CPU vs GPU en Deep Learning: ¿Cuánta diferencia hay en tiempo de entrenamiento?
El código de este post los puedes descargar de GitHub pulsando AQUI.
El uso de GPUs en Deep Learning (Redes Neuronales) para el entrenamiento de modelos esta cada vez más extendido debido a la importante reducción en los tiempos de entrenamiento de los modelos. Pero ¿Sabemos cuantificar cuánta diferencia hay en tiempos de entrenamiento de un modelo entre una CPU y una GPU?. Seguro que si buscamos por internet podemos encontrar conclusiones como que el uso de GPU vs CPU es de entre 8 y 12 veces más rápido y efectivamente dependiendo del problema a resolver y del hardware que utilicemos esa podría ser la horquilla de mejora en tiempos entre una GPU y CPU. En el ejemplo que vamos a mostrar a continuación veremos como con la GPU el entrenamiento del modelo será 9,6 veces más rápido que con la CPU:
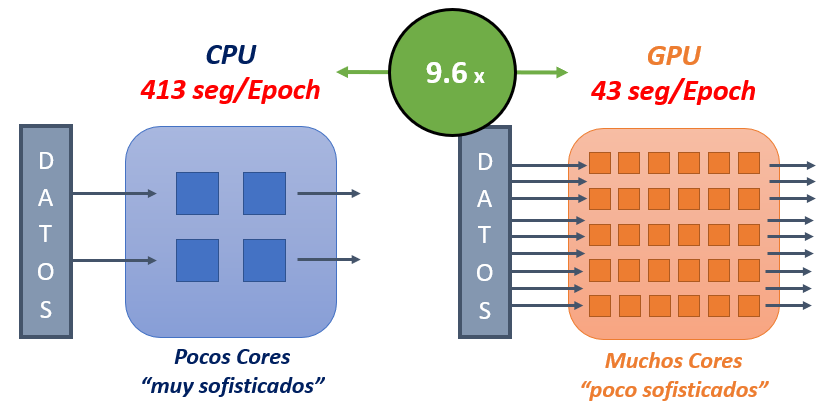
Así que, para demostrar las mejoras de los tiempos de entrenamiento para modelo de Deep Learning entre una CPU y GPU vamos a resolver un problema de «Clasificación de imágenes con Redes Neuronales Convolucionales con TensorFlow» y vamos a ver de manera empírica las diferencias de tiempo entre entrenarlo con una CPU y una GPU.
NOTA-> Si quieres ejecutar el proyecto que comparto y tienes ciertas dudas sobre GPUs, TensorFlow y demás, os comparto los siguientes enlaces a otros artículos que os pueden ser de interés:
- Si quieres saber las diferencias que hay entre una CPU y una GPU, te interesará el post: Python vs Numpy vs GPU (TensorFlow): Tiempos de Ejecución
- Si quieres saber cuales son los requisitos hardware y software para instalar correctamente TensorFlow con GPU, te interesará: ¿Qué debemos saber para instalar correctamente TensorFlow con GPU?
- Si quieres saber cómo instalar TensorFlow para que use la GPU en Windows, te interesará el post: ¿Cómo instalar TensorFlow con GPU en Windows?
Hardware utilizado para el experimento
Para los experimentos se dispone de un ordenador portátil con la siguiente CPU y GPU:
- CPU: intel core i7 10750h / 2.6 ghz
- GPU: NVIDIA GeForce RTX 2060 8GB
Entorno virtual Python para la ejecución
Vamos a crear un nuevo entorno virtual con Anaconda con Python 3.7 en el que instalaremos la versión 2.7.0 de tensorflow-gpu. Para crear un nuevo entorno (que llamaremos «test_tiempos_gpu_cpu») abrimos un terminal de anaconda y ponemos:
>> conda create -n test_tiempos_gpu_cpu python=3.7
Una vez instalado, activamos el entorno de la siguiente manera
>> conda activate test_tiempos_gpu_cpu
E instalamos la versión 2.7.0 de tensorflow con pip
>> pip install tensorflow-gpu==2.7.0
Previamente ya se tiene configurada correctamente la GPU con los Drivers y con un CUDA 11.2 y un cuDNN 8.1
Dataset
En Dataset con las imágenes a clasificar lo hemos obtenido de Kaggle: https://www.kaggle.com/alaanagy/8-kinds-of-image-classification
Para poder ejecutar este proyecto (bien sea en el notebook o en el Script) se debe de descargar este Dataset y guardarlo en la carpeta «data» del proyecto.
Este Dataset contiene 3 carpetas (pred, test y train) con 35.000 imágenes clasificadas en 8 clases diferentes: seas, streets, buildings, glaciers, mountains, forests, cats, and dogs.
Detalles del Script de ejecución
Imprimir por pantalla información de la versión de TensorFlow, versiones de CUDA cuDNN y GPU disponible
Con el siguiente fragmento de código obtenemos la información:
import tensorflow.keras
from tensorflow.python.client import device_lib
print('#### INFORMACIÓN ####')
print(' Versión de TensorFlow: {}'.format(tensorflow.__version__))
print(' GPU: {}'.format([x.physical_device_desc for x in device_lib.list_local_devices() if x.device_type == 'GPU']))
print(' Versión Cuda -> {}'.format(tensorflow.sysconfig.get_build_info()['cuda_version']))
print(' Versión Cudnn -> {}\n'.format(tensorflow.sysconfig.get_build_info()['cudnn_version']))
Obteniendo como salida
#### INFORMACIÓN #### Versión de TensorFlow: 2.7.0 GPU: ['device: 0, name: NVIDIA GeForce RTX 2060, pci bus id: 0000:01:00.0, compute capability: 7.5'] Versión Cuda -> 64_112 Versión Cudnn -> 64_8
Cargamos las imágenes de Entrenamiento y Test
Las carpetas test y train que son las que vamos a usar, contienen a su vez otras 8 carpetas; una por cada categoría, donde en cada una de esas carpetas están las imágenes clasificadas por su categoría. Veamos a continuación la estructura de carpetas:
|-data
| |-test
| |-buildings
| |-cat
| |-dog
| |-forest
| |-glacier
| |-mountain
| |-sea
| |-street
| |-train
| |-buildings
| |-cat
| |-dog
| |-forest
| |-glacier
| |-mountain
| |-sea
| |-street
Para este experimento, vamos a crearnos dos objetos de la clase ImageDataGenerator, que dada una carpeta (en nuestro caso la carpeta train y test) generará tantas imágenes como le indiquemos para el entrenamiento del modelo y para su validación (conjunto de imágenes de test).
«Crearemos» tantas imágenes como le indiquemos a la clase ImageDataGenerator, ya que permite generar nuevas imágenes a partir de una dada haciendo ciertas modificaciones como rotaciones o zooms.
Para este experimento vamos a crear 2 conjuntos de imágenes:
- train_generator: a partir de las carpeta de las imágenes de train, redimensionará las imágenes de tamaño 150×150 (PIXELES) y generará grupos de 32 imágenes (BATCH_SIZE), normalizadas y pudiendo realizar rotaciones (rotation_range) de 20 grados y zoom de hasta un 20% (zoom_range), pudiendo también modificar hasta un 20% de los píxeles de una foto (shear_range).
- test_generator: a partir de las carpeta de las imágenes de test, redimensionará las imágenes de tamaño 150×150 (PIXELES) y generará grupos de 32 imágenes (BATCH_SIZE), normalizadas. Dado que estas imágenes representan la «realidad», no realizaremos modificaciones de las mismas.
from tensorflow.keras.preprocessing.image import ImageDataGenerator
# CONSTANTES:
PIXELES = 150 # Pixeles del alto y ancho de la imagen p.e-> (150,150)
NUM_EPOCHS = 10 # Número de epochs
BATCH_SIZE = 32 # Número de imágenes por batch
NUM_BATCHES_PER_EPOCH = 1000 # Número de Batches a realizar en cada EPOCH
# Definimos como modificar de manera aleatoria las imágenes (pixeles) de entrenamiento
# https://www.tensorflow.org/api_docs/python/tf/keras/preprocessing/image/ImageDataGenerator
# rescale = normalizamos los pixeles
# shear_range = rango de modificación aleatorio
# zoom_range = rango de zoom aleatorio
# ratation_range = máximo ángulo de rotación aleatoria de la imagen
# horizontal_flip = Giro aleatorio de las imágenes
train_datagen = ImageDataGenerator(rescale=1. / 255,
shear_range=0.2,
zoom_range=0.2,
rotation_range=20,
horizontal_flip=True)
# Definimos como modificar las imágenes (pixeles) de test
# rescale = normalizamos los pixeles
test_datagen = ImageDataGenerator(rescale=1. / 255)
# Definimos como son nuestras imágenes de entrenamiento y test
# directory = ruta donde se encuentran las imágenes (una clase por carpeta)
# target_size = tamaño de las imágenes 150x150. Se redimensionan a ese tamaño
# batch_size = Nº de imágenes tras la que se calcularán los pesos de la res
# class_mode = tipo de clasificación: binaria
train_generator = train_datagen.flow_from_directory(directory='./data/train',
target_size=(PIXELES, PIXELES),
batch_size=BATCH_SIZE,
class_mode='categorical')
test_generator = test_datagen.flow_from_directory(directory='./data/test',
target_size=(PIXELES, PIXELES),
batch_size=BATCH_SIZE,
class_mode='categorical')
num_classes = train_generator.num_classes
print("Nº de Imágenes para entrenamiento: {}".format(train_generator.n))
print("Nº de Imágenes para test: {}".format(test_generator.n))
print("Nº de Clases a Clasificar: {} Clases".format(num_classes))
La ejecución de este fragmento de código nos muestra de tenemos disponibles 18687 imágenes para el entrenamiento y 4463 imágenes para el test de 8 clases distintas. A partir de estas imágenes, generaremos tantas imágenes como queramos modificándolas como antes hemos comentado
Found 18687 images belonging to 8 classes. Found 4463 images belonging to 8 classes. Nº de Imágenes para entrenamiento: 18687 Nº de Imágenes para test: 4463 Nº de Clases a Clasificar: 8 Clases
Definimos el modelo de la Red Neuronal Convolucional (CNN)
Definimos una red neuronal con la siguiente arquitectura:
- Imágenes de Entrada 150 pixeles Ancho, 150 Pixeles de Alto, 3 Canales
- Capa Convolucional: 32 filtros, kernel (3×3), Función Activación RELU
- MaxPooling: Reducción de (2,2)
- Capa Convolucional: 64 filtros, kernel (3×3), Función Activación RELU
- MaxPooling: Reducción de (2,2)
- Capa Flatten: Capa de entrada del clasificador. Pasa cada Pixel a neurona
- Capa Oculta 1: 512 Neurona, Función Activación RELU
- Capa Oculta 2: 64 Neurona, Función Activación RELU
- Capa Salida: 8 Neurona (8 Clases), Función Activación SOFTMAX
El modelo va a tener 42 Millones de parámetros (exactamente 42.520.584 parámetros)
Para la optimización de los parámetros de la red utilizaremos:
- Función de perdida: categorical_crossentropy
- Optimizador: ADAM
- Métricas a monitorizar: Accuracy
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D
from tensorflow.keras.layers import MaxPooling2D
from tensorflow.keras.layers import Flatten
from tensorflow.keras.layers import Dense
from tensorflow.keras.layers import Dropout
# Definimos el modelo
model = Sequential()
model.add(Conv2D(filters=32,
kernel_size=(3, 3),
input_shape=(PIXELES, PIXELES, 3),
activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(filters=64,
kernel_size=(3, 3),
activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten())
model.add(Dense(512, activation='relu'))
model.add(Dropout(0.2))
model.add(Dense(64, activation='relu'))
model.add(Dropout(0.2))
model.add(Dense(num_classes, activation='softmax'))
# Imprimimos por pantalla la arquitectura de la red definida
print(model.summary())
# Compilamos el modelo
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['categorical_accuracy'])
Llamando a la función «summary()» nos imprime por pantalla las capas de la rede neuronal y el número de parámetros (pesos) de cada una de las capas:
_____________________________________________________________________________ | Layer (type) | Output Shape | Param | |===================================|=========================|=============| | conv2d (Conv2D) | (None, 148, 148, 32) | 896 | | max_pooling2d (MaxPooling2D) | (None, 74, 74, 32) | 0 | | conv2d_1 (Conv2D) | (None, 72, 72, 64) | 18496 | | max_pooling2d_1 (MaxPooling2D) | (None, 36, 36, 64) | 0 | | flatten (Flatten) | (None, 82944) | 0 | | dense (Dense) | (None, 512) | 42467840 | | dropout (Dropout) | (None, 512) | 0 | | dense_1 (Dense) | (None, 64) | 32832 | | dropout_1 (Dropout) | (None, 64) | 0 | | dense_2 (Dense) | (None, 8) | 520 | |============================================================================ Total params: 42,520,584 Trainable params: 42,520,584 Non-trainable params: 0 _____________________________________________________________________________
Entrenamos la red con la GPU
Tanto para el entrenamiento del modelo con GPU y CPU usaremos:
- epochs: 5 epochs
- steps_per_epoch: Cada epoch tendrá 1000 batches de 32 imágenes
- imágenes de entrenamiento: imágenes cargadas en la variable train_generator de la clase ImageDataGenerator
- imágenes de test: tras cada Epoch se validarán 320 imágenes (10 batches – validation_steps – de 32 imágenes) cargadas en la variable test_generator de la clase ImageDataGenerator
- workers: número de hilos (12) para el procesamiento en paralelo de la CPU. Para el caso del entrenamiento con GPU, será la CPU la encargada de pasar a la GPU los Batches con las imágenes de entrenamiento.
# CONSTANTES:
NUM_EPOCHS = 5 # Número de epochs
NUM_BATCHES_PER_EPOCH = 1000 # Número de Batches a realizar en cada EPOCH
# Ejecución con GPU
try:
with tensorflow.device('/gpu:0'):
print("### EJECUCIÓN CON GPU ###")
model.fit(train_generator,
epochs=NUM_EPOCHS,
steps_per_epoch=NUM_BATCHES_PER_EPOCH,
validation_data=test_generator,
validation_steps=10,
workers=12,
verbose=1)
except Exception as e:
print('WARNING: No es posible ejecutar con GPU: {}'.format(e))
Tras el entrenamiento del modelo con la GPU, podemos ver en la salida cómo tarda entre 38 y 45 segundos por Epochs. Recordar que en cada Epoch hay 1000 Batches de 32 imágenes; es decir que, durante el entrenamiento a la red se le pasan 32 imágenes (1000 veces) y tras clasificar las 32 imágenes, calcula el error cometido en la clasificación y ajusta los 42 Millones de parámetros de la red en función del error cometido. Por tanto en cada Epoch se ajustan 1000 veces los parámetros (o pesos) de la red neuronal.
### EJECUCIÓN CON GPU ### Epoch 1/5 1000/1000 [==============================] - 38s 35ms/step - loss: 1.0006 - categorical_accuracy: 0.6425 - val_loss: 0.8249 - val_categorical_accuracy: 0.6938 Epoch 2/5 1000/1000 [==============================] - 42s 42ms/step - loss: 0.6830 - categorical_accuracy: 0.7616 - val_loss: 0.8725 - val_categorical_accuracy: 0.7000 Epoch 3/5 1000/1000 [==============================] - 45s 44ms/step - loss: 0.6058 - categorical_accuracy: 0.7910 - val_loss: 0.8989 - val_categorical_accuracy: 0.6938 Epoch 4/5 1000/1000 [==============================] - 44s 43ms/step - loss: 0.5522 - categorical_accuracy: 0.8094 - val_loss: 0.8550 - val_categorical_accuracy: 0.7094 Epoch 5/5 1000/1000 [==============================] - 45s 45ms/step - loss: 0.5181 - categorical_accuracy: 0.8197 - val_loss: 0.7174 - val_categorical_accuracy: 0.7594
Entrenamos la red con la CPU
El código para el entrenamiento del modelo con la CPU es:
# Ejecución con CPU
try:
with tensorflow.device('/cpu:0'):
print("### EJECUCIÓN CON CPU ###")
model.fit(train_generator,
epochs=NUM_EPOCHS,
steps_per_epoch=NUM_BATCHES_PER_EPOCH,
validation_data=test_generator,
validation_steps=10,
workers=12,
verbose=1)
except Exception as e:
print('WARNING: No es posible ejecutar con CPU: {}'.format(e))
En el entrenamiento del modelo con la CPU podemos ver como tarda entre 408 y 424 segundos por epoch (7 minutos aprox).
### EJECUCIÓN CON CPU ### Epoch 1/5 1000/1000 [==============================] - 424s 423ms/step - loss: 0.4764 - categorical_accuracy: 0.8343 - val_loss: 0.6885 - val_categorical_accuracy: 0.7406 Epoch 2/5 1000/1000 [==============================] - 413s 413ms/step - loss: 0.4569 - categorical_accuracy: 0.8416 - val_loss: 0.9499 - val_categorical_accuracy: 0.6969 Epoch 3/5 1000/1000 [==============================] - 413s 412ms/step - loss: 0.4339 - categorical_accuracy: 0.8497 - val_loss: 0.6461 - val_categorical_accuracy: 0.7688 Epoch 4/5 1000/1000 [==============================] - 408s 408ms/step - loss: 0.4117 - categorical_accuracy: 0.8571 - val_loss: 0.6222 - val_categorical_accuracy: 0.7812 Epoch 5/5 1000/1000 [==============================] - 408s 407ms/step - loss: 0.3941 - categorical_accuracy: 0.8617 - val_loss: 0.7112 - val_categorical_accuracy: 0.7906
Conclusiones
En este experimento hemos demostrado cómo usando una GPU en vez de una CPU para entrenar un modelo de Deep Learning, el tiempo de entrenamiento es prácticamente 10 veces menor (9,6 veces), siendo el tiempo de entrenamiento con GPU de 43 segundos para 1 Epoch de 1000 Batches de 32 imágenes. Para el entrenamiento con CPU este tiempo (medio) fue de 413 segundos.
CODIGO COMPLETO Y EJECUCIÓN
# -*- coding: utf-8 -*-
__author__ = 'RicardoMoya'
import tensorflow.keras
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D
from tensorflow.keras.layers import MaxPooling2D
from tensorflow.keras.layers import Flatten
from tensorflow.keras.layers import Dense
from tensorflow.keras.layers import Dropout
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.python.client import device_lib
print('#### INFORMACIÓN ####')
print(' Versión de TensorFlow: {}'.format(tensorflow.__version__))
print(' GPU: {}'.format([x.physical_device_desc for x in device_lib.list_local_devices() if x.device_type == 'GPU']))
print(' Versión Cuda -> {}'.format(tensorflow.sysconfig.get_build_info()['cuda_version']))
print(' Versión Cudnn -> {}\n'.format(tensorflow.sysconfig.get_build_info()['cudnn_version']))
# CONSTANTES:
PIXELES = 150 # Pixeles del alto y ancho de la imagen p.e-> (150,150)
NUM_EPOCHS = 5 # Número de epochs
BATCH_SIZE = 32 # Número de imágenes por batch
NUM_BATCHES_PER_EPOCH = 1000 # Número de Batches a realizar en cada EPOCH
# Definimos como modificar de manera aleatoria las imágenes (pixeles) de entrenamiento
# https://www.tensorflow.org/api_docs/python/tf/keras/preprocessing/image/ImageDataGenerator
# rescale = normalizamos los pixeles
# shear_range = rango de modificación aleatorio
# zoom_range = rango de zoom aleatorio
# ratation_range = máximo ángulo de rotación aleatoria de la imagen
# horizontal_flip = Giro aleatorio de las imágenes
train_datagen = ImageDataGenerator(rescale=1. / 255,
shear_range=0.2,
zoom_range=0.2,
rotation_range=20,
horizontal_flip=True)
# Definimos como modificar las imágenes (pixeles) de test
# rescale = normalizamos los pixeles
test_datagen = ImageDataGenerator(rescale=1. / 255)
# Definimos como son nuestras imágenes de entrenamiento y test
# directory = ruta donde se encuentran las imágenes (una clase por carpeta)
# target_size = tamaño de las imágenes 150x150. Se redimensionan a ese tamaño
# batch_size = Nº de imágenes tras la que se calcularán los pesos de la res
# class_mode = tipo de clasificación: múltiple
train_generator = train_datagen.flow_from_directory(directory='./data/train',
target_size=(PIXELES, PIXELES),
batch_size=BATCH_SIZE,
class_mode='categorical')
test_generator = test_datagen.flow_from_directory(directory='./data/test',
target_size=(PIXELES, PIXELES),
batch_size=BATCH_SIZE,
class_mode='categorical')
num_classes = train_generator.num_classes
print("Nº de Imagenes para entrenamiento: {}".format(train_generator.n))
print("Nº de Imagenes para test: {}".format(test_generator.n))
print("Nº de Clases a Clasificar: {} Clases".format(num_classes))
# Definimos el modelo
# Imágenes de Entrada 150 pixeles Ancho, 150 Pixeles de Alto, 3 Canales
# Capa Convolucional: 32 filtros, kernel (3x3), Función Activación RELU
# MaxPooling: Reducción de (2,2)
# Capa Convolucional: 64 filtros, kernel (3x3), Función Activación RELU
# MaxPooling: Reducción de (2,2)
# Capa Flatten: Capa de entrada del clasificador. Pasa cada Pixel a neurona
# Capa Oculta 1: 512 Neurona, Función Activación RELU
# Capa Oculta 2: 64 Neurona, Función Activación RELU
# Capa Salida: 8 Neurona (8 Clases), Función Activación SOFTMAX
model = Sequential()
model.add(Conv2D(filters=32,
kernel_size=(3, 3),
input_shape=(PIXELES, PIXELES, 3),
activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(filters=64,
kernel_size=(3, 3),
activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten())
model.add(Dense(512, activation='relu'))
model.add(Dropout(0.2))
model.add(Dense(256, activation='relu'))
model.add(Dropout(0.2))
model.add(Dense(num_classes, activation='softmax'))
# Imprimimos por pantalla la arquitectura de la red definida
print(model.summary())
# Compilamos el modelo
# Función de perdida: categorical_crossentropy
# Optimizador: ADAM
# Métricas a monitorizar: Accuracy
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['categorical_accuracy'])
# Ajuste del Modelo
# epochs = numero de epochs
# steps_per_epoch = Número de batches por epoch
# validation_data = Imágenes de test (validación)
# validation_steps = Número de lotes (1 Lote = BACH_SIZE imágenes) de imágenes a validar por epoch
# workers = número de hilos para el procesamiento en paralelo de la CPU
# Ejecución con GPU
try:
with tensorflow.device('/gpu:0'):
print("### EJECUCIÓN CON GPU ###")
model.fit(train_generator,
epochs=NUM_EPOCHS,
steps_per_epoch=NUM_BATCHES_PER_EPOCH,
validation_data=test_generator,
validation_steps=10,
workers=12,
verbose=1)
except Exception as e:
print('WARNING: No es posible ejecutar con GPU: {}'.format(e))
# Ejecución con CPU
try:
with tensorflow.device('/cpu:0'):
print("### EJECUCIÓN CON CPU ###")
model.fit(train_generator,
epochs=NUM_EPOCHS,
steps_per_epoch=NUM_BATCHES_PER_EPOCH,
validation_data=test_generator,
validation_steps=10,
workers=12,
verbose=1)
except Exception as e:
print('WARNING: No es posible ejecutar con CPU: {}'.format(e))
#### INFORMACIÓN #### Versión de TensorFlow: 2.7.0 GPU: ['device: 0, name: NVIDIA GeForce RTX 2060, pci bus id: 0000:01:00.0, compute capability: 7.5'] Versión Cuda -> 64_112 Versión Cudnn -> 64_8 Found 18687 images belonging to 8 classes. Found 4463 images belonging to 8 classes. Nº de Imagenes para entrenamiento: 18687 Nº de Imagenes para test: 4463 Nº de Clases a Clasificar: 8 Clases Model: "sequential" _____________________________________________________________________________ | Layer (type) | Output Shape | Param # | |===================================|=========================|=============| | conv2d (Conv2D) | (None, 148, 148, 32) | 896 | | max_pooling2d (MaxPooling2D) | (None, 74, 74, 32) | 0 | | conv2d_1 (Conv2D) | (None, 72, 72, 64) | 18496 | | max_pooling2d_1 (MaxPooling2D) | (None, 36, 36, 64) | 0 | | flatten (Flatten) | (None, 82944) | 0 | | dense (Dense) | (None, 512) | 42467840 | | dropout (Dropout) | (None, 512) | 0 | | dense_1 (Dense) | (None, 64) | 32832 | | dropout_1 (Dropout) | (None, 64) | 0 | | dense_2 (Dense) | (None, 8) | 520 | |============================================================================ Total params: 42,520,584 Trainable params: 42,520,584 Non-trainable params: 0 _____________________________________________________________________________ None ### EJECUCIÓN CON GPU ### Epoch 1/5 1000/1000 [==============================] - 38s 35ms/step - loss: 1.0006 - categorical_accuracy: 0.6425 - val_loss: 0.8249 - val_categorical_accuracy: 0.6938 Epoch 2/5 1000/1000 [==============================] - 42s 42ms/step - loss: 0.6830 - categorical_accuracy: 0.7616 - val_loss: 0.8725 - val_categorical_accuracy: 0.7000 Epoch 3/5 1000/1000 [==============================] - 45s 44ms/step - loss: 0.6058 - categorical_accuracy: 0.7910 - val_loss: 0.8989 - val_categorical_accuracy: 0.6938 Epoch 4/5 1000/1000 [==============================] - 44s 43ms/step - loss: 0.5522 - categorical_accuracy: 0.8094 - val_loss: 0.8550 - val_categorical_accuracy: 0.7094 Epoch 5/5 1000/1000 [==============================] - 45s 45ms/step - loss: 0.5181 - categorical_accuracy: 0.8197 - val_loss: 0.7174 - val_categorical_accuracy: 0.7594 ### EJECUCIÓN CON CPU ### Epoch 1/5 1000/1000 [==============================] - 424s 423ms/step - loss: 0.4764 - categorical_accuracy: 0.8343 - val_loss: 0.6885 - val_categorical_accuracy: 0.7406 Epoch 2/5 1000/1000 [==============================] - 413s 413ms/step - loss: 0.4569 - categorical_accuracy: 0.8416 - val_loss: 0.9499 - val_categorical_accuracy: 0.6969 Epoch 3/5 1000/1000 [==============================] - 413s 412ms/step - loss: 0.4339 - categorical_accuracy: 0.8497 - val_loss: 0.6461 - val_categorical_accuracy: 0.7688 Epoch 4/5 1000/1000 [==============================] - 408s 408ms/step - loss: 0.4117 - categorical_accuracy: 0.8571 - val_loss: 0.6222 - val_categorical_accuracy: 0.7812 Epoch 5/5 1000/1000 [==============================] - 408s 407ms/step - loss: 0.3941 - categorical_accuracy: 0.8617 - val_loss: 0.7112 - val_categorical_accuracy: 0.7906

Que buen experimento y artículo.