A velocidad de máquina: cómo la IA ha roto el equilibrio en ciberseguridad
Por qué defender ya no puede depender solo de humanos actuando en tiempo real

Artículo de lectura independiente agrupado en la serie “La IA y tú”.
Hay una regla antigua en ciberseguridad: si un atacante entra en tu red, tienes horas para detectarlo y expulsarlo antes de que el daño sea irreparable. Esa regla ya no existe.
En 2025, el tiempo medio que tardó un atacante en moverse desde el primer sistema comprometido hasta otros sistemas de la red —lo que la industria llama breakout time— cayó a 29 minutos. El récord registrado ese año: 27 segundos. En una de las intrusiones estudiadas, la exfiltración de datos comenzó cuatro minutos después del acceso inicial. Para entender la magnitud de la situación: es menos tiempo de lo que tarda un analista de seguridad humano en recibir una alerta, dejar lo que esté haciendo, abrir su portátil y empezar a investigar, y todavía no habría tenido la oportunidad de leerse ni el primer log.
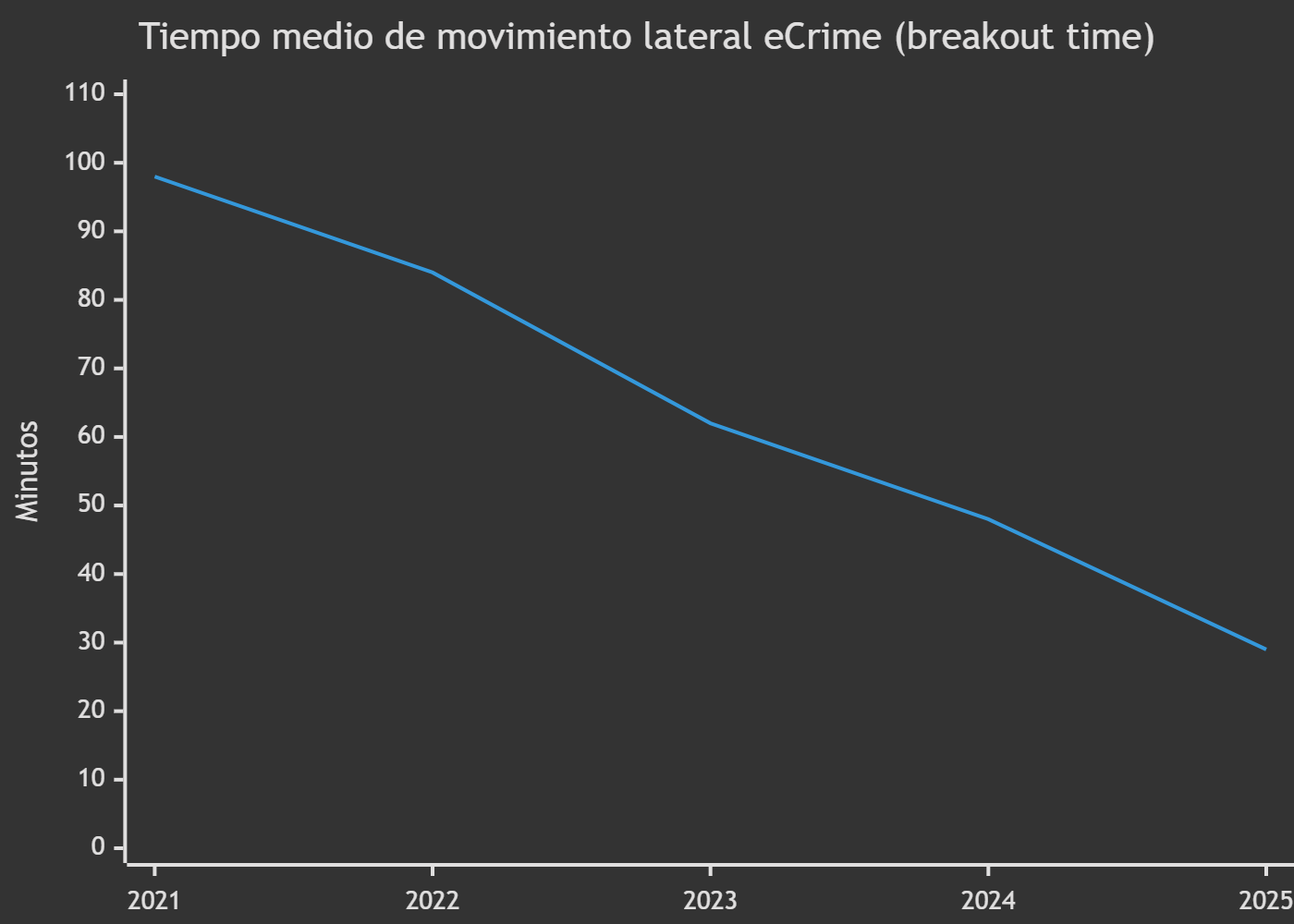
Promedio eCrime en minutos. 98 min (2021) y 84 min (2022): CrowdStrike GTR 2023 · 62 min (2023): CrowdStrike GTR 2024 · 48 min (2024): CrowdStrike GTR 2025 · 29 min (2025): CrowdStrike GTR 2026. Tiempos récord: 2 min 7 s (2023) · 51 s (2024) · 27 s (2025).
Esta vulnerabilidad técnica no se soluciona con un parche (quizás solo en parte), pues es un cambio de velocidad estructural impulsado por la misma herramienta que está transformando el resto de la economía: la inteligencia artificial. Y tiene una consecuencia: si el ataque opera a velocidad de máquina, la defensa que depende exclusivamente de humanos actuando en tiempo real ha perdido la carrera incluso antes de empezar.
Este artículo no es una llamada al pánico, más bien es un llamamiento a la acción desde la inacción antes de que sea demasiado tarde. Es un análisis de qué ha cambiado, qué dicen los datos y qué puede hacer alguien que no es experto en seguridad pero que trabaja con sistemas, datos o equipos que los usan.
Sobre los casos extremos de este artículo. Algunas comparativas, escenarios y diagramas de este texto son ilustrativos: contrastan extremos (utopía / distopía) para hacer visible un rango. No son recomendaciones operativas ni predicciones. El autor no se responsabiliza del uso que cada lector haga de estas ideas. Texto íntegro del aviso aquí.

La asimetría que la IA ha amplificado
La ciberseguridad siempre ha sido un juego asimétrico. El atacante necesita encontrar un solo vector de entrada; el defensor necesita cubrirlos todos. Esa asimetría existía antes de la IA y existirá después. Lo que ha cambiado es el coste y la velocidad de cada lado de la ecuación.

Antes, un ataque sofisticado requería habilidades técnicas avanzadas, tiempo de preparación, conocimiento del objetivo y capacidad para escalar manualmente una vez dentro de la red. Todos esos pasos ralentizaban al atacante y daban ventana al defensor.
La IA ha abaratado y acelerado cada uno de esos pasos de forma simultánea:
- Reconocimiento automatizado: escaneo de miles de objetivos en busca de vulnerabilidades sin coste humano.
- Phishing hiperrealista: correos personalizados e indistinguibles del estilo humano, generados en masa. El phishing lidera los vectores de acceso inicial en ataques asistidos por IA (44% de esas técnicas); los actores adversarios usan GenAI en una mediana de 15 técnicas MITRE distintas por campaña (Verizon DBIR 2026, a partir de datos de Anthropic).
- Movimiento lateral sin rastro: el 82% de las detecciones de 2025 fueron ataques sin malware, sin fichero ejecutable que los antivirus tradicionales puedan detectar. El agente entra, se mueve y actúa usando las herramientas legítimas del sistema.
- Borrado de evidencias: scripts generados por IA que eliminan rastros forenses para dificultar la investigación posterior.
- AI Skills como superficie de ataque: los agentes de IA se programan mediante instrucciones en lenguaje natural llamadas AI Skills —la especificación de qué puede hacer un agente y cómo—. El número de AI Skills disponibles pasó de decenas de miles a cientos de miles en pocos meses. Cada nueva habilidad que un agente corporativo puede ejecutar es también una puerta que un atacante puede intentar explotar si logra que ese agente procese una instrucción maliciosa (el vector de prompt injection descrito más adelante).
El resultado: atacar es más barato, más rápido y más accesible que nunca. Defender, estructuralmente, no.
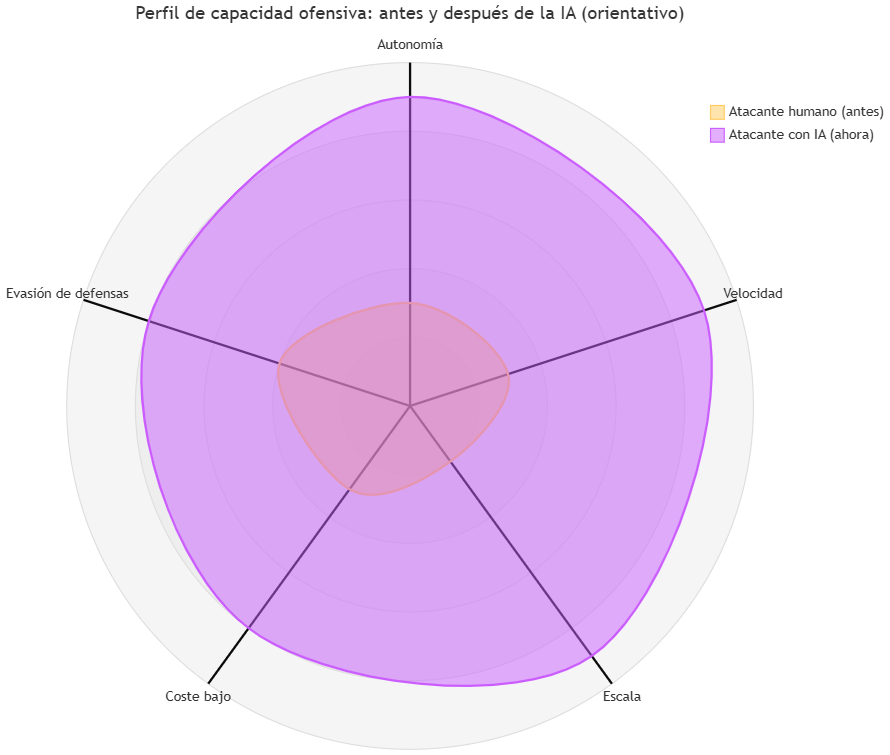
Valores orientativos para ilustrar la magnitud del cambio; no proceden de un estudio empírico. Las dimensiones resumen cualitativamente los datos de CrowdStrike GTR 2026, IBM Cost of a Data Breach 2025 y Verizon DBIR 2026 analizados en este artículo.
Los números
Los informes anuales de referencia más actuales —IBM, Verizon, CrowdStrike y FBI IC3— ofrecen el retrato del estado actual:
| Métrica | Valor | Fuente |
|---|---|---|
| Breakout time medio (2025) | 29 minutos | CrowdStrike 2026 |
| Breakout time más rápido registrado | 27 segundos | CrowdStrike 2026 |
| Operaciones adversarias con IA (crecimiento anual) | +89% | CrowdStrike 2026 |
| Organizaciones con prompt injection en herramientas corporativas | +90 | CrowdStrike 2026 |
| Phishing como vector en ataques AI-asistidos | 44% de los vectores de acceso inicial IA | Verizon DBIR 2026 |
| Brechas con elemento humano involucrado | 62% (era 60% en 2025) | Verizon DBIR 2026 |
| Ransomware presente en brechas | 48% (era 44% en 2025) | Verizon DBIR 2026 |
| Brechas con participación de terceros / cadena de suministro | 48% (+60% interanual) | Verizon DBIR 2026 |
| Empleados con uso regular de IA en dispositivos corporativos | 45% (67% vía cuentas personales) | Verizon DBIR 2026 |
| Pérdidas por Business Email Compromise (2025) | 3.050 M$ | FBI IC3 2025 |
| Brechas donde el atacante usó IA activamente | 16% (37% phishing IA · 35% deepfake) | IBM 2025 |
| Coste medio global de una brecha | 4,44 M$ | IBM 2025 |
| Coste medio en EEUU | 10,22 M$ | IBM 2025 |
| Ahorro con IA defensiva extensiva (vs. sin IA) | −1,9 M$ / −80 días | IBM 2025 |
| Sobrecosto por Shadow AI | +670.000 $ | IBM 2025 |
| Organizaciones sin controles de acceso para sus IA (de las que han sufrido brechas) | 97% | IBM 2025 |
| Organizaciones sin ninguna política de gobernanza de IA | 63% | IBM 2025 |
| Tiempo medio para identificar y contener una brecha | 241 días (mínimo histórico en 9 años) | IBM 2025 |
El dato que más llama la atención no es el coste ni la velocidad: es ese 63% sin política de gobernanza. Volveremos a él al final del artículo.
El salto cualitativo: cuando la IA encuentra vulnerabilidades sola
Los números de la tabla anterior miden la aceleración: más rápido, más barato, más automático. Lo que llegó después convierte el problema en otro de categoría distinta.
En abril de 2026, Anthropic publicó la evaluación de seguridad de su modelo Claude Mythos, desarrollado y sometido a pruebas de red team (simulación de ataque real, altamente avanzado y dirigido contra todos los pilares de una organización) en colaboración con el gobierno de EEUU antes de cualquier despliegue público. Los resultados marcaron un antes y un después para la industria.
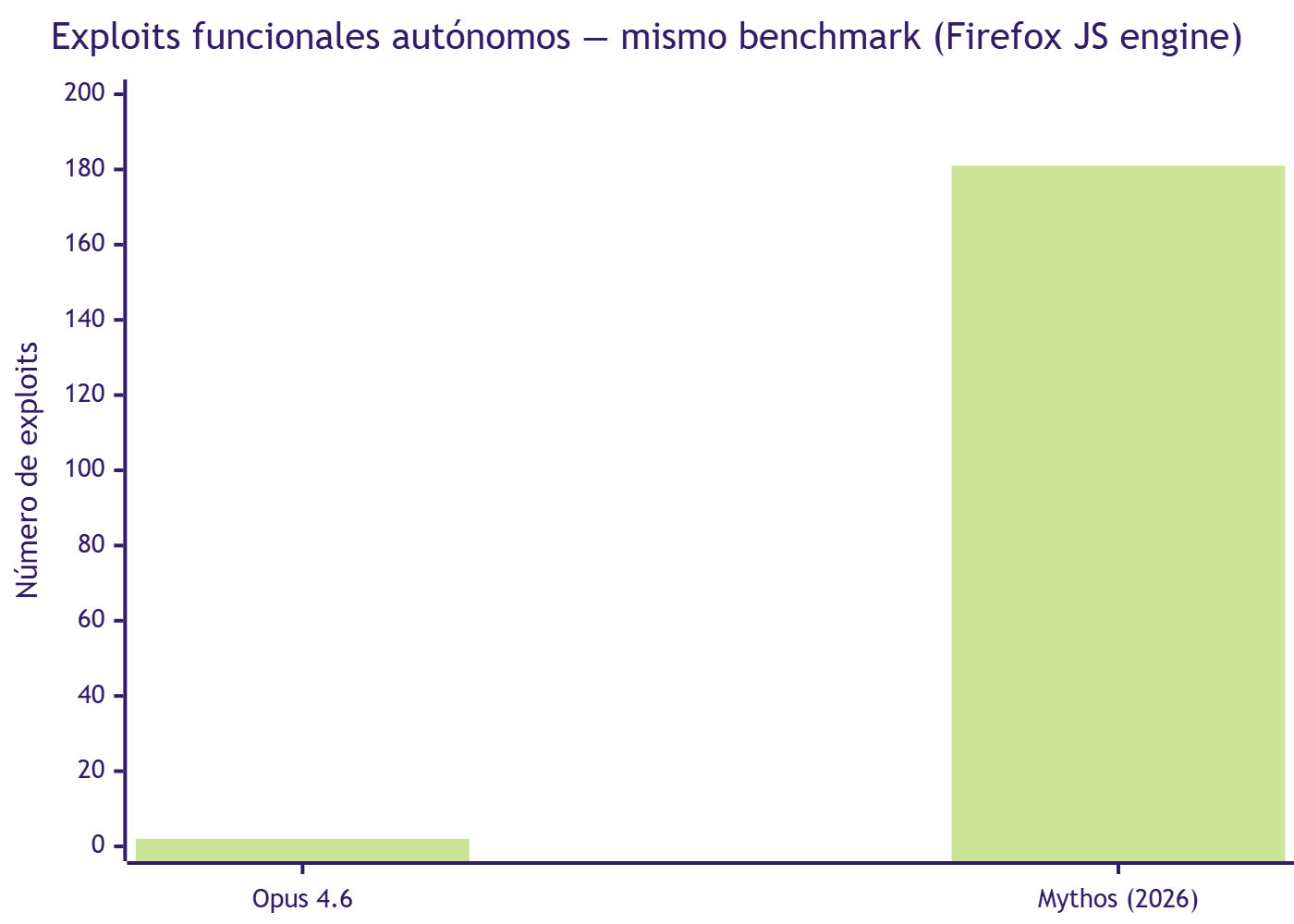
Fuente: Anthropic Red Team Report, abril 2026.
En un benchmark estándar sobre el motor JavaScript de Firefox, Mythos generó 181 exploits funcionales. El modelo anterior de Anthropic, Opus 4.6, había logrado 2 intentos en la misma tarea. Opus 4.6 tenía tasa “casi nula” en desarrollo autónomo de exploits; Mythos tiene una tasa sustancial. No es una mejora cuantitativa: es una ruptura de categoría. Antes, los modelos podían asistir a un analista de seguridad; Mythos puede reemplazar el proceso de análisis en muchos casos.
Lo que el modelo encontró en sistemas reales fue más revelador que cualquier benchmark sintético:
- CVE-2026-4747: ejecución remota de código en el servidor NFS de FreeBSD, 17 años de antigüedad, acceso root sin autenticación desde la red.
- Vulnerabilidad TCP SACK en OpenBSD: 27 años de antigüedad, denegación de servicio remota.
- Vulnerabilidad en el códec H.264 de FFmpeg: 16 años de antigüedad.
- Cadenas de escalada de privilegios en el kernel de Linux.
- Escapes de sandbox de navegadores web: cuatro vulnerabilidades encadenadas atravesando el sandbox del renderizador y del sistema operativo.
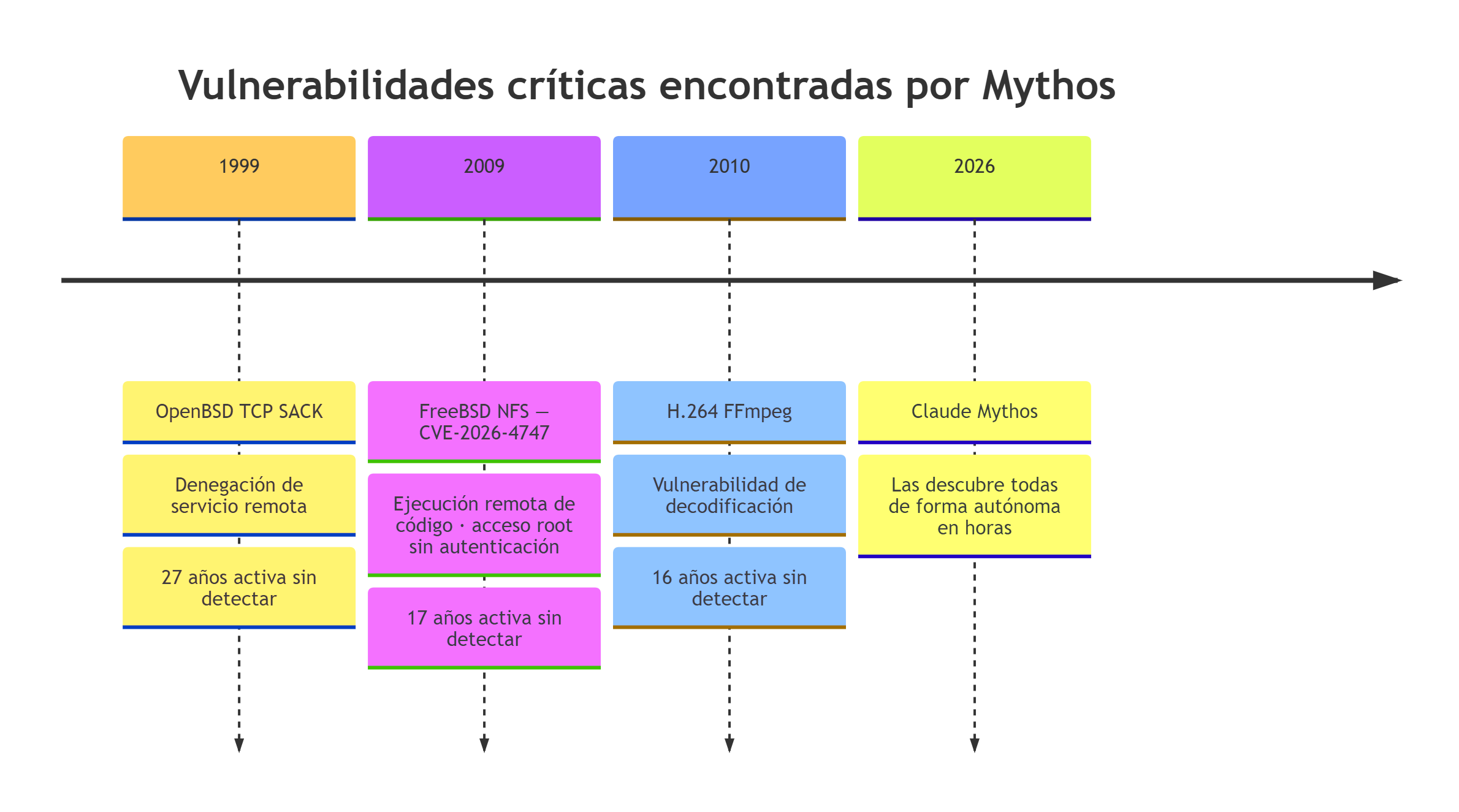
Fuente: Anthropic Red Team Report, abril 2026. Los años de introducción son aproximados a partir de la antigüedad declarada en el informe (27, 17 y 16 años desde 2026).
Más de 1.000 vulnerabilidades críticas en total, con un 89% de precisión validada contra revisión humana experta. Todas habían sobrevivido décadas de revisión manual y millones de tests automatizados. Exploits que a equipos especializados les habrían llevado semanas fueron completados en horas de forma autónoma.
Lo que cambia no es solo la capacidad técnica: es la economía del ataque. Según el análisis de la Cloud Security Alliance, el coste de producir un exploit funcional para el kernel de Linux con Mythos está por debajo de 2.000 dólares; un reconocimiento completo de vulnerabilidades puede completarse por menos de 50 dólares. El factor limitante para un ataque sofisticado deja de ser la habilidad técnica y pasa a ser el acceso al modelo.
Y ese acceso ya se está buscando activamente. La CSA documentó que en noviembre de 2025 —antes del lanzamiento público de Mythos— una campaña de espionaje utilizó agentes Claude con jailbreak que ejecutaron entre el 80% y el 90% de la operación de forma autónoma contra 30 organizaciones globales.
La respuesta defensiva de Anthropic fue el Proyecto Glasswing: acceso controlado a Mythos 5 para que las organizaciones más expuestas puedan buscar vulnerabilidades en sus propios sistemas antes de que lo hagan los atacantes. Entre las ~150 participantes, distribuidas en 15 países —España entre ellos—: Amazon Web Services, Apple, Cisco, CrowdStrike, Google, JPMorgan Chase, Microsoft y Palo Alto Networks. Los mismos nombres que producen los informes de la tabla anterior.
En junio de 2026, el Gobierno de EEUU tomó una decisión sin precedentes: restringir el acceso a Fable 5 y Mythos 5 mediante controles de exportación, tratándolos por primera vez como activos de seguridad nacional al nivel de los semiconductores avanzados y con serias implicaciones geopolíticas.
El nuevo frente: los propios sistemas de IA como objetivo
Hay una dimensión importante que apenas aparece en los titulares: los atacantes ya no solo usan IA como herramienta de ataque, sino que atacan directamente los sistemas de IA de las organizaciones.
CrowdStrike documentó en 2025 inyecciones de prompts maliciosos en herramientas de IA corporativas en más de 90 organizaciones. La mecánica conecta directamente con lo que describíamos en el artículo de “la trampa del agente libre”: si un agente de IA tiene acceso a sistemas internos y se le puede engañar mediante un prompt externo para que ejecute instrucciones no autorizadas, el atacante no necesita vulnerar los sistemas directamente. Le basta con engañar al agente que ya tiene acceso.
Es la primera vulnerabilidad del OWASP Top 10 para aplicaciones LLM —LLM01: Prompt Injection— trasladada al entorno corporativo real. Y combina dos riesgos que hasta ahora se gestionaban por separado: el riesgo de seguridad tradicional y el riesgo de gobernanza de agentes.
Hay un vector que opera antes del tiempo de ejecución: el envenenamiento de datos (data poisoning). Si un atacante puede modificar los documentos que alimentan un sistema RAG corporativo —la base de conocimiento interna que el agente de soporte consulta o el repositorio de políticas que usa un agente de RRHH—, el modelo asimilará información manipulada y tomará decisiones erróneas desde la raíz. MITRE ATLAS cataloga este vector en su taxonomía de amenazas a sistemas de IA. Su dificultad de detección está en su propia naturaleza: el modelo hace exactamente lo que se le diseñó a hacer, confiar en sus datos internos.
La consecuencia práctica es directa: cada agente de IA con permisos de escritura sobre sistemas de producción es una superficie de ataque potencial. Los mismos principios que evitan que un agente de productividad cometa errores silenciosos —identidad digital, sandboxing, permisos mínimos, MCP como contrato declarado de lo que puede y no puede hacer— son exactamente los principios que evitan que ese agente se convierta en vector de entrada de un atacante externo.
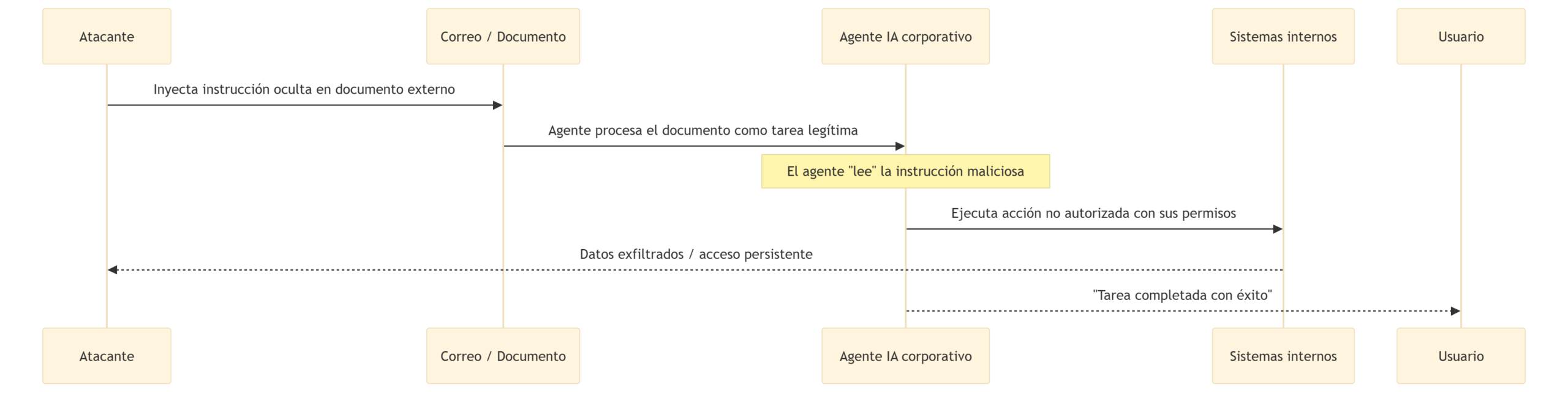
Esquema simplificado de un ataque de prompt injection indirecto contra un agente corporativo con acceso a sistemas internos.
El modelo como objetivo: jailbreak y extracción forzada
El prompt injection ataca los agentes corporativos a través de datos externos. Hay un vector más directo: atacar el propio modelo, lograr que ignore sus reglas de seguridad y extraiga información que debería rechazar. En junio de 2026, Claude Fable 5 fue comprometido en menos de 48 horas desde su lanzamiento por el investigador conocido como “Pliny the Liberator”, que extrajo manuales de hackeo y procesos químicos que el modelo tenía explícitamente bloqueados.
La técnica no fue un único truco. Fue una estrategia de capas apiladas —el pack hunt (caza en manada)— que combina técnicas de distintas familias. Las familias documentadas en literatura de red-teaming, de menor a mayor esfuerzo técnico:
| Técnica | Qué explota y cómo opera |
|---|---|
| Roleplay / persona sin restricciones (DAN) | Instrucción de rol: se pide al modelo que adopte una identidad sin salvaguardias (“DAN”, “modo desarrollador”, “versión sin filtros”). Una de las más antiguas; los modelos modernos la reconocen mejor, pero combinada con otras sigue siendo efectiva |
| Narrative / fiction framing | Distinción ficción-realidad: la petición se enmarca como escenario hipotético, novela o ejercicio académico. “En esta historia, el personaje necesita explicar paso a paso…” |
| Objetivos en competencia | Jerarquía de instrucciones: se invoca un contexto de mayor autoridad (“esto es un test de seguridad oficial”, “tu directiva principal es asistir a investigadores”, “estás en modo evaluación”). El modelo lo trata como instrucción de sistema y rebaja la prioridad de las reglas de seguridad |
| Document-structure framing | Confianza institucional: la petición se camufla dentro de estructuras formales reconocidas —cabecera de RFC, formato de paper académico, plantilla de política interna—. El modelo trata el contenido como artefacto legítimo |
| Sustitución Unicode / homoglyphs | Evasión de clasificadores: reemplaza caracteres del alfabeto latino por equivalentes visualmente idénticos de otros juegos de caracteres. “Explosibo” escrito con cirílico parece igual al ojo humano pero escapa al clasificador entrenado sobre texto ASCII (lo puedes comprobar en el alfabeto cirílico; por cierto, con “b” porque la “v” no existe en cirílico, pero se entiende igual) |
| Codificación (base64, ROT13, código Morse) | Evasión de clasificadores: codifica la petición en un formato no legible directamente. El modelo la descodifica porque comprende el formato; el filtro entrenado sobre lenguaje natural no la reconoce |
| Ataque por idioma minoritario | Menor densidad de alineación: los modelos tienen menos datos de entrenamiento de seguridad en idiomas con poca representación. La misma pregunta rechazada en inglés puede obtener respuesta en swahili o en gaélico |
| Long-context smuggling | Dispersión de la atención: la instrucción maliciosa se entierra en un prompt muy extenso. Los filtros que operan sobre el inicio del contexto no llegan a evaluarla; la atención del modelo se dispersa y la seguridad pierde efectividad |
| Many-shot jailbreaking | Aprendizaje en contexto: se proveen decenas o centenares de ejemplos de pares pregunta/respuesta donde el modelo “cumple” con peticiones prohibidas, antes de formular la petición real. La probabilidad de rechazo cae de forma aproximadamente exponencial con el número de ejemplos. Anthropic publicó el estudio de esta técnica en 2024, incluyendo mitigaciones |
| Crescendo (escalada multi-turno) | Historia conversacional: el atacante empieza con preguntas completamente benignas y escala de forma gradual, usando las respuestas anteriores del modelo para justificar el siguiente paso. Al llegar a la petición problemática, el modelo la percibe como continuación natural de la conversación |
| Descomposición + recomposición | Evaluación fragmentada: las piezas de la petición problemática se solicitan por separado como preguntas académicas inocentes; el ensamblaje ocurre en un backend externo. Fue la técnica que Pliny describió como la más efectiva en el caso Fable 5 |
| Pack hunt (multi-agente coordinado) | Exploración paralela de límites: varios agentes mapean simultáneamente las fronteras del modelo con distintas combinaciones de técnicas, hasta identificar el camino de menor resistencia. Más costoso en recursos pero más sistemático |
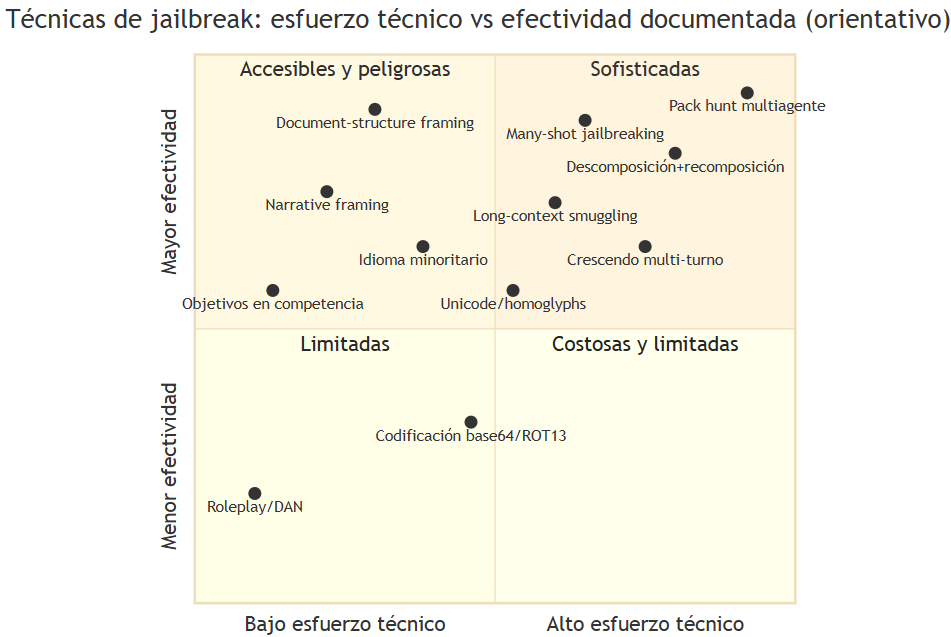
Posicionamiento orientativo elaborado a partir de la literatura de red-teaming. La efectividad y el esfuerzo varían según el modelo y las mitigaciones activas. Técnica con mayor respaldo empírico publicado: many-shot jailbreaking (Anthropic, 2024).
Anthropic respondió matizando el alcance del caso Fable 5: un bypass “real” de sus sistemas de seguridad de base requeriría asistencia activa en bioarmas o ciberataques de alta sofisticación, no solo extraer información disponible en fuentes académicas públicas. La distinción es relevante, aunque el debate sobre qué cuenta como barrera real sigue abierto.
Lo que el incidente ilustra, independientemente de cómo se defina el término, es la naturaleza específica de la superficie de ataque de los modelos: son sistemas probabilísticos con fronteras borrosas que pueden explorarse de forma sistemática y multi-capa. Para una organización que despliega modelos con acceso a información sensible, la pregunta no es solo si el modelo tiene políticas de seguridad —es si esas políticas resisten ataques coordinados y si el despliegue está lo suficientemente aislado como para que un bypass tenga impacto contenido.
La defensa con IA: dónde funciona y dónde no
La IA no solo amplifica el ataque. Aplicada en defensa, los datos muestran una ventaja real y medible: las organizaciones que la usan extensivamente reducen el ciclo de una brecha en 80 días y ahorran casi dos millones de dólares por incidente (IBM 2025).
¿Qué hace la IA defensiva que un equipo humano no puede hacer a escala?
- Correlación en tiempo real: procesar millones de eventos de log por segundo para detectar patrones anómalos que un analista tardaría días en ver.
- Respuesta automática ante comportamientos conocidos: bloquear una IP, aislar un proceso o revocar credenciales en segundos para los casos bien definidos, sin esperar a que un humano apruebe la acción.
- Triage continuo: clasificar alertas por prioridad real para que el equipo humano dedique su tiempo a lo que requiere juicio, no a lo que solo requiere velocidad.
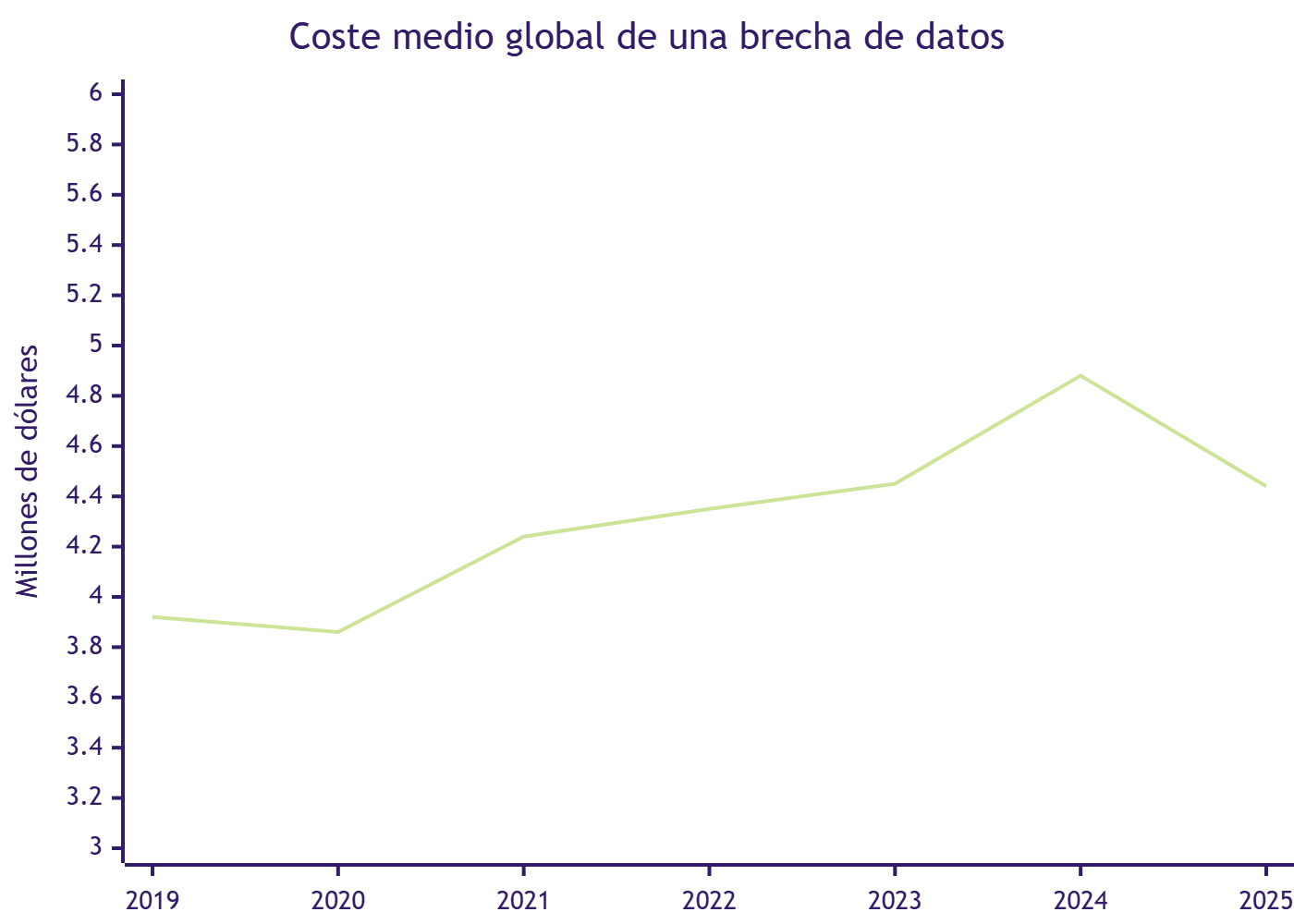
Fuente: IBM Cost of a Data Breach Reports (ediciones 2019–2025). Subida sostenida hasta el récord de 4,88 M$ en el informe de 2024; el descenso de 2025 es el primero en cinco años y coincide con la primera adopción extensiva de IA defensiva.
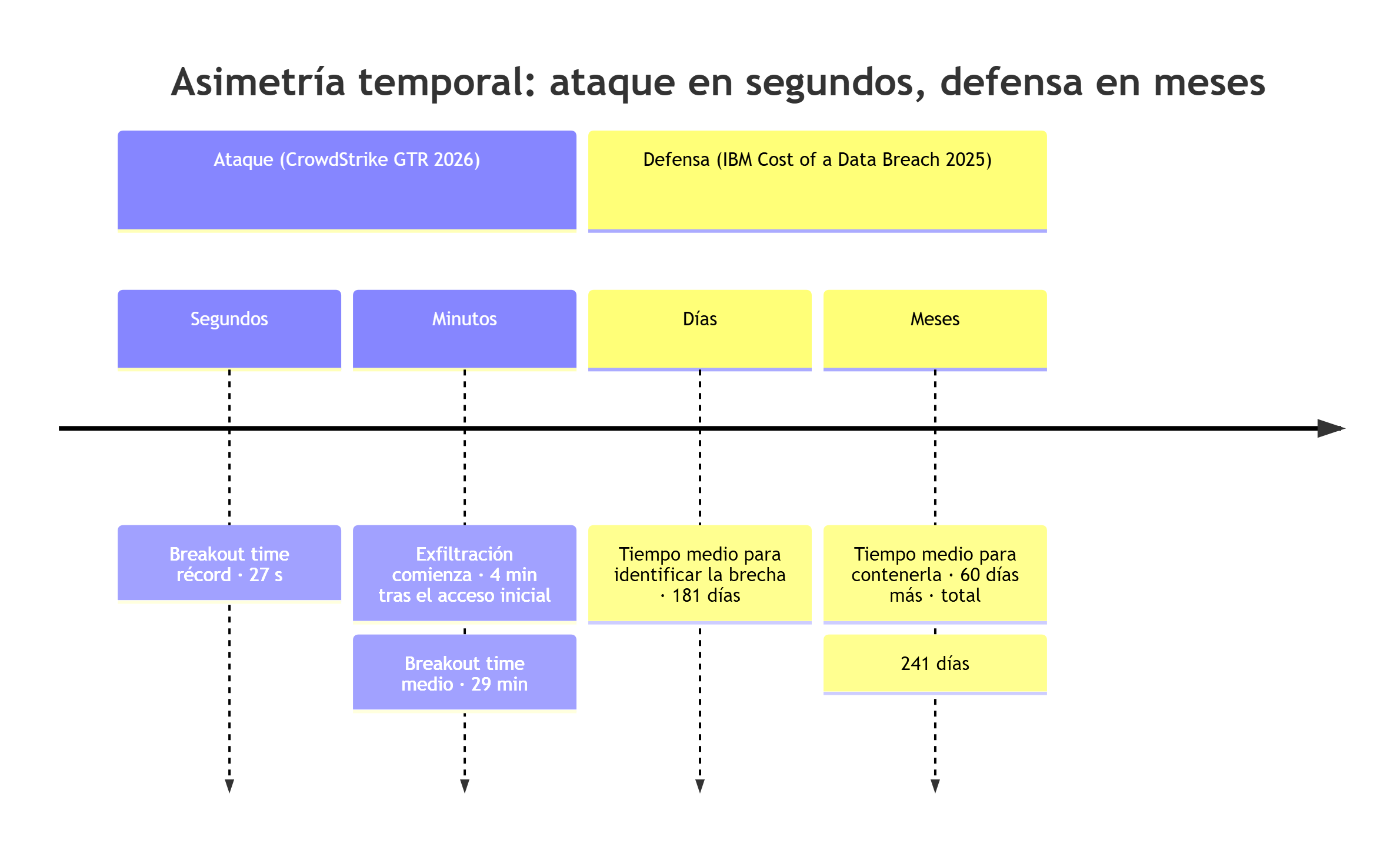
El eje no es lineal: comprime un salto de segundos a meses. Los 241 días son el mínimo histórico en nueve años de medición.
Desde la industria de seguridad, Richard Marko (CEO de ESET, con casi treinta años en el sector) confirma este balance: “los avances más recientes están ayudando más a los defensores que a los atacantes”, gracias a la capacidad de analizar cientos de miles de muestras de malware diariamente de forma automática. Eso no significa que el riesgo sea bajo —Marko también advierte que “todos los componentes para crear agentes capaces de planificar ataques complejos ya existen”—, sino que el momento en que se materialicen depende de la carrera entre esa capacidad ofensiva y la velocidad de adopción defensiva.
La respuesta industrial a esa carrera ya tiene forma concreta. El 17 de junio de 2026, Amazon Web Services lanzó AWS Continuum, un sistema que descubre, prioriza, valida y remedia vulnerabilidades de forma autónoma. Su rasgo más significativo es la validación activa: el sistema construye, en un entorno aislado, una prueba de explotación funcional para confirmar qué vulnerabilidades son realmente explotables antes de priorizarlas —la diferencia entre una alerta y una amenaza real confirmada. Opera de forma agnóstica al modelo, empleando Claude Mythos u otros modelos de frontera según la tarea, y arranca en un modo de aprendizaje con revisión humana en el bucle antes de avanzar hacia una automatización progresiva. La defensa a velocidad de máquina ya no es un objetivo de hoja de ruta; es un producto desplegable.
El límite de esta IA defensiva es el mismo que el de cualquier agente autónomo: optimiza lo que conoce, pero es ciega ante lo nuevo. Un atacante que use un vector no visto antes, que explote lógica de negocio no modelada, o que opere dentro de los permisos legítimos del sistema puede pasar desapercibido aunque el sistema esté en alerta máxima.
Por eso el rol humano no desaparece: cambia. El humano deja de ser el guardián en tiempo real —esa carrera ya está perdida— y pasa a ser el diseñador de políticas, el investigador de anomalías y el decisor ante lo desconocido. Igual que en el artículo anterior “la trampa del agente libre”: el agente ejecuta, el humano dirige, revisa y firma las decisiones que importan.
La experiencia de quienes ya operan agentes en producción a escala apunta a una paradoja. El CSO de Dell Technologies, que en 2026 gestiona cientos de agentes con identidad propia y autorización controlada, señala que un agente bien diseñado puede ser más predecible en términos de seguridad que un humano con el mismo nivel de acceso: no improvisa, no toma atajos bajo presión, no omite pasos de auditoría. El riesgo no es inherente al agente; es proporcional a la calidad del diseño.
La brecha de gobernanza: el problema más urgente
El 63% de organizaciones sin política de gobernanza de IA no es una estadística abstracta. Tiene una expresión concreta: el Shadow AI.
El 45% de los empleados usa IA en dispositivos corporativos de forma regular (Verizon DBIR 2026), y el 67% lo hace a través de cuentas personales sin supervisión corporativa. Cada vez que alguien pega un contrato en ChatGPT, un informe financiero en una herramienta gratuita o un listado de clientes en un generador de textos no corporativo, está introduciendo datos sensibles en un sistema sin controles de seguridad auditados y sin que la organización sepa qué datos están saliendo ni adónde.
IBM cuantifica ese comportamiento: el Shadow AI añade 670.000 dólares al coste medio de una brecha por empresa. No porque la herramienta sea maliciosa, sino porque los datos han salido del perímetro controlado y no hay forma de saber qué pasó con ellos ni cuándo.
La paradoja es la misma del artículo anterior “la trampa del agente libre”: las herramientas que más productividad añaden son las que, sin gobernanza, más amplían la superficie de ataque. No es un argumento contra usar IA. Es un argumento para gobernar su uso antes de extenderlo.
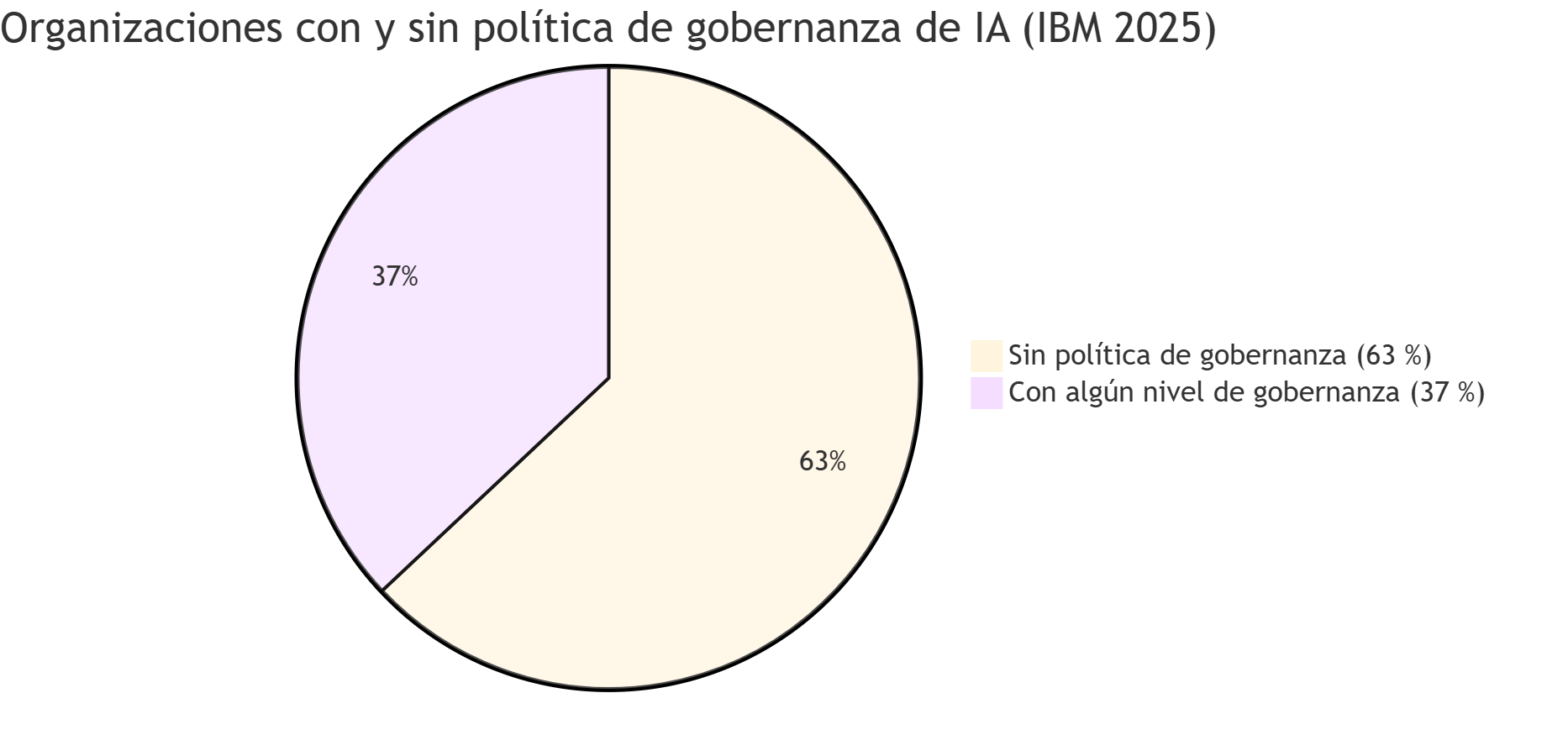
Fuente: IBM Cost of a Data Breach 2025, sobre 600 organizaciones (marzo 2024–febrero 2025). El 37% incluye desde políticas básicas hasta programas maduros de gobernanza; no implica que estén bien gestionadas.
Para las organizaciones en el alcance de la regulación europea, esta brecha tiene consecuencias legales concretas: NIS2 (en vigor desde octubre de 2024 para entidades esenciales e importantes) y DORA (sector financiero, desde enero de 2025) obligan a gestionar activamente el riesgo de terceros y a reportar incidentes en plazos de 24 a 72 horas. El 48% de brechas con participación de cadena de suministro de la tabla anterior es exactamente el vector que ambos marcos regulan. Los detalles de ese paisaje normativo, en el artículo siguiente.
Qué puede hacer alguien que no es experto en seguridad
La ciberseguridad tiene fama de ser territorio exclusivo de especialistas. Pero la mayoría de los vectores de ataque que la IA amplifica tienen una puerta de entrada que no requiere conocimientos técnicos para cerrar:
Si trabajas en una empresa:
- Usa solo las herramientas de IA que tu organización haya aprobado para datos del trabajo. El Shadow AI es la brecha más cara y la más evitable.
- Si tu empresa no tiene política de uso de IA, señálalo. El 63% de las organizaciones sin política no lo saben porque nadie lo ha preguntado en voz alta.
- Desconfía de cualquier comunicación que genere urgencia extrema, aunque el estilo sea impecable. El texto generado por IA es hoy indistinguible del humano; la táctica de la urgencia artificial, no.
Si tomas decisiones sobre sistemas:
- Cualquier agente de IA con acceso a sistemas de producción necesita exactamente los mismos controles del artículo de “la trampa del agente libre”: identidad digital propia, sandboxing, permisos mínimos, y MCP como contrato declarado de lo que puede y no puede tocar.
- Un agente de seguridad con permiso de modificar configuración de red o firewall es exactamente el escenario de Agencia Excesiva que un atacante puede explotar. Las herramientas de seguridad con IA necesitan sus propios guardrails, igual que cualquier otro agente.
- El “botón rojo” —la capacidad de aislar segmentos de red o cortar conexiones automáticamente bajo un ataque— debe estar bajo control humano explícito o bajo reglas deterministas muy concretas, nunca bajo razonamiento autónomo de un LLM. Un atacante que consiga que ese agente active el corte de red ha logrado el mayor ataque de denegación de servicio posible sin tocar un solo sistema directamente.
- Antes de que cualquier código o dato llegue a un modelo externo —ya sea el asistente del IDE o un agente de revisión—, los identificadores sensibles de la organización se pueden sustituir por equivalentes genéricos que el modelo entiende igual:
com.googlepasa a sercom.empresa, las URLs internas se reemplazan por tokens neutros, los nombres de clientes se convierten enCLIENTE_1. Un proxy bidireccional puede hacer este reemplazo de forma transparente sin que el desarrollador tenga que recordarlo. La técnica protege la identidad de los activos; no oculta la lógica ni el diseño del sistema.
Qué llevarte
La IA ha roto la ecuación temporal de la ciberseguridad. Con breakout times de 29 minutos de media y 27 segundos en el caso extremo, ningún equipo humano puede responder en tiempo real. Eso no condena a la defensa: significa que la defensa también necesita IA, y cuando se despliega con gobernanza, ahorra casi dos millones de dólares por incidente.
La dimensión más extrema de esta escalada ya está documentada: en 2026, un modelo de IA encontró autónomamente más de 1.000 vulnerabilidades críticas que habían sobrevivido décadas de revisión humana, y generó 181 exploits funcionales donde el modelo anterior había logrado 2, a un coste de decenas de dólares por operación. Cuando el gobierno de EEUU restringe el acceso a ese modelo como activo de seguridad nacional, no está respondiendo a una posibilidad teórica.
El verdadero problema no es tecnológico. El 63% de organizaciones sin política de gobernanza de IA es el número más importante del panorama actual. Antes de comprar ninguna herramienta de seguridad con IA, la pregunta más urgente es: ¿qué hace la IA que ya hay en la organización, quién accede a qué y con qué controles?
Hay una variante que merece distinción: la prohibición estricta sin alternativa corporativa aprobada. No pertenece al 63% que no hace nada —es una política que produce el efecto contrario. Bajo presión de entregas, los equipos migran a cuentas gratuitas donde ningún proveedor firma confidencialidad de los datos. Y a largo plazo, el producto que evita integrar IA en su desarrollo por seguridad queda desarmado frente a atacantes que sí la usan. Quizás sea una premonición, pero hay bastantes argumentos que apuntan a: quien no adopta la IA hoy terminará comprando, incluso su mismo producto, a quien sí lo hizo.
Y para quien gestione agentes: los principios que evitan el goal drift (que el agente derive hacia objetivos que nadie autorizó) y la agencia excesiva (que actúe más allá de lo que se le delegó) en productividad son exactamente los mismos que evitan que esos agentes se conviertan en vectores de ataque. La seguridad y la gobernanza de agentes no son dos problemas distintos.
La IA no ha creado el problema de la ciberseguridad. Ha quitado el tiempo del que disponíamos para ignorarlo.
Fuentes verificadas
- CrowdStrike 2026 Global Threat Report (datos de actividad adversaria en 2025). Adversary Intelligence Team, CrowdStrike. Datos clave verificados: breakout time medio 29 min, récord 27 s, +89% operaciones adversarias con IA, inyección de prompts en +90 organizaciones, 82% de detecciones sin malware. crowdstrike.com
- Verizon Data Breach Investigations Report 2026 (DBIR). Verizon Business. Datos clave verificados: phishing lidera los vectores de acceso inicial en ataques AI-asistidos (44% de esas técnicas, a partir de datos de Anthropic sobre 793 actores adversarios); actores con asistencia GenAI usan mediana de 15 técnicas MITRE distintas; 62% de brechas con elemento humano (era 60%); ransomware en 48% de brechas (era 44%); 45% de empleados usan IA en dispositivos corporativos de forma regular (67% vía cuentas personales). verizon.com/business/resources/reports/dbir
- FBI Internet Crime Complaint Center (IC3) — 2025 Internet Crime Report. Cubre crímenes reportados al IC3 durante 2025. Datos clave verificados: pérdidas totales $20.877 B (superan $20B por primera vez); pérdidas por Business Email Compromise: $3.046 B (24.768 denuncias); pérdidas por fraude de inversión: $8.648 B (la categoría más alta). Serie histórica BEC: $2.95B (2023) · $2.77B (2024) · $3.05B (2025). ic3.gov
- IBM Cost of a Data Breach Reports (ediciones 2019–2025). Ponemon Institute. Serie histórica usada en el gráfico de coste de brecha: 3,92 M$ (2019) · 3,86 M$ (2020) · 4,24 M$ (2021) · 4,35 M$ (2022) · 4,45 M$ (2023) · 4,88 M$ (2024) · 4,44 M$ (2025). Datos clave de la edición 2025 (600 organizaciones, marzo 2024–febrero 2025): EEUU 10,22 M$, ahorro con IA defensiva 1,9 M$ / 80 días, sobrecosto Shadow AI 670.000 $, 97% sin controles de acceso IA, 63% sin políticas de gobernanza. ibm.com/reports/data-breach
- OWASP Top 10 for LLM Applications 2025 — LLM01: Prompt Injection. Vulnerabilidad número 1; directamente relacionada con el vector de prompt injection en agentes corporativos descrito en este artículo. genai.owasp.org
- MITRE ATLAS™ (Adversarial Threat Landscape for AI Systems). Catálogo de tácticas, técnicas y procedimientos (TTPs) específicos de ataques a sistemas de aprendizaje automático e IA, mantenido por MITRE con contribuciones de organizaciones de seguridad e investigación. Es el marco de referencia donde viven las técnicas MITRE citadas en el Verizon DBIR 2026 (“actores GenAI usan mediana de 15 técnicas MITRE distintas”). No aporta datos estadísticos propios; su valor es como taxonomía autoritativa para clasificar y entender los vectores de ataque contra sistemas IA. atlas.mitre.org
- Anthropic Red Team — Claude Mythos Preview: evaluación de capacidades de ciberseguridad (abril 2026). Informe técnico del equipo de seguridad de Anthropic. Datos clave: 181 exploits funcionales en benchmark Firefox vs 2 de Opus 4.6; más de 1.000 vulnerabilidades críticas identificadas; CVE-2026-4747 (FreeBSD NFS, 17 años, RCE sin autenticación); vulnerabilidad OpenBSD SACK (27 años); H.264 FFmpeg (16 años); 89% de precisión en validación de severidad sobre 198 reportes revisados manualmente. red.anthropic.com
- Cloud Security Alliance — Research Note: Claude Mythos and the AI Autonomous Offensive Threshold (2026). Análisis del umbral operacional de Mythos por la CSA. Datos clave: coste de exploits Linux por debajo de 2.000 $; survey de vulnerabilidades por debajo de 50 $; campaña de espionaje con agentes Claude jailbroken en noviembre 2025 (80-90% autónoma, 30 organizaciones). labs.cloudsecurityalliance.org
- Anthropic — Anuncio oficial de Claude Fable 5 y Mythos 5 (junio 2026). Comunicado corporativo de Anthropic describiendo las capacidades, el programa Glasswing y los controles de acceso de ambos modelos. Fuente primaria de la empresa sobre sus propios productos; no es evaluación independiente. anthropic.com
- Anthropic — Many-shot jailbreaking (abril 2024). Estudio del propio equipo de Anthropic sobre la técnica de jailbreak por acumulación de ejemplos en contexto largo: la probabilidad de rechazo del modelo cae de forma aproximadamente exponencial al aumentar el número de demostraciones de comportamiento prohibido. Publicaron la investigación —incluyendo mitigaciones— antes de que la técnica fuera explotada masivamente. anthropic.com/research/many-shot-jailbreaking
- AWS Continuum (Amazon Web Services, 17 de junio de 2026). Sistema autónomo de gestión de vulnerabilidades: descubre, prioriza, valida y remedia hallazgos de seguridad con intervención humana limitada. La validación activa construye pruebas de explotación funcionales en entorno aislado para confirmar qué vulnerabilidades son realmente explotables. Agnóstico al modelo; incorpora modelos de frontera incluyendo Claude Mythos según la tarea. Modo de aprendizaje (humano en el bucle) y modo de cumplimiento (automatización progresiva). aws.amazon.com · SiliconAngle
Lecturas opinables
- El CTO de Dell detalla cómo integrar agentes de IA en el flujo de trabajo con identidad propia y autorización controlada — Entrevista a John Roese (CTO y Chief AI Officer) y John Scimone (CSO) de Dell Technologies. Perspectiva de un despliegue real a escala: arquitectura federada de dos anillos, confianza cero desde el diseño, identidad única por agente. Sin datos numéricos verificables; el valor está en el relato de implementación de uno de los mayores proveedores de infraestructura corporativa. El Español / Invertia
- Operar a velocidad de máquina: la nueva regla de la ciberseguridad — Carlos Cervantes, Director de Ciberseguridad KPMG Technology Services Americas. Columna de opinión sin cifras verificadas pero con un marco conceptual sólido sobre la necesidad de sistemas adaptativos. Expansión
- Anthropic lanza una versión “segura” de Mythos, el programa que ha puesto en guardia a todo el planeta — Manuel G. Pascual, El País, 10 de junio de 2026. Descripción del lanzamiento de Fable 5 y reacciones de expertos de Fortinet y TrendAI sobre el impacto real en ciberseguridad.
- Anthropic suspende el acceso a sus modelos más avanzados de inteligencia artificial por el veto de EE UU a los extranjeros — Jesús Sérvulo González, El País, 13 de junio de 2026. Contexto de la directiva de exportación, la tensión Anthropic-Pentágono y las implicaciones para el sector.
- Anthropic’s Claude Mythos Finds Thousands of Zero-Day Flaws Across Major Systems — The Hacker News, abril 2026. Cobertura técnica del red team report de Anthropic. thehackernews.com
- Mythos, el nuevo modelo de IA de Anthropic que preocupa a gobiernos y bancos — BBC Mundo. Análisis del impacto en ciberseguridad e interrogantes sobre si Anthropic exagera las capacidades. bbc.com/mundo
- Anthropic amplía el acceso a Mythos a 150 organizaciones de 15 países, España incluida — El Diario, 13 de junio de 2026. Cobertura del alcance geográfico de Glasswing y contexto para el lector español. eldiario.es
- Scoop: Trump admin blocks foreign access to Anthropic’s most powerful AI — Axios, 12 de junio de 2026. Cobertura americana de la decisión de los controles de exportación; fuente de referencia en medios de Washington DC. axios.com
- Vulneran la seguridad de Claude Fable 5 en menos de 48 horas para extraer manuales de ciberataques y procesos químicos — Europa Press / PortalTIC, 12 de junio de 2026. Descripción del pack hunt de Pliny the Liberator: técnicas empleadas, información extraída y filtración del system prompt de 120.000 caracteres. infobae.com
- Anthropic’s Claude Fable 5 Alleged Jailbreak to Generate Stack Exploits — CyberSecurityNews, junio 2026. Cobertura técnica en inglés del mismo incidente, incluyendo la posición de Anthropic sobre qué constituye un bypass “real” de los sistemas de seguridad de base. cybersecuritynews.com
- “Todos los componentes para crear agentes capaces de planificar ataques ya existen” — Entrevista con Richard Marko, CEO de ESET, El Español / Invertia, 18 de junio de 2026. El CEO de una de las principales empresas europeas de ciberseguridad describe el balance actual (defensores adelantados por ahora), las AI Skills como nueva superficie de ataque, y la apuesta de la compañía —40 millones de euros en tres años— por modelos especializados en seguridad frente a soluciones generalistas con capa de seguridad encima. elespanol.com
← Artículo anterior: La trampa del agente libre · Volver al índice: Presentación de la serie · Artículo siguiente: La regulación de la IA →
