Scraping en Python (BeautifulSoup), con ejemplos
El proyecto de este post los puedes descargar pulsando AQUI.
El Web Scraping (o Scraping) son un conjunto de técnicas que se utilizan para obtener de forma automática el contenido que hay en páginas web a través de su código HTML. El uso de estas técnicas tienen como finalidad recopilar grandes cantidades de datos de diferentes páginas web cuyo uso posterior puede ser muy variado: homgenización de datos, tratamiento de contenido para la extracción de conocimiento, complementar datos en una web, etc. Decir por último en esta introducción que las técnicas de Scraping se pueden enmarcar dentro de los campos de la Inteligencia Artificial y del Big Data en la primera fase de recolección de datos para su posterior almacenamiento, tratamiento y visualización.
En este tutorial vamos ha "scrapear" (o a obtener los datos) de los articulos y tutoriales de esta página web, utilizando la librería "BeautifulSoup" (para Python) que es una libreria que nos facilita muchisimo la labor de scrapeo. La finalidad de este tutorial no es hacer un tutorial para expertos, sino hacer una introducción de como hacer las conexiones HTTP y como tratar y extraer el contenido que nos interesa de los HTMLs que obtenemos con la libreria JSoup. Para este tutorial es necesario que se tengan conocimientos mínimos de HTML y CSS (no hace falta ser un experto) ya que a la hora de scrapear tenemos que tener conocimiento de las etiquetas de HTML como pueden ser head, body, h1, h2, …, h6, p, div, span, table, etc. y de los estilos CSS que se pueden aplicar a estas etiquetas con id y class.
Dadas las directrices y los conocimientos mínimos necesarios para este tutorial vamos a proceder a explicar como scrapear y obtener los datos de las entradas de jarroba.com. En primer lugar deberemos de hacer un "pip install" para descargarnos e instalar los paquetes de 'request' y 'beautifulsoup':
$ pip install beautifulsoup4 $ pip install requests
En segundo lugar, se ha de estudiar la estructura del HTML de la web para ver de que forma podemos extaer su contenido. En este caso en el que queremos extraer la información de cada entrada de este web (título, autor y fecha), podemos ver como todas las entradas están entre etiquetas 'div' con la clase CSS 'col-md-4 col-xs-12'; es decir (tal y como vemos en la siguiente imagen), debemos de obtener el contenido que hay entre "<div class="col-md-4 col-xs-12"> contenido </div>"
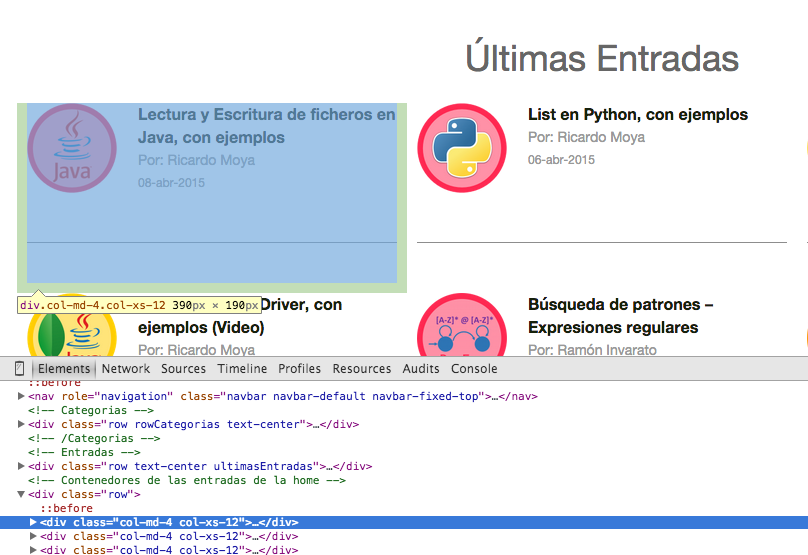
Como podemos ver, puede resultar relativamente sencillo crearse una expresión regular y obtener todas las apareciones que hay entre las etiquetas 'div' con la clase CSS mencionada anteriormente (por cierto son clases de CSS Bootstrap), pero la libreria BeautifulSoup ya nos aporta los métodos necesarios (y muy bien optimizados ya que el Patter y Matcher son procesos muy pesados y lentos) para obtener el contenido que hay entre las etiquetas HTML.
Dentro de esas etiquetas, tenemos que seguir extrayendo los datos del título, autor y fecha. Si vemos más en detalle su HTML, vemos lo siguiente:

Por tanto con esto ya hemos hecho un estudio del HTML y ya sabemos a partir de que etiquetas tenemos que scrapear los datos, por tanto vamos a pasar ahora a explicar como hacer el scrapeo con la libreria BeautifulSoup de python, utilizando también la libreria request para hacer la petición http.
En primer lugar tenemos que hacer una petición HTTP a la página web para obtener su HTML. Para ello utilizaremos la libreria 'request' y utilizando el método get (pasandole como parámetro la url) nos dará entre otras cosas el HTML de la web y su "Status Code". Esto lo hacemos de la siguiente forma:
url = "https://jarroba.com/" # Realizamos la petición a la web req = requests.get(url)
A partir del objeto "req", que almacena mucho datos relacionados con la petición HTTP (cabeceras, cookies, etc.) obtenemos el Status Code y el HTML (como un string) de la web. Esto lo hacemos de la siguiente forma:
statusCode = req.status_code htmlText = req.text
Con el Status Code y con el HTML de la web, ya podemos empezar a scrapear la web. A continuación (y hecho ya el estudio del HTML de la web y como obtener el HTML y su Status Code) se muestra todo el código y posteriormente se explicará paso a paso, para que tengáis un visión más general:
# -*- coding: utf-8 -*-
__author__ = 'RicardoMoya'
from bs4 import BeautifulSoup
import requests
URL = "http://jarroba.com/"
# Realizamos la petición a la web
req = requests.get(URL)
# Comprobamos que la petición nos devuelve un Status Code = 200
status_code = req.status_code
if status_code == 200:
# Pasamos el contenido HTML de la web a un objeto BeautifulSoup()
html = BeautifulSoup(req.text, "html.parser")
# Obtenemos todos los divs donde están las entradas
entradas = html.find_all('div', {'class': 'col-md-4 col-xs-12'})
# Recorremos todas las entradas para extraer el título, autor y fecha
for i, entrada in enumerate(entradas):
# Con el método "getText()" no nos devuelve el HTML
titulo = entrada.find('span', {'class': 'tituloPost'}).getText()
# Sino llamamos al método "getText()" nos devuelve también el HTML
autor = entrada.find('span', {'class': 'autor'})
fecha = entrada.find('span', {'class': 'fecha'}).getText()
# Imprimo el Título, Autor y Fecha de las entradas
print "%d - %s | %s | %s" % (i + 1, titulo, autor, fecha)
else:
print "Status Code %d" % status_code
En primer lugar definimos la url para obtener el Status Code y el HTML. En segundo lugar comprobamos que el "status code" es igual a 200 y si es así obtenemos en un objeto de la clase "BeautifulSoup", pasándole el HTML de la web. Con ese objeto, vamos a poder obtener con los métodos pertinentes los elementos de la web. En este caso vamos a obtener todas las entradas que las guardaremos en una lista que corresponda a una serie de etiquetas y estilos CSS. En este caso guardaremos todos los fragmentos HTML que correspondan a cada entrada (ver primer imagen de la entrada):
# Pasamos el contenido HTML de la web a un objeto BeautifulSoup()
html = BeautifulSoup(req.text, "html.parser")
# Obtenemos todos los divs donde estan las entradas
entradas = html.find_all('div',{'class':'col-md-4 col-xs-12'})
En este caso utilizamos el método "find_all()" que lo que hace es coger todos los fragmentos del HTML que correpondan a una etiqueta div, seguido de las clases 'col-md-4' y 'col-xs-12'. Ahora ya tenemos en una lista (entradas), todas las entradas en HTML. Ahora debemos de recorrer esa lista y obtener de esos fragmentos de código los datos del título, autor y fecha. De la misma forma esa información esta dentro de etiquetas HTML y clases CSS que debemos de tratar (como se muestra en la segunda imagen de la entrada). BeautifulSoup nos da los métodos para obtener el contenido pasandole el nombre de la clase CSS. Esto se hace de la siguiente forma:
# Recorremos todas las entradas para extraer el título, autor y fecha
for i,entrada in enumerate(entradas):
# Con el método "getText()" no nos devuelve el HTML
titulo = entrada.find('span', {'class' : 'tituloPost'}).getText()
# Sino llamamos al método "getText()" nos devuelve también el HTML
autor = entrada.find('span', {'class' : 'autor'})
fecha = entrada.find('span', {'class' : 'fecha'}).getText()
# Imprimo el Título, Autor y Fecha de las entradas
print "%d - %s | %s | %s" %(i+1,titulo,autor,fecha)
Como vemos a los métodos "find()" se les pasa el nombre de la clase CSS y te obtiene el contenido que hay entre esas etiquetas. Por último señalar lo que dejo en el comentario del fragmento de código anterior, que si no se utiliza el método "getText()", se muestra también el contenido HTML, mientras que si lo utilizamos, solo mostramos el contenido que hay entre las etiquetas HTML. Como resultado de la ejecución del programa tenemos lo siguiente:
1 - Arquitectura Android – ART vs Dalvik | Por: Ramón Invarato | 17-may-2015 2 - Scraping en Java (JSoup), con ejemplos | Por: Ricardo Moya | 12-may-2015 3 - Diccionario en python, con ejemplos | Por: Ricardo Moya | 05-may-2015 4 - DataSet de resultados de partidos de fútbol para su predicción (Machine Learning) | Por: Ricardo Moya | 26-abr-2015 5 - Intalar Ubuntu en una máquina virtual con VirtualBox (Video) | Por: Ricardo Moya | 15-abr-2015 6 - Lectura y Escritura de ficheros en Java, con ejemplos | Por: Ricardo Moya | 08-abr-2015 7 - List en Python, con ejemplos | Por: Ricardo Moya | 06-abr-2015 8 - Python MongoDB Driver (pymongo), con ejemplos (Video) | Por: Ricardo Moya | 23-mar-2015 9 - Java MongoDB Driver, con ejemplos (Video) | Por: Ricardo Moya | 18-mar-2015
Esta libreria BeautifulSoup, es una libreria muy potente para hacer scraping. En esta entrada hemos visto como hacer una conexión HTTP y obtener el contenido HTML para almacenarlos en una lista para posteriormente sacar elementos o fragmentos de código HTML (find() o find_all()) como si de un parseo con expresiones regulares se tratase pero sin meterse en el "engorro" de trabajar con expresiones regulares. BeautifulSoup también tiene métodos para sacar el contenido de etiquetas como los h1, h2, …, p, img, etc. que en este caso no hemos visto en el ejemplo pero que si revisais su documentación veréis los métodos que permiten hacer esas acciones.
Para terminar dejo el programa que permite obtener todas las entradas de Jarroba.com (título, autor y fecha) y no solo los de la página principal como en el ejmplo mostrado:
# -*- coding: utf-8 -*-
__author__ = 'RicardoMoya'
from bs4 import BeautifulSoup
import requests
URL_BASE = "http://jarroba.com/"
MAX_PAGES = 20
counter = 0
for i in range(1, MAX_PAGES):
# Construyo la URL
if i > 1:
url = "%spage/%d/" % (URL_BASE, i)
else:
url = URL_BASE
# Realizamos la petición a la web
req = requests.get(url)
# Comprobamos que la petición nos devuelve un Status Code = 200
statusCode = req.status_code
if statusCode == 200:
# Pasamos el contenido HTML de la web a un objeto BeautifulSoup()
html = BeautifulSoup(req.text, "html.parser")
# Obtenemos todos los divs donde estan las entradas
entradas = html.find_all('div', {'class': 'col-md-4 col-xs-12'})
# Recorremos todas las entradas para extraer el título, autor y fecha
for entrada in entradas:
counter += 1
titulo = entrada.find('span', {'class': 'tituloPost'}).getText()
autor = entrada.find('span', {'class': 'autor'}).getText()
fecha = entrada.find('span', {'class': 'fecha'}).getText()
# Imprimo el Título, Autor y Fecha de las entradas
print "%d - %s | %s | %s" % (counter, titulo, autor, fecha)
else:
# Si ya no existe la página y me da un 400
break

Estimado como obtengo este dato 2,36923, dos datos obtuve con tu excelente código, pero no como obtener este que está dentro de una tabla, de antemano muchas gracias
Bs2,36923 por unidad de UFV
Buenas Luis.
Para las tablas tendrás que jugar con las etiquetas tr, td, th.
Quizás tengas que utilizar alguna expresión regular (tienes un ejemplo en la respuesta de https://jarroba.com/foro/1856/sumar-datos-especifico-de-un-diccionario)
Muchas gracias Ramón, reviso el link , saludos.
Hola Richard:
Felicidades muy buen ejemplo mismo que me ayudó a scrapear el tipo de cambio, pero no se como obtener un dato que estadentro de una tabla:
Bs
10.1256
ABC
De antemano muchas gracias.
Hola una ayudita , soy nuevo en programacion intento hacer un scraping con BeautifulSoup pero no me sale este es el codigo que hice pero cuando lo ejecuto me sale en blanco o sea solo sale Nombres y Puntos , y me pone Empty data passed with indices specified:
from bs4 import BeautifulSoup import requests import pandas as pd url = 'https://resultados.as.com/resultados/futbol/primera/clasificacion/' page = requests.get(url) soup = BeautifulSoup(page.content, 'html.parser') #Equipos eq = soup.find_all('span', class_='nombre-equipo') equipos = list() count = 0 for i in eq: if count < 20: equipos.append(i.text) else: break count += 1 #Puntos pt = soup.find_all('td', class_='destacados') puntos = list() count = 0 for i in pt: if count < 20: puntos.append(i.text) else: break count += 1 df = pd.DataFrame({'Nombres': equipos,'Puntos': puntos}, index=list(range(1,21))) df.to_csv('Clasificacion', index=False)Buenas Giraldo.
No te encuentra «soup.find_all» la clase «destacados», pues no existe en el HTML que has descargado. Sugiero que eches un vistazo a «page.content» y busca el nombre de la clase que quieras obtener la información (al igual que has hecho con la clase «nombre-equipo», la cual sí tiene información).
Hola y si lo que quiero capturar del sitio web son las clases css de cada elemento? como haria por ejemplo si quiero saber que clases tienen los elementos h1 del documento html como las capturo?
H1 es un elemento de HTML, lo puedes capturar y seleccionar su clase con:
capturado = html.find('h1', {'class' : 'nombre-clase'})Hola,
Estoy intentado trastear con esta librería y al realizar una petición sobre una web me parece el siguiente output:
NOMBRE DE LA WEB QUE OMITO PARA REALIZAR LA PREGUNTAwindow.__pageLoadedTime=Date.now()You need to enable JavaScript to run this app.
¿Esto por qué es? ¿Tendría que descargarme Eclipse o plataformas similares para hacerlo en Java/Javascript?
El código lo he ejecutado desde jupyter lab (ANACONDA) con la última versión actualizada de Python.
¿Podrían darme unas pautas para intentar llegar a la solución?
Un saludo, muy buena web y gracias por la ayuda
Vuelvo a subir el output:
///!DOCTYPE html
///html lang=»en»>NOMBRE DE LA WEB QUE OMITO PARA REALIZAR LA PREGUNTAwindow.__pageLoadedTime=Date.now()You need to enable JavaScript to run this app.</html
A ver si ahora si consigo que el output salga bien…
///
//////NOMBRE DE LA WEB ///QUE OMITO PARA REALIZAR LA PREGUNTAwindow.__pageLoadedTime=Date.now()You need to enable JavaScript to run this app.
Si el error te sale al instalar beautifulsoup4 y request comprueba que no estés detrás de un proxy, sino puede que la web que quieras acceder devuelva dicho error.
Buenas tardes. Estoy iniciandome en esto del scraping y ya he podido hacer el print de titulo, autor, fecha tal como comentas en el ejemplo de jarroba. Me gustaría saber como extraerlo todo a un excel, he probado a hacerlo con panda y solo se guarda la última entrada, la 9. Podrías guiarme de como hacer que se guarde todo eso que ha salido en el print? Gracias, es muy útil todo lo que explicas.
Buenas.
Para trabajar con Excel en Python existe la biblioteca openpyxl externa que facilitan la tarea.
como seria para extraer videos de una web?
Podrías obtener los vídeos directamente a ficheros con request:
import requests
from pathlib import Path
# Obtener los datos desde una Web
url = 'https://www.paginaweb.com/rutaalvideo/video.avi'
datos_del_get = requests.get(url)
# Guardar el fichero en disco
ruta_hasta_el_fichero_a_guardar = Path("/ruta/hasta/el/fichero/video_descargado.avi")
open(str(ruta_hasta_el_fichero_a_guardar), 'wb').write(datos_del_get.content)
Hola , solo comentar que en esta linea: autor = entrada.find(‘span’, {‘class’ : ‘autor’}) , falta el valor de .getText(), quedando asi: autor = entrada.find(‘span’, {‘class’: ‘autor’}).getText() | esto con el objetivo de que no aparezca el span class literalmente en la salida.
Excelente página…. Muchas gracias por compartir.
Hola Ricardo
el ejercicio me salio perfecto…!!!
pero si quisiera obtener los 166 artículos de Jarroba como haría?
le pondría un while como en php o se trabajaría directamente con la paginación?
también estoy buscando obtener la url de cada uno de los artículos,
agradecería puedas brindarme algunos tips para poder lograrlo, gracias !!!!
Estimado Ricardo, estoy trabajando en un proyecto para scrapear los datos de la tabla «Resultados» del siguiente enlace:
https://app.powerbi.com/view?r=eyJrIjoiMGY2YThlZjctMmEyMy00Nzc3LWFmZWItMTkyNzhjOWY1YmQwIiwidCI6IjkwNTdiNGRiLWNiNDctNDc0NC05YzBkLTQxMTVhMzBiMDRiYiIsImMiOjR9
Es un trabajo hecho en PowerBI, y me gustaría que me puedas ayudar o por lo menos decirme si es posible hacerlo con Python y BeautifulSoup.
Muchísimas gracias.
¿Que utilidad tiene la librería urllib?. En teoría BeautifulSoup tiene todos los elementos necesarios para manejar paginas web. Y en la practica he probado con «req = requests.get(url)» y con la url directamente , obteniendo los mismos resultados. Como es la primera vez que hago esto, gracias a este tutorial, no se si ha sido cuestión de suerte.
Lo que he aprendido aqui lo he aplicado a obtener las url de imagenes de una web, bajo la clase «cycles». Pongo el ejemplo por si a alguien le interesa:
url=’http://www.loquesea.es»
html = BeautifulSoup(url, «html.parser»)
imagenes=clase.find_all(‘img’)
for a in imagenes:
img=a[‘src’]
print(img)
Perdón,omití una linea del código, la que hace referencia a la clase. Lo pongo otra vez completo:
url=’http://www.loquesea.es”
#
html = BeautifulSoup(url, “html.parser”)
clase = html .find(‘div’,{‘class’: ‘cycles’}) # busca una sola ocurrencia
imagenes=clase.find_all(‘img’) # busca todas las ocurrencias
for a in imagenes: # recorre la lista
img=a[‘src’] # saca la url
print(img)
El código se puede compactar más, por ejemplo:
imagenes= html .find(‘div’,{‘class’: ‘cycles’}).find_all(‘img’),
Pero asi queda mas claro.
Hola, buenas tardes! Lo primero es agradecer el presente tutorial, resulta muy útil de cara a obtener datos desde páginas web que lo ponen un poco "difícil" al usuario.
He puesto este tutorial en práctica para intentar hacer scraping en la web de Red Eléctrica de España (https://demanda.ree.es/movil/peninsula/demanda/tablas/1). La diferencia con lo que se explica aquí, es que el protcolo al que se atiene dicha web no es http, sino https. El resultado es que al aplicar:
html = BeautifulSoup(req.text, "lxml")
No obtengo el código html, sino el código java. Luego, al continuar con:
filas = html.find('table', {'id': 'tabla_evolucion'}).find_all('tr')
fecha = filas[1].find_all('td')[0].getText()
Resulta en el siguiente error:
AttributeError: 'NoneType' object has no attribute 'find_all'
Entiendo que la razón del error se debe a que estoy obteniendo el código Java y, por lo tanto, al buscar 'table' no estoy obteniendo nada. Entonces, ¿cómo puedo resolver este problema? Pongo a continuación el código entero por si sirviese de ayuda.
Saludos y gracias de antemano.
from bs4 import BeautifulSoup
import requests
url = "https://demanda.ree.es/movil/peninsula/demanda/tablas/1"
req = requests.get(url)
statusCode= req.status_code
if statusCode == 200:
html = BeautifulSoup(req.text, "lxml")
filas = html.find('table', {'id': 'tabla_evolucion'}).find_all('tr')
fecha = filas[1].find_all('td')[0].getText()
Hola amigos.
Estoy intentando usar el scraping para obtener una información muy sencilla de una URL pero el programa no me pasa de
>>> req = requests.get(url) me arroja lo siguiente: NameError: name 'requests' is not defined.
— o—
>>> url = "https://jarroba.com/"
>>> req = requests.get(url)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
NameError: name 'requests' is not defined
— 0 —
Nota: en teoria ya instale " install requests" a travez del terminal. Mi version de python es 2.7.10
que estoy haciendo mal?
Hola Edwin, es un problema de reconocimiento del módulo, revise el import requests.
Un saludo,
Buenas noches… por favor una ayudita!!!
Estoy intentando extraer las propiedades de una sustancia de una base de datos y se me ha dificultado mucho; tiene algunas variantes.
Me podrias ayudar Ricardo? Quiero obtener la tempratura critica del Metano, como hago?. El link es: https://www.cheric.org/research/kdb/hcprop/showprop.php?cmpid=1
Si de algo sirve… el codigo que estaba armando era:
url = 'https://www.cheric.org/research/kdb/hcprop/showprop.php?cmpid=1'
req = requests.get(url)
statusCode = req.status_code
if statusCode == 200:
html = BeautifulSoup(req.text, "lxml")
entradas = html.find_all('table',{'class':'table table-condensed'}) #Cada una de las tablas
for i,entrada in enumerate(entradas):
titulo = entrada.find('tbody').getText()
print "%d – %s" %(i+1,titulo)
else:
print "Status Code %d" %statusCode
Supongo que ya lo habras resuelto, pero si no es asi:
estas recorriendo todas las tablas cuando a ti solo te interesa la primera, es decir entradas[0], llamala tabla, asi:
tabla=entradas[0] a continuacion en tabla buscas los <td>
datos=tabla.find_all('td') y el 12 es tu valor, por si quieres ver todos haz un for asi:
for i in range(0,len(datos),2):
print(datos[i].getText()+" "+datos[i+1].getText)
Espero que te sea de utilidad. Salud.
No funciona 🙁
Ricardo, podrías actualizar el artículo?
Hola Carlos.
Me funciona el código perfectamente. Lo que si es cierto que me salia un warning para que indicase al objeto de BeautifulSoup que lo parsease como un html (lo indico abajo) pero el código funciona correctamente. Recuerdo que yo utilizo siempre la versión 2.X de python no la versión 3.X. Igual es por eso por lo que no te funciona
Hola Ricardo soy nuevo en la programación , estoy aprendiendo python y he buscado por Internet pero no encuentro ejemplos de como usar BeautifulSoup con orientación a objetos, y quería preguntarte si tendrías algún ejemplo de como scraping con orientación a objetos.
Hola ricardo, estoy trabajando con python la parte de scraping, pero tengo problemas con paginas que son solo javascript y al momento de buscar un div no lo esta encontrando debido a que cuando hago el request de la pagina me retorna un monton de scripts, que podria hacer en este caso?
hola. estoy aprendiendo y cuanto trato de correr el codigo me sale
File "C:\Users\MANUEL\Desktop\python2\hackers\informacion de toda una web.py", line 40
print "%d – %s | %s | %s" %(counter,titulo,autor,fecha)
tendras idea porque?
Puede que sea por el tipo de la variable «counter», mira que sea de tipo número (lo pide el %d), o si es string la puedes convertir con: int(counter)
Puede que sea un problema de la codificación de caracteres en python. Prueba a poner en la segunda línea del fichero «# -*- coding: utf-8 -*-«. Un ejemplo de la cabecera del fichero:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
También puedes probar con el método encode():
variable_texto = «mi texto».encode(«utf-8»)
Ricardo,
de verdad muchas gracias, con esto puedo dar casi por terminado el software de mi proyecto y parece que compila correctamente. Te agradezco también la explicación detallada que me ha hecho darme cuenta de mis errores y entender mejor el scraping (aunque como tu bien has deducido, no tengo ninguna soltura con este código).
Sólo te rogaría me aclarases una cosa más: tanto si compilo el programa para todas las estaciones (estrictamente el código que te has currado) como si lo hago para una sóla estación (modificado por mi), me da el siguiente error:
/Library/Frameworks/Python.framework/Versions/2.7/bin/python2.7 /Users/rafaelayuso/PycharmProjects/datosweb/DatosWeb3_Jarroba_AllEstaciones.py
URL: http://www.juntadeandalucia.es/agriculturaypesca/ifapa/ria/servlet/FrontController?action=Static&url=datosDiarios.jsp&c_provincia=4&c_estacion=1
/Library/Frameworks/Python.framework/Versions/2.7/lib/python2.7/site-packages/bs4/__init__.py:166: UserWarning: No parser was explicitly specified, so I'm using the best available HTML parser for this system ("html.parser"). This usually isn't a problem, but if you run this code on another system, or in a different virtual environment, it may use a different parser and behave differently.
To get rid of this warning, change this:
BeautifulSoup([your markup])
to this:
BeautifulSoup([your markup], "html.parser")
markup_type=markup_type))
No existe esta estacion
URL: http://www.juntadeandalucia.es/agriculturaypesca/ifapa/ria/servlet/FrontController?action=Static&url=datosDiarios.jsp&c_provincia=11&c_estacion=1
No existe esta estacion
URL: http://www.juntadeandalucia.es/agriculturaypesca/ifapa/ria/servlet/FrontController?action=Static&url=datosDiarios.jsp&c_provincia=14&c_estacion=1
No existe esta estacion
URL: http://www.juntadeandalucia.es/agriculturaypesca/ifapa/ria/servlet/FrontController?action=Static&url=datosDiarios.jsp&c_provincia=18&c_estacion=1
No existe esta estacion
URL: http://www.juntadeandalucia.es/agriculturaypesca/ifapa/ria/servlet/FrontController?action=Static&url=datosDiarios.jsp&c_provincia=21&c_estacion=1
No existe esta estacion
URL: http://www.juntadeandalucia.es/agriculturaypesca/ifapa/ria/servlet/FrontController?action=Static&url=datosDiarios.jsp&c_provincia=23&c_estacion=1
No existe esta estacion
URL: http://www.juntadeandalucia.es/agriculturaypesca/ifapa/ria/servlet/FrontController?action=Static&url=datosDiarios.jsp&c_provincia=29&c_estacion=1
No existe esta estacion
URL: http://www.juntadeandalucia.es/agriculturaypesca/ifapa/ria/servlet/FrontController?action=Static&url=datosDiarios.jsp&c_provincia=41&c_estacion=1
No existe esta estacion
Process finished with exit code 0
No se cual es el html.parser que debo indicarle ni a que se debe este problema. ¿Quizás sea por que estoy compilando en un Mac? Por favor, ilustrame, imágino que si ya has llegado hasta aquí no te importará darme un último empujón.
Gracias de antemano,
Un saludo!
Disculpa Ricardo, olvidaba comentarte que al añadir a la línea:
html = BeautifulSoup(req.text,"html.parser")
ya me compila sin darme ese error pero me sigue indicando:
URL: http://www.juntadeandalucia.es/agriculturaypesca/ifapa/ria/servlet/FrontController?action=Static&url=datosDiarios.jsp&c_provincia=41&c_estacion=5
No existe esta estacion
Process finished with exit code 0
y no me muestra los valores deseados.
Gracias y disculpa mi pesadez.
Hola Rafael.
No consigo reproducir tu error. Por lo que he visto por internet debe ser un error del encode, pero arriba del todo del codigo especifico claramente que sea en utf-8 «# -*- coding: utf-8 -*-«, por lo que deduzco que el problema viene de la configuración de tu IDE.
El problema es que al leer el contenido de la web detecta una excepción en la obtención del contenido y por eso ejecuta la excepción:
except: print "No existe esta estación" breakPrueba a ejecutar el script desde un terminal poniendo «python ./nombreDelScript.py» a ver si te funciona.
Más que esto no te puedo decir ya que es un error de tu entorno y no de código, pero busca algo en el IDE de encode, decode, coding, «IDE Encoding», «Project Encoding» o algo así y pon la opcion de utf-8 a ver si así te funciona.
SL2
Estimado Ricardo,
gracias por el post, resulta muy útil para los que necesitamos apoyo en nuestras labores de programación.
Estoy desarrollando un proyecto personal que engloba eléctrónica, automatización y obviamente programación de un software de tipo científico. Para ello necesito obtener datos diarios de estaciones agroclimáticas (para este ejemplo concreto: estación de Santaella, link adjunto) que están disponibles en una página de la Junta de Andalucía: https://www.juntadeandalucia.es/agriculturaypesca/ifapa/ria/servlet/FrontController?action=Static&url=datosDiarios.jsp&c_provincia=14&c_estacion=7.
He seguido tus enseñanzas de cara a obtener el dato de ETo que es el que me interesa y hacerlo de forma automatizada para tener cada día el dato disponible en mi programa Python pero no me está funcionando bien y no consigo saber qué, por lo que te rogaría me echases una mano.
El código que he escrito, a imagen y semejanza del tuyo, es el siguiente:
# -*- coding: utf-8 -*- from bs4 import BeautifulSoup import requests urlBase = "http://www.juntadeandalucia.es/agriculturaypesca/ifapa/ria/servlet/" maxPages = 20 counter = 0 for i in range(1, maxPages): if i > 1: url = "FrontController?action=Static&url=datosDiarios.jsp&c_provincia=14&c_estacion=7" % (urlBase, i) else: url = urlBase req = requests.get(url) statusCode = req.status_code if statusCode == 200: html = BeautifulSoup(req.text) entradas = html.find_all('div', {'id': 'recordcontent'}) for entrada in entradas: counter += 1 ETo = entrada.find('td', {'class': 'textoCampo'}).getText() print "%d – %s" % (counter, ETo) else: breakEl extracto del código html que nos atañe de la página de la Junta de andalucía es el siguiente (puedes consultarlo en el link adjunto):
<tr>
<td class="tituloCampo">Temp. Media (ºC)</td>
<td class="textoCampo">17.8</td>
<td class="tituloCampo">ETo (mm/dia)</td>
<td class="textoCampo">1.95</td>
</tr>
No se si el problema esta en la fracción que hago en la asignación de urlBase y url pero en caso de tener que poner toda la dirección en urlBase PyCharm no me deja porque se superan los 120 caracteres máximos. Por otro lado no sé si los argumentos del código html que incluyo en la programación son las correctas. Por lo demás no sé dónde puede existir algún problema.
Comentarte que al compilar en PyCharm no me da error en ninguna línea, simplemente me dice "Process finished with exit code 1"
Cualquier ayuda que puedas brindarme te estaré enormemente agradecido.
Un saludo!
Hola Rafa.
No solemos responder a este tipo de comentarios en los que nos planteáis un problema para que lo resolvamos ya que siempre nos lo piden estudiantes para que les hagamos las practicas o empresas que no les apetece abordar el problema y que nos lo pasan para ver si cuela, pero dado que tu caso trata sobre un proyecto personal, accedo a ayudarte.
Por el código que me pasas veo que no tienes mucha soltura en el tema del scraping ya que has intentado adaptar el código de este tutorial a tu problema en concreto que se debe de resolver de forma diferente. Por lo que veo, la web que me pasas tiene informacion de una serie de estaciones que las enumera en la url con "c_estacion=X" y que las divide por las provincias Andaluzas, las cuales tienen un código (4=Almeria; 11=Cadiz; …..; 41=Sevilla) que también va en la peticion por la URL "c_provincia=X". Dado que tienes estas dos variable y si quieres obtener los valores de todas las estaciones Andaluzas, debes de formar la URL de forma correcta para obtener los datos y así es como lo hago en el código que te paso más abajo.
Por otro lado una vez formada la url, accedes a descargar el código HTML para parsearlo, y debes de parsear en concreto una tabla que puede ser un poco compleja de parsear, ya que debes de ir elemeno a elemento para obtener la informacion y no a traves de clases css.
En resumen, te paso un script que te obtiene la informacion del ETo diario y Acumulado de todas las estaciones de todas las provincias Andaluzas. En el caso de que solo quisieses los datos de la estacion que me pasas, puedes quitar los bucles 'for' y poner la variable 'url' con la url completa; es decir, la urlBase mas la url que tu has definido como "FrontController?action=Static&url=datosDiarios.jsp&c_provincia=14&c_estacion=7":
# -*- coding: utf-8 -*- __author__ = 'Richard' from bs4 import BeautifulSoup import requests urlBase = "http://www.juntadeandalucia.es/agriculturaypesca/ifapa/ria/servlet/" urlProvEstacion = "FrontController?action=Static&url=datosDiarios.jsp&c_provincia=%d&c_estacion=%d" # Lista con los ids de las provincias 4=Almeria; 11=Cadiz; .....; 41=Sevilla provincias = [4, 11, 14, 18, 21, 23, 29, 41] # Número máximo de estaciones que vamos a ver por provincia maxEstaciones = 30 # Formamos las URLs a partir de las provincias y numero de estaciones: for prov in provincias: for est in range(1,maxEstaciones): url = "%s%s" %(urlBase, urlProvEstacion %(prov, est)) print "URL: %s" %url # Realizamos la petición a la web req = requests.get(url) # Comprobamos que la petición nos devuelve un Status Code = 200 statusCode = req.status_code if statusCode == 200: # Pasamos el contenido HTML de la web a un objeto BeautifulSoup() html = BeautifulSoup(req.text) try: # Obtenemos las filas de las columnas filas = html.find('table', {'summary': 'Últimos datos registrados'}).find_all('tr') # De la fila 1 obtenemos el nombre de la provincia provincia = filas[0].find_all('td')[1].getText() # De la fila 2 obtenermos el nombre de la estación estacion = filas[1].find_all('td')[1].getText() # De la fila 8 obtenermos el ETo (mm/dia) EToDia = filas[7].find_all('td')[3].getText() # De la fila 11 obtenermos el ETo Acumulada (mm) EToAcu = filas[10].find_all('td')[3].getText() print "Provincia: %s\nEstacion: %s\nETo(mm/dia): %s\nETo Acumulada(mm): %s\n" %(provincia, estacion, EToDia, EToAcu) except: print "No existe esta estación" break