¿Cómo instalar TensorFlow con GPU en Windows?
En el artículo «¿Qué debemos saber para instalar correctamente TensorFlow con GPU?» explicamos que elementos (y versiones) eran necesarios instalar para que TensorFlow hiciese uso de la GPU: Drivers de NVidia, CUDA, cuDNN, Python y TensorFlow.
En este artículo vamos a explicar como instalar todos estos elementos siguiendo los siguientes pasos (para una GPU «GeForce RTX 2060» en Windows 10):
- Instalación de los Drivers NVidia para Windows
- Instalación de CUDA Toolkit 11.2
- Instalación de cuDNN 8.1
- Instalación de TensorFlow 2.6.0 en un Python 3.7 (Entorno Virtual con Anaconda)
Como último paso:
- Probaremos el correcto funcionamiento de TensorFlow haciendo uso tanto de la GPU como de la CPU y veremos sus diferencias en tiempos de entrenamiento; con la librería ai-benchmark
Prerrequisitos:
Para poder seguir los pasos de este tutorial se debe tener ya instalado:
- Compilador de Microsoft Visual C++: CUDA Toolkit hace uso del compilador de C++. La forma más sencilla de instalarlo es a través de Microsoft Visual Studio.
- Anaconda: Necesario para crear un entorno virtual con Python 3.7 y TensorFlow-gpu 2.6.0. Se utilizará en este tutorial para probar el correcto uso de la GPU con TensorFlow. En el siguiente enlace del Curso «Python desde cero, con ejemplos» se muestran los pasos para la instalación de Anaconda: https://jarroba.com/curso-de-python-0-entorno-de-desarrollo-para-python/
Instalación de los Drivers:
Sabiendo la GPU que tenemos y el sistema operativo sobre el que queremos trabajar, nos vamos a la web de NVidia en las sección de descarga de Drivers (https://www.nvidia.es/Download/index.aspx?lang=es) y rellenamos el formulario:

Una vez relleno, pulsamos en buscar y nos llevará a una página donde nos dará información sobre la versión del driver a descargar y lo descargaremos:

Con los Drives descargados (en un archivo .exe), procedemos a su instalación en modo «Gilipollez tipo Windows: si a todo (Quequé)«:
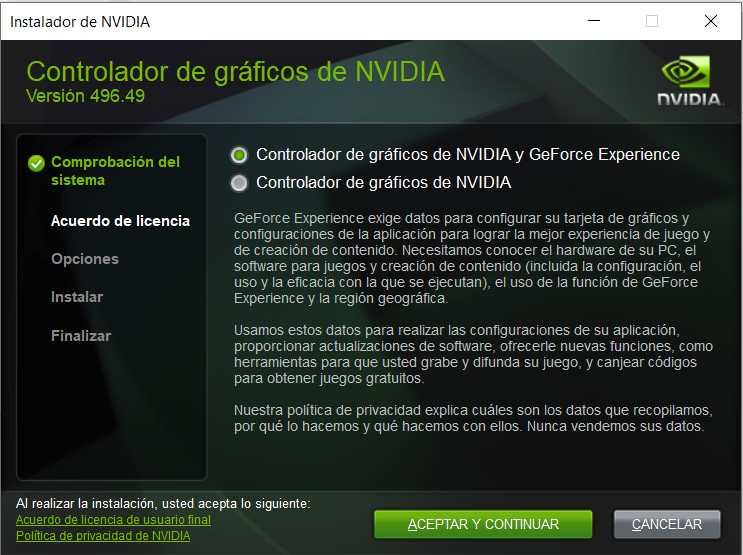
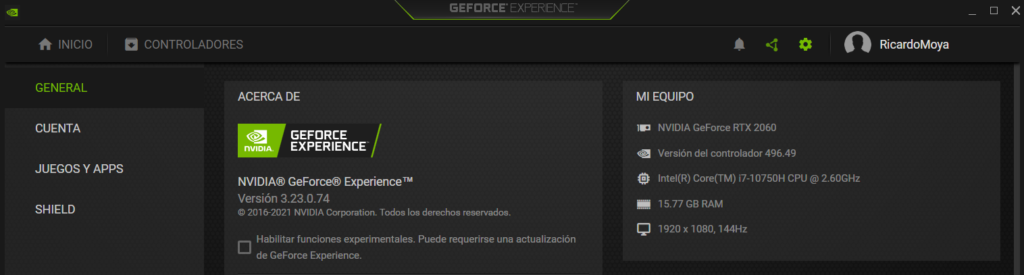
Una vez instalado podemos acceder a la aplicación «GeForce Experience» de NVidia y ver las características de nuestro PC (Drivers y GPU entre otros):
Instalación de CUDA Toolkit 11.2:
Antes de instalar CUDA, debemos de saber que versiones de CUDA son compatibles con la versión de los Drivers instalada. Para ello nos vamos al siguiente enlace (https://docs.nvidia.com/deploy/cuda-compatibility/index.html#minor-version-compatibility) para ver las compatibilidades.
En nuestro caso (y como ya explicamos en el artículo «¿Qué debemos saber para instalar correctamente TensorFlow con GPU?«) vamos a descargar la versión 11.2 de CUDA. Para ello nos vamos a la web de descarga (https://developer.nvidia.com/cuda-toolkit-archive) y seleccionamos la versión 11.2 que queremos descargar:

Posteriormente seleccionamos el sistema operativo (Windows) y el tipo de instalación (.exe) y nos darán el enlace para la descarga:
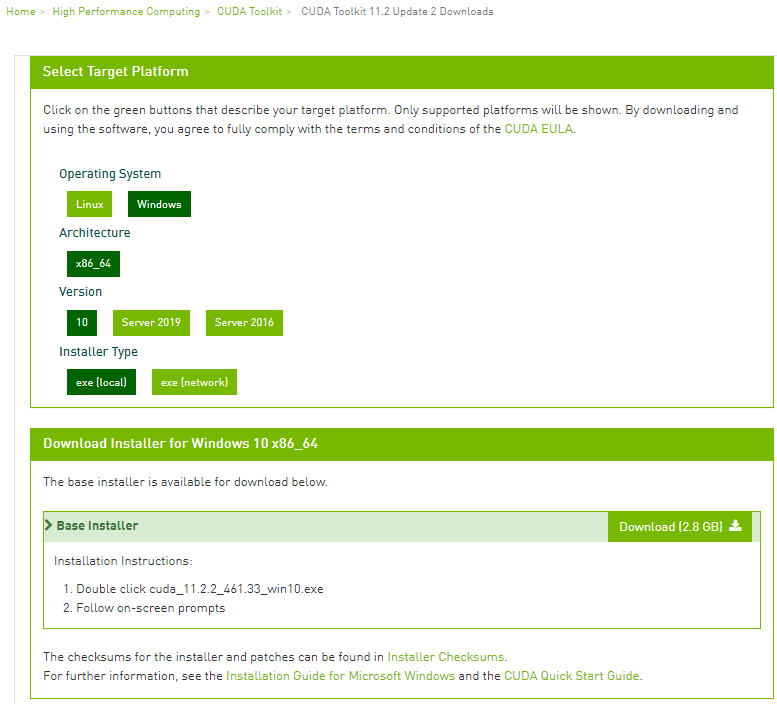
Procedemos a la instalación «personalizada» y «dándole» a todo que «si» y «siguiente»:
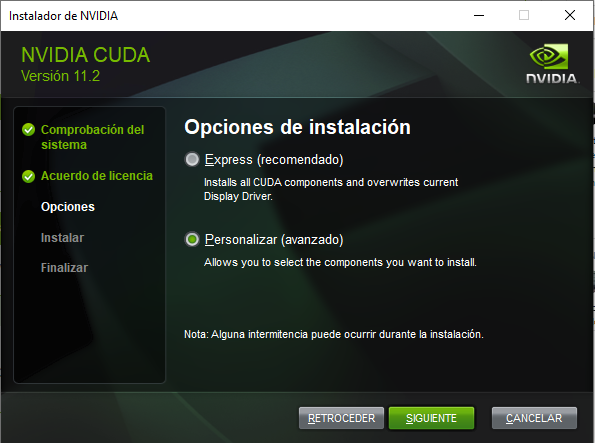
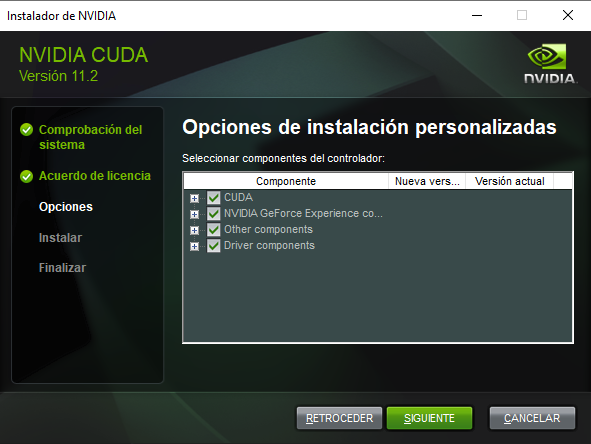
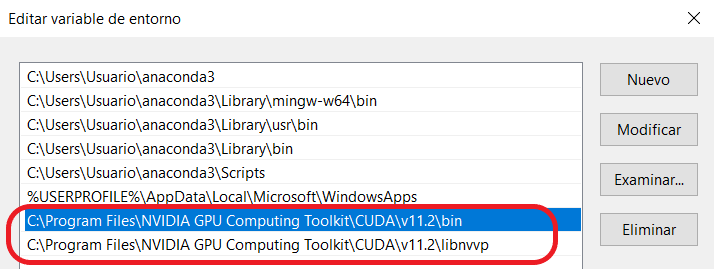
IMPORTANTE: Una vez instalado CUDA, debes de añadirlo a las variables de entorno. CUDA tiene que estar en la carpeta de «Archivos de Programa -> NVIDIA GPU Computing Toolkit -> CUDA -> «versión» (v11.2) -> bin». También debes de añadir la carpera «libnvvp»:
Instalación de cuDNN 8.1:
El primer paso es la descarga de cuDNN. Para descargarlo es necesario registrarse en la web de NVidia: https://developer.nvidia.com/cudnn-download-survey.

Una vez registrados procedemos a descargar la versión de cuDNN que quereamos; en nuestro caso la versión 8.1. En el siguiente enlace se encuentran las diferentes versiones de cuDNN: https://developer.nvidia.com/rdp/cudnn-archive.
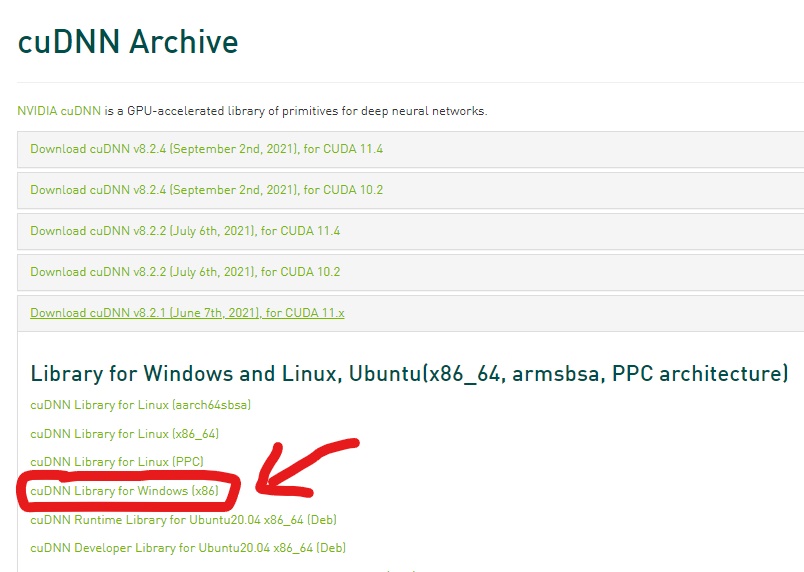
cuDNN no es un instalador. Si abrimos el archivo comprimido que nos descargamos, veremos que el nombre de la carpeta descargada se llama «cuda» y contiene una serie de carpetas (bin, include y lib) con unos ficheros:
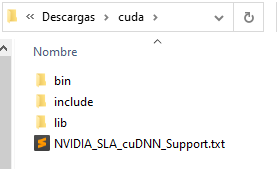
Estos ficheros debemos de copiarlos en las respectivas carpetas (bin, include y lib) de la versión 11.2 de CUDA que se encuentran (si se ha realizado la instalación estándar) en «C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.2»:
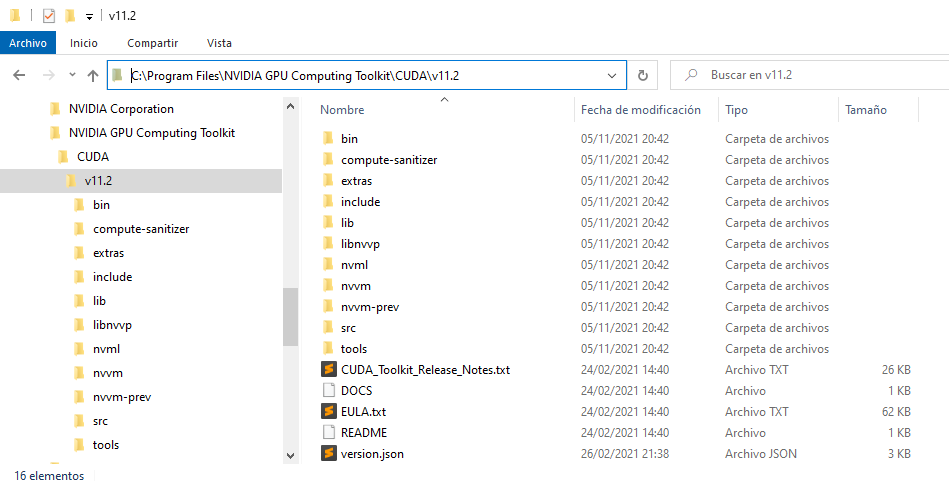
Por tanto hay que copiar todos los fichero de cuDNN de las capetas bin, include y lib a las mismas carpetas de CUDA:
![]()
Instalación de TensorFlow 2.6.0 en un Python 3.7:
Vamos a crear un nuevo entorno virtual con Anaconda con Python 3.7 en el que instalaremos la versión 2.6.0 de tensorflow-gpu. Para crear un nuevo entorno (que llamaremos «test_tensorflow_gpu») abrimos un terminal de anaconda y ponemos:
>> conda create -n test_tensorflow_gpu python=3.7
Una vez instalado, activamos el entorno de la siguiente manera
>> conda activate test_tensorflow_gpu
E instalamos la versión 2.6.0 de tensorflow con pip
>> pip install tensorflow-gpu==2.6.0
Para comprobar que hemos instalado correctamente tensorflow-gpu y que este funciona, habrimos un terminal de python y ponemos lo siguiente (Cuidado con las indentaciones):
>>> import tensorflow
>>> from tensorflow.python.client import device_lib
>>> def print_info():
... print(' Versión de TensorFlow: {}'.format(tensorflow.__version__))
... print(' GPU: {}'.format([x.physical_device_desc for x in device_lib.list_local_devices() if x.device_type == 'GPU']))
... print(' Versión Cuda -> {}'.format(tensorflow.sysconfig.get_build_info()['cuda_version']))
... print(' Versión Cudnn -> {}\n'.format(tensorflow.sysconfig.get_build_info()['cudnn_version']))
...
>>> print_info()
Como resultado a este código tenemos la información de las versiones de TensorFlow, CUDA y cuDNN; así como información de la GPU:
Versión de TensorFlow: 2.6.0 GPU: ['device: 0, name: NVIDIA GeForce RTX 2060, pci bus id: 0000:01:00.0, compute capability: 7.5'] Versión Cuda -> 64_112 Versión Cudnn -> 64_8
Probando TensorFlow GPU (con ai-benchmark):
ai-benchmark es una librería para evaluar el rendimiento del hardware (GPU, TPU y CPU) con TensorFlow; evaluando los tiempos de entrenamiento y predicción de los modelos pre entrenados más populares como: MobileNet, Inception, ResNet, VGG, etc.
Instalaremos esta librería con pip (teniendo el entorno virtual antes creado activado) de la siguiente manera:
>> pip install ai-benchmark
A continuación abriremos un terminal de Python y evaluaremos los tiempo de entrenamiento de estos modelos (tanto con GPU como con CPU) de la siguiente manera (PACIENCIA: tarda bastante tiempo en ejecutarse):
Para GPU
>>> from ai_benchmark import AIBenchmark >>> benchmark_gpu = AIBenchmark(use_CPU=False) >>> benchmark_gpu.run_training()
Obtenemos los siguientes resultados de tiempos de entrenamiento:
* TF Version: 2.6.0 * Platform: Windows-10-10.0.19041-SP0 * CPU: N/A * CPU RAM: 16 GB * GPU/0: NVIDIA GeForce RTX 2060 * GPU RAM: 3.9 GB * CUDA Version: 11.2 * CUDA Build: V11.2.152 The benchmark is running... The tests might take up to 20 minutes Please don't interrupt the script 1/19. MobileNet-V2 1.1 - training | batch=50, size=224x224: 325 ± 5 ms 2/19. Inception-V3 2.1 - training | batch=20, size=346x346: 385 ± 2 ms 3/19. Inception-V4 3.1 - training | batch=10, size=346x346: 407 ± 5 ms 4/19. Inception-ResNet-V2 4.1 - training | batch=8, size=346x346: 451 ± 4 ms 5/19. ResNet-V2-50 5.1 - training | batch=10, size=346x346: 236 ± 2 ms 6/19. ResNet-V2-152 6.1 - training | batch=10, size=256x256: 357 ± 7 ms 7/19. VGG-16 7.1 - training | batch=2, size=224x224: 293 ± 3 ms 8/19. SRCNN 9-5-5 8.1 - training | batch=10, size=512x512: 387 ± 2 ms 9/19. VGG-19 Super-Res 9.1 - training | batch=10, size=224x224: 465 ± 8 ms 10/19. ResNet-SRGAN 10.1 - training | batch=5, size=512x512: 308 ± 6 ms 11/19. ResNet-DPED 11.1 - training | batch=15, size=128x128: 349 ± 4 ms 12/19. U-Net 12.1 - training | batch=4, size=256x256: 429 ± 8 ms 13/19. Nvidia-SPADE 13.1 - training | batch=1, size=128x128: 344 ± 3 ms 14/19. ICNet 14.1 - training | batch=10, size=1024x1536: 475 ± 18 ms 15/19. PSPNet 15.1 - training | batch=1, size=512x512: 317 ± 4 ms 16/19. DeepLab 16.1 - training | batch=1, size=384x384: 263 ± 2 ms 17/19. Pixel-RNN 17.1 - training | batch=10, size=64x64: 8149 ± 760 ms 18/19. LSTM-Sentiment 18.1 - training | batch=10, size=1024x300: 3692 ± 220 ms 19/19. GNMT-Translation Device Training Score: 6172
Para CPU
>>> benchmark_cpu = AIBenchmark(use_CPU=True) >>> benchmark_cpu.run_training()
Obtenemos los siguientes resultados de tiempos de entrenamiento:
* TF Version: 2.6.0 * Platform: Windows-10-10.0.19041-SP0 * CPU: N/A * CPU RAM: 16 GB The benchmark is running... The tests might take up to 20 minutes Please don't interrupt the script 1/19. MobileNet-V2 1.1 - training | batch=50, size=224x224: 3148 ± 83 ms 2/19. Inception-V3 2.1 - training | batch=20, size=346x346: 6586 ± 239 ms 3/19. Inception-V4 3.1 - training | batch=10, size=346x346: 7742 ± 106 ms 4/19. Inception-ResNet-V2 4.1 - training | batch=8, size=346x346: 10347 ± 47 ms 5/19. ResNet-V2-50 5.1 - training | batch=10, size=346x346: 4618 ± 13 ms 6/19. ResNet-V2-152 6.1 - training | batch=10, size=256x256: 6686 ± 66 ms 7/19. VGG-16 7.1 - training | batch=2, size=224x224: 2069 ± 70 ms 8/19. SRCNN 9-5-5 8.1 - training | batch=10, size=512x512: 18523 ± 415 ms 9/19. VGG-19 Super-Res 9.1 - training | batch=10, size=224x224: 23369 ± 95 ms 10/19. ResNet-SRGAN 10.1 - training | batch=5, size=512x512: 11348 ± 132 ms 11/19. ResNet-DPED 11.1 - training | batch=15, size=128x128: 13336 ± 1105 ms 12/19. U-Net 12.1 - training | batch=4, size=256x256: 8660 ± 74 ms 13/19. Nvidia-SPADE 13.1 - training | batch=1, size=128x128: 3285 ± 88 ms 14/19. ICNet 14.1 - training | batch=10, size=1024x1536: 5136 ± 16 ms 15/19. PSPNet 15.1 - training | batch=1, size=512x512: 5876 ± 104 ms 16/19. DeepLab 16.1 - training | batch=1, size=384x384: 4025 ± 21 ms 17/19. Pixel-RNN 17.1 - training | batch=10, size=64x64: 10582 ± 201 ms 18/19. LSTM-Sentiment 18.1 - training | batch=10, size=1024x300: 25986 ± 19 ms 19/19. GNMT-Translation Device Training Score: 392
Conclusión GPU vs CPU
Realizadas estas pruebas con la GPU y CPU podemos observar como entrenar modelos con una GPU es unas 8 o 10 veces más rápido que hacerlo con una CPU. En particular vemos como el tiempo de entrenamiento de la «MobileNet-V2» para un batch de 50 es de 325 ms con GPU frente a 3148 ms que tarda con una CPU; es decir, casi 10 veces más rápido con una GPU que con una CPU.
