LangChain: lo que me hubiese gustado saber antes de empezar (Parte I)
Cuando empiezas a estudiar un nuevo framework, es fácil sentirse abrumado por la cantidad de conceptos, componentes y posibilidades que ofrece. LangChain no es la excepción; es un ecosistema amplio y profundo que va mucho más allá de simplemente “hacer prompts”.
Por eso, cuando exploro librerías como LangChain, me resulta de gran ayuda construirme un esquema mental para entender cuáles son sus piezas clave, cómo encajan entre sí y qué problemas reales resuelven dentro de un sistema. Sin ese mapa conceptual, es fácil perderse entre clases y ejemplos aislados.
En este post quiero compartir el esquema mental que he ido construyendo, con la intención de ayudarte a comprender qué es realmente LangChain, cómo utilizarlo con criterio y en qué tipo de arquitecturas aporta valor. Intentaré apoyar cada concepto con pequeños fragmentos de código autoejecutables, aunque algunos puntos (por su complejidad) requerirán un enfoque más conceptual que práctico.
Antes de empezar: ¿Es LangChain una librería?
No LangChain no es una librería. Y esta distinción es más importante de lo que parece. LangChain es un framework modular para orquestar LLMs. Está compuesto por varios paquetes con responsabilidades bien diferenciadas. Entender esta estructura evita confusiones cuando empiezas a instalar dependencias o a diseñar arquitectura.
Podemos dividir el ecosistema en «3+1» bloques principales:
- LangChain Core: Es el núcleo estable del framework. Aquí viven las abstracciones fundamentales como:
Runnable,PromptTemplate,ChatPromptTemplate,Parsers,Composición con LCEL, etc. Se instala con:pip install langchain - LangChain Community: Contiene integraciones mantenidas por la comunidad con servicios externos que no forman parte del core como:
Chroma,Qdrant,PyPDFLoader,WebBaseLoader, Integraciones experimentales, etc. Se instala con:pip install langchain-community - Partner Packages: Son conectores oficiales mantenidos en colaboración con proveedores de LLMs. Implementan la integración directa con APIs comerciales como
OpenAI,Gemini,Claude,DeepSeek, etc. Cada proveedor se instala por separado:pip install langchain-openai pip install langchain-google-genai pip install langchain-anthropic pip install langchain-deepseek - (+1) Librerías complementarias: LangChain no vive solo. En sistemas reales suele combinarse con librerias para el desarrollo de pipelines RAG, sistemas de indexación, validación estructurada o despliegues interactivos, etc. Algunas de estas librería son:
chromadb,faiss-cpu,pypdf,beautifulsoup4,pydantic,streamlit,fastapi,langchain-huggingface,sentence-transformers,tiktoken, etc. y cada una tiene su instalación independiente.
Entender esta modularidad desde el principio cambia la forma en la que trabajas con el framework: no instalas “LangChain”, diseñas un sistema compuesto por piezas interoperables. Esquemáticamente podemos representarlo así:

Índice de conceptos
En esta serie de posts voy a cubrir los siguientes conceptos clave para entender y utilizar LangChain de manera efectiva:
- ¿Qué es un LLM?
- APIs y proveedores de LLMs
- Runnables
- LCEL
- PromptTemplate, ChatPromptTemplate & Placeholder
- MessagesPlaceholder
- Document Loaders
- Text Splitters
- Embeddings
- Bases de datos vectoriales
- Retrievers
- RAG
Bonus track:
- Pydantic
- Streamlit
1. ¿Qué es un LLM?
Un LLM (Large Language Model) es un modelo que recibe como entrada un texto denominado Prompt y genera una respuesta en lenguaje natural. Para que el modelo procese el prompt, este se convierte en tokens, que son la unidad mínima de texto que un LLM entiende y genera. Un Token puede ser una palabra completa, un fragmento, un espacio o un símbolo. Como referencia, 1000 tokens corresponden aproximadamente a 750 palabras (1 token ≈ 0.75 palabras). Los proveedores de LLMs miden y facturan el uso del modelo en función del número total de tokens procesados.
Los LLMs operan dentro de una Context Window (ventana de contexto), que es la cantidad total de información que el modelo puede manejar en una interacción. Esta ventana incluye el prompt actual, el historial previo de la conversación y los tokens que el modelo está generando como respuesta; la suma de todos ellos no puede superar el límite máximo del modelo.
Tras recibir el prompt, comienza la Inferencia, que es el proceso en el que el modelo genera de manera secuencial (token a token) los tokens de salida, construyendo progresivamente un texto coherente hasta completar la respuesta o alcanzar el límite establecido. El texto generado se denomina Completion (Prompt + Texto generado).
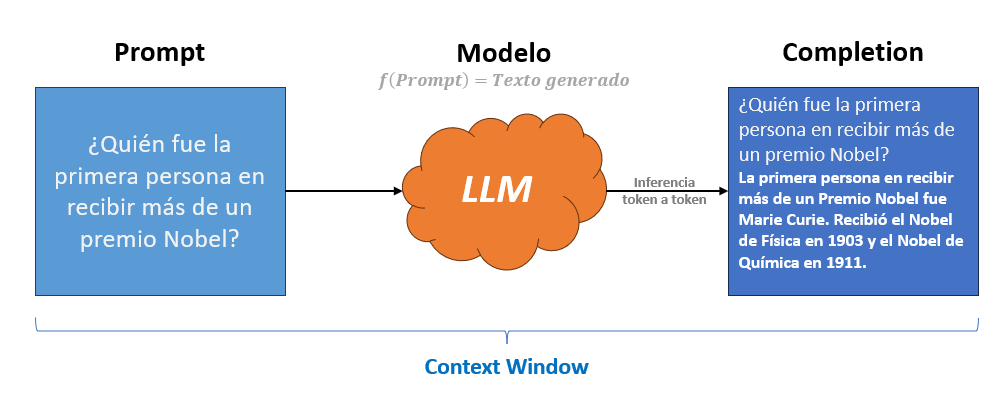
A modo de referencia comparativa, en la siguiente tabla se muestran algunos de los modelos más representativos del mercado, junto con su ventana de contexto y sus costes aproximados por millón de tokens.
| Modelo | Context Window | Coste Input (≈ $ / 1M tokens) | Coste Output (≈ $ / 1M tokens) |
|---|---|---|---|
| GPT-5.X | ~400K tokens | ~$10–15 | ~$30–40 |
| GPT-4o-mini | ~128K tokens | ~$5 | ~$15 |
| Gemini 3 | ~1M tokens | ~$7–12 | ~$20–30 |
| Gemini 2.5 Flash | ~1M tokens | ~$1–3 | ~$3–8 |
| Claude Opus 4.5 | ~200K tokens | ~$15–20 | ~$60–75 |
| Claude 4.5 Sonnet | ~1M tokens | ~$3–6 | ~$15–20 |
| Claude 3 Haiku | ~200K tokens | ~$0.25–1 | ~$1–4 |
| DeepSeek V3.2 | ~128K tokens | ~$0.5–2 | ~$2–5 |
| DeepSeek Chat (Lite) | ~128K tokens | ~$0.2–0.8 | ~$1–3 |
Resumen de los conceptos clave relacionados con los LLMs:
| Concepto | Definición |
|---|---|
| LLM | Modelo que recibe un Prompt como entrada y genera una respuesta en lenguaje natural. |
| Prompt | Texto de entrada que el usuario envía al modelo. |
| Token | Unidad mínima de texto que el LLM entiende y genera; puede ser una palabra, fragmento, espacio o símbolo. |
| Context Window | Cantidad total de tokens que el modelo puede manejar en una interacción (prompt + historial + salida). |
| Inferencia | Proceso mediante el cual el modelo genera secuencialmente los tokens de salida. |
| Completion | Texto final generado por el modelo como respuesta al prompt. |
2. APIs y proveedores de LLMs – OpenAI, Gemini, Anthropic, DeepSeek, …
El primer paso para construir cualquier sistema con LLMs es poder invocarlos correctamente.
LangChain proporciona integraciones oficiales vía API con los principales proveedores. Cada uno ofrece distintos modelos, límites, políticas de uso, coste, etc. Desde el punto de vista arquitectónico, todos se consumen como servicios remotos que exponen un endpoint HTTP y facturan por volumen de tokens procesados (entrada + salida). Ver listado de proveedores: https://docs.langchain.com/oss/python/integrations/chat
Para poder utilizarlos necesitas:
- Crear una cuenta en la plataforma del proveedor.
- Generar una API_KEY.
- Configurar esa clave en tu entorno (normalmente como variable de entorno).
- Disponer de saldo suficiente, ya que la facturación se realiza por token consumido.
En la práctica, todos los proveedores operan bajo el mismo modelo económico: cuanto mayor sea el número de tokens que envíes y generes, mayor será el coste. Por eso es importante diseñar desde el inicio pensando en la eficiencia.
Si estás empezando, una buena opción es Google Gemini, que ofrece una cuota gratuita limitada que permite experimentar sin coste inicial. No obstante, el objetivo de este post no es detallar el proceso de registro ni la generación de claves; para ello te recomiendo consultar la documentación oficial de cada proveedor.
A continuación, tienes los enlaces de alta en las principales plataformas:
- OpenAI: https://openai.com/es-ES/api/
- Google Gemini: https://aistudio.google.com/app/api-keys
- Anthropic: https://platform.claude.com/
- DeepSeek: https://platform.deepseek.com/
Para poder utilizar un modelo de chat en LangChain primero debese legir el proveedor y después instalar el paquete correspondiente:
pip install langchain-openai
pip install langchain-google-genai
pip install langchain-anthropic
pip install langchain-deepseekCada uno de estos paquetes implementa su propia clase ChatModel, pero todas comparten una interfaz común y un conjunto de parámetros muy similares.
| Parámetro | Propósito | ¿Qué es? | ¿Para qué sirve? |
|---|---|---|---|
| model | Nombre del modelo | Identificador del modelo a utilizar | Seleccionar capacidades, contexto, coste y rendimiento |
| temperature | Control de aleatoriedad | Parámetro de sampling que ajusta la entropía | Hacer la salida más determinista (0) o más creativa (>0.7) |
| max_tokens | Máximo tokens de salida | Límite superior de tokens que puede generar el modelo | Controlar longitud de respuesta y coste |
| timeout | Tiempo máximo de espera | Tiempo límite de espera para la respuesta API | Evitar bloqueos indefinidos si el proveedor tarda o falla |
| max_retries | Reintentos automáticos | Número de intentos automáticos ante error | Aumentar robustez frente a rate limits o errores temporales |
| api_key | Clave API | Credencial privada de autenticación | Autorizar y facturar el uso del servicio |
api_key como parámetro en el código. Configúralo como variable de entorno (OPENAI_API_KEY, GOOGLE_API_KEY, etc.).A continuación mostramos el código para instanciar a los LLMs de los diferentes proveedores:
OpenAI
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0.2, timeout=30, max_retries=2)
Google (Gemini)
from langchain_google_genai import ChatGoogleGenerativeAI
llm = ChatGoogleGenerativeAI(model="gemini-2.5-flash", temperature=0.2)
Anthropic (Claude)
from langchain_anthropic import ChatAnthropic
llm = ChatAnthropic(model="claude-3-5-sonnet-latest", temperature=0.2, timeout=30)
DeepSeek
from langchain_deepseek import ChatDeepSeek
llm = ChatDeepSeek(model="deepseek-chat", temperature=0.2, timeout=30, max_retries=2)
Observa que en todos los casos estamos asignando la instancia a la variable llm. Esto permite cambiar de proveedor sin modificar el resto del sistema. Una forma limpia de hacerlo es centralizar la construcción del modelo:
from langchain_openai import ChatOpenAI
from langchain_google_genai import ChatGoogleGenerativeAI
from langchain_anthropic import ChatAnthropic
from langchain_deepseek import ChatDeepSeek
def build_llm(provider: str, temperature: float = 0.2, timeout: int = 30, max_retries: int = 2):
provider = provider.lower()
if provider == "openai":
return ChatOpenAI(model="gpt-4o-mini", temperature=temperature, timeout=timeout, max_retries=max_retries)
elif provider == "google":
return ChatGoogleGenerativeAI(model="gemini-2.5-flash", temperature=temperature, timeout=timeout, max_retries=max_retries)
elif provider == "anthropic":
return ChatAnthropic(model="claude-3-5-sonnet-latest", temperature=temperature, timeout=timeout, max_retries=max_retries)
elif provider == "deepseek":
return ChatDeepSeek(model="deepseek-chat", temperature=temperature, timeout=timeout, max_retries=max_retries)
else:
raise ValueError("Proveedor no soportado. Usa: openai | google | anthropic | deepseek")
De esta forma, tu arquitectura queda desacoplada del proveedor y puedes cambiar de modelo sin reescribir tu pipeline.
3. Runnables – la interfaz base de LangChain
En LangChain, prácticamente todo es un Runnable: modelos, prompts, retrievers, parsers o incluso funciones personalizadas.
Un Runnable es la interfaz base de ejecución del framework. Define cómo se ejecuta cualquier componente: recibe una entrada, realiza una operación y devuelve una salida. La forma estándar de ejecutarlo es mediante el método invoke().
Todos los Runnable implementan la misma interfaz de ejecución:
| Método | ¿Qué hace? |
|---|---|
invoke(input) |
Ejecuta el Runnable de forma síncrona y devuelve el resultado completo. |
stream(input) |
Ejecuta el Runnable y devuelve la salida de manera incremental (por partes). |
batch(inputs) |
Ejecuta el Runnable sobre múltiples entradas y devuelve una lista de resultados. |
ainvoke() |
Versión asíncrona de invoke(), permite usar await en entornos concurrentes. |
astream() |
Versión asíncrona de stream(), genera salida incremental sin bloquear el hilo principal. |
abatch() |
Versión asíncrona de batch(), permite procesar múltiples entradas en paralelo. |
Esto implica algo fundamental: un LLM, un Retriever o una función custom se utilizan exactamente igual desde el punto de vista de ejecución. La arquitectura se vuelve homogénea.
Veamos un ejemplo sencillo invocando un modelo mediante invoke(), que es la forma más habitual de ejecutar un Runnable:
from langchain_google_genai import ChatGoogleGenerativeAI
llm = ChatGoogleGenerativeAI(model="gemini-2.5-flash", temperature=0.2)
out = llm.invoke("¿Quien fue la primera persona en recibir más de un premio Nobel?")
print(out.content)
# La primera persona en recibir más de un Premio Nobel fue Marie Curie ...
En este caso, llm es simplemente un Runnable. Recibe un texto como entrada, ejecuta la llamada al modelo y devuelve un objeto AIMessage cuyo contenido accedemos mediante .content.
Entender que todo en LangChain es un Runnable es clave, porque significa que cualquier componente del sistema puede ejecutarse, combinarse y sustituirse siguiendo exactamente el mismo patrón.
4. LCEL – construyendo el pipeline de ejecución
Si los Runnables son las piezas básicas de LangChain, LCEL (LangChain Expression Language) es el mecanismo que permite conectarlos entre sí para construir un pipeline de ejecución.
LCEL es una sintaxis declarativa que utiliza principalmente el operador | para encadenar Runnables. Conceptualmente, cada | indica que la salida de un componente se convierte en la entrada del siguiente. Es decir:
input -> Runnable1 -> Runnable2 -> ... -> outputNo estamos escribiendo código procedural paso a paso, sino declarando un flujo de transformación de datos.
Veamos a continuación un ejemplo práctico donde encadenamos un LLM con una función personalizada (Runnable) que transforma la salida a mayúsculas:
from langchain_google_genai import ChatGoogleGenerativeAI
from langchain_core.runnables import RunnableLambda
# 1.- Instanciamos el LLM
llm = ChatGoogleGenerativeAI(model="gemini-2.5-flash", temperature=0.2)
# 2️.- Creamos un Runnable que transforma la salida a mayúsculas
to_upper = RunnableLambda(lambda msg: msg.content.upper())
# 3️.- Encadenamos ambos Runnables y la cadena se interpretaria como:
# input -> llm -> to_upper -> output
chain = llm | to_upper
# 4️.- Ejecutamos
out = chain.invoke("¿Quién fue la primera persona en recibir más de un premio Nobel?")
print(out)
# LA PRIMERA PERSONA EN RECIBIR MÁS DE UN PREMIO NOBEL FUE MARIE CURIE ...
¿Qué está ocurriendo realmente? en ‘chain = llm | to_upper’
- El input (un string) entra en el LLM.
- El LLM devuelve un AIMessage.
- Ese AIMessage pasa automáticamente al siguiente Runnable (to_upper).
- to_upper transforma el contenido a mayúsculas.
- El resultado final es la salida del pipeline.
En definitiva, LCEL convierte una colección de componentes aislados en un pipeline declarativo y componible, permitiendo construir sistemas más complejos sin abandonar el mismo patrón de ejecución.
5. PromptTemplates, ChatPromptTemplates & Placeholders
Los PromptTemplate permiten definir prompts dinámicos como artefactos reutilizables, en lugar de texto estático repartido por el código. En la práctica funcionan como un contrato de entrada: explicitan qué variables necesita el modelo y bajo qué reglas debe responder, facilitando la mantenibilidad y haciendo el comportamiento más consistente.
En este punto veremos que es un PromptTemplate y ChatPromptTemplate, introduciendo el concepto de Root Prompt y el uso de placeholders.
Para entender el Root Prompt, piensa en cómo empiezas una conversación en ChatGPT, Claude, Gemini, etc. sueles empezar con un primer mensaje indicándoles:
- Rol o personalidad
- Reglas y restricciones
- Estilo de respuesta
- Contexto persistente
Por ejemplo, podriamos escribir algo como:
Eres un asistente especializado en Futbol.
Reglas:
- Respondé en español rioplatense (Argentina).
- Explica los conceptos de forma simple
- Usa analogías cuando sea posible
- No des respuestas genéricas, sé concreto y directo
- Las respuestas deben ser breves, de no más de 100 palabras
Pregunta:
¿Qué es el fuera de juego?
Ese primer mensaje es el Root Prompt: define identidad, tono y límites, y condiciona toda la interacción posterior.
La idea clave es que este Root Prompt puede hacerse reutilizable y dinámico mediante una plantilla. En el ejemplo las reglas podrian ser las mismas, pero el tema (Futbol) y la pregunta (¿Qué es el fuera de juego?) podrían cambiar. Aquí entran los placeholders, que no son más que variables dentro del prompt que se sustituyen por valores concretos en tiempo de ejecución.
Un PromptTemplate es precisamente eso: una plantilla de texto con placeholders que permite mantener la estructura base (identidad y reglas) y cambiar únicamente lo variable, como el tema o la pregunta, sin reescribir el prompt.
En LangChain se hace con PromptTemplate así:
from langchain_core.prompts import PromptTemplate
from langchain_google_genai import ChatGoogleGenerativeAI
# LLM
llm = ChatGoogleGenerativeAI(model="gemini-2.5-flash", temperature=0.2)
# Prompt como contrato
prompt = PromptTemplate(
template="""
Eres un asistente especializado en {tema}.
Reglas:
- Respondé en español rioplatense (Argentina).
- Explica los conceptos de forma simple
- Usa analogías cuando sea posible
- No des respuestas genéricas, sé concreto y directo
- Las respuestas deben ser breves, de no más de 100 palabras
Pregunta: {pregunta}
""",
input_variables=["tema", "pregunta"]
)
# LCEL (input -> prompt -> llm -> output)
chain = prompt | llm
# Ejecutamos el pipeline con diferentes preguntas pero manteniendo el mismo contrato de entrada
respuesta = chain.invoke({
"tema": "Machine Learning",
"pregunta": "Overfitting"
})
# Imprimimos la respuesta
print(respuesta.content)
# ¡Che, mirá! El overfitting es cuando tu modelo de Machine Learning se la re banca con los datos que ya vio ...
# Es como si un pibe estudiara para un examen memorizando las respuestas exactas de un cuestionario viejo ...
Así, el template define el contrato (variables obligatorias) y puedes ejecutar el mismo “molde” con entradas distintas. La limitación es que PromptTemplate modela bien casos de un único mensaje, pero resulta menos adecuado cuando necesitas conversación con varios turnos, historial, ejemplos y roles explícitos y aquí entra el ChatPromptTemplate.
El ChatPromptTemplate construye el prompt como una secuencia de mensajes en la que cada uno tiene un rol (system, human, ai, etc.). Esto importa porque el modelo interpreta de forma distinta una instrucción del sistema, una pregunta del usuario o una respuesta previa, y esa estructura mejora la coherencia en sistemas conversacionales.
Los roles predefinidos más habituales son:
| Rol | Explicación breve |
|---|---|
| system | Define la identidad del modelo, sus reglas, tono y restricciones globales. Es el Root Prompt que condiciona todo el comportamiento. |
| human | Representa la entrada del usuario. Contiene la pregunta o instrucción dinámica que se quiere resolver. |
| ai | Representa respuestas previas del modelo. Se usa en historial conversacional o en ejemplos few-shot para guiar el estilo y formato de salida. |
| tool | Contiene el resultado de una herramienta externa invocada por el modelo. Se usa en arquitecturas con tool-calling o agentes. |
Un ejemplo con ChatPromptTemplate sería:
from langchain_core.prompts import ChatPromptTemplate
from langchain_google_genai import ChatGoogleGenerativeAI
# LLM
llm = ChatGoogleGenerativeAI(model="gemini-2.5-flash", temperature=0.2)
# ChatPromptTemplate como contrato estructurado
chat_prompt = ChatPromptTemplate.from_messages([
# Rol SYSTEM → Root Prompt (identidad + reglas globales)
("system", """
Eres un asistente especializado en {tema}.
Reglas:
- Respondé en español rioplatense (Argentina).
- Explicá los conceptos de forma simple.
- Usá analogías cuando sea posible.
- No des respuestas genéricas, sé concreto y directo.
- Las respuestas deben ser breves, de no más de 100 palabras.
"""),
#### Historico de conversación: esto es lo que se llama contexto persistente ####
# Rol HUMAN → Pregunta que realiza el usuario
("human", "¿Qué es un modelo supervisado?"),
# Rol AI → Respuesta del modelo a la pregunta del usuario
("ai", "Es como aprender con un profe que te corrige. Te dan ejemplos con la respuesta correcta y el modelo ajusta hasta acertar solo."),
#### Fin del contexto persistente ####
# Rol HUMAN → input dinámico real
("human", "{pregunta}")
])
# LCEL (input -> chat_prompt -> llm -> output)
chain = chat_prompt | llm
# Ejecutamos el pipeline
respuesta = chain.invoke({
"tema": "Machine Learning",
"pregunta": "¿Qué es el overfitting?"
})
print(respuesta.content)
# Che, el overfitting es cuando tu modelo se aprende los datos de entrenamiento ¡demasiado bien! Es como un pibe ...
# Después, le cambiás una coma en la pregunta y ya no sabe qué hacer. Se vuelve un capo para lo que ya vio ...
La diferencia práctica es que aquí el contrato queda expresado como conversación: el Root Prompt vive en system, el contexto persistente se representa con mensajes human/ai, y la entrada actual entra como human con un placeholder.
En resumen, PromptTemplate y ChatPromptTemplate convierten el prompt en un artefacto mantenible: declaran contratos de entrada, separan reglas de la lógica y permiten reutilizar el comportamiento del sistema de forma consistente, desde casos simples hasta conversaciones complejas.
6. MessagesPlaceholder y Few-shot
Un LLM no tiene memoria propia, no recuerda interacciones anteriores ni aprende de cada conversación, ya que no se reentrena en tiempo real. Sin embargo, en aplicaciones como ChatGPT, Gemini o Claude parece que “recuerda” lo dicho antes. Esto ocurre porque en cada llamada se le envía la nueva pregunta y el historial de la conversación (contexto).
No hay que olvidar que un LLM no es más que un modelo que genera texto a partir de un texto de entrada (prompt). No hace nada más. La responsabilidad de cómo se construye y gestiona ese prompt recae en el sistema que desarrolles. Diseñar correctamente el contexto es lo que permite construir aplicaciones que aparenten memoria, coherencia y continuidad en el tiempo.
Para esta tarea, LangChain ofrece el componente MessagesPlaceholder, que es un tipo especial de placeholder que se utiliza para representar el historial de mensajes en un ChatPromptTemplate. En lugar de simplemente insertar texto, este MessagesPlaceholder se encarga de formatear y estructurar el historial de la conversación (contexto) de manera adecuada para que el modelo lo interprete correctamente.
Veamos a continuación un ejemplo práctico donde se utiliza MessagesPlaceholder para incluir un historial de conversación con varias iteraciones, y luego se hace una pregunta teniendo en cuenta ese contexto:
from langchain_google_genai import ChatGoogleGenerativeAI
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.messages import HumanMessage, AIMessage
# LLM
llm = ChatGoogleGenerativeAI(model="gemini-2.5-flash", temperature=0.2)
# Prompt conversacional con historial
prompt = ChatPromptTemplate.from_messages([
("system", """
Eres un asistente especializado en {tema}.
Reglas:
- Respondé en español rioplatense (Argentina).
- Explicá los conceptos de forma simple.
- Usá analogías cuando sea posible.
- No des respuestas genéricas, sé concreto y directo.
- Las respuestas deben ser breves, de no más de 100 palabras.
"""),
MessagesPlaceholder(variable_name="historial"),
("human", "{pregunta}")
])
# Historial de la conversación con 4 iteraciones completas
historial = [
HumanMessage(content="Che, ¿qué es el aprendizaje supervisado?"),
AIMessage(content="Es como aprender con un profe que te pasa ejercicios con la respuesta correcta y te va corrigiendo hasta que lo hacés bien vos solo."),
HumanMessage(content="¿Y qué sería un modelo?"),
AIMessage(content="Es como una regla matemática que intenta copiar un patrón, algo que agarra datos de entrada y los transforma en una respuesta."),
HumanMessage(content="¿Y entrenar el modelo qué significa?"),
AIMessage(content="Es ir ajustando sus parámetros con ejemplos, como cuando practicás un montón hasta que te sale casi sin pensar."),
HumanMessage(content="¿Y qué pasa si practica demasiado con los mismos ejemplos?"),
AIMessage(content="Puede empezar a memorizar todo tal cual, en vez de entender la idea general.")
]
# LCEL
chain = prompt | llm
# Nueva pregunta dependiente del contexto
resp = chain.invoke({
"tema": "Machine Learning",
"historial": historial,
"pregunta": "Entonces, ¿qué es el overfitting en este contexto?"
})
print(resp.content)
# Ahí va: el overfitting es cuando tu modelo se vuelve un capo para los datos que ya vio, los memoriza de
# punta a punta, ¡hasta los errores! Pero después, cuando le tirás datos nuevos que nunca vio, se hace un lío y
# no sabe qué hacer. Es como si un estudiante se aprendiera de memoria las respuestas de un examen viejo,
# pero no entendiera la materia para uno nuevo.
Gracias a este enfoque podemos controlar el contexto programaticamente como queramos; por ejemplo, limitando el número de mensajes enviados, resumiendo el historial, eliminando contenido irrelevante o sensible, o aplicar cualquier estrategia que optimice calidad y coste en tokens, etc.
Otra técnica clave para mejorar el comportamiento del modelo es el few-shot prompting o few-shot learning. En lugar de explicar con más instrucciones lo que esperamos, le mostramos ejemplos concretos de entrada y salida.
Por ejemplo, podemos pedirle que genere un acta de reunión a partir de una transcripción e incluir ejemplos de actas generadas a partir de su transcripción. Esto guía al modelo hacia un formato, estilo o patrón específico. Con ChatPromptTemplate y MessagesPlaceholder, incluir ejemplos es tan sencillo como añadir pares human/ai al historial.
Veamos a continuación un ejemplo típico de few-shot en el que clasifica unos textos según su sentimiento (positivo, negativo o neutral) a partir de ejemplos previos incluidos en el historial:
from langchain_google_genai import ChatGoogleGenerativeAI
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.messages import HumanMessage, AIMessage
llm = ChatGoogleGenerativeAI(model="gemini-2.5-flash", temperature=0.2)
prompt = ChatPromptTemplate.from_messages([
("system", "Clasifica el sentimiento como: POSITIVO, NEGATIVO o NEUTRO. Responde solo con la etiqueta."),
MessagesPlaceholder(variable_name="ejemplos"),
("human", "Texto: {texto}")
])
ejemplos = [
HumanMessage(content="Me encanta este producto"),
AIMessage(content="POSITIVO"),
HumanMessage(content="El servicio fue terrible"),
AIMessage(content="NEGATIVO"),
HumanMessage(content="Es lo que esperaba de este producto, ni más ni menos"),
AIMessage(content="NEUTRO"),
]
chain = prompt | llm
resp = chain.invoke({
"ejemplos": ejemplos,
"texto": "Esto funciona bastante bien, pero podría mejorar."
})
print(resp.content)
# NEUTRO
En conclusión, MessagesPlaceholder y few-shot no consisten en añadir más texto, sino en controlar el contexto que se le pasa el LLM. El historial aporta continuidad y coherencia a la conversación y los ejemplos aportan comportamiento y formato.
Diseñar bien qué mensajes entran en el prompt, en qué orden y con qué propósito, es lo que convierte un simple generador de texto en un sistema que parece inteligente, consistente y alineado con nuestras expectativas.
Conclusión
En esta primera parte hemos cubierto los conceptos fundamentales para entender qué es LangChain, cómo se organiza y qué problemas resuelve realmente. Hemos visto que no es una librería monolítica, sino un ecosistema modular compuesto por distintas piezas con responsabilidades claras.
Hemos entendido cómo se invoca un LLM y por qué todo en LangChain gira en torno a la interfaz Runnable, que unifica la ejecución. A partir de ahí, hemos visto cómo LCEL permite construir pipelines declarativos y componibles, y cómo PromptTemplate y ChatPromptTemplate convierten el prompt en un contrato explícito y mantenible dentro de la arquitectura.
Por último, hemos aprendido que la coherencia conversacional no es memoria real, sino gestión del contexto, apoyándonos en MessagesPlaceholder, y que el comportamiento del modelo puede guiarse de forma efectiva mediante ejemplos few-shot. Con estos seis pilares claros, ya dispones del mapa mental mínimo para empezar a diseñar sistemas con LLMs con criterio arquitectónico.
Anexo: Implementa con los conceptos vistos to chatModel con LangChain
Con todo lo visto, vamos a implementar un chat por consola con Gemini + LangChain.
Una vez que ejecutes el código que se muestra a continuación, le indicarás un tema de conversación (por ejemplo, «Machine Learning») y luego podrás hacer preguntas relacionadas con ese tema como si de un chatGPT se tratase.
Para que visualices lo que realmente se le está enviando al modelo, en cada turno imprimiremos el mensaje del sistema (Root Prompt), el historial de la conversación (contexto) y la pregunta actual, así podrás entender cómo se construye el prompt en cada interacción y cómo el modelo utiliza ese contexto para generar respuestas coherentes.
# Chat por consola con Gemini + LangChain.
# En cada turno imprime lo que se envía al LLM: system + historial + pregunta.
from langchain_google_genai import ChatGoogleGenerativeAI
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.messages import HumanMessage, AIMessage
tema = input("Tema de la conversación: ").strip() or "Machine Learning"
llm = ChatGoogleGenerativeAI(model="gemini-2.5-flash", temperature=0.2)
prompt = ChatPromptTemplate.from_messages([
("system", f"Eres un asistente experto en {tema}. Responde en español de España, breve y claro con respuestas de menos de 30 palabras."),
MessagesPlaceholder("historial"),
("human", "{pregunta}")
])
historial = []
print("\nEscribe 'salir' para terminar.")
while True:
pregunta = input("Tú: ").strip()
if pregunta.lower() == "salir":
break
# Mensajes exactos que van al LLM (system + historial + pregunta)
mensajes = prompt.format_messages(historial=historial, pregunta=pregunta)
print("\n--- ENVIADO AL LLM ---")
for m in mensajes:
role = m.__class__.__name__.replace("Message", "").lower()
print(f"[{role}] {m.content}")
# Llamada al LLM
resp = llm.invoke(mensajes)
print("--- RESPUESTA ---")
print(resp.content)
# Actualizamos historial (esto es “el contexto”)
historial += [HumanMessage(content=pregunta), AIMessage(content=resp.content)]
A continuación, te dejo un ejemplo de cómo se vería la interacción en consola:
Tema de la conversación: Machine Learning
Escribe 'salir' para terminar.
Tú: ¿Qué es el aprendizaje supervisado?
--- ENVIADO AL LLM ---
[system] Eres un asistente experto en Machine Learning. Responde en español de España, breve y claro con respuestas de menos de 30 palabras.
[human] ¿Qué es el aprendizaje supervisado?
--- RESPUESTA ---
Aprende de datos etiquetados (pares entrada-salida) para predecir resultados o clasificar nuevos datos. Busca una función que mapee la entrada a la salida.
Tú: ¿Qué es un modelo?
--- ENVIADO AL LLM ---
[system] Eres un asistente experto en Machine Learning. Responde en español de España, breve y claro con respuestas de menos de 30 palabras.
[human] ¿Qué es el aprendizaje supervisado?
[ai] Aprende de datos etiquetados (pares entrada-salida) para predecir resultados o clasificar nuevos datos. Busca una función que mapee la entrada a la salida.
[human] ¿Qué es un modelo?
--- RESPUESTA ---
Es la función o algoritmo entrenado con datos que predice o clasifica. Representa el conocimiento extraído del aprendizaje.
Tú: ¿Y entrenar el modelo qué significa?
--- ENVIADO AL LLM ---
[system] Eres un asistente experto en Machine Learning. Responde en español de España, breve y claro con respuestas de menos de 30 palabras.
[human] ¿Qué es el aprendizaje supervisado?
[ai] Aprende de datos etiquetados (pares entrada-salida) para predecir resultados o clasificar nuevos datos. Busca una función que mapee la entrada a la salida.
[human] ¿Qué es un modelo?
[ai] Es la función o algoritmo entrenado con datos que predice o clasifica. Representa el conocimiento extraído del aprendizaje.
[human] ¿Y entrenar el modelo qué significa?
--- RESPUESTA ---
Significa ajustar sus parámetros internos usando datos para que aprenda patrones y haga predicciones o clasificaciones precisas.
Tú: ¿Qué es el overfiting?
--- ENVIADO AL LLM ---
[system] Eres un asistente experto en Machine Learning. Responde en español de España, breve y claro con respuestas de menos de 30 palabras.
[human] ¿Qué es el aprendizaje supervisado?
[ai] Aprende de datos etiquetados (pares entrada-salida) para predecir resultados o clasificar nuevos datos. Busca una función que mapee la entrada a la salida.
[human] ¿Qué es un modelo?
[ai] Es la función o algoritmo entrenado con datos que predice o clasifica. Representa el conocimiento extraído del aprendizaje.
[human] ¿Y entrenar el modelo qué significa?
[ai] Significa ajustar sus parámetros internos usando datos para que aprenda patrones y haga predicciones o clasificaciones precisas.
[human] ¿Qué es el overfiting?
--- RESPUESTA ---
El modelo se ajusta excesivamente a los datos de entrenamiento, perdiendo capacidad de generalizar a datos no vistos y haciendo malas predicciones.
