Sistemas de Recomendación basados en Filtrado Colaborativo (K-Vecinos)
Como ya se vio en la entrada de "¿Que son los Sistemas de Recomendación?"; los sistema de recomendación son un sistema inteligente que proporciona a los usuarios una serie de sugerencias personalizadas (recomendaciones) sobre un determinado tipo de elementos (items). También vimos (aunque aquí lo volvemos a recordar) los 4 tipos en los que se clasifican los sistemas de recomendación que son los siguientes:
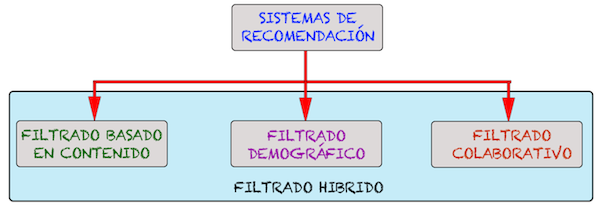
En esta entrada nos vamos a centrar en una parte del filtrado colaborativo, más concretamente en el filtrado colaborativo basado en memoria. Dentro de los sistemas de recomendación basados en filtrado colaborativo, existen dos clasificaciones que son los basados en memoria y los basados en modelos.
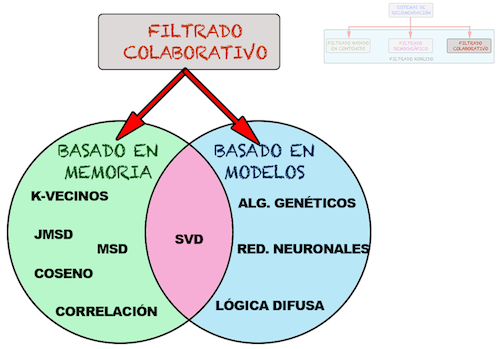
- Métodos basados en memoria: emplean métricas de similaridad para determinar el parecido entre una pareja de usuarios. Para ello calculan los items que han sido votados por ambos usuarios y comparan dichos votos para calcular la similaridad.
- Métodos basados en modelos: utilizan la matriz de votaciones para crear un modelo a través del cual establecer el conjunto de usuarios similares al usuario activo. Algunos ejemplos de estos modelos son los clasificadores bayesianos, las redes neuronales, algoritmos genéticos, sistemas borrosos y la técnica de descomposición matricial basada en la técnica matemática del SVD.
En esta entrada vamos a explicar la técnica de los K-vecinos para realizar recomendaciones, que es una técnica que se engloba dentro de los métodos basados en memoria. Esta técnica es quizás (sin considerar el SVD) la mejor técnica para realizar recomendaciones ya que se basa en recomendar a un usuario (en adelante usuario activo) los items (películas, libros, viajes, etc) que le han gustado a usuarios con gustos similares al usuario activo, de ahí el nombre de los k-vecinos, considerando los vecinos como usuarios con gustos similares al usuario activo. Por ejemplo si a un usuario U1 le han gustado las películas del "El Padrino", "Terminator" y "Resacón en las Vegas" y al usuario activo (Ua) le ha gustado también "El Padrino" y "Terminator", es muy probable que al ser usuarios con gustos muy similares, al usuario activo también le guste la película de "Resacón en las Vegas", por tanto el sistema de recomendación deberá recomendar esta película al usuario activo. Esto es un ejemplo muy básico para entender el concepto de esta técnica de los k-Vecinos que mostraremos con mas detalle posteriormente.
Vamos a poner un ejemplo de una página web que se dedica a la recomendación de películas y series (utilizando la técnica de los K-vecinos) como es FilmAffinity. Esta página web tiene registradas miles de películas y a su vez también debe de tener miles de usuarios registrados a los que debe recomendar. Para recomendar a un usuario con esta técnica de los K-Vecinos, el usuario previamente debe de "votar" una serie de películas (en esta web lo hacen con notas del 1 al 10) para que se sepan cuales son sus gustos. A su vez los otros miles de usuarios (de entre los cuales seguro que hay alguno que tiene gustos similares a usuario activo) deben de haber votado una serie de películas. De esta forma se tiene lo que se denomina la "Matriz de Votos" que representa los votos que han emitido los usuarios sobre las películas. Ni que decir tiene que esta matriz de votos va a ser muy dispersa; es decir, que los usuarios van a votar un muy pequeño porcentaje de películas, ya que si hay registrada miles de películas en la base de datos de la web, el usuario normal (a no ser que sea un cinefilo) habrá votado unas 100-200 películas. Con esta matriz de votos, podemos calcular lo que se denomina la "Similaridad entre usuarios" que no será mas que un valor (normalmente este valor suele tener un valor de entre 0 y 1) que nos diga el grado de similaridad que tenemos con otro/s usuarios. Esta similaridad entre usuario la calculamos con alguna de las métricas de similaridad existentes para los sistemas de recomendación. Las métricas más conocidas (y las que aquí vamos a explicar) son las del MSD (diferencia cuadrática media), la Correlación de Pearson y la del Coseno. Existen otras métricas mucho mejores que estas, como son las métricas del JMSD y la métrica de las Singularidades, que no vamos a explicar por su relativa complejidad, pero las comentamos y os ponemos los enlaces a sus artículos por si queréis verlas. A continuación vamos a mostrar las tres métricas de similaridad propuestas que básicamente lo que hacen es calcular "las distancias" que hay entre cada para de usuarios:
1.-MSD (Minimun Square Difference):
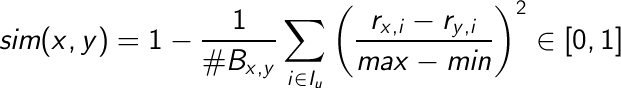
Siendo #Bx,y el número de películas que ambos usuarios han votado (y que tiene que ser necesariamente mayor que 0); siendo rx,i y ry,i los votos emitidos por los usuarios x e y respectivamente, y siendo max y min las notas máximas y mínimas que los usuarios han emitido.
2.-Correlación de Pearson:
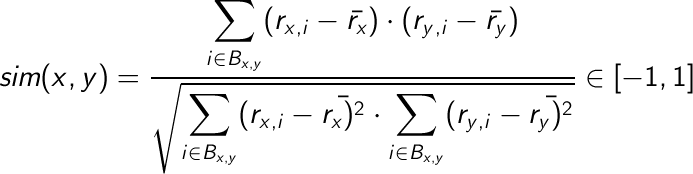
Siendo el rx "gorrito" la media de votos del usuario x.
3.-Coseno: mide la distancia que hay entre dos usuarios en función del ángulo que forman entre ellos.
Y llegados a este punto ¿En que consiste la técnica de los K-Vecinos?. Pues muy sencillo; esta técnica consiste en seguir una serie de pasos para realizar las recomendaciones que son los siguientes 4 pasos (Esquema general del filtrado colaborativo):
- Cálculo de la similaridad entre usuarios: En primer lugar se ha de elegir una métrica (MSD, Coseno, …) para determinar la similaridad entre una pareja de usuarios.
- Calcular los K-Vecinos: Haciendo uso de la métrica de similaridad seleccionada, se obtienen los k usuarios más similares al usuario activo. A estos usuarios se les denomina como los k-vecinos del usuario activo.
- Calcular las predicciones de los items: A partir de los k-vecinos del usuario activo, se determinan las posibles valoraciones que el usuario activo haría sobre los items que no ha votado, es decir, se predice como el usuario valoraría esos items.
- Realizar las recomendaciones: Tras el calculo de las predicciones, se eligen los N items más adecuados para ser recomendados al usuario, es decir, las predicciones más altas, mas novedosas, mas votadas, etc. De forma opcional, puede incluirse un umbral para evitar que los items con una predicción inferior a dicho umbral sean recomendados.
Llegados a este punto, hemos visto la técnica de los K-Vecinos desde un punto de vista muy teórico, así que vamos a poner un ejemplo de como recomendar dada la siguiente matriz de votos en la cual los usuarios votan en un rango del 1 al 5 (en vez de 1 a 10):
Las posiciones donde esta el simbolo "•", significa que el usuario no ha votado el item correspondiente.
Una vez que se tiene la matriz de votos se han de calcular las similaridades que tiene un usuario con el resto de usuarios de la base de datos. A modo de ejemplo vamos a mostrar como se calcula la similaridad entre los usuarios U1 y U2 utilizando la métrica de similaridad del MSD:
Las similaridades que hay entre cada par de usuarios las mostramos en la siguiente tabla. Estas similaridades las hemos calculado utilizando la métrica del MSD y podeis realizar los cálculos para cada par de usuarios para comprobar que calculáis correctamente la similaridad entre cada para de usuarios:
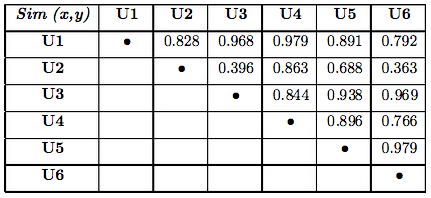
Llegados a este punto debemos ordenar las similaridades de mayor a menor para cada usuario y coger el número de vecinos que queramos para posteriormente poder predecir la votación del usuario. En este caso vamos a coger a dos vecinos, por tanto podemos ver que los dos usuarios que mas se parecen al usuario U1 son el usuario U4 y U3 al tener estos una mayor similaridad. En la siguiente tabla mostramos los dos vecinos correspondientes a cada usuario:

Una vez que tenemos elegidos a los vecinos no nos queda mas que predecir los votos que un usuario realizaría sobre los items que no ha valorado. Esta predicción se puede hacer con la media aritmética de los votos de los vecinos o con la media ponderada de los votos de los vecinos teniendo en cuenta la similaridad entre ellos. Las formulas de la media ponderada y de la media aritmética son las siguientes:
1.- Media aritmetica:
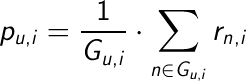
2.- Media ponderada:
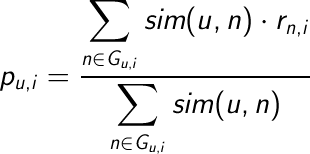
A modo de ejemplo pasamos a calcular la predicción del item I1 que realizará el usuario U4, teniendo en cuenta que sus vecinos son los usuarios U1 y U5, teniendo una similaridad de 0,979 y 0,896 respectivamente:
1.- Media aritmetica:
![]()
2.- Media ponderada:
![]()
Para simplificar los cálculos, pasamos a mostrar todas las predicciones de todos los items de los que se pueden calcular las predicciones, mostrando en color azul las predicciones de los items que el usuario no ha votado:
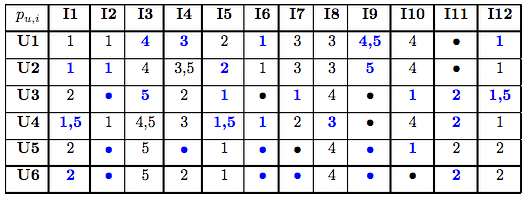
Una vez que se han obtenido las predicciones sobre los items que el usuario no ha votado, solo queda realizar las recomendaciones y esto se hace ordenando las predicciones de mayor a menor y recomendar aquellas que mayor nota de predicción tengan. Por ejemplo al usuario U1 el primer item a recomendar seria el item I9 ya que se ha predecido que el usuario votará dicho item con una nota de 4,5, luego se le recomendará el item I3 y así sucesivamente. Lo que se suele hacer en los sistemas de recomendación es recomendar un número determinado de items; por ejemplo, 20 peliculas, 10 libros etc, que corresponderán a las mejores predicciones. Para terminar este ejemplo, vamos a suponer que en nuestro sistema de recomendación vamos a recomendar solamente dos items, por tanto en la siguiente tabla vamos a mostrar que items son susceptibles de ser recomendados a cada usuario y cuales se les recomienda:

En resumen esta es la técnica de los K-vecinos y hemos puesto un sencillo ejemplo de como realizar recomendaciones. Este ejemplo ha sido obtenido del proyecto fin de Master de Ricardo Moya (Co-Creador de esta web) del capítulo 2 del que se habla del estado del arte de los sistemas de recomendación y que podéis ver en el siguiente enlace “SVD aplicado a Sistemas de Recomendación Basados en Filtrado Colaborativo (TFM) “ para ampliar conocimientos sobre estos temas y sobre la técnica del SVD de la cual hablaremos más adelante en otras entradas.
BIBLIOGRAFÍA
Parte de la información mostrada en esta entrada ha sido obtenida de las clases de la asignatura de “Sistemas de Recomendación” impartida en el Master de “Ciencias y Tecnologías de la Computación” en la Escuela Universitaria de Informática de la UPM por el profesor y Doctor Antonio Hernando y también del proyecto fin de Master del profesor e investigador de la EUI Fernando Ortega, siendo ambos grandes expertos en Sistemas de Recomendación habiendo publicado numerosos artículos JCR sobre Sistemas de Recomendación y siendo los creadores de las métricas del JMSD y la Singularidades (junto con Jesus Bobadilla y Jesus Bernal) mencionadas en esta entrada.
