Tablas Hash (o Tabla de Dispersión)
¿Cómo funcionan las "Tablas Hash", o "Tablas de Dispersión" (o en ciertas estructura de programación también llamado "Diccionario de Datos")? Te vamos a desvelar el secreto (podría decir el "secreto mejor guardado", pero no, es de dominio público, así que muy bien guardado no es que esté 😉 ) de una manera sencilla, a la vez que ágil, y sin código, aquí en Jarroba.com, cuál es el funcionamiento de una Tabla Hash (y que se puede aplicar a código muy fácilmente, al final daré unos ejemplos para los interesados en su aplicación práctica).
¿Nunca te has preguntado cómo busca un buscador online (Google, Bing, Yahoo, etc) tan deprisa? O, ¿Cómo encuentra el buscador de un sistema operativo (Windows, Linux, iOS, Android, etc) tan rápido cualquier fichero cuando escribimos una palabra? O, incluso ¿Cómo encuentran la información tan deprisa los más nuevos asistentes personales (Cortana, Google Now, Siri, Sherpa, etc)?
No sé si te habrás fijado que a veces aparece “indexando” en el buscador del sistema operativo (suele aparecer recién formateamos un ordenador, o se han añadido muchos ficheros nuevos), y en ese momento la búsqueda se hace muy lenta; pero cuando no pone “indexando” la búsqueda es inmediata de cualquier cosa en nuestro ordenador.
Esto es por qué este “indexado” lo que hace es crear las “tablas Hash”, las rellena con la información de los ficheros contenidos en el ordenador, como veremos a continuación. La “indexación” suele ser bastante compleja, tanto como lo hayan querido hacer de complejo el creador de la misma “indexación” (no será igual a como lo haga Google, a Microsoft, a Apple, entre otros); podría complementarse con otra estructura de datos como los árboles (algunos son árboles B, B+, o B*), utilizar la nube para obtener datos pre-calculados, etc.
Nota sobre las marcas antes citadas:
Primero, los ejemplos antes citados son los que se me han pasado por la cabeza, ni recomiendo ni dejo de recomendar ninguna marca o producto, tampoco nos patrocina ninguno. Segundo, que evidentemente cualquiera de los productos antes citados, como el buscador Google o Windows, harán uso de algoritmos extra; y, al utilizar algoritmos privados o secretos, no sabremos a ciencia cierta si utilizan tal cual las “tablas Hash” o alguna variante de la misma, pero lo suponemos para el ejemplo pues es bastante probable.
Veamos el funcionamiento de las tablas Hash con un ejemplo casi real. Supongamos que tenemos la siguiente función Hash: “contar el número de letras de una palabra”
Nota sobre el nivel de este artículo:
Si quieres profundizar más sobre Hash te recomiendo que eches un vistazo al artículo sobre códigos Hash, donde lo explicamos con todo lujo de detalle con una lectura ágil. También indicar que este artículo de "Tablas Hash" pudiera requerir que tuvieras antes de continuar unas nociones básicas sobre códigos Hash (digo "pudiera requerir" pues lo considero que sin entender del todo Hash se puede entender en gran parte, pero también indico que no se le sacará del todo partido sino se conoce qué son y como funcionan los códigos Hash en una visión más amplia; es decir, si te suena a chino este artículo, lee antes el artículo de códigos Hash para entenderlo todo, no tardarás más que unos minutos y ya estarás de vuelta a este artículo).
Nota sobre la función Hash del ejemplo:
Como hemos visto hay funciones Hash más complejas, la que utilizo para este ejemplo es muy sencilla y provoca muchas colisiones; podría haber escogido algo más complejo como asignar a cada letra del abecedario un número y que la suma sea el código Hash, o directamente utilizar funciones Hash como MD5 o SHA2. Pero para el ejemplo y las imágenes quedaría horrible para entenderlo de un simple vistazo.
Las “Tablas Hash” son un tipo de “Estructura de datos”. “Estructura de datos” pues sirve para clasificar los datos y poder acceder a ellos, buscar, ordenar o modificar de una forma mucho más óptima que haciéndolo de otro modo. Veamos un ejemplo paso a paso.
Nuestro ordenador tiene varios ficheros con un nombre por el que queremos buscar rápidamente (en un ordenador también se busca por metadatos internos, fecha, tipo, etc; aquí no lo complicaré, solo por nombre, pero puedes extrapolarlo a algo más complejo). Estos ficheros tienen de nombre:
- Foto
- Presentación
- Novela
- Factura
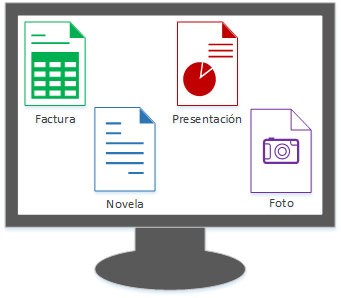
Cada uno de estos ficheros reside en memoria del ordenador (En el disco duro, sea un disco duro de plato o SSD; o incluso puede estar en RAM, u otros tipos de memoria como la caché). En la imagen la memoria la representaré como memoria RAM (por ser más directo para entender que en un círculo que podría ser un plato, y por parecerse a como guardan los datos un disco SSD; de cualquier manera, la idea es la misma), aunque podría ser un disco duro; una memoria dividida en 64 direcciones de memoria.
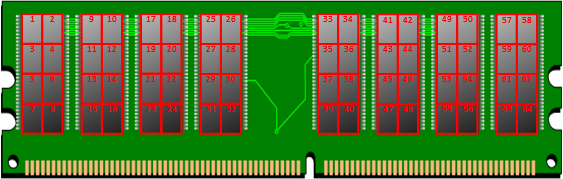
Como curiosidad, cada dirección de memoria suele ser de 32 bits (dependerá de lo que quiera el fabricante y lo que el sistema operativo sea compatible, sino no funciona). Aunque en el ejemplo de la imagen no utilizaremos el tamaño de cada dirección de memoria, pero que sepas que está ahí siempre sea el tamaño que sea. Por ejemplo, supondremos que los ficheros anteriores ocupan:
- Foto: 6 direcciones de memoria
- Presentación: 4 direcciones de memoria
- Novela: 2 direcciones de memoria
- Factura: 4 direcciones de memoria
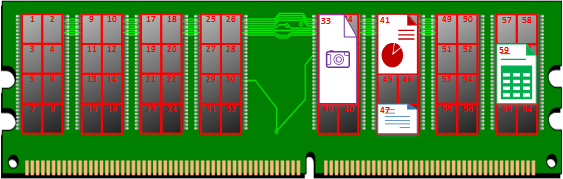
Evidentemente, en la realidad un fichero tenderá a ocupar cientos de direcciones de memoria ¿Imaginas cuánto ocuparía una película en alta definición? Además, que no va a ocupar la dirección última del fichero todos los bits exactos (lo que falte se rellenará, con “0s” posiblemente, dependerá de la política de la memoria), y podrían ser también direcciones impares (en la imagen queda más visual con el fichero pintado encima, pero recuerda que lo que guarda la memoria son ceros y unos; a la memoria le da igual que sea una factura o una novela, ella solo guarda y devuelve lo guardado, le da igual lo que sea). Decir que un fichero comienza por su primera posición, de este modo hemos colocado:
- Foto: en la dirección 33
- Presentación: en la dirección 41
- Novela: en la dirección 47
- Factura: en la dirección 59
Cuando se coloca una nueva memoria, sea del tipo que sea, en un ordenador, requiere que el sistema operativo reserve espacios de memoria para cada una de las necesidades. De este modo y para este ejemplo nuestro “sistema operativo simulado” reservará la mitad de memoria para la “Tabla Hash” (de la dirección de memoria 1 a la 32, incluidas ambas), y la otra mitad para los ficheros (de la dirección de memoria 33 a la 64, ambas inclusive); como se puede pensar, en un ordenador real los ficheros consumen la mayoría de la memoria, y las tablas Hash muy poco en comparación (recuerda que este artículo explica un ejemplo sencillo, en la realidad todo se hace a gran escala y de manera automática, millones de veces por segundo y en millones de direcciones de memoria; solo le queda a tu mente extrapolar lo aprendido a la realidad 😉 ). Además, que la tabla hash no tiene por qué estar al principio de las direcciones de memoria; con que el sistema operativo sepa dónde empieza y donde acaba le vale, además de encargarse el sistema operativo su gestión (actualizarla cuando sea necesario) claro está.
Inciso
Llegados a este punto hago un inciso, y como comparativa de optimización. Si quisiéramos buscar un archivo, por ejemplo “Novela”, si utilizáramos la búsqueda tradicional, y si suponemos que tardamos 1 segundo en acceder a cada dirección de memoria ¿Cuánto tiempo tardaríamos?
Pues si empezamos por la dirección de memoria “1” tardaríamos 32 segundos hasta encontrar el primer archivo en la dirección de memoria “33”; dicho archivo tardaríamos en leer 6 segundos (todo el tamaño que ocupa en memoria) más solo para preguntarle por su nombre que es “Fotos”, con lo que no es el qué queremos. Sabiendo donde acaba el fichero, continuamos buscando desde la dirección “39”. 2 segundos más hasta la dirección “41” donde encontramos otro archivo que suma 4 segundos de acceso para preguntar por su nombre, y es “Presentación” con lo que todavía no lo hemos encontrado. Continúa la búsqueda otros 2 segundos más hasta el siguiente fichero en la dirección de memoria “47”, 2 segundos en leerlo y al ver que se llama “Novela” ya lo habríamos encontrado. Tiempo invertido total: 32 + 6 + 2 + 4 + 2 + 2 = 48 segundos, lo que viene siendo un montón de tiempo desperdiciado innecesario (un ordenador tarda milésimas de segundo en acceder a una posición de memoria, pero piensa que hoy día no es raro ver Terabytes en ordenadores domésticos; así que una búsqueda así podría demorarse horas, no es para nada óptimo y cualquier usuario se desesperaría). Además, hay que pensar que la búsqueda anterior, el peor de los casos que es que no exista el fichero con ese nombre en la memoria, es que se busque hasta el final de la memoria, con el consecuente gasto de tiempo para nada.
Fíjate en el desperdicio de recursos y de tiempo de la siguiente imagen para encontrar el fichero:
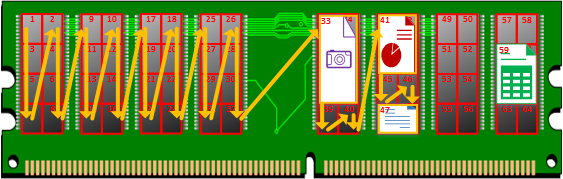
¿Solución? Tablas Hash
¿Cuánto tiempo tarda la búsqueda de la tabla Hash con este ejemplo? 1 segundo en acceder a la posición de memora donde está el apuntador a la dirección de memoria que contiene el fichero que queremos, y el tiempo que se consuma en leer el fichero, que en el ejemplo eran 2 segundos; por lo que el tiempo total sería 1 + 2 = 3 segundos, nos hemos ahorrado un montón de segundos. Además, siempre va a ser este tiempo lo que se tarde en devolver el archivo buscado, independientemente de la posición de la memoria en la que esté el archivo ¿Y si no existe un archivo con el nombre buscado? Pues la posición de la memoria de la Tabla Hash estará vacía, con lo que gastará 1 segundo, ya que no hay otra a la que se apunte
Como se puede ver, la ventaja de las tablas Hash es más que notable. No solo las búsquedas son inmediatas, sino que al leer menos de memoria el tiempo de vida del Hardware se alarga. Hemos optimizado.
Aplicar código Hash de contar las letras:
- Foto: 4 letras
- Presentación: 12 letras
- Novela: 6 letras
- Factura: 7 letras
Realizar la acción que vamos a explicar a continuación es lo que se suele llamar como “Indexación” en los sistemas operativos. Se guarda en cada dirección de memoria que corresponde con el número del código Hash anterior la dirección de memoria donde se encuentra el archivo:
- Foto: en la dirección de memoria 4 se guarda el número 33 (apunta a la dirección de memoria 33)
- Presentación: en la dirección de memoria 12 se guarda el número 41 (apunta a la dirección de memoria 41)
- Novela: en la dirección de memoria 6 se guarda el número 47 (apunta a la dirección de memoria 47)
- Factura: en la dirección de memoria 7 se guarda el número 59 (apunta a la dirección de memoria 59)
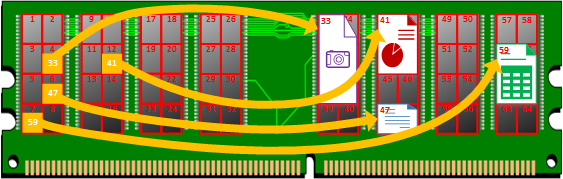
Y ya tenemos nuestra “Tabla Hash”. De este modo cuando queramos buscar cualquier cosa será inmediato.
En comparación a los ejemplos anteriores de los buscadores de los sistemas operativos, hasta este punto hemos hecho el “indexando”, que aparece en dos ocasiones:
- Cuando se crea la "Tabla Hash": que normalmente sucede la primera vez que el sistema de indexado existe en un sistema de ficheros (por ejemplo, cuando se instala por primera vez el sistema operativo; o cuando instalamos un programa que tiene que indexar archivos, por ejemplo un reproductor de música o un visor de fotos). Por lo que el sistema de indexado irá fichero a fichero por todas las unidades de memoria creando un mapa (la "Tabla Hash") de apuntadores a estos ficheros
- Cuando se actualiza la "Tabla Hash": Ya existiendo la "Tabla Hash", se dará cuando un archivo se crea, se modifica, se mueve a otra posición de memoria, o se borra (pues puede que el apuntador ya no sea válido y haya que apuntar a otra dirección de memoria, o no apuntar a nada si se ha borrado).
La "Tabla Hash" tiene que estar precalculada antes de realizar cualquier búsqueda. Supongo que habrás notado que la primera vez que compras o formateas un ordenador -tenga el sistema operativo que tenga- y lo enciendes, todavía no puedes realizar búsquedas inmediatas; pero al cabo de un tiempo (pasadas unas horas) normalmente sí, pues está ya todo precalculado. Sino está precalculada la "Tabla Hash", o todavía está incompleta (faltan partes de la memoria por calcular), entonces al sistema operativo no le queda otra que ir fichero por fichero buscando de la manera lenta que hablamos en el cuadro anterior "Inciso" (y lo más seguro es que aproveche esta lenta búsqueda para realizar los cálculos).
Ahora, un ejemplo de búsqueda de los datos guardados por pasos:
- Un usuario busca en su ordenador “Novela”, (el buscador que utiliza es el que hemos estado hablando, el del sistema operativo del ordenador, por ejemplo).
- El sistema operativo calculará el código Hash de la palabra “Novela” que es “6”
- Por lo que el sistema operativo buscará en la “dirección de memoria 6” a qué dirección de memoria apunta, y es la “dirección de memoria 47”
- El sistema operativo ya sabe que en esa dirección de memoria está el fichero que se busca, lo obtiene y se lo devuelve al usuario.
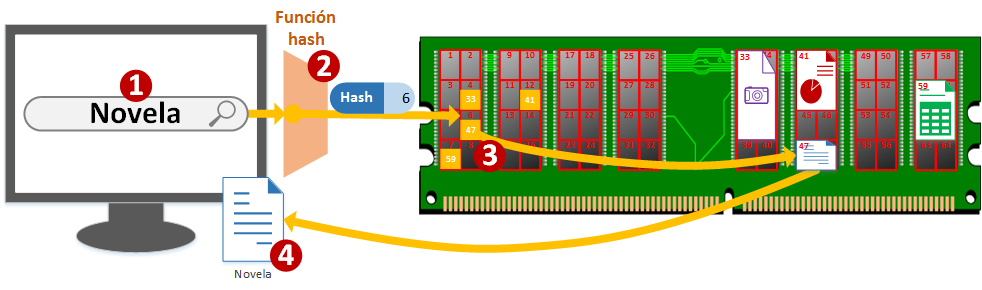
Para el usuario la búsqueda fue instantánea, para el ordenador el consumo de recursos mínimo.
Representación de tabla Hash
Aunque aquí dibujé para que fuera muy fácil de entender en contexto como funciona una “Tabla Hash” en memoria. Lo normal que vas a ver, y entendido lo anterior, será la representación de la memoria como una columna de muchas filas. Luego, las direcciones de memoria apuntadas con una flecha; cada dirección de memoria se suele dividir en cuadros que representan cada uno de los valores, normalmente van a ser datos guardados (los ficheros troceados en cada dirección de memoria) y punteros a otras direcciones de memoria (direcciones de memoria que apuntan a otras para poder general el fichero total al juntar todos sus cachos). Un ejemplo, las dos siguientes direcciones de memoria “552” y “997” (en las posteriores imágenes represento los números decimales en rojo, o los textos también; pero ojo, siempre van a ser en binario), donde cada dirección (en sus 32bits de “1s” y “0s” seguidos) hemos visto bien dividirlo en dos valores:
- El de la izquierda guarda datos (cachos de imágenes, vídeos, documentos de texto, etc.)
- Y la parte de la derecha, que sirve para apuntar a la siguiente dirección de memoria si existe alguna a la que apuntar (si es un vídeo troceado en muchas direcciones de memoria, cada trozo apuntará al siguiente hasta completar el fichero de vídeo entero; aquí represento los datos como 3 bits aleatorios como pudiera ser “101” o “011”). Si no existe ninguna memoria a donde apuntar se dice que está a "null" ("null" NO es un texto, es un carácter como cualquier otro como las letras "A", "B", "C", etc; pero es un caracter llamado "NO imprimible", pues el usuario no lo va a ver, como puede ser el caracter de "salto de página", de "tabulación" o de "espacio en blanco", son carácteres que no se ven pero existen. Si tenemos varias personas en una cola y cada persona está apuntándo con el dedo a la que tiene delante, la que encabeza la cola no tiene a quién apuntar, pero tiene un dedo que tiene que apuntar a algo y ese algo a quien apuntar será a "nadie", pues esa persona que apunta a "nadie", decimos que apunta a "null")

Esto es así porque es más fácil de dibujar con un lápiz sobre un papel que las anteriores imágenes que has visto. Aunque todavía es más sencilla su representación, los punteros directamente ni se escriben, se representan con una flecha, y muchas veces no hace ni falta escribir la dirección de memoria (aquí mantengo los números de las direcciones de memoria justo encima, para poder hacer un ejemplo sencillo en sucesivos párrafos):
![]()
Entendido el resumen de representación de memorias. Ahora podemos representar la anterior “Tabla Hash” (para que quede más visual he agrupado los conjuntos de direcciones de memoria que forman cada fichero; el resto es igual que la representación de memoria anterior, pero cambiando la cuadrícula por una columna, y que solo representamos en la columna la tabla Hash; el resto de direcciones de memoria da igual donde estén mientras se apunten correctamente, yo lo he puesto encima para que puedas tener una visión con el dibujo de la memoria RAM anterior):

Por cierto, por esto se llaman “diccionario de datos” a las “Tablas Hash”. Porque funcionan de manera semejante a un diccionario de papel. La dirección de memoria que apunta es la “palabra del diccionario” y la dirección de memoria que es apuntada es la “definición de la palabra del diccionario” (Lo verás más claro en los ejemplos de programación de más abajo).
Como no puede ser de otro modo, no nos libramos de las colisiones (que al menos dos mensajes den de resultado el mismo código Hash; más información en el artículo de códigos Hash). En este caso la colisión de dos códigos Hashes se llaman “sinónimas” (como hemos visto en el anterior párrafo, sabemos que se ha copiado tal cual las palabras respecto a los “diccionarios” de lengua de toda la vida). Por ejemplo, con a la anterior función Hash de contar el número de letras, sabemos que “Factura” su código Hash es “7”; ahora si creamos otro documento que se llame “Escrito” nos encontramos con que su código Hash también es “7”, una colisión en toda regla ¿Cuál guardamos en la dirección de memoria “7”? Pues ambos.
Para tratar las colisiones (para que lo entiendas de una manera muy sencilla te recomiendo que lo veas en el dibujo de abajo junto la explicación de este párrafo), lo que se hace es enlazar apuntadores a ficheros que sean sinónimos; es decir, tendremos tres valores a guardar en cada dirección de memoria: el título, la dirección de memoria donde está el fichero, y, como añadido, la dirección de memoria donde apunta el siguiente (el siguiente que tendrá estos mismos valores, y así continuamente por cada colisión). De este modo, si primero tenemos “Factura”, guardaremos:
- Un primer puntero al fichero "Factura" en la dirección de memoria “7” (reserva de memoria para la tabla Hash inicial); que, como vimos en el ejemplo anterior, apunta a la dirección de memoria “59” (donde está el fichero "Factura" guardado); ahora también guardaremos otro segundo puntero que apunte a la dirección de memoria “65”
- Un segundo puntero en la dirección de memoria “65” (como puedes ver, esta dirección de memoria es nuevo espacio de memoria reservado para la tabla Hash, podría estar o no estar contiguo, depende de la política de gestión de la memoria), que apunta a la dirección de memoria “51” (donde está el fichero "Escrito" guardado, para este ejemplo ocupa desde la dirección de memoria 51 a la 56)
- Si tuviéramos un tercer, cuarto, quinto, etc ficheros cuyo Hash fuera “7”, seguiríamos encadenándolos con la misma lógica
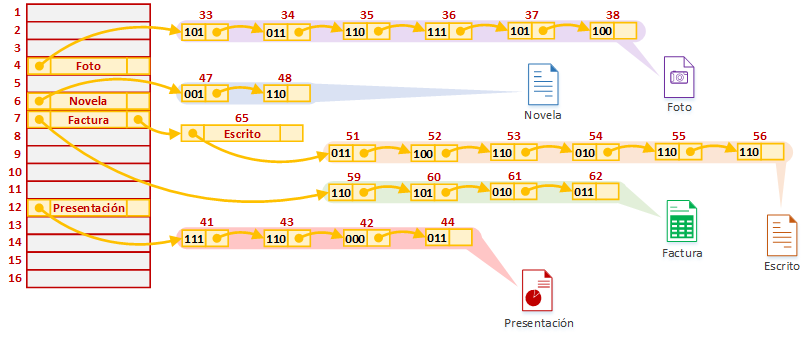 Para hacer la búsqueda será parecido a como se hacía antes. Pero ahora cuando localicemos la dirección de memoria con los listados de claves sinónimas, iremos una por una del listado de claves sinónimas comparando con el título que guardamos previamente hasta encontrar el fichero que queremos. De este modo, en el ejemplo, si buscamos el nuevo fichero “Escrito”, la función Hash nos llevará a la posición de memoria “7”, y empezaremos por el primer elemento de la lista ¿Es “Escrito”? Como podemos ver en la imagen es “Factura” con lo que no lo es, y pasaremos al siguiente en la posición de memoria “65” ¿Es “Escrito”? En este casi sí lo es, por lo que lo hemos encontrado y podremos dirigirnos a la dirección de memoria que contiene el fichero, a la “51”.
Para hacer la búsqueda será parecido a como se hacía antes. Pero ahora cuando localicemos la dirección de memoria con los listados de claves sinónimas, iremos una por una del listado de claves sinónimas comparando con el título que guardamos previamente hasta encontrar el fichero que queremos. De este modo, en el ejemplo, si buscamos el nuevo fichero “Escrito”, la función Hash nos llevará a la posición de memoria “7”, y empezaremos por el primer elemento de la lista ¿Es “Escrito”? Como podemos ver en la imagen es “Factura” con lo que no lo es, y pasaremos al siguiente en la posición de memoria “65” ¿Es “Escrito”? En este casi sí lo es, por lo que lo hemos encontrado y podremos dirigirnos a la dirección de memoria que contiene el fichero, a la “51”.
Se podría mejorar todavía más el rendimiento con el trato de colisiones como ordenar cada listado de claves sinónimas con algún algoritmo, como “Quicksort” (más información del algoritmo “Quicksort” en https://es.wikipedia.org/wiki/Quicksort), para agilizar posteriormente la búsqueda; o utilizar algún algoritmo de búsqueda para no tener que ir uno a uno por el listado de claves sinónimas (recuerda que las tablas Hash ya son un algoritmo de búsqueda en sí; no obstante, bien estudiado se puede utilizar otro algoritmo para agilizar a otro; o incluso usar el mismo algoritmo dentro de sí mismo).
Si tienes más curiosidad de la gran cantidad de cosas que hacen los código Hash por nosotros, no te pierdas el artículo de códigos Hash pinchando aquí.
Ejemplos de uso de “Tablas Hash” con programación
Java
Para este ejemplo voy a utilizar “HashMap” por ser más utilizado y para muchas cosas más interesante, para el desarrollador funciona igual que “HashTable” (Java incorpora ambos “HashMap” y “HashTable”, entre otras variantes. Algunas diferencias es que “HashTable” es thread-safe, que con hilos puede ser sincronizado con varios a la vez; que es más lento en un solo hilo que “HashMap”; “HashMap” permite el valor “null”; entre otros). De cualquier manera, ambos utilizan la idea antes explicada de “Tablas Hash” (por eso se llaman “HashAlgo”).
En este artículo explicaré lo necesario para entender “HashMap”. Tienes mucha más información de “HashMap” en el artículo dedicado en https://jarroba.com/map-en-java-con-ejemplos/
Vamos a suponer que queremos guardar las partes de un árbol y su definición. Siendo el nombre de la parte del árbol la “clave” que queremos buscar, y la descripción el “valor”. Crearemos un “HashMap” formado por un texto para el nombre de la parte del árbol y otro para la definición del mismo (“<String, String>”, siendo el primero para la clave y el segundo para el valor; podríamos utilizar cualquier cosa como clave o como valor, como un número entero, un booleano, un objeto, etc). Con el método “put()” insertaremos cada nombre de cada parte del árbol y su definición (He obtenido la información sobre árboles de https://es.wikipedia.org/wiki/%C3%81rbol). De este modo ya tenemos creada nuestra “Tabla Hash”.
Map tablaHash = new HashMap<string, string>();
tablaHash.put("Raíz","Las raíces fijan el árbol al suelo. Las raíces pueden tener un...");
tablaHash.put("Tronco","El tronco sostiene la copa. Su capa exterior se llama corteza...");
tablaHash.put("Ramas","Las ramas suelen brotar a cierta altura del suelo...");
tablaHash.put("Hojas","A través de las hojas el árbol realiza la fotosíntesis y puede por lo tanto alimentarse...");
Si queremos buscar inmediatamente la definición de cualquier palabra como “Ramas”, siemplemente utilizaríamos “get()” (“get()” devuelve un objeto, lo convertimos a lo que nos interesa, que es un texto, poniendo delante “(String)”) y ya la tendríamos.
String descripcionBuscada = (String) tablaHash.get("Ramas");
Así de fácil 😉
Bibliografía
- Transparencias de “Tablas Hash”. De Jenifer Pérez Benedi, para la UPM
- Experiencia propia del autor de éste artículo
