Apache Kafka
Apache Kafka o simplemente Kafka sirve para encolar mensajes (datos) y es muy usado en arquitecturas Big Data como intermediador de datos entre sistemas (entre procesos ETL, “Data Lakes”, etc.) por su robustez, su alta disponibilidad, su tolerancia a fallos, por ser distribuido, escalable y por encolar tareas para que el sistema las procese cuando lo requiera y pueda (salvando el resto de los procesos de datos de un colapso y evitando la pérdida irremediable de datos), además, que ofrece un alto rendimiento y una baja latencia.
Índice
- Apache Kafka: Teoría.
- Instalar Apache Kafka: Instalación y consola.
- Consumidores y Productores de Apache Kafka con Java y Python: Ejemplos de código.
- Clúster Apache Kafka tolerante a fallos y alta disponibilidad: Configuración de brókeres y sistema distribuido.
Cuando se habla de Kafka se dice que es una cola ¿Y cómo piensas que es Kafka? Pues quizás pensemos que es la típica cola de clientes con carrito de los supermercados cuando van a pagar a una caja registradora y podría ser un uso de Kafka, pero, sinceramente, para una cola simple no merece la pena usar Kafka.
Entonces ¿Qué tipo de cola es Kafka? Kafka no es una cola ¡Es mucho más que una cola! Kafka es un gestor de colas y también es las colas que gestiona.
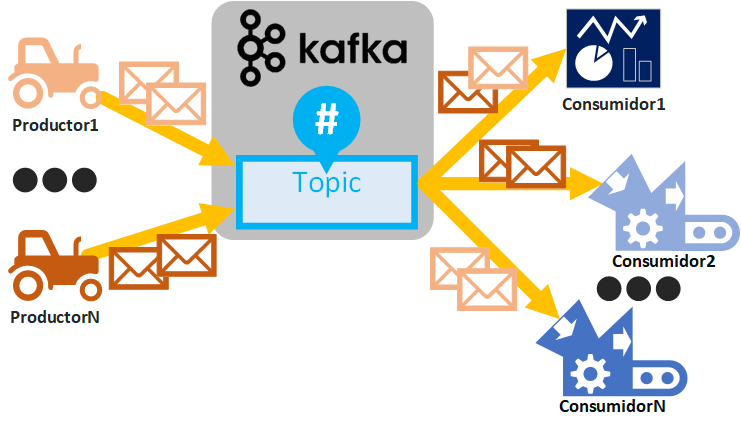
Para tener una primera idea rápida, supongamos lo siguiente: por un lado, tenemos tractores robotizados que recogen de nuestro campo de manzanos las manzanas (rojas y verdes), por otro lado, tenemos varias máquinas empaquetadoras de manzanas que esperan a las manzanas para ser empaquetadas y enviarlas al almacén; podríamos programar a cada tractor que descargue las manzanas en cada empaquetador, pero ¿Y si los empaquetadores son más lentos que los tractores trayéndoles manzanas? Tendríamos un cuello de botella, por otro lado ¿y si tenemos muchos más empaquetadores que tractores? Necesitaremos una manera de distribuir el conjunto de las manzanas de todos nuestros tractores. Para actuar de intermediario de manzanas, tenemos a Kafka que almacenará todas las manzanas que le manden los Tractores (Productores de Kafka) y se encargará de distribuir las manzanas a todas las empaquetadoras (Consumidores de Kafka).

Este es un ejemplo muy rápido y básico con algo real: las manzanas. Aunque Kafka nunca recibirá manzanas, sino mensajes (quizás sea la información recogida por los sensores de nuestros tractores robotizados, como la cantidad de manzanas recogidas por parte de los tractores o su color; por otro lado, los consumidores podrían ser cuadros de mando con gráficas sobre el estado de los tractores y las manzanas que han recogido, para que un solo operario controle a una flota completa de tractores robotizados). Además, que el ejemplo de los “objetos reales” (las manzanas) se me queda corto, pues Kafka puede hacer mucho más que no se puede hacer con “objetos reales”, como copiar todas las manzanas que le han llegado a otro lugar, para que en caso de que una de las copias falle, tener otra de respaldo y nunca dejar de producir ni consumir manzanas (alta disponibilidad).
Por qué Kafka
¿Por qué usar Kafka? Cuando se tiene una fuente que envía datos en flujo (streaming) que queremos que estén disponibles temporalmente y sea muy rápido para ser leídos en tiempo real por alguien, entonces necesitamos Kafka. Por ejemplo, las redes sociales, como LinkedIn (quien creó Kafka y la usa bastante como podemos ver en https://engineering.linkedin.com/blog/2016/04/kafka-ecosystem-at-linkedin) usan la cola de Kafka encolar los eventos (como los posts).
¿Y por qué no utilizar una base de datos? Pues porque la conexión a una base de datos es más lenta (la base de datos almacena los datos para “siempre” en contra de Kafka que es “temporal”), Kafka se utiliza como intermediario entre un sistema lento de consulta como una “base de datos” (o Hadoop) y el consumidor; también para que le dé tiempo a consumir a los sistemas lentos los datos y que no se pierdan (imagina que tienes un millón de tractores robotizados en tus campos enviando datos a tus servidores, la base de datos puede saturarse si se envían directamente, pero si los tractores los envían a una cola de Kafka, que es muy rápida, entonces la base de datos puede tardar lo que quiera en guardar los datos que obtendría desde Kafka).
Pero ¿Quién usa Kafka? No voy a decir todas, pero podría poner la mano en el fuego que la gran mayoría de las grandes compañías usan software para el encolamiento de mensajes (y la compañía de un buen tamaño que no lo use, tendría que planteárselo seriamente, entre otras cosas por la ventaja competitiva por el gobierno de sus datos) y, entre todas estas compañías, Kafka tiene una gran adopción por ser Open-source (y si no usan directamente Kafka, quizás sí que utilicen otras soluciones basadas en Kafka, como Confluent). Algunas de las compañías más populares que usan Kafka, que posiblemente te suenen son: The New York Times, Pinterest, Adidas, Airbnb, Barckays, Cisco, Foursquare, Lindekdin, Twitter, Netflix, Firefox, Oracle, PayPal, OVH, Salseforce, Strava, Spotyfy, Trivago, Tumlr, Wikipedia, etc. Y estas son solo unas pocas que directamente no solo usan Kafka, sino que lo patrocinan pues las he extraído de la página oficial: https://kafka.apache.org/powered-by.
¿Qué objetivos ayuda a conseguir Kafka en la transmisión de nuestros datos (Pongo “ayuda” pues, aunque algunos los logra Kafka por sí mismo con una buena configuración, otros necesitan de una arquitectura bien diseñada para que se consigan con Kafka como facilitador)?:
- Tolerancia a fallos: Con Kafka bien configurado, si un servidor falla, el resto de los servidores seguirán proporcionando el servicio, con todos los datos, sin perder ninguno.
- Distribución: Con recursos y una buena configuración de Kafka, los datos distribuidos en diferentes servidores reducen la carga de uno solo y brindan una tolerancia a fallos robusta.
- Alta disponibilidad: si la tolerancia a fallos y la distribución es buena, entonces tendremos una alta disponibilidad de nuestros datos.
- Escalable: Si necesitamos más recursos, basta con levantar más instancias y Kafka se encarga del resto, redistribuyendo los datos.
- Idempotencia: Con una buena programación de los conectores y el código, aseguraremos muchísimo que los datos de la fuente y el sumidero serán los mismos, sin repeticiones y sin faltar datos.
- Orden: Con una buena comprensión de Kafka se logra el orden de los datos.
- Alto rendimiento: Optimización para el paso rápido de mensajes, sin mucha latencia. Quizás esto sea lo que menos tendremos que configurar a nivel de Software y más dedicar a nivel de Hardware, pues dependerá de nuestra red si es distribuido o de la velocidad de procesado que dependerá del procesador, discos duros, etc.
¿Qué Patrón usa? Kakfa usa los patrones de mensajería de microservicios:
- Colas de mensajes: conexión de componentes y servicios distribuidos y en la nube, con un acoplamiento flexible que maximice la escalabilidad. Comunicación asíncrona que desacople servicios (Productor y Consumidor sin interacción directa), comunicación en tiempo real y notificación del estado de la comunicación.
- Publicador-Subscriptor: Una aplicación envía mensajes de manera asíncrona a varios Consumidores, sin empajar Productores con los Consumidores.
Topic (tema), Partición, Bróker
Podríamos pensar en los Topics de Twitter (las frases comenzadas por almohadilla “#” o quizás te suene el termino de “trending topic”) donde cada mensaje está clasificado por su Topic y si pinchamos en un Topic se filtra por esos mensajes. Pues un Topic en Kafka es semejante, aunque éste Topic de Kafka se encuentra antes de que se te muestre el resultado y también antes de que se filtre, pues directamente son los mensajes encolados y clasificados por un Topic determinado, listos para ser consumidos por un Consumidor (siguiendo con el ejemplo de Twitter, deberemos cambiar la forma de pensar y entender que cuando pinchas en un Topic de Twitter no hay un filtro, sino que directamente se consumen desde el Topic de Kafka ya preparado; advierto que esto es un ejemplo y que no sé si Twitter usa Kafka por debajo para esto, solo es para entenderlo de una manera que espero sea más sencilla). Los Productores van a escribir mensajes en un Topic y los Consumidores van a leer los mensajes de un Topic determinado. Podremos tener múltiples Productores y Consumidores escribiendo y leyendo mensajes de diferentes Topics.
Si solo vas a programar Productores y Consumidores de Kafka te puedes saltar el resto de explicación de Topic (pues es la “caja negra” donde se meten cosas y se sacan), aunque siempre recomiendo entenderlo todo para explotar al máximo sus ventajas y saber evitar sus limitaciones.
El Topic lo es “todo” en Kafka, lo demás orbita a su alrededor (Consumidores, Productores, Brókeres, etc.), por lo que antes de comenzar a explicar cómo funciona un Topic debemos tener en la cabeza que un Topic:
- Es escalable mediante Particiones.
- Ofrece alta disponibilidad mediante el “Factor de replicación”.
Eso sí, en un entorno empresarial cumpliremos lo anterior si creamos un Topic correctamente y si tenemos la arquitectura necesaria (explicaré como hacer todo esto fácilmente y paso a paso). Ahora sí, empecemos con la definición de un Topic de Kafka.
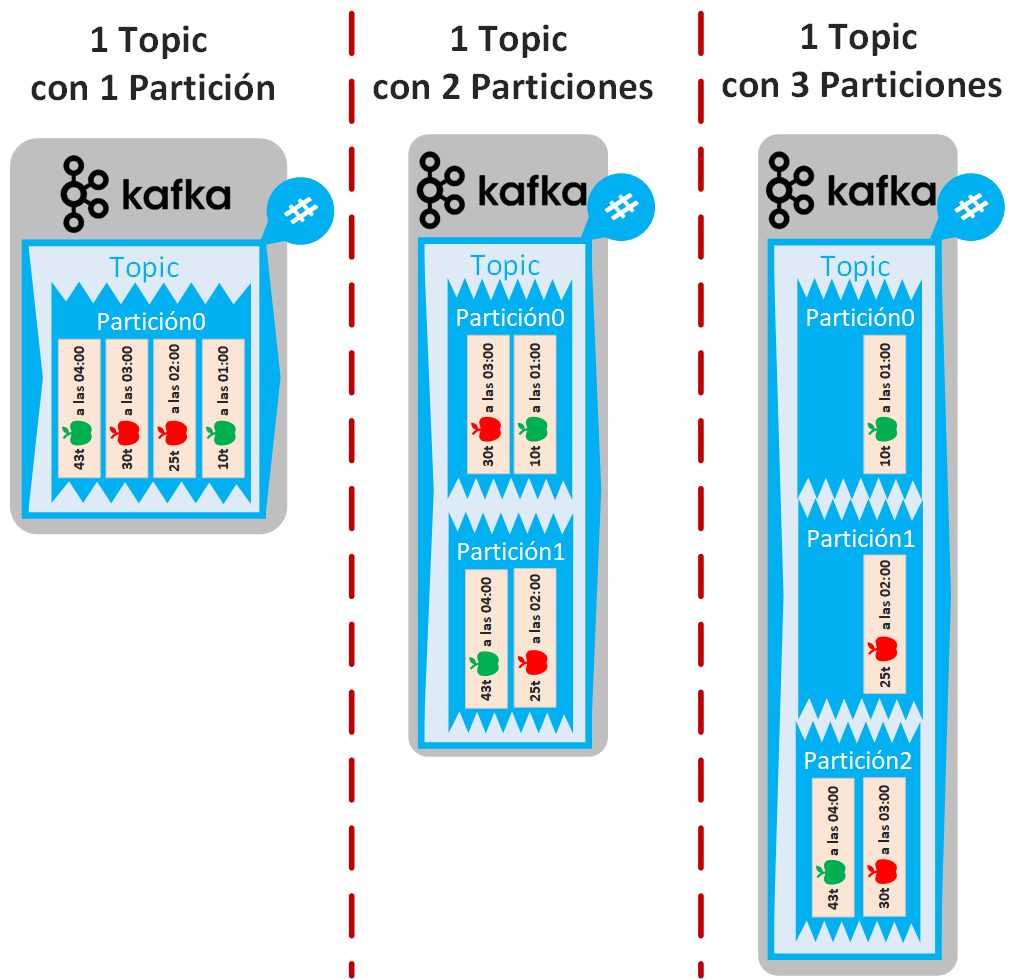
Un Topic (tema) está dividido en particiones (si no se define un número de particiones, por defecto un Topic siempre tendrá una partición). Diferentes Topics podrán tener diferentes números de particiones.
Por ejemplo, si creamos 1 Topic con 2 particiones sobre 1 Bróker:
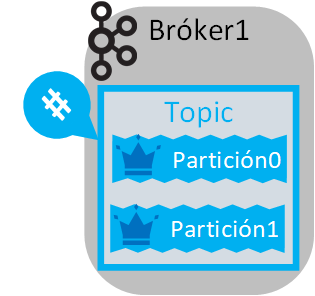
Una partición es una cola de mensajes del Topic (después de tanto hablar de la «cola de Kafka», esta es la verdadera «cola»). Si un Topic tiene una única partición significará que será donde se encolen todos los mensajes. Si un Topic tiene varias particiones, entonces todos los mensajes del Topic se distribuirán entre las particiones (será una distribución más o menos de manera equitativa, según un algoritmo).
Un concepto importante a entender es que en una cola los mensajes están ordenados según van entrando (es decir, que el primer mensaje que entra a la cola estará en la cabeza de la cola y será el primero en ser leído; el resto de los mensajes se van encolando detrás y se leen en orden de llegada). Como una partición es una cola, los mensajes están ordenados según su orden de llegada a cada una de las particiones y serán leídos empezando por el primer mensaje de cada una de las particiones, por lo que si hay más de una partición no se asegura el orden de entrega (consumo) de los mensajes. Si necesitamos asegurar el orden de los mensajes o bien nuestro Topic tiene una única partición o, si tenemos varias particiones, forzamos a que todos los mensajes vayan a la misma partición (esto se consigue con la Clave de los consumidores, como veremos).
En el ejemplo con dos particiones, los mensajes se encolarán en cada partición en orden de llegada, pero cuando los mensajes vayan a ser leídos se tomará cualquiera de los mensajes que ocupen la primera posición. Esto es importante, pues en muchos casos nos dará igual qué mensaje de cuál partición se lea el primero, es más, será una ventaja para el procesamiento en paralelo de mensajes; pero en otros casos sí que nos importará el orden de los mensajes (por ejemplo, si los mensajes son logs con la hora exacta, posiblemente nos importe el orden de los mismos).
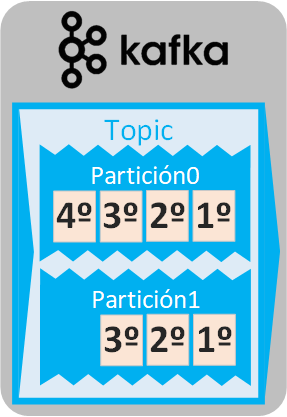
Una partición siempre tiene definido un “Factor de replicación” que no podrá ser mayor al número de Brókeres (si no se define un “Factor de replicación”, por defecto siempre será 1, que significa que se cree una partición).
Por ejemplo, 2 Particiones de un Topic, 2 Brókeres y un Factor de replicación de 2:

Un “Factor de Replicación” es la cantidad de veces que queremos que una partición esté replicada (copiando todos los mensajes que tenga) en otros brókeres diferentes. La partición principal se denomina “Líder” (en las imágenes lo represento pintando una corona), que será donde se conectarán los Consumidores y Productores, y todas las réplicas serán una copia en espejo del Líder (esto es, si se le añade un mensaje al Líder, automáticamente todas las réplicas tendrán dicho mensaje y si se elimina un mensaje del Líder, las réplicas también lo eliminarán). La partición Líder puede cambiar y convertirse una réplica en el nuevo Líder si, por ejemplo, se cae (o muere) el bróker donde se encuentra la partición Líder.
Por ejemplo, si el “Factor de Replicación” es 3 significa que tendremos “dos copias de seguridad de una partición” más la partición original (2 réplicas + 1 líder) en brókeres diferentes (necesitaremos de un mínimo de 3 brókeres):
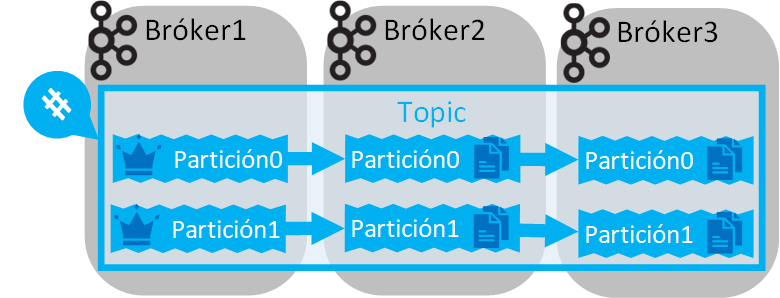
Un Topic hay que crearlo sobre un Bróker y Kafka se encargará de distribuir automáticamente sus particiones y replicarlas entre diferentes Brókeres.
Si hay varios Brókeres, entonces las Particiones de un Topic se distribuirán entre todos los Brókeres (que también será de manera equitativa, es decir, se intentará poner una partición por Bróker si hay suficientes o todas las particiones en el mismo Bróker si solo hay uno). Aunque primará distribuir a las Particiones replicadas.
Por ejemplo, podríamos tener un “Factor de Replicación” de 2 con 4 Brókeres (manteniendo las 2 particiones del Topic):
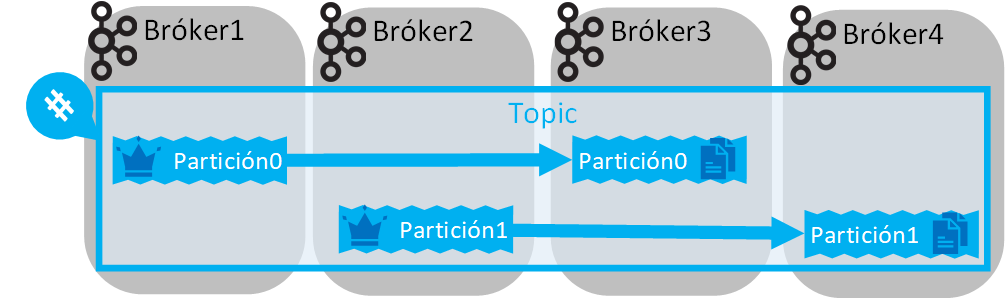
Aquí pueden surgir algunas dudas:
- ¿Cuántas particiones es bueno tener? Las menos posibles, pues la división de mensajes y su gestión requieren de más tiempo de procesado; pero las más posibles para tener multitarea, descongestionar la llegada de mensajes y que se puedan conectar más Consumidores en un “grupo de consumidores”. Esta duda se resuelve según la necesidad, los recursos disponibles y probando.
- ¿Cuál es el factor de replicación ideal? Lo ideal para producción es no menos de 3 (según la regla para minimizar riesgos casi a cero de copias de seguridad “3-2-1”, donde 3 son las copias replicadas de los datos, 2 deben ser las máquinas físicas diferentes y 1 máquina localizada muy lejos de las otras 2); pero a mayor factor de replicación se consumirá más disco duro (las réplicas son copias exactas de los datos, por lo que se consumirá las veces del número del factor de replicación que pongamos, esto es, si un Topic ocupa 1GiB, con un factor de replicación de 3 ocupará 3GiB). Para pruebas de desarrollo nos sobrará con un factor de replicación de 1, pero no para producción.
- ¿Cuántos brókeres debemos tener? Al menos tantos Brókeres como factor de replicación máximo que tenga alguno de nuestros Topics (si mañana queremos un Topic con más factor de replicación, deberemos levantar más Brókeres). A más Brókeres más recursos se consumen, por lo que es bueno ir teniendo más según las necesidades. Es interesante tener los Brókeres distribuidos en distintas máquinas (como se indicaba antes en la regla “3-2-1”, al menos 2 máquinas distintas y 1 adicional muy lejos de las otras 2, por lo que le pueda pasar a las 2 primeras ¿Cómo de lejos? Pues depende del riesgo que asumamos, lo peor que les puede pasar a nuestras máquinas es que les afecte una catástrofe natural gorda, si queremos prevenir esto deberemos tener alguna máquina con los datos a buen recaudo lo más lejos posible). Lo malo de los Brókeres distribuidos en diferentes máquinas es el consumo de red y el posible cuello de botella.
Productor de Kafka (Productor o Source en Conectores)
Los Productores envían mensajes a un Topic de Kafka.
Un menaje siempre se compone de un contenido que queramos enviar (un texto, un JSON, etc. Kafka trabaja a nivel de bites, le da igual lo que le mandemos como contenido del mensaje) y una clave (si no asigna clave alguna, por defecto es null, que a efectos será como si le asignara una clave única para cada mensaje, como veremos a continuación).
Un Productores se tiene que conectar a un Bróker de un Clúster de Kafka, para que le sea devuelto el listado de Brókeres accesibles al Productor que realizó la petición de conexión. En alguno de esos Bróker debe estar el Topic que el Productor quiera escribir. Si el Topic no existe, dependiendo de la restricción, se creará automáticamente en el Bróker o no estará permitido su creación.
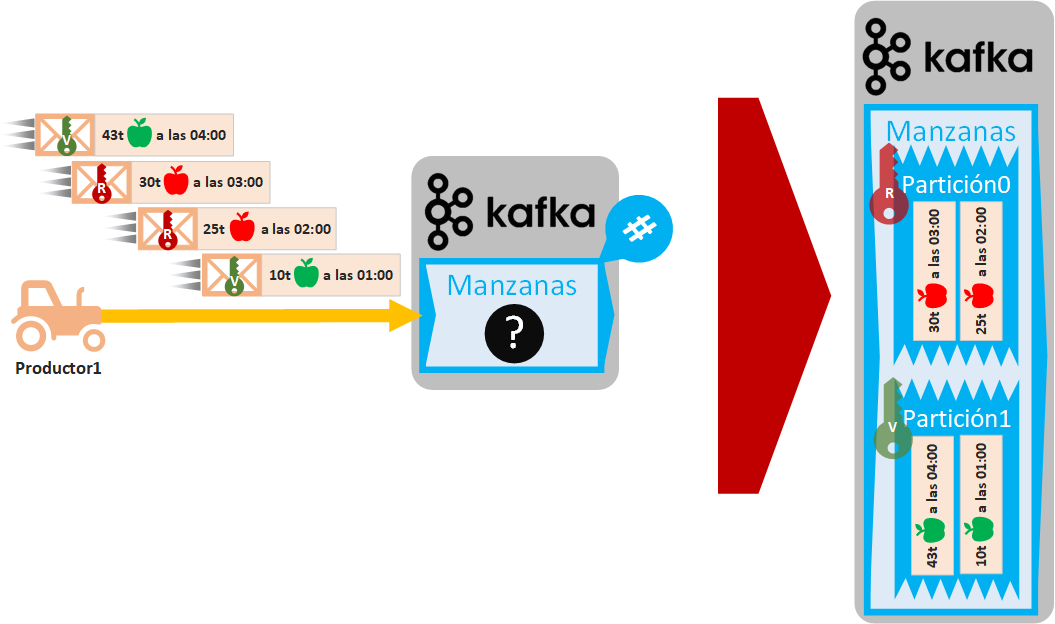
En el siguiente ejemplo el Productor (un tractor robotizado que recoge manzanas verdes y rojas de nuestro campo y cada hora envía un mensaje a nuestro servidor de Kafka) manda mensajes secuenciales (cada uno con la cantidad de manzanas recogidas en ese momento, el tipo de manzana y la hora) para que queden encolados en nuestro Topic de Kafka que hemos llamado “Manzanas” (el Productor desconoce cómo está configurado el clúster de Kafka, solo sabe a qué Topic enviarlo):

Aunque el Productor a nivel de Software desconoce cómo está configurado el Topic en el Clúster, el programador del Productor necesita conocer el funcionamiento de las particiones de un Topic y, en caso de necesitarlo, solicite más información a quien administre el clúster de Kafka.
Cuando un Topic recibe un mensaje, lo encola únicamente en una de las particiones de dicho Topic según la planificación Round-Robin (https://es.wikipedia.org/wiki/Planificaci%C3%B3n_Round-robin en resumen, es una asignación equitativa de mensajes entre las diferentes particiones; aunque se puede configurar otro tipo de planificación). Antes de seguir, recuerdo que las particiones podrían estar en diferentes Brókeres y, a su vez, los Brókeres podrían estar distribuidos en diferentes máquinas. También recuerdo que cada partición es una cola (el primer mensaje que entra será el primero en salir).
Por ejemplo, dependiendo de la configuración se podría dar alguno de los siguientes casos, dependiendo de las particiones que tenga nuestro Topic:
- 1 partición: Los mensajes se encolan según llegan y aseguramos el orden de salida de los mensajes cuando sean consumidos por un Consumidor.
- 2 particiones: Los mensajes se van encolando de manera equitativa, por lo que NO aseguramos el orden de salida (cuando el Consumidor vaya a consumir de este Topic podrá recibir en primer lugar cualquiera de los primeros mensajes de cualquiera de las particiones).
- 3 particiones: igual que con 2 particiones, pero con 3.
- Etc.
Como Productor tenemos cierto control sobre cómo se van a clasificar los mensajes entre las particiones y esto se realiza añadiendo una clave a cada mensaje. La gracia de esta clave es que NO debe ser única, ya que los mensajes que tengan la misma clave se nos asegura que se encolarán siempre dentro de la misma partición, de este modo, cuando un Consumidor obtenga los mensajes lo hará siempre en orden. Lo que no sabremos es si tal clave va a cuál partición, esto lo gestiona Kafka de manera transparente. Si solo hay una partición, pues la clave no sirve para nada. Como es posible que como programadores de Productores no sepamos cuántas particiones hay, lo conveniente es pensar que hay varias particiones, por lo que tendremos que programar el Productor teniendo esto en cuenta. Por ejemplo, si queremos que el tipo de las manzanas (rojo y verde) estén siempre clasificadas y ordenadas por partición, pues le añadiremos a cada mensaje una clave (podrá ser un número o un texto, en mi ejemplo he puesto “V” para las manzanas verdes y “R” para las rojas). Para mi ejemplo, he puesto dos particiones, por lo que las manzanas rojas irán a una partición y lar verdes a la otra siempre:
La clave tiene el inconveniente de evitar que los mensajes se distribuyan equitativamente entre particiones (la planificación Round-Robin no funcionará a nivel de mensaje), esto es, si tenemos muchas particiones en un Topic y todos los mensajes les ponemos la misma clave, entonces vamos a tener una única partición con todos los mensajes y el resto de las particiones estarán vacías.
Varios productores pueden enviar mensajes a la vez a un mismo Topic. Si varios Productores envían mensajes a la vez, no podremos asegurar un orden de los mensajes por Productor y todos los mensajes quedarán mezclados, aunque tengamos una única partición (quizás esto no tenga que ser tan indeseable como otros desórdenes, pero hay que tenerlo en cuenta). En el siguiente ejemplo, hemos comprado un tractor robotizado más, por lo que tendremos 2 Productores enviando mensajes, de los cuales los que coinciden en hora se envían a la par, por lo que, si nuestro Topic “Manzanas” se encolarán de manera aleatoria para los mensajes que se envían por ambos Productores a la misma hora (en el ejemplo pongo 1 partición para que se vea la intercalación, pero podría haber cualquier número de particiones).
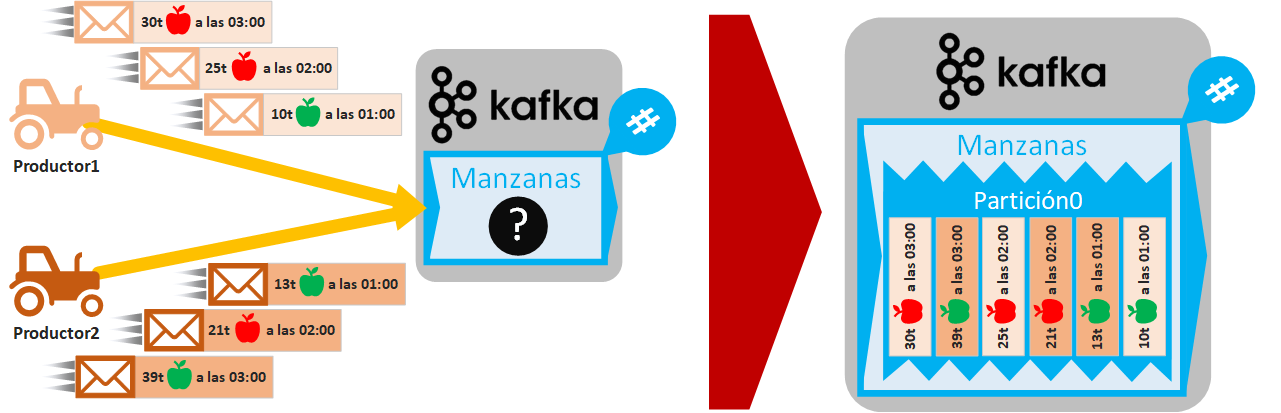
Como podrás imaginar, si añadimos claves a los mensajes y hay más de una partición, como antes, podremos clasificar por tipo de manzana, aunque si los Productores mandan cada uno un mensaje con la misma clave, se encolarán de manera aleatoria en la misma partición. Otro ejemplo de clasificación diferente es que queramos que todos los mensajes de cada Productor estén por separado en cada partición, es cuestión de jugar con las claves para lo que queramos.
Un Productor siempre obtiene mensajes de una Fuente (Source) de datos como:
- Mensajes (no de Kafka): como los de las redes sociales o para comunicación de microservicios.
- Actividades: como el seguimiento de la actividad web o de los videojuegos.
- Streaming: de datos en tiempo real o de procesado (como ETL).
- Métricas: mediciones, como de campañas de marketing (como el tráfico de una web) o de sensores.
- Eventos: como de IoT (Internet de las cosas).
- Logs: como de auditoría o de sistemas.
- Datos: de bases de datos o de Data Lakes.
- APIs: por ejemplo, podríamos consultar al API de Twitter para obtener todos los mensajes de cierto hilo.
- Un Topic de Kafka: Los datos pueden ser consumidos de un Topic, procesados y vueltos a enviar a otro Topic o incluso a otro clúster de Kafka.
Un Productor se pueden programar en diferentes lenguajes como Java, Python, por Shell, etc. (como veremos más adelante). O utilizar un conector de ya hecho (todos los conectores disponibles de Kafka se encuentran en https://www.confluent.io/es-es/product/connectors/).
Consumidores de Kafka (Consumer o Sink en Conectores)
Los Consumidores leen mensajes de un Topic (tema) de Kafka.
De manera semejante los Productores, un Consumidor se tiene que conectar a un Bróker de un Clúster de Kafka, para que le sea devuelto el listado de Brókeres accesibles al Consumidor que realizó la petición de conexión. En alguno de esos Bróker debe estar el Topic que el Consumidor quiera leer.
Un Consumidor recibirá mensajes de una o varias particiones de un Topic. En la siguiente imagen de ejemplo Kafka, va enviando mensajes de un Topic de uno en uno y el Consumidor que los recibe los va procesando a la vez (en cuanto recibe un mensaje lo procesa, en tiempo real). En la siguiente imagen de ejemplo, el Consumidor es una máquina empaquetadora industrial, que crea cajas con cada una de las manzanas (esto es un ejemplo simplificado de realizar ETL a los mensajes y extraer de cada String de cada mensaje el valor numérico y el color de la manzana, desechando la hora). Como los Productores, el Consumidor no conoce las particiones del Topic, pues le dan igual, solo quiere mensajes y procesarlos:

En este punto da igual que detengamos el proceso Consumidor, que lo volvamos a activar en un segundo que después de un montón de tiempo (siempre que no se exceda del “tiempo de retención”). Siempre que volvamos a activar nuestro Consumidor, leerá los siguientes mensajes de Kafka (sin repetir los mensajes que ya leyó previamente), todo esto sin guardar estados, ya que quien guarda el estado es Kafka con un puntero llamado “Offset” (de desplazamiento).
El “tiempo de retención” es un tiempo máximo que puede estar un mensaje encolado en un Topic de Kafka, pasado ese tiempo (que es configurable), el mensaje será eliminado haya sido leído o no. Los mensajes no están eternamente en Kafka para no llenar los discos duros, porque ya se habrán procesado, para eliminar mensajes antiguos que ya no sean importantes (por ejemplo, si en Kafka guardamos datos del tiempo atmosférico de hoy, cuando sea mañana, lo de ayer ya no nos querremos ni procesarlo por no importarnos ya) y para aligerar carga al propio Kafka.
El “Offset” (Desplazamiento) es un puntero que guarda el último mensaje enviado de un Topic a un “grupo de Consumidores” (“consumer group”, lo veremos un poco más adelante). Dicho de otra forma, los mensajes enviados, se marcan como enviados en el Topic (ojo, NO se guarda en los Consumidores) y ya no se vuelen a enviar a los Consumidor que pertenezcan a un mismo “grupo de consumidores” (ya que se supone consumidos previamente por algún Consumidor del “grupo de consumidor”).
De este modo, en nuestro ejemplo anterior, existirá un Offset que indique los mensajes enviados al Consumidor del Topic del que está recibiendo dichos mensajes:
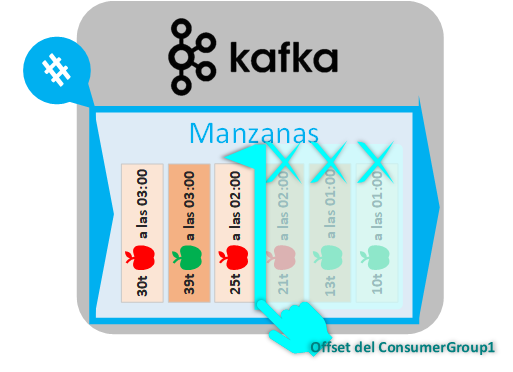
Un Consumidor siempre va a estar agrupado dentro de un “grupo de consumidores” (“consumer group”).
Un “grupo de consumidores” es un conjunto de Consumidores que cooperan para consumir datos de alguno o algunos de los Topics. Si no se define un grupo de consumidores, por defecto todos los Consumidores pertenecerán al mismo.
Los Consumidores dentro de un mismo “grupo de consumidores” siempre recibirán mensajes diferentes del Topic (es decir, que sendos Consumidores de un mismo “grupo de consumidores” no recibirán el mismo mensaje).
Para nuestro ejemplo anterior, el Consumidor1 siempre había pertenecido a un “grupo consumidor” que he llamado ConsumerGroup1, por lo que si añadimos un nuevo Consumidor2 al mismo grupo y Kafka nos envía el resto de los mensajes, los mensajes se dividirán equitativamente entre todos los Consumidores pertenecientes al grupo. Y, como cabría esperar, el offset del “grupo de consumidores” se desplazará para marcar los mensajes enviados.
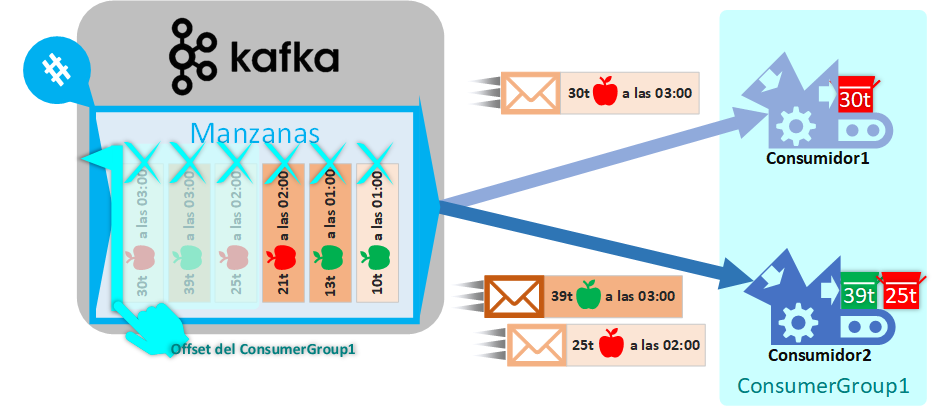
Cada “grupo de consumidores” tendrá su propio puntero Offset, por lo que los consumidores de diferentes “grupos de consumidores”
Para nuestro ejemplo, si añadimos un nuevo “grupo de consumidores” ConsumerGroup2 y le añadimos un Consumidor, éste empezará a recibir todos los mensajes del Topic desde el inicio (realmente, por defecto, un Consumidor que se conecta ahora va a empezar a leer mensajes nuevos que lleguen, no los pasados, aunque este comportamiento es configurable y para el ejemplo se ve más claro si se consumen desde el inicio), pues el Offset de este grupo nuevo estará apuntando al primer mensaje y avanzará desde el inicio a medida que se los envíe.

Existen maneras de mover el Offset de un “grupo de consumidores”, aunque no es recomendable mover el Offset, solo con fines de desarrollo, o de reprocesar mensajes que lo fueron previamente y que por alguna razón haya que volver a Consumirlos y procesarlos
Un “grupo de consumidores” podrá tener uno o varios Consumidores, pero no deberá haber más Consumidores dentro del “grupo de consumidores” que Particiones Líder tenga el Topic que queramos leer (los Consumidores de más no recibirán mensajes y las particiones replicadas no cuentan para este máximo). Las particiones Líder de un Topic se asignan a los Consumidores del “grupo de consumidores” (de manera equitativa).
Por ejemplo, si el Topic tiene 3 Particiones, podremos tener hasta un máximo de 3 Consumidores dentro de un “grupo de consumidores” (más no, pues no existen más Particiones que asignar a un Consumidor). En nuestro ejemplo, el ConsumerGroup1 tenía 2 Consumidores, por lo que 1 Partición se asignará a un Consumidor y las otras 2 al otro Consumidor. Mientras que, para el ConsumerGroup2, como tiene solo un Consumidor, se le asignarán todas las particiones:
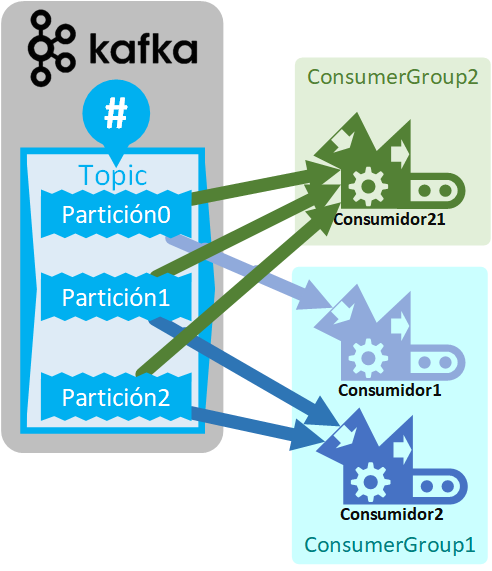
Un “grupo de consumidores” podrá recibir menajes de diferentes Topics.
Los Consumidores se pueden escalar fácilmente, por lo que, si por ejemplo tenemos un Consumidor de un “grupo de consumidores” que consume más lento los datos de lo que se producen en el Topic, es recomendable crear otro Consumidor en el mismo “grupo de consumidores” para que procesen datos en paralelo de este Topic y así acelerar el procesado de la cola Kafka (entonces, las particiones se reasignaran entre todos los Consumidores del “grupo de consumidores”). Si un Consumidor falla o se quita del grupo, el resto de los Consumidores recibirán los mensajes que iban destinados a este (se le reasignan las particiones entre los Consumidores que queden en el “grupo de consumidores” automáticamente). Cuando se reasignan particiones a los Consumidores de un “grupo de consumidores” se denomina Reequilibrio y durante el reequilibrio no se pueden consumir mensajes.
Todos los Consumidores envían sus mensajes a un sumidero (Sink) de datos, como (que podría coincidir con la Fuente de datos o no):
- Bases de datos: se podría analizar cada dato encolado para discernir si persistirlo en una base de datos tradicional (MySQL, MariaDB, Oracle SQL, etc.), de Big Data (Hbase, Bigtable, Hadoop, HDFS, etc.) o extraer cierto dato para enviarlo a alguna dedicada (NeoJ, MongoDB, etc.).
- Analíticas y auditorias: podríamos generar informes y visualizaciones (cuadros de mando) con estadísticas en tiempo real a medida que la cola Kafka los devuelve.
- Sistema de mensajes (post de redes sociales, Email, notificaciones, etc.): serían los datos encolados en Kafka enviados desde los usuarios al sistema (como los posts que se suben a una red social por los usuarios, se pasarían a una cola Kafka y serían consumidos por el sistema que los procesa para diferentes fines: filtrar spam, detectar palabras clave, etc.)
- Procesado ETL: podremos tener procesos intermedios que consuman mensajes de Kafka, los procesen y los manden a otro sitio (o los vuelvan a encolar en el mismo u otro Topic).
- Un Topic de Kafka: Los datos pueden ser consumidos de un Topic, procesados y vueltos a enviar a otro Topic o incluso a otro clúster de Kafka.
Al igual que los Productores, un Consumidor se pueden programar en diferentes lenguajes como Java, Python, por Shell, etc. (como veremos más adelante). O utilizar un conector de ya hecho (todos los conectores disponibles de Kafka se encuentran en https://www.confluent.io/es-es/product/connectors/)
Semánticas
Los sistemas de mensajería de publicación-suscripción distribuida aseguran un alto grado de fiabilidad, pero no son perfectos, que todos los mensajes existentes se entreguen el 100% es complicado, Kafka asegura una alta fiabilidad, pero habrá que diseñar cuidadosamente los Consumidores y Productores para asegurar la idempotencia (datos no repetidos y todos los datos).
Semánticas en Kafka:
- At most once (Una vez como máximo): Si los mensajes se pierden, nunca se vuelven a enviar. Si el cliente es un Productor, este envía cada mensaje a Kafka una única vez; si es un Consumidor, en cuanto Kafka le envía el mensaje desplaza el Offset.
- At least once (Al menos una vez): Si los mensajes se pierden, se vuelven a enviar, pudiéndose enviar varias veces el mismo mensaje. Si el cliente es un Productor, envía mensajes a Kafka y reciben una confirmación de recepción (ACK), si no recibe la confirmación en un tiempo, se vuelve a enviar el mensaje; Si es un Consumidor, es éste quien envía la confirmación de recepción a Kafka (si recibe el ACK desplaza el Offset, sino vuelve a enviar el mismo mensaje otra vez).
- Exactly once (exactamente una vez): Asegurar que el mensaje se envíe una vez y solo una vez. Requiere cooperación entre Productores, Consumidores y Kafka.
Más información sobre las semánticas en: https://kafka.apache.org/documentation/#semantics
Bróker, Zookeper, Quorum y Clúster de Kafka
Los Topics de Kafka se crean y todas sus particiones son mantenidos por un proceso llamado Bróker que está iniciado sobre una máquina (esta máquina puede ser desde tu ordenador, a un servidor, una máquina virtual, etc.).
Los brókeres de Kafka solo almacenan arrays de bytes pues actúa de búfer de datos. Guardar los datos como arrays de bytes otorga versatilidad a Kafka, pues dichos arrays de bytes podrán ser cualquier cosa (textos, imágenes, canciones, objetos Java o Python, etc.). Por tanto, todo (mensajes y claves) lo que mandemos a un bróker como Productores lo tendremos que convertir (codificar) previamente a arrays de bytes (codificar una estructura de datos cualquiera a un array de bytes se denomina “serializar”); y los mensajes que obtengamos de un bróker como Consumidores deberemos reconvertirlo (decodificar) al tipo de datos que queramos (decodificar un array de bytes a una estructura de datos se denomina “deserializar”).

Podremos tener uno o varios Brókeres gestionando el mismo Topic. Si tenemos más de un Bróker, en un Bróker podrá estar la Partición Líder y en otros las copias, por lo que se considerará que el Topic está distribuido a nivel local.
Siempre hay al menos un Bróker que será el Coordinador. El Bróker coordinador será el encargado de escuchar los latidos (heartbeats) de los clientes (Consumidores, Productores y los otros Brókeres) para saber si los clientes siguen vivos. Un Latido puede ser un ACK o la petición de mensajes de un Consumidor, por ejemplo. Si un Bróker coordinador no recibe latidos en un tiempo de sesión de un cliente, se considerará que dicho cliente está muerto (si el cliente era un Consumidor, se iniciará el reequilibrio de particiones).
Como hemos dicho, cada Bróker es un proceso y todos Brókeres están gestionados por otro proceso llamado Zookeper. Zookeper almacena metadatos (ubicación de las particiones y configuración de los Topics), es quien decide qué partición de un Topic es Líder y se comunica con otros Zookepers (para Kafka distribuido en remoto). Dicho esto, un Bróker por si solo no funciona, un Bróker siempre necesita a Zookeper para funcionar.
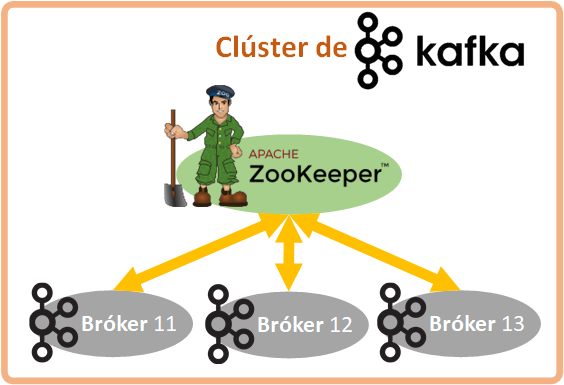
Nota sobre Zookeper: Cuando estaba escribiendo este artículo, los creadores de Kafka estaban trabajando en introducir Zookeper en el Bróker, para que no haya que depender de dos procesos por separado (es decir, que Bróker y Zookeper sean uno) y sea más fácil de usar Kafka. De cualquier manera, es importante en tender el concepto por separado de Bróker y Zookeper, pues los necesitaremos para entender cómo configurar Kafka y cómo trabajar bien con Kafka.
Todos los Brókeres comunicados entre sí mediante los Zookepers, es lo que se conoce como Clúster de Kafka.
Cuando un Productor o Consumidor se conectan a un Bróker del Clúster de Kafka, se le envían todos los Brókeres del clúster para que se pueda conectar directamente al que tiene la Partición Líder del Topic que necesita. Adicionalmente, una buena práctica es indicar en el Productor y Consumidor una lista de Brókeres por defecto (todos los Brókeres del Clúster, si es posible), por si hubiera algún Bróker no disponible en cierto momento, que el Productor o Consumidor pueda probar a conectarse al siguiente.
Tener una sola máquina para todo nuestro clúster de Kafka tiene mucho riesgo (todo en local), pues si esa máquina es destruida se perderá la disponibilidad de la información (por ejemplo, si nuestra web dependía de esos datos, pues ya no podrá dar servicio a los usuarios), además de que se perderán irremediablemente los datos que esa máquina tenía. La ventaja que nos da tener varios Brókeres en una sola máquina es la distribución de carga de trabajo entre procesos y que si uno de los procesos muere (por ejemplo, que el sistema operativo lo haya matado por falta de memoria), pues que no dejen de funcionar el resto de los Brókeres.
Si queremos distribuir nuestro clúster de Kafka en condiciones, entonces necesitaremos distribuirlo en varias máquinas remotas. Por lo que podremos tener Brókeres en diferentes máquinas, estando gestionados en cada máquina por un Zookeper diferente. Las diferentes máquinas, a nivel de Kafka, se comunicarán entre los Zookepers de cada máquina (con lo que llaman Quorum). De este modo, la Partición Líder de un Topic estará en una máquina y la copia en otra, en caso de destruirse una de las máquinas, Zookeper elegirá una nueva Partición como Líder (si fuera el caso que la máquina sobre la que estaba la partición Líder fuera la afectada), Kafka seguirá funcionando como si no hubiera pasado nada y en cuanto levantemos otra máquina con su Zookeper conectado al resto y con su Bróker, pues Kafka se redistribuirá solo (previas configuraciones). De manera semejante a las particiones de un Topic, cuando tenemos varios Zookepers (cada uno en su máquina), uno de los Zookepers es el Líder y el resto son Zookepers Seguidores de ese Líder. Todos los Zookepers de clúster conocen dónde están el resto, por lo que si un Zookeper falla (por ejemplo, la máquina arde), pues se reasigna el Líder si es necesario y Kafka sigue funcionando como si no hubiera pasado nada.
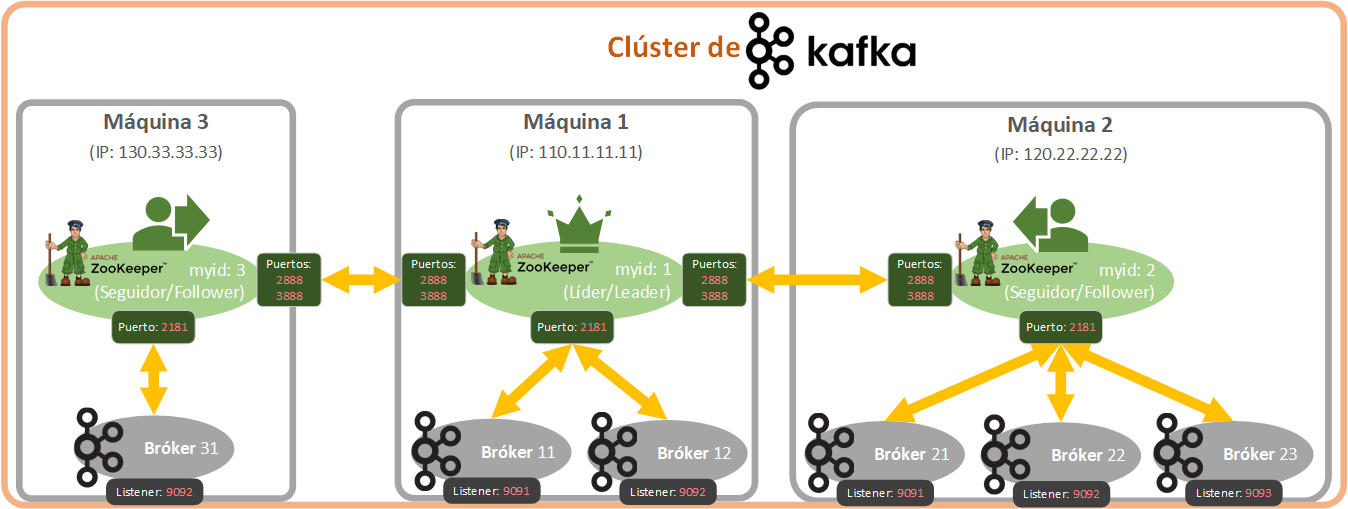
En la anterior imagen he añadido los puertos, pues es importante que nos suene al menos los que nos importan, ya que hay puertos de comunicación entre Zookepers (por defecto: 2888 y 3888), para comunicar los Brókers con su Zookeper (por defecto: 2181) y para comunicar cada Bróker con los Productores y Consumidores (por defecto: 9092, aunque cada Bróker tendrá el suyo). Si estamos programando Consumidores y Productores, nos interesa sobre todo el último puerto de comunicación con los Brókeres. Por otro lado, cada Zookeper tiene un identificador único, así como los Brókeres. Cada Bróker y Zookeper que tengamos tendrá su propio fichero de configuración. Antes he hablado de Quorum, es el controlador encargado de gestionar la replicación de mensajes entre varios brókeres, además de gestionar cuál Bróker es Líder (leader) y cuales los Seguidores (followers) mediante un algoritmo. No lo utilizaremos directamente, pero entrará en juego sobre todo cuando tengamos varios Brókeres.
Conectores de Kafka
Como hemos visto, Kafka no distingue los datos al procesarlos como bytes, pero sí que hay que diferenciar la Plataforma a la que nos conectamos con los Productores y Consumidores, ya que serán Fuentes (Source) de datos o Sumideros (Sink) de datos muy distintos entre sí.
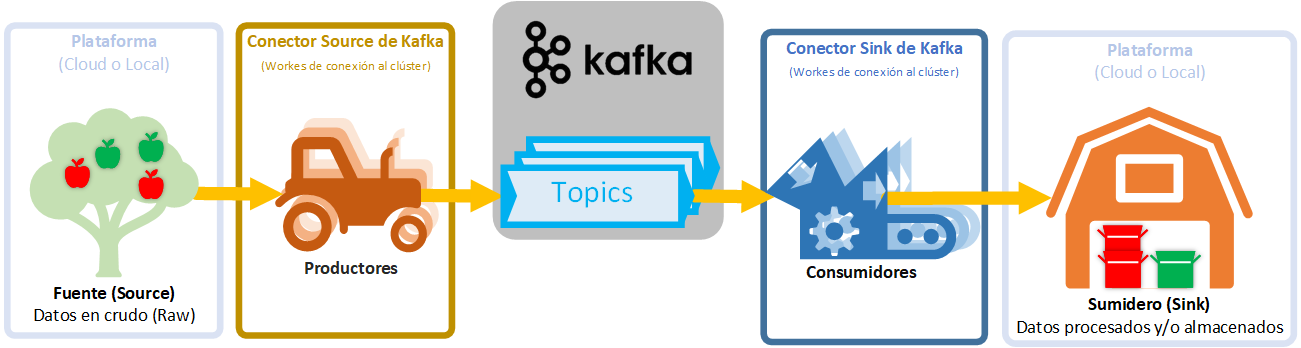
La Fuente y el Sumidero del dato podría coincidir o no como entrada y salida de un Topic de Kafka. Fuentes y Sumideros de datos hay muchas y pueden ser: JDBC, SAP, Blockchain, Cassandra, DynamoDB, FTP, IoT (Internet de las cosas), MongoDB, Salesforce, Solr, Twitter, Amazon S3, Google BigQuery, Azure, Oracle, Datadog, ElasticSearch, ElasticSearch, HDFS, JDBC, SAP, DocumentDB, Cassandra, DynamoDB, HBase, Redis, Splunk, Adobe, Neo4j, etc. Entre otras muchas.
Para conectarnos a todas estas Plataformas (Fuentes/Sumideros de datos) existen numerosos Conectores ya programados (Productores y Consumidores preparados para ser usados de una manera fácil y rápida) que se pueden encontrar (clasificados por Source/Sink, en español: Fuentes/Sumideros) en https://www.confluent.io/es-es/product/connectors/ o también podremos programar una solución adecuada a nuestras necesidades (programar a mano los Productores y Consumidores).
Nota sobre bases de datos “tradicionales”: existe un conector universal llamado Debezium que es capaz de conectarse a múltiples bases de datos como MySQL, PostgreSQL, SQL Server, MongoDB, etc.
Ventajas e inconvenientes de Kafka
Deben servir para entender para qué es bueno Kafka y para que no se debería utilizar. Kafka debe complementar a otras estructuras de datos (como Data Lakes, Data Warehous, Bases de datos, Hadoop, Elastic Search, etc.), pero no las sustituye.
Ventajas de Kafka:
- Optimización: Es un sistema optimizado para leer y escribir datos (eventos) nuevos.
- Escrituras ilimitadas: Kafka agrega los datos secuencialmente en un gran archivo en disco.
- Alta confiabilidad: tolerante a fallos, por lo que no perderemos datos.
- Ordenamiento secuencial de datos en cada partición: todos los consumidores leen los datos en el mismo orden.
- Escribir una única vez: reduce la carga del lado del consumidor.
Inconvenientes de Kafka:
- La retención de los datos es muy costosa: entre 10 y 100 veces más que almacenar datos en la nube (en un Data Lake), puesto que Kafka almacena varias copias de los mensajes en distintos discos duros de diferentes máquinas.
- Mal acceso a datos específicos: un consumidor Kafka tendrá que leer un registro completo y obtener de éste un dato específico, lo que es un desperdicio de recursos si se compara con Apache Parquet (que guarda los datos en columnas para acceder a datos específicos rápidamente).
- A más consumidores menos rendimiento.
- Gobierno de dato por consumidor: para que cada consumidor tenga una buena calidad del dato requiere de deduplicación (compresión inteligente de los datos para eliminar copias de datos repetidos), administración de esquemas y monitorización.
Kafka en funcionamiento
Si quieres entender el funcionamiento de Kafka de una manera fácil y visual, recomiendo echar un vistazo https://softwaremill.com/kafka-visualisation/ donde podremos jugar con varias configuraciones y ver en una animación cómo funciona Kafka.
Para lo que seamos técnicos, necesitaremos de entrar más en detalle, por lo que en los siguientes artículos veremos en detalle como funciona cada una de las cosas que hemos visto en este artículo de introducción a Kafka.
Continuar aprendiendo
Este artículo es el primero de una serie de artículos más técnicos sobre Apache Kafka. Dependiendo de si nos va a interesar instalar Apache Kafka, configurarlo o simplemente programar Productores y Consumidores, nos interesará un artículo u otro, o quizás todos si queremos tener una idea completa:
- Apache Kafka: un vistazo profundo a los puntos clave y la teoría (artículo actual).
- Instalar Apache Kafka: Instalación y uso desde la consola (recomendado para tener una idea general).
- Consumidores y Productores de Apache Kafka con Java y Python: ejemplos de código de conexión y controla de mensajes (principalmente recomendado para programadores).
- Clúster Apache Kafka tolerante a fallos y alta disponibilidad: configuración de varios brókeres y un sistema distribuido en varias máquinas (principalmente recomendado para sistemas).
Bibliografía
- Web de Apache Kafka: https://kafka.apache.org/
- Documentación de Apache Kafka: https://kafka.apache.org/documentation/
- Conectores: https://www.confluent.io/es-es/product/connectors/
- Sobre la semántica: https://www.confluent.io/es-es/blog/exactly-once-semantics-are-possible-heres-how-apache-kafka-does-it/
