Dockerfile: Directivas y Dockerizar proyectos
Los Dockerfiles son ficheros que, de una forma detallada y flexible, se definen para construir y desplegar aplicaciones con Docker personalizadas. Un Dockerfile consta de directivas que permiten especificar desde el sistema operativo base, las dependencias de la aplicación, los comandos de arranque y mucho más. Así mismo, podemos usarlo para automatizar procesos, garantizar la coherencia y optimizar nuestros flujos de trabajo de desarrollo.
Índice
- Docker básico: Usar imágenes (para todos los públicos).
- Docker Compose: Usar cómodamente imágenes (para todo quien quiera trabajar más cómodamente con Docker).
- Docker Compose en un proyecto: Uso de imágenes en un desarrollo (para aprender de verdad cualquier arquitectura de desarrollo).
- Imágenes Docker: Gestión de imágenes avanzada por consola (para usuarios avanzados).
- Dockerfile: Directivas y Dockerizar proyectos: trabajar con proyectos Dockerizados (para desarrolladores que quieran dockerizar su proyecto)
- Dockerfile avanzado: multietapa, repositorio y trucos: para especializarse en Dockerizacion (para que desarrolladores y managers controlen los detalles)
Para empezar a Dockerizar, vamos a ver un ejemplo rápido de uso de un fichero Dockerfile para entender su funcionamiento interno, pues es importante para desarrollar bien y aprovechar la velocidad del cacheado.
Git: el código de en este artículo también lo puedes encontrar en ps://github.com/Invarato/docker/tree/main/articulos-jarroba/dockerfile-directivas-y-dockerizar-proyectos
Dockerizar
Hasta ahora solo hemos visto cómo usar imágenes Docker creadas por terceros, es hora de crear nuestras propias imágenes Docker como profesionales.
Conceptos importantes sobre la Dockerización y su ciclo de vida:
- Proyecto Dockerizado: proyecto que tu desarrollas (con Python, Java, etc.) y al que le añades un fichero de propiedades llamado “Dockerfile”.
- Imagen Docker: resultado de la construcción del “Proyecto Dockerizado” (con el comando: “docker build”). Como comparación tonta: la imagen es como si le dieras a tu amigo tu ordenador con el proyecto con el que estás trabajando listo para ejecutar (si es un proyecto Python, sería tu ordenador con todo listo, con el sistema operativo sobre el que corre, la versión de Python ya instalada y todas las librerías sin que tu amigo tenga que hacer ni si quiera “pip install”, es decir, el máximo trabajo que tiene que hacer tu amigo para ejecutar tu proyecto es encender el ordenador). Por tanto, desde aquí, ya no necesitas el código de tu proyecto para ejecutar el Proyecto, solo la imagen.
- Contenedor: entorno aislado que encapsulan todo lo necesario (así como las dependencias del sistema operativo y el código fuente), para ejecutar tu “Proyecto”. Es decir, es donde se ejecuta tu imagen (con el comando: docker run).
Para Dockerizar un proyecto es tan fácil como escribir un fichero de propiedades (llamado “Dockerfile”) y ejecutar un comando muy corto, entonces, lo tienes encapsulado rápidamente para usar de inmediato en local o para desplegarlo sobre un Kubernetes, que puede ser un entorno de microservicios altamente escalable y distribuido.
Dockerfile
El Dockerfile consta etapas (stage), cada etapa tiene capas (layer) y cada capa la forma una única instrucción. Una instrucción comienza con una directiva Docker como la directiva “FROM” (aunque vamos a ver fácilmente las directivas más útiles más adelante, tienes la documentación oficial de las directivas Docker en https://docs.docker.com/reference/dockerfile/ ) seguido de parámetros (para que la directiva haga lo que queramos que haga). Las etapas empiezan siempre por la instrucción con la directiva FROM; la instrucción con FROM será la base (pues será donde pidamos el sistema operativo que queramos con los programas preinstalados que necesitemos) sobre la que trabajemos en el resto de la etapa. Una instrucción es una capa porque añade algo a todo lo anterior (a todas las instrucciones que se han ejecutado previamente).
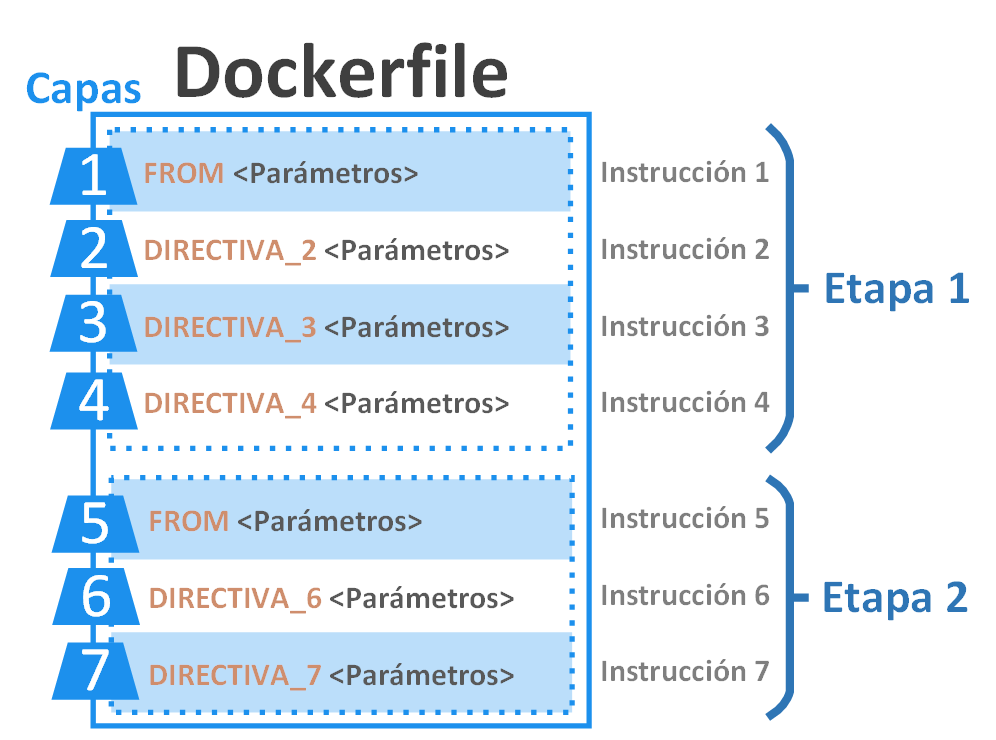
Nota de diferencia entre capa vs instrucción vs directiva: aunque en Docker se suele decir por simplicidad que toda instrucción crea una capa, no es cierto del todo, pues solo crean capas “reales” aquellas instrucciones que añadan peso, es decir, megas al disco (normalmente las instrucciones de copiado como “COPY”, que copian cosas de nuestro ordenador y las pegan dentro de la imagen Docker; por otro lado, las instrucciones de documentación, como “LABEL”, pues solo sirve para indicar metadatos como la versión o una descripción, no añade ficheros a la imagen). Entiende bien la diferencia entre directiva e instrucción, porque muchas veces verás que se dice instrucción en vez de directiva por resumir, por ejemplo, la frase “errónea” <<vamos a usar la instrucción FROM>>, pero queremos decir que usaremos la directiva FROM seguido de argumentos permitidos para esa directiva, que es lo que formará nuestra instrucción (instrucción = directiva + parámetros).
Ahora veamos un fichero Dockerfile real muy simple, de una sola etapa (una sola instrucción “FROM”), con 6 capas y cada capa con su “instrucción” (en el siguiente dibujo son “instrucciones”: FROM, VOLUME, WORKDIR, COPY, RUN, CMD; en la línea 5, RUN está mal a propósito, porque pone RUUUUUUUUN, es decir, no compilará esa instrucción). En esta parte no voy a entrar en para qué sirve cada instrucción, pues lo que aquí nos importa es saber cómo funciona un Dockerfile (más adelante entraré en detalle y lo haremos funcionar con un proyecto real); a grandes rasgos, la instrucción FROM de este Dockerfile, le pido una imagen Docker con Python sobre el sistema operativo Linux Alpine (Docker buscará esta imagen en nuestro ordenador, pero si no la encuentra, la descargará automáticamente de Docker Hub; tienes la documentación de esta imagen preconstruida que usaremos en https://hub.docker.com/_/python ) y el resto de instrucciones luego las entenderemos (aquí me importa que veas como se compone un Dockerfile con sus instrucciones/capas y los parámetros a la derecha de cada instrucción).

Podremos crear la imagen Docker desde nuestro Dockerfile con el comando “build”, que se vería algo así:
docker build -t nombre_imagen .Se irán ejecutando instrucción a instrucción de arriba a abajo, y cada vez que ejecute una instrucción Docker se procesará y cacheará automáticamente el resultado hasta ese punto. Por ejemplo, si empezamos desde cero, cuando ejecutemos FROM, Docker buscará en caché la imagen de “Python sobre Linux Alpine”, pero como no la encontrará, la descargará desde Docker Hub; de esta manera, la próxima vez que volvamos a ejecutar el comando “build”, el FROM se ejecutará inmediatamente porque recuperará de caché (de nuestro ordenador) la imagen de “Python sobre Linux Alpine” (ya no volverá a descargarla). Sin embargo, hemos cometido un error en nuestro Dockerfile, una instrucción está mal escrita, concretamente RUUUUUUUUN, que debe ser RUN, por lo que cuando la ejecución del comando “build” llegue hasta esa instrucción, se detendrá y nos devolverá un error en la consola.
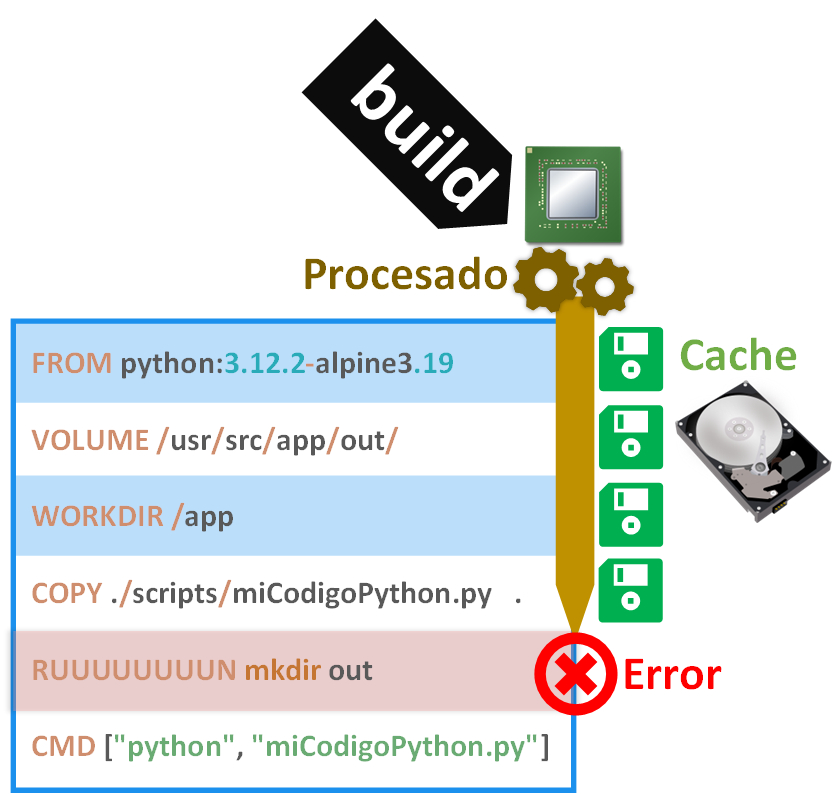
Nota de la diferencia entre ejecutar, procesar y cachear: la ejecución es empezar un proceso (por ejemplo, pedir copiar un fichero); el proceso es la operación de procesado que requiere un tiempo (algunas veces demasiado) en realizarse (por ejemplo, el hecho real de copiar un fichero y esto tardará mucho si es el fichero es muy grande); el cacheo es guardar algo y recuperarlo muy rápido, por lo que si guardamos el resultado de algo procesado (por ejemplo, el estado final de la copia de antes), pues no tendremos que reprocesar.
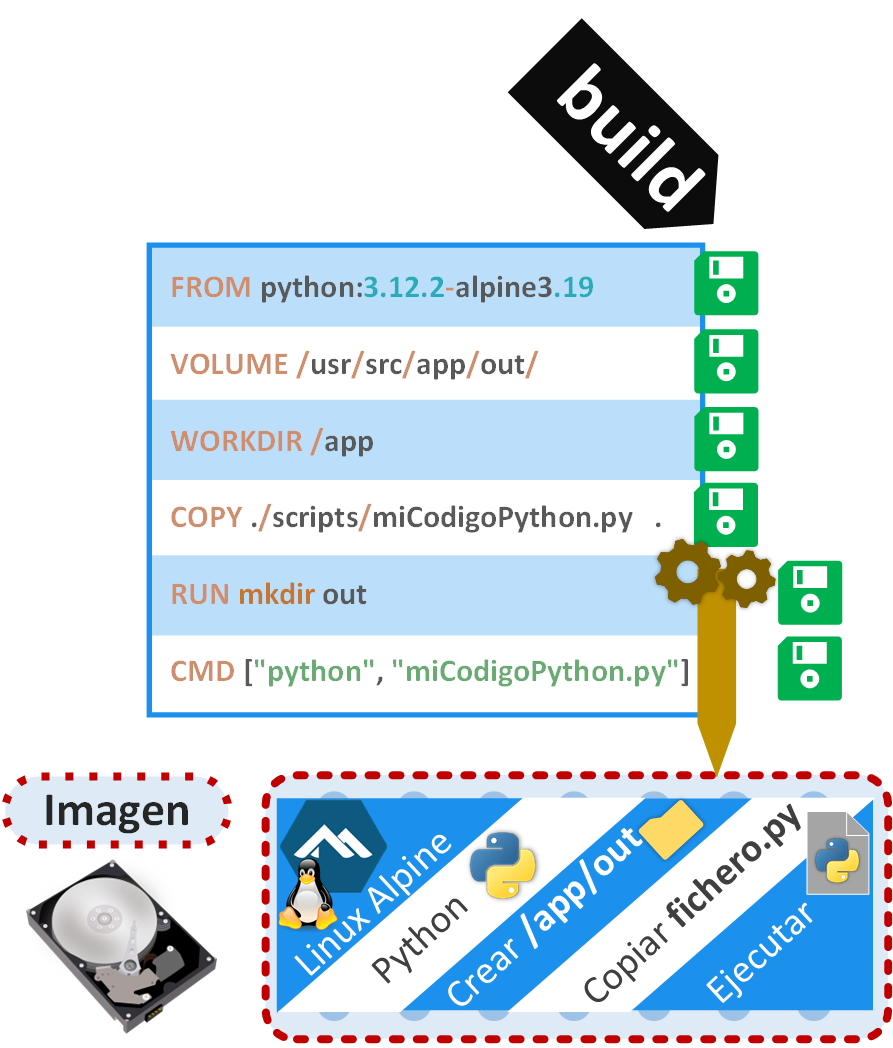
Corregimos esa línea y volvemos a ejecutar el comando “build”. Se volverán a ejecutar todas las instrucciones desde el principio, pero las instrucciones cacheadas devolverán el resultado inmediatamente, hasta llegar a las instrucciones que no se llegaron a ejecutarse, entonces, esas se tendrán que procesar, que se cacharán cuando vayan terminando de procesarse. Cuando se ejecuten todas las instrucciones por completo todo el Dockerfile, habremos obtenido nuestra imagen Docker que podremos utilizar.
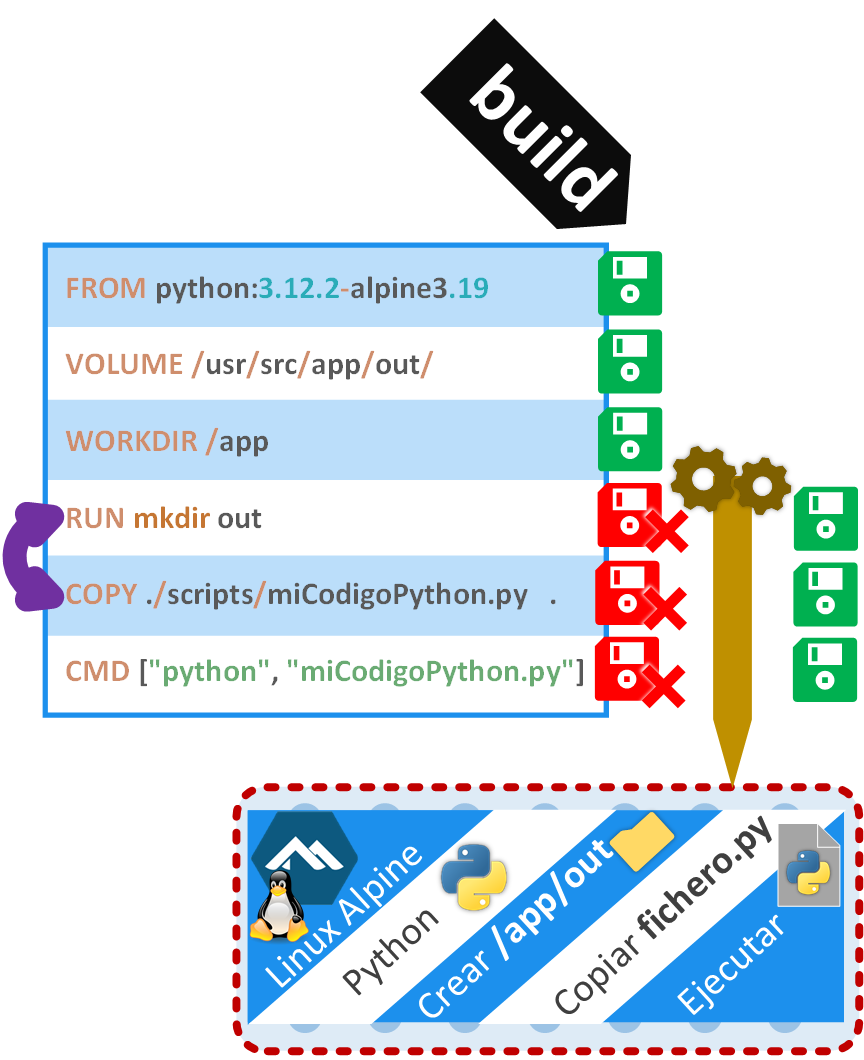
Si cambiamos cualquier instrucción, la caché se invalidará (borrará) desde ahí en adelante. Para mi ejemplo voy a cambiar de orden dos instrucciones, por lo que la caché se invalidará desde la instrucción de más arriba hacia abajo; por tanto, si volvemos a usar el comando “build”, se recuperará de caché el resultado de las instrucciones no invalidadas y, cuando lleguemos a la caché invalidada (que será como si no hubiera caché), se volverá a procesar la instrucción, guardando su nuevo resultado en caché; y si se ejecutan todas las instrucciones del fichero Dockerfile, se generará una nueva imagen.
Dockerfile en detalle técnico
El fichiero Dockerfile permite construir una o varias imágenes Docker a la vez. Se constituye de:
- Instrucción: línea que comienza con una directiva Docker (RUN, CMD, ENTRYPOINT, FROM, ENV, WORKDIR, etc.) con sus parámetros y se ejecutará en cada paso (step) del proceso de construcción (salvo que esté cacheado, en ese caso, se recupera el resultado de la instrucción desde la caché).
- Capa (layer): es el cambio de estado en una imagen que provoca la ejecución de una instrucción (por ejemplo, FROM, RUN, COPY, ADD, etc.) en el proceso de construcción (“build”) de la imagen (por ejemplo, supongamos que tenemos una imagen vacía, entonces, ejecutamos “RUN apt install -y python”, esto provocará la instalación de Python creando una nueva capa que podríamos llamar “capa con Python”). La mayoría de las instrucciones generan capas, pero hay otras que no porque no cambian el estado de la imagen (por ejemplo, la instrucción WORKDIR solo ubica el cursor en un directorio dentro de la imagen, no cambia nada de la imagen como tal). Una capa se guarda en caché (digamos que es como un “commit” de Git) para cuando se requiera reconstruir de nuevo lo mismo (por si vuelves a ejecutar las mismas instrucciones en el mismo orden y con el mismo contenido) que sea mucho más rápido. El orden de las capas puede no influir en el resultado de la ejecución de tu código, pero sí en el comportamiento de la caché; por ejemplo, no es lo mismo [COPY] copiar un proyecto escrito en Java y luego [RUN apt install -y openjdk…] instalar Java (cada vez que cambies algo del proyecto se invalidarán todas las capas que van después, por lo que tendrás que esperar a que se instale Java cada vez), que [RUN] instalar Java y luego [COPY] copiar el proyecto (como los cambios en el proyecto invalidan las capas que van después de la instalación de Java, la capa que instala Java se recupera de la caché, por lo que es inmediato).
- Etapa de construcción (build stage): se define una nueva etapacada vez que utilizas la instrucción FROM en un Dockerfile (con sus instrucciones). Con multietapa (multistage) se logra ejecutar pasos de compilación en paralelo (por ejemplo, puedes realizar varias compilaciones en paralelo de varios proyectos que luego van juntos en la imagen final, por lo que ganamos velocidad) y reduce el tamaño de la imagen (por ejemplo, si en una sola etapa copias tu código a la imagen y luego lo compilas dentro, tendrás de resultado una imagen con el código y la compilación, cuando el código ya no es útil y ocupa espacio innecesariamente; si aplicas multietapa, en la primera etapa se copiaría tu código y compilaría, pero solo se pasaría el compilado a la etapa final, por lo que el código se descartaría y solo te quedarías la compilación en la imagen, con lo que ganamos espacio).
Dockerizar un proyecto completo con Dockerfile
Queremos Dockerizar nuestro proyecto, por lo que vamos a suponer que tenemos un proyecto cualquiera (Java, Python, Node, Go, Ruby, Scala, PHP, Angular, etc.). Para mi ejemplo crearé un mini proyecto Python por simplicidad que imprima una línea de texto y guarde otra línea de texto en un fichero.
A continuación, te detallaré paso a paso todo, pero te facilito previamente un pantallazo con la estructura de mi proyecto en el estado final:
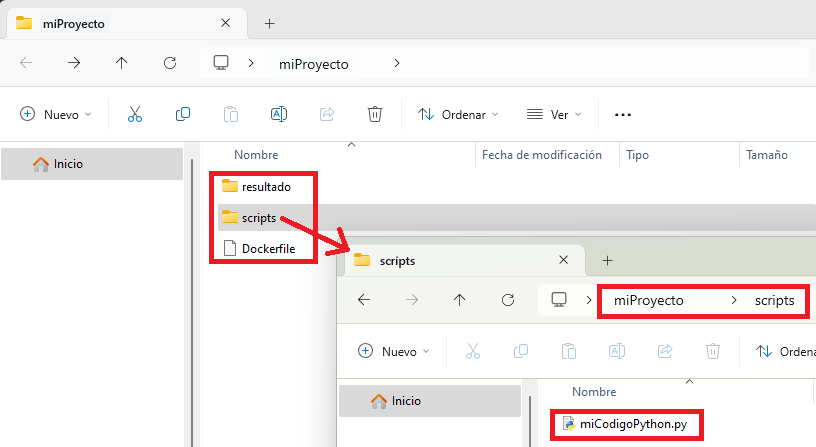
Empezaré creando una carpeta que contendrá mi proyecto y que llamaré “miProyecto” (la crearé en el escritorio). Dentro de esta carpeta crearé dos carpetas (en este ejemplo no estoy siguiendo ninguna convención de estructura del proyecto más allá de la Dockerización, por lo que vale para cualquiera):
- “resultado”: donde quiero que mi código Python guarde un fichero con el texto que va a fichero.
- “scripts”: para guardar todos los ficheros con mi código de Python, que para este ejemplo solo será el siguiente fichero que llamaré “miCodigoPython.py” con el código Python (yo editaré el fichero con el bloc de notas, por ejemplo, recuerda guardar los cambios):
#!/usr/bin/env python3
print("Ejecutando mi codigo Python")
with open('/usr/src/app/out/resultado.txt', 'w') as f:
f.write('Texto de mi fichero!\n')
Como puedes ver en este código, que es muy simple, hay:
- Un “print” para imprimir por consola «Ejecutando mi codigo Python»
- Un “write” para guardar el texto “Texto de mi fichero” en el fichero llamado “resultado.txt”; pero, ojo, si te fijas he puesto una ruta extraña “/usr/src/app/out/” en el “open” que abre al fichero, esta ruta no es la de mi ordenador local, sino la de dentro del contenedor de Docker (puesto que cuando ejecutemos este código dentro de un Contenedor de Docker, guardará el fichero dentro de la estructura de ficheros de ese contenedor, NO en nuestro ordenador local; es decir, que tenemos que ver más adelante como le decimos que la carpeta “/usr/src/app/out/” corresponde con la de “resultado” que acabamos de crear en nuestro ordenador local, quizás esto te suene de los anteriores artículos).
Vamos a crear un fichero que se va a llamar “Dockerfile” en la carpeta raíz, que en mi caso es “miProyecto”. Es importante que se llame exactamente “Dockerfile” (sin extensión de archivo) porque es el estándar para que Docker sea capaz de encontrarlo automáticamente (se podría llamar de otras maneras, pero entonces ya tendríamos que estar complicando los comandos, así que yo voy a optar por el estándar simple, que te adelante que es el que uso siempre realmente en mis proyectos).
Antes de seguir tenemos que pensar qué queremos en nuestra imagen, para mi caso quiero:
- Un sistema operativo con Python instalado
- Una carpeta donde pueda poner mi fichero “miCodigoPython.py”
- Una carpeta de salida para el resultado (si miras mi código Python, quiero que el fichero se cree y se guarde en “/usr/src/app/out/”)
- Y quiero ejecutar mi fichero Python “miCodigoPython.py” y que todo vaya bien.
Para ello editamos el fichero “Dockerfile” (yo lo haré con el bloc de notas), le copiamos el siguiente contenido (las siguientes instrucciones) y guardamos el fichero “Dockerfile” (te detallo en comentarios qué hace cada instrucción de nuestro Dockerfile):
# Utilizamos la base de Python oficial como imagen padre
FROM python:3.12.2-alpine3.19
# Documentamos indicando que habrá un volumen externo a la imagen, que será donde pongamos el fichero resultante
VOLUME /usr/src/app/out/
# Establecemos el directorio de trabajo a /app, terminará siendo: /usr/src/app (la base que viene en el FROM ya lo establece antes en /usr/src)
WORKDIR /app
# Creamos dentro un directorio llamado out, que será el que compartamos con el resultado
RUN mkdir out
# Copiamos el código de nuestro proyecto al directorio del último WORKDIR (a app)
COPY ./scripts/miCodigoPython.py .
# Ejecutamos nuestro código Python en nuestro contenedor
CMD ["python", "miCodigoPython.py"]
Al final el proyecto debe quedar como la siguiente captura (el archivo “miCodigoPython.py” te lo abro con Sublime Text para que coloree el código y se distinga del Dockerfile):
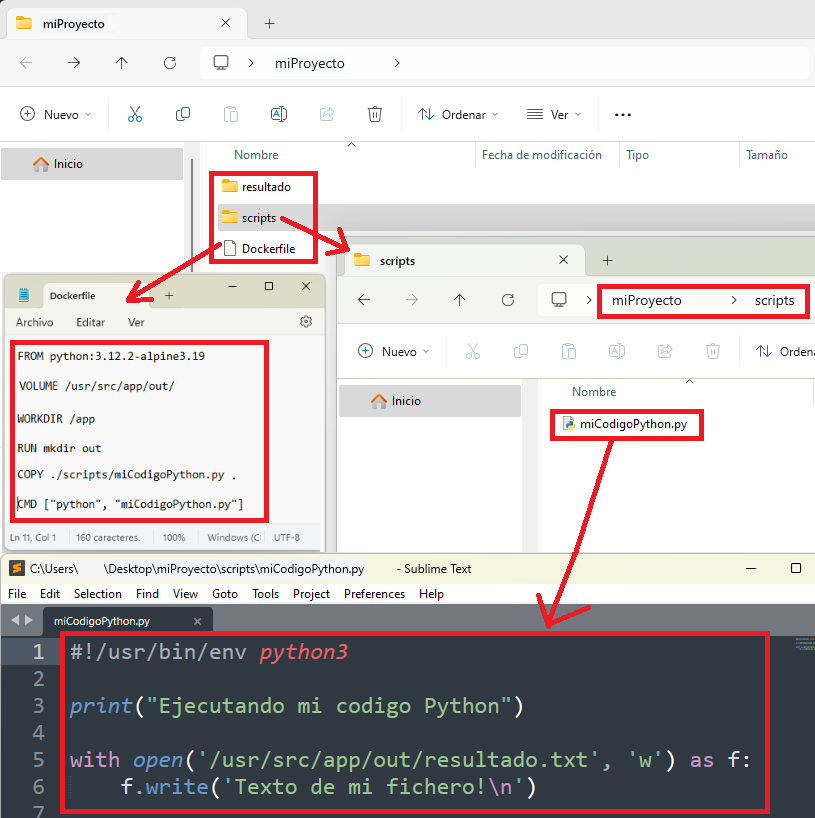
De lo anterior, quiero aclarar un par de instrucciones, puesto que el resto creo que se entienden bien desde los comentarios (además, que te detallo las directivas más adealnte):
- FROM: estoy pidiendo “python:3.12.2-alpine3.19”, donde “3.12.2” es la versión de Python que trae instalado el sistema operativo Linux Alpine cuya versión es la “3.19”.
- COPY: copia de la carpeta relativa (el punto “.” Indica relativo, no tenemos que poner todo la la ruta absoluta “C:\Users\usuario\Desktop\miProyecto\scripts\miCodigoPython.py”) al “Dockerfile” de mi ordenador local “./scripts/miCodigoPython.py” al interior del contenedor a la carpeta relativa “.” que hayamos puesto en el último WORKDIR, que en mi caso es “/app” (más concretamente, en ruta absoluta: “/usr/src/app”).
- VOLUME: solo sirve para documentar e indicar que para nuestra imagen se van a guardar datos ahí que estaría bien crear un Volumen o un Bind Mount (pero no lo crea); en mi ejemplo, indico que “/usr/src/app/out/” sería interesante vincularla algún lado y querré en el futuro hacerlo con la carpeta “resultado” de mi ordenador local.
- CMD: ejecuta en la terminal del contenedor el comando: «python miCodigoPython.py» (utilizando de ubicación relativa la puesta en el WORKDIR).
Ahora, abrimos una terminal y navegamos hasta el directorio que contiene el Dockerfile, que en mi caso es en la carpeta “miProyecto” que está en el escritorio.
Ahora construimos desde nuestra imagen con el comando “build”, llamaré a mi imagen “mi-imagen” (tras “-t”) y el punto “.” indica dónde está el Dockerfile a utilizar:
docker build -t mi-imagen .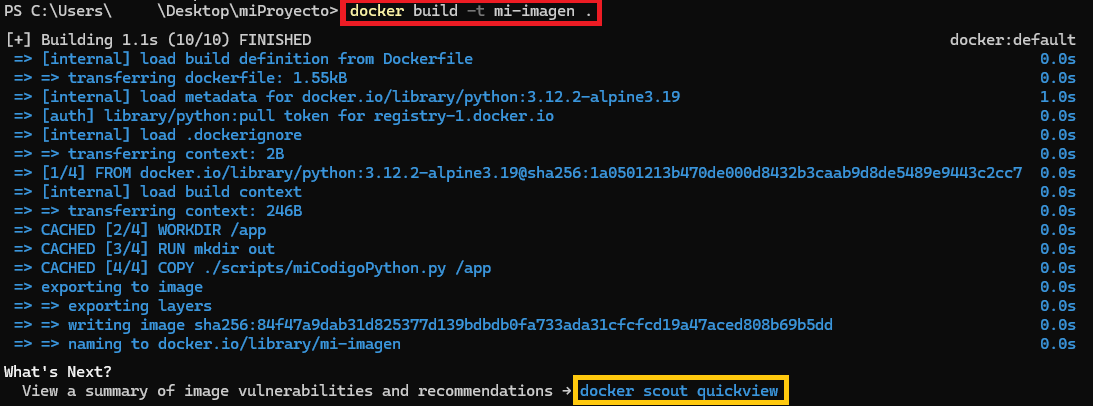
Si todo ha ido bien, nuestra imagen habrá sido construida.
Analizar vulnerabilidades (Opcional)
Si te fijas, Docker nos recomienda usar un comando “scout” (es opcional) , que lo que hará será analizar nuestra imagen en busca de vulnerabilidades, si lo ejecutamos ahora (antes de ejecutar otros comandos) no se nos pedirá introducir el nombre del contenedor, ya que se guarda el último “build” por comodidad. Este comando quizás no lo utilices mucho cuando estás Dockerizando todo el rato, pero es una buena práctica pasarlo antes de finalizar nuestro proyecto (antes de enviar a producción):
docker scout quickview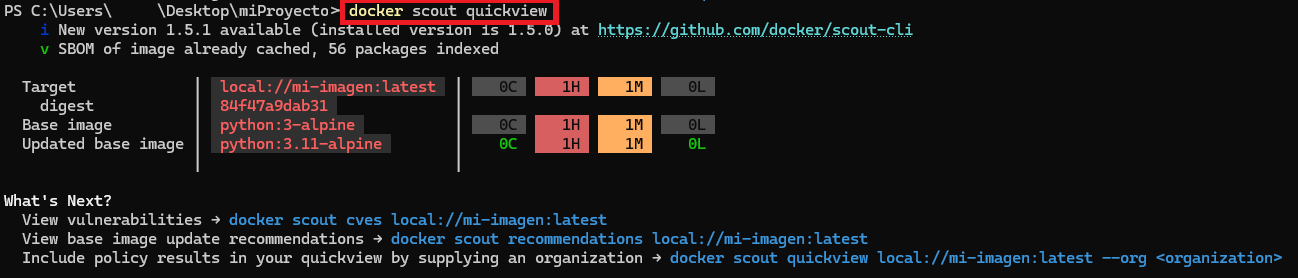
Tras ejecutarlo veremos algunas vulnerabilidades, quizás no sean nuestras, en mi ejemplo me dice que las trae la imagen base, así que por mi parte está todo perfecto (es casi imposible que no haya vulnerabilidades, sobre todo en las imágenes base que usamos en el FROM, ya que ahí viene por lo menos un sistema operativo completo, que por muy actualizado que esté, no estará libre de vulnerabilidades, al menos, podemos minimizarlas si instalamos últimas versiones). Lo importante por nuestro lado es no introducir nuevas vulnerabilidades, yo recomiendo usar el “recommendations” de “scout” (también opcional) para que nos recomienden mejoras a nuestra imagen:
docker scout recommendations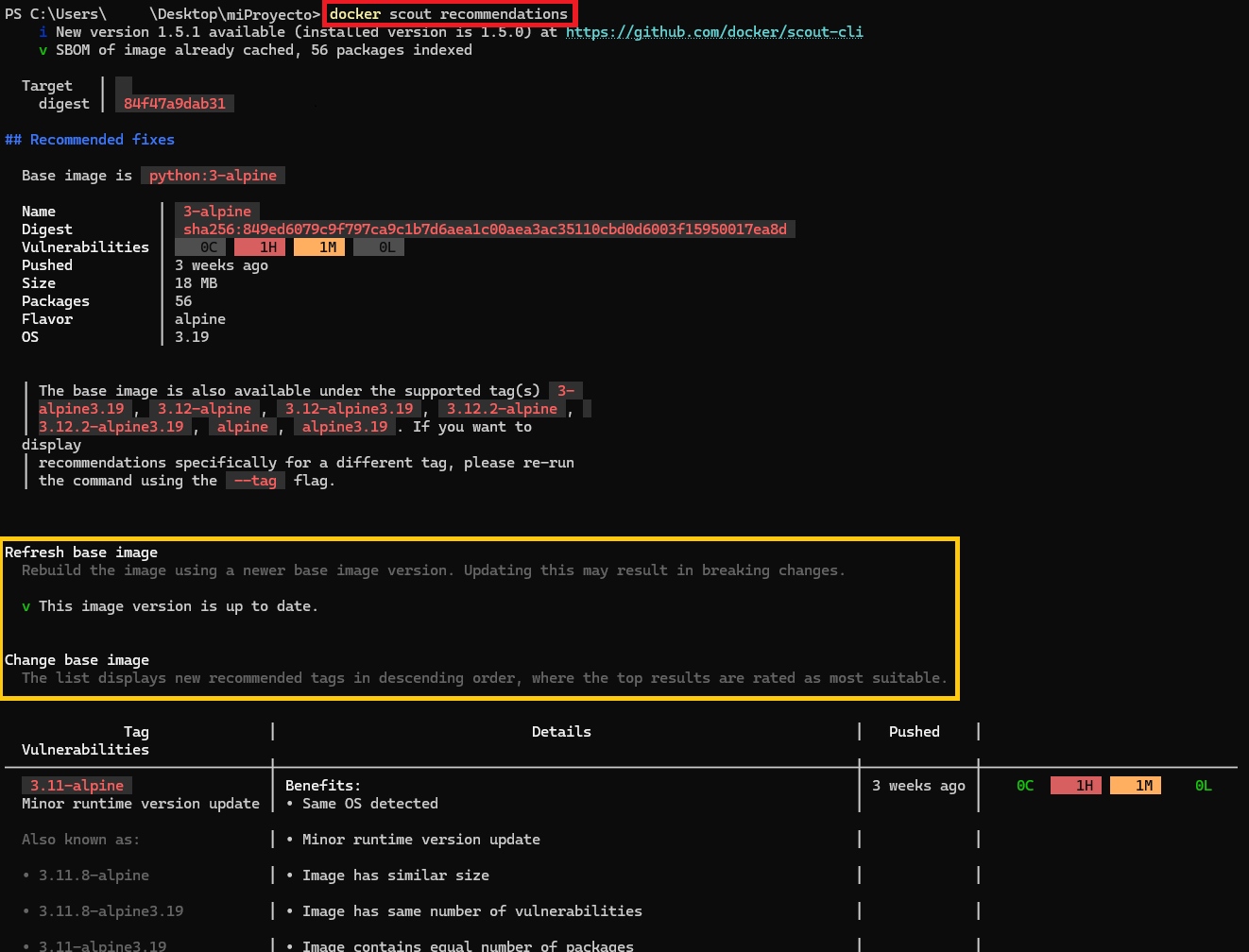
En el informe que se genera nos avisa si podemos hacer algo para mejorar nuestro contenedor, lo más común es que nos sugiera que actualicemos la imagen base si hay alguna versión superior (por ejemplo, yo he usado la base “python:3.12.2-alpine3.19”, cuando saga la versión que me invento “python:4 -alpine10”, nos dirá que actualicemos que hay menos vulnerabilidades en la versión más moderna). En mi caso no me sugiere nada porque estoy usando la última versión a la hora de escribir este artículo.
Historial de la imagen
Otro comando útil es el del historial, puesto que nos mostrará cada una de las capas que se nos ha generado en nuestra imagen (esto es importante para optimización de la imagen):
docker history mi-imagen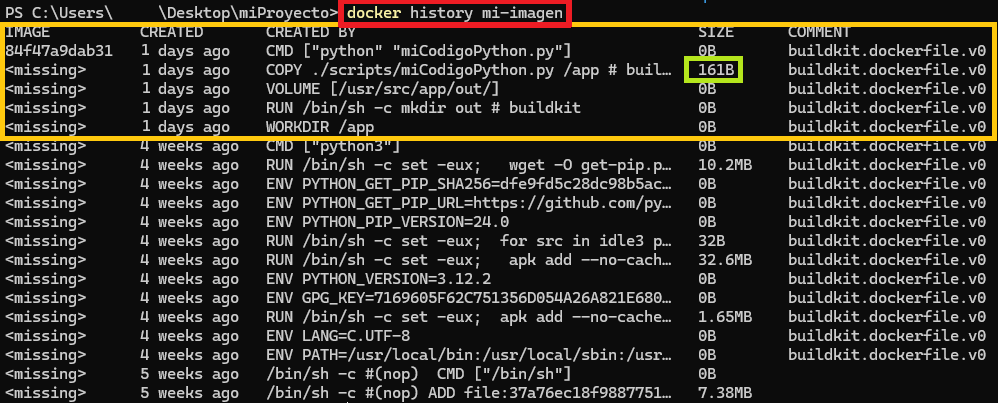
Viene en orden invertido, lo más nuevo arriba, por lo que mi Dockerfile está arriba, todo lo que viene después es lo que otros desarrolladores han añadido de capas de más en la imagen que yo he obtenido con “FROM python:3.12.2-alpine3.19”.
Otra cosa interesante es la columna SIZE, donde si es mayor que cero nos indica las capas digamos que “reales”, puesto que son las que añaden contenido a la imagen y las que hay que vigilar para que nuestra imagen sea ligera. En mi caso fue cuando copiamos el fichero con COPY, el resto de las instrucciones no añadieron peso a la imagen.
Para ejecutar un contenedor desde la imagen que hemos creado utilizamos el comando “run” de Docker. Con “–name” recomiendo siempre ponerle nombre al contenedor. Con “-v” creamos el Bind Mount (es igual a como vimos en los artículos anteriores), donde pongo la ruta absoluta a mi carpeta local “resultado”, dos puntos “:” y la ruta absoluta a la carpeta que he llamado “out” dentro de mi contenedor. Al final del comando le decimos qué imagen de las existentes que remos usar, en mi caso la que acabamos de crear “mi-imagen”:
docker run --name mi-contenedor -v C:\Users\usuario\Desktop\miProyecto\resultado:/usr/src/app/out/ mi-imagen
Podrás ver en la consola el texto del “print” de Python, por lo que por lo menos nos aseguramos de que el fichero de Python se ha ejecutado.
Para terminar, comprobamos en la carpeta “resultado” de nuestro ordenador local, si se ha creado el fichero “resultado.txt” con el texto dentro que queríamos:
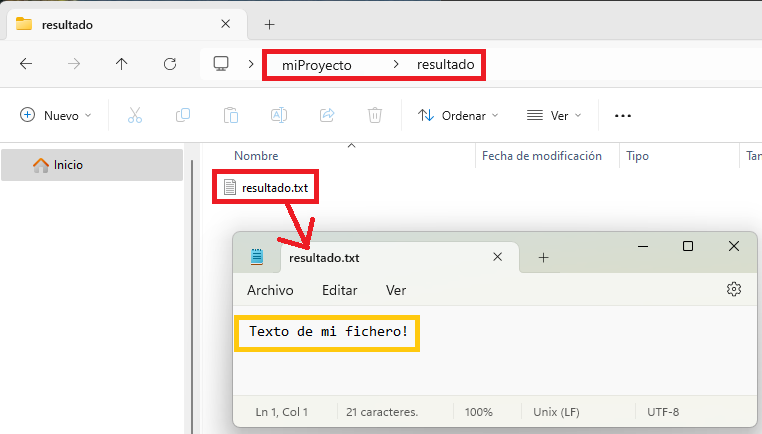
Quizás te hayas sorprendido de que nuestro contenedor apenas haya vivido un segundo, puesto que la imagen base que hemos usado está diseñada para crear “contenedores efímeros” (lo definimos en el artículo de Docker básico), el cual solo vive mientras se ejecuta lo que tiene que ejecutar y se apaga. La creación de un fichero para este ejemplo no ha sido casual, pues los “contenedores efímeros” son muy interesantes para realizar trabajos puntuales y que terminen, pero querremos los datos resultantes en algún lado (sino se perderían en cuanto se apague el contendor) y ese lado es en nuestro ordenador local, por ejemplo.
Contendor Daemon
Si queremos que se mantenga eternamente el contenedor, por ejemplo, para ejecutar comandos Python dentro a través de la terminal del contenedor, entonces tendremos que crear un contenedor Daemon (si no lo es a imagen base que hemos puesto en el “FROM”).
Para ello y mantener un contenedor en ejecución, se utiliza un comando que no termine, como un bucle infinito (por ejemplo, un servidor), un truco muy común es utilizar al final el comando “sleep infinity” (para que se mantenga activo infinito), “exec /bin/sh” (que abre una Shell y así no se termina el nunca el proceso) o “tail -f /dev/null” (que lee eternamente el archivo “null” que nunca se llena).
Por ejemplo, podría editar mi Dockerfile para cambiar la última línea por (el “&” le indica a Linux que ejecute en paralelo el comando “python miCodigoPython.py” y el comando “sleep infinity”):
CMD python miCodigoPython.py & sleep infinityQuedando:
FROM python:3.12.2-alpine3.19
VOLUME /usr/src/app/out/
WORKDIR /app
RUN mkdir out
COPY ./scripts/miCodigoPython.py .
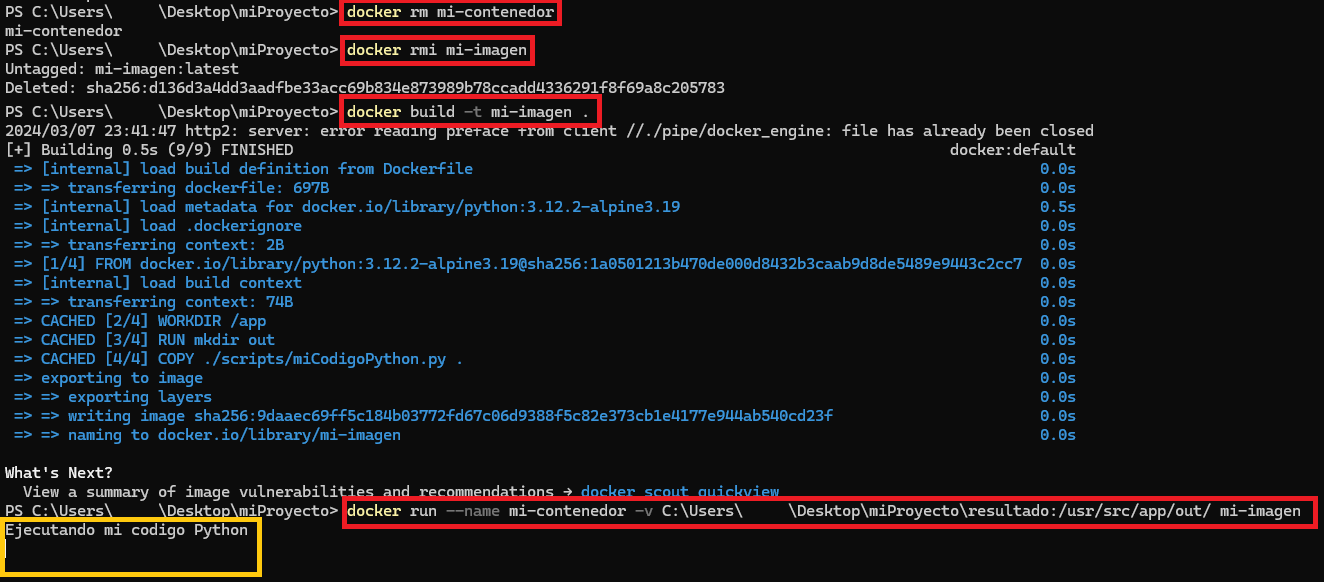
CMD python miCodigoPython.py & sleep infinityHay que construir de nuevo la imagen, pero antes hay que eliminarlo y previamente eliminar los contenedores que la usen, para mi ejemplo se puede eliminar con:
docker rm mi-contenedor
docker rmi mi-imagenY reconstruimos con “build” e iniciamos el contenedor con “run”:
docker build -t mi-imagen .
docker run --name mi-contenedor -v C:\Users\usuario\Desktop\miProyecto\resultado:/usr/src/app/out/ mi-imagenVerás que el código Python se ha ejecutado y que, además, se ha quedado pillada la terminal (esto es porque hemos logrado un “contenedor Daemon”).
Si abres otra segunda terminal y ejecutas “exec” puedes entrar en la terminal de nuestro contenedor y trabajar dentro:
docker exec -it mi-contenedor /bin/shPor probarlo un poco, hago un “ls” para ver mi fichero “miCodigoPython.py” y la carpeta “out”. Luego abro la terminal de Python y hago una suma simple (todo esto dentro de mi contenedor):
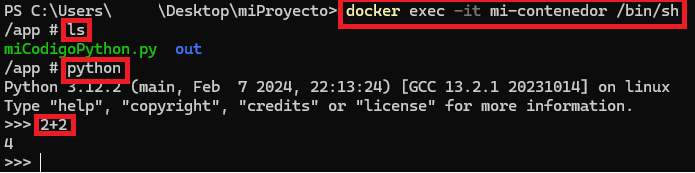
Para terminar el contenedor, en otra terminal ejecutar “stop” (o “kill”, si se pone muy pesado):
docker stop mi-contenedorFicheros recomendados y estandarizados para un Proyecto Docker
Cuando creas un proyecto Docker es común incluir los siguientes ficheros (además de los que tenga tu proyecto) a tú estructura de un proyecto Docker (los dos primeros ficheros ya los hemos visto previamente, los siguientes te pongo un ejemplo):
- Dockerfile: como ya se vio, sirve para Dockerizar el proyecto (usa “.dockerignore” para ignorar ficheros).
- compose.yaml: lo vimos en el artículo sobre Docker Compose. Se usa para trabajar con los sistemas en local, típicamente para desarrollo y que el microservicio funcione independientemente a otros sistemas (“standalone”, por ejemplo, puedes añadir una base de datos para que el microservicio de conecte a ésta en local y funcione sin salida a internet).
- .dockerignore: para que Docker ignore esos archivos y directorios cuando se construye (build) la imagen (similar .gitignore de Git). Ejemplo:
# .dockerignore
node_modules/
npm-debug.log
Dockerfile*
compose*
.git
.gitignore
README.md
README.Docker.md
LICENSE
.vscode
.idea- README.Docker.md: Un Readme exclusivo para lo relativo con Docker sobre el proyecto, como puede ser cómo construirlo desde el “Dockerfile” o consideraciones para levantar el “compose.yaml”. Ejemplo:
# README.Docker.md
## Comienzo rápido
Esta aplicación está diseñada para ejecutarse sobre [Docker](https://www.Docker.com/what-docker).
Construir la imagen:
````shell
docker build -t mi-imagen .
````
Para ejecutar un contenedor desde la imagen:
````shell
docker run --name mi-contenedor -v directorio/local/resultado:/usr/src/app/out/ mi-imagen
````
Se generará un fichero de ejemplo en la carpeta local `directorio/local/resultado`.
Directivas Docker
La mayoría de las instrucciones en un Dockerfile crean una nueva capa que se suma a la imagen. Te pongo las instrucciones ordenadas según suelen necesitarse en el fichero Dockerfile, aunque no es el único orden (salvo el FROM que tiene que ir al principio y CMD o ENTRYPOINT que van al final):
1) Inicializa una nueva etapa de compilación y establece la imagen base (obligatorio):
- FROM: Establece la imagen base para las siguientes instrucciones (a continuación, te muestro algunas imágenes base que se pueden usar aquí y en el siguiente artículo te mostraré imágenes de sistemas operativos pelados que podremos usar). Ejemplo:
FROM mysql:8.32) Documenta:
- LABEL: Agrega metadatos a una imagen que pueden ser consumidos por los usuarios, por Docker, etc. Ejemplo:
LABEL authors="Ramon Invarato"- EXPOSE: Informa que el contenedor escuchará en los puertos de red especificados en tiempo de ejecución. Ejemplo:
EXPOSE 8080- VOLUME: Crea un punto de montaje para un volumen (Los volúmenes permiten la persistencia y compartir archivos o directorios entre contenedores y el anfitrión). Crea un nuevo volumen de Docker y lo monta en el punto de montaje especificado; si no especificas un volumen al iniciar el contenedor, Docker utiliza el volumen que creó automáticamente. También se utiliza como documentación, para indicar que el contenedor está diseñado para usar volúmenes en los puntos de montaje especificados. Ejemplo:
VOLUME /datos3) Define variables:
- ARG: Define una variable que los usuarios pueden pasar en tiempo de compilación al constructor con el parámetro docker build –build-arg <varname>=<value>. Lo que se ponga después del igual es el parámetro por defecto. Ejemplo:
ARG VERSION_PROYECTO=0.0
# Se puede usar más adelante con $VERSION_PROYECTO
# Comando que lo usa: docker build --build-arg VERSION_PROYECTO=1.0 -t nombreimagen:tag .
- ENV: Establece una variable de entorno persistente para los siguientes pasos en el Dockerfile y puede ser usado en el contenedor cuando se ejecute. Ejemplo (de establecer las variables de Java, tras instalar Java con RUN, por ejemplo):
ENV JAVA_HOME /usr/lib/jvm/java-11-openjdk-amd64
ENV PATH $JAVA_HOME/bin:$PATH
4) Establece el directorio de trabajo y realiza el trabajo:
- WORKDIR: Establece el directorio de trabajo en el contenedor para las siguientes instrucciones RUN, CMD, ENTRYPOINT, COPY y ADD. Ejemplo (lo siguiente sería como hacer un “mkdir app” y después un “cd app”):
WORKDIR /app- ADD: Copia archivos y directorios al «sistema de archivos» del contenedor. también puede manejar URLs y descomprimir archivos tar.
- COPY: Similar a ADD, pero más simple, ya que solo soporta la copia de archivos y directorios (no soporta URLs ni descomprimir archivos tar). Se recomienda usar COPY antes que ADD. Ejemplo (donde “rutahots/*.jar” indica que se copien todos los ficheros JAR de la carpeta del hots “rutahosts” al directorio del contenedor establecido con WORKDIR, que en el anterior ejemplo era el directorio “app”):
COPY rutahots/*.jar ./- RUN: Permite ejecutar un comando en el sistema operativo y crear una nueva capa de la imagen. Este comando permite otras opciones, una interesante es montar un caché persistente (con “–mount=type=cache”) para acelerar los pasos de compilación, especialmente cuando se instalan paquetes (mediante administradores de paquetes) para solo descargar los paquetes nuevos o modificados; además, monta enlaces (con “–mount=type=bind”) de los ficheros con los de host, para no tener que copiar los archivos dentro de la imagen (nos ahorramos usar COPY). Ejemplo (de instalar Java):
RUN apt update && \
apt install -y openjdk-11-jdk && \
apt clean;
# O forzando el guardado en caché de la descarga del openjdk
RUN --mount=type=cache,target=/var/cache/apt \
apt update && \
apt install -y openjdk-11-jdk && \
apt clean;
4) Cambia de usuario a uno no root:
- USER: Establece el usuario que se utilizará para los siguientes RUN, CMD, and ENTRYPOINT múltiples instrucciones en el contenedor (por defecto es root). Ejemplo (de crear usuario y establecerlo; si el usuario ya existiera en la imagen base no habría que crear el usuario):
RUN useradd -ms /bin/bash usuarionoroot
USER usuarionoroot
5) Comprueba la salud de tu contenedor:
- HEALTHCHECK: es una manera de indicar a Docker cómo probar si un contenedor está todavía trabajando correctamente. Ejemplo (tras un con un periodo de inicio “start-period” de 5 segundos para esperar a que se levante el contenedor, se chequea cada intervalo “interval” de 30 segundos a http://localhost:8080 que esté levantado y se espera una respuesta antes de los 15 segundos “timeout”, y realizará 3 intentos “retries” antes de considerar al contenedor no saludable; se considera saludable si devuelve 0, si NO es saludable devolverá 1):
HEALTHCHECK --interval=30s --timeout=15s --start-period=5s --retries=3 CMD curl -f http://localhost:8080 || exit 16) Ejecuta tu contenedor (obligatorio):
- ENTRYPOINT: Configura un contenedor para que se ejecute como un ejecutable. Este comando no es recomendable sobrescribirlo, aunque se podría. Sólo la última instrucción ENTRYPOINT del Dockerfile será efectiva. Ejemplo (ejecuta “java -jar /app/miFicheroJava.jar”, que ejecuta el fichero “miFicheroJava.jar” con Java):
ENTRYPOINT ["java", "-jar", "/app/miFicheroJava.jar"]- CMD: Proporciona valores por defecto para un contenedor en ejecución. Se utiliza para proporcionar los argumentos por defecto que se pueden incluir en la línea de comandos cuando se inicia Docker; de esta manera, si especificas algún argumento al iniciar el contenedor, estos argumentos reemplazarán a los que están definidos en CMD (A diferencia de ENTRYPOINT, el CMD se puede sobrescribir). Sólo puede existir una instrucción CMD en un Dockerfile; en caso de especificar varias, sólo la última tomará efecto. Ejemplo (ejecuta “python /app/miFicheroPython.py”, que ejecuta el fichero “miFicheroPython.jar” con Python y le pasa por defecto el parámetro “parametroPorDefecto”, el cual se puede sobrescribir al ejecutar el “docker run”):
ENTRYPOINT ["python", "/app/miFicheroPython.py"]
CMD ["parametroPorDefecto"]
# Podemos cambiar el CMD si ejecutamos: docker run <nombreimagen> parametroNuevo
Nota sobre sobrescribir: Se puede sobrescribir tanto el ENTRYPOINT como el CMD, aunque el ENTRYPOINT hay que especificarlo ya que no es recomendable sobrescribirlo. En los siguientes ejemplos cambiamos (sobrescribimos) el ENTRYPOINT del Dockerfile por el comando “echo” y el CMD por el texto «Hola Mundo»:
- Dockerfile: docker run –entrypoint echo <nombreimagen> «Hola Mundo»
- Docker compose (“compose.yml”):
version: '3'
services:
my_service:
image: mi_imagen
entrypoint: echo
command: ["Hola Mundo"]
7) Añade información para quien use de base tu imagen Docker (solo en caso de extrema necesidad):
- ONBUILD: Agrega un disparador para la imagen que se ejecutará en el momento en que se utilice esa imagen como base para otra imagen. No afecta a la imagen actual, pero se «incorporará» a cualquier imagen que se base en ella. Por ejemplo (para forzar que todo quien use tú imagen como base se mantenga actualizado):
ONBUILD RUN apt-get update && apt-get upgrade -yEjemplo completo de Dockerfile con todas las directivas anteriores (el siguiente Dockerfile solo es ilustrativo, no funcional; veremos uno funcional en el siguiente artículo):
# Establecemos la imagen base.
FROM node:16-alpine
# Etiqueatas con Metadatos
LABEL version="1.0"
LABEL description="Mi aplicacion Node.js"
LABEL authors="Ramon Invarato"
LABEL maintainer="ramon@jarroba.com"
# Exponemos el puerto de la aplicación
EXPOSE 8080
# Argumento con valor por defecto
ARG NODE_ENV=desarrollo
# Establecemos la variable de entorno
ENV NODE_ENV=$NODE_ENV
# Creamos el directorio de trabajo y nos ubicamos en él
WORKDIR /app
# Copiamos el archivo donde están las dependencias (así solo se descargarán una vez y podremos modificar lo que necesitemos muchas veces)
COPY package.json .
# Instalamos las dependencias
RUN npm install
# Copiamos el resto de la aplicación donde están los ficheros con los que hemos trabajado
COPY . .
# Instalamos 'curl' para el chequeo de salud (pues la imagen base no lo incluye)
RUN apk add --no-cache curl
# Establecemos un usuario no root
USER node
# Verificamos la salud de la aplicación
HEALTHCHECK --interval=30s --timeout=30s --start-period=5s --retries=3 CMD curl -f http://localhost:8080 || exit 1
# Ejecutamos la aplicación con argumentos necesarios para que funcione
ENTRYPOINT ["npm", "start"]
# Completamos el comando anterior con argumentos opcionales que se pueden sobrescribir
CMD ["--entorno=$NODE_ENV"]
# Instrucción a ejecutar cuando se utilice esta imagen como base de otra imagen
ONBUILD RUN echo 'Construyendo desde imagen base'
Imágenes base
Imágenes base de terceros para usar en el FROM hay muchas (te recomiendo revisarlas en https://hub.docker.com/), algunos ejemplos son (muchos ya los hemos visto en estos artículos):
- Node (https://hub.docker.com/_/node): Para aplicaciones de Node.js
- Python (https://hub.docker.com/_/python): Para aplicaciones Python
- Ruby (https://hub.docker.com/_/ruby): Para aplicaciones Ruby
- Golang (https://hub.docker.com/_/golang): Para aplicaciones Go
- Java (hay varias, una es https://hub.docker.com/_/eclipse-temurin): Para aplicaciones Java
- Php (https://hub.docker.com/_/php): Para aplicaciones PHP
- Mysql (https://hub.docker.com/_/mysql): Para el servicio de base de datos MySQL
- Postgres (https://hub.docker.com/_/postgres): Para el servicio de base de datos PostgreSQL
- Mongo (https://hub.docker.com/_/mongo): Para el servicio de base de datos MongoDB
- Nginx (https://hub.docker.com/_/nginx): Para el servidor web/proxy inverso Nginx
- Httpd (https://hub.docker.com/_/httpd): Para el servidor web Apache HTTP Server
- Redis (https://hub.docker.com/_/redis): Para la base de datos en memoria Redis
- WordPress (https://hub.docker.com/_/wordpress): Para la plataforma de blogs y gestión de contenido WordPress
- Drupal (https://hub.docker.com/_/drupal): Para la plataforma de gestión de contenido Drupal
- Jenkins (https://hub.docker.com/r/jenkins/jenkins): Para el servidor de integración continua Jenkins
Ver Dockerfile públicos
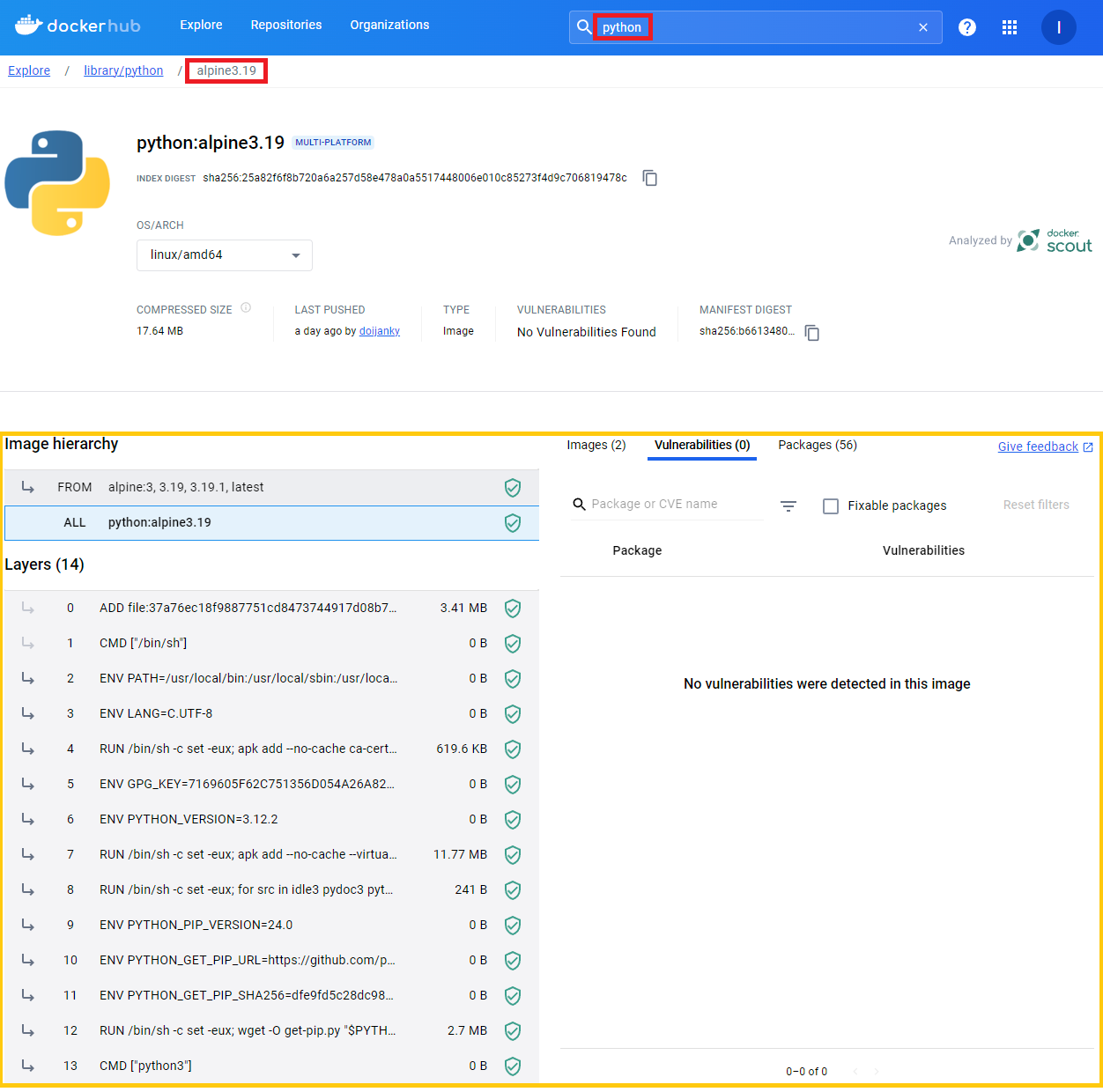
Si vamos al Docker Hub y escogemos cualquier imagen y si entramos dentro de su tag, podremos ver el Dockerfile con el que está construido cualquier imagen. Sirve tanto para aprender de éste, como para ver qué están haciendo y poder confiar en la imagen de Docker, así como ver si tiene vulnerabilidades, etc.
Yo entraré en el tag “alpine3.19” de “python”: https://hub.docker.com/layers/library/python/alpine3.19/images/sha256-b6613480a7eac9a1e50ef5dbe57195e335b5545e1ef8d1d20e97db531033c8b6?context=explore
Dentro podremos ver el Dockerfile, así como otra mucha información, de una manera bastante detallada:
Continúa el curso de Docker
Puedes continuar con la siguiente parte de este curso en:

One thought on “Dockerfile: Directivas y Dockerizar proyectos”