Instalar Apache Spark en cualquier sistema operativo y aprender a programarlo con Python, Scala o Java
Si queremos trabajar con datos “Big Data” (tantos datos que una única máquina no es capaz de procesarlos al menos en un tiempo prudencial y menos en un solo hilo) necesitamos que los datos se procesen: en paralelo, descentralizados, auto-balanceados y con corrección de errores; entonces una de las opciones más potentes que existe es Apache Spark (que simplifica el trabajo sobre Apache Hadoop, pues está basado en éste).
Spark se puede instalar en cualquier sistema operativo (Windows, Linux, Mac), aunque para hacerlo de una manera más homogénea vamos a centrarnos en la instalación en Linux mediante la consola (que es muy parecido para Mac) y para Windows es igual, pero utilizaremos WSL2 (por lo que utilizaremos Linux); es más, para este artículo se ha probado con WSL2 con Ubuntu sobre Windows.
Nota sobre instalar WSL2 en Windows: es muy rápido de instalar, tan solo es activar una característica de Windows “Subsistema de Windows para Linux” e instalar del Market un sistema operativo como Ubuntu; tienes los pasos en https://docs.microsoft.com/es-es/windows/wsl/install-win10 .
En este artículo lo voy a explicar paso a paso y desde cero, para que sea sencillo llegar hasta realizar un pequeño programa funcional con Spark tanto con Python, Scala o Java, tanto por consola como trabajando con Jupyter (este solo con Python y Scala). La instalación realmente no se tarda más de unos minutos, pese a que aquí explique mucho, y una vez instalado ya solo quedará programar.
Descargar Spark
Spark se puede descargar desde https://spark.apache.org/downloads.html
NO vamos a descargar directamente Spark, sino que vamos a seleccionar la versión de Spark que deseamos descargar (para este ejemplo voy a seleccionar la versión “3.1.1 (Mar 02 2021)”) y el tipo de paquete (en este ejemplo selecciono “Pre-built for Apache Hadoop 3.2 and later”). Y clicamos en descargar, que es el tercer punto, donde pone “Download Spark” (en mi caso en el enlace que se llama “spark-3.1.1-bin-hadoop3.2.tgz”).
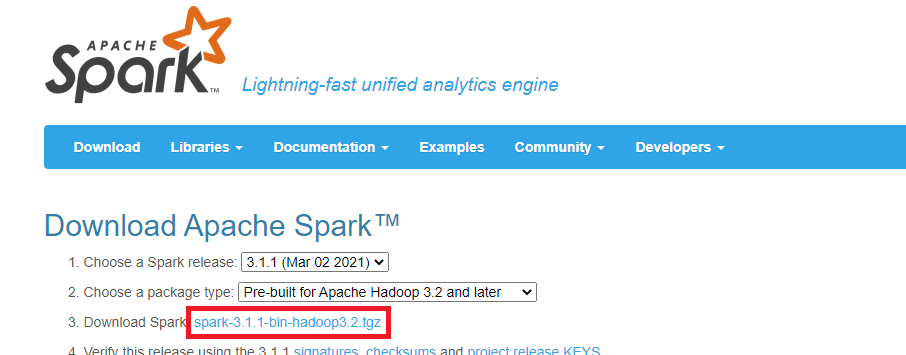
Esto es importante, pues Spark no se descarga directamente, sino que nos llevará a una web (como la siguiente imagen), de la que nos interesa copiar el enlace real de descarga (En mi caso es “https://ftp.cixug.es/apache/spark/spark-3.1.1/spark-3.1.1-bin-hadoop3.2.tgz”).
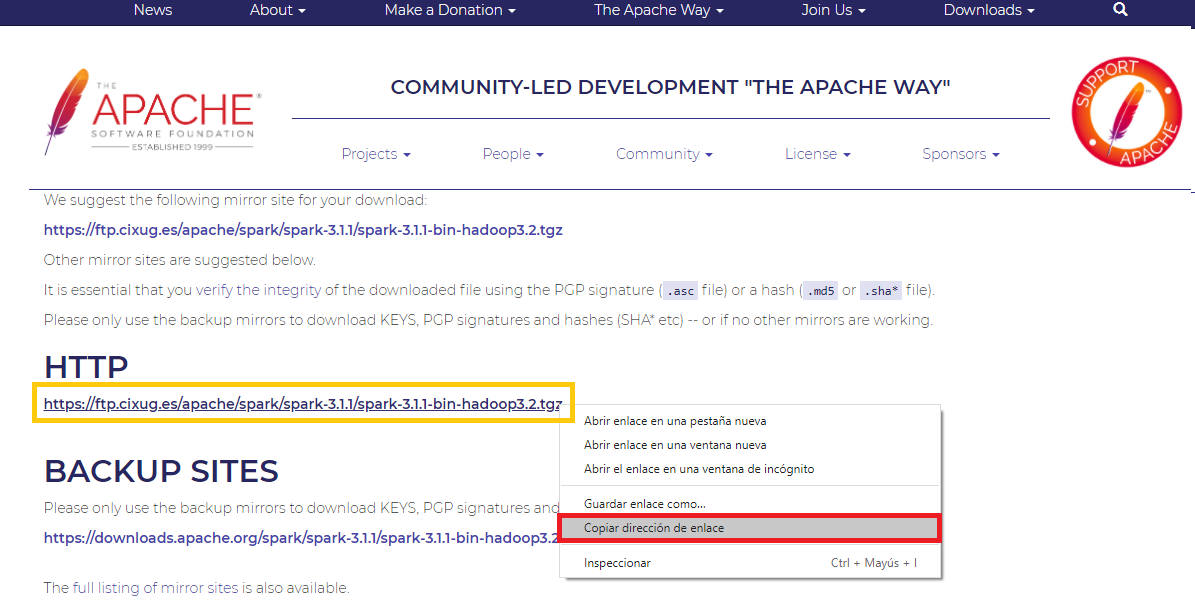
Nota: aquí copiamos la URL para descargar este Software mediante la consola de comandos de Linux (como se verá a continuación), pero si quieres hacerlo de otra manera también puedes.
Descargaremos por la consola de Linux mediante el comando “wget” añadiendo tras el comando (y un espacio) la URL con la descarga de Spark que hemos copiado anteriormente.
wget https://ftp.cixug.es/apache/spark/spark-3.1.1/spark-3.1.1-bin-hadoop3.2.tgzAl ejecutar este comando se descargará el fichero comprimido de Spark en la ruta donde estemos.
Instalar Spark
Crearemos una carpeta llamada “hadoop” para instalar ahí Spark, con el siguiente comando:
mkdir hadoopPara descomprimir el contenido en la carpeta de “hadoop”, que hemos creado anteriormente, utilizaremos el siguiente comando “tar”:
tar -xvzf descargas/spark-3.1.1-bin-hadoop3.2.tgz -C ~/hadoopComprobamos lo que se ha descomprimido; basta con echar un rápido vistazo a todo lo que está dentro de la carpeta “hadoop” (se puede utilizar “ls” o “ll”):
ls hadoop/
Esto es importante para ver la ruta correcta que tenemos que utilizar para añadirla a las variables de entorno (en mi caso tengo en el usuario la ruta, por lo que sería “~/hadoop/spark-3.1.1-bin-hadoop3.2”).
Obtener la ruta completa
Con la ruta con encabezada con el símbolo virgulilla “~” es más que suficiente, pues indica en Linux el usuario actual. Pero si queremos la ruta completa con nuestro usuario podremos obtener la con el comando “readlink”:
readlink -f hadoop/spark-3.1.1-bin-hadoop3.2/Que te devolvería algo así: /home/usuario/hadoop/spark-3.1.1-bin-hadoop3.2
Aunque si queremos que la ruta sea más universal (y la que yo usaré): ~/hadoop/spark-3.1.1-bin-hadoop3.2
Añadiremos la variable de entorno SPARK_HOME a nuestro sistema con el comando “export”, donde añadiremos la ruta que de nuestra instalación de Spark:
export SPARK_HOME=~/hadoop/spark-3.1.1-bin-hadoop3.2Y la añadimos SPARK_HOME a la variable de entorno PATH con el siguiente comando:
export PATH=$SPARK_HOME/bin:$PATHInstalar Java (Dependencia de Spark obligatoria)
Spark está escrito en Scala que a su vez requiere Java, por lo que necesitamos Java para que Spark funcione.
Nota sobre si quieres programar con Python en vez de con Scala o Java: Da igual que vayas a programar con Python, Java o Scala, Spark necesita Java para que funcione (la explicación larga es que el servidor de Spark ejecuta Scala y Scala compila sus ficheros en “.class” de Java, que funcionan sobre la máquina virtual de Java; luego las bibliotecas que utilicemos en Python, Java o Spark son independientes al servidor de Spark, pero funcionan contra este).
Es importante instalar las versiones de las dependencias compatibles con Spark, se puede comprobar las versiones de las dependencias compatibles con la última versión de Spark en: https://spark.apache.org/docs/latest/ . Para Java es muy importante fijarnos las versiones compatibles en (en mi caso servirá Java 8 y Java 11).
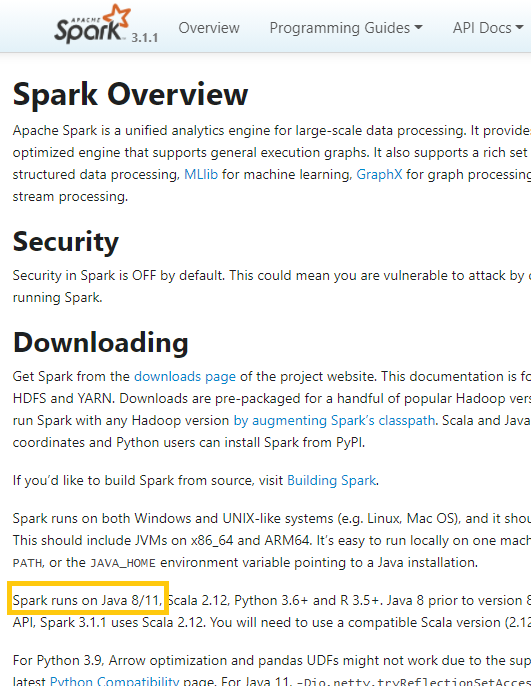
Nota para comprobar dependencias de otras versiones de Spark: si no has descargado la última versión de Spark tendrás que seleccionarla desde https://spark.apache.org/docs/
Actualizar APT
Si APT no tiene los enlaces a los repositorios actualizados, podría no encontrar todo lo que se necesitará a continuación (dando error con la descarga).
Para actualizar los listados de APT bastará con ejecutar (esto no actualiza el Software instalado):
sudo apt updateInstalar el JDK de Java con APT que queramos; yo voy a instalar la versión 11, que será el openjdk-11-jdk:
sudo apt install openjdk-11-jdkAl pulsar la tecla “Intro” comenzará la descarga y la instalación, que tardará unos minutos.
Nota sobre la instalación: Durante la ejecución del comando APT puede pedir que confirmemos si queremos seguir con la instalación, simplemente escribimos la letra “Y” y pulsamos la tecla “Intro”.
Java se instala normalmente en la carpeta “/usr/lib/jvm”, por lo que podemos comprobar la instalación con “ls” (o “ll” si queremos ver todo):
ls /usr/lib/jvm
Para crear la variable de entorno JAVA_HOME es importante copiar la ruta al ejecutable de Java (recomiendo copiar el “enlace simbólico”, el que aparece en azul claro) para formar la ruta para crear la variable entorno, en mi caso sería:
export JAVA_HOME=/usr/lib/jvm/java-1.11.0-openjdk-amd64Y probamos que Java esté bien instalado, bastará con ejecutar el siguiente comando que muestra la versión de Java:
java -version
Si queremos utilizar otra versión de Java
Podemos ver qué versiones hay disponibles en el repositorio de APT si NO completamos el comando (escribimos hasta antes de la versión) y pulsamos la tecla tabular:
sudo apt install openjdk-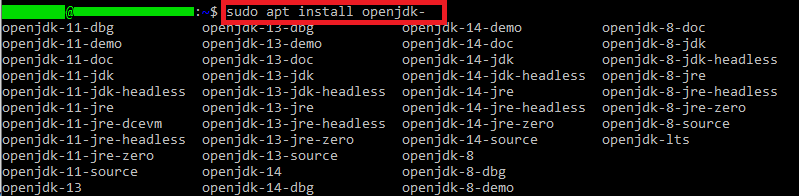
Luego completamos el comando con la versión del JDK de Java que nos interese y lo instalamos.
Y, si tienes varias versiones de Java instaladas, puedes elegir con qué versión de Java compatible con Spark trabajar, con el comando:
sudo update-alternatives --config javaProbar la Shell de Spark y programar con Scala
En este punto ya tenemos Spark instalado, tanto si vamos a programas con Scala como si no, recomiendo probar esto. Podemos probar lanzando la Shell de Spark con:
spark-shellLa primera vez, tarda como un minuto en arrancar el servidor, se sabe que ha arrancado porque aparece “scala>” y permite comenzar a programar con el lenguaje Scala.
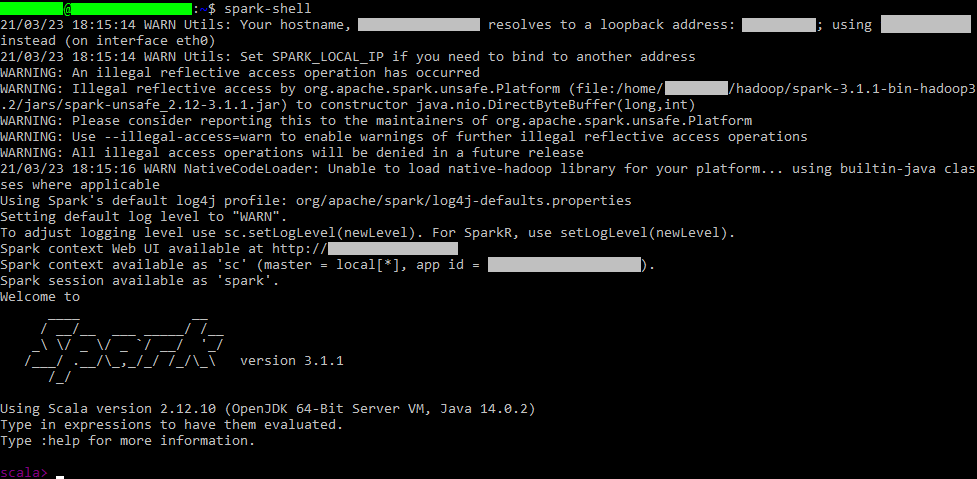
Aquí ya podemos trabajar con Spark con el lenguaje Scala (Si queremos Python o instalar JupyterLab, continúa con el resto del artículo).
Un ejemplo rápido de cómo funciona con Scala: realizamos un ejemplo simple de uso con una lista de enteros paralelizado y tomamos 2 (como puedes leer en el texto que aparece en la consola, ya nos da SparkContext instanciado en la variable “sc” que podemos utilizar directamente):
val rdd = sc.parallelize(List(1, 2, 3, 4))
rdd.take(2)
Para salir de la Shell de Spark, bastará con pulsar: [ctrl] + [c]
Preparar Python, instalar PySpark
Para este apartado al menos hay que instalar Python como se explica en este otro artículo paso a paso (e incluso te recomiendo que instales Jupyter como se indica en ese otro artículo, para que trabajes más cómodamente con Spark con Python y Scala).
Si queremos utilizar Spark en Python tendremos que instalar la biblioteca de Python PySpark con:
pip install pysparkFindspark NO es necesario
Si has añadido las variables de entorno descritas en este artículo y en artículo el de la instalación de Python, entonces NO necesitas findspark, por lo que te puedes saltar este cuadro.
Por si lo necesitaras, indicarte que se puede instalar con:
pip install findsparkY en tu código Python tienes que añadir al principio:
import findspark
findspark.init()Como te comento, si has seguido bien este tutorial y el sugerido, no lo necesitas; por tanto, nos ahorramos líneas de código y paquetes de más.
En este punto podremos programar con Python desde la consola de Python con el comando:
pythonY podemos probar que funciona con el siguiente código Python, donde la primera línea importa SparkContext del paquete PySpark y lo instanciamos:
from pyspark import SparkContext
sc = SparkContext()Arrancará el servidor y podremos probar con un listado pequeño de datos (en el siguiente ejemplo un listado de números) y tomando los 2 primeros datos del listado paralelizado con Spark:
datos = sc.parallelize([1, 2, 3, 4])
datos.take(2)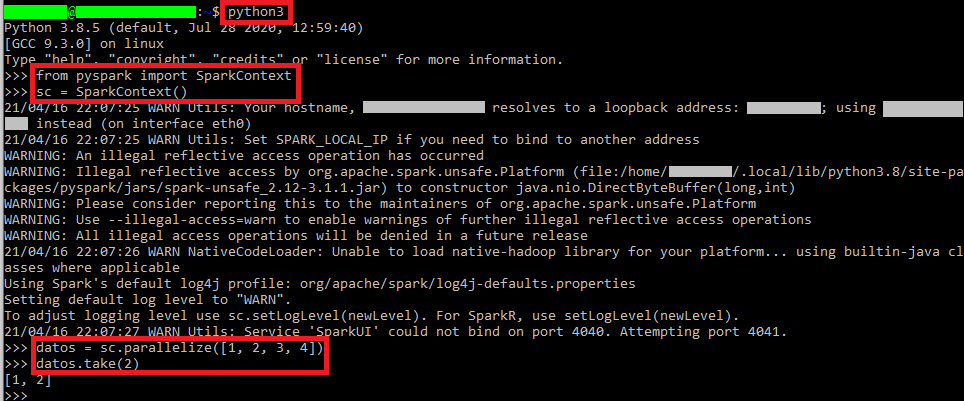
Para salir del intérprete de comandos de Python, escribe la siguiente función (no sirve [ctrl]+[c], ya que se captura esta señal para poder utilizarla dentro de nuestros programas):
exit()Nota si quieres aprender Python: hemos abierto un curso gratuito de Python en https://jarroba.com/courses/curso-de-python-gratis/ donde aprenderás Python desde una perspectiva profesional para trabajar con grandes cantidades de datos, con muchos ejemplos de código y teoría en vídeo.
Python con Spark en Jupyter Notebook o JupyterLab
Para seguir con este apartado necesitamos tener instalado Jupyter notebook o JupyterLab, explicamos paso a paso como se hace en este otro artículo dedicado (Explicamos como crear un nuevo fichero Notebook que es necesario para realizar este apartado).
Introducimos el siguiente código Python para probar Spark (está descrito más arriba, en “Instalar Python y PySpark”) en las celdas de nuestro Notebook (recomiendo poner los “import” en una celda principal, la línea “sc = SparkContext()” en una celda aparte porque solo va a iniciar el servidor una vez, que además tarda un minuto en arrancar, y luego podremos trabajar todo lo que queramos pudiendo colocar como queramos el resto de líneas de código):
from pyspark import SparkContext
sc = SparkContext()
datos = sc.parallelize([1, 2, 3, 4])
datos.take(2)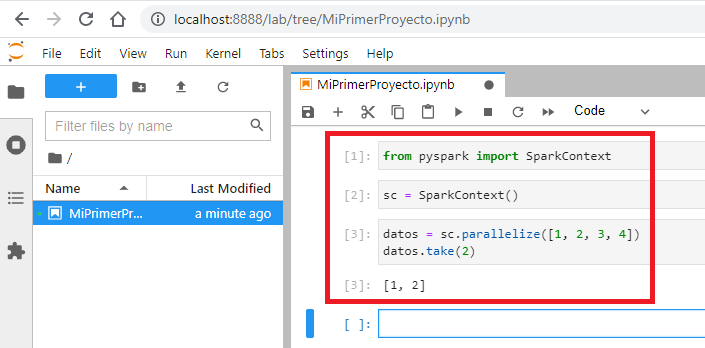
Scala con Spark en Jupyter Notebook o JupyterLab con Spylon-kernel
Podemos instalar un “plugin” para Jupyter (afecta a Jupyter y JupyterLab) llamado “spylon-kernel” de la siguiente manera:
pip install spylon-kernelLuego es necesario ejecutar spylon_kernel en Python (esto creara un kernel para Jupyter; dicho de otro modo: activa el “plugin”):
python3 -m spylon_kernel install --user
Si lo has instalado con SUDO
Entonces tendrás que ejecutar (en vez de «python3 -m spylon_kernel install –user»):
sudo python3 -m spylon_kernel installSi inicias JupyterLab (o Jupyter) podrás iniciar un nuevo Notebook con “spylon-kernel” para programas con Scala sobre Spark:
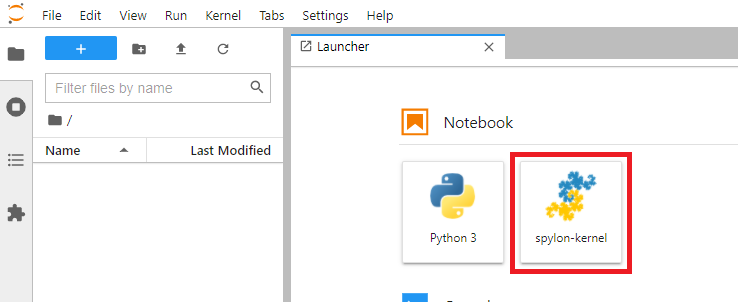
Inicializamos el intérprete de Scala (y el contexto de Spark) ejecutando en una celda un Notebook (tarda como un minuto en arrancar):
scY en otras celdas podemos ejecutar el código de Scala que queramos sobre Spark:
val rdd = sc.parallelize(List(1, 2, 3, 4))
rdd.take(2)
Java con Spark
Necesitamos añadir a nuestro proyecto la biblioteca “spark-core” (puedes ver todas las versiones y descargar la que necesites en: https://mvnrepository.com/artifact/org.apache.spark/spark-core).
A continuación, voy a explicar rápidamente como hacer un proyecto funcional de Spark con Java desde cero por la consola de Linux.
Nota sobre otras maneras de trabajar con Spark en Java: Existen otras maneras de trabajar con Java más cómodas mediante IDEs, pero como estoy explicando como trabajar con comandos, me voy a centrar en esta manera.
Instalar Maven en Linux por consola y crear un arquetipo rápido
Existen otras maneras de tener Maven instalado (por ejemplo, que el IDE lo traiga instalado o por instalador), pero aquí voy a atender a realizarlo todo por la consola de Linux (de WSL si usas Windows; para saber más de Maven y sus trucos recomiendo leer el artículo dedicado https://jarroba.com/maven/ ).
Para instalar Maven:
sudo apt install mavenComprobamos que esté bien instalado:
mvn --version
Creamos una carpeta para nuestro proyecto de Java:
mkdir proyectoJavaEntramos en ella:
cd proyectoJavaCreamos un arquetipo (un “arquetipo” es un proyecto Maven listo para trabajar con él, el cual creará un directorio que se llamará igual que el valor que pongamos en “-DartifactId=” y la estructura del proyecto seguirá lo que pongamos en el valor de “-DgroupId=”; aquí voy a crear uno rápido y simple; si queremos crear un arquetipo paso a paso tienes toda la información en este artículo sobre Maven):
mvn archetype:generate -DgroupId=com.jarroba.app -DartifactId=miProyectoJava -DarchetypeArtifactId=maven-archetype-quickstart -DarchetypeVersion=1.4 -DinteractiveMode=false
Si miras dentro de esta carpeta generada por Maven habrá un fichero “pom.xml” y un directorio “src”:
ls
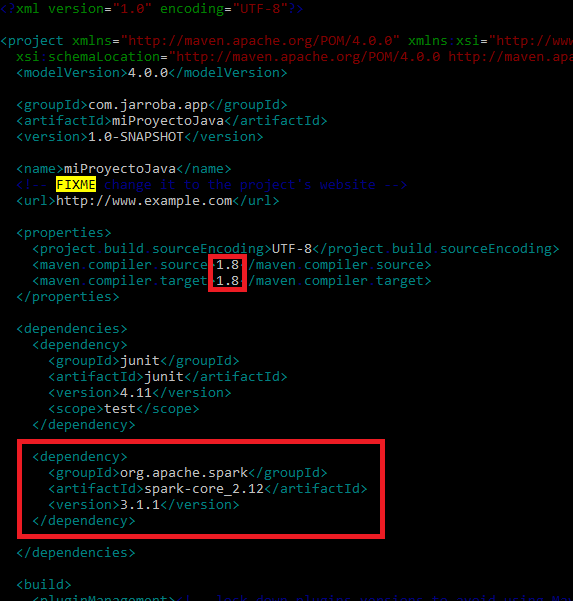
Yo utilizaré Maven para añadir la dependencia “spark-core” en el “pom.xml” (es importante añadir el siguiente XML dentro de “dependencies”):
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>3.1.1</version>
</dependency>También tendremos que asegurar que se compila al menos con Java 8 (por ser dependencia de Spark) y para ello, en el pom.xml, cambiaremos “maven compiler source” y “maven compiler target” a 1.8 si no lo está.
La siguiente imagen muestro tanto la dependencia “spark-core” añadida en el apartado “dependencies”, como la modificación de “maven compiler source” y “maven compiler target” a 1.8 (para editar “pom.xml” yo he utilizado VIM, puedes utilizar el editor que quieras):
Crearemos nuestro código Java, para ello vamos a modificar el fichero Java que se nos habrá creado en la carpeta “src” (en mi caso “App.java”).

Y sustituiré lo que hay con el siguiente código (que hace lo mismo que en los ejemplos de Python y Scala: un listado de números que paralelizamos e imprimimos los dos primeros números para ver que funciona); por cierto, cambia la primera línea (“package com.jarroba.app;”) y el nombre de la clase (“public class App {”) por los tuyos:
package com.jarroba.app;
import java.util.List;
import java.util.Arrays;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.JavaRDD;
public class App {
public static void main( String[] args ){
SparkConf conf = new SparkConf().setMaster("local").setAppName("MiAplicacionSpark");
JavaSparkContext sc = new JavaSparkContext(conf);
List<Integer> miLista = Arrays.asList(1, 2, 3, 4);
JavaRDD<Integer> rdd = sc.parallelize(miLista);
List<Integer> miSubLista = rdd.take(2);
System.out.println(miSubLista.toString());
sc.stop();
}
}Cuando guardemos. Ejecutamos el comando de Maven “Package” para construir nuestro proyecto (y compilar el código Java) en el directorio donde está el “pom.xml”:
mvn packageSi todo ha ido bien, sin errores, aparecerá un texto “BUILD SUCCESS” y tendremos nuestro proyecto en un paquete JAR en la carpeta llamada “target” en la raíz en nuestro proyecto (por el nombre que yo le puse anteriormente, el mío se llama “miProyectoJava-1.0-SNAPSHOT.jar”).

Es hora de ejecutar nuestro proyecto Spark en Java mediante el ejecutable “spark-submit”, que se encuentra dentro de la carpeta “bin” de nuestra instalación de Spark (donde lo descomprimimos pasos atrás). Este ejecutable requiere que pongamos de valor “–class” el nombre de nuestra clase con su espacio de nombres (en mi caso “com.jarroba.app.App”); el valor de “–master” escribiremos “local” para que se ejecute en local (y el contexto de Spark se pase a nuestro programa Java desde ahí); y terminaremos con la ruta hasta nuestro fichero JAR en la carpeta “target” (en mi caso es “~/miProyectoJava/target/miProyectoJava-1.0-SNAPSHOT.jar”):
~/hadoop/spark-3.1.1-bin-hadoop3.2/bin/spark-submit --class "com.jarroba.app.App" --master local ~/miProyectoJava/target/miProyectoJava-1.0-SNAPSHOT.jarDespués de mucha información de Spark, hacia el final de la ejecución, podrás ver la salida por pantalla de nuestro programa:

No podemos ejecutar un programa Spark con Java (de la manera tradicional)
Al menos no he encontrado manera alguna, pues si intentamos ejecutar el programa Java con:
java -cp target/miProyectoJava-1.0-SNAPSHOT.jar com.jarroba.app.AppJava no nos va a encontrar los archivos de Spark y devolverá un error:
Exception in thread "main" java.lang.NoClassDefFoundError: org/apache/spark/SparkConf
at com.jarroba.app.App.main(App.java:25)
Caused by: java.lang.ClassNotFoundException: org.apache.spark.SparkConf
at java.base/jdk.internal.loader.BuiltinClassLoader.loadClass(BuiltinClassLoader.java:581)
at java.base/jdk.internal.loader.ClassLoaders$AppClassLoader.loadClass(ClassLoaders.java:178)
at java.base/java.lang.ClassLoader.loadClass(ClassLoader.java:522)Bibliografía
- Scala con Spark, apuntes de la asignatura «Sistemas de Gestión de datos e Infraestructura» (En la Universidad Europea de Madrid).
- https://spark.apache.org/docs/0.9.1/scala-programming-guide.html
- https://spark.apache.org/docs/latest/submitting-applications.html
- https://spark.apache.org/docs/0.9.1/java-programming-guide.html
- https://pypi.org/project/spylon-kernel/
