Instalar Apache Kafka
Vamos a instalar Apache Kafka paso a paso. Se instala y se usa prácticamente igual en cualquier sistema operativo, aunque aquí lo haré en Linux con la distribución Ubuntu (para Windows sugiero usar la WSL, aunque también se puede instalar sobre el sistema operativo directamente).
Índice
- Apache Kafka: Teoría.
- Instalar Apache Kafka: Instalación y consola.
- Consumidores y Productores de Apache Kafka con Java y Python: Ejemplos de código.
- Clúster Apache Kafka tolerante a fallos y alta disponibilidad: Configuración de brókeres y sistema distribuido.
Nota sobre Kafka en Docker: Alternativamente a la instalación descrita en este artículo, puedes usar el «Docker Compose» con Kafka que he creado y dejado en https://github.com/Invarato/docker/tree/main/kafka (Solo te lo recomiendo si tienes experiencia en Docker Compose). De cualquier manera, te recomiendo leerte este artículo, pues tiene teoría muy necesaria.
Elegir dónde instalar Apache Kafka
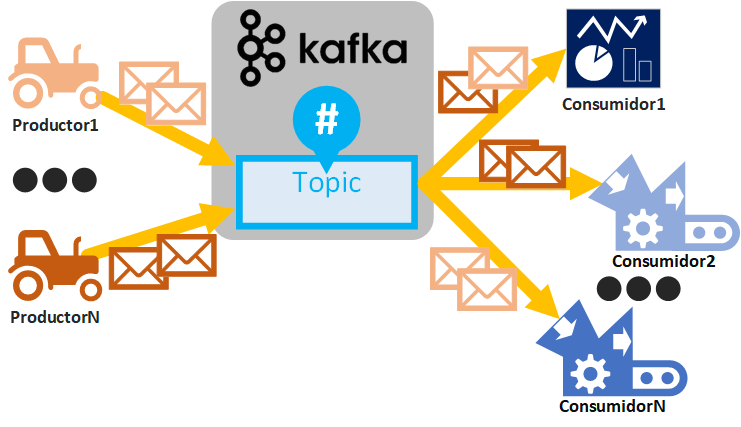
Antes de continuar, tendremos que tener claro dónde instalaremos Apache Kafka, pues será donde se tengan que conectar nuestros Consumidores y Productores.
Recuerda que los tres puntos clave que se van a interconectar entre ellos en Kafka son: Consumidor, Productor y servidor Apache Kafka (y a otros servidores de Apache Kafka si está distribuido).
Luego podremos tener diferentes combinaciones (que aprenderás a utilizar leyendo más adelante) que podrían ser:
- Todo local (solo para aprender): Servidor Apache Kafka, Consumidores y Productores en local. En local significa tanto todo en tu ordenador, como todo en una misma máquina remota. Como está todo en loca no necesitarás abrir puertos al exterior.
- Parte en local (para aprender y para producción): Consumidores y productores en local, pero servidor Apache Kafka en remoto. Si en tu ordenador están los Consumidores y Productores, por lado, en remoto Apache Kafka, tendrás un aprendizaje completo de cómo se trabaja en una empresa.
- Todo en remoto (entorno bastante real de producción): Servidor Apache Kafka en una máquina en remoto, Consumidores en otra máquina en remoto y Productores en una tercera máquina remota. Esta configuración es la más compleja y la más utilizada en empresas, pues se pueden configurar Apache Kafka distribuido en múltiples máquinas y que muchas máquinas ataquen como Productores y Consumidores (es una configuración para el tratamiento de datos de Big Data real que te voy a enseñar a configurar más adelante y te lo dejaré funcionando para que puedas jugar con ello). Por cierto, que esté todo en remoto no significa que no podamos lanzar Productores o Consumidores en local contra dichos Kafkas remotos.
Para que quede clara cada una de las partes, yo instalaré Kafka en remoto y cloud para simular lo más que pueda un entorno empresarial real y dejaré el local para los Consumidores y Productores. Si estas aprendiendo y ya tienes cierta experiencia programando, puedes seguir este artículo tal cual (como te explicaré tendremos cierto dinero gratis para probar en cloud, con lo que trabajaremos como se trabaja en una empresa de verdad, pero deberás de ser consciente de que si se agota el dinero te empezarán a cobrar, aunque para seguir este artículo da más que de sobra) o podrás hacerlo todo en local (simplemente cambiando dónde apuntan las IPs).
Trabajar de verdad sobre un entorno real remoto y cloud
Para simular un entorno real de empresa (que es lo más próximo a un entorno real que te puedo dejar, pues es un entorno real) voy a utilizar la infraestructura de https://clouding.io/ (montar una máquina es muy sencillo, en tan solo unos pocos clics, además, explico cómo montar una máquina remota en el artículo sobre “Cómo funcionan los Servidores y Servicios de Hosting”). Montar una máquina remota es un servicio de pago y que hay que añadir la tarjeta de crédito con la que se te cobra 1 euro para comprobar tu identidad, que se devuelve siempre, sin excepciones y una vez hecho esto, en https://clouding.io/ te regalan 5€ de prueba y con ese dinero tenemos más que de sobra para practicar con Apache Kafka. Estas máquinas las podremos eliminar completamente cuando no las usemos para que no se nos cobre más, salvo que realmente queramos montarnos una infraestructura real y seguir usándolas, aquí cada cual decida. Si decidimos empezar a usarlas, podemos hacer las recargas de saldo que queramos con un importe mínimo de 2€.
Para las pruebas crearé de primeras una máquina “Ubuntu” con 2GB, con 1 vCore y 20GB (en este punto aviso que cuanto más le pongamos más se nos cobrará).

Tarda unos minutos en crearse la máquina, pero cuando esté creada tendremos la “IP pública” de nuestra máquina remota y el acceso por SSH a la misma (Lo explico paso a paso en el artículo “Cómo funcionan los Servidores y Servicios de Hosting”).
A esta máquina remota me conectaré por SSH e instalaré Apache Kafka.
Nota sobre la máquina remota: Vuelvo a avisar que cuando no se utilice la máquina remota hay que ELIMINARLA para que no nos cobren (si solo se “apaga” la máquina, los recursos siguen reservados para nosotros y por esa exclusividad tendremos que pagar lo que hayamos configurado por hora, aunque no se use). Otra opción es ARCHIVAR la máquina, cuando está archivada sólo pagas el disco SDD NVMe, no la RAM ni la CPU. Si quieres utilizar el servicio para realmente tener un entorno de producción y pagar por su servicio, pues adelante, te lo recomiendo, ya que es un buen servicio.
Instalar Apache Kafka
Apache Kafka lo podemos descargar desde https://kafka.apache.org/downloads (o si estamos en la página principal, pulsando el botón “Download Kafka”).
Nota sobre Kafka en Docker: Si no quieres instalar Kafka puedes usar https://github.com/Invarato/docker/tree/main/kafka
En la página de descarga nos aparecerán varias versiones que tendremos que entender para evitar incompatibilidades:
- Versión de Kafka: aparece en negrita grande. En mi caso Kafka descargaré la versión “3.1.0” de Kafka.
- Versión de Scala compatible: Kafka está construido sobre Scala (y Scala requiere Java), pero esta versión nos da más igual, ya que es la que viene dentro del paquete (junto con Kafka). En mi caso escogeré la versión “2.13”.
- Versión de Java compatible: Como Scala requiere Java, pues también necesitaremos Java, abajo aparecerá la versión máxima que soporta (quizás tengas que hacer scroll hacia abajo); es importante no sobrepasar la versión de Java sobre la que se ejecutará nuestra versión de Kafka (si la sobrepasamos no funcionará).
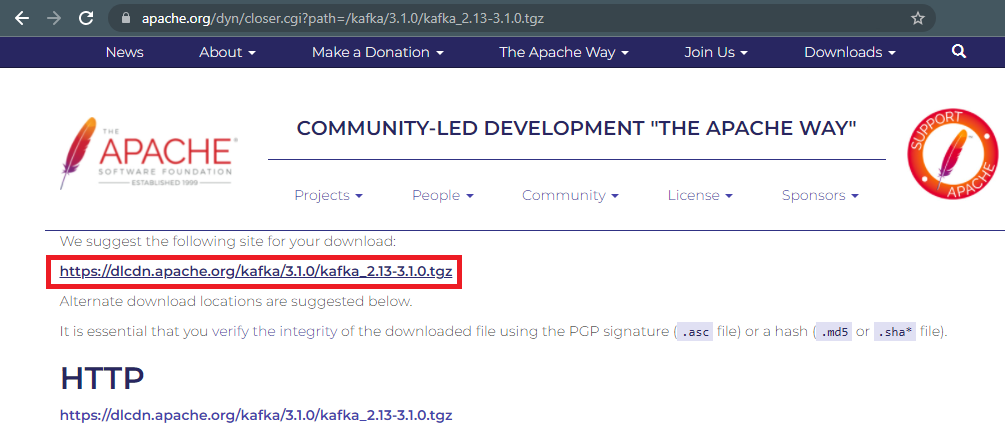
En esta página elegiremos la versión del binario que queremos instalar, en mi caso voy a escoger la versión “kafka_2.13-3.1.0.tgz”:

Y nos llevará a otra ventana con el enlace de la descarga, que en mi caso es “https://dlcdn.apache.org/kafka/3.1.0/kafka_2.13-3.1.0.tgz”, el cual podremos descargar directamente o copiar (si queremos descargarlo mediante wget):
Descargar y descomprimir en Shell
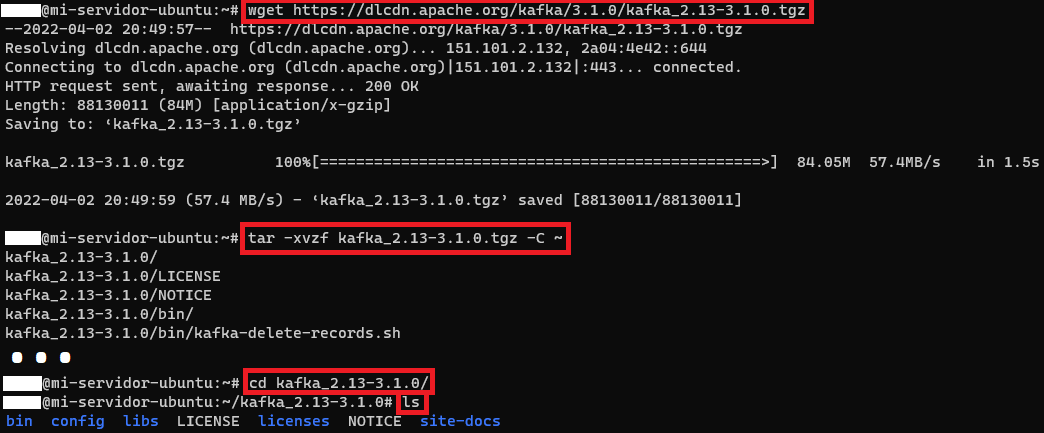
En la Shell (terminal) de Linux podremos descargarlo mediante el comando “wget” en el directorio actual:
wget https://dlcdn.apache.org/kafka/3.1.0/kafka_2.13-3.1.0.tgzLo voy a descomprimir en mi usuario (virgulilla “~” o “/home/miUsuario”) directamente:
tar -xvzf kafka_2.13-3.1.0.tgz -C ~Lo que me creará un directorio con el mismo nombre que el comprimido, pero sin extensión: “kafka_2.13-3.1.0”. Si entramos dentro (“cd kafka_2.13-3.1.0”) observaremos (“ls”) que tendremos los ficheros de Kafka listos. A continuación, te muestro una captura con todos los pasos:
Al terminar podremos eliminar el comprimido para liberar espacio:
rm kafka_2.13-3.1.0.tgzValidar e instalar el JDK de Java
Podemos probar si tenemos instalado Java con:
java -versionSi no está instalado lo podremos instalar con (voy a instalar la versión 11 del JDK de Java, la versión headless que no incluye interfaz gráfica, para que ocupe menos espacio de disco):
sudo apt install openjdk-11-jre-headlessNota sobre la instalación: te pedirá aceptar la descarga, por lo que pulsaremos “y” y la tecla “Enter”.
Cuando esté instalado correctamente con “java -version” podremos ver la información de Java:

Añadir al PATH
Si queremos que estén siempre disponible Kafka desde cualquier sitio de la sesión actual de la Shell, podemos añadir la variable KAFKA_HOME con el directorio con la instalación de Kafka y en el PATH el directorio “bin” con el mismo, por ejemplo, con:
export KAFKA_HOME=~/kafka_2.13-3.1.0
export PATH=$PATH:${KAFKA_HOME}/binSi no está instSi queremos que perdure en todas las sesiones de Shell que abramos en un futuro, podemos añadir con VIM (o el editor que prefieras) los “exports” anteriores al final del fichero “.bashrc” (este fichero está oculto en el “home” del usuario o “~”; se puede ver con “ls -a”), o bien puedes ejecutar el siguiente comando para añadirlo directamente:
echo "export KAFKA_HOME=~/kafka_2.13-3.1.0" >> ~/.bashrc
echo "export PATH=\$PATH:\${KAFKA_HOME}/bin " >> ~/.bashrcSi hasta aquí todo ha ido bien, la prueba que suele hacer todo el mundo es ejecutar “kafka-topics.sh” (desde cualquier lugar si has configurado bien las variables de entorno o desde la instalación de Kafka dentro de la carpeta “bin”) y si devuelve “cosas” (devuelve la ayuda), es que hasta aquí está todo bien instalado:
kafka-topics.sh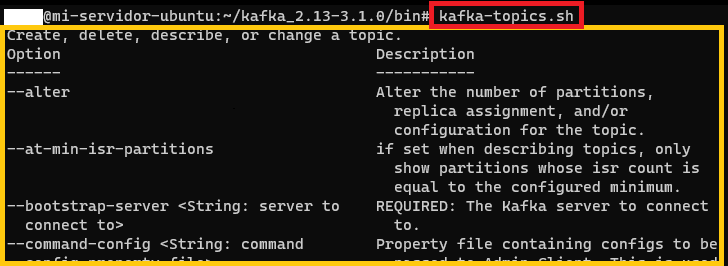
Script de instalación rápida de Apache Kafka
Todos estos pasos anteriores se pueden meter en un script para que sea más rápido instalar Kafka y más cuando hay que distribuirlo en múltiples servidores en cloud (pues hay que realizar la instalación en cada uno). A continuación, te regalo un script para instalar todo lo anterior en cada servidor (tienes que cambiar el valor de la variable de “version” de Kafka y “package” con el nombre del paquete de Kafka, por las que quieras instalar). Crea un fichero llamado por ejemplo “miEjecutable.sh” y pega el siguiente código dentro (puedes utilizar VIM):
#!/bin/sh
version=3.1.0
package=kafka_2.13-3.1.0
java_pkg=openjdk-11-jre-headless
echo "https://dlcdn.apache.org/kafka/$version/$package.tgz"
wget https://dlcdn.apache.org/kafka/$version/$package.tgz
tar -xvzf $package.tgz -C $(pwd)
rm $package.tgz
if type -p java; then
echo "Java encontrado en: $PATH"
elif [[ -n "$JAVA_HOME" ]] && [[ -x "$JAVA_HOME/bin/java" ]]; then
echo "Java encontrado en: $JAVA_HOME"
else
echo "Java no encontrado, instalando: $java_pkg"
sudo apt --yes --force-yes install $java_pkg
fi
export KAFKA_HOME=$(pwd)/$package
export PATH=$PATH:${KAFKA_HOME}/bin
echo "export KAFKA_HOME=$(pwd)/$package" >> ~/.bashrc
echo "export PATH=\$PATH:\${KAFKA_HOME}/bin" >> ~/.bashrc
echo "export KAFKA_HOME=$(pwd)/$package"
echo "export PATH=$PATH:${KAFKA_HOME}/bin"
echo "Hecho"
Y lo puedes ejecutar con:
source miEjecutable.shDespués de que termine de ejecutar (te he puesto un “Hecho” al final), puedes borrar este fichero.
Iniciar servidor de Zookeeper
Zookeeper es importante porque es quien gestionará los brókeres de Kafka.
Iniciaremos el servidor de Zookeeper y le pasaremos el fichero de configuración “zookeeper.properties” (que también está en la carpeta “config” de Kafka); podremos editar (por ejemplo, con “vim”) este fichero de configuración para configurar las diferente opciones de Zookeeper si lo necesitamos (por ejemplo, si queremos podremos cambiar el puerto al que escucha Zookeeper si cambiamos el valor de la variable “clientPort”, que por defecto su valor es “2181” y recomiendo dejar como está, sino habrá que cambiarlo también en otros ficheros de configuración; o “dataDir” para cambiar la ruta en la que Zookeeper guarda los temporales; podemos dejar los valores por defecto sin tocarlos). Después lanzar el comando de Zookeeper tarda un poco en iniciarse completamente (es importante esperar a que Zookeeper termine de iniciarse completamente):
zookeeper-server-start.sh ~/kafka_2.13-3.1.0/config/zookeeper.properties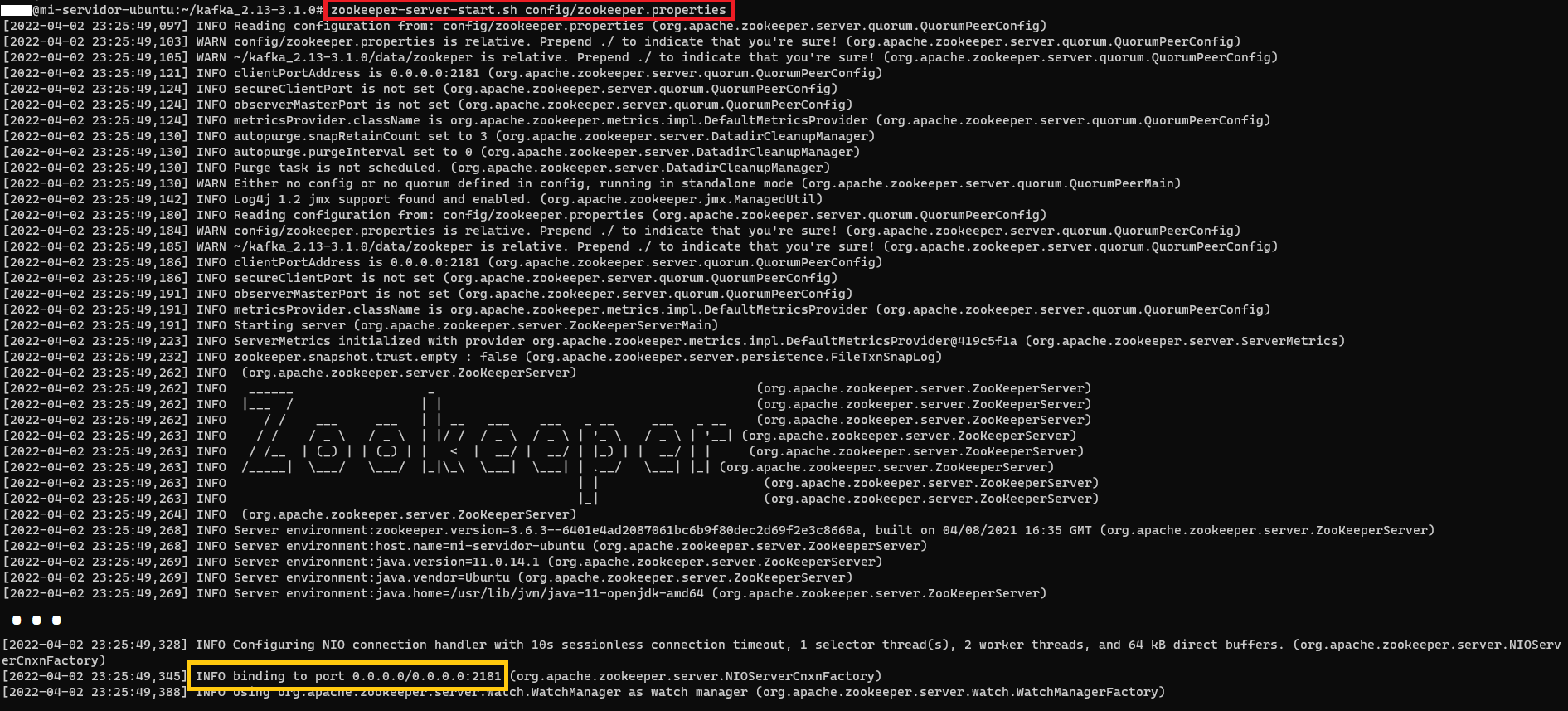
Al iniciarse completamente veremos que se quedará escuchando el puerto 2181 (o el que configuramos en “clientPort” del fichero “zookeeper.properties”).
Comprobar que Zookeeper está escuchando en el puerto correcto
Si no cambiamos la configuración, el puerto por defecto al que escucha Zookeeper es el “2181”. Con el siguiente comando podemos comprobarlo:
ss -tulwn
Hago un resumen rápido el “Administrador del sistema” (ss; más información en https://man7.org/linux/man-pages/man8/ss.8.html):
- -t: muestras las conexiones TCP
- -u: muestra las conexiones UDP
- -l: filtrar por los sockets que están escuchando
- -w: muestra sockets RAW
- -n: no resuelve nombres de servicio
Antes de iniciar un bróker de Kafka, debemos asegurarnos de que Zookeeper ha terminado de iniciarse (tarda menos de un minuto, esperamos o lo aseguramos viendo los logs de salida que muestra Zookeeper hasta que aparece el “binding” que mostré antes en la imagen).
Iniciar un servidor bróker de Kafka
Abrimos una nueva Shell (otra consola), pues la anterior ya está pillada con la salida de Zookeeper y la queremos ver (en un futuro, cuando aprendas, podrás mandarlo a segundo plano y hacer todo en la misma terminal).
y entonces podemos iniciar el servidor de Kafka con “kafka-server-start.sh” y le pasaremos la configuración “server.properties” (que también está en la carpeta “config” de Kafka; al igual que el fichero de propiedades de Zookeeper anterior, podremos editar sus variables, como por ejemplo la ruta donde guarda el bróker de Kafka los logs, que sería la variable “log.dirs”, importante será el identificador del bróker en “broker.id” y la variable “listeners” si tenemos más de un bróker):
kafka-server-start.sh ~/kafka_2.13-3.1.0/config/server.properties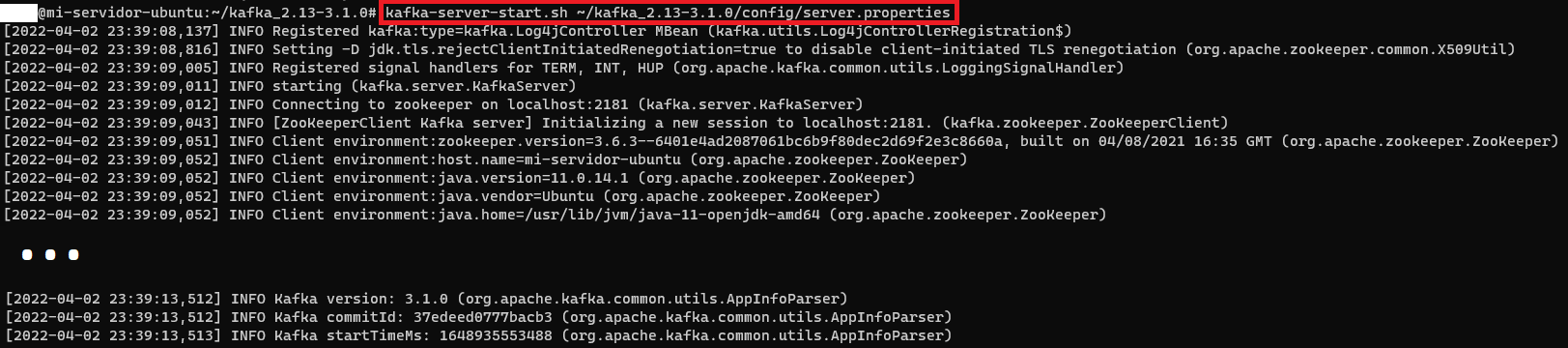
Error de espacio al iniciar el servidor de kafka
Puede salir un error semejante:
OpenJDK 64-Bit Server VM warning: INFO: os::commit_memory(0x00000000c0000000, 1073741824, 0) failed; error='Not enough space' (errno=12)Quiere decir que la máquina virtual de Java necesita al menos un 1GiB (=1073741824 bytes), por lo que para solucionarlo añadiremos las siguientes variables para:
export KAFKA_HEAP_OPTS="-Xmx1G -Xms1G"
export KAFKA_JVM_PERFORMANCE_OPTS="-Xmx256M -Xms128M"
Nota sobre estos valores: esta configuración está bien para desarrollo o realizar pruebas, para producción puede ser necesario ampliar bastante más la memoria.
Este bróker que hemos levantado, podremos llamarle al puerto 9092 (que es el puerto por defecto).
Nota para varios brókeres por Zookeeper: Con un solo bróker no hace falta cambiar nada del fichero “server.properties”, pero si tenemos más de un bróker gestionado por el mismo Zookeeper, será necesario crear un fichero “server.properties” para cada bróker y cada uno de estos ficheros deberá tener un identificador único (en “broker.id”) y un puerto único (en “listeners”). Veremos esto con ejemplos más adelante.
Puertos requeridos abiertos para conectarnos a un servidor remoto con Apache Kafka
Para comunicarnos con nuestra máquina remota (por ejemplo, desde nuestro ordenador) es necesario que tengamos abiertos los puertos “9092” (para el bróker de Kafka) y “2181” (para el servidor de Zookeeper).
Por ejemplo, en el portal clouding, en https://portal.clouding.io/, podremos ir a “Mis Firewalls”, seleccionar el perfil que queramos (yo utilizaré el de “default”, aunque podremos clonarlo si queremos), y en el “+” añadiremos los puertos:
- Puerto del bróker de Kafka: Puerto “9092”, con la IP de Origen la del ordenador con el que nos queramos conectar (o “0.0.0.0/0” para permitir todas las IPs, aunque esto es inseguro ya que cualquier otra persona podría conectarse a este puerto; yo pongo el puerto “0.0.0.0/0” porque cuando estés leyendo este artículo esa máquina ya no existirá, así que muchísimo cuidado con esto y más si es para producción 😉 ), con el protocolo “TCP” y se sugiere poner el nombre “Permitir Kafka” (o en inglés “Allow Kafka”). En caso de tener más brókeres de Kafka, necesitaremos abrir un puerto por cada bróker (según tengamos configurado en cada fichero “server.properties”; veremos un ejemplo más adelante)
- Puerto de Zookeeper: Puerto “2181”, con la IP de Origen la del ordenador con el que nos queramos conectar (o “0.0.0.0/0” para permitir todas las IPs), con el protocolo “TCP” y se sugiere poner el nombre “Permitir Zookper”.
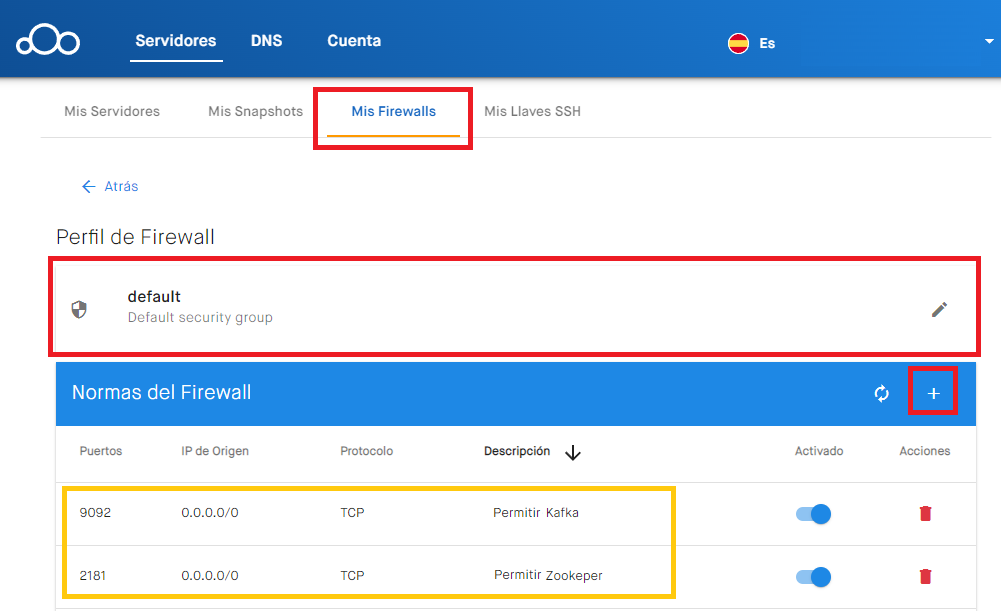
Con esto tendremos abiertos los puertos.
Comandos de Apache Kafka
Los siguientes ejemplos los voy a poner siempre llamando al “localhost”, es decir, lanzaré los comandos en la misma máquina donde tengamos instalado Apache Kafka (pues requieren de una instalación de Apache Kafka). Si queremos, en un futuro podremos tener varias instalaciones de Apache Kafka y lanzar un comando que afecte a otra remota (para esto necesitamos abrir los puertos, que explico más adelante).
Desde la consola, para crear (–create) un nuevo topic llamado “miNuevoTopic” (–topic miNuevoTopic), con un factor de replicación de 1 (–replication-factor 1), con 2 particiones (–partitions 2) y en la cola Kafka del mismo servidor (bootstrap-server localhost:9092):
kafka-topics.sh --create --topic miNuevoTopic --replication-factor 1 --partitions 2 --bootstrap-server localhost:9092
Nota sobre la ruta de las imágenes: si has exportado como se ha indicado anteriormente, no hará falta estar en la carpeta “bin” de Kafka para ejecutar “kafka-topic.sh”, en las imágenes simplemente lo muestro como recordatorio.
Truco para crear topics rápidamente: en vez de usar “–create”, podremos insertar datos en un topic que no existe (con un productor, como veremos más adelante) y dicho topic que no existe se creará automáticamente (esto solo funciona si la configuración lo permite).
Para eliminar un topic de Kafka:
kafka-topics.sh --delete --topic miNuevoTopic --bootstrap-server localhost:9092Nota si queremos borrar todos los mensajes de un topic (vaciar un topic): Lo más sencillo es eliminar con “–delete” el topic entero y volverlo a crear con “–create”. También existe el truco de bajar al mínimo el tiempo de retención y volver a recuperarlo (Por ejemplo, con: “kafka-topics.sh –alter –topic miNuevoTopic –bootstrap-server localhost:9092 –config retention.ms=1000”, esperar a que se vacíe y luego tendrás que volver a poner el tiempo de retención anterior con otro “–alter”).
Para listar (–list) los topics creados:
kafka-topics.sh --list --bootstrap-server localhost:9092
Para ver los detalles (uso de sus particiones, réplicas, etc.) de un topic:
kafka-topics.sh --describe --topic miNuevoTopic --bootstrap-server localhost:9092
Para producir (escribir) mensajes en un topic (con “kafka-console-producer.sh”), se quedará escuchando por cada línea que insertemos (para enviar un mensaje: escribir lo que queramos y pulsar la tecla [Intro]):
kafka-console-producer.sh --topic miNuevoTopic --bootstrap-server localhost:9092Nota para finalizar: Si hemos terminado de insertar mensajes, podemos terminar pulsando [Ctrl]+[C].

Para consumir (leer) los mensajes de un topic (con “kafka-console-consumer.sh”), desde el principio (–from-beginning):
kafka-console-consumer.sh --topic miNuevoTopic --from-beginning --bootstrap-server localhost:9092Nota sobre el anterior comando: se quedará esperando eternamente por nuevos mensajes entrantes hasta que terminemos el proceso (con [Ctrl]+[C]). Si queremos que solo muestre unos mensajes máximos y termine, podremos utilizar “–max-messages”, por ejemplo, para mostrar 10 mensajes: –max-messages 10

Nota de tiempo real del Consumidor y Productor: si tenemos dos terminales, una terminal con el Productor y otra terminal con el Consumidor, podremos enviar datos por la terminal del productor y verlos en tiempo real por la terminal del consumidor.
Idea sobre los requisitos de Hardware
Para desarrollo nos valdrá con lo que tengamos, quizás tener al menos 20GB de disco duro para las instalaciones de Java, Kafka y que no nos quedemos sin memoria cuando utilicemos Kafka.
Para producción tampoco hay una cifra exacta, idealmente es que cuanto más mejor, aunque te doy unas cifras para hacernos una idea:
- Memoria RAM: Para producción se recomienda al menos 32 GB de RAM por máquina, pues los consumidores leen de memoria RAM, si no hay espacio Kafka guardará en disco duro y tener que leer de disco será muy lento. Kafka usa JVM heap (tener al menos 1GB para replicar las particiones entre brókeres y para comprimir logs) y el paginado en caché del sistema operativo (consumidores siempre leen de memoria)
- Disco duro: 500GB o más. Usar múltiples discos duros para maximizar el rendimiento y un buen balanceo de los datos de lectura y escritura (configurando múltiples directorios de datos o mediante RAID 1 o 10).
- Procesador: 4 núcleos o más. Mejor más núcleos que más velocidad de reloj del procesador.
- Red: mínimo de 1 GbE-10 GbE y baja latencia.
- Sistema de ficheros de alto rendimiento: XFS o Ext4
