Cliente-Servidor: Petición del Cliente
Indicar que he creado este artículo como divulgativo, independientemente de lo que se conozca de desarrollo web, para que pueda ser entendido por cualquiera que haya Navegado por Internet.
He procurado que el artículo sea lo más completo y resumido posible, con imágenes que aclaren. Puedes pensar que es un poco largo, sí es verdad, y sin embargo antes dejo una reflexión: Internet se creó sobre 1969, trabajaron millones de personas por todo el planeta durante décadas, aprender todo lo que te voy a contar me llevo años. Aún con todo voy a describir lo máximo posible el proceso al completo, partiendo de la base que sabes manejar mínimo el Navegador de Internet (sino no sé cómo has llegado a este artículo Web, magia o algo extraño :S ), para que incluso desarrolladores avanzados rellenen lagunas y se pueda desarrollar una página Web a continuación; todo esto en unos pocos párrafos y muchas imágenes 😉
Así que ánimo, considera esta serie de artículos sobre Internet una historia de ciencia Ficción, sin ser historia ni tampoco Ficción; pues es muy del momento real y actual. Una historia porque no vamos a programar nada, que paradójicamente sirve muchísimo para desarrollar.
Cuando te conectas a Internet a cualquier página web como esta, lo que has tenido que hacer primero es ir al “Navegador web” (Chrome, Firefox, Internet Explorer) e introducir la dirección, como por ejemplo la que has introducido para llegar a esta web; vale, puede que hayas llegado aquí haciendo clic en un enlace, pero fíjate que al hacer clic en el enlace has introducido indirectamente la dirección en la “barra de direcciones” (el cuadro de búsqueda superior de tu Navegador). Un ejemplo más simple, podemos escribir la siguiente dirección: www.Jarroba.com

El navegador es lo que se denomina como Cliente, y no el usuario como se suele confundir. El navegador es quien solicita a un Servidor una página web (un Servicio o Recurso).
Ya sé que el usuario -un humano de carne y hueso- es quien escribe una dirección en el navegador, que es quien solicita la información; pero él no hace todo el trabajo que hay por debajo. Así que Cliente es el Navegador, aplicación, o cualquier Software que lanza la petición hacia un Servidor. No hace falta decir que estos clientes están contenidos en el que se considera también cliente físico, el Hardware que se conecta a un Servidor, como el Ordenador/PC de Sobremesa, el portátil, el Smartphone, etc.
Centrémonos en el navegador con el que estás leyendo este artículo (el resto de Clientes funcionan igual). Vayamos paso a paso. Primero escribimos una dirección en el Navegador (o hacemos clic en un vínculo, que hace lo mismo, escribe una dirección en el Navegador de manera automática), una dirección como la que ves ahora en la barra del Navegador como https://jarroba.com/cliente-servidor-peticion-del-cliente.
Dirección Web, URL o URI
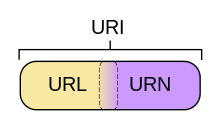
Esta dirección web que insertamos la conocemos como URL (Uniform Resource Locator, localizador de recursos uniforme), aunque también la podremos encontrar con el nombre de URI (Uniform Resource Idenfifier, identificador de recursos uniforme). ¿Qué diferencia hay entre URI y URL? La URI sirve para identificar algo en algún lugar, como un archivo dentro de una serie de carpetas (algo como “carpeta/otra_carpeta/archivo.exe”); la URL localiza un algo cuyo contenido puede cambiar, como esta página web (algo así “jarroba.com/artículos/articulo_x”), hoy la verás como la ves hoy día, mañana puede que cambien los estilos, los textos, las imágenes, etc.
Entonces ¿Una URI no cambia y una URL sí? Ojo con este mal entendido, la URI identifica pudiendo cambiar o no cambiar en toda la vida, la URL localiza por lo que sí puede cambiar; quiere decir que una URL es siempre una URI, pero no toda URI es una URL. ¿Y cómo se llama al URI que nunca cambia? Esto es una curiosidad pues para el tema de web y redes no nos importa, se llama URN (Uniform Resource Name, Nombre de Recurso Uniforme) y sirve para identificar cosas que no cambian como libros o películas publicadas (el ISBN de un libro es una URN por ejemplo).
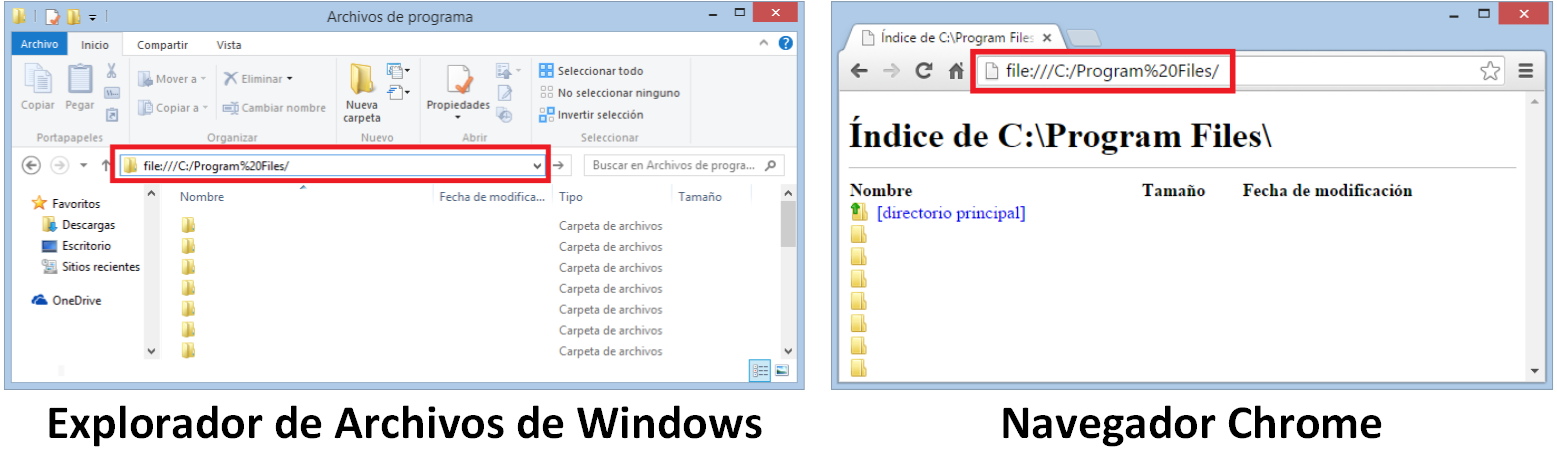
Una URL no solo sirve para ir a una página web como “https://jarroba.com”; sino que también la utilizamos cuando vamos de una carpeta a otra en nuestro sistema operativo como en Windows “file:///C:/Program%20Files/” que es lo mismo que ir a la carpeta “C:\Program Files” (puedes probarlo tanto desde la barra de direcciones del explorador de archivos o de un Navegador; al fin y al cabo, el explorador de archivos es un navegador para navegar entre carpetas); entre otras.
Antes de continuar permíteme maravillarte con una URL con todas sus partes (aunque parece mucho no es tanto como se intuiría a simple vista; tiene su lógica, no todo se usa siempre, y por fortuna no hay que aprenderse nada de esto, solo conocerlo para cuando se necesite saber qué buscar 🙂 ):
http://usuario:contrasenia@jarroba.com:80/articulos/unarticulo/?id=123&busqueda=java#comment-12345
¡Vaya chorro de letras! Que dicen tanto en tan poco.
Partes de una URL
Cada parte sería:
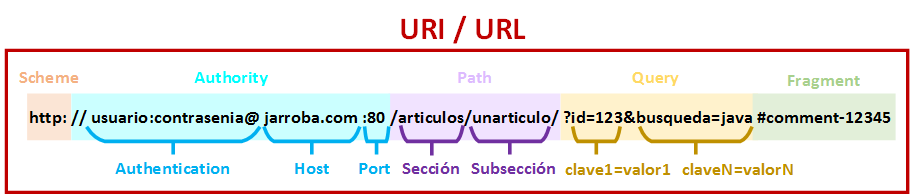
Visto lo anterior una URL se compone (su sintaxis) de las siguientes partes estandarizadas:
Scheme (Esquema)
Identifica de qué tipo es la URL. Es un prefijo que va seguido de dos puntos “:”, como por ejemplo “http:” ¿No se suele poner siempre “http://” con dos barras? Sí, no nos adelantemos. Existen varios tipos de Schemes como:
- http: para el protocolo utilizado para World Wide Web (el que utilizamos para Navegar por Internet).
- https: igual que http para navegar por Internet, pero indica que la conexión va a ir protegida/cifrada (extenderemos la explicación en otro artículo).
- ftp: para transferir archivos entre ordenadores. Si vas a trabajar con Servidores probablemente lo utilices bastante, se suele utilizar mucho por los desarrolladores para subir los archivos que componen una web.
- sftp: lo mismo que ftp, pero enviado fichero protegidos/cifrados
- file: para acceder a ficheros desde dentro del mismo ordenador. Por ejemplo, el que vimos antes “file:///C:/Program%20Files/” que sirve para ir a la carpeta del sistema operativo “C:/Program Files” dentro del ordenador, o rutas con el archivo también como "file:///C:/Program%20Files/musica.mp3"
- mailto: para enviar emails. Por ejemplo si pones la siguiente dirección en el Navegador (no funciona en algunos navegadores) “mailto:jarrobaweb@gmail.com” se abrirá la redacción de nuevo correo para enviar un email a “jarrobaweb@gmail.com”
- data: para incluir datos en la misma URL. Por ejemplo, una imagen codificada en base 64 dentro de la misma URL siguiente que si decodificas (si quieres probarlo puedes buscar en Google "base64 to image online" y copiar la URL siguiente del ejemplo de la imagen en base 64) obtendrás el favicon de Jarroba que puedes ver en la pestaña del Navegador “data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAABAAAAAQCAYAAAAf8/9hAAAABmJLR0QA/wD/AP+gvaeTAAAACXBIWXMAAARuAAAEbgHQo7JoAAAAB3RJTUUH3wsKFgwWdxvwsAAAA61JREFUOMtdk01MIgccxd98gBAIo5W6y2AXW1gUXC3RiLHrbpTd4FdmE0hIqkkvbeyeemx65dCe2sRsvPTYzaYXv2pjiNk1UeKhCeuqQTAiH0GoBATjKEZGYJzpwe2m6e/88vLe/59H4D0+nw/z8/Nwu93NNE33sCxrTyYS32tFsVFkmAVCll+Jori1trZWxn+gAMDj8WBxcRFer9fjcDi8nZ2drW93d8en0+muyasr5RuC6Bj3elMMwwwxDKOMx+PJiYkJJBKJW4NYLIbJycnnQ0ND5mQyKYRCoYX1tbU3KZ5/LvA88TKXW1Wr1T9LknR/YGDgU51OZ11eXt7+EGNsbOzR7Oysf2pq6jsAkGUZAOxtNH1mViqvAZj+1XIc55uZmfFzHDcBANTo6GiTw+H4qlAo3KTT6V+6u7vlSCRCF8/PF150dLR729rotNn8xPvsmd5msz3O5/O/lctlc3t7+wOVSvWWpChqwGQyiYeHh6/X19els7Mzulgs/uDhuMwez6N6eAi2tbXe1dUFjUZDbW5uXl9eXv7R0NBwo1Ao+kmTyXT/6OiIOjk5eQcARqPx2/7+fjqbyxHs/j5aLy5QrdUkkiSJbDa7AwCBQKDI87xkMBiMpFqt1lYqletwOCyOjIzctdlsd0iSxM7u7ilEEQWGgUatlkqlElGv1w98Pt/t+yhKwTDMJ3S9XhdIktQCAEmSD1iWlURRBH9+XjtRqfCR1QpZkuR8Pk+urq4m3x/9idVqrcdiMYkUBKFM07QCAHQ6XSNJkiAIQlbStPLGbodOqwVFUfLx8XEYAIaHh019fX1DFxcXUrVaLVN6vV7d29v7GYCz5uZm48np6UQ6m7W1W621j0ul7kZZRrSpKVsqFP60WCx3nU7nl+VyWRQEAfF4fIus1WpbxWKRNhgMw5FoVNIdHIw8LhYfHmUybk08juvbajc9PT1POY4b53leSKVS+7IsN1Sr1S06GAzWNBrNusvlevTX9rbtXjiMfq0WX9fr+l/LZWxFo8ir1VVGpSI2NjZ2eJ5POp3Oyb29vdfBYLBCAUAikUgzDGP6wuk08vl8n6dQwE+CQDQBeHl1hVeJxHgoFFqwWCxmp9M5ls1mc0tLS4sfxuR2u7GyshJuaWm5+VurfSobjdq6RoNthQIv9PrcN9PTvMvlGmNZ9l4kEnk3Nzf3u8fjQSwWA4H/8XBwsPm4UPhRxzCDd1paLj+321cqlcp5JpNJEQSxGwgESn6/H36/HwDwD6fprBvtjaoPAAAAAElFTkSuQmCC”
![]()
Authority (Autoridad)
Comienza por dos barras “//” (aquí están las dos barras famosas). La Authority es el nombre simbólico de entrada al proveedor. Se compone de dos partes:
- Autentication (Autenticación): para poner el usuario y contraseña, separados por dos puntos “:” y terminado por “@”; del tipo “usuario:contrasenia@”. No suele ser muy conocido, pero es muy cómodo para desarrollo, para no tener que estar teniendo que introducir la dirección, por una parte, y el usuario y contraseña por otra; con este truco se introducen todos los datos de acceso con tan solo copiar y pegar la URL completa. Se suele utilizar mucho para ftp como “sftp://usuario:contrasenia@jarroba.com/ruta”, e incluso para repositorios git privados como “https://usuario:contrasenia@github.com/jarroba.git” (Nota de seguridad: utilizar siempre en conexiones seguras como “https” o “sftp”, sino irá en claro hasta el Servidor y podría ser robados las credenciales de acceso por alguien que esté escuchado por el camino)
- Host: Este es el más fácil de todos “jarroba.com”; es decir, el nombre registrado o la dirección IP como “213.186.33.40”. Dicho de otro modo, la dirección a donde queremos viajar (como comparación, si fuera un teléfono, sería el número de teléfono)
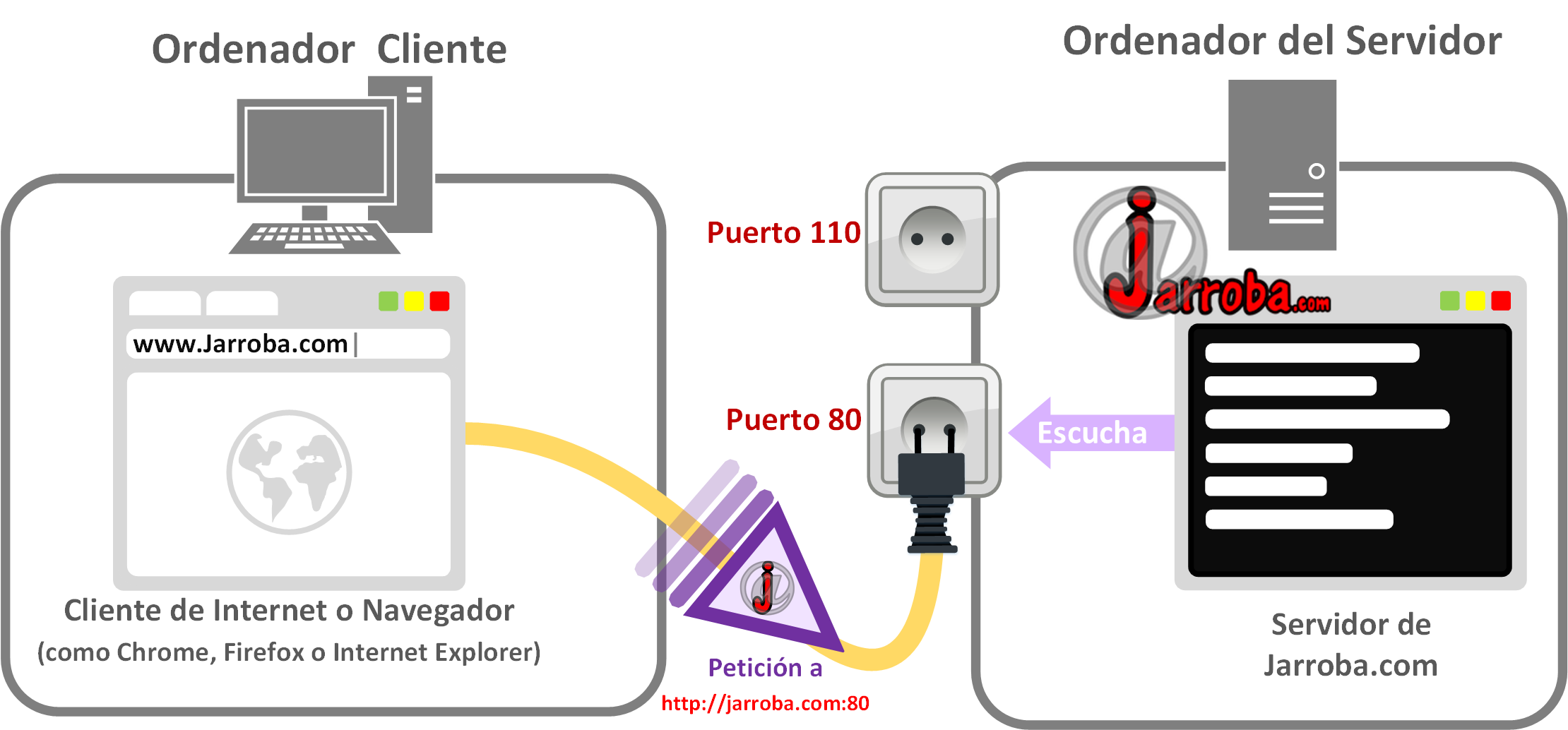
- Port (Puerto): Siempre después de Host comienza con dos puntos “:” y sigue por el número de puerto y aunque no lo parezca siempre hay que ponerlo ¿Pero yo nunca tengo que ponerlo en mi Navegador para ver a una web? Claro, porque te lo pone el navegador por ti de forma automática, mucho más fácil (es como el aire, que no lo veamos no significa que no exista, existe siempre 😉 ). Para entender los puertos te tienes que imaginar que enviamos por un cable una URL tal como “https://jarroba.com:80” hacia otra casa llamada “jarroba.com” que tiene miles de ordenadores, cada ordenador con un enchufe hembra numerado (cada enchufe numerado es un puerto); como nos ha llegado “80” enchufamos dicho cable al ordenador con el puerto “80”, de este modo el ordenador que escucha a su puerto puede recibir datos para trabajar con ellos y enviar respuestas. Entendido lo anterior, extrapólalo a un solo ordenador al que le llega la URL, el sistema operativo es quien se encarga de ver a que puerto dirigir los datos, las aplicaciones/procesos (como un Servidor, un Navegador, un Juego que se conecte a Internet, etc) son las que escuchan los puertos esperando datos por ellos. Un ejemplo es cuando has consultado esta página web en nuestro Servidor, tu ordenador ha recibido una respuesta con el puerto “80” que tu sistema operativo ha redirigido al puerto 80, que identifica justo el HTTP, por lo que entenderás que el Navegador estaba escuchando este puerto esperando la respuesta para mostrarte esta página con éste artículo. Hay miles de puertos que por fortuna no tenemos que aprendernos, sino utilizar el que debamos cuando construyamos URLs (los utilizaremos directamente como desarrolladores; como usuarios nos lo va a poner siempre el programa que utilicemos de manera automática). Veremos más sobre los puertos más adelante.
Path (Ruta)
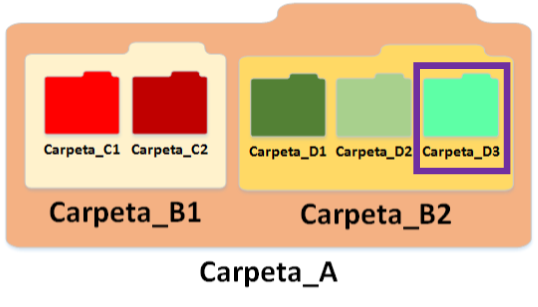
Nombre de la ruta jerárquica que empieza por barra “/”, cada subsección se separa con otra barra “/”, y puede terminar con otra barra “/”. Podrían ser una carpeta que tiene subcarpetas como el siguiente ejemplo, si quiero hacer referencia a la carpeta “Carpeta_D3” haría: “/Carpeta_A/Carpeta_B2/Carpeta_D3”
Query (Consulta)
La parte de las Queries empieza por un símbolo de interrogación “?”. Luego cada consulta consta de una clave y un valor unidos por un símbolo igual “=”, tal como “?clave=valor”; pudiendo separar varios pares de clave y valor por andpersand “&” o por punto y coma “;”, como “?clave1=valor1&clave2=valor2&clave3=valor3”.
La Query se utiliza mucho para realizar consultas en la base de datos, por ejemplo, cuando buscas algo en nuestro buscador como “Programar con Java” podrás ver en la barra del Navegador algo como “https://jarroba.com/?s=Programar+con+Java”, donde la “s” es la clave que el Servidor interpretará como algo que buscar, y “Programar+con+Java” es el valor que hay que buscar en la base de datos.
Imagina que tenemos un formulario de Usuario y Contraseña para iniciar sesión en alguna web, que al pulsar el botón de Login, podríamos hacer una Query como “?user=ramon&contrasenia=abc123”.
Esta manera de enviar datos en la misma URL se conoce como método GET (que veremos un poco más adelante).
Fragment (Fragmento)
El Fragment comienza por almohadilla “#” y simplemente indica una sección de una página web. Lo que hace el Navegador web al cargar la página es desplazar el Scroll hacia esa sección.
Por ejemplo, si pinchas en la fecha de los comentarios de cualquier artículo de esta web te redirigirá a una URL como “https://jarroba.com/reflection-en-java/#comment-21793”, podrás comprobar como al cargar la página, el Navegador bajará el Scroll hasta el elemento HTML con el “id” puesto como Fragment, en el caso de este ejemplo el Navegador buscará el elemento:
<li id='comment-21793'>
¿Qué es "<li …>"?
El tag HTML “li”, que por ejemplo puede ser “<li>Un Texto</li>” simplemente indica que lo que esté dentro de los tags, en el ejemplo “Un Texto” se le pondrá delante una viñeta, como puedes ver a continuación:
- Un Texto
Nota sobre la codificación (URL encode) y decodificación (URL decode) de caracteres de la URL
Las URL solo permite ciertos caracteres, el resto de caracteres hay que tener cuidado al utilizarlos, ya que algunos son especiales para delimitar “:/?#[]@!$&'()*+,;=” (es decir, los utilizados al formar las partes de la URL anteriores). Otros no están permitidos directamente como el carácter de espacio “ ”. De este modo, si queremos escribir algún texto como en la Query “Programar con Java”, hay que realizar la codificación de la URL (URL encode) para convertirlo en “Programar+con+Java” o en “Programar%20con%20Java”. El símbolo de porcentaje “%” con un número de dos cifras detrás indica que se ha codificado un carácter especial (URL encoded character), otro ejemplo es la codificación de un correo como “jarrobaweb@gmail.com” a “jarrobaweb%40gmail.com”. Para hacer lo contrario, se decodificarán los caracteres (URL decoded). Los únicos caracteres que están permitidos para textos son números, dígitos y los caracteres “~.-_”. Por fortuna para todos, existen formas muy sencillas de realizar el “URL encode” y el “URL decode” tanto desde la parte del Servidor como del Cliente, por lo que nuestra preocupación sobre este aspecto será mínima, y si desarrollamos con algún Framework inexistente.
Cuando hacemos clic en un vínculo o escribimos una dirección en el navegador, para realizar la conexión el navegador envía una serie de información. El navegador lo que hace es crear un paquete con varios datos que se llama “HTTP Request” (solicitud HTTP).
HTTP Request
El “HTTP Request” contiene información tanto para el Servidor al que se dirige como para el camino por el que viajarán los datos.

Sus datos son:
Request URL (URL de la solicitud)
La dirección como por ejemplo “www.jarroba.com”
Request Method (Métodos HTTP de la solicitud)
Aquí se envía un verbo, como lo oyes se envía lo que tiene que hacer la URL anterior como “obtener”, “eliminar” o “guardar”, eso sí en inglés GET, DELETE o PUT. Es decir, imagina que estás en tu bandeja de entrada de correo favorita, y pulsas sobre un correo que por dentro hay un link para que se abra otra página web con el contenido del correo; como quiere obtener la información ese link enviará GET como “Request Method”.
Lo mismo con esta web de Jarroba, como es todo información los métodos serán todos GET. Esto lo define el desarrollador al crear formularios normalmente. A la hora de la verdad se suelen utilizar solo dos métodos que si eres desarrollador te interesa conocer, estos son GET y POST ¿Y DELETE, PUT y otros que existen? Se pueden utilizar, pero están en desuso en favor de únicamente estos dos; simplemente he puesto PUT y DELETE para mencionarlos y explicar para que sirve esta información. ¿Qué diferencia hay entre GET y POST?
- GET: Busca cualquier cosa en Google y mira la URL. Será algo como “https://www.google.es/webhp?sourceid=chrome-instant&ion=1&espv=2&ie=UTF-8#q=jarroba” y si te fijas, entre otra información, el contenido de la búsqueda está detrás de un “q=” en la URL. Esto es enviar datos por GET; es decir, el desarrollador que creo el formulario (donde escribes en el buscador de Google) hizo que se enviara el texto directamente concatenada en la misma URL. Una limitación de la URL es que solo permiten 2000 caracteres, así que para textos cortos se puede usar, sino POST.
- POST: Este método es parecido a GET aunque mucho más poderoso, pues permite enviar imágenes, vídeos, ficheros y cualquier otro tipo de archivo además de textos de cualquier longitud. Lo malo -si se puede llamar malo- es que la información no la veremos en la URL, sino que se manda en el “Request Payload Body” (cuerpo de la solicitud) cuerpo de la solicitud. ¿Si es tan bueno, puedo mandar todo por POST? Si configuras el Servidor para que lo acepte sí, requiere un poco más de trabajo para el desarrollador, pero personalmente lo considero muy versátil. ¿Y GET se puede no utilizar para nada? A veces es necesario, el ejemplo de antes de Google hace solicitudes por GET para que el usuario le sea muy sencillo copiar la URL con los datos ya puestos, y poder compartir la búsqueda fácilmente con un amigo; esto con POST no se puede porque si Google lo hubiera hecho por POST posiblemente copiarías solo “https://www.google.es” y nuestro amigo no recibiría la búsqueda que hemos hecho.
Request Payload Body (Cuerpo de la solicitud)
Solo se aparecerá el “Request Payload Body” si el utiliza el método POST o PUT. Contiene los datos codificados en un texto plano que se quieran enviar, datos tales como Textos, Imágenes, Vídeos, etc. Este texto plano se envía al Servidor y será recodificado para cobrar sentido como el dato que se envió original (Nota sobre datos complejos enviados con POST o PUT: si enviamos un fichero, como una imagen o un vídeo, se verá un conjunto de letras sin sentido; no caigamos en la trampa de pensar que está cifrado, pues no lo está ya que es información codificada en formato estándar -posiblemente Base64- que cualquiera puede decodificar en un segundo sin clave alguna).
Request Headers (Cabeceras HTTP de la solicitud)
Estos datos son como una carta de presentación para el Servidor al que se dirige. Indica algunos datos como (muchos más en https://en.wikipedia.org/wiki/List_of_HTTP_header_fields):
- Accept: El tipo de fichero que el navegador aceptará cuando el Servidor le devuelva la información. Algunos son: text/html (acepta documentos de texto con extensión “html”) o image/png (acepta imágenes con extensión “png”). Esta información solo sirve para informar al Servidor y decirle que, si nos envía algo que no acepta el Navegador, lo rechazará por seguridad.
- Accept-Encoding: Formatos de compresión de los ficheros que aceptará el Navegador. Para ahorrar ancho de banda los envíos se comprimen tanto desde Servidor al Cliente y viceversa, y se descomprimen en el otro lado para leer el fichero comprimido. Algunos formatos son: gzip (puede que te recuerde al “zip” de los archivos comprimidos con “Winzip”), deflate o sdch
- Accept-Language: Idiomas humanos admitidos en la respuesta. Pues eso, como “es-ES” para el español de España, “en-US” para el inglés de Estados Unidos, etc.
- Connection: Si la conexión se ha de abrir y cerrar por cada Petición HTTP y Respuesta HTTP, o se mantendrá la conexión para múltiples Peticiones HTTP y Respuestas HTTP. “keep-alive” indica que se va a abrir una única conexión, se enviarán múltiples Peticiones HTTP y se recibirán también varias Respuestas HTTP (Por ejemplo, en nuestro foro puedes enviar varios comentarios y recibir la respuesta de que se han enviado correctamente en una única conexión), y cuando se termine todo entonces se cerrará la conexión (si tuviéramos que abrir y cerrar la conexión por cada petición y respuesta HTTP tardaría mucho más; keep-alive” ahorra mucho tiempo)
- Cookie: La Cookie HTTP (las famosas Cookies cada vez más en desuso, no es más que información que identifica a un Navegador con un usuario; Navegador donde el usuario ha introducido un nombre y una contraseña, de este modo mantener abierta la sesión cuando el usuario navega por la web) que envió con anterioridad un Servidor (estará vacío si es la primera vez que se realiza la petición)
- Host: El nombre del dominio del Servidor como “jarroba.com” o con el puerto como “jarroba.com:80”
- Referer: Dirección de la página web anterior desde la que se navegó. Es decir, estoy en la dirección “jarroba.com/primera” y dentro tiene un botón que me lleva a la “jarroba.com/segunda”; hago clic en éste botón y el Servidor me devuelve la página de “jarroba.com/segunda”, ahora en el Referer pondrá “jarroba.com/primera”
- User-Agent: un texto que indica los datos del Cliente (normalmente el Navegador y el Sistema Operativo) desde el que se hizo la solicitud. Por ejemplo: “Windows NT 6.3; WOW64” que significa que la solicitud se hizo desde un ordenador que tenía instalado Windows 8.1 de 64bits; más datos que pueden ir es “Chrome/41.3”, que indica que se hizo la solicitud desde un Navegador Chrome cuya versión es 41.3
Nota sobre la privacidad del usuario
Después de leer lo anterior puede que genere inquietud saber toda la información que sale de nuestro ordenador hacia Inernet, al alcance de cualquiera (antes, cuando no sabías nada de esto vivías feliz, después de saberlo vas a vivir igual pues es igual que siempre salvo que ahora lo sabes; no hay que preocuparse). No hay que alarmarse, esta información su propósito no es otro que el Servidor conozca qué es lo que quiere el Navegador, para enviarle una información u otra.
Por ejemplo, si el Servidor sabe que se ha hecho la solicitud desde un Móvil, pues puede que, en vez de enviarle un vídeo en máxima calidad, se lo envíe en menos; otro ejemplo, es conocer la versión del Navegador para enviarle contenido Flash o HTML5 o CSS3 pues no todas las versiones de Navegadores son compatibles. Aunque todo esto es positivo y necesario para una buena experiencia de usuario, no quita que se utilice esta información para fines menos éticos (como saber que versión del Navegador tiene el usuario para aprovechar alguna vulnerabilidad de esa versión en concreto; o algunas webs maliciosas que intentan engañar al usuario, haciéndole creer que tienen acceso a su ordenador con el simple hecho de mostrar los datos del Request Header que se envían siempre).
De cualquier manera, si te preocupa la privacidad el Navegador dispone de configuraciones de Seguridad (ver en ayuda del Navegador en cuestión para más información). Lo más aconsejable es Navegador siempre actualizado por parte del usuario, y buenas políticas de seguridad por parte del Servidor.
¿Cómo ver los datos del “Request HTTP”?
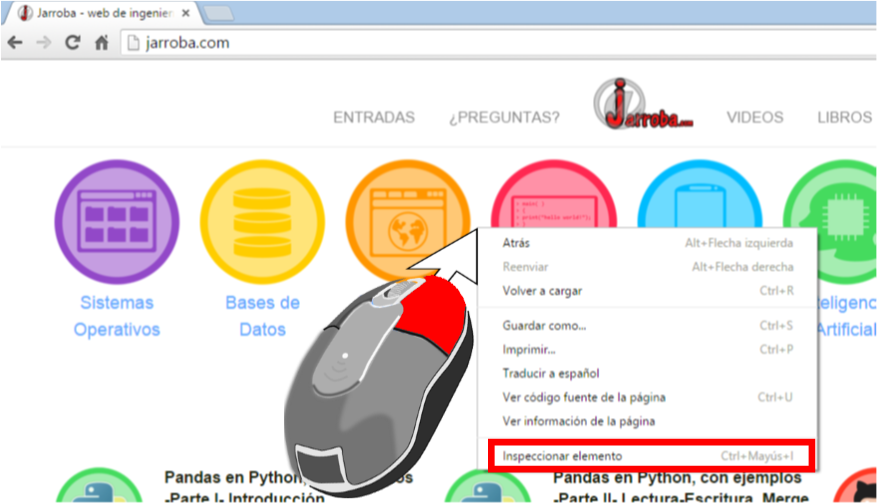
Podemos ver esta información de una manera muy sencilla en nuestro navegador. Simplemente posiciona el cursor en cualquier parte de una web como ésta que estás leyendo, pulsa el botón derecho del ratón y elige “Inspeccionar elemento” (en la imagen de abajo vemos Chrome, pero es muy parecido en todos los navegadores).
Nos abrirá un cuadro con un montón de información de la página (que si no somos desarrolladores de momento no nos interesa, y aprenderemos sobre esto en otros artículos) que se llama “consola de desarrollador” (o también lo puedes ver con el nombre de “Herramientas para desarrolladores”). En este artículo no vamos a desarrollar nada, sino que vamos a cotillear un poco como viene esta información.
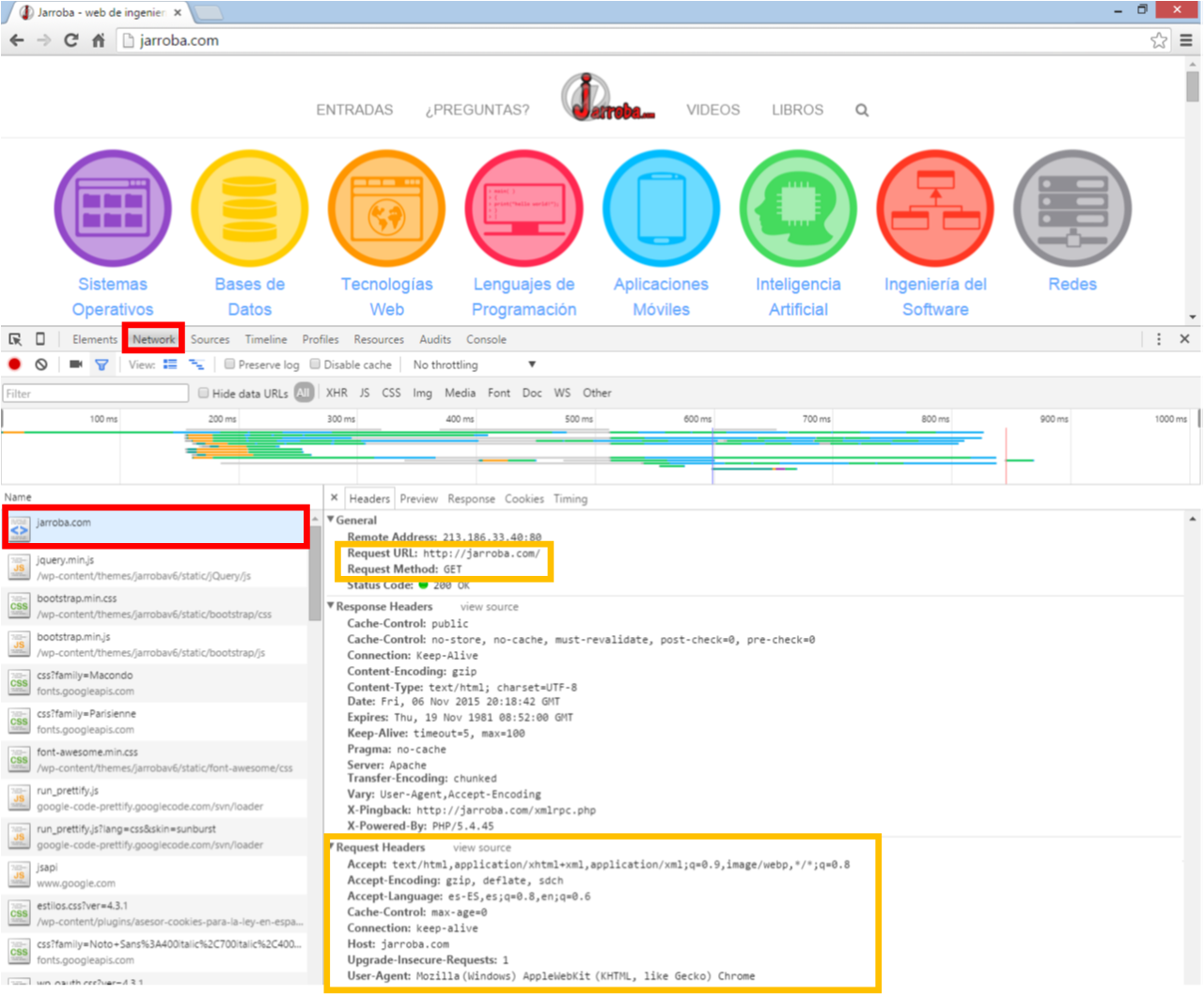
Para ver estos datos iremos a la pestaña llamada “Network” que inicialmente estará vacía (debido a que acabamos de abrir la “consola de desarrollador”, y solo mientras está abierta captura datos), así que refrescamos el navegador pulsado la tecla de “volver a cargar” o directamente la tecla “F5” de nuestro teclado.
Entre todos los datos que se cargan, en el panel de la izquierda llamado “name” buscamos el fichero que coincida con la URL que hemos introducido en el navegador (suele ser el primero o uno de los primeros), lo seleccionamos y a la derecha nos cargará la información de los “Headers”. Para el ejemplo de “www.jarroba.com” veremos que efectivamente el navegador ha enviado al Servidor el “Request URI”, el “Request Method” (como es GET no se envía el “Request Payload Body”) y los “Request Headers”
Aunque hay mucha otra información, todo el resto es información que nos ha enviado el Servidor después de la solicitud. La “consola de desarrollador” nos devuelve la información mezclada la Solicitud/Request del Navegador con la Respuesta/Response del Servidor. En este punto del artículo todavía te estoy contando como hacer solicitudes al Servidor desde el Navegador, al resto de cosas que aparecen ya llegaremos.
Puedes cerrar la “consola de desarrollador” pulsando la “X” de arriba a la derecha de la misma consola.
Hasta aquí es la petición del Cliente. Ahora veamos como salen los datos de nuestro ordenador y viajan hacia otro diferente a través de Internet.
Atribuciones
- Imagen sin modificar de URI = URL + URN por David Torres obtenida de: https://commons.wikimedia.org/wiki/File:URI_Euler_Diagram_no_lone_URIs.svg
Referencias
- Años de experiencia personal
- https://es.wikipedia.org/wiki/Cliente_(inform%C3%A1tica)
- https://es.wikipedia.org/wiki/Cliente-servidor
- https://en.wikipedia.org/wiki/POST_(HTTP)
- https://es.wikipedia.org/wiki/Base64
- https://en.wikipedia.org/wiki/HTTP_cookie
- https://en.wikipedia.org/wiki/Port_(computer_networking)
- https://en.wikipedia.org/wiki/List_of_TCP_and_UDP_port_numbers
- https://es.wikipedia.org/wiki/Hypertext_Transfer_Protocol
- http://www.w3.org/TR/uri-clarification/
- https://en.wikipedia.org/wiki/Uniform_Resource_Identifier
- https://en.wikipedia.org/wiki/Uniform_Resource_Locator
- https://en.wikipedia.org/wiki/Uniform_Resource_Name
- http://tools.ietf.org/html/rfc3986

{kind=link}