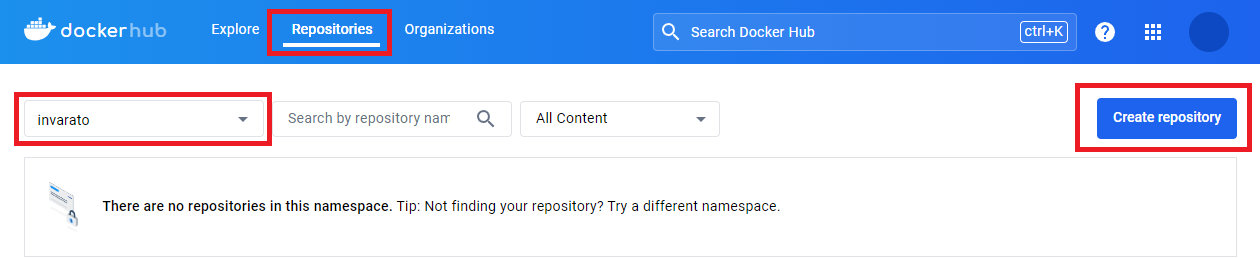
Rellenamos lo datos: en “Repository Name” yo llamaré a mi repositorio “jarroba_repo”, en “Short description” crearé una descripción que detalle mi a mi repositorio (es opcional), en “Visibility” escogeremos si queremos que sea un repositorio público o privado (privado es una opción de pago, pero se nos regala 1 repositorio privado gratis), nos fijamos en los comandos de la derecha (luego los veremos) y pulsamos “Create”.
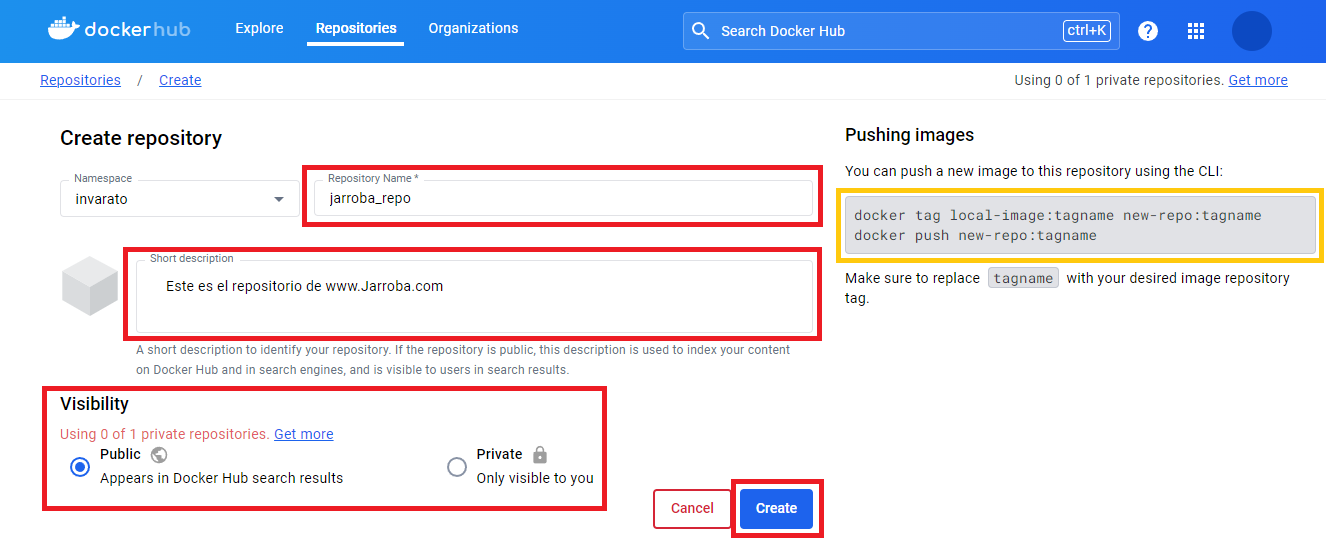
Nota sobre “Repository Name”: este nombre que pongamos será el nombre de la imagen que la gente utilizará para descargar nuestra imagen, es decir, se usará “<Namespace>/<RepositoryName>” en mi caso será “invarato/jarroba_repo” (por las características de la imagen que voy a subir, podría haber llamado a mi repositorio “jupyter” para que quedara “invarato/jupyter”, pero en este artículo quiero que quede clara la diferencia con el repositorio).
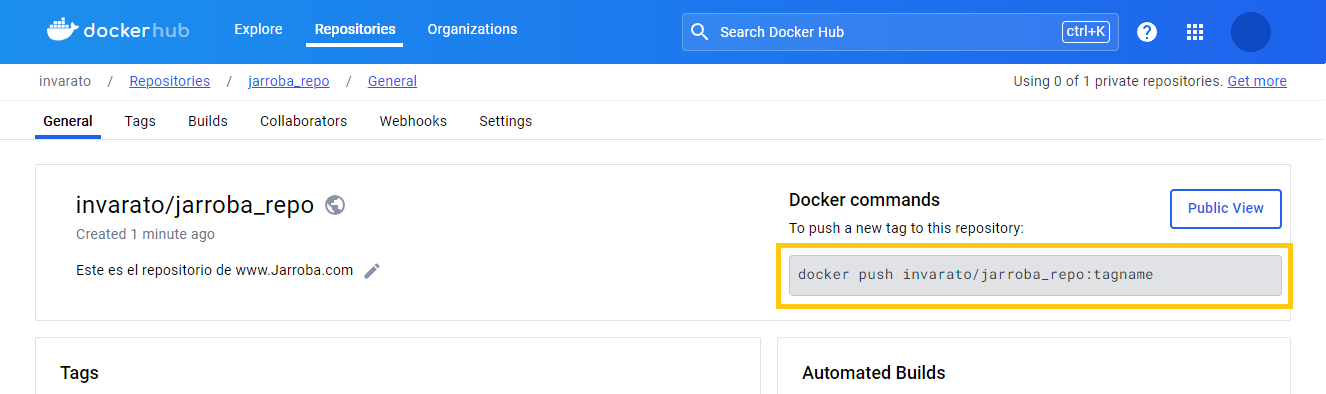
Dentro del repositorio veremos la información y configuración de este, pero ahora lo más importante es fijarnos en el comando de la derecha.
Nuevo Token
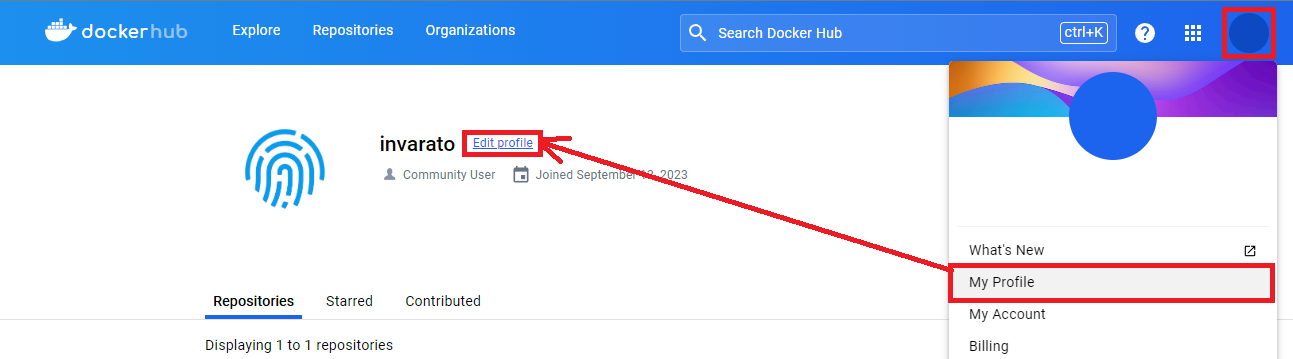
Crearemos un nuevo Token: para ello vamos a nuestro perfil (círculo de arriba a la derecha), pulsamos “My Profile” y después en “Edit profile”.
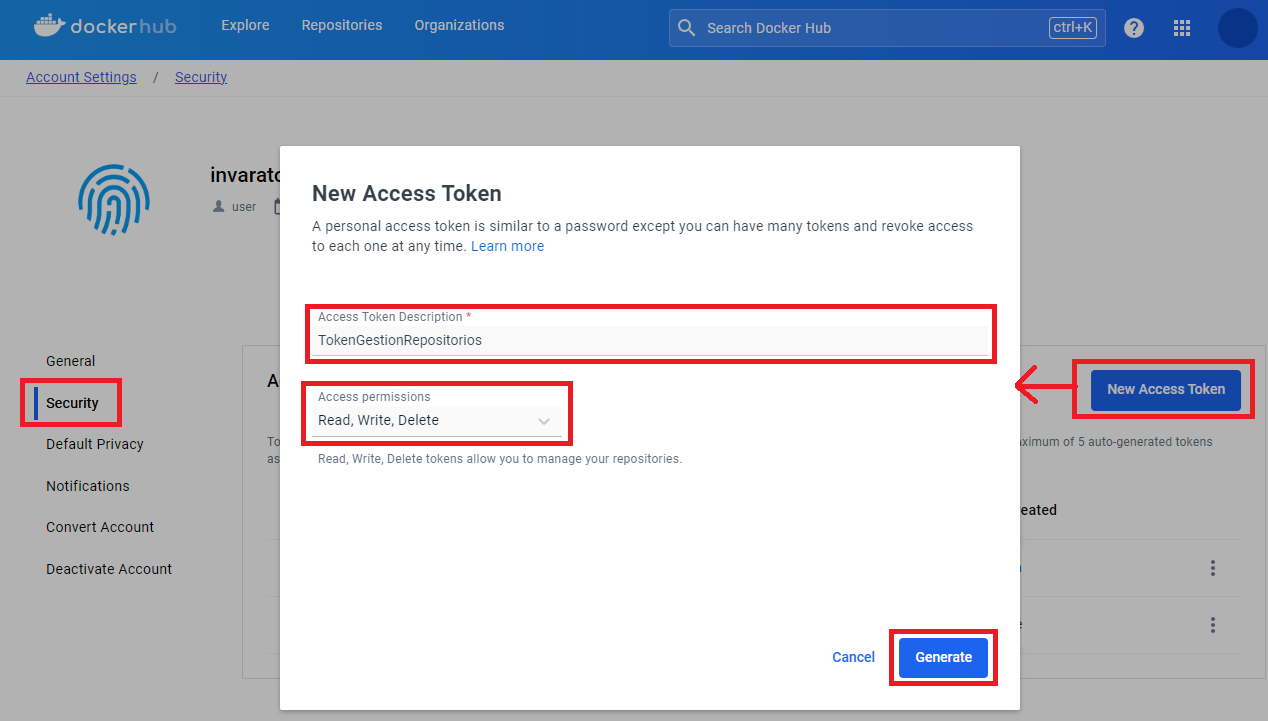
Luego vamos en el menú de la izquierda a “Security” y creamos un token pulsando en “New Acces Token”. Ahí se nos abrirá una ventana donde le daremos un nombre a nuestro Token en “Access Token Description” (yo le llamaré “TokenGestionRepositorios”), en “Access permissions” le daremos permisos de “Read, Write, Delete” y pulsaremos “Generate”.
En la siguiente ventana, copiaremos el Token que se nos ha generado (es importante copiarlo aquí, porque no se nos volverá a mostrar y lo vamos a necesitar para iniciar sesión desde la terminal con el comando “docker login”, como veremos).
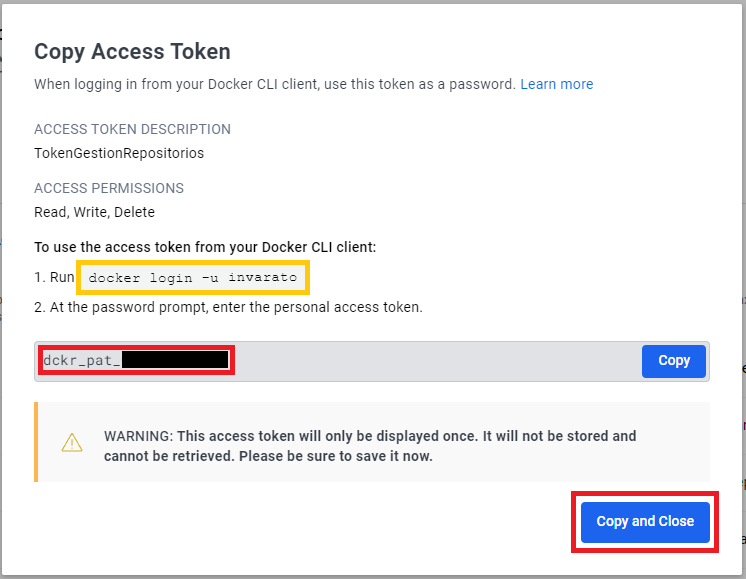
Nota: Recuerda este Token, porque lo vamos a necesitar para hacer login por la terminal.
Ya tenemos todo preparado para subir nuestra imagen al repositorio de Docker Hub.
Aunque antes hicimos el build de la imagen y la podríamos subir, pero aquí la vamos a volver a construir con algunas buenas prácticas más (puedes eliminar la anterior imagen con: docker rmi -f mi-imagen-jupyter ). Para construir una imagen para un repositorio se suele seguir el siguiente esquema:
docker build -t <nombre_imagen_local>:<version> .Vamos a crear la imagen en local con una versión por si tenemos varias:
docker build -t mi-imagen-jupyter:1.0 .Nota del nombre de la imagen en local vs en repositorio: este nombre de imagen del build es el tag propiamente, por lo que podríamos directamente ponerla en el formato que se pide en el repositorio, pero aquí quiero dejar por separado ambos para que se vea claramente. Es decir, tras el build tendré una imagen llamada (tag) como “mi-imagen-jupyter”, pero para el repositorio necesitaré una llamada como “invarato/jarroba_repo:1.0”.
Cuando tengamos construida la imagen, necesitaremos crear nuevos tags apropiados para el repositorio que siguen el esquema “<espacio_de_nombres>/<repositorio>:<version>” y utilizaríamos el comando “tag”:
docker image tag <tag_de_imagen_existente> <nuevo_tag>Para mi ejemplo quedaría:
docker image tag mi-imagen-jupyter:1.0 invarato/jarroba_repo:1.0Además, si queremos tener un “latest” apuntando a nuestra última versión, el tag de “latest” hay que generarlo a mano, por lo que podremos utilizar el comando “tag” donde:
docker image tag mi-imagen-jupyter:1.0 invarato/jarroba_repo:latestNota sobre revisar tag de imágenes: para comprobar que tenemos todo correcto, es bueno revisar nuestras imágenes con el comando: docker images
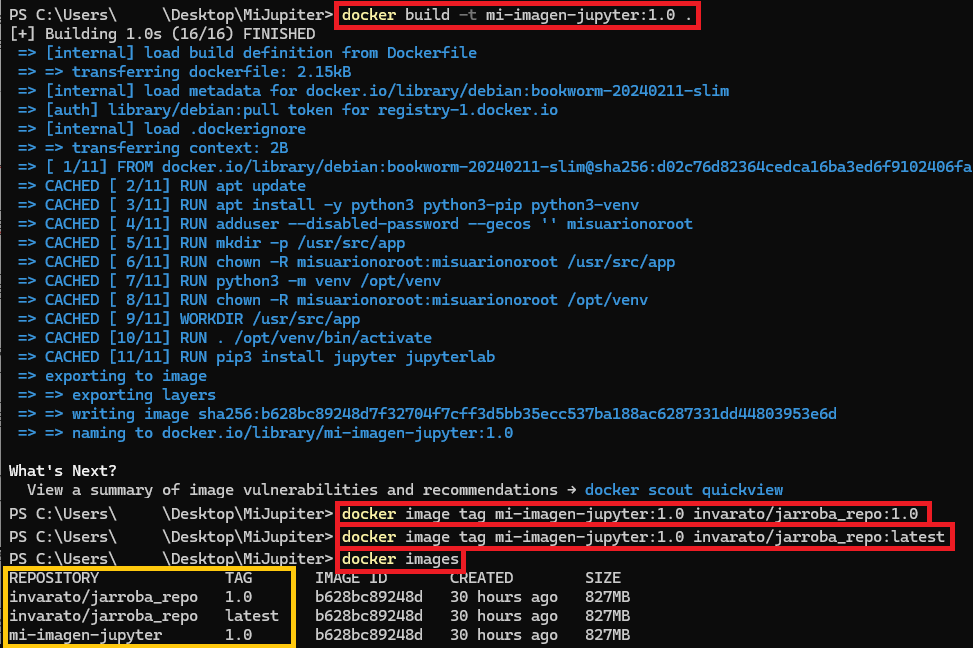
Ya tenemos preparada nuestra imagen con los tags listos, por lo que ahora nos conectamos a nuestro repositorio con login:
docker login <url-a-mi-mi-repositorio> -u <usuario> -p <token>Nota sobre “url-a-mi-mi-repositorio”: para Docker Hub no hace falta, pero si queremos apuntar a otro lado, por ejemplo, a un Harbor, sí que tienes que ponerlo (en este artículo lo añado por demostrarlo).
Para mi ejemplo inicio sesión con (la ruta al repositorio oficial de Docker Hub es “https://index.docker.io/v1” como viene en la documentación https://docs.docker.com/reference/cli/docker/login/ ; recuerda que aquí la pongo por ejemplificarlo, está puesta por defecto, por lo que no haría falta ponerla):
docker login https://index.docker.io/v1 -u invaratoNota sobre la contraseña/token: el comando anterior pedirá una contraseña, usa tu Token que creamos y copiamos antes. Así mismo, puedes usar el parámetro “-p” para poner la contraseña en la misma línea del comando (aunque es más seguro introducirla a mano como antes te expliqué).
Tras iniciar sesión, solo nos queda hacer push de nuestra imagen.
docker push invarato/jarroba_repo:1.0Y lo repetimos para el “latest”:
docker push invarato/jarroba_repo:latestPues ya estaría todo y tu imagen debería estar ahora en el Docker Hub lista para ser usada.
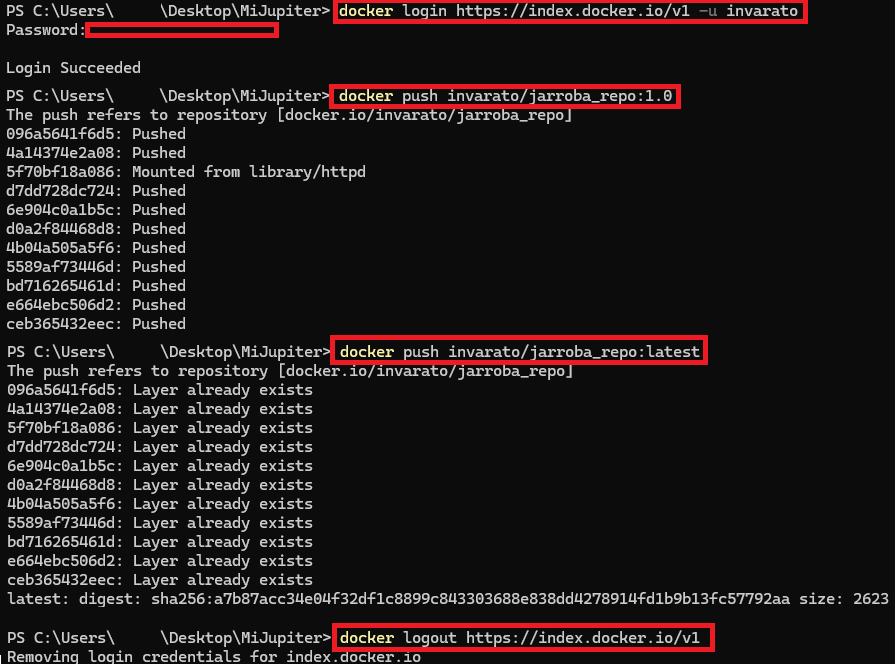
Para cerrar sesión:
docker logout https://index.docker.io/v1Si vas Docker Hub a nuestro repositorio, pues ya estará listo para que el mundo la pueda utilizar y descargar:
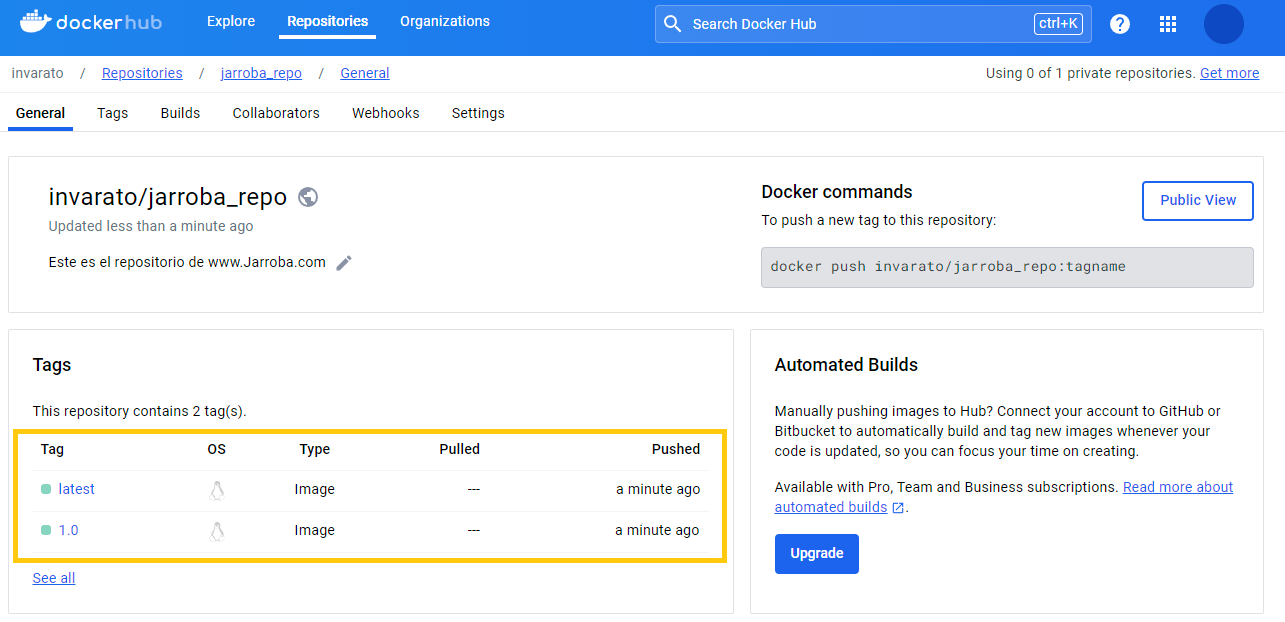
Puedes consultar este repositorio de demo en: https://hub.docker.com/r/invarato/jarroba_repo
Adicionalmente, te cuento el comando pull rápidamente, aunque no se suele usar, ya que se hace pull solo cuando tras ejecutar el build se encentra un FROM que tenga la imagen necesaria o cuando se usa Docker Compose lo defina. Un ejemplo de pull sería (puedes poner la versión “:1.0”, “:latest” o nada, que por defecto es “:latest”):
docker pull invarato/jarroba_repo:1.0Dockerfile multietapa
Los Dockerfile multietapa vienen muy bien para muchas cosas y principalmente para aligerar imágenes y para agilizar nuestro desarrollo al no tener que construir todo cada vez que modifiquemos algo (aprovechamos el cacheado de las capas de Docker). Por ejemplo, pues puedes tener una primera etapa para construir tu proyecto y una segunda para usar lo mínimo imprescindible, así solo se conserva la última etapa y te quedas con lo que necesitas.
Voy a ponerte un ejemplo muy rápido para que te hagas una idea (este ejemplo no te lo voy a hacer funcionar en este artículo, daría para otro, pero el Dockerfile sí que es real).
Imagina que has terminado un proyecto con Spring Boot (Java) con sus respectivos ficheros Docker que queda algo así (fíjate en la captura en los ficheros Docker):
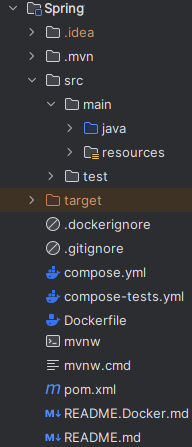
Para crear el “Dockerfile” sabemos que Java hay que compilarlo en un fichero Jar y que lo hacemos con Maven, por lo que podemos definir:
- Una primera etapa: de compilación con Maven de todo nuestro código (notarás que aquí le paso la versión APP_VERSION de mi microservicio por terminal, lo hago por motivos de CD/CI).
- Una segunda etapa: donde desechamos todo menos el Jar que queremos ejecutar sobre una base ligera de Java (Aquí también uso la directiva HEALTCHECK para que Docker se encargue de comprobar la salud de mi microservicio Spring Boot).
ARG APP_VERSION=unknown
FROM maven:3.9.6-eclipse-temurin-17-alpine AS build
LABEL authors="Ramon Invarato"
ARG APP_VERSION
WORKDIR /app
COPY pom.xml .
RUN --mount=type=cache,target=/root/.m2 mvn dependency:go-offline
COPY src/ /app/src
RUN mvn versions:set -DnewVersion=${APP_VERSION} && mvn package -Dspring.profiles.active=build
FROM eclipse-temurin:17-alpine
ARG APP_VERSION
EXPOSE 8080
WORKDIR /usr/src/app
COPY --from=build /app/target/*.jar app.jar
HEALTHCHECK --start-period=60s --interval=30s --timeout=3s CMD curl -f http://localhost:8080/actuator/health || exit 1
ENTRYPOINT ["java", "-jar", "app.jar"]
Recomendaciones generales para crear buenos Dockerfiles
Recomendaciones:
- Usa imágenes base oficiales y verificadas.
- Fija la versión de la imagen base.
- Establece el directorio de trabajo lo primero WORKDIR, antes de usar COPY y RUN
- Usa COPY en lugar de ADD (salvo que necesites manejar archivos “tar” y URL remotas).
- Parametriza con ARG lo que se necesite cambiar entre compilaciones (por ejemplo, la versión de tu proyecto).
- Minimiza las capas al combinar las instrucciones RUN.
- Limpia los archivos de caché y temporales innecesarios en la etapa final, con el objetivo de reducir el tamaño de la imagen lo más que puedas.
- Construye en múltiples etapas para que tu imagen sea pequeña y segura. Antes vimos un ejemplo para Java, ahora te voy a poner otro ejemplo para Node:
# Primera etapa: compilar el proyecto
FROM node:14.17.3-alpine as builder
ARG PROJECT_VERSION=1.0.0
# Establecer el directorio de trabajo
WORKDIR /app
# Copiar los archivos del paquete de json
COPY package*.json ./
# Instalar las dependencias
RUN npm install
# Copiar el resto de los archivos de la aplicación
COPY . .
# Construir la aplicación
RUN npm run build
# Segunda etapa: crear la imagen final
FROM node:14.17.3-alpine
# Establecer el directorio de trabajo
WORKDIR /app
# Copiar desde la etapa de construcción
COPY --from=builder /app ./
# Limpiar archivos temporales y de cache innecesarios
RUN rm -rf /var/cache/* \
&& rm -rf /tmp/*
# Exponer puerto para aplicación
EXPOSE 8080
# Comando de inicio
CMD ["npm", "start"]
- Nunca pongas credenciales o contraseñas en el Dockerfile.
- Quita el acceso de root cuando termines las tareas root (por ejemplo, cuando termines de instalar). Ejemplo:
FROM ubuntu:18.04
# root para trabajar sin restricción
USER root
# Instale los paquetes necesarios aquí con el usuario root
RUN apt-get update && apt-get install -y \
paquete-requerido-1 \
paquete-requerido-2 \
etc.
# Luego cree su usuario no root y cambie a ese usuario
RUN useradd -ms /bin/bash usuarionoroot
USER usuarionoroot
# Ahora estás ejecutando comandos como usuarionoroot
RUN whoami # Se imprimirá "usuarionoroot"
- Diseña cada contenedor para manejar un aspecto diferente de tu aplicación, no uses un contenedor para todo.
- No olvides usar ENTRYPOINT o CMD para especificar el comando de inicio, de lo contrario no servirá de nada tu Dockerfile.
- Evita los scripts de construcción en la imagen, mejorusa compilaciones de múltiples etapas.
- Mantén solo los archivos necesarios en el directorio de construcción.
- Especifica los puertos con EXPOSE si son necesarios.
- Estructura las instrucciones del Dockerfile para maximizar la reutilización de capas.
Recomendación para reducir el tamaño de una imagen Docker
Cuando construyamos nuestra propia imagen debemos cuidarnos de reducir el tamaño de la imagen al mínimo (pues querremos que sea portable, que se despliegue rápido, que ocupe cuanto menos para ahorrar memoria y que se descargue rápido cuando hagamos pull). Recomendaciones:
- Build multi-stage (build de etapas múltiples): por ejemplo, en una primera etapa se puede compilar tú código y empaquetar tú aplicación (por ejemplo, si trabajas con Spring, convertirlo en un “jar”), esto ocupa mucho espacio; y en una segunda etapa se pueden copiar solo lo estrictamente necesario para la imagen final (en el ejemplo anterior, sería copiar solo el “jar”), por lo que todo lo que usamos antes para compilar no se incluiría, con lo que reduce bastante el espacio.
- Empieza siempre con las imágenes más puras posibles: utiliza siempre imágenes base lo más estándar y sin añadidos posibles. Por ejemplo, lo que NO es recomendable es que, si ahora creo un “Hello Word” simple de java, podría utilizar perfectamente la imagen que me generó el anterior Dockerfile (ya que incluye una imagen pura de Java) y me funcionaría, pero estoy añadiendo el “jar” del proyecto de Spring Boot que no necesito en esta nueva imagen.
- Usa lo mínimo imprescindible: cuantas más etapas añadas pues más va a ocupar, pues cada etapa añade sus propios metadatos y archivos. Además, comprende muy bien las instrucciones que utilices, por ejemplo, cada vez que uses la instrucción “COPY” te va a copiar contenido o si utilizas la instrucción “FROM” pues te va a descargar una imagen nueva si no la tenía antes.
