¿Que es el Clustering?
- Este post forma parte del libro "Machine Learning (en Python), con ejemplos"
El Clustering es una tarea que consiste en agrupar un conjunto de objetos (no etiquetados) en subconjuntos de objetos llamados Clusters. Cada Cluster está formado por una colección de objetos que son similares (o se consideran similares) entre sí, pero que son distintos respecto a los objetos de otros Clusters.
En el campo del ML, el Clustering se enmarca dentro del aprendizaje no supervisado; es decir, que para esta técnica solo disponemos de un conjunto de datos de entrada, sobre los que debemos obtener información sobre la estructura del dominio de salida, que es una información de la cual no se dispone.
Es importante no confundir el Clustering con los problemas de Clasificación. Las técnicas de Clasificación se enmarcan dentro del aprendizaje supervisado porque para cada dato tenemos información sobre sus variables de entrada y de salida; es decir, cada dato u objeto esta etiquetado. Sin embargo para aquellos casos en los que no disponemos de la salida de cada dato y queramos agrupar estos objetos en grupos similares, debemos de aplicar alguna de las técnicas de Clustering para saber la procedencia de estos datos.
Supongamos el siguiente caso de ejemplo: Tenemos un data set (DS1) con el color de pelo de un conjunto de personas. Como entrada tenemos el color en RGB del pelo de cada persona y como salida un conjunto finito de etiquetas {Moreno, Rubio, Castaño, Canoso}. Por otro lado tenemos otro data set (DS2) con el color del pelo en RBG de otro conjunto de personas, pero en este caso no tenemos como salida una etiqueta que nos diga si el individuo es Moreno, Rubio, Castaño o Canoso. Para ambos casos queremos generar un modelo que nos permita etiquetar a nuevas personas en Morenos, Rubios, etc. ¿Cómo abordaríamos este problema para el DS1 y DS2?.
- DS1: El primer caso se trata de un problema de clasificación, ya que para cada individuo tenemos su color de pelo en RGB y su clasificación correspondiente {Moreno, Rubio, Castaño, Canoso}. Para este caso debemos de obtener una función (o hipótesis) en base a los datos de entrenamiento para que a cada nueva entrada (color del pelo en RGB) lo etiquete de forma correcta:
f(x=color)={Moreno,Rubio,Castaño,Canoso}
- DS2: El segundo caso se trata de un ejemplo claro de Clusterización, ya que tenemos que obtener información sobre su estructura o dominio de salida en base a los datos del color de pelo que tenemos en el data set. Para ello debemos de utilizar alguna de las técnicas de Clustering e indicarle que nos agrupe todos los datos en 4 Clusters. Una vez hecha esta Clusterización podremos identificar que individuos son Morenos, Rubios, Castaños o Canosos viendo solamente el valor medio (o Centroide) de cada Cluster. Un ejemplo de Clusterización de este data set visto en 2D sería el siguiente:
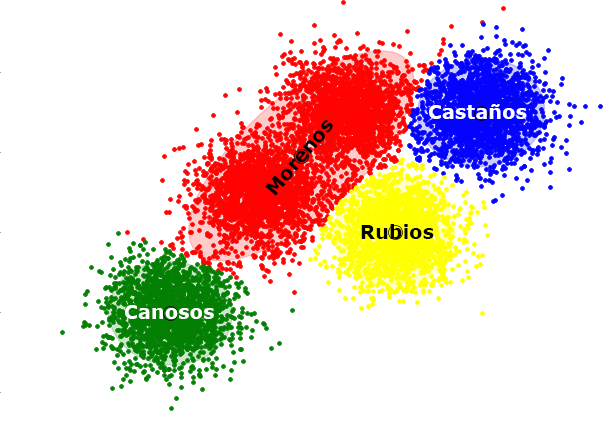
En este ejemplo podemos apreciar como nos divide los individuos en 4 grupos, en función de su color de pelo y como podemos ser capaces posteriormente de identificar y etiquetar a cada grupo de personas.
Este ejemplo propuesto, es un ejemplo muy sencillo y didáctico para ver la diferencia entre las tareas de Clasificación y de Clustering; para dejar muy claro, que la primera se enmarca dentro del aprendizaje supervisado y la segunda en el aprendizaje no supervisado. Para los casos prácticos en los que hay que aplicar técnicas de Clustering no solemos tener información a priori sobre los datos a analizar ni información sobre los modelos que han generado estos datos. En el ejemplo propuesto hemos asumido que solo tendríamos personas con estos cuatro tipos de pelo y no sabemos si habría personas con el pelo teñido de color azul, verde, etc. lo que supondría haber realizado una tarea de Clustering poco acertada ya que posiblemente agruparía en Clusters diferentes a personas consideradas Morenas o asumiría que las personas Castañas y Rubias pertenecerían al mismo Cluster.
En resumen, las técnicas de Clustering son apropiadas para los casos de aprendizaje no supervisado en los que se quiere agrupar y tener conocimiento a un alto nivel de cómo se han generado los datos y como están organizados, sin tener conocimiento a priori de estos.

La diferencia entre clasificación y agrupamiento está, como dices, en el hecho de que en la clasificación conocemos la respuesta correcta. Por tanto se convierte en aprendizaje supervisado. Así, las técnicas de machine learning de clasificación pueden aprender qué atributos son relevantes.
En el caso del clustering, como no hay ninguna respuesta correcta, la responsabilidad de elegir atributos que tengan sentido para agruparlos recae sobre nosotros.
Excelente explicación !
gracias por el aporte, muy bueno tu libro.