Clúster Apache Kafka tolerante a fallos y alta disponibilidad
Para sacar todas las ventajas de Apache Kafka requerimos que tengamos más de un bróker (si un bróker falla, que al menos otro tenga una copia de los datos) y que sea distribuido en varias máquinas (si una máquina falla, que otras máquinas sigan funcionando como si no hubiera pasado nada); además, que sea escalable.
Índice
- Apache Kafka: Teoría.
- Instalar Apache Kafka: Instalación y consola.
- Consumidores y Productores de Apache Kafka con Java y Python: Ejemplos de código.
- Clúster Apache Kafka tolerante a fallos y alta disponibilidad: Configuración de brókeres y sistema distribuido.
Voy a explicar por separado como crear con varios brókeres por un lado y luego distribuido en varias máquinas, aunque luego, como te podrás imaginar, podrás montar la configuración que desees.
Multi-bróker
Vamos a crear 3 brókeres (que además es el número mínimo y óptimo para entorno de producción, para poder tener un factor de replicación de cada topic decente) que gestionará nuestro Zookeeper que seguirán la siguiente arquitectura:
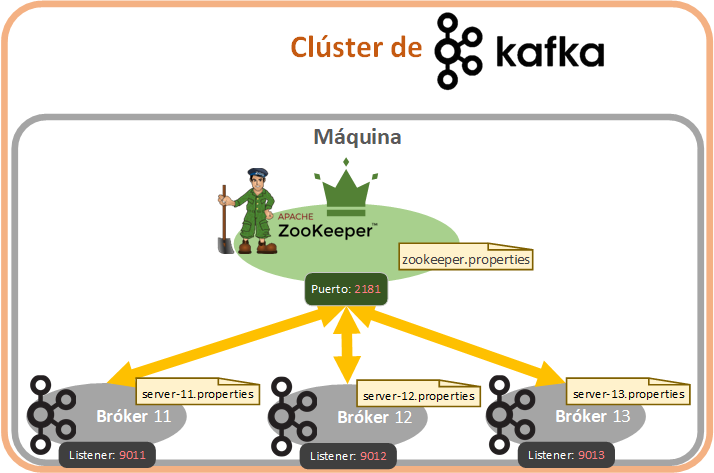
Primero tenemos que crear un fichero de propiedades (utilizando de plantilla “server.properties”) para cada servidor Broker de Kafka que queramos. Para este ejemplo voy a crear 3 Brókeres de Kafka en los ficheros que tendrán la siguiente configuración (mínimo hay que cambiar el “broker.id” y el “listeners”):
- server-11.properties: será el bróker de id 11 y escuchará el puerto 9011.
- server-12.properties: será el bróker de id 12 y escuchará el puerto 9012.
- server-13.properties: será el bróker de id 13 y escuchará el puerto 9013.
Para esto, en nuestra instalación de Kafka, dentro de la carpeta “config”, copiamos el fichero “server.properties” para crear cada uno de los ficheros:
cp server.properties server-11.properties
cp server.properties server-12.properties
cp server.properties server-13.propertiesPosteriormente, editamos fichero a fichero (yo utilizaré vim). Empezando con el primero:
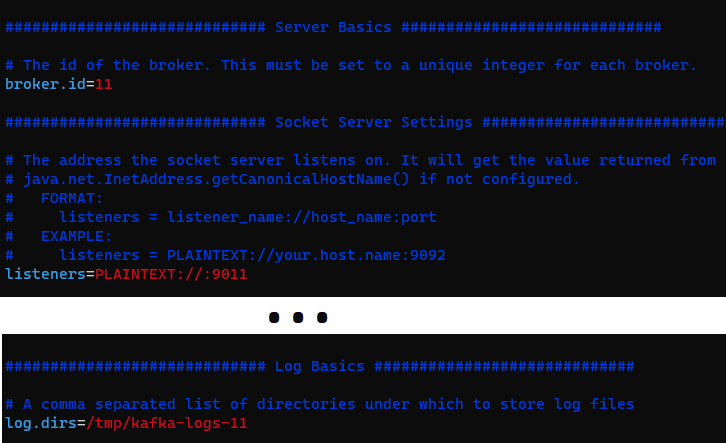
vim server-11.propertiesDe este fichero modificaremos los siguientes parámetros para que queden (adicionalmente al id y el puerto, modificaré nombre del fichero de logs en “log.dirs”, para separar los logs por cada bróker; por cierto, el “listeners” está comentado en la línea 31, pues por defecto el puerto es el 9092, pero si queremos más de 1 bróker necesitaremos quitar el comentario y poner un puerto exclusivo, pues cada bróker requiere de uno exclusivo):
- broker.id=11
- listeners=PLAINTEXT://:9011
- log.dirs=/tmp/kafka-logs-11
El interior del fichero “server-11.properties” tendrá que quedar algo así (la siguiente imagen está recortada, muestro únicamente los parámetros que he modificado):
Guarda los cambios del fichero y de manera análoga modificaremos el resto de los ficheros:
vim server-12.propertiesCon las variables modificados de los parámetros:
- broker.id=12
- listeners=PLAINTEXT://:9012
- log.dirs=/tmp/kafka-logs-12
Y lo mismo con el último fichero:
vim server-13.propertiesCon las variables:
- broker.id=13
- listeners=PLAINTEXT://:9013
- log.dirs=/tmp/kafka-logs-13
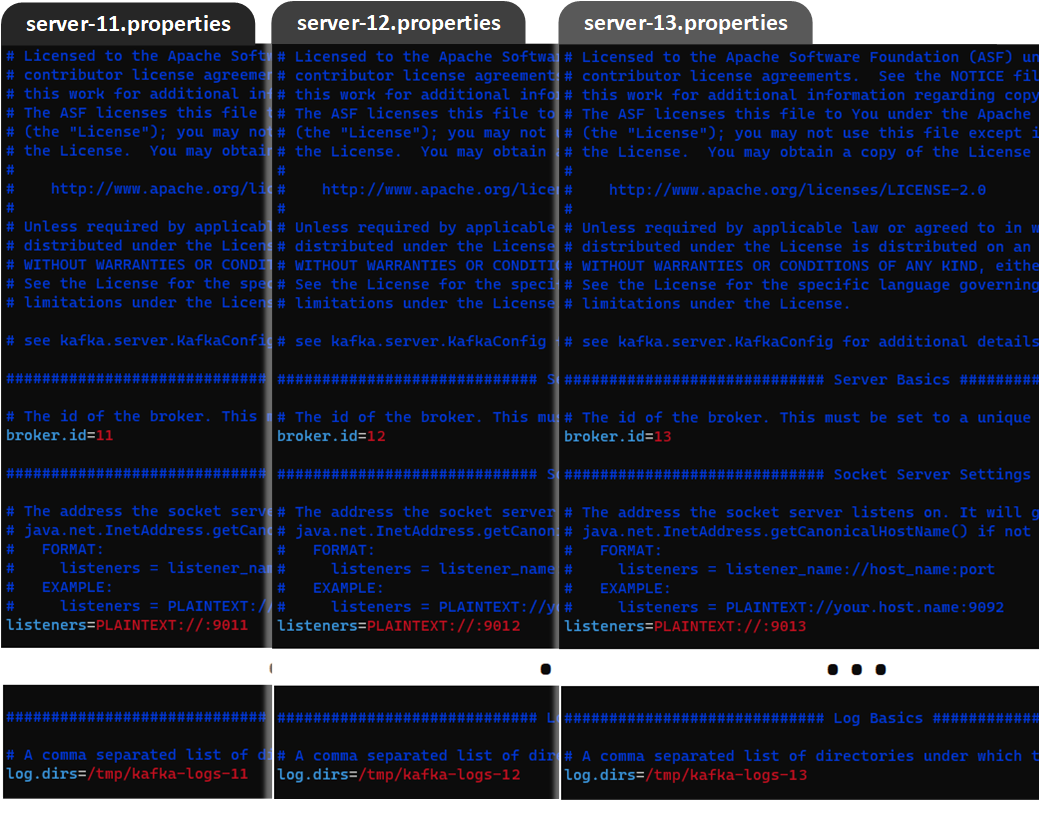
Quedando los tres ficheros:
Asegúrate tener un servidor de Zookeeper en ejecución como vimos antes, aunque te recuerdo el comando:
zookeeper-server-start.sh ~/kafka_2.13-3.1.0/config/zookeeper.propertiesAhora lanzaremos cada uno de los brokers (para empezar, recomiendo lanzar cada uno en una Shell diferente y ver lo que va mostrando cada uno de ellos). Te pongo los tres comandos seguidos, pero habrá que copiar cada uno de ellos a una Shell diferente:
kafka-server-start.sh ~/kafka_2.13-3.1.0/config/server-11.properties
kafka-server-start.sh ~/kafka_2.13-3.1.0/config/server-12.properties
kafka-server-start.sh ~/kafka_2.13-3.1.0/config/server-13.properties
Si ya tenemos soltura con la Shell, podemos ejecutar todos en la misma Shell, mandar su salida a 3 ficheros que he llamado “salida<ID>.out” y dejarlos en segundo plano:
kafka-server-start.sh ~/kafka_2.13-3.1.0/config/server-11.properties > salidaB11.out &
kafka-server-start.sh ~/kafka_2.13-3.1.0/config/server-12.properties > salidaB12.out &
kafka-server-start.sh ~/kafka_2.13-3.1.0/config/server-13.properties > salidaB13.out &Recuerdo rápido de Jobs en Linux
Los anteriores procesos crearán tres Jobs (procesos en segundo plano) que podremos ver con el comando:
jobs
Podemos recuperar cada uno con “fg [id_del_job]” (“fg” de “ForeGround” o primer plano). Por ejemplo, para obtener el primero:
fg 1Una vez recuperado uno de los procesos podemos o bien:
- Terminarlo con [Ctrl]+[C] o bien.
- Volver a dejarlo en segundo detenido con [Ctrl]+[Z].
- Dejarlo en segundo plano corriendo con bg [id_de_job](“bg” de “Back Ground” o segundo plano).
Podemos ver el log en tiempo real de un proceso con “tail -f”, por ejemplo:
tail -f salidaB11.outO podemos ver todos los ficheros a la vez y en tiempo real con:
tail -f *Clúster Kafka distribuido en varias máquinas
Kafka puede ejecutarse en varias máquinas (Servidor físico) diferentes (distribuido), cada una de estas máquinas puede estar cada una en un punto del planeta y funcionar todo el conjunto como si fuera “una cola Kafka normal” (dicho de otro modo, para productores y consumidores como esté configurado Kafka es transparente, pero los datos que envían y leen estarán a salvo por estar replicados y procesados en máquinas físicas separadas).
Para este ejemplo voy a montar dos Zookeeperes con un bróker para cada uno, un Zookeeper por máquina y los comunicaré entre sí (aunque lo ideal para tener una alta disponibilidad y tolerancia a fallos es disponer de 3 máquinas).
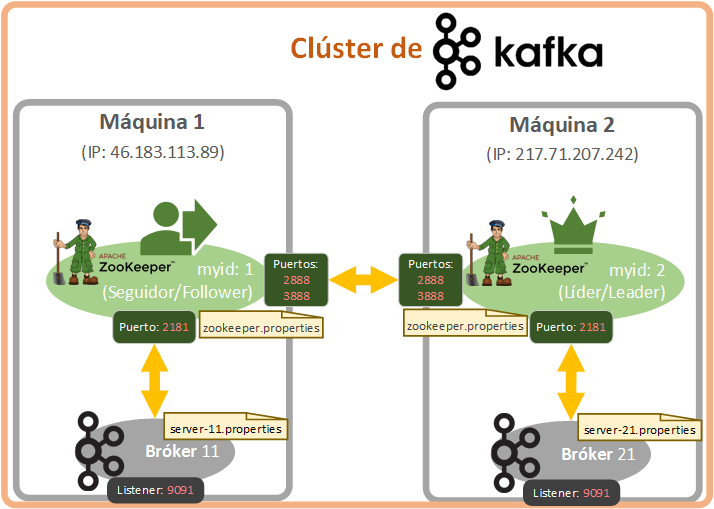
Cuando trabajamos con un solo Zookeeper no requiere de mucho más, pero si vamos a tener un clúster con varios hay que identificar cada uno de manera única con un número, así que ve pensando que número quieres asignar a cada Zookeeper. También hay que indicar a cada Zookeeper cuál es la ruta de todos los Zookpeeres (de todas las máquinas) para que entre ellos hablen, se intercambien la información que necesiten, comparan mensajes, establezcan quien es el Zookeeper líder, etc.
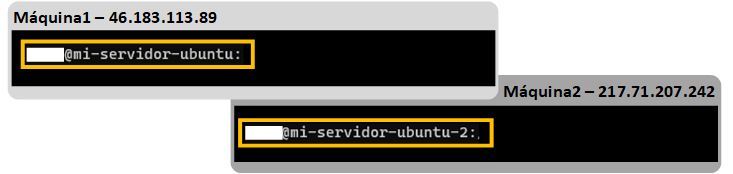
En todo momento tendré dos consolas abiertas y cada una apuntará a cada una de mis máquinas:
- Máquina 1 que he llamado “mi-servidor-ubuntu” con la IP “46.183.113.89”.
- Máquina 2 que he llamado “mi-servidor-ubuntu2” con la IP “217.71.207.242”.
Probar con dos máquinas cloud de verdad
Para esta parte voy a tener creadas dos máquinas remotas de verdad, que es igual a como se trabajaría en un entorno empresarial Big Data de verdad, así que si estás aprendiendo vas a poder aprender igual que en un entorno de verdad y desde casa.
En mi caso voy a utilizar el portal de clouding https://portal.clouding.io/ (usar el servicio es de pago, pero si eres nuevo te dan dinero gratis para que pruebes sus servidores, para montar un par de máquinas y probar Kafka distribuido nos sobra. Una vez agotado el saldo gratuito de 5€, si decidimos comenzar a utilizar el servicio, podemos hacer una recarga de saldo, ya que el servicio de Clouding es un pre-pago).
Yo voy a montar 2 máquinas de 1 Core, con 2 GB de RAM y 20 GB de disco duro.
Nota de trabajar con varias Shell y cada una apuntando a cada máquina: Te recomiendo tener a mano el comando “ifconfig” para saber en todo momento en la Shell que estás trabajando la IP que tiene, es importante no equivocarnos con las IPs y más con los ficheros de configuración.
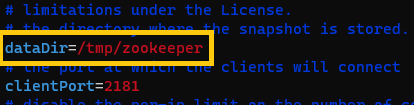
Primero, editamos el fichero “zookeeper.properties” de cada una de nuestras máquinas y consultamos el valor del parámetro “dataDir” (en qué ruta están guardándose los datos). En mi caso, como he dejado el valor por defecto será “/tmp/zookeeper”:
Y al final de cada uno de estos ficheros vamos a añadir unos parámetros (“tickTime”, “initLimit”, “syncLimit” y los servidores correctamente identificados) con sus valores que previamente no estaban, pero que son necesarios para que los Zookeeper de las dos máquinas se comuniquen. Un ejemplo de lo que tendríamos que añadir al final de cada fichero “zookeeper.properties” es:
# heartbeat de zookeeper en milliseconds
tickTime=2000
# Tiempo de la sincronización inicial
initLimit=10
# Ticks antes del timeout
syncLimit=5
# A continuación, definir línea a línea todos los servidores como: server.<id>=IP:2888:3888
# 2888 para conexiones de seguidor al líder
# 3888 para conexiones durante la fase de elección del líder
server.1=46.183.113.89:2888:3888
server.2=217.71.207.242:2888:3888
Nóta sobre esta configuración: si no apuntamos a localhost y apuntamos a cada servidor por su IP, podremos copiar y pegar rápidamente a todas las máquinas.
Guardamos los ficheros “zookeeper.properties” y hemos terminado con ellos.
Abrir puertos para establecer una conexión distribuida de Apache Kafka
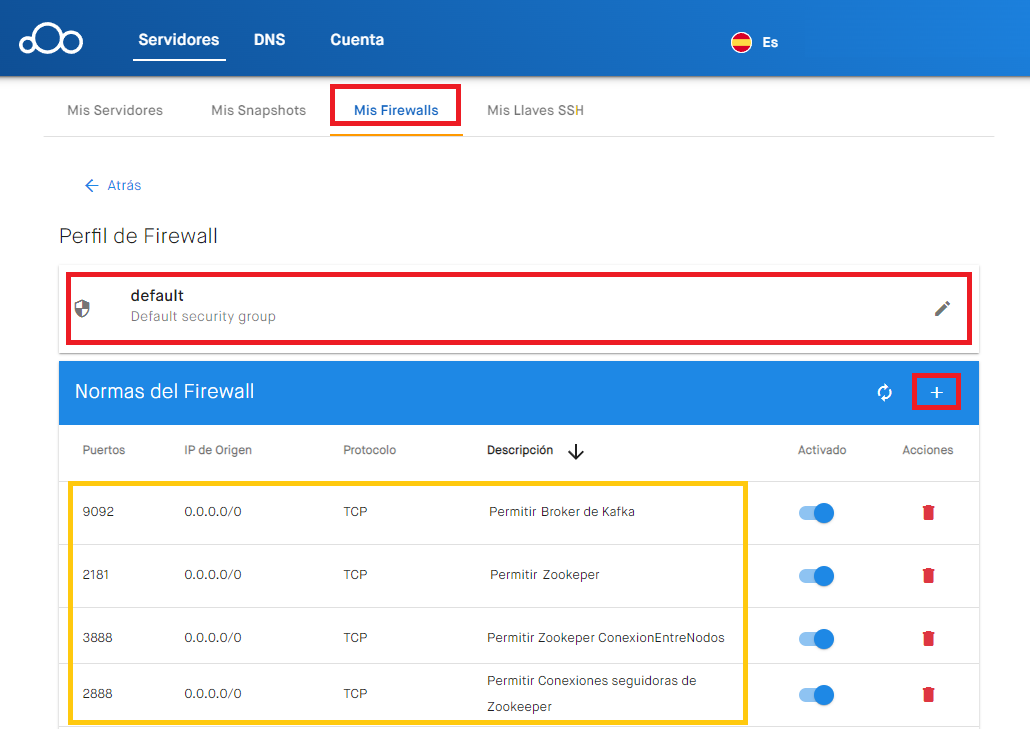
Para crear nuestro clúster de Kafka tenemos que abrir los siguientes puertos TCP para permitir las conexiones desde el exterior y que todas nuestras máquinas con servidor de Kafka interactúen:
- 2888: para conexiones de seguidor al líder.
- 3888: para conexiones durante la fase de elección del líder.
Si utilizamos los servicios de https://clouding.io/ tendremos que abrir estos puertos desde su panel de “Mis Firewalls”, quedando todos los puertos de Kafka necesarios abiertos, como la siguiente imagen de ejemplo (en la siguiente imagen el “IP de Origen” lo he abierto para todos “0.0.0.0”, por seguridad deberíamos de ser más restrictivos, más en producción):
Ahora vamos al directorio de “dataDir” (en mi caso “/tmp/zookeeper”; este directorio lo crea Zookeeper al iniciarse, sino lo has iniciado lo puedes crear a mano con “mkdir /tmp/zookeeper”) de cada máquina, donde crearemos un fichero llamado “myid” en el que guardaremos un número identificativo único para que identifique a nuestro Zookeeper. Para el primer servidor yo le voy a poner un 1 como id de Zookeeper, por lo que crearé un fichero llamado “myid” y escribimos un 1, se puede crear con un editor como Vim o directamente:
echo 1 > /tmp/zookeeper/myidY en mi segunda máquina le pondré a Zookeeper en “myid” el id de 2:
echo 2 > /tmp/zookeeper/myidNota sobre los ficheros myid: cada fichero myid en cada una de las máquinas tendrá exclusivamente el número que le hemos puesto, nada más.
Ya estamos listos para ejecutar en cada máquina zookeeper, yo por mantener una terminal abierta ejecutaré el siguiente comando en las dos máquinas (donde lo ejecutes te generará el fichero de salida “zookeeper.out” con la salida y el proceso se irá a segundo plano):
zookeeper-server-start.sh ~/kafka_2.13-3.1.0/config/zookeeper.properties > zookeeper-server.out &Esperamos unos minutos o miramos el fichero de salida a que se levante cada uno de los dos Zookeepers.

Si miramos el contenido de cada uno de los dos ficheros “zookeeper-server.out” (podemos ver su interior, por ejemplo, con “tail” o “less”):
less zookeeper-server.outNotaremos algo curioso y es que primero se han creado cada uno de ellos (En la salida donde pone “binding”), se han detectado entre ellos y luego uno de los Zookeeper se ha convertido en el líder (leader) del otro y el otro en el seguidor (following). En mi caso el “leader” se ha convertido mi segunda máquina y como “following” la primera. Recomiendo revisar ambos ficheros de salida de cada Zookeeper para entender cómo se han conectado cada uno y que realmente se están comunicando el uno al otro.
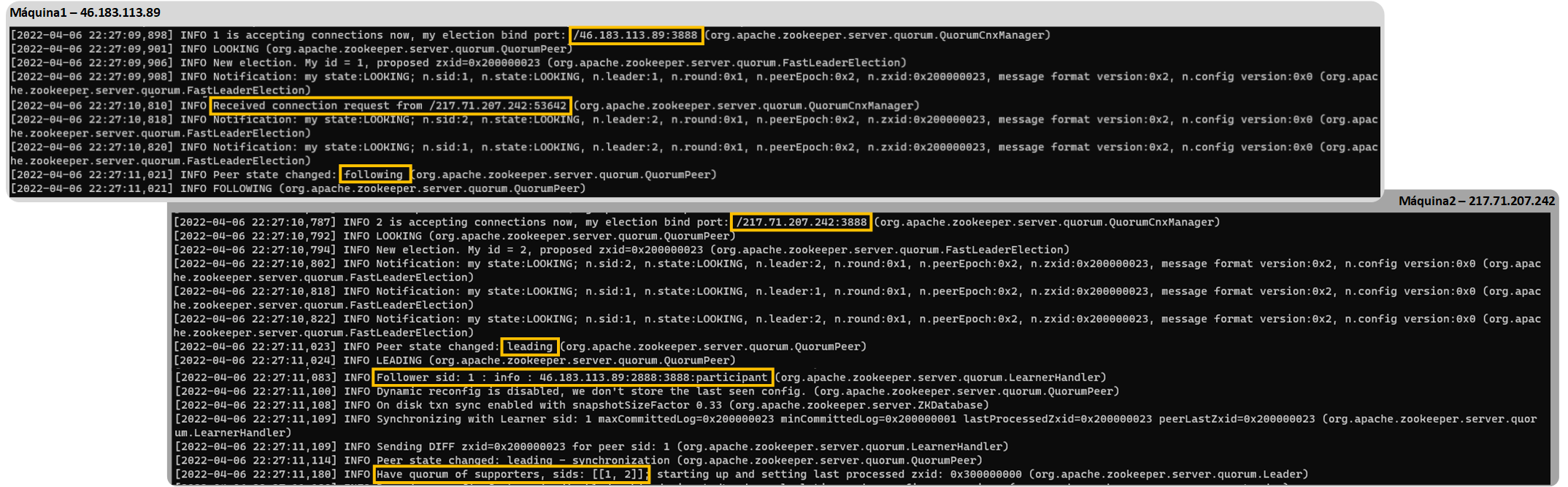
Ya estando todos los Zookeepers levantados podremos crear los brókeres que queramos en cada una de las máquinas. Yo, por hacerlo fácil, crearé un bróker en cada máquina con su fichero de configuración “server.properties” (es parecido a como vimos al crear varios brókeres para una única máquina) y le pondré un identificador en el parámetro de “broker.id” único (el resto de parámetros no hace falta cambiarlos si solo vamos a tener un bróker por máquina, si vamos a tener más de un bróker por máquina recuerda cambiar también “log.dirs” y el “listeners”), también deberemos completar la propiedad “advertised.listener”. (esta propiedad está comentada).
Diferencia entre la propiedad Listener y Advertised.listeners
- Listeners: Lista de direcciones (interfaces) a las que se une (bind) el bróker actual para escuchar. Se ha de poner la IP que el bróker va a escuchar (anteriormente pusimos valores de este tipo “PLAINTEXT://:9092” para que cada bróker escuche un puerto de la máquina local). Es necesario rellenarlo si tenemos muchos brókeres por máquina.
- Advertised.listeners: Lista de direcciones a las que tienen que apuntar los clientes (productores, consumidores, otros brókeres, etc.) para comunicarse con el bróker actual. Se ha de poner la IP con el puerto de la máquina actual (Por ejemplo, “PLAINTEXT://46.183.113.89:9092”). Es necesario rellenarlo si tenemos muchas máquinas.
De este modo, tendremos que rellenar en cada máquina de la carpeta “config” de nuestra instalación de Kafka un fichero de “server.properties”, que yo haré con la siguiente configuración:
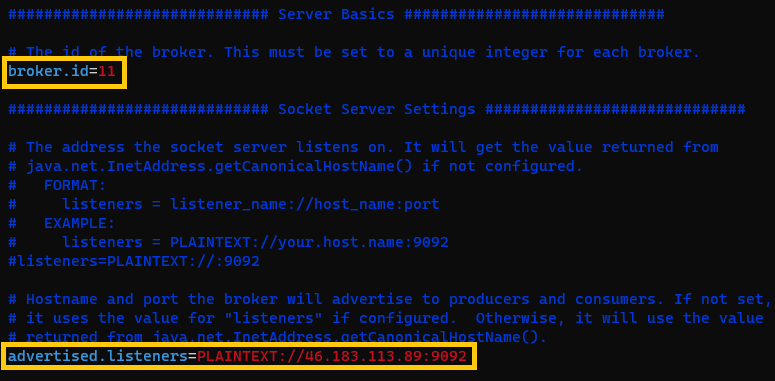
- En el fichero “server-11.properties” en la máquina 1 (46.183.113.89): broker.id=11 y “advertised.listeners=PLAINTEXT://46.183.113.89:9092”.
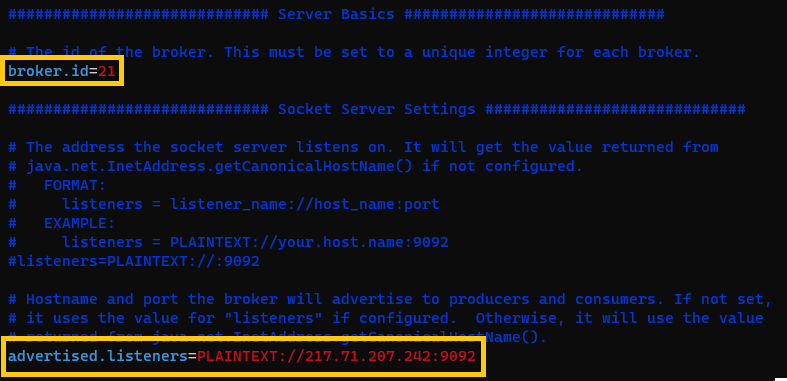
- En el fichero “server-21.properties” en la máquina 2 (217.71.207.242): broker.id=21 y “advertised.listeners=PLAINTEXT://217.71.207.242:9092”.
En la máquina 1 ejecutaré el bróker de id 11 (lo pongo en segundo plano y guardo su salida a un fichero de la ruta actual):
kafka-server-start.sh ~/kafka_2.13-3.1.0/config/server-11.properties > broker11.out &Y en la máquina 2 lanzaré el bróker de id 21:
kafka-server-start.sh ~/kafka_2.13-3.1.0/config/server-21.properties > broker21.out &A partir de ahora, será una buena práctica que todos los consumidores y productores añadan al “bootstrap-server” todas las IPs a todos los brókeres que tengamos, de este modo, si una máquina no está disponible, saltará a otra que sí lo esté. En el lenguaje de programación o consola que sea que utilicen consumidores o productores, podría ser algo así con mis direcciones de ejemplo (apuntando a los brókeres, en mi caso al puerto 9092, y las direcciones separadas por comas):
bootstrap-server=46.183.113.89:9092,217.71.207.242:9092De esta manera, tendremos una alta disponibilidad y tolerancia a fallas (junto con la replicación “replication-factor”); así, si una de nuestras máquinas le pasa algo (se prende en llamas, por ejemplo), la otra máquina seguirá funcionando y los clientes quienes usen nuestro Kafka (consumidores y productores) no notará que una máquina no está disponible. Para cuando esté arreglada la máquina que falle, bastará con volver a levantar el Zookeeper y el Bróker (no tendrá datos, pero Kafka se encargará de volver a completárselos desde la otra máquina que sí los tenía) para que entre ellos se compartan datos y todo vuelva a funcionar.
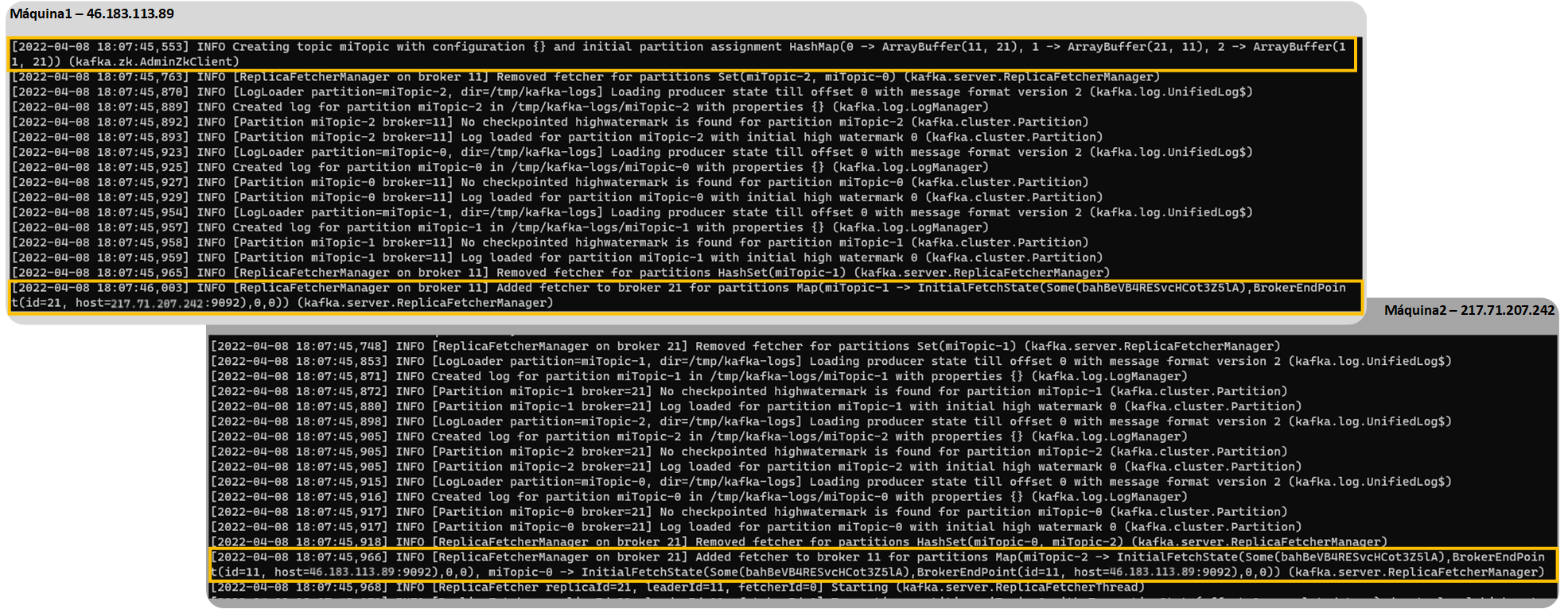
Ya podremos utilizar nuestro Kafka. Por ejemplo, podríamos crear un topic que utilice los dos brókeres como si estuvieran en la misma máquina (aunque realmente está cada uno en cada máquina). Y la gracia es que puedes lanzar el siguiente comando desde una de estas dos máquinas o desde una tercera:
kafka-topics.sh --create --topic miTopic --replication-factor 2 --partitions 3 --bootstrap-server 46.183.113.89:9092,217.71.207.242:9092En la salida de los brókeres veremos como el líder ha gestionado la creación del topic y el seguidor ha obedecido a su líder:
Y podremos analizar cómo nos ha creado el topic con “–describe”:
kafka-topics.sh --describe --topic miTopic --bootstrap-server 46.183.113.89:9092,217.71.207.242:9092
Advertencia sobre la seguridad
Aquí he explicado cómo hacer funcionar un clúster de Kafka entre dos máquinas físicas, pero a un nivel sencillo, que asegure que funcione, sin ninguna seguridad en el traspaso de los mensajes entre máquinas (van en claro) y sin muchas de las capas de seguridad adecuadas.
Deberás tener en cuenta aspectos como:
- Crear un usuario del sistema operativo exclusivo para Kafka, con permisos restringidos.
- Limitar los puertos del firewall abiertos.
- Restringir las IPs aceptadas.
- Habilitar un protocolo SSL para el intercambio de mensajes.
- Bloquear los Topics por permisos.
- No permitir la gestión de Kafka desde fuera de la misma máquina.
- Protección de datos en Consumidores y Productores.
- Etc.
