¿Qué es el Machine Learning?
- Este post forma parte del libro "Machine Learning (en Python), con ejemplos"
El Machine Learning (ML) o Aprendizaje Autónomo es una rama de la Inteligencia Artificial (IA) que tiene como objetivo crear sistemas capaces de aprender por ellos mismos a partir de un conjunto de datos (data set), sin ser programados de forma explícita.
Para que estos sistemas puedan aprender por ellos mismos, se utilizan una serie de técnicas y algoritmos capaces de crear modelos predictivos, patrones de comportamiento, etc. Aunque no existe en la bibliografía actual un listado concreto y acotado de aquellas técnicas y algoritmos que se enmarcan dentro de la rama del ML (aunque hay algunas técnicas que claramente son propias de dicha área), si que podemos decir que en el área del ML encaja todo proceso de resolución de problemas, basados más o menos explícitamente en una aplicación rigurosa de la teoría de la decisión estadística; por tanto, es muy normal que el área del ML se solape con el área de la estadística. En ML; a diferencia de la estadística, se centra en el estudio de la complejidad computacional de los problemas, ya que gran parte de estos son de la clase NP-completo (o NP-hard) y por tanto el reto del ML está en diseñar soluciones factibles para este tipo de problemas.
Veamos a continuación dos definiciones de ML:
Aprendizaje del sistema: Regresión y Clasificación
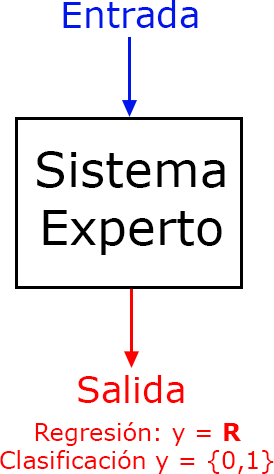 Como se ha comentado en la definición de ML, este área debe de crear sistemas que tienen que ser capaces de aprender por ellos mismos sin ser programados de forma explicita, con la finalidad de predecir hechos futuros, realizar recomendaciones, clasificaciones de elementos, eventos, tags, etc. Por tanto; después de una fase de aprendizaje, tendremos un “sistema experto” que dada una determinada entrada nos proporcionara una salida (predicción, recomendación, clasificación, etc.), como resultado de haber aplicado una función de regresión o clasificación (que debe de aprender el sistema) sobre los datos de entrada.
Como se ha comentado en la definición de ML, este área debe de crear sistemas que tienen que ser capaces de aprender por ellos mismos sin ser programados de forma explicita, con la finalidad de predecir hechos futuros, realizar recomendaciones, clasificaciones de elementos, eventos, tags, etc. Por tanto; después de una fase de aprendizaje, tendremos un “sistema experto” que dada una determinada entrada nos proporcionara una salida (predicción, recomendación, clasificación, etc.), como resultado de haber aplicado una función de regresión o clasificación (que debe de aprender el sistema) sobre los datos de entrada.
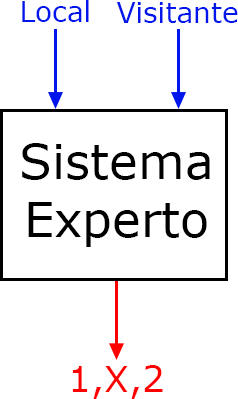
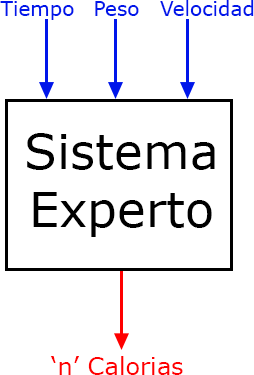
Dos ejemplos de sistemas expertos creados tras aplicar alguna/s técnica/s de ML, serían los siguientes: uno, un sistema experto en predicción de quinielas (clasificación), que pasándole el nombre del equipo local y visitante, devuelve como resultado una de las tres opciones de la quiniela (1, X, 2); y otro un sistema experto en el cálculo de calorías quemadas (regresión) al hacer carrera continua (running), en el que pasándole como entrada el peso de la persona, el tiempo de carrera y la velocidad, devuelva como resultado el número de calorías quemadas (0 <= calorías < ∞).
|
|
Como hemos visto, estos sistemas tienen dos formas de proporcionar un resultado: uno; la clasificación, que devuelve como salida un conjunto finito de resultados; generalmente pequeño, (y={0,1}, y={1,X,2}, y={si,no}) y otro; la regresión, que devuelve como salida un valor arbitrario (un número real, un vector de números reales, cadenas de símbolos, etc.).
Una vez explicado lo que es la regresión y la clasificación, veamos a continuación una definición más formal de las mismas:
Visto el tipo de sistemas expertos que queremos conseguir tras aplicar alguna/s técnica/s de ML, tenemos que ver como aprenden estos sistemas para obtener esa función de clasificación o regresión, que en adelante la denominaremos “hipótesis”.
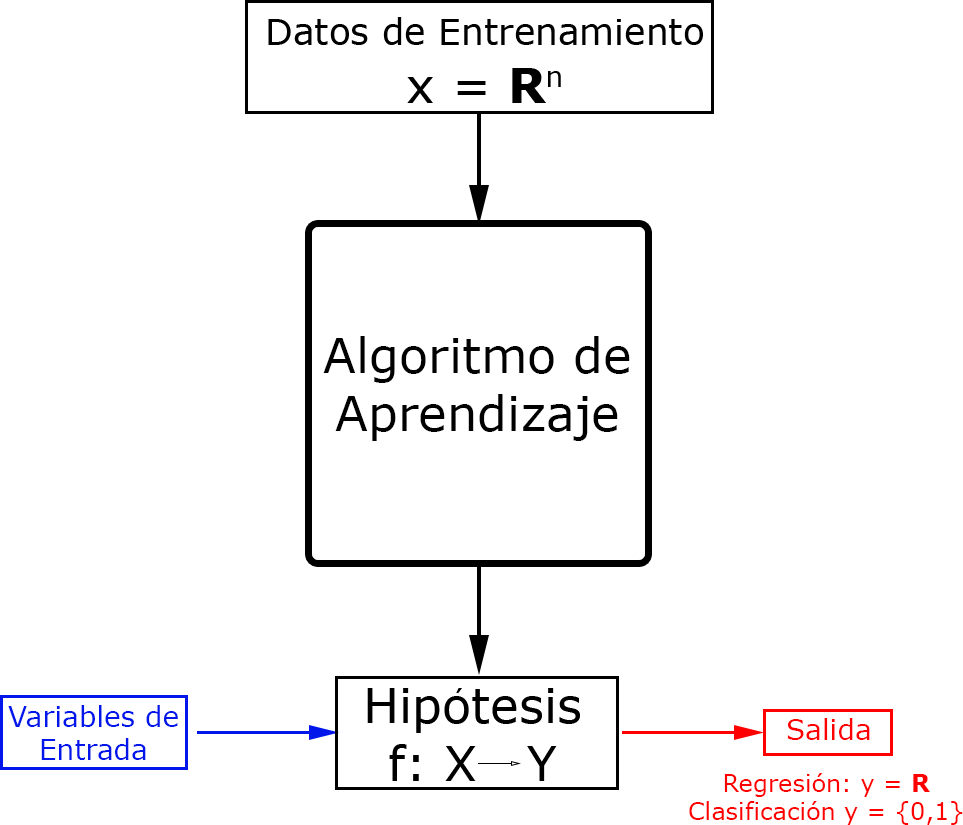 Para que los sistemas aprendan, se ha de tener un conjunto de datos (o data set) de aprendizaje o entrenamiento (datos de entrada y de salida ) que son utilizados para obtener una hipótesis (modelo o función ) que generalice esos datos adecuadamente. Cuando se habla de “generalizar”, se habla de predecir la salida a partir de nuevos datos de entrada (datos de test) distintos a los datos de entrenamiento.
Para que los sistemas aprendan, se ha de tener un conjunto de datos (o data set) de aprendizaje o entrenamiento (datos de entrada y de salida ) que son utilizados para obtener una hipótesis (modelo o función ) que generalice esos datos adecuadamente. Cuando se habla de “generalizar”, se habla de predecir la salida a partir de nuevos datos de entrada (datos de test) distintos a los datos de entrenamiento.
Este proceso de aprendizaje para la obtención de una hipótesis, lo podemos ver esquematizado en la siguiente imagen. En primer lugar contamos con un conjunto de datos que los utilizaremos para entrenar o enseñar al sistema. Aplicando alguna de las técnicas de ML, obtendremos una hipótesis que a priori debería ser la mejor función que se ajusta y generaliza los datos de entrenamiento. Para entender este esquema, supongamos que estamos en el caso de un aprendizaje supervisado (que explicamos en el punto de Tipos de Aprendizaje), en el que para cada entrada de los datos de entrenamiento, conocemos cual va a ser su salida. Por tanto; para obtener la hipótesis en este tipo de aprendizaje, tenemos que obtener una función que se ajuste a esos datos de entrenamiento; o dicho de otra manera, que minimize el “error empírico” que es el error medido tras aplicar la hipótesis a los datos de entrenamiento. Ciertamente lo que interesa es que la hipótesis obtenida tenga el menor error posible con los datos de test, pero se asume que los datos de entrenamiento son una muestra lo suficientemente representativa como para que el error cometido con los datos de test sea similar al error empírico.
En resumen el objetivo de estas técnicas es encontrar aquella función o modelo (hipótesis); dentro de todo el conjunto de funciones o modelos, que mejor se ajusta y generaliza los datos de entrenamiento para aplicarlo a los datos de test y así obtener una predicción, recomendación, clasificación, etc.
Overfitting y Underfitting
Uno de los puntos más interesantes en el ML, es que se haya conseguido un aprendizaje correcto con los datos de entrenamiento, obteniendo una hipótesis capaz de generalizar correctamente los nuevos datos de entrada. Por el contrario, el obtener una hipótesis como resultado de un sobreajuste (overfitting) o sobregeneralización (underfitting) de los datos de entrenamiento, hará que la salida proporcionada con nuevos datos de entrada tenga (muy probablemente) un error muy elevado, lo que quiere decir que la predicción no será correcta.
Para ver el significado más en detalle de overfitting y underfitting, supongamos el caso de nuestro sistema experto para la predicción de quinielas: Sabemos que el FC Barcelona es uno de los equipos más potentes del mundo y obviamente de la liga Española. Por el contrario hay equipos más modestos como puede ser el caso del Rayo Vallecano al que le encajan muchos goles y pierde más partidos de los que gana; pero casualmente en los datos de entrenamiento, tenemos tres resultados en los que el Rayo Vallecano ha ganado al FC Barcelona en su estadio. Por otro lado en la mayoría de los datos de entrenamiento nos encontramos que los partidos de fútbol jugados por el FC Barcelona se saldan con victoria; y a parte, otro dato relevante, es que el 60% de los partidos de los datos de entrenamiento tiene como resultado la victoria del equipo local (resultado = 1). Con estos datos ¿Cuál sería la predicción del resultado del encuentro “FC Barcelona-Rayo Vallecano”?.
Aunque esto sería un resumen de los datos que hay en el conjunto de datos de entrenamiento, una persona (sea o no experta en fútbol) y viendo los datos de entrenamiento, podría predecir que el resultado de este partido sería un “1” (gana el FC Barcelona) ya que el FC Barcelona es: uno de los equipos más potentes, gana la mayoría de los partidos, se enfrenta a un equipo que pierde más partidos de los que gana y además juega en su estadio (60% de los partidos los ganan los equipo locales). Aunque los algoritmos de aprendizaje en ML no tienen la capacidad de hacer estos razonamientos (ya que estos se hacen de forma matemática) si que se espera que el resultado sea coherente y similar al que haría un humano. Pero, ¿Que resultado arrojaría el sistema si se ha producido overfitting o underfitting?:
- Overfitting ("FC Barcelona-Rayo Vallecano = Victoria del Rayo Vallecano”): Como en el conjunto de datos de entrenamiento se ha dado la casualidad de que solo hay 3 datos de enfrentamientos entre estos equipos y son de victorias de Rayo Vallecano; ajustándome a los datos de entrenamiento, digo que gana el Rayo Vallecano porque es la información de la que se dispone.
- Underfitting ("FC Barcelona-Rayo Vallecano = Victoria del FC Barcelona”): Al haber sobregeneralización la hipótesis arroja como resultado que va a ganar el equipo local ya que el 60% de los resultados son victorias de los locales; por tanto, en este caso acertaría el resultado.
- Underfitting ("Rayo Vallecano-FC Barcelona = Victoria del Rayo Vallecano”): Por analogía con el caso anterior; al ser el Rayo Vallecano el equipo local, ganaría el Rayo Vallecano.
Lo que se ha pretendido al explicar este ejemplo tan largo, es que la hipótesis obtenida no tiene porque predecir correctamente el 100% de los casos, pero si que se ha de exigir; en cierta medida, que generalice correctamente aunque esto suponga cometer errores puntuales. Dicho de otra manera, hay que ser capaz de encontrar una hipótesis en la que haya un equilibrio entre el sobreajuste y la sobregeneralización.
Veamos a continuación gráficamente el concepto de overfitting y underfitting para los problemas de clasificación y regresión:
Obtención de un clasificador que aproxime f:R2→{*,x}:
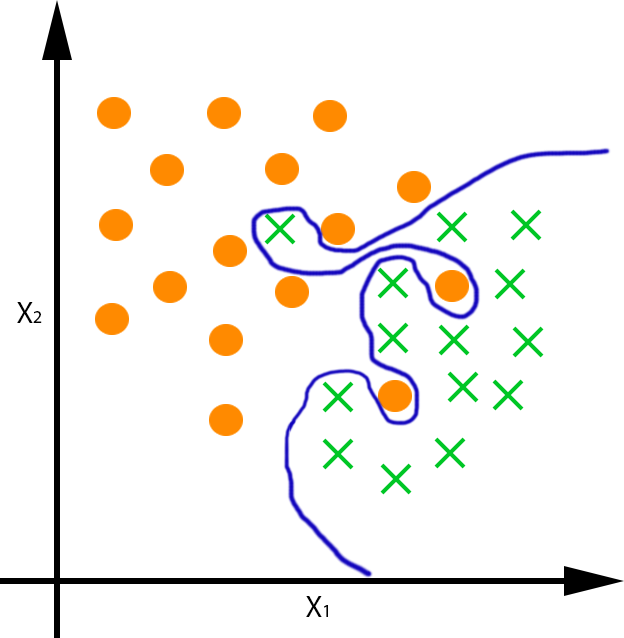
|
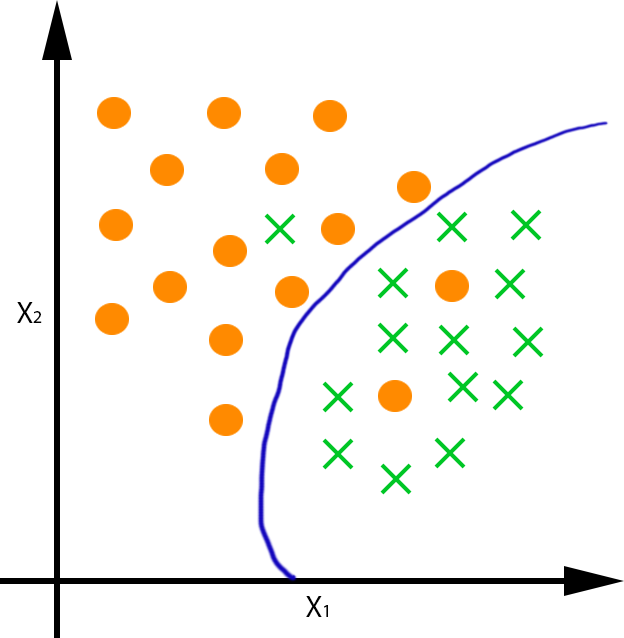
|
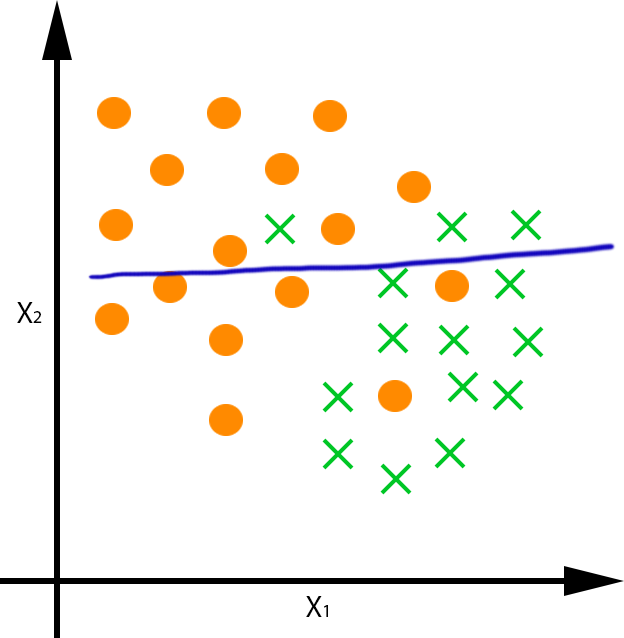
|
| Overfitting | OK | Underfitting |
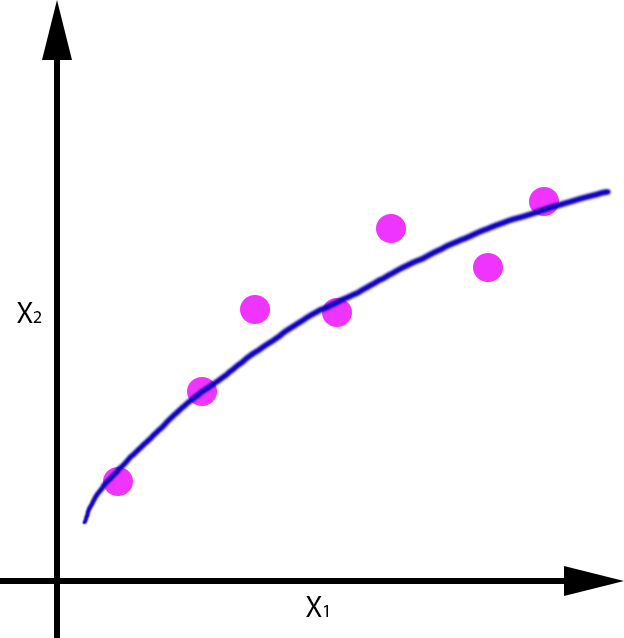
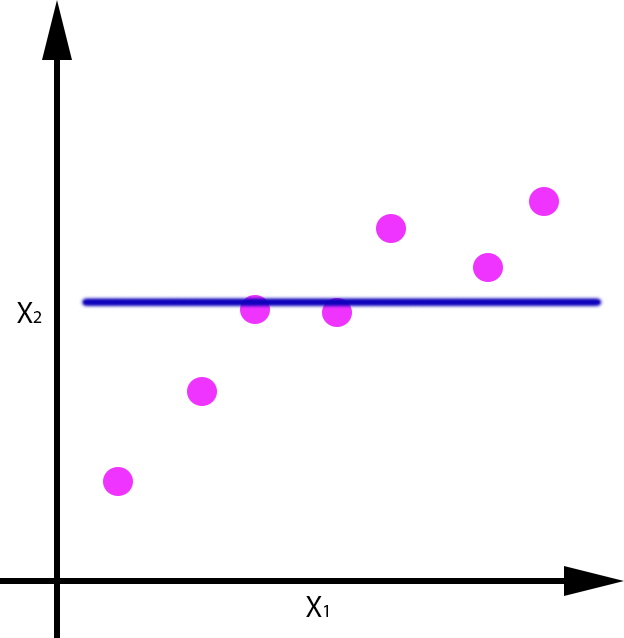
Modelo de regresión que aproxime f:R→R:
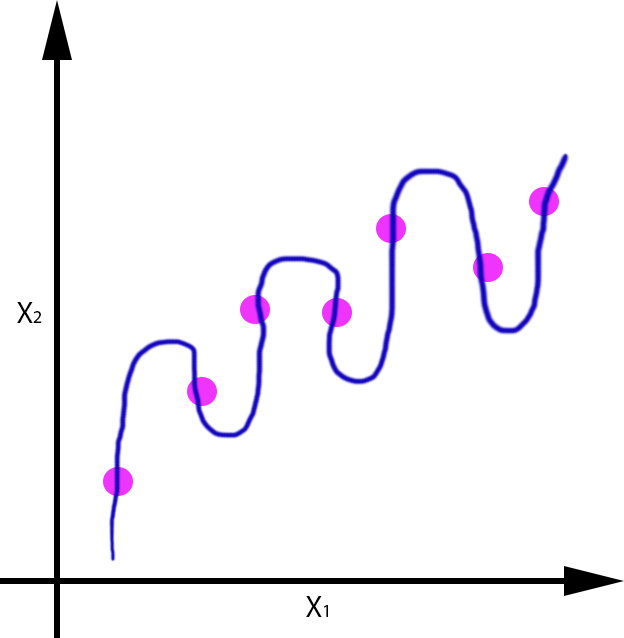
|
|
|
| Overfitting | OK | Underfitting |
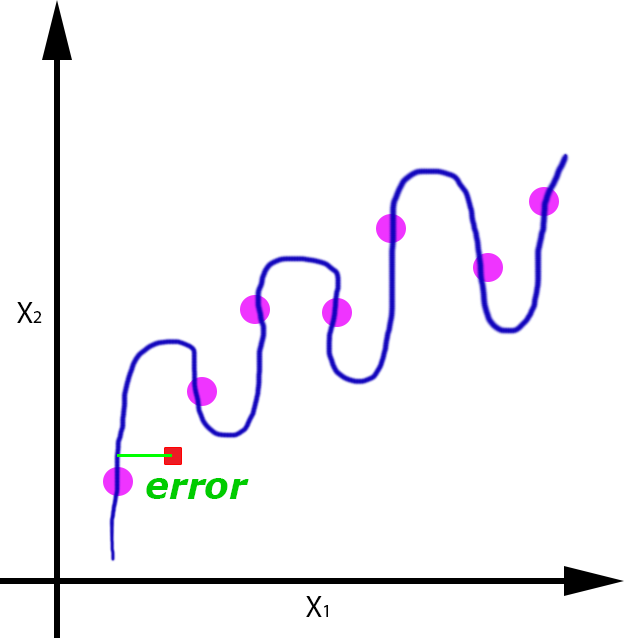
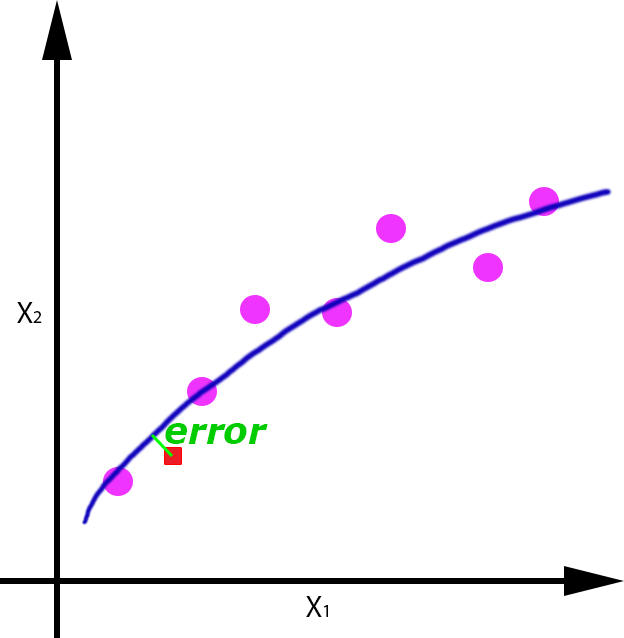
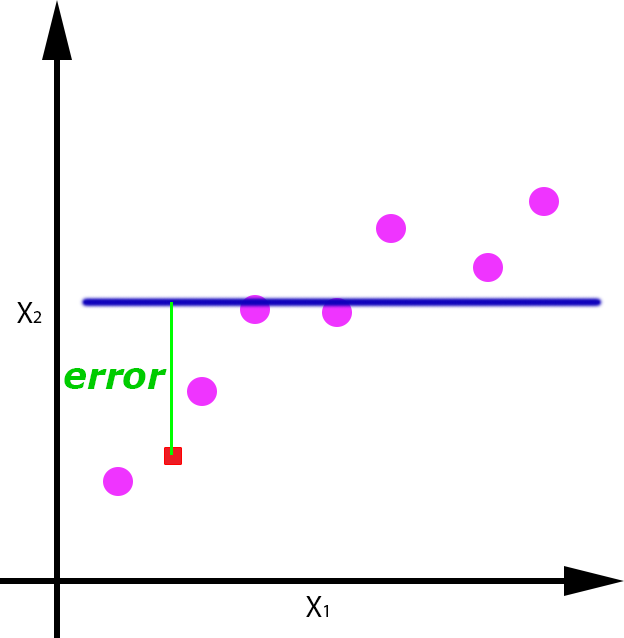
Veamos por ejemplo para el caso de la regresión, el error que se cometería si nos llegase un nuevo dato de entrada (punto rojo), para cada uno de las funciones obtenidas:
|
|
|
| Overfitting | OK | Underfitting |
Se puede apreciar como el error cometido con un dato de test, es mayor en el caso en el que se produce overfitting y underfitting, y es menor en el caso en el que se ha generalizado de forma correcta, aunque evidentemente tiene un pequeño error.
Tipos de aprendizaje
Dependiendo de cómo sean los datos de los que dispongamos para entrenar al sistema, podemos aplicar un tipo de aprendizaje u otro. A continuación se enumeran y explican los tipos de aprendizaje más comunes:
- Aprendizaje supervisado: Tipo de aprendizaje en el que se tiene la información completa de los datos de entrenamiento; es decir, los datos de entrada y la salida de los mismos. Es el tipo de aprendizaje que mejores resultado ofrece ya que es el que más información tiene.
- Aprendizaje no supervisado: Tipo de aprendizaje en el que únicamente se disponen de los datos de entrada y tiene como objetivo el obtener información sobre la estructura del dominio de salida.
- Aprendizaje semi-supervisado: Es un tipo de aprendizaje híbrido entre el aprendizaje supervisado y no supervisado.
- Aprendizaje Adaptativo: Tipo de aprendizaje en el que se parte de un modelo previo cuyos parámetros se modifican o adaptan usando los nuevos datos de entrenamiento.
- Aprendizaje on-line: En este tipo de aprendizaje no hay una distinción concreta entre la fase de test y de entrenamiento. El sistema aprende (normalmente desde cero) mediante el propio proceso de predicción en el que hay una supervisión humana que consiste en validar o corregir cada salida en función de la entrada.
-
Aprendizaje por refuerzo: Tipo de aprendizaje híbrido entre el aprendizaje on-line y aprendizaje semi-supervisado en el que la supervisión es incompleta; normalmente una información del tipo {si,no}, {0,1}, {premio,castigo}. Es un tipo de aprendizaje que se basa en el “argumentum ad baculum”, utilizado normalmente en la educación de los animales.
Métodos de evaluación de un sistema
Para evaluar las hipótesis obtenidas tras la aplicación de alguna de las técnicas de ML, es necesario disponer de un conjunto de datos (etiquetados o no) para generar la mejor de las hipótesis posibles y minimizar el error empírico. Dado un conjunto de datos, podemos enumerar los siguientes métodos de evaluación en función de cómo se dividen los datos de entrenamiento y de test:
- Resustitución: Es un método muy optimista en el que todos los datos disponibles se utilizan como datos de test y de entrenamiento.
- Partición (Hold Out): Este método divide los datos en dos subconjuntos: uno de entrenamiento y uno de test. El problema que tiene este método es que se desaprovechan los datos de test para la obtención de la hipótesis.
- Validación cruzada (Cross Validation): Este método divide los datos aleatoriamente en ‘N’ bloques. Cada bloque se utiliza como test para un sistema entrenado por el resto de bloques. El inconveniente de este método es que reduce el número de datos de entrenamiento cuando el número de datos de cada bloque es grande.
-
Exclusión individual (Leaving one out): Este método utiliza cada dato individual como dato único de test de un sistema entrenado con todos los datos excepto el de test. Es similar al método de la validación cruzada, pero en este caso el coste computacional es muy grande por la cantidad de fases de aprendizaje que se deben de realizar.
Técnicas del Machine Learning
Resulta verdaderamente complejo hacer una jerarquización o clasificación de las técnicas de ML en función de los problemas que pueden resolver; ya que por ejemplo, hay técnicas muy concretas como el K-means o el Expecation-Maximization (EM) que se utilizan claramente para problemas de Clustering y sin embargo técnicas como la de Support Vector Machine (SVM) o incluso las Redes Neuronales pueden encajar tanto en problemas de Regresión como de Clasificación, aunque sean más propias de la clasificación que de la regresión. Independientemente de que cada una de las técnicas pueda ser clasificada de una manera o de otra, lo que si es obvio es que los profesionales del ML deben de preocuparse en aprender correctamente cuantas más técnicas mejor y de esta forma tener una formación lo suficientemente alta como para saber abordar y solucionar los problemas utilizando la/s técnica/s que mejor se puedan adaptar.
A continuación mostramos una clasificación de las técnicas y problemas del ML, utilizando en parte la clasificación propuesta por la Wikipedia Inglesa.
| Problemas | Aprendizaje Supervisado | Clustering |
|
|
|
| Reducción de la dimensionalidad | Modelos Probabilísticos | Detección de anomalías |
|
|
|
| Redes Neuronales | Sistemas de Recomendación | Teorías |
|
|
|

alguien aca ha trabajado con Active Learning?
Muy interesante! Sin embargo, sigue siendo demasiado ambiguo… Claramente un ejemplo haría de este post una verdadera joya.
Saludos
Agustín