Los trucos del Streaming: generadores, buffer y caché
El Streaming es bastante sencillo si sabemos jugar con las diferentes estructuras de datos.
Por simplicidad lo más común es utilizar listados para mantener en memoria conjuntos de datos y luego recorrerlos para utilizarlos uno a uno. Imagina que el listado ocupa muchísimo, tanto que lo podríamos llamar “Big data” (por ejemplo varios Gibibytes o Tebibytes en el mismo listado; más información en de las unidades de medida de la información en https://jarroba.com/unidades-medida-la-informacion/ ) puede que no tengamos suficiente memoria RAM (memoria principal) para soportar tal tamaño de listado. U otro caso, puede que nos vaya llegando de Internet varias líneas de datos, y entre cada línea de datos pase un tiempo (unos segundos, por ejemplo) hasta que nos llega la siguiente línea, por lo que esperar a que lleguen todas las líneas para procesarlas es perder el tiempo; sería maravilloso poder procesar cada línea de datos cuando llegue sin tener que esperar al resto, es lo que llamamos “Streaming de datos” (o “flujo de datos”, aunque se suele utilizar la palabra inglesa “Stream” para designar el “flujo”) ¿Y la solución? Los “generadores” (podríamos llamarles los creadores del “Streaming de datos”).
Al empezar a programar, se suelen utilizar estructuras de datos simples como listados (puede que los conozcas como “arrays”) para guardar los datos, como un listado de líneas de texto, números, etc. Estas estructuras de datos (los listados) consumen memoria y se tienen que rellenar antes de obtener los datos (Utilizo una representación similar al artículo de multitarea que recomiendo repasar previamente https://jarroba.com/multitarea-e-hilos-facil-y-muchas-ventajas/).
En el siguiente ejemplo mostraré momentos temporales diferentes (un momento temporal por cada imagen a modo de comic).
Desde algún sitio como Internet (o incluso desde otra función, o desde el proceso de otro listado) nos llegan datos que procesamos previamente (por ejemplo, comprobando que los datos descargados de Internet no contengan errores) y los guardaremos en un listado (los datos se guardan como “elementos” de un “listado”) que ocupan espacio de memoria; y habrá alguien que espere consumir esos datos (podría ser otro servidor de Internet, otra función u otro listado mismo).
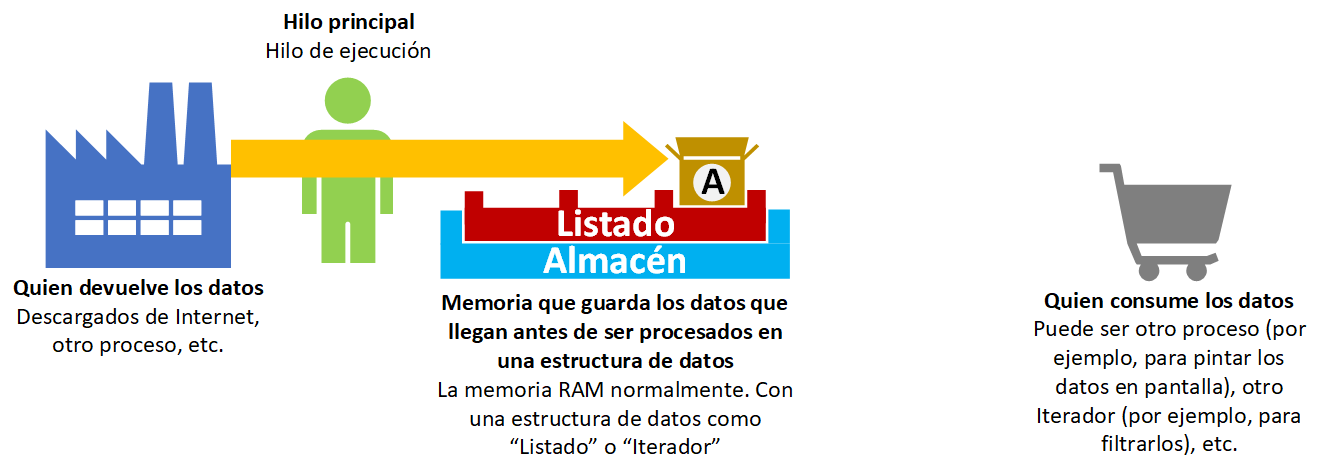
Nos siguen llegando datos que procesamos y los vamos guardando en el listado, ocupando más memoria.

¿Acaso no se puede en un listado añadir un único elemento en una posición y luego leer dicha posición? Sí, existen trucos, pero muchas veces un listado es necesario y otras veces no. Además, con una variable nos bastaría (no haría falta un listado) pues la lectura del programa es lineal. De cualquier manera, la posición del listado con el elemento guardado ya está ocupando memoria antes de ser obtenido (es decir, que, si el elemento se guarda y dentro de una hora se lee, esa memoria está ocupada durante una hora). Sin embargo, como veremos más adelante, un generador directamente crea y devuelve un elemento en el momento de ser obtenido.
Sea como sea, si necesitamos un listado es más óptimo procesar todos los datos, rellenar el listado y luego leer los datos en un bucle. Así que continuamos procesando y rellenando el listado hasta que nos dejen de llegar datos.

Cuando tengamos los datos deseados en el listado, podemos proceder a procesarlos (por ejemplo, en un bucle) para entregarlos a la siguiente parte del programa (como a la siguiente línea de ejecución del programa que puede ser otra función “set(listado)”, como en el retorno de una función “return listado”, etc.).

Como vemos, el listado puede ocupar mucho en memoria. Además, hay que esperar a rellenar el listado de datos procesados para poder iterar u obtener cualquiera de sus datos para luego entregarlos.
Generador
La gracia del generador es precisamente que se encarga de “generar” los datos como si fuera un “listado” pero no los mantiene en memoria.

Genera el dato y lo entrega. Por ejemplo, descarga el dato de Internet y comprueba que no tenga errores (lo genera en la anterior imagen), para inmediatamente obtener el dato generado y utilizarlo por ejemplo imprimiéndolo por pantalla.

El generador se comporta “como” un listado, pero sin guardar en memoria y sin tener que esperar a procesar el listado entero.

De esta manera obtenemos datos finales de una manera muy rápida y con un consumo mínimo de memoria.

Por tanto, un “generador” y un “listado” ambos son “iterables”.
Iterable
Aunque ya he puesto alguna diferencia, quiero dejar bien claro que un “generador” NO es un “listado” (un “generador” puede generar un listado o no; esto lo indico porque cuando programes un “generador” se va a usar igual que un listado, y cuando imprimas el resultado del “generador” vas a ver que devuelve los elemento igual que un listado y no es un listado). Y “generador” es un “iterable” pero no al revés (“iterable” es la base del “generador; es como la “suma” que es la base de la “multiplicación”, pero no es la “multiplicación” es la base de la “suma”); “iterable” y “generador” no hay que confundirlos.
Un “Iterable” es aquel objeto que se pueda iterar (que se pueda recorrer en un bucle), por ejemplo:
- Los elementos de un “listado” (List)
- Cada grupo de clave y valor de un “diccionario” (Dict)
- Los elementos de un “conjunto” (Set)
- Las letras de un “texto” (String)
- Las líneas de un “fichero” (File)
- Un “generador” (generator) de elementos
- Un objeto de una clase que creemos nosotros y que sea iterable (por ejemplo, podríamos crear nuestro propio objeto que se comporte como un listado, pero que solo devuelva las posiciones pares de los elementos añadidos).
¿Y una función asignada a una variable?
Una función es la estructura de datos que devuelve. Es decir, si devuelve un listado pues se comportará como un listado, si es otra “cosa” pues como la “cosa” que devuelva.
Caché
Si ya tenemos el listado con los elementos procesados previamente, obtenerlos del listado es muy rápido, pero con el consecuente consumo de memoria.

Sin embargo, el generador genera cada dato en el momento de ser demandado, por lo que tarda más en devolver cada dato. Gracias a esto ocupa muy poca memoria, ya que solo ocupa el tamaño de dato devuelto.

Una solución intermedia para consumir la mínima memoria y que la devolución sea más rápida es jugar a mezclar las estructuras de datos. Así, por cada dato procesado por el generador, si lo guardamos en una estructura como un listado (o un diccionario, dependerá de las necesidades) que llamaremos “memoria caché”. La “memoria caché” es la estructura que guarda un dato ya procesado para devolverlo en futuras peticiones de manera inmediata. La gracia es que quien pide el dato no sabe quién se lo devuelve (si el generador o el listado), le da igual quién se lo devuelva, solo quiere el dato; pero cuanto antes y de la manera más óptima mejor.

La “memoria caché” se irá llenando de datos, lo ideal es que tenga un límite para que no nos llene la memoria RAM (sino estaríamos en el mismo caso que en el listado simple). Cuando se genere un nuevo dato, al guardarlo y no caber en la “memoria caché” habrá que hacerle espacio. Los datos que se borrarán de la “memoria caché” dependerán de la política de limpieza que necesitemos, por ejemplo:
- Borrar el dato más viejo (FIFO, de “First In First Out”, en español “El primero en entrar es el primero en salir”, es decir, una “cola” típica).
- Borrar el dato que hace más tiempo se haya solicitado (LRU, de “Last Recentrly Used”, el “Menos usado recientemente”).
- Borrar el dato que menos veces se hayan solicitado (LFU, de “Last Frequently Used”, el “Menos usado frecuentemente”).
- Borrar un dato aleatorio.
- Borrar el dato que cumplan ciertas condiciones (por ejemplo, que el propio dato tenga una fecha de caducidad).
La política de limpieza de la “memoria caché” hay que pensarla bien. Por ejemplo, si la política es “Borrar los datos más viejos” y se borra un dato que se solicita mucho, entonces habrá que volver a generar dicho dato muchas veces, por lo que no será muy óptimo. O al revés, si la política es “Borrar los datos que menos se hayan solicitado”, si todos los datos se piden con la misma frecuencia (supongamos que se piden un número exacto de veces, como diez veces), los que lleguen a la “memoria caché” un poco más tarde estarían borrándose prácticamente nada más entrar y se van a pedir las mismas veces que el resto, por lo que no seríamos justos con los nuevos datos al favorecer a los más antiguos (que si ya se han pedido las diez veces que hemos puesto de ejemplo, ya no se volverán a pedir nunca y estarían ocupando espacio inútilmente).
Streaming (Buffer)
No sé si estás familiarizado con la palabra “Stream” (“Flujo”), aunque seguramente lo has escuchado en decenas de ocasiones sobre todo con vídeos o videojuegos en internet. Resumido “Stream” es tener un dato, procesarlo y entregarlo (se guarda en memoria principal el valor del dato a devolver y se descarta al entregarse; después quien lo recoja podrá guardarlo en memoria principal por ejemplo al meterlo en un listado, o no guardarlo por ejemplo al imprimirlo por pantalla); NO es “Stream” esperar a tener un listado de datos, procesarlos todos uno a uno, y devolver un listado con todos los datos procesados (lo que guarda mantiene en memoria principal el listado entero para devolverlo).
Para entendernos con los “vídeos en Internet”, “Stream” es poder ver el vídeo sin tener que esperar a que descargue entero (como hacen plataformas como YouTube o Netflix), y NO sería “Stream” descargar el vídeo entero para luego poder verlo (por ejemplo, si se descarga un vídeo comprimido hay que descargarlo entero, no vale descargar un trozo para poder verlo, una vez descargado entero hay que descomprimirlo y luego se puede ver).
Sabemos que un “generador” genera un flujo ininterrumpido de datos (Stream de datos). Pero no es un “Stream” ideal, pues nadie quiere ver un vídeo de YouTube a cortes, porque si solo utilizara el generador, si se corta la conexión a Internet durante un segundo el vídeo se nos pararía ese mismo tiempo, hasta que volvamos a recibir datos que procesar y entregar.
Para hacer las cosas bien, necesitamos almacenar los datos (el llamado “buffer”) cuando tenemos la oportunidad, y así si se nos corta la conexión a Internet, que el generador vaya tirando del almacén de datos mientras el almacén de datos espere a que la conexión a Internet esté otra vez disponible (es por esta razón, por la que en algunos reproductores de vídeo o audio online pone algo así como “almacenando en buffer”).
El buffer es un almacén de datos intermedio alimentado por uno o varios procesos y consumido por uno o varios procesos (en esta definición he utilizado «procesos», porque cada proceso tiene como mínimo un hilo propio; podrían ser «hilos dentro de un mismo proceso» en vez de «procesos separados»). Lo ideal es añadir un generador que obtenga los datos del buffer siempre que tenga, y que espere si no tiene. Esto además es mejor hacerlo con dos hilos para brindar velocidad, que un hilo se encargue de guardar cosas en el buffer, y el buffer siendo un generador permitirá iterar sobre los elementos del mismo buffer.
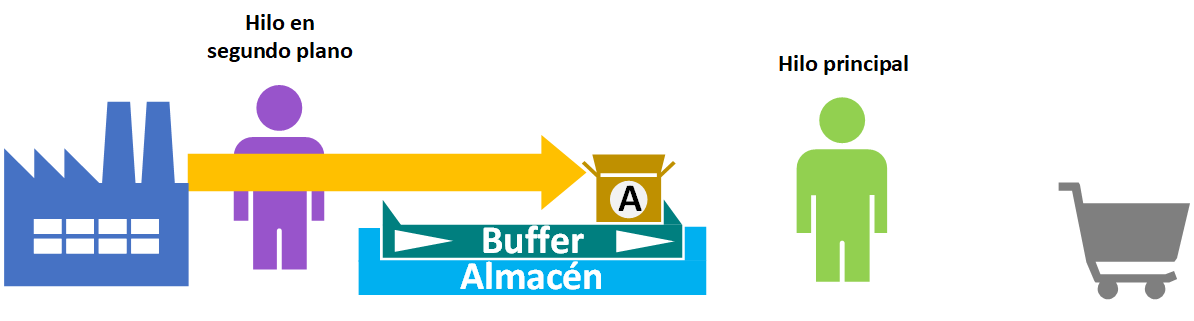
De este modo, si por lo que sea el hilo que guarda en el buffer es más rápido que el itera (con el generador) por los datos del buffer, habrá más datos guardados disponibles en el buffer para una futura obtención sin interrupciones.
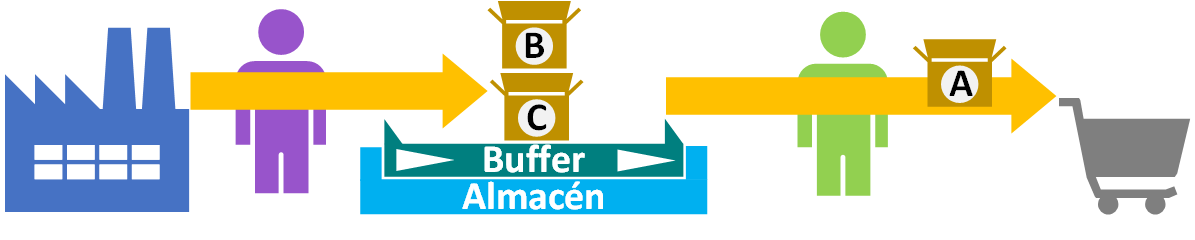
El hilo del buffer puede terminar de guardar datos en el buffer o que haya habido un problema (como un corte de conexión de Internet) y que no tenga datos que seguir guardando. Sea como sea, no habrá interrupción en la generación de datos para el consumidor de datos (por ejemplo, no se detendría la impresión de los fotogramas en la pantalla de la persona que está viendo un vídeo en YouTube) desde el buffer porque ya había datos guardados previamente para evitar esto.

Si después se sigue guardando datos en el buffer, el hilo que los obtiene del generador ni lo notará.

Eso sí, si se termina de enviar datos habrá que enviar una “señal de Fin” (En inglés “Signal”) para que el proceso que obtiene los datos del buffer (con el generador) sepa que ya no van a existir más datos nunca más después del último (por ejemplo, para que el programa reproductor que visualiza un vídeo muestre al usuario que ya ha terminado de reproducir el vídeo; o si es un programa de música si una canción ha terminado sepa cuando puede pasar a la siguiente canción). Evidentemente, la “señal de Fin” no se entregará, es solo para uso interno del consumidor de datos del buffer (para que sepa cuando se han consumido todos los datos de buffer realmente). Sino se manda esta señal, el hilo consumidor de datos del generador nunca sabrá cuándo acaban los datos pues pensará que se están retrasando y quedará esperando (por ejemplo, sino recibe la “señal de Fin”, pensará que se ha vaciado el buffer de un vídeo que estábamos viendo y el vídeo se ha quedado a medias, por lo que esperará por los siguientes fotogramas).
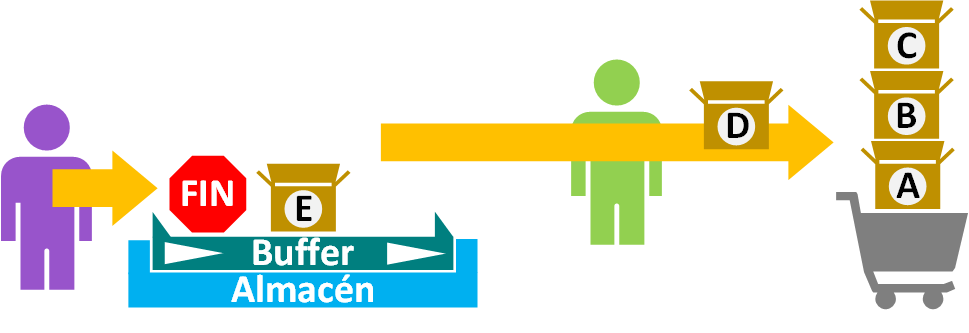
¿Cuál es la “señal de Fin”?
La que queramos. Algunos ejemplos:
- Si los datos enviados por el buffer son tipo “String”, podríamos poner un texto como “señal de Fin” por ejemplo: “=#=Esto es la señal de fin=#=”. Tiene un problema este método, que es ¿Qué pasa si nos mandan ese mismo texto desde Internet? Pues que el hilo que recoge los datos generados pensará que es el fin y ya no pedirá más ¿Viene bien alguna vez? Sí, si sabemos al 100% que nada puede introducir el mismo texto que pongamos como “señal de Fin”.
- Usar el valor “Nulo” (“None” o “Null”) como “Señal de Fin”. Si siempre llegan datos con valores, el valor “Nulo” no es un dato que se pueda repetir, por lo que es perfecto como “señal de Fin” ¿Y si nos mandan un “Null” desde Internet? Primero hay que estar seguros que nos pueden llegar valores Nulos, en caso de que nos llegue hay que ver que no sea el texto «Null» (es decir, las letras «N» «u» «l» «l» seguidas, dando la sensación que es el valor Nulo, pero realmente es un String) o «None»; sino, todavía nos quedan más opciones.
- Si se programa en un lenguaje débilmente tipado (como Python) o usando tipos de datos que permitan múltiples tipos (como en Java, tipando con Object o <?>), podemos utilizar otro tipo de datos diferente para enviar la «señal de Fin». Por ejemplo, si los datos del buffer son de tipo texto, si mandamos un número entero como «señal de Fin», el hilo que consume tendría que preguntar si el valor del dato es instancia de Texto o número entero para interpretar si es dato o «Señal de Fin». No es la mejor opción, es muy poco eficiente, es mejor la última.
- Usar otra vía que no sea el mismo buffer para enviar la “señal de Fin”. Si las anteriores soluciones más inmediatas no son buenas, siempre se puede utilizar otra variable compartida entre los hilos (como, por ejemplo, otra canalización entre hilos como puede ser “Pipe”) para enviar una “señal de Fin”. El hilo que consume los datos del buffer al recibir la “señal de Fin” sabrá que cuando consuma el último dato del buffer ya no habrá más. En este caso se tienen que dar dos condiciones para que este hilo se detenga: que este hilo consuma todos los datos del buffer, y que le llegue la “señal de Fin” desde el hilo que añade datos al buffer.
En siguientes artículos mostraremos ejemplos con código real que funciona.
Otro ejemplo a favor del Streaming
En el ejemplo anterior se ha hecho hincapié en no tener que esperar por datos que llegan desde Internet. Igualmente podemos aplicar Streaming en el procesamiento de datos propios.
Un ejemplo, imagina que tenemos infinitos datos (un número extremadamente grande de datos) en varios discos duros; es decir, tenemos tantos datos que no caben todos juntos en la memoria RAM de tu ordenador. Nuestro objetivo, o porque nos apetece, es obtener los datos que contengan la palabra «pastel», por ejemplo. Quiere decir que vamos a tener que ir mirando de dato en dato de los discos duros buscando la palabra «pastel», y mirar cada dato requiere copiarlo a la memoria RAM. Para hacer esto nos plantearemos alguno de los siguientes casos:
- Buscar y esperar a guardar todos los datos que contengan «pastel» en un listado para devolverlo no es viable, pues nos quedamos sin memoria principal (recuerda que tenemos infinitos datos, aunque sean menos datos los que contengan la palabra «pastel» que el total, lo más probable es que no quepa en memoria RAM).
- Un generador solo, sin buffer entre medias, es ineficiente porque cada vez que se pide un dato que contenga la palabra «pastel» es el justo momento cuando se realizar la búsqueda por alguno de los datos con la palabra «pastel», deteniendo el programa hasta que se encuentre alguno.
- Un hilo o proceso en segundo plano que guarde los datos que contengan la palabra «pastel» en un buffer generador para que otro hilo consuma los datos con la palabra «pastel» cuando quiera. Si hay datos en el buffer los consumirá de inmediato, y si no los hay le tocará esperar al consumidor (como en el anterior punto). Pero si hay datos y toma uno podrá trabajar con este dato mientras el buffer se va llenando. En comparación con el anterior punto, no se tendrá que detener el consumidor a esperar a que se genere el dato mientras haya datos en el buffer.
Programar Generadores en Python
Para aprender el uso de los Generadores en Python y como se programan, dedicamos un artículo detallado pinchando aquí, con trucos y todo lo que se necesitas saber acerca del Streaming de datos.

hola, interesante, queria hacer un streaming de datos desde un arduino con esp8266, podrian enviarse todas las señales o datos en crudo y luego en un servidor tener un programa ya sea en python o c++ que recoja las señales las organice e imprima en pantalla sin almacenar nada en la memoria de el microcontrolador?
seria muy bueno un ejemplo de codigo para saber mas que nada como abordar el problema del streaming y los datos, gracias por la info.
Para hacer Streaming por Python puedes o bien crear o bien un iterador (más información y ejemplos en https://jarroba.com/nuestra-propia-coleccion-en-python/) o un Generador ().
Para conectar al servidor puedes utilizar los ejemplos que vienen en la documentación de Arduino: https://www.arduino.cc/en/Reference/ServerBegin y otros ejemplos en el foro .
Hay varias maneras de hacer esto; la más fácil que se me ocurre es que en el servidor podrías enviar la información a un fichero (o base de datos que no son muy difíciles de crear), luego organizarla con python (en tiempo real, cron, en tiempo real, como necesites) y volcarla a otro fichero para leerla con una web HTML (o una APP de móvil, o con lo que necesites).