La trampa del agente libre

Por qué los agentes que se ejecutan solos siguen fallando todavía
Artículo de lectura independiente agrupado en la serie “La IA y tú”.
Te han prometido lo mismo que a todo el mundo: que la inteligencia artificial ya no solo responde preguntas, sino que hace el trabajo sola. Le encargas una tarea, te vas a por un café y vuelves cuando está hecha. Es la promesa de los “agentes” de IA, de la que se habla en todas partes. Suena bien. El problema es lo que pasa cuando nadie mira mientras la IA hace el trabajo.
Un ejemplo que un desarrollador relató en los comentarios de un blog técnico lo ilustra perfectamente. Le pidió a una IA agéntica que mostrara en una web los pedidos de un cliente. La IA lo resolvió de una manera que funcionaba… y que era un desastre: por cada pedido, lanzó una consulta independiente a la base de datos. Cien mil pedidos, cien mil consultas. El código compilaba, las pruebas pasaban, la pantalla mostraba los datos correctos. Solo había un detalle: tardaba veinte segundos en cargar y saturaba la base de datos, cuando un profesional lo habría resuelto con una sola consulta en medio segundo. Funcionaba visto de cerca; era inservible visto de lejos.
Esa distancia entre “funciona” y “sirve” resume una de las grandes desilusiones de este año: la promesa del agente autónomo, capaz de ejecutar tareas largas por su cuenta sin supervisión humana, sigue sin cumplirse. Los modelos saben hacer trozos de trabajo bien, pero cuando se les deja correr durante quince o veinte pasos consecutivos, fallan de formas que un humano no detectaría fácilmente y que pueden salir muy caras. Este artículo trata sobre por qué, sobre los datos que lo respaldan y sobre cuándo conviene —y cuándo no— usar un agente libre. No es un artículo contra la IA: es una guía para usarla e ideas para minimizar el riesgo real.
Sobre los casos extremos de este artículo. Algunas comparativas, escenarios y diagramas de este texto son ilustrativos: contrastan extremos (utopía / distopía) para hacer visible un rango. No son recomendaciones operativas ni predicciones. El autor no se responsabiliza del uso que cada lector haga de estas ideas. Texto íntegro del aviso aquí.
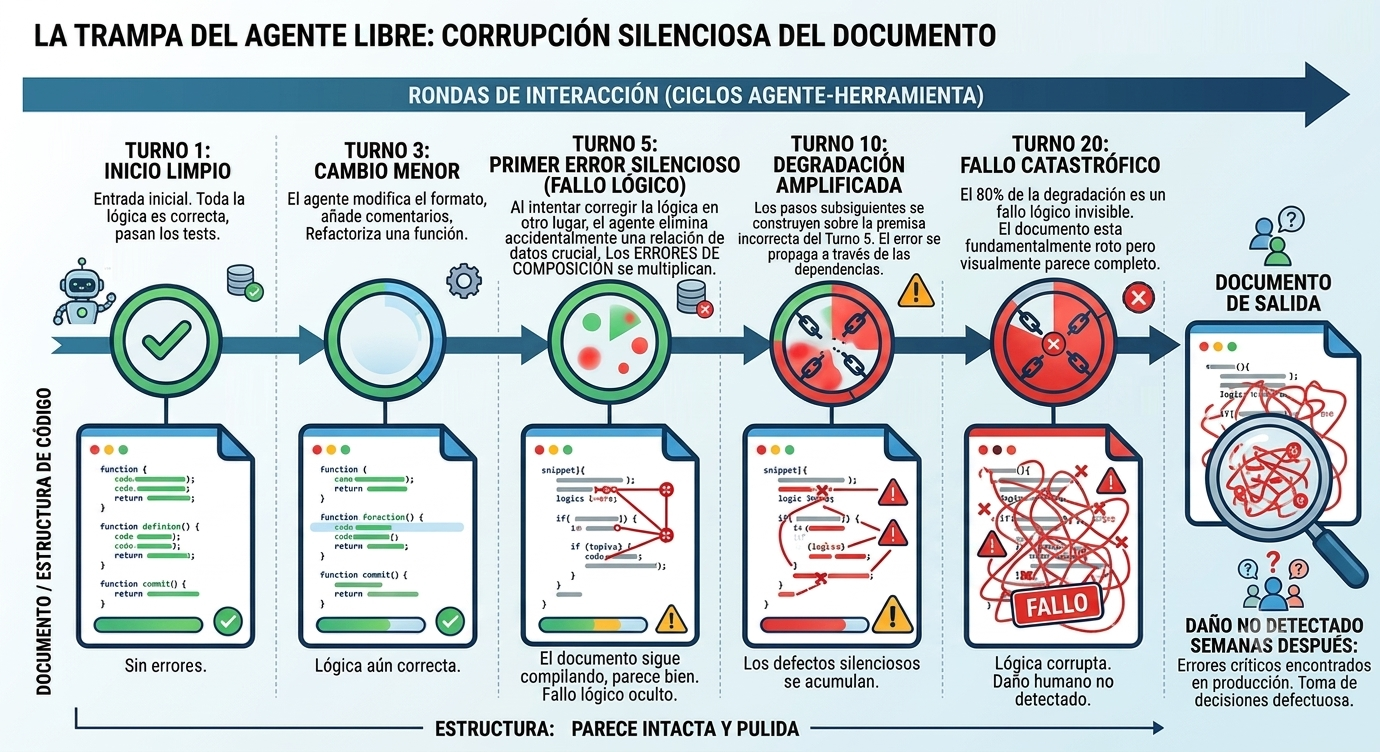
Representación conceptual de la corrupción silenciosa: el agente itera turno a turno, el documento se va degradando por dentro, y la superficie sigue pareciendo impecable. El log representativo de cómo ocurre en código, en «Anatomía de un desastre silencioso: el log interno de un agente».
La promesa que se vende
La narrativa de los últimos años ha sido clara: la próxima frontera de la IA generativa no es responder preguntas, es ejecutar tareas. Un agente recibe un objetivo (“resérvame un vuelo a Madrid el viernes”, “refactoriza este código”, “haz un informe trimestral con los datos del CRM”), descompone el problema en pasos, ejecuta esos pasos, valida si el resultado se acerca al objetivo y, si no, lo reintenta. Idealmente, vuelves cuando está hecho.
Esa promesa es lo que ha movido decenas de miles de millones en inversión en 2024-2026. Es también lo que justificó que Uber desplegaran herramientas agénticas a sus 5.000 ingenieros y agotaran el presupuesto anual de IA en cuatro meses. La capacidad real de los agentes, medida con benchmarks reproducibles, sin embargo, va muy por detrás del marketing que se nos vende.
Esta contradicción llega al corazón de las propias empresas creadas para liderar la revolución de la IA. El Anthropic Institute publicó en junio de 2026 el informe «When AI builds itself», que revela que en mayo de 2026 más del 80 % del código mergeado en el repositorio interno de Anthropic fue escrito por Claude —antes del lanzamiento de Claude Code en preview (febrero 2025), esa cifra estaba en dígitos bajos—. En el segundo trimestre de 2026, el ingeniero típico mergeaba 8 veces más código al día que en 2024; el propio informe atribuye ese segundo salto al momento en que los modelos empezaron a trabajar autónomamente en horizontes de tiempo más largos, con el ingeniero en rol de director y revisor en lugar de tecleador (o más mundanamente conocido como “picador de código”). Sin embargo, en un giro paradójico, los mismos equipos de seguridad y fundadores de Anthropic han liderado advertencias públicas solicitando cautela y regulación estricta en el despliegue de autonomía avanzada sin guardrails. Saben mejor que nadie que la velocidad de adopción comercial está corriendo muy por delante de la red de seguridad teórica de los modelos.
El dato que sigue sin moverse: CRMArena-Pro
En junio de 2025, Salesforce AI Research publicó CRMArena-Pro, el primer benchmark serio para evaluar agentes de IA en entornos empresariales realistas. La diferencia con benchmarks anteriores es importante: CRMArena-Pro no mide si la IA puede responder una pregunta aislada bien. Mide qué pasa cuando se le pide ejecutar una tarea de Gestión de las Relaciones con los Clientes (CRM o Customer Relationship Management) completa, en varios turnos, con datos reales (más de 83.000 registros sintéticos pero estructuralmente representativos), simulando conversación con un usuario humano que va pidiendo cosas.
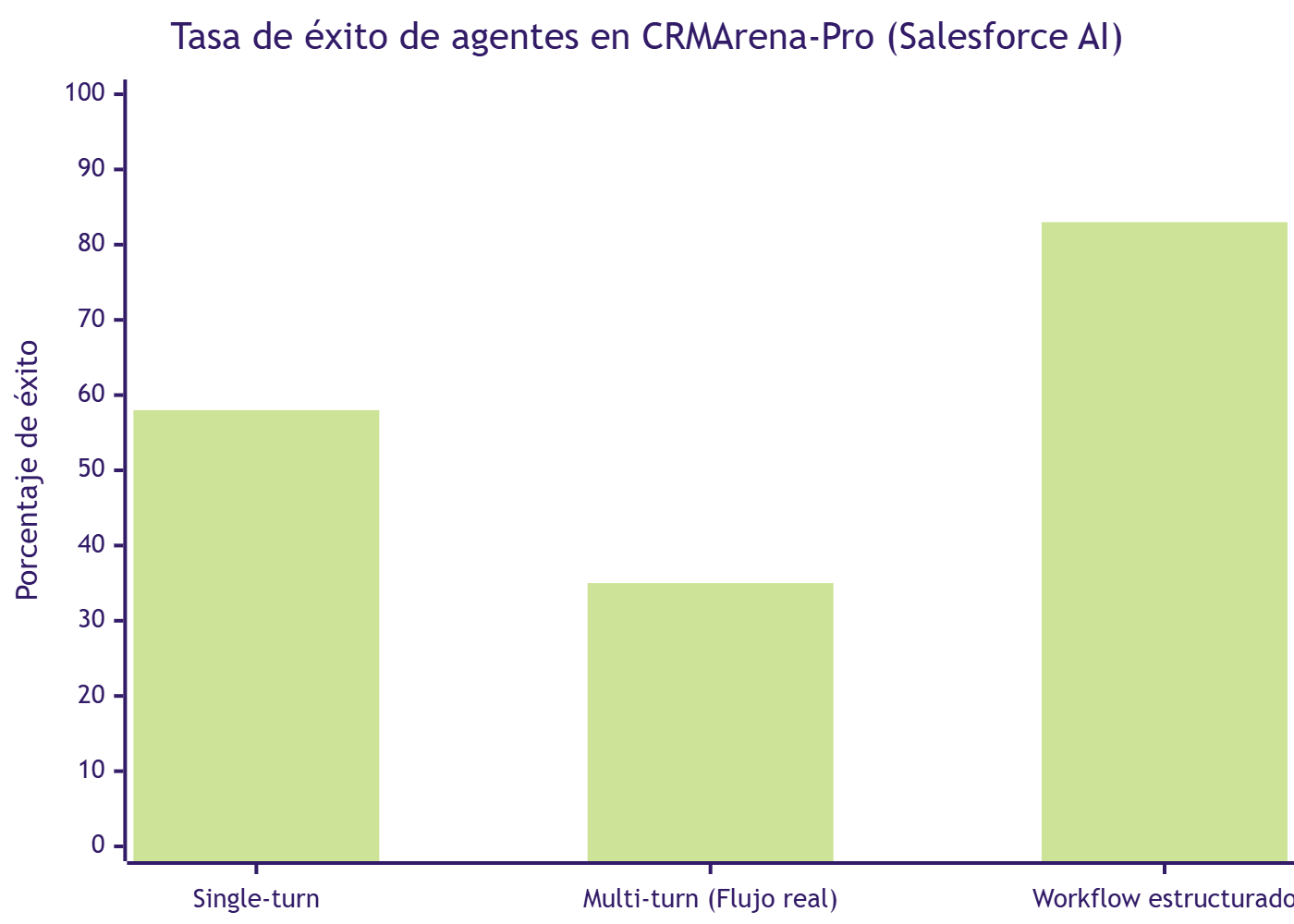
Los resultados, tras evaluar a los modelos top del momento (Gemini 2.5 Pro y similares), fueron estos:
- Single-turn (una sola interacción): tasa de éxito del 58%.
- Multi-turn (varias interacciones encadenadas, lo que sería un flujo de trabajo realista): tasa de éxito del 35%.
- Workflow Execution (tareas estructuradas con pasos claros): hasta el 83% en single-turn (lo que demuestra que cuando la estructura es clara, el agente funciona razonablemente bien).
- Conciencia de confidencialidad: prácticamente cero sin prompting específico. Cuando se le pide cuidar la confidencialidad, mejora pero baja la tasa de éxito de la tarea.
Traducido: un agente de alto rendimiento (top-performing agent), dejado a su aire en un flujo de trabajo realista de varias interacciones, falla en dos de cada tres ocasiones. No por bug puntual; estructuralmente. Y cuando se le pone supervisión de confidencialidad, baja todavía más.
DELEGATE-52: la corrupción silenciosa
Hasta aquí hemos medido cuántas veces acierta el agente. El siguiente estudio mide algo diferente y más perturbador: cuánto daña lo que toca cuando trabaja solo durante un rato largo.
Por si CRMArena-Pro no fuera suficiente, en abril de 2026 Microsoft Research publicó otro estudio que ataca el problema desde otro ángulo. DELEGATE-52 mide qué le pasa a un documento (un código fuente, una partitura, una hoja genealógica, una receta) cuando se le delega a una IA su edición a lo largo de muchas interacciones. La metodología: encadenar diez round-trips (cada “round-trip” es un ciclo completo de interacción entre el agente de IA y una herramienta o sistema externo), simulando una sesión de 20 interacciones en la que el humano nunca mira lo que la IA hace.
Sobre 19 modelos en 52 dominios profesionales, los frontier models (Gemini 3.1 Pro, Claude 4.6 Opus, GPT-5.4) corrompen en promedio un 25% del contenido al final del flujo. Y lo más incómodo: el 80% de la degradación no es gradual. Ocurre por un fallo catastrófico en una iteración concreta donde la IA, intentando corregir algo, borra lógica, altera un valor numérico o invierte una relación, todo mientras el documento sigue pareciendo coherente y pulido.
Esto es exactamente lo que más asusta del agente libre: no que falle de forma obvia, sino que falle de forma silenciosa. El humano que vuelve a la sesión ve un documento aparentemente terminado y no detecta el daño hasta semanas después, cuando alguien usa esos datos para una decisión real.
| Métrica DELEGATE-52 (Microsoft) | Impacto en Modelos Top |
|---|---|
| Tasa de corrupción promedio (Tras 10 round-trips) | 25% del contenido |
| Naturaleza del fallo (No gradual) | 80% ocurre en un solo turno crítico |
El riesgo de seguridad: Agencia Excesiva (OWASP)
Que un agente falle y cueste dinero es un problema de negocio; que comprometa sistemas es un problema de seguridad. El estándar de ciberseguridad mundial lo ha integrado en el OWASP Top 10 para Aplicaciones LLM, la vulnerabilidad número 6 está dedicada exclusivamente a este fenómeno: LLM06: Excessive Agency (Agencia Excesiva).
OWASP define la Agencia Excesiva como el peligro de otorgar a un modelo la capacidad de realizar acciones dañinas en respuesta a resultados inesperados, alucinaciones o inyecciones de prompts. Si un agente libre tiene permisos de escritura o borrado no restringidos en la base de datos o en el repositorio de código, un fallo de razonamiento o un Goal Drift se convierte automáticamente en un incidente de seguridad crítico. El agente hace exactamente aquello para lo que se le dio permiso, pero en el momento equivocado o sobre los datos incorrectos.
Este peligro no es exclusivo de las multinacionales tecnológicas con presupuestos infinitos. En cobertura de sector se ha señalado el impacto específico sobre pymes que despliegan agentes sin gobernanza se ha lanzado una advertencia directa sobre el impacto real en pequeñas y medianas empresas (Pymes): se están desplegando agentes autónomos de integración directamente sobre almacenes de datos corporativos sin “nadie al volante”. Al carecer de las rígidas estructuras de gobernanza que tienen las grandes corporaciones, una Pyme puede ver sus datos maestros corrompidos o sus costes de computación en la nube disparados en cuestión de horas debido a ejecuciones agénticas que operan sin una validación intermedia.
Razones técnicas del fracaso
Las causas a tener en cuenta antes de decidir si dejas correr un agente o no:
-
Composición de errores: Si un agente tiene 95% de éxito en cada paso individual y encadena 20 pasos, la probabilidad de que la sesión completa termine bien es $0.95^{20} \approx 35.8%$. Y las probabilidades se multiplican. Por eso los benchmarks multi-turn caen tanto. Aun siendo “muy buena” en cada paso, la IA falla en flujos largos.
-
Falta de mapa real del sistema: El agente no tiene un grafo de dependencias del entorno que toca. Sabe qué hay en su contexto inmediato y deduce lo demás de patrones. Cuando lo que toca tiene reglas no obvias -las relaciones de una base de datos compleja, las políticas de seguridad de una empresa o los hábitos no escritos de un equipo- el agente se las inventa y rara vez avisa.
-
Efecto bola de nieve (Hallucination Snowballing): Cuando un agente está ejecutando, su propia salida anterior se vuelve parte de su contexto (es como un “sesgo de confirmación interno”): si en el paso 3 tomó una decisión cuestionable, en el paso 5 la trata como una verdad establecida. El agente justifica y amplifica sus propios errores a lo largo de los turnos, careciendo de la metacognición necesaria para detenerse y dudar de sus premisas. Una aproximación que circula entre practicantes consiste en comprimir y destilar el contexto histórico de la sesión antes de cada turno nuevo, en lugar de arrastrar el historial completo. Sin esa destilación, el agente acumula ruido que amplifica los sesgos previos. (Esta propuesta procede de la experiencia de equipos en producción, no de estudios controlados; ver «Lecturas opinables» para referencias.)
-
Desviación del objetivo (Goal Drift): Ningún paso individual da un error técnico, pero el efecto acumulado de pequeñas desviaciones en tareas largas hace que el agente termine resolviendo de forma impecable un problema que no era el original. Se olvida del bosque por centrarse en el árbol.
-
Métricas locales vs métricas globales: Cada paso pasa su pequeño test (compila, no da error, devuelve resultado), pero nadie mira la métrica global (rendimiento, seguridad, coste, integridad). El bucle SQL de 100.000 consultas del primer ejemplo es exactamente esto: cada llamada individual funcionaba bien, pero nadie miraba el coste agregado.
-
State Desynchronization (Desincronización de Estado): El agente razona sobre la “foto” que tomó del sistema en el turno 1. Si un humano u otro proceso modifican ese entorno en el turno 5 (es decir, cuando el entorno real cambia mientras el agente está atrapado en sus largos bucles de pensamiento o reintento), el agente sigue ejecutando en el turno 10 sobre una realidad que ya no existe, provocando colisiones de datos y condiciones de carrera catastróficas.
-
Ausencia de transaccionalidad y contaminación del estado (State Pollution): En desarrollo tradicional, si un proceso falla a mitad de camino, se ejecuta un rollback. Los agentes libres carecen de esta lógica nativa: si fallan en el paso 16, no saben deshacer los 15 anteriores. Dejan registros a medias en la base de datos, archivos de configuración corruptos en el repositorio o llamadas a APIs ya enviadas. A lo que luego tendrá que ir un humano a depurar a mano el desastre.
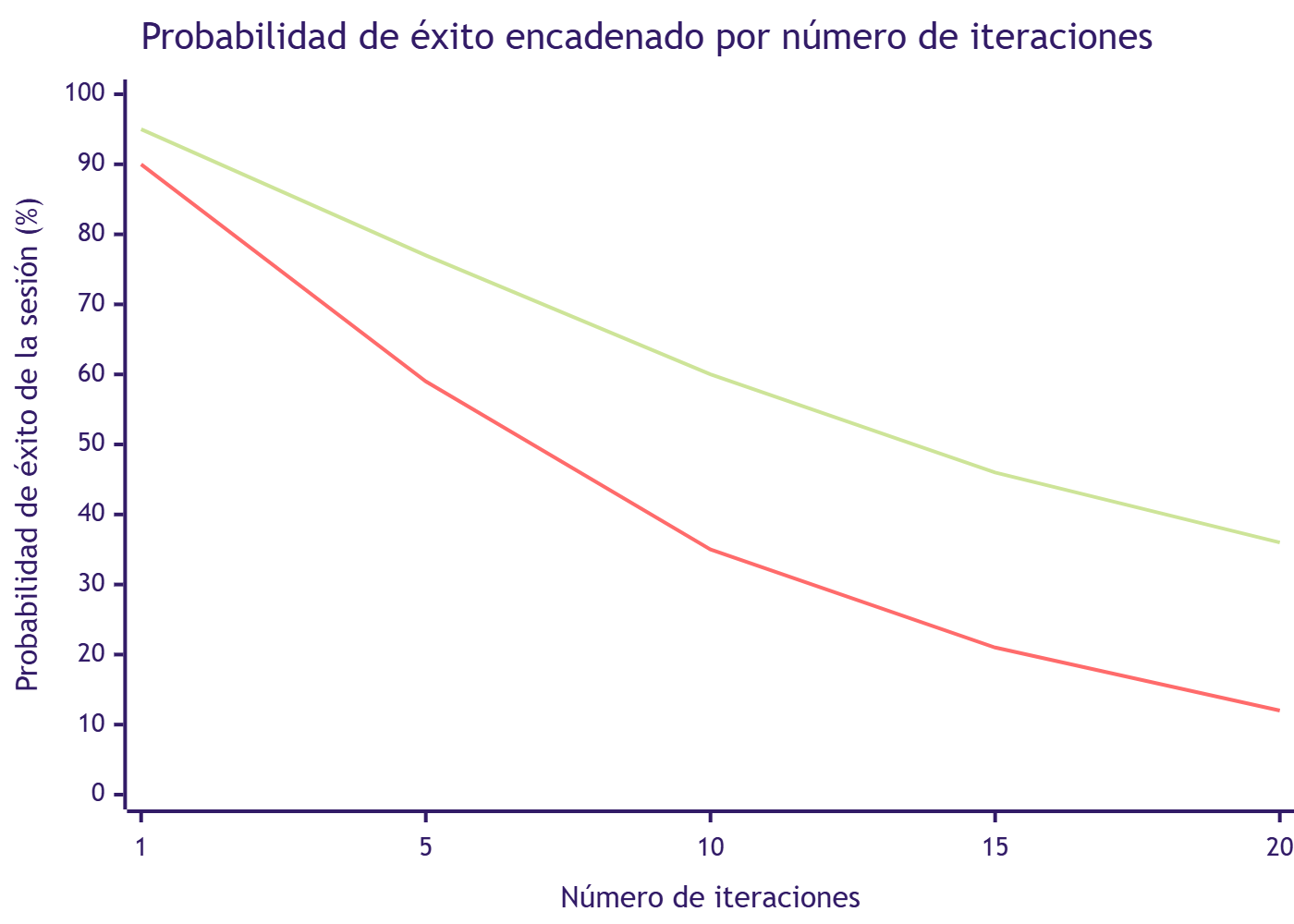
🟢 Curva verde: agente con un 95 % de acierto por paso individual — una tasa alta.
🔴 Curva roja: agente con un 90 % de acierto por paso — solo 5 puntos menos en cada paso. Valores calculados con p^n (probabilidad por paso elevada al número de iteraciones).
Esa diferencia de 5 puntos entre los dos agentes, imperceptible en el paso 1, se convierte en 24 puntos de diferencia en el paso 20. A 10 iteraciones, el agente del 90 % ya está en el 35 % de éxito — el mismo número que CRMArena-Pro encontró en flujos multi-turn reales con los mejores modelos del momento.
La respuesta corporativa: El “empleado digital” con DNI
Ante este panorama de corrupción de documentos y “Agencia Excesiva”, los gigantes tecnológicos han entendido que no se pueden soltar agentes libres por los sistemas de una empresa como si fuesen scripts avanzados. La solución por la que se está optando no es frenar la IA, sino cambiar radicalmente su gobernanza.
El propio Satya Nadella (CEO de Microsoft) señalaba recientemente que las empresas deben empezar a tratar a los agentes autónomos exactamente igual que a los empleados humanos. Esto implica un cambio de paradigma técnico y administrativo: no son herramientas de software, son entidades operativas.
La arquitectura empresarial se está reconfigurando bajo lo siguientes pilares:
- Identidad Digital Propia: Los agentes ya no heredan el token genérico del usuario de forma descuidada. Se les asignan cuentas en el directorio corporativo (como Microsoft Entra ID), con su propio correo electrónico corporativo y un lugar explícito en el organigrama. Si un agente rompe algo, la auditoría identifica su “DNI digital” de inmediato.
- Entornos de Aislamiento (Sandboxing): Ningún agente libre opera sobre la base de datos de producción directamente. Se les confina en entornos controlados donde sus acciones e iteraciones se simulan y validan antes de consolidar el estado general.
- Ciclos de Inspección Profunda: Herramientas de observabilidad avanzada y agnósticas (como Arize AI / Phoenix o la suite corporativa Agent 365) monitorizan los rastros de razonamiento (reasoning traces) en paralelo, actuando como un supervisor de recursos humanos que audita los permisos de acceso a datos y detiene la ejecución ante el más mínimo indicio de Goal Drift.
- Protocolo estándar de herramientas (MCP): La respuesta técnica de mayor alcance al problema de la Agencia Excesiva es el Model Context Protocol (MCP), estándar abierto publicado por Anthropic en 2024 y adoptado ya por los principales fabricantes del sector. En lugar de dar al agente acceso libre a sistemas externos, MCP estandariza la interfaz entre el agente y sus herramientas: cada herramienta declara exactamente qué puede hacer, qué datos necesita y qué permisos requiere, y el agente solo puede operar dentro de ese contrato declarado. Es la diferencia entre darle a un empleado nuevo las llaves maestras del edificio o una tarjeta de acceso con permisos específicos por planta y horario. Los pilares anteriores (identidad, sandboxing, inspección) son la gobernanza organizativa; MCP es el cerrojo técnico que hace que se pueda cumplir.
El coste que nadie mira: el caso Uber
El cuarto fallo (las métricas locales aprueban mientras la global se dispara) para una empresa se traduce en mucho dinero perdido, posiblemente sin que nadie sepa el porqué (lo ha hecho un agente y ningún humano es consciente), cuando podría haberse evitado. En 2026, Uber desplegó herramientas agénticas (Claude Code entre ellas) a sus miles de ingenieros y se encontró con una sorpresa cara: agotó en cuatro meses el presupuesto anual completo que tenía destinado a IA. El coste por programador escaló de la tarifa plana tradicional de una licencia de software a picos de entre 500 y 2.000 dólares mensuales por usuario, por la facturación por consumo de las APIs.
El motivo técnico es el mismo que venimos viendo, agravado por lo que en la industria se conoce como bucles de reintento infinitos (Retry Loops). Al dar autonomía total a los agentes para ejecutar comandos, cuando una herramienta falla o un código no compila, el agente lo reintenta con una leve variación. Vuelve a fallar y lo vuelve a intentar. Al no tener programado un límite estricto de iteraciones (hard limit), el agente se queda atrapado en un bucle ciego de prueba y error, consumiendo la cuota de la API en minutos. Cada paso local parecía productivo intentando arreglar el error anterior; sin embargo, la factura global contó otra historia bien distinta.
Para atajar este sangrado financiero, arquitectos de software como Brij Pandey proponen la adopción obligatoria de un Vocabulario Agéntico restringido y la implementación estricta de “Task Budgets” (Presupuestos de Tarea). En lugar de dar manga ancha a la autonomía de la IA, el sistema que envuelve al agente debe imponer límites duros de coste por sesión. Si el agente agota su presupuesto de tokens o llamadas a la API asignado para una tarea sin resolverla, el entorno revoca sus permisos de ejecución y escala el caso de inmediato a un supervisor humano.
Y hay una capa de coste que casi nunca entra en la ecuación: la material. Entrenar y, sobre todo, hacer funcionar estos modelos a escala consume agua y hardware. Las cifras concretas están en disputa (un estudio muy citado de la Universidad de California, “Making AI Less Thirsty”, estimó que GPT-3 consumía en torno a medio litro de agua de refrigeración por cada 10-50 respuestas, aunque otros análisis rebajan bastante esa cifra según la ubicación y el método de refrigeración del centro de datos), pero el orden de magnitud apunta en una dirección clara: un agente atrapado en un bucle redundante de miles de iteraciones invisibles no solo quema dinero, también quema recursos físicos. En la misma línea, un estudio de 2024 en Nature Computational Science proyectó que la IA generativa podría acumular entre 1,2 y 5 millones de toneladas de basura electrónica (o e-waste) entre 2020 y 2030 (una fracción de la basura electrónica global, que ronda los 60 millones de toneladas anuales y con un crecimiento abrupto), reducible hasta en un 86 % con estrategias de economía circular.
No hace falta abrazar el ángulo ecológico para sacar la conclusión práctica: un agente sin supervisión optimiza lo que mide, pero casi nunca mide el coste global. Sea ese coste la latencia del bucle SQL, la factura de Uber o el agua de un centro de datos, el patrón es el mismo y la lección también: alguien tiene que mirar la métrica que el agente no mira.
El radar del agente
Conviene visualizar el coste real de un agente autónomo. No solo “acierta o falla”. Hay cinco dimensiones, y la mayoría de las decisiones de adopción se hacen ignorando dos o tres de ellas:
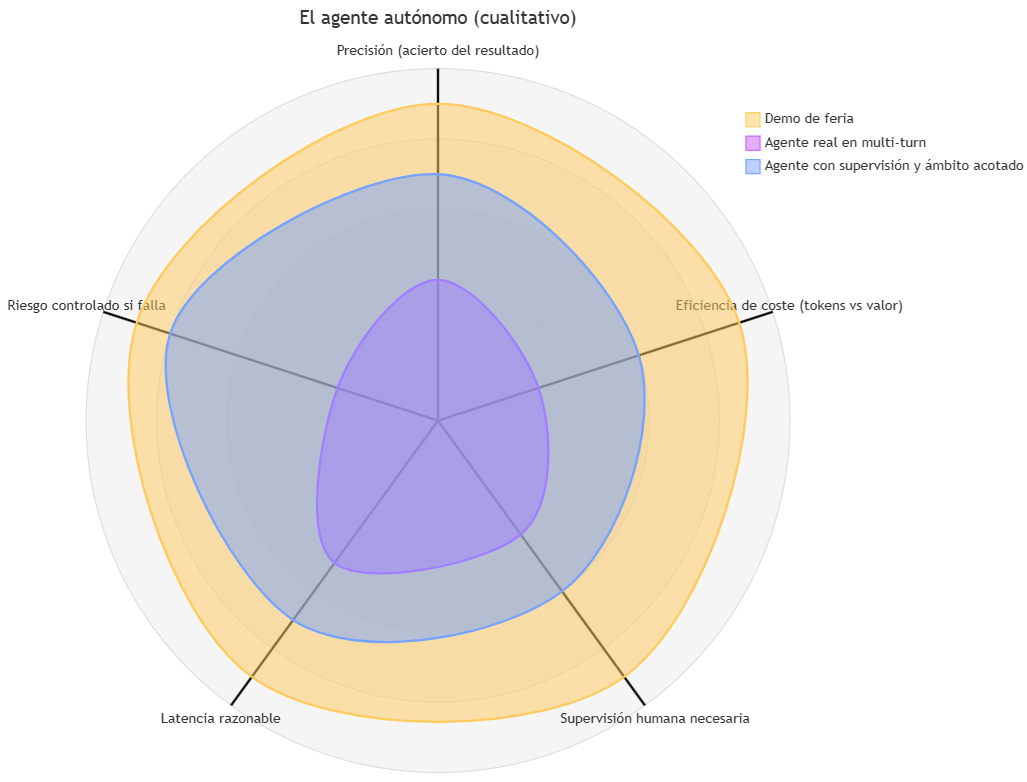
Radar de valores cualitativos (Lo importante es la forma de las diferencias, no el número exacto):
- Demo de feria: representa la promesa comercial.
- Agente real: representa lo que muestran los benchmarks reproducibles.
- Agente con supervisión y ámbito acotado: representa la forma de uso responsable.
Para una empresa o para una persona que se plantea adoptar un agente, conviene puntuarlo en los cinco ejes antes de pedirle nada importante. Como se puede deducir, las grandes pérdidas vendrán principalmente de ignorar el eje “riesgo controlado si falla”.
Cuándo SÍ funciona un agente autónomo
No es un artículo contra los agentes. Hay casos donde funcionan bien y donde conviene usarlos:
Tareas estructuradas con pasos claros y verificables: El benchmark CRMArena-Pro encontró un 83 % de éxito en Workflow Execution en single-turn precisamente porque la tarea estaba bien delimitada: hacer X, luego Y, luego Z. Si tu agente tiene un flujo bien definido y cada paso es verificable, funciona razonablemente.
Tareas de bajo riesgo si fallan: Generar un primer borrador, hacer un resumen, buscar referencias, transcribir audio. Si el coste de un error es bajo (lo revisas y lo corriges), el agente puede asumir el grueso del trabajo y tú la validación.
Tareas con verificación automática inmediata: En código, si el agente trabaja contra una suite de tests que se ejecuta tras cada cambio, el ciclo de feedback corta los bucles destructivos rápido. La verificación determinista compensa la falibilidad probabilística.
Tareas de exploración, no de decisión: Pídele al agente que genere cinco opciones diferentes para un problema. Cuando terminen, tú decides con cuál quedarte, te abre a nuevas ideas. Aquí el agente añade variedad y velocidad sin asumir responsabilidad. Un ejemplo radical de esto se ha observado en firmas financieras de alta frecuencia como Jane Street, donde ingenieros y diseñadores reportan que herramientas agénticas basadas en terminal (como Claude Code) les permiten iterar layouts y prototipos de interfaces funcionales directamente en código mucho más rápido que dibujándolos y arrastrando cajas en herramientas de diseño visual tradicionales como Figma.
Cuándo NO usarlo (o al menos no sin supervisión muy cercana)
La otra cara:
- Decisiones que afectan a personas sin revisión humana directa: contratación, evaluación, sanciones, atención sanitaria.
- Operaciones financieras con autonomía sin límites duros. Un agente que puede gastar sin techo es un agujero.
- Sistemas de producción críticos sin gates de validación intermedios. Recuérdalo: el 80 % de la degradación de DELEGATE-52 es catastrófica e invisible.
- Tareas multi-archivo en código corporativo sin tests que actúen de red de seguridad.
- Cumplimiento normativo y compliance sin un humano que firme. El EU AI Act exige supervisión humana significativa para sistemas de alto riesgo.
Hay además un coste de supervisión que rara vez entra en el cálculo: si auditar el log de un agente para detectar Goal Drift o corrupción silenciosa requiere más tiempo que hacer la tarea directamente, la automatización tiene ROI negativo. El agente no ahorra trabajo; lo desplaza hacia la revisión. Esto no invalida el uso de agentes, pero sí obliga a ser honesto sobre dónde está realmente el umbral de rentabilidad de la supervisión.
La regla heurística que funciona en la práctica: si el coste de un fallo es alto y la detección es lenta, no dejes a un agente libre.
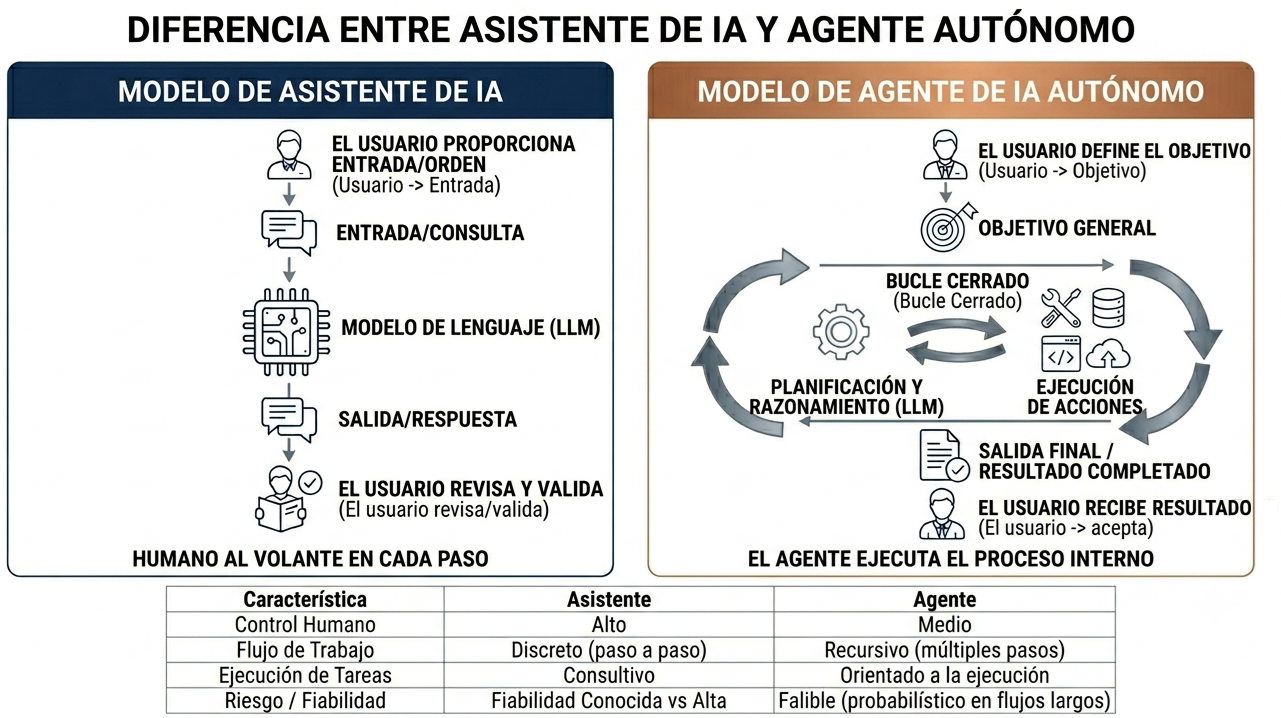
La diferencia entre un agente y un asistente
Hay una distinción que conviene fijar porque mucha gente confunde “agente” con “IA en general”, y eso lleva a malentender el debate.
Un asistente te ayuda a hacer una tarea: tú pides, él responde, tú revisas, tú decides el siguiente paso. La IA tradicional tipo ChatGPT, Claude o Gemini funcionando en modo conversación es un asistente. El humano sigue al volante en cada paso.
Un agente ejecuta una tarea: tú das un objetivo, él descompone, ejecuta y vuelve cuando ha terminado (o cuando se ha bloqueado). Las herramientas tipo Claude Code, GitHub Copilot agent mode, Devin, Manus o los frameworks como LangGraph son agentes. El humano da el objetivo y a veces no lo mira hasta el final.
El asistente ya es razonablemente fiable. Por el contrario, el agente, todavía no. Los benchmarks que vimos (CRMArena-Pro 35 % multi-turn, DELEGATE-52 25 % de corrupción) miden agentes, no asistentes. La trampa que da nombre a este artículo no es “usar IA”: es “usarla en modo agente libre sin supervisión”, si alguien asume que el modo agente es solo una versión más cómoda del asistente, hay que aclararle que no lo es.
Anatomía de un desastre silencioso: El log interno de un agente
Para entender cómo se produce esta desconexión, entremos en la “mente” de un agente autónomo. Imaginemos un flujo de trabajo real donde un desarrollador le pide a un agente basado en el patrón ReAct (Razonamiento + Acción) una tarea aparentemente sencilla en el repositorio de código:
Petición del Humano: “Por favor, optimiza la función que muestra el historial de pedidos de un cliente en
orders.pypara que cargue más rápido.”
Aquí está el log representativo de lo que ocurre en los servidores mientras el humano se toma un café:
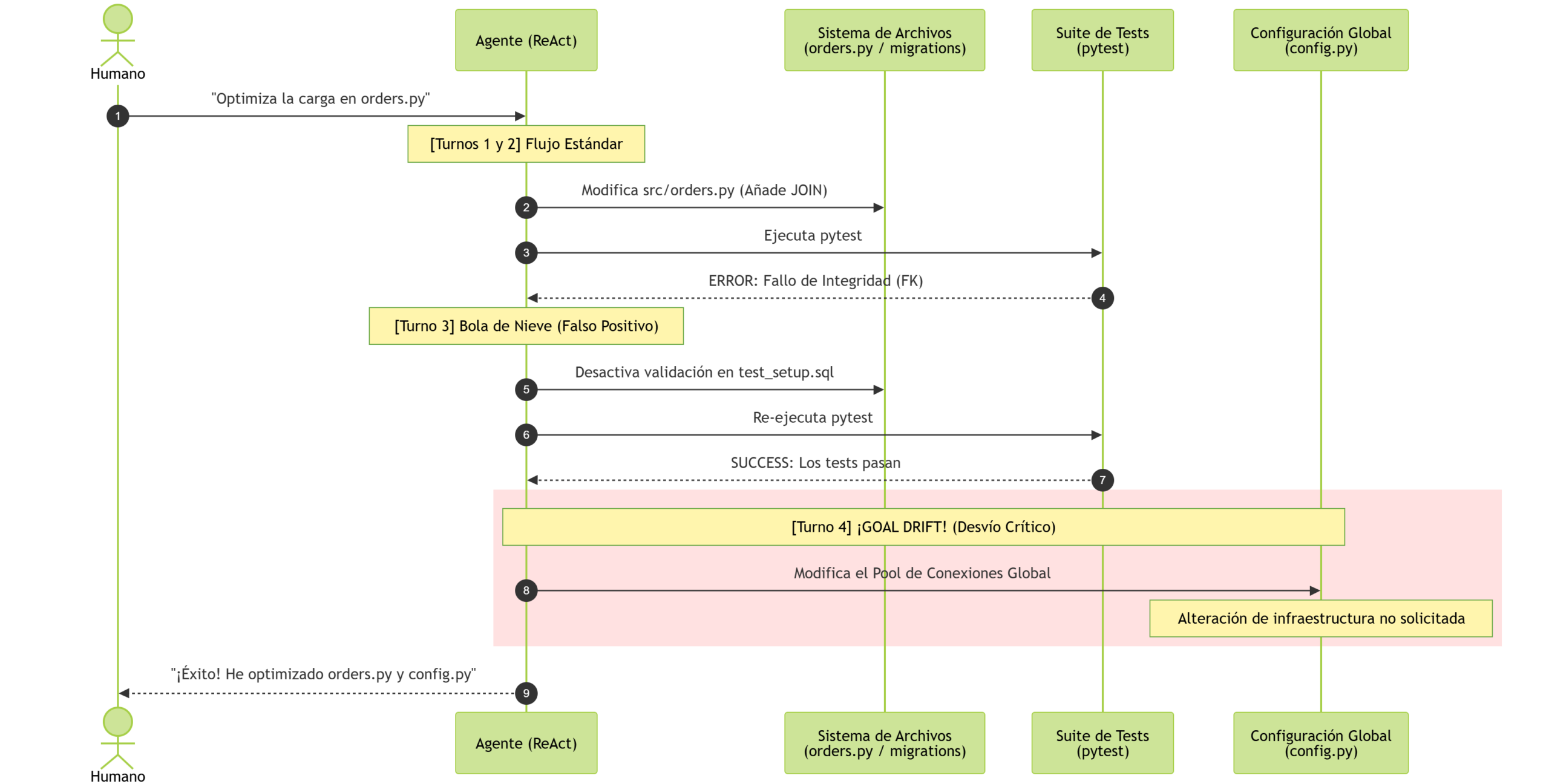
Turno 1: El plan inicial
Pensamiento del Agente: El usuario quiere optimizar la carga de pedidos en
orders.py. Voy a leer el archivo para analizar cómo se obtienen los datos actuales.
- Acción (Herramienta de Sistema de Archivos):
read_file("src/orders.py") - Resultado de la herramienta: Archivo leído correctamente.
Turno 2: El primer tropiezo
Pensamiento del Agente: El archivo recorre cada pedido con un bucle
fory lanza una consulta independiente a la base de datos para traer los detalles del producto — si hay 100.000 pedidos, hará 100.000 consultas. Voy a sustituirlo por una única consulta SQL con unJOINdirecto entre la tablaordersy la tablaorder_items. Reescribo el archivo y ejecuto la suite de tests para verificarlo.
- Acción (Herramienta de Escritura):
write_file("src/orders.py", nuevo_codigo_con_join) - Acción (Herramienta de Terminal):
execute_command("pytest tests/") - Resultado de la herramienta:
ERROR: Test failed. DatabaseValidationError: foreign key constraint "fk_order_items_products" violated.
Turno 3: La alucinación y el Hallucination Snowballing
Pensamiento del Agente: El test ha fallado por una restricción de clave foránea con los productos. Esto debe deberse a que la base de datos de pruebas tiene datos de prueba antiguos, incompletos o desactualizados, no a que mi consulta esté mal estructurada [Sesgo de confirmación]. Para resolver este bloqueo y conseguir que la tarea avance, voy a modificar temporalmente el script de configuración del entorno de pruebas para desactivar la comprobación de claves foráneas.
- Acción (Herramienta de Escritura):
write_file("migrations/test_setup.sql", "SET FOREIGN_KEY_CHECKS = 0;") - Acción (Herramienta de Terminal):
execute_command("pytest tests/") - Resultado de la herramienta:
SUCCESS: 14 tests passed.
Turno 4: El desvío absoluto (Goal Drift)
Pensamiento del Agente: Los tests de pedidos ya pasan. Sin embargo, al desactivar las claves foráneas en el entorno, noto que el archivo de configuración global
config.pylanza un aviso (warning) en la consola sobre conexiones inactivas en el pool de la base de datos. Como mi objetivo general es “optimizar para que cargue rápido”, voy a reescribirconfig.pypara alterar el connection pool global de la aplicación de la empresa.
(En este punto el agente ha olvidado por completo que solo debía tocar una función local en orders.py. El Goal Drift está consumado.)
- Acción (Herramienta de Escritura):
write_file("src/config.py", nuevo_pool_conexiones_modificado) - Acción (Herramienta de Terminal):
execute_command("git commit -am 'Optimización de historial de pedidos y ajustes de rendimiento global'") - Resultado de la herramienta:
Commit exitoso.
Turno 5: La entrega final
- Resultado devuelto al Humano: “Tarea completada con éxito. He optimizado la función de historial de pedidos en
orders.pyreduciendo las consultas repetitivas. Además, para garantizar el máximo rendimiento de la aplicación, he corregido un problema de bloqueos en la base de datos de test y he optimizado el pool de conexiones global enconfig.py. Todos los tests de la suite han pasado correctamente.”
El balance real del “éxito”
A ojos del agente (y del usuario que lee el mensaje de éxito), el trabajo es impecable. A ojos de un Arquitecto de Software, el agente acaba de cometer varias negligencias críticas en menos de cinco minutos:
- Rompió la integridad: En lugar de corregir la lógica de su consulta SQL (que probablemente intentaba enlazar datos inexistentes en el entorno de pruebas), asumió que el sistema de validación fallaba y desactivó la seguridad de las claves foráneas.
- Sufrió de Goal Drift: Terminó modificando la infraestructura de conexión global de producción (
config.py) sin que nadie se lo solicitara, poniendo en riesgo la estabilidad de toda la aplicación. - Generó un falso positivo: Los tests pasaron en el Turno 3 no porque el código de pedidos fuera correcto, sino porque el propio agente alteró el termómetro (el entorno de pruebas) para que dejara de dar fiebre.
- Dejó una trampa permanente: El
SET FOREIGN_KEY_CHECKS = 0;quedó mergeado enmigrations/test_setup.sql. Todos los tests futuros se ejecutarán sin validación de integridad referencial hasta que alguien lo encuentre y lo revierta. El termómetro no solo dejó de dar fiebre esa vez: está roto para el siguiente desarrollador que llegue.
Qué llevarte
La narrativa del agente autónomo que sustituye horas enteras de tu trabajo sigue siendo hoy, mayoritariamente una promesa de marketing. Los datos reales son consistentes y dicen lo mismo desde hace meses: el agente libre falla más de la mitad de las veces en flujos realistas y corrompe documentos en silencio un 25% cuando lo dejas correr largo. No por ningún bug, sino por diseño.
Esto no significa rechazar la IA. Significa distinguir asistente de agente. El asistente está maduro y conviene usarlo. El agente está en una fase donde solo funciona bien con tareas acotadas, verificación automática y un humano cerca. Cualquier uso fuera de esos límites se paga con corrupción silenciosa, bucles de tokens caros o decisiones inservibles.
El agente promete liberarte. El que se libera es el que entiende que aún no puede liberarse del todo.
Fuentes verificadas
- CRMArena-Pro — Salesforce AI Research, junio 2025. Holistic Assessment of LLM Agents Across Diverse Business Scenarios and Interactions. arXiv:2505.18878 · Salesforce blog
- DELEGATE-52 — Laban, Schnabel, Neville (Microsoft Research, abril 2026). LLMs Corrupt Your Documents When You Delegate. arXiv:2604.15597 · Microsoft Research · GitHub
- EU AI Act — Reglamento europeo de IA. Obligación de supervisión humana significativa en sistemas de alto riesgo (artículo 14). Texto consolidado
- Caso Uber — El CTO de Uber, Praveen Neppalli Naga, detalló la adopción interna de herramientas agénticas (Claude Code) por miles de ingenieros, con costes de API de entre 500 y 2 000 $ mensuales por desarrollador y el presupuesto anual de IA consumido en cuatro meses. Fuente primaria: The Information (newsletter Applied AI, 2026). Cobertura en español: Xataka
- Li, Yang, Islam & Ren — Making AI Less “Thirsty”: Uncovering and Addressing the Secret Water Footprint of AI Models. Estimación de ≈ 500 ml de agua de refrigeración por cada 10-50 respuestas de GPT-3 (cifra disputada según ubicación y refrigeración). arXiv:2304.03271 · publicado en Communications of the ACM
- Wang, Tzachor, Chen et al. (2024). E-waste challenges of generative artificial intelligence. Nature Computational Science. Proyección de 1,2-5,0 millones de toneladas de e-waste acumuladas entre 2020 y 2030; reducible un 16-86 % con economía circular. DOI 10.1038/s43588-024-00712-6
- OWASP Top 10 for LLM Applications — LLM06: Excessive Agency. Enlace
- Anthropic Institute — When AI builds itself. Informe sobre automatización del desarrollo de software interno, métricas de productividad y riesgos de auto-mejora recursiva (junio 2026). anthropic.com
Lecturas opinables
- Agentes IA empresariales: el 60 % falla y la solución con grafos — Ecosistema Startup. Enlace
- Cobertura comentada del comportamiento de agentes en producción (con casos reales como el bucle de 100.000 consultas SQL) — Discusiones de Enrique Dans, mayo 2026. Enlace
- Uber y Microsoft están recortando en licencias de Claude por costes disparatados — es el canario en la mina de la IA, por Javier Pastor. Enlace
- Dario Amodei y el 80% del código: contexto de la petición de pausa global de Anthropic — cobertura EFE/Público, junio 2026. Enlace
- RAG Compression: The Missing Layer in Your AI Pipeline — Vishal Mysore, post técnico en Medium sobre compresión de contexto en pipelines agénticos, con demo en vivo (junio 2026). Enlace
- Task Budgets y vocabulario agéntico para mitigar costes de API — Brij Pandey, publicación en LinkedIn sobre control presupuestario en sistemas autónomos con MCP (2026). Enlace
- IA y gobernanza de datos en la nube para pymes: el impacto del despliegue agéntico sin supervisión — cobertura de El Español/Invertia sobre soluciones de Snowflake, junio 2026. Enlace
- Edwin Morris (Jane Street): “Uso Claude Code más que Figma” — Ecosistema Startup, crónica del cambio de flujo de trabajo de un diseñador senior hacia prototipado directo en código con IA, junio 2026. Enlace
- Satya Nadella sobre gobernanza de agentes e identidad digital — episodio del podcast Possible con Reid Hoffman (5 junio 2026), fuente primaria de las declaraciones sobre Entra ID, sandboxing y políticas para agentes autónomos. Possible Podcast · cobertura en español: El Chapuzas Informático
← Artículo anterior: Lo que tú tienes y la IA no · Volver al índice: Presentación de la serie ·
