Scraping en Java (JSoup), con ejemplos
El proyecto de este post los puedes descargar pulsando AQUI.
El Web Scraping (o Scraping) son un conjunto de técnicas que se utilizan para obtener de forma automática el contenido que hay en páginas web a través de su código HTML. El uso de estas técnicas tienen como finalidad recopilar grandes cantidades de datos de diferentes páginas web cuyo uso posterior puede ser muy variado: homgenización de datos, tratamiento de contenido para la extracción de conocimiento, complementar datos en una web, etc. Decir por último en esta introducción que las técnicas de Scraping se pueden enmarcar dentro de los campos de la Inteligencia Artificial y del Big Data en la primera fase de recolección de datos para su posterior almacenamiento, tratamiento y visualización.
En este tutorial vamos ha "scrapear" (o a obtener los datos) de los articulos y tutoriales de esta página web, utilizando la librería "JSoup" (para Java) que es una libreria que nos facilita muchisimo la labor de scrapeo. La finalidad de este tutorial no es hacer un tutorial para expertos, sino hacer una introducción de como hacer las conexiones HTTP y como tratar y extraer el contenido que nos interesa de los HTMLs que obtenemos con la libreria JSoup. Para este tutorial es necesario que se tengan conocimientos mínimos de HTML y CSS (no hace falta ser un experto) ya que a la hora de scrapear tenemos que tener conocimiento de las etiquetas de HTML como pueden ser head, body, h1, h2, …, h6, p, div, span, table, etc. y de los estilos CSS que se pueden aplicar a estas etiquetas con id y class.
Dadas las directrices y los conocimientos mínimos necesarios para este tutorial vamos a proceder a explicar como scrapear y obtener los datos de las entradas de jarroba.com. En primer lugar vamos a utilizar la libreria JSoup, por tanto nos la debemos importar, bien sea con el ".jar" o a través de Maven. En este caso nos hemos creado un proyecto Maven e importamos el JSoup añadiendo a nuestro fichero pom.xml lo siguiente:
<!-- JSoup --> <dependency> <groupId>org.jsoup</groupId> <artifactId>jsoup</artifactId> <version>1.8.1</version> </dependency>
En segundo lugar, se ha de estudiar la estructura del HTML de la web para ver de que forma podemos extaer su contenido. En este caso en el que queremos extraer la información de cada entrada de este web (título, autor y fecha), podemos ver como todas las entradas están entre etiquetas 'div' con la clase CSS 'col-md-4 col-xs-12'; es decir (tal y como vemos en la siguiente imagen), debemos de obtener el contenido que hay entre "<div class="col-md-4 col-xs-12"> contenido </div>"
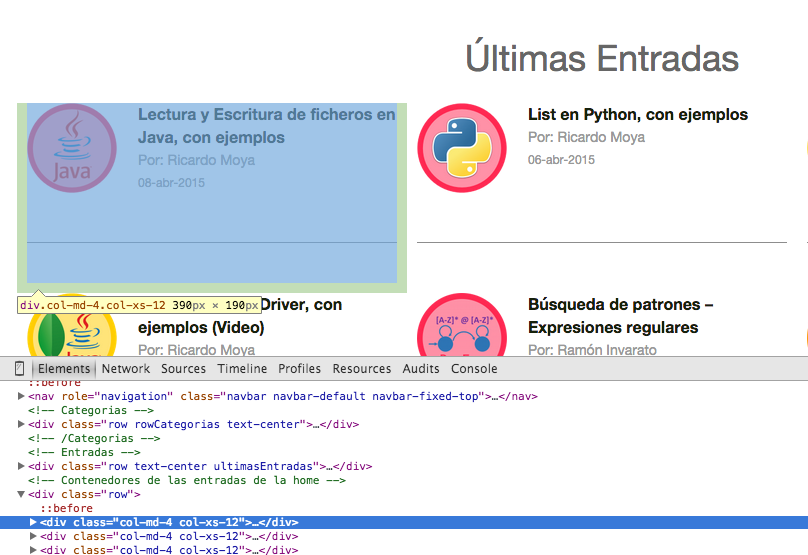
Como podemos ver, puede resultar relativamente sencillo crearse una expresión regular y obtener todas las apareciones que hay entre las etiquetas 'div' con la clase CSS mencionada anteriormente (por cierto son clases de CSS Bootstrap), pero la libreria JSoup ya nos aporta los métodos necesarios (y muy bien optimizados ya que el Patter y Matcher son procesos muy pesados y lentos) para obtener el contenido que hay entre las etiquetas HTML.
Dentro de esas etiquetas, tenemos que seguir extrayendo los datos del título, autor y fecha. Si vemos más en detalle su HTML, vemos lo siguiente:

Por tanto con esto ya hemos hecho un estudio del HTML y ya sabemos a partir de que etiquetas tenemos que scrapear los datos, por tanto vamos a pasar ahora a explicar como hacer el scrapeo con la libreria JSoup.
En primer lugar tenemos que hacer una petición HTTP a la página web para obtener su HTML. Previamente, seria recomendable (aunque no necesario, pero ya de paso lo explico), saber el estado o el "status code" de la petición a esa web. Para ello JSoup tiene los métodos necesarios para darnos el "status code" y a continuación podeis ver un método que dado una url nos devuelve su "status code":
/**
* Con esta método compruebo el Status code de la respuesta que recibo al hacer la petición
* EJM:
* 200 OK 300 Multiple Choices
* 301 Moved Permanently 305 Use Proxy
* 400 Bad Request 403 Forbidden
* 404 Not Found 500 Internal Server Error
* 502 Bad Gateway 503 Service Unavailable
* @param url
* @return Status Code
*/
public static int getStatusConnectionCode(String url) {
Response response = null;
try {
response = Jsoup.connect(url).userAgent("Mozilla/5.0").timeout(100000).ignoreHttpErrors(true).execute();
} catch (IOException ex) {
System.out.println("Excepción al obtener el Status Code: " + ex.getMessage());
}
return response.statusCode();
}
JSoup nos proporciona los métodos necesarios para obtener el HTML de una url; o dicho de otra mamera, hace la petición HTTP dada una url. En el siguiente fragmento de código vemos como dada una url nos devuelve un objeto de la clase "Document" con el contenido del HTML:
/**
* Con este método devuelvo un objeto de la clase Document con el contenido del
* HTML de la web que me permitirá parsearlo con los métodos de la librelia JSoup
* @param url
* @return Documento con el HTML
*/
public static Document getHtmlDocument(String url) {
Document doc = null;
try {
doc = Jsoup.connect(url).userAgent("Mozilla/5.0").timeout(100000).get();
} catch (IOException ex) {
System.out.println("Excepción al obtener el HTML de la página" + ex.getMessage());
}
return doc;
}
La clase "Document" es una clase que guarda el HTML obtenido de una petición y que posteriormente nos servirá para obtener el contenido entre etiquetas HTML y clases CSS.
Por último vamos a pasar a mostrar el código de scrapeo de las entradas de la página principal de Jarroba.com y posteriormente explicaremos sus detalles:
public class Scraping {
public static final String url = "https://jarroba.com/";
public static void main (String args[]) {
// Compruebo si me da un 200 al hacer la petición
if (getStatusConnectionCode(url) == 200) {
// Obtengo el HTML de la web en un objeto Document
Document document = getHtmlDocument(url);
// Busco todas las entradas que estan dentro de:
Elements entradas = document.select("div.col-md-4.col-xs-12").not("div.col-md-offset-2.col-md-4.col-xs-12");
System.out.println("Número de entradas en la página inicial de Jarroba: "+entradas.size()+"\n");
// Paseo cada una de las entradas
for (Element elem : entradas) {
String titulo = elem.getElementsByClass("tituloPost").text();
String autor = elem.getElementsByClass("autor").toString();
String fecha = elem.getElementsByClass("fecha").text();
System.out.println(titulo+"\n"+autor+"\n"+fecha+"\n\n");
// Con el método "text()" obtengo el contenido que hay dentro de las etiquetas HTML
// Con el método "toString()" obtengo todo el HTML con etiquetas incluidas
}
}else
System.out.println("El Status Code no es OK es: "+getStatusConnectionCode(url));
}
}
En primer lugar definimos la url para obtener el HTML de la misma. En segundo lugar comprobamos que el "status code" es igual a 200 y si es así obtenemos en un objeto de la clase "Document" el HTML de la web. Con ese objeto de la clase Document, vamos a poder obtener con los métodos pertinentes de JSoup, los elementos de la web. En este caso vamos a obtener todas las entradas que las guardaremos en un objeto de la clase "Elements" que corresponda a una serie de etiquetas y estilos CSS. En este caso guardaremos todos los fragmentos HTML que correspondan a cada entrada (ver primer imagen de la entrada):
// Obtengo el HTML de la web en un objeto Document
Document document = getHtmlDocument(url);
// Busco todas las historias de meneame que estan dentro de:
Elements entradas = document.select("div.col-md-4.col-xs-12").not("div.col-md-offset-2.col-md-4.col-xs-12");
En este caso utilizamos el método "select" que lo que hace es coger todos los fragmentos del HTML que correpondan a un etique div, seguido de las clases 'col-md-4' y 'col-xs-12'. Dado que en la web hay otro fragmento de código que contiene la clase CSS 'col-md-4', seguido de otras clases y no corresponden a ninguna entra y por tanto no lo queremos seleccionar, le decimos con el método "not", que no nos seleccione ese fragmento de HTML. Ahora ya tenemos en una lista (entradas), todas las entradas en HTML. Ahora debemos de recorrer esa lista y obtener de esos fragmentos de código los datos del título, autor y fecha. De la misma forma esa información esta dentro de etiquetas HTML y clases CSS que debemos de tratar (como se muestra en la segunda imagen de la entrada). JSoup nos da los métodos para obtener el contenido pasandole el nombre de la clase CSS. Esto se hace de la siguiente forma:
// Paseo cada una de las entradas
for (Element elem : entradas) {
String titulo = elem.getElementsByClass("tituloPost").text();
String autor = elem.getElementsByClass("autor").toString();
String fecha = elem.getElementsByClass("fecha").text();
System.out.println(titulo+"\n"+autor+"\n"+fecha+"\n\n");
// Con el método "text()" obtengo el contenido que hay dentro de las etiquetas HTML
// Con el método "toString()" obtengo todo el HTML con etiquetas incluidas
}
Como vemos a los métodos "getElementsByClass" se les pasa el nombre de la clase CSS y te obtiene el contenido que hay entre esas etiquetas. Por último señalar lo que dejo en el comentario del fragmento de código anterior y esque no es lo mismo utilizar el método "toString()" y el método "text()", que este último si que es propio de la libreria JSoup y te da el contenido que hay entre las etiquetas HTML, mientras que el método "toString()" te da el contenido más el HTML. Veamos el resultado de la ejecución del programa para que veais el resultado:
Número de entradas en la página inicial de Jarroba: 9 Diccionario en python, con ejemplos Por: Ricardo Moya 05-may-2015 DataSet de resultados de partidos de fútbol para su predicción (Machine Learning) Por: Ricardo Moya 26-abr-2015 Intalar Ubuntu en una máquina virtual con VirtualBox (Video) Por: Ricardo Moya 15-abr-2015 ............ ............
Esta libreria JSoup, es una libreria muy potente para hacer scraping. En esta entrada hemos visto como hacer una conexión HTTP y obtener el contenido HTML para almacenarlos en un objeto de la clase Dcoument para posteriormente sacar elementos o fragmentos de código HTML (clase Element o Elements si son varios) como si de un parseo con expresiones regulares se tratase pero sin meterse en el "engorro" de trabajar con expresiones regulares. JSoup también tiene métodos para sacar el contenido de etiquetas como los h1, h2, …, p, img, etc. que en este caso no hemos visto en el ejemplo pero que si revisais su javadoc veréis los métodos que permiten hacer esas acciones.
Para terminar dejo el programa que permite obtener todas las entradas de Jarroba.com (título, autor y fecha) y no solo los de la página principal como en el ejmplo mostrado:
package com.jarroba.scraping.Scraping_jarroba_java;
import java.io.IOException;
import org.jsoup.Connection.Response;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class Scraping_allPost {
public static final String url = "https://jarroba.com/page/%s/";
public static final int maxPages = 20;
public static void main (String args[]) {
for (int i=1; i<maxPages; i++){
String urlPage = String.format(url, i);
System.out.println("Comprobando entradas de: "+urlPage);
// Compruebo si me da un 200 al hacer la petición
if (getStatusConnectionCode(urlPage) == 200) {
// Obtengo el HTML de la web en un objeto Document2
Document document = getHtmlDocument(urlPage);
// Busco todas las historias de meneame que estan dentro de:
Elements entradas = document.select("div.col-md-4.col-xs-12").not("div.col-md-offset-2.col-md-4.col-xs-12");
// Paseo cada una de las entradas
for (Element elem : entradas) {
String titulo = elem.getElementsByClass("tituloPost").text();
String autor = elem.getElementsByClass("autor").toString();
String fecha = elem.getElementsByClass("fecha").text();
System.out.println(titulo+"\n"+autor+"\n"+fecha+"\n");
}
}else{
System.out.println("El Status Code no es OK es: "+getStatusConnectionCode(urlPage));
break;
}
}
}
/**
* Con esta método compruebo el Status code de la respuesta que recibo al hacer la petición
* EJM:
* 200 OK 300 Multiple Choices
* 301 Moved Permanently 305 Use Proxy
* 400 Bad Request 403 Forbidden
* 404 Not Found 500 Internal Server Error
* 502 Bad Gateway 503 Service Unavailable
* @param url
* @return Status Code
*/
public static int getStatusConnectionCode(String url) {
Response response = null;
try {
response = Jsoup.connect(url).userAgent("Mozilla/5.0").timeout(100000).ignoreHttpErrors(true).execute();
} catch (IOException ex) {
System.out.println("Excepción al obtener el Status Code: " + ex.getMessage());
}
return response.statusCode();
}
/**
* Con este método devuelvo un objeto de la clase Document con el contenido del
* HTML de la web que me permitirá parsearlo con los métodos de la librelia JSoup
* @param url
* @return Documento con el HTML
*/
public static Document getHtmlDocument(String url) {
Document doc = null;
try {
doc = Jsoup.connect(url).userAgent("Mozilla/5.0").timeout(100000).get();
} catch (IOException ex) {
System.out.println("Excepción al obtener el HTML de la página" + ex.getMessage());
}
return doc;
}
}

No me deja ejecutar el codigo en consola, ni cuando lo hago en un .jar
Buenas Oscar.
¿Qué error te sale?
Buenas, queria saber porque en ciertas paginas si funciona hacer esto (Esta) y en otras no.
Muchas gracias
Para que funcione la configuración debe ser correcta y que lea bien el código de la página. Por otro lado, algunas páginas están protegidas contra este tipo de técnicas.
Recuerdo que no en todas las páginas está permitido hacer scraping se pueda o no.
excelente el tutorial me sirvio, te dejo una consulta si extraes un precio de una pagina con el siguiente formato – ejemplo «$3500», al extraerlo como lo transformas a un tipo de dato numérico? muchas gracias
Buenas Charly.
Podrías obtener el número con una expresión regular (ejemplos en Java en https://jarroba.com/busqueda-de-patrones-expresiones-regulares/) y de ahí convertirlo a entero.
Hola Jarroba, necesito hacer un post, a una pagina para logearme, pero el formato de los datos son JSON, y por mas que el .data(«FORMATO JSON»), me da error y no logra entrar. ¿Alguna idea de porque no puedo logearme? CUando no es JSON el formato de los datos del login, lo hago sin ningun tipo de problema.
Gracias, un saludo
Gracias Jarroba, sois de gran ayuda!
Hola buenos noches estoy trabado de extraer datos de sitio tripAdvisor pero el problema esque no puedo extraer los datos de todas las paginas ya que esta de la siguiente manera ayuda por favor ..
1
Hola Luis, y como puedo hacer para usar la imagen en este caso la imagen de tu mismo ejemplo que usas
Hola, ¿qué tal? me esta siendo de mucha ayuda tu ejemplo de scraping, me ha funcionado leyendo datos de otra página sin problemas, esto lo estoy empleando en una app que estoy haciendo con android studio.
Pero el tema es el siguiente: mi app tiene varios botones, se conecta a la página de la tienda Ripley en Perú. Un botón debe obtener por ejemplo los datos de los televisores que tienen en tienda por marca, el segundo boton por función, etc. si apreto el primer botón me muestra los datos, pero si apreto el segundo botón ya no me muestra nada, imprimo en terminal la página web que debería estar leyendo, y esta es la correcta, ya que la copio y pego en mi explorador y muestra lo que debe mostrar, pero lo que obtengo como respuesta de response.statusCode () es 400, sabes ¿cómo puedo solucionar esto, o qué puede estar pasando? Gracias
Estimado como se puede hacer si la pagina enmascara la direccion no se ven los parametros
Los parámetros de las URL no se pueden ocultar, si acaso se estarán mandando por POST (se envían en el cuerpo) y no por GET (se envían en la URL), pero los parámetros tienen que estar en algún sitio. Más información en: http://jarroba.com/cliente-servidor-peticion-del-cliente/
Hola…muy bueno el tuto, si qisiera scrapear una pagina con login.?? Coml haria en ese caso…?
Hola Ricardo, estoy intentando hacer Scraping de mis datos de la web de Zara, para hacerme una app que me avise cada vez que compro algo.
Intento hacer el login instantaneo y no lo consigo.¿podrías ayudarme?
Hola conseguiste realizar el login? con los datos de la pagina que son en JSON?
ha "scrapear"(o a obtener los datos)No queda muy bien , me imagino que querías decir "a scrappear" …
Muchas Gracias por su aportación … excelente
GRacias me gusto mucho el post!!
solo tengo una duda ¿porque el url asi:
http://jarroba.com/page/%s/
?
Entiendo que mas adelante en el codigo haces un for para aumentar el numero de las paginas pero no veo en que momento cambias %s por el numero.
De antemano gracias!!
Hola Luis,
Me imagino que ya es tarde y sabrás la respuesta, pero aún así voy a contestar por si acaso te ayuda.
Fíjate en que, justo debajo del bucle "for", utiliza el método String.format. Este método sirve para construir Strings con parámetros.
En esta cadena introduce "%s" para que el método String.format() sepa que ahí tiene que añadir un String.
String url = "http://jarroba.com/page/%s/";
En esta linea, en cada iteración, sustituye %s por el valor de i y crea la url completa.
String urlPage = String.format(url, i);
Un saludo