CI (Integración Continua): análisis, tests, calidad y seguridad
📚 Serie: CI/CD y la IA: De la teoría a la práctica
La fase de CI es el núcleo de calidad del pipeline: aquí el código se compila, se analiza, se prueba y se evalúa antes de llegar a producción. Cubre cada etapa del CI —desde el linting hasta el escaneo de seguridad— y el papel que puede jugar la IA en cada una.
Partes de este bloque:
- Parte 1 — Arquitectura general y PR Checks
- Parte 2 — CI: análisis, tests, calidad y seguridad ← estás aquí
Índice
- Linting
- Compilación / Build y empaquetado de artefactos
- Static Analysis — modo profundo
- Unit Tests (Tests Unitarios)
- Integration Tests (Tests de Integración)
- Service Tests / Component Tests
- Coverage (Test Coverage)
- Code Quality Gate
- Security Scan
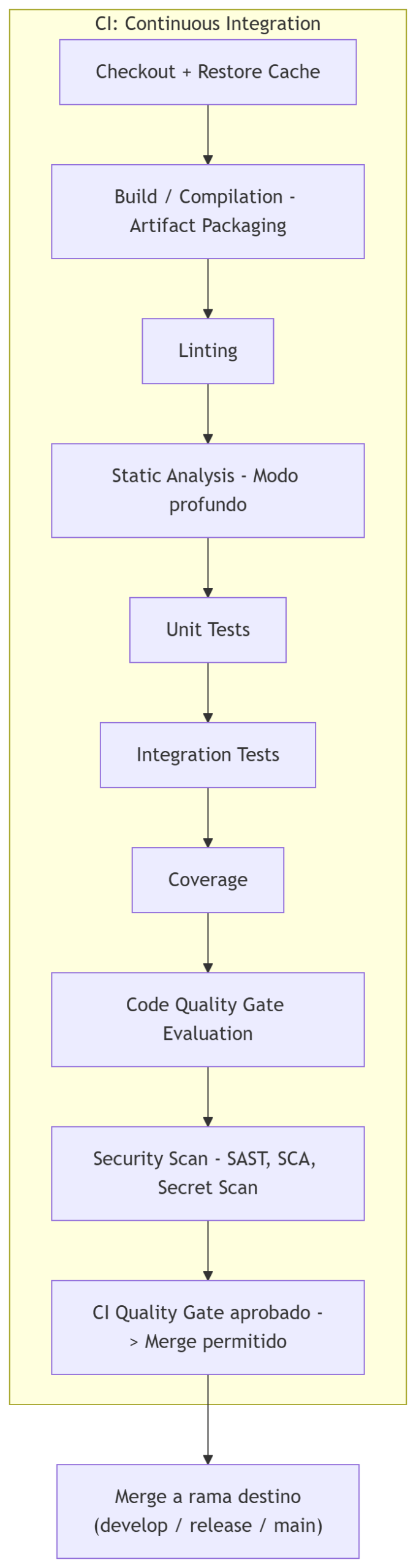
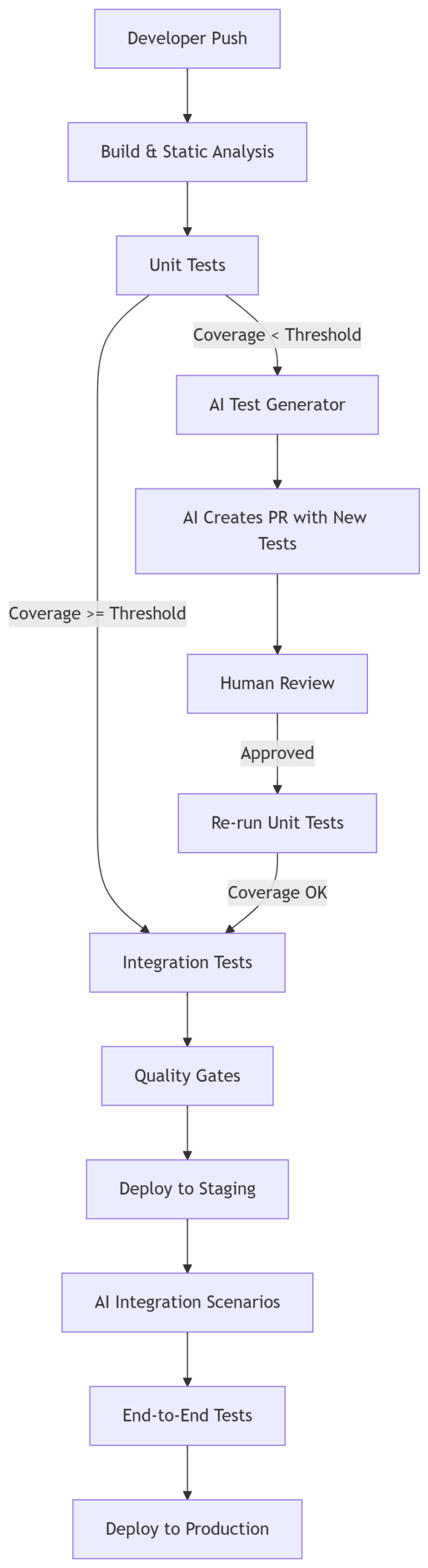
Diagrama completo de CI
Arquitectura completa del CI que veremos:
Linting
Objetivo: El linter es la herramienta que revisa el estilo, la consistencia y las reglas de formato del código. Es rápido, superficial e inmediato.
Qué detecta un linter
- errores de sintaxis
- variables no usadas
- imports no usados
- nombres incorrectos
- estilo inconsistente
- indentación incorrecta
- espacios, saltos de línea, comillas
- reglas de estilo del equipo
- convenciones de nombres
- malas prácticas básicas
Qué NO detecta un linter
- errores lógicos
- problemas de arquitectura
- vulnerabilidades
- rendimiento
- duplicación
- complejidad
- patrones incorrectos
Herramientas por lenguaje
| Lenguaje | Linter |
|---|---|
| JavaScript / TypeScript | ESLint |
| Python | Flake8, Pylint |
| Java | Checkstyle, SpotBugs (parte estática) |
| Go | golint, go vet |
| C# | Roslyn Analyzers |
| Terraform | tflint |
| YAML | yamllint |
IA en esta fase
La IA NO sustituye al linter, pues el linter debe ser:
- objetivo
- determinista
- reproducible
- sin interpretación semántica
La IA no es buena para esto porque:
- puede equivocarse
- puede interpretar mal
- no garantiza consistencia
- puede dar falsos positivos o negativos
Pero después de que el linter dé error, la IA puede corregir automáticamente los errores detectados por el linter.
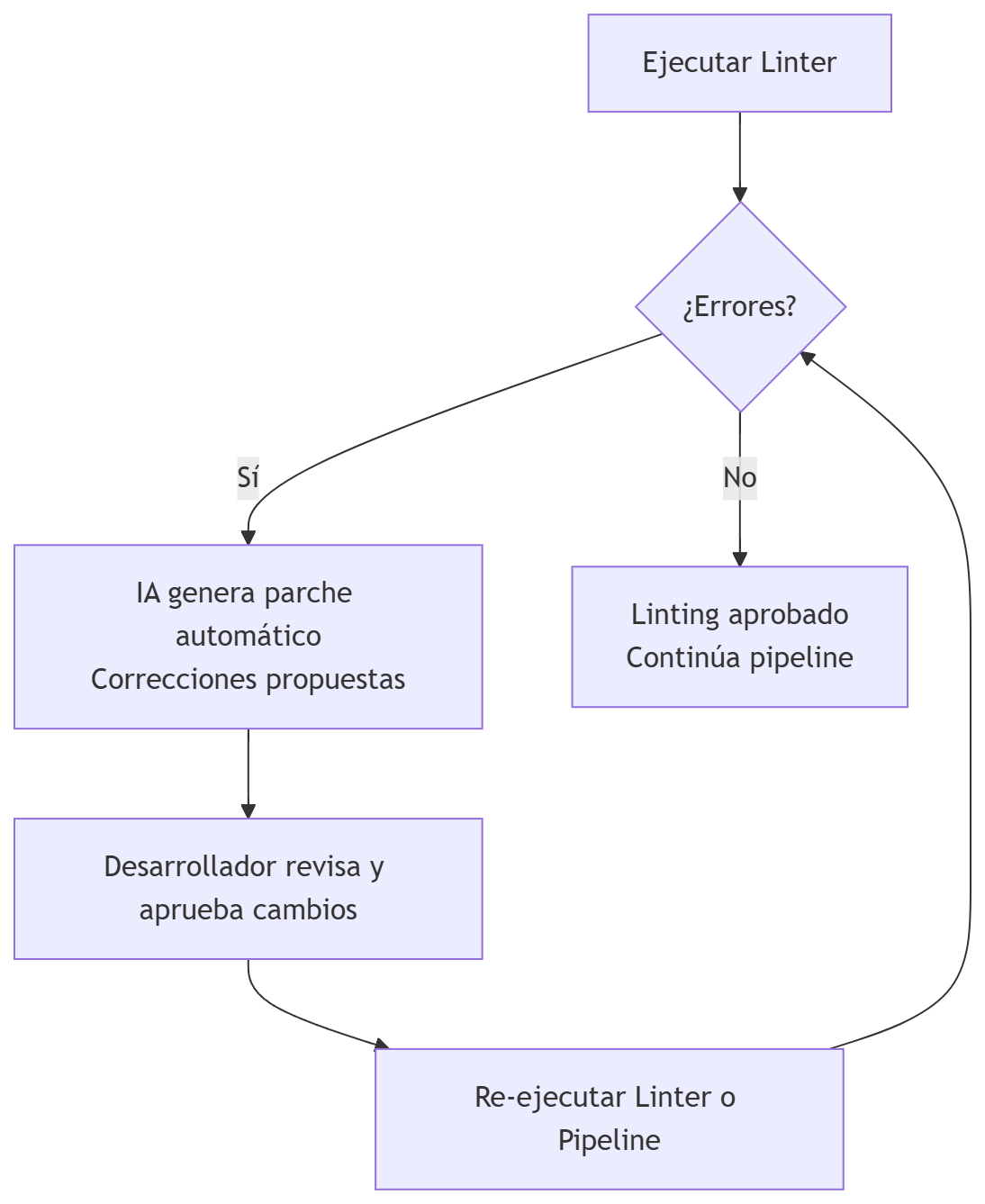
La IA puede ayudar a pasar el linter más fácilmente, pues:
- detecta inconsistencias semánticas
- sugiere nombres mejores
- reescribe código para cumplir estándares
- corrige automáticamente el linter
- explica por qué una regla se incumple
- genera parches listos para aplicar
Compilación / Build y empaquetado de artefactos
Esta etapa del código pertenece al lenguaje o framework que genera artefactos.
Da como resultado: un artefacto listo para empaquetar.
Si el lenguaje genera artefactos (como Spring Boot se convierte en JAR o WAR), a esta etapa se la suele llamar Artifact Packaging (empaquetado de artefactos). Para lenguajes que no generan artefactos (como Python), esta etapa se suele saltar.
Qué genera
Aquí ocurre:
- compilación
- empaquetado
- minificación
- generación de artefactos (JAR, WAR, DLL, binarios, dist/)
Ejemplos:
mvn package(Java) documentación maven packagegradle builddocumentación gradle buildnpm run build(Node.js) documentación npm rundotnet builddocumentación dotnet buildgo builddocumentación go buildcargo build(Rust) documentación cargo build
Docker multi-stage y cuándo separar el build del empaquetado
¿Se puede unificar la etapa de “Compilation / Build” y de “Empaquetado en una imagen”? Aunque en la etapa futura de “Empaquetado en una imagen” también se hace build, se recomienda hacerlo fuera de imagen previamente especialmente cuando:
- usas cachés de build del sistema CI (el build se cachea en el runner, no en Docker)
- quieres escaneo de artefactos antes de empaquetar
- necesitas reutilizar el artefacto en otros jobs
- puedes publicar el artefacto en Nexus/Artifactory
- tienes pipelines monorepo
- usas SonarQube en modo “full scan” (Sonar analiza el código antes del Docker build)
- quieres separar responsabilidades (build (dev) ≠ empaquetado (ops))
- Menos acoplamiento ya que el Dockerfile no necesita Maven
- Mejora la auditoría o compliance
IA en esta fase
Esta etapa es un proceso determinista del lenguaje y la IA no aporta nada.
Static Analysis — modo profundo
Objetivo: El análisis estático es mucho más profundo y más lento que el linting (por eso se recomienda ejecutar después). Analiza el código sin ejecutarlo, pero con conocimiento semántico, de flujo y de arquitectura.
Qué detecta el análisis estático
- vulnerabilidades (SAST)
- dependencias inseguras (SCA)
- duplicación de código
- complejidad ciclomática
- funciones demasiado largas
- clases demasiado grandes
- patrones incorrectos
- violación de arquitectura
- dead code (código muerto)
- errores potenciales
- null pointer risks (riesgos de puntero nulo)
- SQL injection patterns (patrones de inyección SQL)
- XSS patterns (patrones de scripting entre sitios)
- rutas críticas inseguras
Qué NO detecta
- errores lógicos de negocio
- problemas que solo aparecen en runtime (tiempo de ejecución)
- fallos de integración
- problemas de concurrencia complejos
Diferencia entre modo PR y modo CI (profundo)
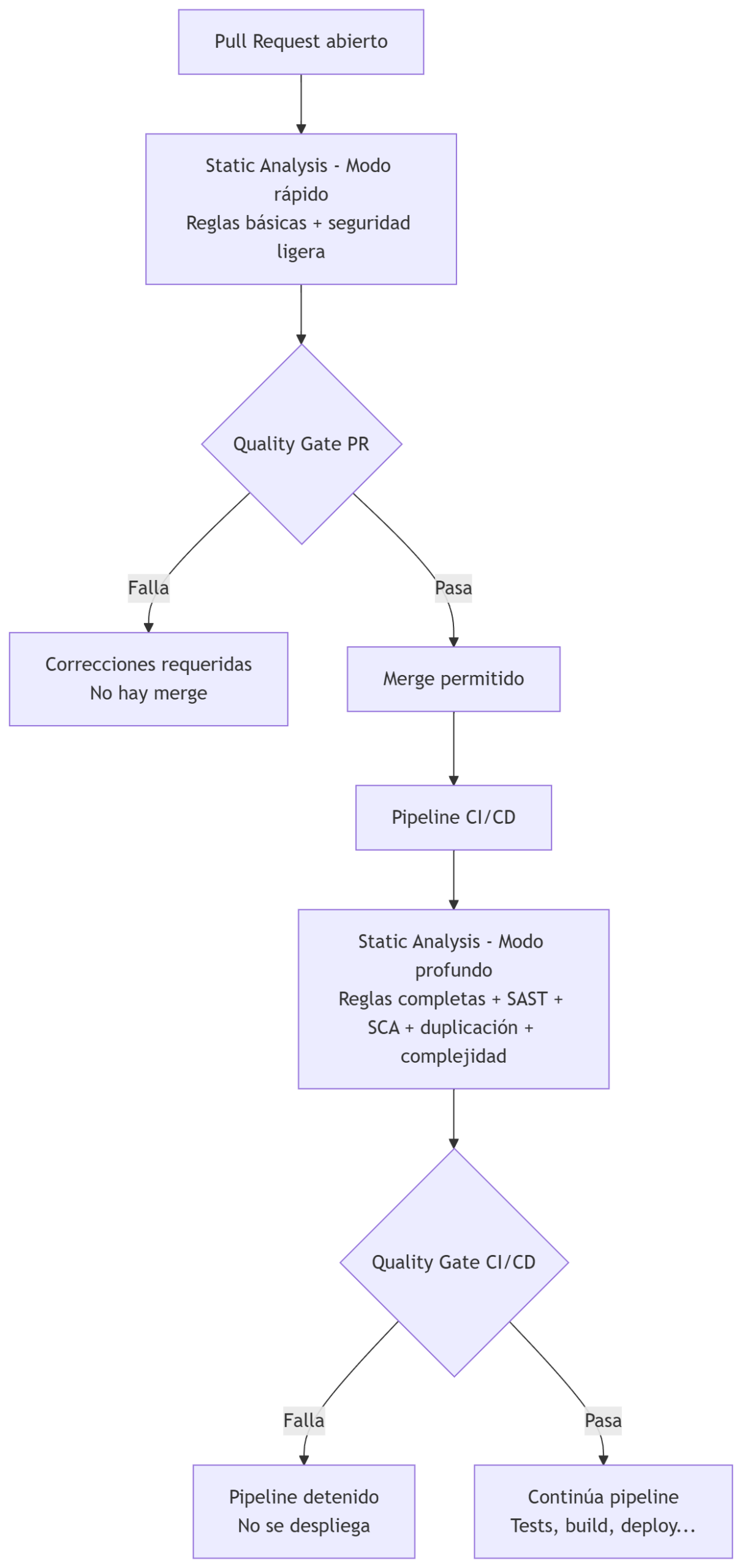
Herramientas de Static Analysis
| Tipo | Herramientas |
|---|---|
| SAST (seguridad) | SonarQube, Semgrep, Checkmarx, Fortify |
| SCA (dependencias) | Snyk, Dependabot, OWASP Dependency Check |
| Calidad | SonarQube, PMD, SpotBugs |
| Arquitectura | ArchUnit, SonarQube Rules, Semgrep Custom Rules |
IA en esta fase
La IA complementa el análisis estático, pero no lo sustituye.
El análisis estático tradicional (SonarQube, Semgrep, Checkmarx …) detecta:
- vulnerabilidades
- duplicación
- complejidad
- patrones peligrosos
Pero no entiende el contexto del negocio ni la arquitectura completa.
La IA puede:
- explicar findings (hallazgos) complejos
- correlacionar findings entre módulos
- sugerir refactors
- generar parches
- detectar riesgos semánticos
- validar arquitectura (DDD, hexagonal, CQRS)
- detectar inconsistencias entre capas
Otras ideas donde la IA amplía el análisis estático:
- detecta vulnerabilidades no cubiertas por reglas tradicionales
- analiza patrones de arquitectura
- identifica riesgos semánticos
- genera parches automáticos
- explica findings en lenguaje natural
- correlaciona findings entre módulos
- predice qué partes del código son más frágiles
Unit Tests (Tests Unitarios)
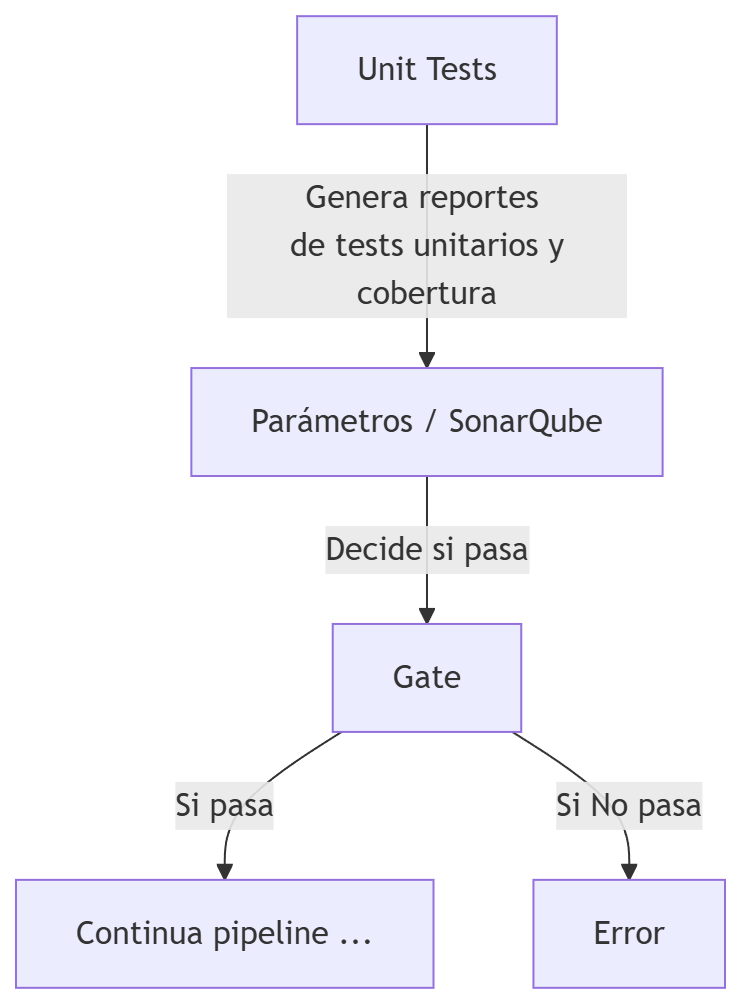
Objetivo: Validar el comportamiento de una unidad de código aislada: una clase, función o módulo.
Características
- Prueban solo la lógica interna de una función/método.
- Aíslan dependencias mediante mocks (simulaciones), stubs o fakes (todo lo externo se mockea: repositorios, colas, APIs, servicios, ficheros).
- Son rápidas (milisegundos), por ello son las primeras pruebas que se ejecutan.
- Se ejecutan en cada merge a la rama de main (usualmente tras PR, pull request).
- No requieren infraestructura externa (no deben depender de infraestructura).
- Cobertura típica esperada: 70–90% (Sonar suele configurar por defecto el 80%) según la organización.
- Validan: lógica pura, flujos de control, validaciones, cálculos, errores esperados.
Objetivo y cuándo ejecutarlo
Previo al pipeline CI/CD. Motivos:
- Como checks del PR (se ejecutan antes de que se merge a main)
- Para evitar que llegue código roto a la rama
main - Para dar feedback rápido al desarrollador
- Para no saturar el pipeline CI/CD con fallos triviales
- Para que la revisión humana vea el PR “verde”
Continuous Integration (CI). Motivos:
- Para generar el reporte de cobertura (JaCoCo)
- Para alimentar a SonarQube
- Para aplicar el Quality Gate (puerta de calidad)
- Para garantizar reproducibilidad (no confiar solo en los checks del PR)
- Para que el pipeline sea determinista
Ejemplo de test Java con mocks/stubs
Ejemplo de código Java (Testing con Spring Boot y Testing Web Layer con Spring Boot) para aplicar un test unitario probando un servicio que obtiene una tarea (task) de la base de datos por su ID:
public Task getTask(@PathVariable Long id) {
// 1. Buscamos la tarea (Optional maneja si existe o no)
Optional<Task> taskOptional = repository.findById(id);
// 2. Verificamos si está presente
if (taskOptional.isEmpty()) {
throw new ResourceNotFoundException("Tarea con ID " + id + " no encontrada");
}
// 3. Extraemos y retornamos
Task foundTask = taskOptional.get();
return foundTask;
}
Para probarlo como test unitario, solo se prueba el código del método getTask sin salir de este (desde la primera línea hasta la última del método). Si hay llamadas externas como a una base de datos, se mockea (se falsean los datos que devuelve la base de datos con when, donde le decimos que cuando se llame a findById devuelva un Optional con un objeto ficticio/mock Task llamado mockedTask con datos inventados):
@Test
void getTask_ShouldReturnTask_WhenIdExists() {
// GIVEN
Long taskId = 1L;
Task mockedTask = new Task();
mockedTask.setId(taskId);
mockedTask.setTitle("Tarea Existente");
// Simulamos que el repositorio encuentra la tarea envolviéndola en un Optional
when(repository.findById(taskId)).thenReturn(Optional.of(mockedTask));
// WHEN
Task result = controller.getTask(taskId);
// THEN
assertNotNull(result);
assertEquals(taskId, result.getId());
assertEquals("Tarea Existente", result.getTitle());
}
Herramientas por lenguaje
- Java → JUnit, TestNG
- JavaScript/TS → Jest, Mocha, Vitest
- Python → PyTest
- Go →
go test - .NET → xUnit, NUnit
IA en esta fase
Las pruebas unitarias son un buen sitio para usar IA, ya que hacerlas es tedioso y lento, además de que no ofrece mucha complicación y la modificación de un poco de código obliga a reescribir los tests que ya están hechos.
AI-Assisted Gate (puerta asistida por IA):
- Si cobertura < umbral:
- La IA analiza código y cobertura
- La IA genera tests faltantes
- La IA crea rama
ai/test-fix/<build-id> - La IA abre PR con tests generados
- Revisión humana obligatoria
- Re-ejecución del stage
Integration Tests (Tests de Integración)
Los Integration Tests (tests de integración) validan cómo interactúan varios componentes (repositorios, servicios, controladores, configuración, etc.) existentes dentro del mismo módulo o servicio. Es decir, prueban el microservicio por dentro por completo de principio a fin (por ejemplo, se hace una llamada a un controlador que llama a un método de una clase servicio que llama a un repositorio), con servicios externos y bases de datos de prueba (reales pero para testeo).
Nota sobre la palabra “servicio”: aquí se usa “servicio” en las dos acepciones técnicas. “Servicio” como “microservicio entero” (o “aplicación entera”, como proceso independiente en el ámbito de red) y “servicio” como “clase” (en un ámbito interno siguiendo el patrón Controlador-Servicio-Repositorio o Domain-Driven Design).
Cuando interesa ejecutarlo: después de los Unit Tests y antes del empaquetado.
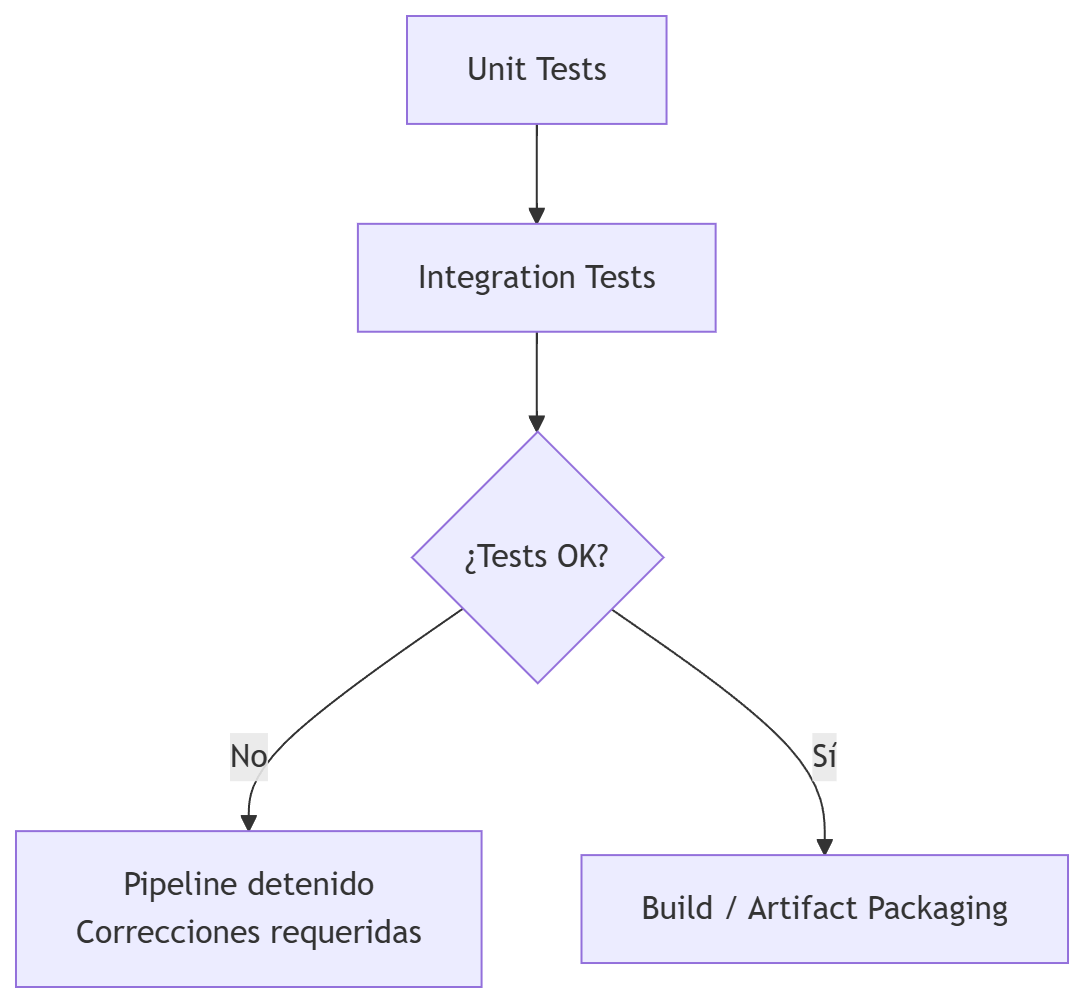
Con los Tests de Integración se prueba:
- interacción entre clases
- interacción entre módulos internos
- interacción con la base de datos (real o testcontainers)
- interacción con repositorios
- interacción con servicios internos del mismo microservicio
- wiring (cableado) del framework (Spring context, beans, DI)
Las 6 estrategias para simular servicios externos
1) Instancias reales dedicadas a pruebas (casi en desuso)
Hoy solo se usa en casos muy específicos (sistemas legacy o entornos muy controlados). Ejemplo: una base de datos Postgres “de pruebas” compartida por todos los desarrolladores.
Ventajas:
- entorno real
- mismo motor que producción
Problemas:
- mantenimiento constante
- riesgo de interferencias entre tests
- estado inconsistente
- difícil de resetear
- no reproducible
2) Simulaciones ligeras (H2, SQLite, memoria, mocks internos)
Útil para tests rápidos, pero no recomendado para integración real. Ejemplo: usar H2 en lugar de Postgres.
Ventajas:
- rápido
- sin dependencias externas
- fácil de configurar
Problemas:
- no es el mismo motor que producción
- diferencias sutiles en SQL, índices, tipos, transacciones
- tests que pasan en H2 pero fallan en Postgres
3) Mocks de servicios externos (WireMock, MockWebServer, Mockito avanzado)
Se simulan servicios HTTP externos. Muy útil para microservicios que consumen APIs externas. Ejemplos:
Ventajas:
- reproducible
- rápido
- control total de respuestas
Problemas:
- no prueba la red real
- no prueba timeouts, latencias, TLS, etc.
4) Contenedores externos gestionados manualmente (Docker, Kubernetes)
Mejor que las simulaciones ligeras, pero aún imperfecto. Ejemplo: levantar un Postgres en Docker o en un namespace de Kubernetes.
Ventajas:
- mismo motor que producción
- entorno más realista
Problemas:
- hay que mantenerlos
- riesgo de interferencias entre tests
- no se resetean automáticamente
- requieren infraestructura adicional
5) Testcontainers (el estándar moderno, opción recomendada)
Testcontainers permite levantar contenedores efímeros (de corta vida), aislados y reproducibles para cada test o suite.
Ejemplo: un Postgres idéntico al de producción:
@Container
static PostgreSQLContainer<?> postgres = new PostgreSQLContainer<>("postgres:15");
Ventajas:
- mismo motor que producción
- contenedores aislados por test
- estado limpio en cada ejecución
- reproducible en cualquier máquina
- integración nativa con algunos frameworks (como Spring Boot)
- no requiere infraestructura externa
6) Ambientes efímeros completos (Ephemeral Environments)
Se levanta todo el servicio (o varios) en un entorno temporal. Esto ya se acerca más a Service Tests o End-to-End Tests, pero en algunas ocasiones es necesario usarlo como Integration Tests avanzados.
Tecnologías:
- Kubernetes namespaces efímeros
- Okteto
- Garden
- Tilt
- Nx Dev Environments
- GitHub Actions + Kind
- GitLab Review Apps
Ventajas:
- entorno casi idéntico a producción
- pruebas de integración más realistas
- pruebas multi-servicio
Problemas:
- más lento
- más caro
- más complejo
Tabla comparativa de estrategias
| Estrategia | Realismo | Aislamiento | Mantenimiento | Recomendado |
|---|---|---|---|---|
| Instancia real compartida | ✔ | ❌ | Alto | ❌ |
| Simulaciones ligeras (H2 / in-memory) | ❌ | ✔ | Bajo | ⚠️ Solo para tests rápidos |
| WireMock / MockWebServer | ⚠️ | ✔ | Bajo | ✔ Para APIs externas |
| Contenedores externos | ✔ | ⚠️ | Medio | ⚠️ |
| Testcontainers | ✔ | ✔ | Muy bajo | ✔ Mejor opción |
| Ambientes efímeros | Muy alto | ✔ | Alto | ✔ Para equipos avanzados |
IA en esta fase
No sustituye a los tests de integración, pero los complementa.
La IA (no ejecuta los tests, solo ayuda a escribirlos):
- genera mocks complejos
- genera escenarios de API
- simula fallos de red, latencias, timeouts
- genera datos realistas
- detecta dependencias no cubiertas
- genera tests faltantes
- detecta casos límite
- sugiere mocks
- explica fallos
- genera fixtures
- crea tests con Testcontainers
- sugiere estrategias de infraestructura simulada para tests
Service Tests / Component Tests
Los Service Tests (tests de servicio) prueban el servicio completo desde fuera, como si fueras un cliente real. Son una prueba de “caja negra” para una aplicación completa, pero aislada del resto del mundo.
A diferencia de los Unit Tests (que prueban una función) o los Integration Tests (que suelen probar la conexión con la DB), el Service Test valida que toda la maquinaria interna de tu aplicación (rutas, controladores, servicios, repositorios) funcione correctamente ante una petición real.
Cuando interesa ejecutarlo: después de generar la imagen Docker, porque necesitas el servicio funcionando tal cual “como se ejecuta en producción”.
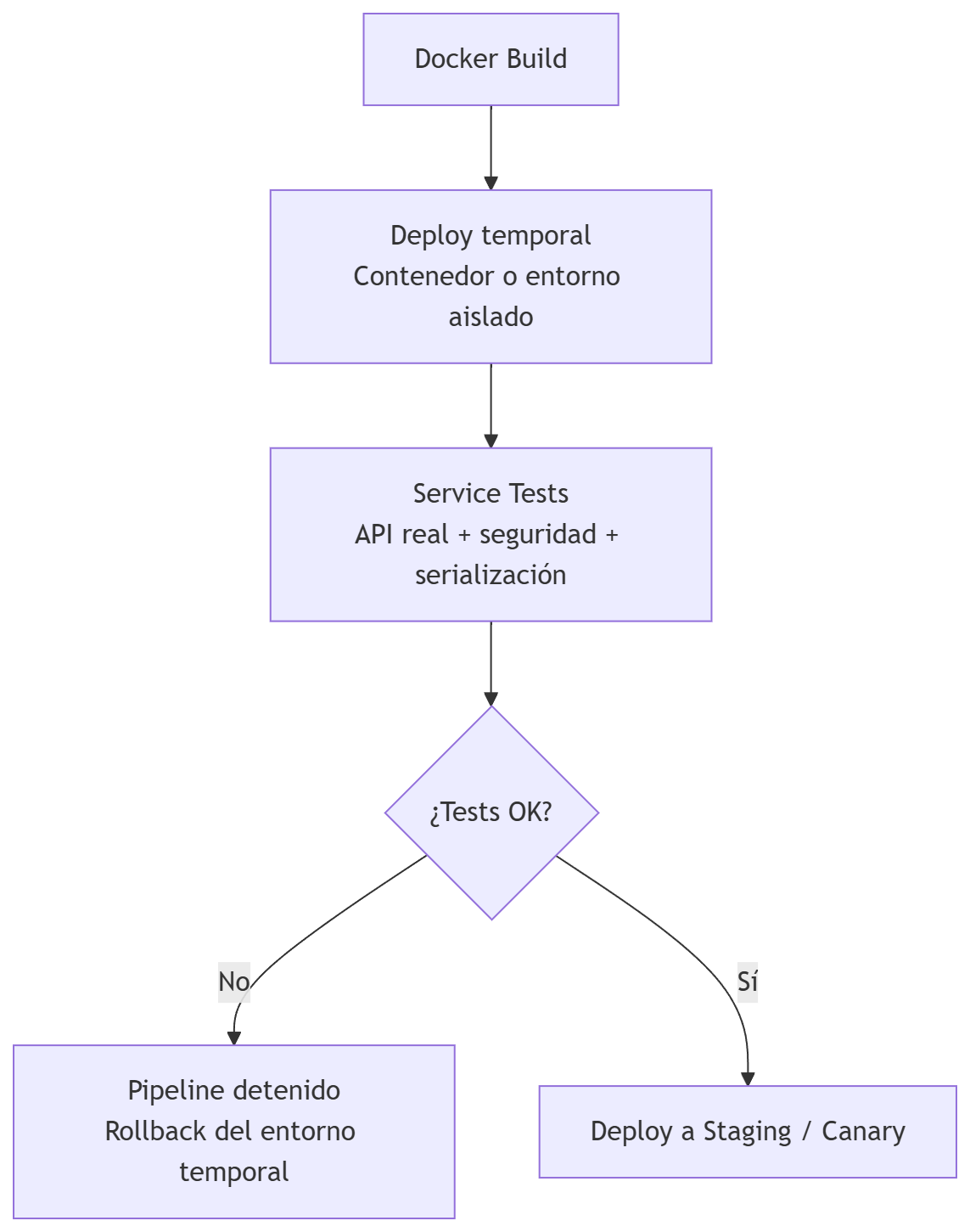
Qué prueban
- endpoints REST, HTTP, SOAP reales
- validaciones
- serialización/deserialización
- seguridad (tokens, roles)
- lógica completa del servicio
- comportamiento observable desde fuera
- integración con dependencias simuladas (mocks, wiremock)
NO prueban
- detalles internos del código
- interacción entre clases internas
- lógica privada
- arquitectura interna
Normalmente se prueba en:
- entorno temporal
- contenedor aislado
- docker-compose
- Kubernetes ephemeral namespace (espacio de nombres efímero de Kubernetes)
Contract verification, serialización y herramientas
Los tests de servicio validan especialmente:
- Serialización/deserialización: que los JSON/XML que envía y recibe el servicio son correctos
- Contratos de API: que el servicio responde como promete (especialmente útil en arquitecturas de microservicios)
Herramientas principales:
- RestAssured: framework Java para tests de API REST
- Karate: DSL para tests de API, combina BDD y tests funcionales
- Postman / Newman: colecciones de tests de API ejecutables en CI
- Playwright API: tests de API modernos con Playwright
Ejemplo del diagrama del servicio de pedidos
Ejemplo de service test para un microservicio de pedidos (orders service):
- levantar el servicio completo en un entorno aislado
- llamar a
/api/orderscon HTTP real - validar respuesta, headers, status codes
- simular dependencias externas (en el ejemplo
/stock) con WireMock
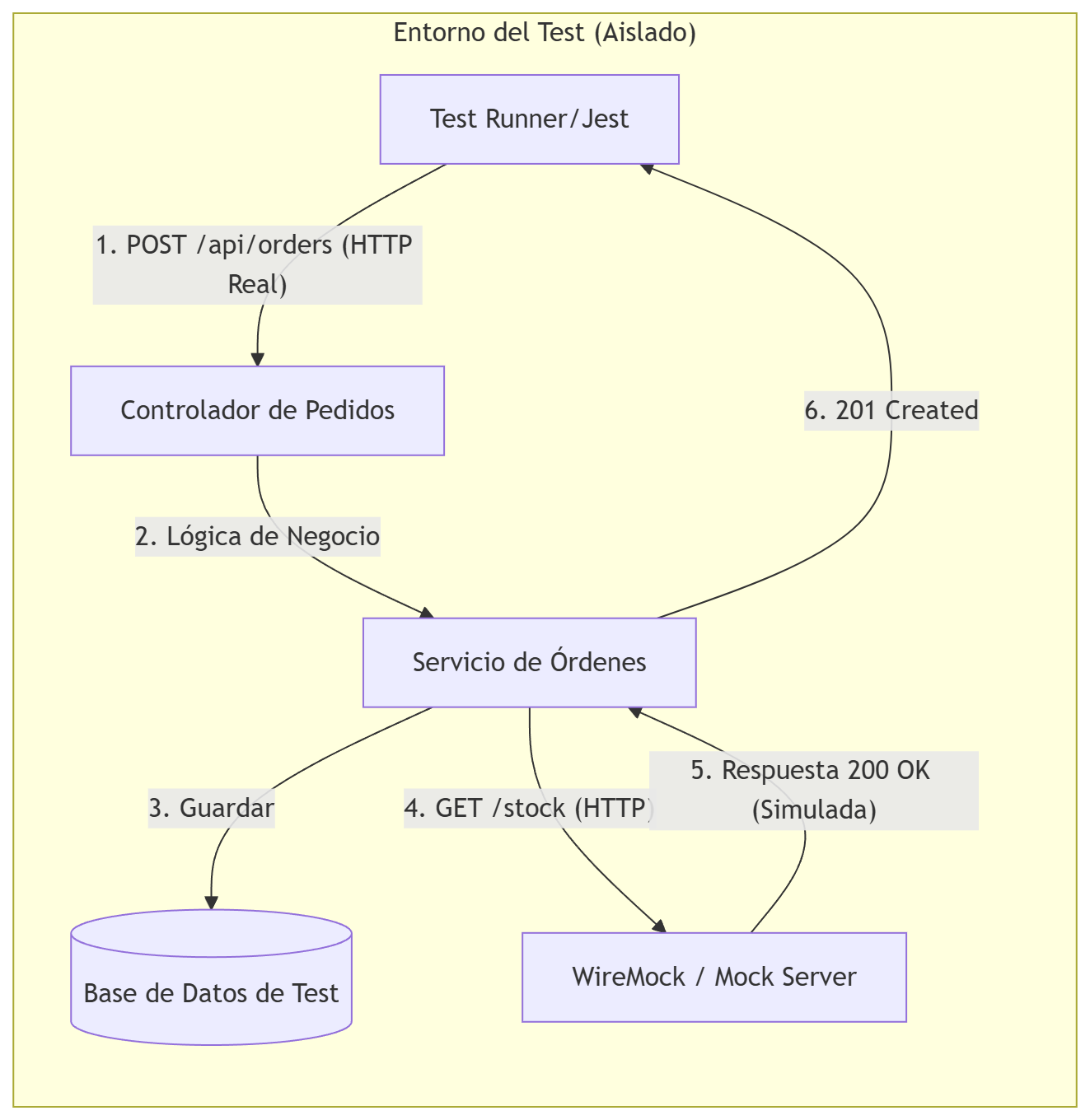
Con esto:
- Validas la Red: compruebas que tus serializadores de JSON, tus Middlewares de autenticación y tus rutas están bien configurados
- Aislamiento Total: si el equipo que hace el “Servicio de Inventario” (
/api/orders) tiene el servidor caído, tus tests siguen pasando porque estás usando WireMock - Confianza: si este test pasa, tienes un 90% de certeza de que tu código funcionará al desplegarlo, ya que lo has probado como si fueras un cliente real
IA en esta fase
La IA es útil con (no sustituye a la ejecución real):
- generar escenarios de API
- crear tests con RestAssured, Karate, Postman, Playwright API
- detectar rutas no cubiertas
- generar mocks de servicios externos
- sugerir casos de seguridad (JWT, roles, CSRF)
Coverage (Test Coverage)
La fase de Coverage (cobertura) mide qué porcentaje del código está cubierto por tests automatizados. No valida si los tests son buenos, sino qué partes del código se ejecutan durante los tests.
Esta etapa garantiza:
- que el código tiene un nivel mínimo de calidad
- permite que en la etapa de
security scanlas herramientas como SAST o análisis de riesgos prioricen mejor - evita que se analice código sin testear, lo cual suele ser un indicador de riesgo
Ventajas:
- Aumenta la calidad del código
- Reduce regresiones
- Permite detectar código muerto o no testeado
- Mejora la confianza antes de ejecutar análisis de seguridad
Desventajas:
- No garantiza que los tests sean buenos
- Puede ralentizar el pipeline si los tests son pesados
- Puede generar “gaming” (tests triviales para subir cobertura)
- Requiere mantenimiento continuo
Métricas y flujo del diagrama de cobertura
Esta etapa se divide en los siguientes pasos:
-
Recoger artefactos generados (los resultados) de los tests ya ejecutados en unit tests e integration tests. Este punto consume:
- Archivos de informe de cobertura
- Porcentajes por archivo/módulo
- Datos para aplicar el coverage gate (mínimos exigidos)
-
Procesar los ficheros de cobertura generados por esos tests. Para procesarlo se puede usar:
- Java (JaCoCo):
.execo XML - JavaScript o TypeScript (Istanbul/NYC):
.lcov - Python (Coverage.py):
.coverage - Go:
cover.out(documentación de cover)
- Java (JaCoCo):
-
Generar el informe de cobertura:
- Cobertura global
- Cobertura por módulo
- Cobertura por archivo
- Líneas cubiertas vs no cubiertas
-
Publicar el reporte (por ejemplo, ponerlo como gráfico en la página de la ejecución de Jenkins) en formatos como:
- LCOV
- Cobertura XML
- HTML (para visualizar en Jenkins, GitLab, GitHub, Azure DevOps)
-
Aplicar el coverage gate, por ejemplo:
- Mínimo 80% global
- Mínimo 70% por módulo
- No permitir que baje respecto a
main(compararlo) - Decidir si el pipeline sigue o se detiene
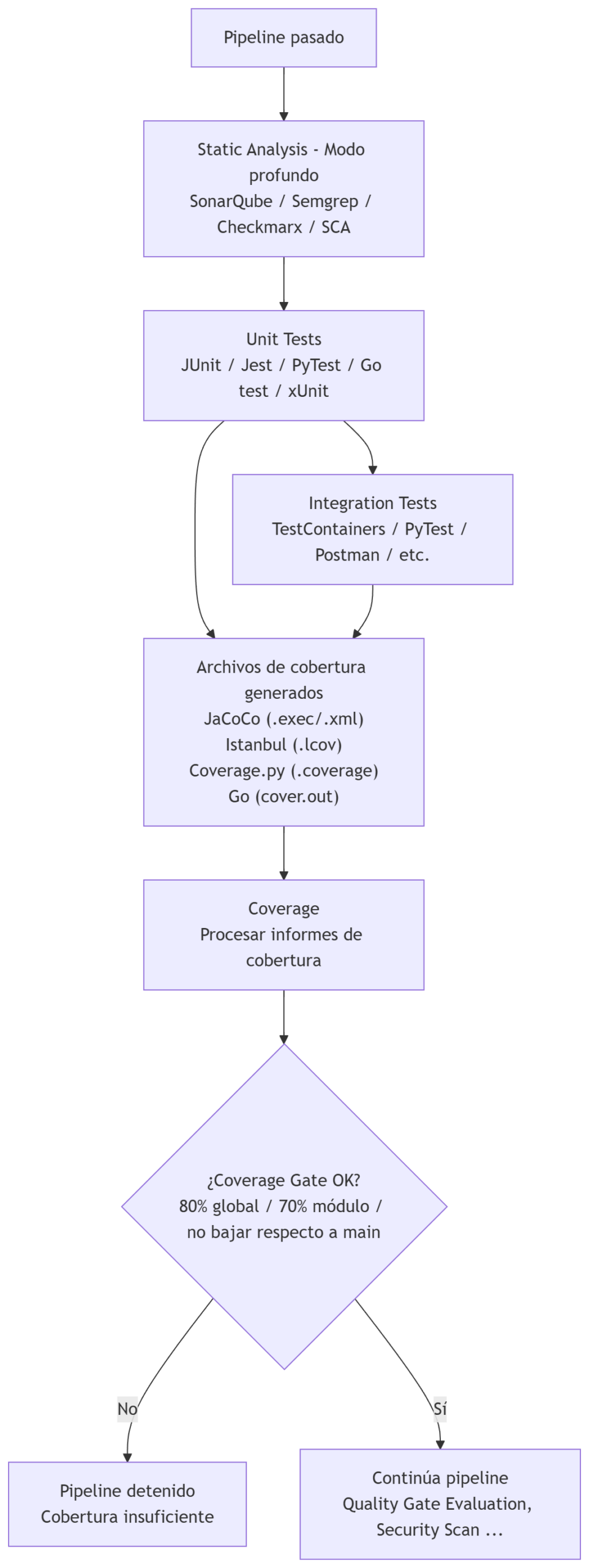
Herramientas por lenguaje
- Java: JaCoCo (genera
.exec/.xml) - JavaScript / TypeScript: Istanbul/NYC (genera
.lcov) - Python: Coverage.py (genera
.coverage) - Go: herramienta nativa
go test -cover(generacover.out)
Gate de cobertura
Ejemplo de etapa Coverage en Jenkins declarativo:
stage('Coverage') {
steps {
sh './gradlew test jacocoTestReport'
junit 'build/test-results/test/*.xml'
publishCoverage adapters: [jacocoAdapter('build/reports/jacoco/test/jacocoTestReport.xml')]
}
}
IA en esta fase
Sustituye esta etapa: NO. La cobertura es un dato objetivo.
Mejora en esta etapa:
- Generar tests automáticamente para aumentar cobertura
- Detectar áreas críticas sin testear
- Sugerir casos de borde que faltan
- Priorizar tests según riesgo (código sensible, seguridad, lógica compleja)
- Explicar por qué una parte del código debería tener tests
Recordatorio del uso de IA de pasos previos:
- Auto-generar tests unitarios
- Auto-generar tests de integración
- Detectar “coverage gaps” en PRs
- Recomendar refactors para mejorar testabilidad
Code Quality Gate
Aquí se consolidan todas las métricas de calidad del código (cobertura, bugs, vulnerabilidades, duplicación, complejidad, deuda técnica) y se evalúa si el proyecto cumple los estándares definidos por la organización.
El resumen rápido de esta etapa:
- Recibe la cobertura generada en la etapa anterior
- Agrega métricas de análisis estático profundo
- Evalúa el Quality Gate (puerta de calidad) definido por la organización
- Decide si el pipeline puede continuar
Este punto sirve para agregar métricas de calidad como:
- Cobertura
- Bugs
- Vulnerabilidades
- Code smells (malos olores de código)
- Complejidad
- Duplicación
- Debt ratio (ratio de deuda técnica)
- Maintainability index (índice de mantenibilidad)
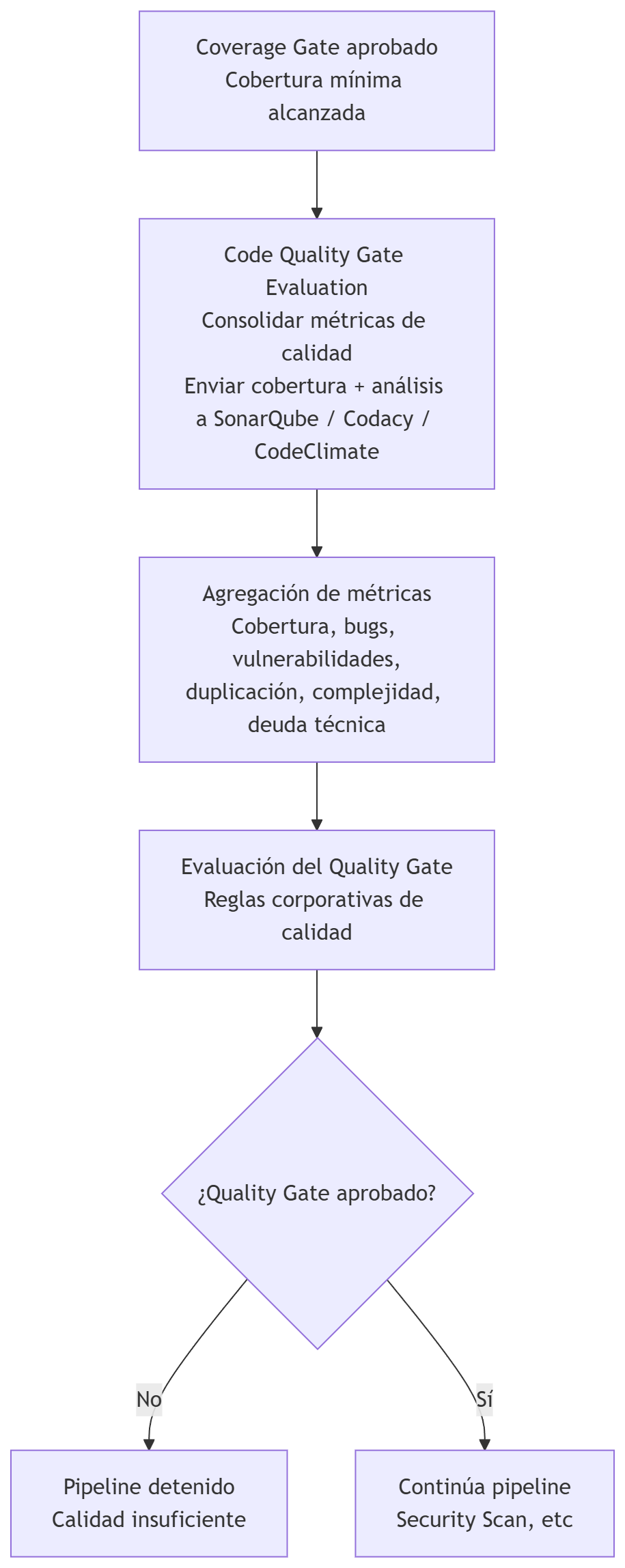
Objetivo: realizar una inspección continua de la calidad y seguridad del código fuente, consolidando todas las métricas generadas en etapas anteriores (análisis estático, cobertura, duplicación, complejidad, etc.) y evaluando si el proyecto cumple los estándares corporativos definidos en el Quality Gate.
Características:
- Detección de problemas: identifica errores (bugs), vulnerabilidades de seguridad y code smells
- Métricas de calidad: analiza complejidad, duplicación, mantenibilidad y cobertura de tests
- Seguridad: evalúa riesgos basados en estándares como OWASP Top 10, SANS Top 25 o CWE
- Multilenguaje: compatible con Java, C#, JavaScript, Python, Go, C++, etc.
- Quality Gate: decide si el código aprueba o no según reglas corporativas
- Reducción de deuda técnica: detecta puntos de mejora para evitar degradación del código
- Automatización: se integra en CI/CD para inspección continua
- Estándares comunes: asegura que todo el equipo sigue las mismas reglas de calidad y seguridad
SonarQube, Codacy, CodeClimate, DeepSource
La herramienta más popular es SonarQube, aunque existen otras:
- SonarQube / SonarCloud
- Codacy
- CodeClimate
- DeepSource
- Semgrep App
- Fortify SSC
- Checkmarx One
- GitLab Code Quality
- GitHub Advanced Security (CodeQL + coverage)
Y sirve para evaluar como un Quality Gate que responde a:
- ¿Cumple los mínimos?
- ¿Hay vulnerabilidades nuevas?
- ¿Ha bajado la cobertura?
- ¿Hay demasiada duplicación?
Comparativa: Coverage Gate vs SonarQube Gate
¿Tiene sentido tener dos Quality Gates de cobertura?
Sí. Las diferencias son que en el step anterior de Coverage Gate:
- Se ejecuta rápido
- Se ejecuta antes de enviar nada a Sonar
- Evita “ensuciar” Sonar con builds fallidos
- Evita análisis innecesarios
- Es un fail fast (fallo rápido)
- Ejemplo: “Si la cobertura < 80%, detén el pipeline inmediatamente.”
Y este step de Code Quality Gate Evaluation que se ejecuta después de enviar cobertura a Sonar (es el Quality Gate final del análisis estático completo) evalúa:
- cobertura
- bugs
- vulnerabilidades
- code smells
- deuda técnica
- mantenibilidad
- Ejemplo: “Coverage on new code ≥ 90%”, “No new critical vulnerabilities”, “Duplicación < 3%”
| Gate | Objetivo | Momento | Ventaja |
|---|---|---|---|
| Coverage Gate (CI) | Fail fast | Antes de Sonar | No malgastas tiempo |
| SonarQube Gate | Calidad global | Después de enviar cobertura | Análisis completo |
IA en esta fase
Sustituye esta etapa: NO. La IA no debe inventar ni simular estos datos. Pues debe ser objetivo:
- El cálculo real de cobertura
- La ejecución de tests
- La verificación objetiva de líneas cubiertas
- La evaluación formal del Quality Gate
- La agregación de métricas de análisis estático
- La validación de reglas corporativas de calidad
Estas tareas requieren:
- Datos reales
- Ejecución real
- Métricas deterministas
- Reglas de negocio
- Auditoría y trazabilidad
Mejora en esta etapa en las siguientes áreas:
-
Generación automática de tests para aumentar cobertura:
- Generar tests unitarios faltantes
- Detectar rutas no cubiertas
- Proponer casos de borde
- Crear tests de integración
- Sugerir mocks y fixtures
-
Explicar por qué falla el Coverage Gate:
- Analizar qué módulos tienen baja cobertura
- Explicar qué líneas no están cubiertas
- Priorizar qué tests faltan
- Sugerir refactors para mejorar testabilidad
-
Mejorar el análisis estático profundo:
- Detectar patrones semánticos que las reglas no ven
- Correlacionar findings entre módulos
- Detectar inconsistencias arquitectónicas
- Sugerir refactors complejos
- Generar parches automáticos
-
Enriquecer el Code Quality Gate Evaluation:
- Explicar findings de SonarQube
- Proponer soluciones
- Detectar falsos positivos
- Priorizar deuda técnica
- Recomendar cambios estructurales
-
Automatizar decisiones del pipeline:
- Predecir si un PR romperá la calidad
- Sugerir cambios antes de ejecutar el pipeline
- Detectar patrones de riesgo en el código
- Recomendar gates dinámicos según criticidad
Security Scan
El stage de Security Scan no es un único paso monolítico, sino un conjunto de jobs paralelos, cada uno especializado en un tipo de análisis (normalmente seguridad a alto nivel, es decir, sin ejecutar el código).
Esta separación permite ejecutar los análisis simultáneamente, reducir el tiempo total del pipeline y aplicar políticas de seguridad independientes.
Finalmente, un Security Gate consolida los resultados y decide si el pipeline puede continuar hacia las fases de build, test o deploy.
Los jobs de seguridad pueden variar. Aquí pondremos de ejemplo los siguientes que suelen ser interesantes:
- SAST (Static Application Security Testing): analiza el código fuente
- SCA (Software Composition Analysis): analiza dependencias y vulnerabilidades conocidas (CVEs)
- Secret Scan (detección de secretos): detecta credenciales expuestas
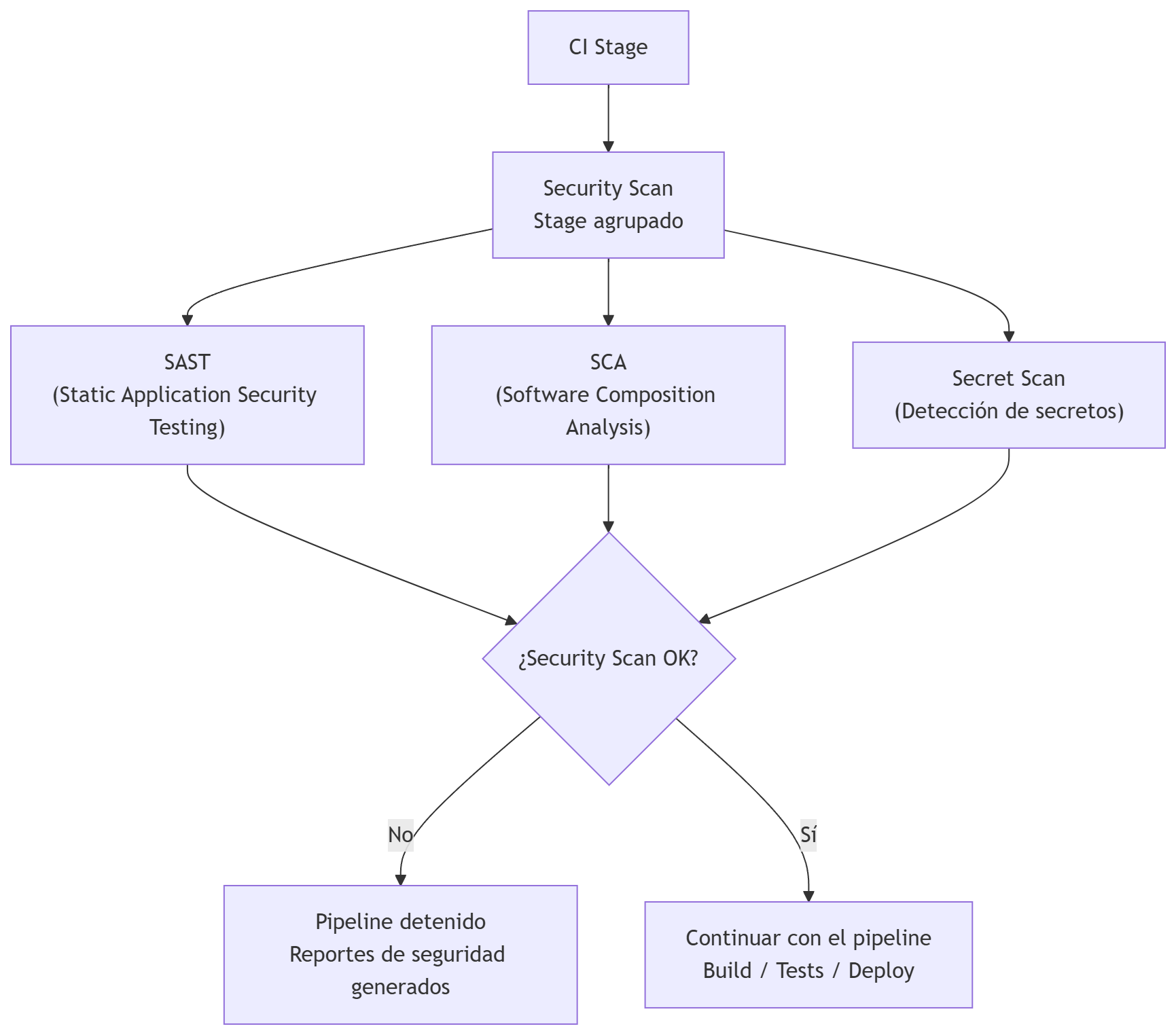
Al terminar, el gate revisa los resultados de los jobs y aplica políticas que queramos como:
- Si hay Critical → bloquear
- Si hay High → depende de la política
- Si hay Medium/Low → permitir pero registrar
Ejemplo en Jenkins:
stage('Security Scan') {
parallel {
stage('SAST') {
steps {
sh 'semgrep --config auto'
}
}
stage('SCA') {
steps {
sh 'trivy fs --scanners vuln .'
}
}
stage('Secret Scan') {
steps {
sh 'gitleaks detect --source .'
}
}
}
}
stage('Security Gate') {
steps {
sh './evaluate-security-results.sh'
}
}
Herramientas integradas que cubren múltiples tipos de análisis:
- Semgrep Platform → SAST + SCA + Secrets + IA.
- DragonSec → SAST + SCA + Secrets + IaC, open‑source.
- Snyk → SCA + contenedores + IaC + algo de SAST
- GitLab Ultimate → SAST + SCA + Secrets + IaC
- GitHub Advanced Security → CodeQL + Dependabot + Secret Scanning
SAST (Static Application Security Testing)
SAST analiza el código fuente sin ejecutarlo. Busca patrones inseguros, malas prácticas, vulnerabilidades lógicas y uso incorrecto de APIs. Su objetivo es detectar fallos de seguridad lo antes posible, idealmente en el PR.
Ventajas:
- Detecta vulnerabilidades antes de compilar o desplegar
- Se integra fácilmente en PR/MR
- Muy útil para lenguajes tipados y frameworks con patrones conocidos
- Permite crear políticas corporativas (reglas custom)
Desventajas:
- Puede generar falsos positivos
- No detecta problemas que dependen del entorno de ejecución
- Requiere mantenimiento de reglas para evitar ruido
- En proyectos legacy puede producir un “tsunami” de findings
Ejemplo de uso en CI/CD:
sast:
stage: security
script:
- semgrep --config auto
allow_failure: false
Herramientas SAST:
- Semgrep → Multilenguaje, reglas personalizables, IA para reducir falsos positivos
- SonarQube → Java, C#, JS, Python, etc. Muy usado en enterprise (entornos empresariales)
- Checkmarx → Amplio soporte de lenguajes, enfoque corporativo
- Fortify Static Code Analyzer → Muy completo, orientado a grandes organizaciones
- CodeQL (GitHub) → Análisis semántico avanzado, muy potente para repos grandes
- DragonSec → SAST para 20+ lenguajes, open‑source, alineado con OWASP Top 10:2025. Github
- Bandit (Python) → Específico para Python
- Brakeman (Ruby on Rails) → Específico para Rails
- GolangCI-Lint (Go) → Incluye reglas de seguridad
IA en esta fase (SAST)
No puede sustituirlo, porque SAST requiere reglas deterministas y trazabilidad.
Sí puede mejorarlo:
- Explicando findings en lenguaje natural
- Proponiendo fixes (correcciones) automáticos
- Priorizando vulnerabilidades según contexto del código
- Generando reglas personalizadas basadas en patrones del repositorio
SCA (Software Composition Analysis)
SCA analiza dependencias, librerías y paquetes para detectar:
- Vulnerabilidades conocidas (CVE, Common Vulnerabilities and Exposures)
- Licencias no permitidas
- Versiones inseguras
Es crítico en entornos modernos donde el 70–90% del código es “third‑party” (de terceros).
Ventajas:
- Detecta vulnerabilidades reales y conocidas
- Permite políticas de licencias (GPL, MIT, Apache…)
- Se integra con PRs para sugerir upgrades automáticos
- Muy rápido: analiza manifests (package.json, pom.xml, etc.)
Desventajas:
- Depende de la calidad de la base de datos CVE
- Puede generar ruido si hay dependencias transitorias profundas
- A veces sugiere upgrades que rompen compatibilidad
- No detecta vulnerabilidades en tu propio código (eso es SAST)
Ejemplo de uso en CI/CD:
sca:
stage: security
script:
- trivy fs --scanners vuln .
allow_failure: false
Herramientas SCA:
- Snyk → SCA + contenedores + IaC
- Trivy → SCA + contenedores + IaC, muy usado en CI/CD
- OWASP Dependency-Check → Open‑source, muy extendido
- GitHub Dependabot → Actualizaciones automáticas de dependencias
- Whitesource / Mend → Enfoque corporativo
- Semgrep Supply Chain → SCA con análisis de “reachability” (solo CVEs explotables). Semgrep
IA en esta fase (SCA)
No puede sustituirlo, porque SCA depende de bases de datos CVE oficiales.
Sí puede mejorarlo:
- Priorizando vulnerabilidades según impacto real en tu código
- Explicando si una CVE afecta realmente a tu uso del paquete
- Proponiendo migraciones automáticas a versiones seguras
- Detectando dependencias no usadas (dead dependencies)
Secret Scanning (Detección de secretos expuestos)
Busca credenciales expuestas en el repositorio:
- API keys (claves de API)
- Tokens OAuth
- Passwords (contraseñas)
- Certificados
- Claves privadas
Su objetivo es evitar filtraciones y accesos no autorizados.
Ventajas:
- Detecta secretos antes de que lleguen a main
- Muy rápido y fácil de integrar
- Compatible con PR/MR y commits individuales
- Evita incidentes de seguridad críticos
Desventajas:
- Puede detectar falsos positivos (ej.: cadenas que parecen claves)
- No evita que un desarrollador suba un secreto cifrado incorrectamente
- No protege secretos en runtime (solo en repositorio)
- Requiere políticas de rotación si detecta un leak (fuga)
Ejemplo de uso en CI/CD:
secret_scan:
stage: security
script:
- gitleaks detect --source .
allow_failure: false
Herramientas Secret Scanning:
- Gitleaks → Muy rápido, open‑source, estándar de facto
- TruffleHog → Escaneo profundo, incluso en historia de Git
- GitHub Secret Scanning → Integrado en GitHub
- GitLab Secret Detection → Integrado en GitLab
- Semgrep Secrets → IA + análisis semántico para reducir falsos positivos. Semgrep
- DragonSec Leaks → 50+ patrones de secretos (AWS, GCP, GitHub, SSH…). Github
IA en esta fase (Secret Scanning)
No puede sustituirlo, porque la detección requiere patrones criptográficos y heurísticas específicas.
Sí puede mejorarlo:
- Clasificando si un secreto es real o falso positivo
- Proponiendo automáticamente la rotación del secreto
- Sugiriendo cómo refactorizar el código para evitar hardcoding (credenciales incrustadas en el código)
- Detectando patrones de riesgo (ej.: “este módulo suele contener claves”)
