Curso de MongoDB -Parte I- (Video) – «Introducción»
![]() MongoDB es un sistema de "Base de datos" multiplataforma orientada a documentos y de esquema libre. También suelen definir a MongoDB como un sistema de Base de Datos "NoSQL" o "No Relacional", aunque estas dos ultimas formas de definir a MongoDB (NoSQL y No Relacional) no me gustan mucho ya que MongoDB plantea una filosofía distinta (y no contraria como muchos se piensan) de almacenamiento de datos, respecto a las bases de datos relacionales.
MongoDB es un sistema de "Base de datos" multiplataforma orientada a documentos y de esquema libre. También suelen definir a MongoDB como un sistema de Base de Datos "NoSQL" o "No Relacional", aunque estas dos ultimas formas de definir a MongoDB (NoSQL y No Relacional) no me gustan mucho ya que MongoDB plantea una filosofía distinta (y no contraria como muchos se piensan) de almacenamiento de datos, respecto a las bases de datos relacionales.
Como la mayoría de las cosas que hacemos en esta web son cosas practicas, vamos a realizar este curso de MongoDB desde un punto de vista más práctico que teórico con el fin de que podáis trabajar lo antes posible con la base de datos de MongoDB. Como "pre-requisito" a la hora de leer y seguir este curso, seria conveniente que tuvieseis ciertas nociones y conocimientos de diseño software, POO (Programación Orientada a Objetos) y de bases de datos. Esto no es requisito indispensable, pero con estos conocimientos podréis seguir este curso muy bien.
En primer lugar vamos a ver que es lo que nos ofrece mongoDB (según los de MongoDB University) respecto de los demás sistemas de bases de datos que hay a día de hoy. Los de MongoDB University suelen empezar sus curso con una gráfica (Funcionalidad Vs Escalabilidad y Rendimiento) en el que sitúan los sistemas de bases de datos en función de esas características. En principio y sin saber nada de bases de datos, podréis pensar que si un sistema de base de datos tiene una gran escalabilidad y rendimiento, deberá tener una baja funcionalidad y viceversa. Esto es cierto con los sistemas de bases de datos que hay y es que podemos ver que los sistemas de bases de datosen los que se guardan pares "Clave-Valor" (los diccionarios) tienen alta escalabilidad y rendimiento pero poca funcionalidad, al contrario que los sistemas de gestión de bases de datos relacionales que tienen un bajo rendimiento y escalabilidad pero son muy funcionales. Como podréis suponer "MongoDB" va a ser "el galáctico" de los sistemas de bases de datos y va a presentar una gran funcionalidad a la par que una gran escalabilidad y rendimiento. De esta forma es como los de MongoDB "nos venden" su sistema de base de datos orientada a documentos, cogiendo lo mejor de cada uno de los sistemas de bases de datos existente, poniéndonos una gráfica tal que así:
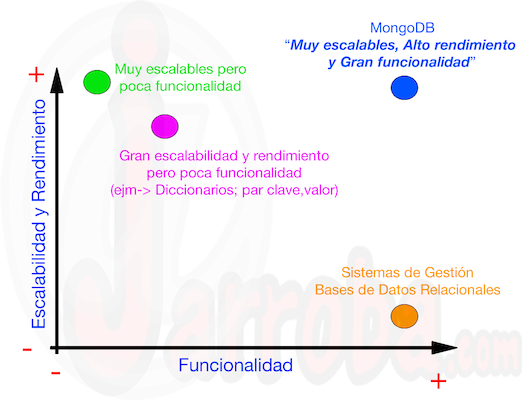
Vistas las características de MongoDB respecto de otros sistemas de bases de datos vamos a pasar a poner un ejemplo. Antes de comenzar con este ejemplo, queremos dejar muy claro que en ningún momento vamos a decir que MongoDB es mucho mejor que cualquier otro sistema de base de datos ya que se ve por muchos blogs o webs (los "fanáticos" de MongoDB) que dicen que MongoDB es lo mejor "del mundo mundial" y eso es una gran mentira ya que dependiendo de las características de cada sistema software se deberá elegir el mejor sistema de base de datos que sea adapte al proyecto en función de sus características; ya sea MongoDB o Bases de Datos Relacionales.
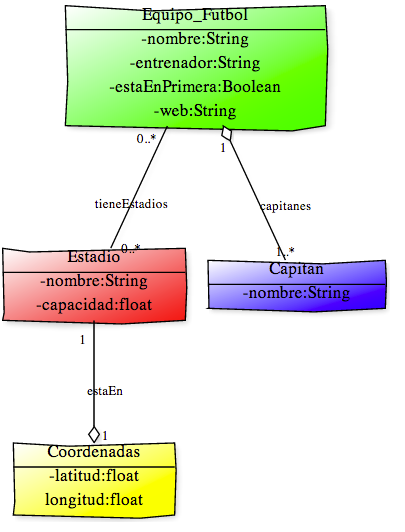
En este ejemplo vamos a ver como sería una aplicación o un sistema de gestión de datos de "Clubes de fútbol" hecha con MongoDB y hecha con Bases de Datos relacionales, para ver las diferencias. Vamos a suponer que nuestra aplicación quiere trabajar con ciertos datos de equipos de fútbol como son el nombre del club, cual es su entrenador, cual o cuales son los capitanes del equipo, si el equipo esta en primera división o no, la web del club y datos relacionados con el estadio de fútbol en el que juega el club; como es el nombre, la capacidad y sus coordenadas geográficas. A todos esto siempre hay algunas restricciones respecto de los datos, como por ejemplo que un club pueda no tener o tener más de un estadio de fútbol; que pueda ser que no tenga página web o que en el club hubiese varios capitanes. Sabiendo las características que va a tener nuestra aplicación, podemos plasmar en un diagrama de clases, las clases que deberá tener nuestro sistema (importante para entender esto, saber algo de diseño y POO):
Si estos datos que necesitamos para nuestra aplicación los tuviésemos que guardar en una base de datos relacional (una MySql por ejemplo), tendríamos las siguientes tablas para guardar estos datos que mostramos en el siguiente diagrama "Entidad/Relación":
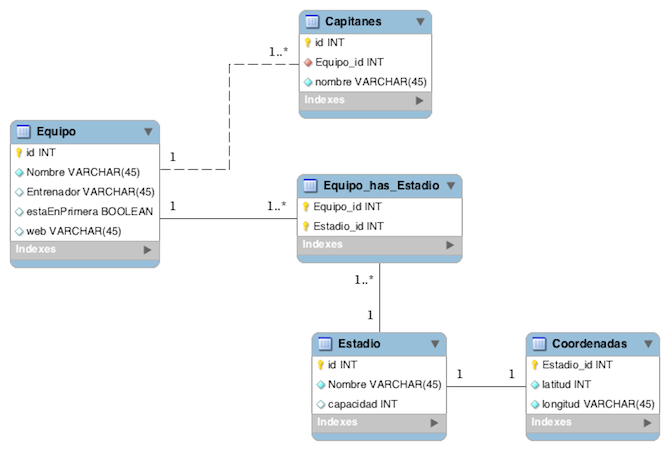
NOTA: No entro a valorar si esta diagrama "Entidad/Relación" se podía haber hecho mejor o si se podía haber normalizado a la "Forma Normal de Boyce-Codd", simplemente es un ejemplo ;).
Con estas tablas en la base de datos mostradas en el "Entidad/Relación" os pregunto; ¿Como haríais una consulta (o Query) para obtener todos los datos de un Club para mostrarlos por pantalla?. Bien es cierto que los expertos en SQL se estarán riendo de la pregunta que he planteado porque no les parecerá complicada, pero muchos otros (entre los que yo me incluyo) tardaríamos un rato en sacar esa consulta o Query para obtener los datos que nos permitiesen mostrar por pantalla algo parecido al siguiente "documento" (ejm del Atlético de Madrid):
"club" : "Club Atletico de Madrid" "entrenador" : "El Cholo" "capitan" : "Gabi" "estaEnPrimera" : SI "estadio" : "nombreEstadio" : "Vicente Calderon" "capacidad" : 54851 "coordenadas" -> "latitud" : 40.4015213, "longitud" : -3.7214151000000584 "webClub" : "http://www.clubatleticodemadrid.com/"
En realidad lo que he querido hacer con este ejemplo es mostraos un ejemplo "trampa" para que veáis como MongoDB guarda los datos; y es que como dije al principio de este post, MongoDB esta orientado a documentos y los datos los guarda en documentos en formato JSON; bueno en realidad en las máquinas se guardan documentos en formato BSON (Binary JSON) pero por el momento vamos a considerar que los documentos los guarda en formato JSON que es el formato que se ve cuando se hacen consultas. Por tanto si quisiésemos obtener todos los datos del Atlético de Madrid de la base de datos tendríamos que hacer la siguiente consulta (ya explicaremos más adelante como se hacen las consultas, esto es solo un ejemplo):
db.equiposFutbol.find({"club":"Club Atletico de Madrid"})
Dando como resultado de esta consulta un documento en formato JSON con el siguiente contenido:
{
"_id" : ObjectId("525ee424ecc5dd1123ccbd1f"),
"club" : "Club Atletico de Madrid",
"entrenador" : "El Cholo",
"capitan" : "Gabi",
"estaEnPrimera" : true,
"estadio" : {
"nombreEstadio" : "Vicente Calderon",
"capacidad" : 54851,
"coordenadas" : {
"latitud" : 40.4015213,
"longitud" : -3.7214151000000584
}
},
"webClub" : "http://www.clubatleticodemadrid.com/"
}
Evidentemente para cualquier tipo de aplicación, los documentos en formato JSON se deben de parsear para mostrarlos al usuario de una forma más amigable, aunque bien es cierto que un documento en este formato se entiende bastante bien; y también es cierto que en la mayoría de los lenguajes de programación (por no decir que en todos) existen librerías o APIs que parsean este tipo de documentos de forma muy rápida y cómoda para el programador; por tanto en un principio vemos que MongoDB sirve los datos tras una consulta en un formato muy "entendible" y ligero, como es el formato JSON.
Lo siguiente que vamos ha hacer, es mostrar otra de las "ventajas" que en mi opinión tiene MongoDB respecto de las bases de datos relacionales y antes de desvelar esta ventaja, voy a mostrar parte del contenido de una consulta que haré a la base de datos que es la siguiente:
{
"_id" : ObjectId("525ee1d4ecc5dd1123ccbd1d"),
"capitan" : [
"Puyol",
"Xavi"
],
"club" : "FC Barcelona",
"entrenador" : "Tata Martino",
"estaEnPrimera" : true,
"estadio" : {
"nombreEstadio" : "Camp Nou",
"capacidad" : 99354,
"coordenadas" : {
"latitud" : 41.3809029,
"longitud" : 2.1227777999999944
}
},
"webClub" : "http://www.fcbarcelona.es/"
}
{
"_id" : ObjectId("525ee424ecc5dd1123ccbd1f"),
"club" : "Club Atletico de Madrid",
"entrenador" : "El Cholo",
"capitan" : "Gabi",
"estaEnPrimera" : true,
"estadio" : {
"nombreEstadio" : "Vicente Calderon",
"capacidad" : 54851,
"coordenadas" : {
"latitud" : 40.4015213,
"longitud" : -3.7214151000000584
}
},
"webClub" : "http://www.clubatleticodemadrid.com/"
}
{
"_id" : ObjectId("525ee4caecc5dd1123ccbd20"),
"club" : "Sporting de Gijon",
"estaEnPrimera" : false,
"estadio" : {
"nombreEstadio" : "El Molinon",
"capacidad" : 30000
},
"webClub" : "http://www.realsporting.com/"
}
Después ver el documento que me da MongoDB tras realizar una consulta; os pregunto lo siguiente: ¿Veis algo raro en la estructura del documento?…..Pues si le dedicáis un minuto, veréis que los clubes del Atlético de Madrid y el Barça tiene los mismos atributos en su documento (aunque no en el mismo orden), mientras que al documento del Sporting de Gijón le faltan atributos. Esto en realidad no es que sea una ventaja, pero si que es cierto que si no se dispone de un dato, no hace falta en MongoDB poner ese atributo a "null"; simplemente ese atributo no existe y no se pone. Por otro lado también se le pueden añadir atributos nuevos a los documentos sin necesidad de modificar absolutamente nada la estructura de la base de datos, al contrario que en las bases de datos relacionales en las que habría que modificar las estructuras de las tablas o añadir nuevas tablas. En mi opinión esto último si que es una ventaja a la hora del desarrollo porque cuantas veces ha pasado que tras 2 o 3 meses de desarrollo de un proyecto te llega el cliente y te dice que añadas un nuevo requisito como por ejemplo: "Ahora hay que guardar los datos personales de los jugadores de fútbol de cada club" y entonces habría que añadir una nueva tabla y añadir nuevas relaciones entre ellas, mientras que en MongoDB solo habría que añadir una nueva colección o nuevos atributos al documento de MongoDB.
Por último y para terminar con esta primera entrada; se pretende explicar porque al principio dije eso de que MongoDB es muy escalable y muy funcional; pues bien, es cierto que MongoDB es escalable "hasta el infinito" o hasta ocupar todo el espacio de almacenamiento que tiene las máquinas en las que se almacena la base de datos ya que MongoDB guarda los datos en formato BSON y los muestra en formato JSON. Como digo MongoDB es escalable hasta la capacidad máxima que tengan nuestras máquinas, ya sea 1Gb o 100000GB. Por otro lado MongoDB es muy funcional. No vamos a explicar en este curso como esta hecho MongoDB "por debajo" pero decir brevemente que tiene una estructura de clusters que hacen que MongoDB sea muy funcional y tenga un muy buen rendimiento; simplemente en este curso vamos a mostrar como trabajar con los datos almacenados en la Base de Datos de mongoDB.
En resumen; hemos querido explicar en esta primera entrada del curso la forma en que MongoDB almacena los datos (en formato JSON y no en formato BSON) y algunas de sus ventajas. Hemos querido hacer una comparación con un ejemplo que podía ser real de como se almacenarían los datos en una base de datos relacional y en MongoDB; viendo sus ventajas. Es cierto que el ejemplo que hemos visto lo hemos puesto para "vender" las ventajas que tiene MongoDB pero bien es cierto que si hubiésemos planteado una Aplicación con un sistema muy distinto y que hubiese muchas relaciones entre sus entidades; hubiese sido mejor elegir bases de datos relacionales que MongoDB. Como se dijo en un principio no es el objetivo del curso menospreciar al resto de sistemas de bases de datos; sino el de mostrar el funcionamiento de MongoDB.
A continuación os dejamos un video explicativo de todo lo que se ha contado en esta entrada:
