Pandas en Python, con ejemplos -Parte II- Lectura-Escritura, Merge & GroupBy
El proyecto de este post lo puedes descargar pulsando AQUI.
Sobre la librería de Pandas vamos a hablar de los siguientes temas en las entradas:
- Parte I: Introducción a Pandas.
- Parte II: DataFrame: Lectura y Escritura, Mergeo de DataFrame's y GroupBy.
- Parte III: Operaciones de "Pivot_table" con DataFrame's.
Lectura-Escritura, Merge y GroupBy
En este tutorial vamos a mostrar algunas de las operaciones y funcionalidades que nos aporta la librería de Pandas para trabajar con DataFrame's. Para ello utilizaremos el data set del sistema de recomendación de MovieLens que tiene información sobre películas, usuarios y sobre los votos que emiten los usuarios a las películas. A través del siguiente enlace (http://grouplens.org/datasets/movielens/) podéis descargaros este data set (con diferente número de votos: 100K, 1M, 10M, etc), aunque en el proyecto que hemos compartidos en github están los ficheros del data set que vamos a utilizar (con 100K votos).
Aunque en el data set de Movilens vienen varios ficheros con diferente información; para el ejemplo que vamos a realizar, solo utilizaremos los datos de los usuarios, películas y votos. Como estos datos los ha compartido Movilens obteniendolos de su base de datos, la relación entre estos ficheros quedaría de la siguiente manera (en un diagrama Entidad-Relación):
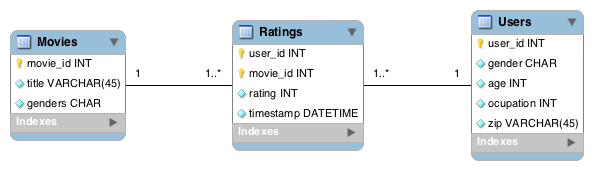
Como vemos, tenemos informacion relativa a los usuarios y películas, y como relación N-M tenemos la tabla intermedia de votos.
Lectura-Escritura
Con la libreria Pandas podemos leer los data set a partir de diferentes formatos; como por ejemplo txt, csv, json, sql, html, y un largo etc. En el siguiente enlace http://pandas.pydata.org/pandas-docs/stable/io.html podéis ver todos los posibles formatos. Cada uno de estos métodos de lectura de determinados formatos (read_NombreFormato) tiene infinidad de parámetros que podéis ver en la documentación y que no vamos a explicar por lo extensísima que seria esta explicación. Sin embargo si que paso a explicar el método "generico" para la lectura de ficheros sea cual sea su formato; como es el caso del método "read_table()". Este método también puede tener infinidad de parámetros, pero siendo prácticos y para la mayoría de los casos que nos vamos a encontrar los parámetros serían los siguientes:
pd.read_table(dir_fichero, engine='python', sep=';', header=True|False, names=[lista con nombre columnas])
Básicamente hay que pasarle el fichero a leer, cual es su separador, si la primera linea del fichero contiene el nombre de las columnas y en el caso de que no las tenga pasarle en 'names' el nombre de las columnas. Veamos por ejemplo como leeriamos el fichero con los datos de los usuarios, siendo el contenido de las 5 primeras lineas el siguiente:
1::F::1::10::48067 2::M::56::16::70072 3::M::25::15::55117 4::M::45::7::02460 5::M::25::20::55455
Vemos que la primera linea no tiene el nombre de las cabeceras; por tanto, hay que indicarle el 'header=False'. También vemos que el separador de las columnas es '::' y el nombre de las columnas es el que indicamos en el diagrama Entidad-Relación anterior. Por tanto para leer los datos de los usuarios a partir del fiecho txt y pasarlos a un DataFrame habría que hacer lo siguiente:
# Load users info
userHeader = ['user_id', 'gender', 'age', 'ocupation', 'zip']
users = pd.read_table('dataSet/users.txt', engine='python', sep='::', header=None, names=userHeader)
# print 5 first users
print '# 5 first users: \n%s' % users[:5]
Como salida a este fragmento de código en el que al final imprimimos por pantalla los 5 primeros usuarios quedaría de la siguiente forma:
# 5 first users: user_id gender age ocupation zip 0 1 F 1 10 48067 1 2 M 56 16 70072 2 3 M 25 15 55117 3 4 M 45 7 02460 4 5 M 25 20 55455
Para escribir un DataFrame en un fichero de texto se pueden utilizar los método de escritura (ver en http://pandas.pydata.org/pandas-docs/stable/io.html) para escribirlos en el formato que se quiera. Por ejemplo si utilizamos el método 'to_csv()' nos escribirá el DataFrame en este formato estandar que separa los campos por comas; pero por ejemplo, podemos decirle al método que en vez de que utilice como separador una coma, que utilice por ejemplo un guión. Si queremos escribir en un fichero el DataFrame 'users' con estas características lo podemos hacer de la siguiente manera:
users.to_csv('MyUsers.txt', sep='-')
Para este ejemplo nos genera un fichero de texto llamado 'MyUsers.txt' con el siguiente contenido, en el que vemos que en la primera linea nos escribe el nombre de las columnas y en la siguiente el contenido del DataFrame, pero incluyendo en la primera posición el índice:
-user_id-gender-age-ocupation-zip 0-1-F-1-10-48067 1-2-M-56-16-70072 2-3-M-25-15-55117 3-4-M-45-7-02460 4-5-M-25-20-55455 5-6-F-50-9-55117 ................. .................
Merge
Una funcionalidad muy potente que ofrece Pandas es la de poder mergear (en bases de datos sería hacer un JOIN) datos siempre y cuando este sea posible. En el ejemplo que estamos haciendo con el data set de MovieLens podemos ver esta funcionalidad de forma muy intuitiva, ya que los datos de este data set se han obtenido a partir de una bases de datos relacional. Veamos a continuación como hacer un JOIN o un mergeo de los ficheros 'users.txt' y 'ratings.txt' a partir del 'user_id':
# Load users info
userHeader = ['user_id', 'gender', 'age', 'ocupation', 'zip']
users = pd.read_table('dataSet/users.txt', engine='python', sep='::', header=None, names=userHeader)
# Load ratings
ratingHeader = ['user_id', 'movie_id', 'rating', 'timestamp']
ratings = pd.read_table('dataSet/ratings.txt', engine='python', sep='::', header=None, names=ratingHeader)
# Merge tables users + ratings by user_id field
merger_ratings_users = pd.merge(users, ratings)
print '# Merge tables users + ratings by user_id field \n%s' % merger_ratings_users[:10]
Como resultado a este fragmento de código tenemos las 10 primeras posiciones de esta unión:
# Merge tables users + ratings by user_id field user_id gender age ocupation zip movie_id rating timestamp 0 1 F 1 10 48067 1193 5 978300760 1 1 F 1 10 48067 661 3 978302109 2 1 F 1 10 48067 914 3 978301968 3 1 F 1 10 48067 3408 4 978300275 4 1 F 1 10 48067 2355 5 978824291 5 1 F 1 10 48067 1197 3 978302268 6 1 F 1 10 48067 1287 5 978302039 7 1 F 1 10 48067 2804 5 978300719 8 1 F 1 10 48067 594 4 978302268 9 1 F 1 10 48067 919 4 978301368
De la misma forma que hemos hecho el JOIN de los usuarios y los votos, podemos hacer lo mismo añadiendo también los datos relativos a las películas:
# Load Data
userHeader = ['user_id', 'gender', 'age', 'ocupation', 'zip']
users = pd.read_table('dataSet/users.txt', engine='python', sep='::', header=None, names=userHeader)
movieHeader = ['movie_id', 'title', 'genders']
movies = pd.read_table('dataSet/movies.txt', engine='python', sep='::', header=None, names=movieHeader)
ratingHeader = ['user_id', 'movie_id', 'rating', 'timestamp']
ratings = pd.read_table('dataSet/ratings.txt', engine='python', sep='::', header=None, names=ratingHeader)
# Merge data
mergeRatings = pd.merge(pd.merge(users, ratings), movies)
Si quisiésemos ver por ejmplo un elemento de este nuevo JOIN creado (por ejemplo la posición 1000), lo podríamos hacer de la siguiente forma:
info1000 = mergeRatings.ix[1000] print 'Info of 1000 position of the table: \n%s' % info1000[:10]
Teniendo como resultado lo siguiente:
Info of 1000 position of the table: user_id 3612 gender M age 25 ocupation 14 zip 29609 movie_id 1193 rating 5 timestamp 966605873 title One Flew Over the Cuckoo's Nest (1975) genders Drama Name: 1000, dtype: object
GroupBy
La última funcionalidad que vamos a ver en este tutorial es la de agrupación de datos en los DataFrame's que correspondería a la operación 'groupby' que se puede hacer en las bases de datos. Con esta funcionalidad no solo permite hacer agregaciones; sino también, hacer operaciones en base a esas agregaciones como el calculo de sumas, medias, desviaciones típicas, etc. Para los ejemplos que vamos a ver a continución necesitaremos utilizar la librería 'numpy' para hacer este tipo de operaciones, por tanto hay que importarla en nuestro proyecto:
import pandas as pd import numpy as np
Para ver un ejemplo de la operación 'groupby', vamos a unir primero las tres fuentes de datos (users, movies y ratings) y vamos a agrupar por el título de la película (columna 'title') y vamos a contar cuantos votos ha recibido cada película (haciendo un conteo del número de tuplas). Posteriormente haremos una ordenación de mayor a menos para ver las 10 más votadas. Esto lo hacemos de la siguiente manera:
# Load Data
userHeader = ['user_id', 'gender', 'age', 'ocupation', 'zip']
users = pd.read_table('dataSet/users.txt', engine='python', sep='::', header=None, names=userHeader)
movieHeader = ['movie_id', 'title', 'genders']
movies = pd.read_table('dataSet/movies.txt', engine='python', sep='::', header=None, names=movieHeader)
ratingHeader = ['user_id', 'movie_id', 'rating', 'timestamp']
ratings = pd.read_table('dataSet/ratings.txt', engine='python', sep='::', header=None, names=ratingHeader)
# Merge data
mergeRatings = pd.merge(pd.merge(users, ratings), movies)
# Clone DataFrame
def cloneDF(df):
return pd.DataFrame(df.values.copy(), df.index.copy(), df.columns.copy()).convert_objects(convert_numeric=True)
# Show Films with more votes. (groupby + sorted)
numberRatings = cloneDF(mergeRatings)
numberRatings = numberRatings.groupby('title').size().sort_values(ascending=False)
print 'Films with more votes: \n%s' % numberRatings[:10]
Vemos como con el método 'groupby()' nos permite agrupar por la columna que le indiquemos, con el método 'size()' nos hace la cuenta del número de veces que se repiten los títulos tras la agrupación y por último com el método 'sort_values()' nos ordena el resultado de mayor a menor, teniendo como resultado lo siguiente:
Films with more votes: title American Beauty (1999) 3428 Star Wars: Episode IV - A New Hope (1977) 2991 Star Wars: Episode V - The Empire Strikes Back (1980) 2990 Star Wars: Episode VI - Return of the Jedi (1983) 2883 Jurassic Park (1993) 2672 Saving Private Ryan (1998) 2653 Terminator 2: Judgment Day (1991) 2649 Matrix, The (1999) 2590 Back to the Future (1985) 2583 Silence of the Lambs, The (1991) 2578 dtype: int64
ADVERTENCIA!! para la copia o "clone" de DataFrame's:
Por lo general para la mayoría de las estructuras de datos en python suele haber un método 'copy()' o 'clone()' que te hace una copia de una estructura de datos determinada. Para el caso de los DataFrame's (aunque si buscáis por internet veréis algunos ejemplos que no funcionan) no se aplican estos métodos y para crearse una copia de un DataFrame, hay que construirse otro DataFrame con los mismos datos del DataFrame original. A continuación comparto un método ('cloneDF(df)') devuelve una copia del DataFrame que se pasa como parámetro:
# Clone DataFrame
def cloneDF(df):
return pd.DataFrame(df.values.copy(), df.index.copy(), df.columns.copy()).convert_objects(convert_numeric=True)
Probablemente exista una solución mejor a la que aquí se propone, pero esta solución funciona.
Para ver que más cosas se pueden hacer, podemos hacer la agrupación por más columnas; como por ejemplo, por título e identificador de la película y en este caso calcularemos la nota media de los votos por película con el método 'mean()':
# Show avg ratings movie (groupby + avg) avgRatings = cloneDF(mergeRatings) avgRatings = avgRatings.groupby(['movie_id', 'title']).mean() print 'Avg ratings: \n%s' % avgRatings['rating'][:10]
Avg ratings: movie_id title 1 Toy Story (1995) 4.146846 2 Jumanji (1995) 3.201141 3 Grumpier Old Men (1995) 3.016736 4 Waiting to Exhale (1995) 2.729412 5 Father of the Bride Part II (1995) 3.006757 6 Heat (1995) 3.878723 7 Sabrina (1995) 3.410480 8 Tom and Huck (1995) 3.014706 9 Sudden Death (1995) 2.656863 10 GoldenEye (1995) 3.540541 Name: rating, dtype: float64
En este caso hemos indicado que nos muestre el valor medio del campo 'rating', pero al aplicar el método 'mean()' en el DataFrame nos ha calculado todas las médias de todas las columnas que tienen datos numéricos.
Ahora seguimos agrupando por titulo e identificador, pero además vamos a hacer varios cálculos simultáneos que le indicaremos con una lista que le pasamos al método 'agg()':
# Show data ratings movies (groupby + several funtions) dataRatings = cloneDF(mergeRatings) dataRatings = dataRatings.groupby(['movie_id', 'title'])['rating'].agg(['mean', 'sum', 'count', 'std']) print 'Films ratings info: \n%s' % dataRatings[:10]
Films ratings info:
mean sum count std
movie_id title
1 Toy Story (1995) 4.146846 8613 2077 0.852349
2 Jumanji (1995) 3.201141 2244 701 0.983172
3 Grumpier Old Men (1995) 3.016736 1442 478 1.071712
4 Waiting to Exhale (1995) 2.729412 464 170 1.013381
5 Father of the Bride Part II (1995) 3.006757 890 296 1.025086
6 Heat (1995) 3.878723 3646 940 0.934588
7 Sabrina (1995) 3.410480 1562 458 0.979918
8 Tom and Huck (1995) 3.014706 205 68 0.954059
9 Sudden Death (1995) 2.656863 271 102 1.048290
10 GoldenEye (1995) 3.540541 3144 888 0.891233
Al método 'agg()' le podemos pasar también funciones declaradas por nosotros mismos como es el siguiente caso en el que hacemos una función que nos calcula la media de los votos y para ver que es correcto, indicamos también que nos calcule la media (en este caso vamos a utilizar las funciones de la librería numpy):
# Show data ratings movies, applying a function (groupby + lambda function)
myAvg = cloneDF(mergeRatings)
myAvg = myAvg.groupby(['movie_id', 'title'])['rating'].agg(
{'SUM': np.sum, 'COUNT': np.size, 'AVG': np.mean, 'myAVG': lambda x: x.sum() / float(x.count())})
print 'My info ratings: \n%s' % myAvg[:10]
My info ratings:
COUNT SUM AVG myAVG
movie_id title
1 Toy Story (1995) 2077 8613 4.146846 4.146846
2 Jumanji (1995) 701 2244 3.201141 3.201141
3 Grumpier Old Men (1995) 478 1442 3.016736 3.016736
4 Waiting to Exhale (1995) 170 464 2.729412 2.729412
5 Father of the Bride Part II (1995) 296 890 3.006757 3.006757
6 Heat (1995) 940 3646 3.878723 3.878723
7 Sabrina (1995) 458 1562 3.410480 3.410480
8 Tom and Huck (1995) 68 205 3.014706 3.014706
9 Sudden Death (1995) 102 271 2.656863 2.656863
10 GoldenEye (1995) 888 3144 3.540541 3.540541
Como último ejemplo vamos a agrupar por tíyulo e identificador y vamos a calcular el número de votos recibidos por película, calculamos la nota media y por último ordenamos las películas por el número de votos para poder ver la nota media de las películas más votadas:
# Sort data ratings by created field (groupby + lambda function + sorted)
sortRatingsField = cloneDF(mergeRatings)
sortRatingsField = sortRatingsField.groupby(['movie_id', 'title'])['rating'].agg(
{'COUNT': np.size, 'myAVG': lambda x: x.sum() / float(x.count())}).sort('COUNT', ascending=False)
print 'My info sorted: \n%s' % sortRatingsField[:15]
My info sorted:
COUNT myAVG
movie_id title
2858 American Beauty (1999) 3428 4.317386
260 Star Wars: Episode IV - A New Hope (1977) 2991 4.453694
1196 Star Wars: Episode V - The Empire Strikes Back ... 2990 4.292977
1210 Star Wars: Episode VI - Return of the Jedi (1983) 2883 4.022893
480 Jurassic Park (1993) 2672 3.763847
2028 Saving Private Ryan (1998) 2653 4.337354
589 Terminator 2: Judgment Day (1991) 2649 4.058513
2571 Matrix, The (1999) 2590 4.315830
1270 Back to the Future (1985) 2583 3.990321
593 Silence of the Lambs, The (1991) 2578 4.351823
1580 Men in Black (1997) 2538 3.739953
1198 Raiders of the Lost Ark (1981) 2514 4.477725
608 Fargo (1996) 2513 4.254676
2762 Sixth Sense, The (1999) 2459 4.406263
110 Braveheart (1995) 2443 4.234957
CONCLUSIONES:
La librería de Pandas es una librería destinada al análisis de datos muy utilizada por los 'data scientists'. Con esta librería se pueden hacer infinidad de cosas y en este caso hemos visto algunos casos prácticos utilizando el data set de MovieLens que es junto con el data set de Netflix son los data sets de referencia para el mundo de la investigación de los Sistemas de Recomendación (filtrado colaborativo principalmente) y Machine Learning. Dado que es un tutorial de introducción se han visto pocas cosas sobre esta librería, pero si que se han visto las necesarias como para empezar a trabajar con Pandas y una vez que se tenga soltura con esta librería seguro que podréis hacer un análisis de datos muy exhaustivo y preciso ya que es una librería que utilizan hoy en dia los data scientists profesionales.

Gracias Ricardo. No se encuentra mucho en castellano y en internet para poder iniciarse con Pandas. Para el análisis de datos, muchas veces tendremos que trabajar con fechas. Yo me estoy volviendo loco con este problema.
Estoy aprendiendo a trabajar con DataFrames en Pandas. En mi caso, el formato original en la hoja Excel es «dd-mm-YY». Al importar a un DataFrame con pandas, mediante la sentencia df = pd.read_excel(file, parse_dates=[‘Fecha’], dayfirst = True ) el formato que me presenta es «YY-mm-dd» («Fecha» es el nombre de la columna en la que tengo introducidas fechas). No solo no mantiene el formato original, si no que lo modifica. ¿Qué opciones tengo para cambiar ese formato y volver al original, actuando sobre el DataFrame? No venbdría mal que completaras este capítulo con alguna referencia a esto. Saludos cordiales
Si tengo una archivo de datos con extensión .csv y deseo ordenar solo una porción del archivo de menor a mayor por el campo temperatura, por ejemplo, como podría hacer esto?. Supongamos que tenemos esto:
id,type,xs,ys,zs
500,1,0.413068,0.247238,0.139937
384,1,0.509008,0.225649,0.113632
391,1,0.596777,0.212693,0.0827694
91,1,0.554459,0.155958,0.15268
396,1,0.678003,0.227263,0.134453
183,1,0.263006,0.32626,0.129268
199,1,0.355738,0.315005,0.0961778
572,1,0.398526,0.368158,0.0291984
563,1,0.449962,0.296985,0.0700937
710,1,0.431955,0.334981,0.152336
612,1,0.486912,0.343823,0.000879648
754,1,0.541953,0.275987,0.0351425
737,1,0.529449,0.313131,0.123254
y que quisiera ordenar una porción de este archivo, por ejemplo, por el campo id, usando el módulo pandas. Como podría hacer esto?
** Manejo de JOIN **
mergeInner = pd.merge(datosPersona, datosVehiculo, on=’ID_DATA’, how=’inner’)
mergeInner