CD (Entrega Continua) — Parte 2: Image Scan y Service Tests
📚 Serie: CI/CD y la IA: De la teoría a la práctica
Esta parte cubre el escaneo de vulnerabilidades de la imagen de contenedor y las pruebas de servicio (service tests) que validan que el servicio funciona correctamente antes de los despliegues.
Partes de este bloque:
- Parte 1 — Docker Packaging, SBOM y remediación)
- Parte 2 — Image Scan y Service Tests ← estás aquí
- Parte 3 — Deploy a Dev y Smoke Tests
- Parte 4 — Deploy a Staging y Performance Smoke Tests
- Parte 5 — LCA: Load, Stress y Chaos Engineering
- [Parte 6 — Validaciones finales, Manual Approval y Deploy a Producción](https://jarroba.com/ci-cd-y-la-ia-de-la-teoria-a-la-practica/
Image Scan
Sirve para detectar vulnerabilidades, errores de configuración y secretos en la imagen de contenedor antes de que llegue a entornos ejecutables. El escaneo extrae un inventario de paquetes (similar a un SBOM) y lo cruza con bases de datos de vulnerabilidades (NVD, OSV, repositorios de distribuciones) para identificar CVE y problemas de configuración.
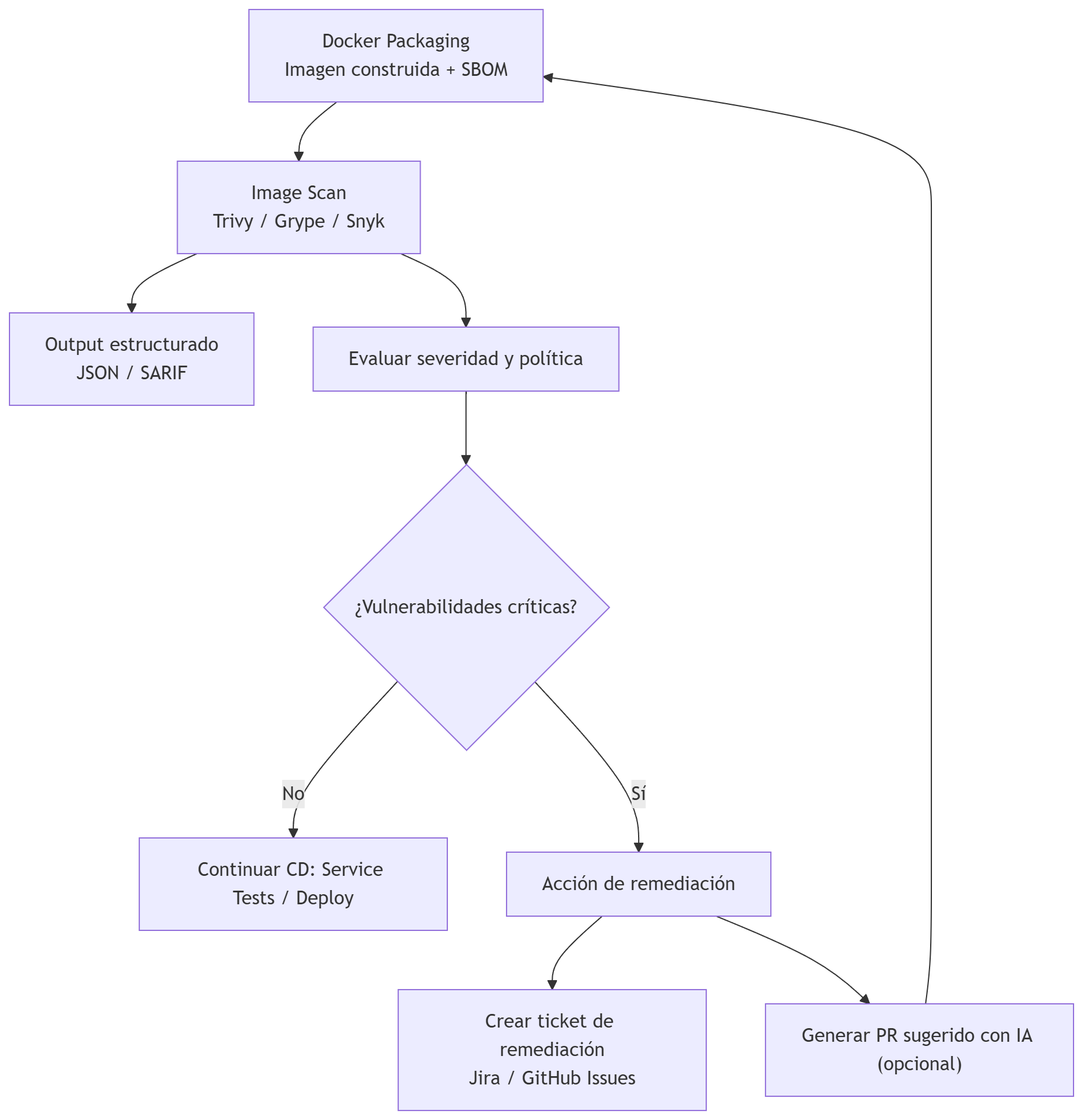
Pasos que incluyen en esta etapa del pipeline
- Obtener la imagen: usar la imagen recién construida o descargar la imagen publicada en el registry.
- Ejecutar el escáner contra la imagen local o el tar exportado (Trivy, Grype, Snyk, Docker Scout).
- Configurar umbrales y exit codes para que el job falle si aparecen vulnerabilidades de severidad alta/critical según la política.
- Generar salida estructurada (JSON, SARIF) para ingestión por otras herramientas y para crear tickets automáticos.
- Correlacionar con SBOM para reducir falsos positivos y priorizar remediación (el SBOM permite saber si un paquete realmente está en la imagen y en qué capa).
- Actuar según resultados: continuar pipeline, crear ticket de remediación o bloquear despliegue según severidad y política.
Buenas prácticas
- Escanear siempre la imagen final que se va a publicar; no solo las capas base.
- Integrar el escaneo en CI para que cada build/PR pase por el control antes del merge.
- Usar SBOM para correlación y priorización; generar SBOM en el mismo job de build para garantizar consistencia.
- Definir políticas claras (qué severidades fallan el pipeline, qué se crea como ticket).
- Escanear imágenes en el registry periódicamente, porque las bases de datos de CVE se actualizan continuamente.
Ventajas
- Prevención temprana: evita que imágenes vulnerables lleguen a entornos productivos.
- Automatización: integración CI/CD permite bloqueo automático y trazabilidad.
- Mejor priorización con SBOM: reduce ruido y acelera respuesta.
Desventajas
- Falsos positivos si no se correlaciona con SBOM o contexto de ejecución.
- Coste en tiempo en pipelines si no se optimiza (cachés, escaneo incremental).
- Mantenimiento de políticas: definir umbrales adecuados requiere gobernanza y ajuste continuo.
Herramientas y ejemplos de comandos
Trivy:
trivy image --format json --output trivy.json --severity HIGH,CRITICAL myapp:latest
Grype:
grype myapp:latest -o json > grype.json
Escaneo desde archivo tar (útil en runners sin daemon):
podman save -o /tmp/myapp.tar myapp:scan
trivy image --input /tmp/myapp.tar --severity HIGH,CRITICAL --exit-code 1
Generar SBOM con Syft (salida SARIF/JSON para ingestión en dashboards o creación automática de issues):
syft myapp:latest -o cyclonedx-json > sbom.json
IA
No sustituye el escaneo técnico: la IA no puede ejecutar el análisis ni generar SBOMs reales. Actúa como asistente de decisión y automatización, no como reemplazo del escáner.
Sí mejora el proceso en varias áreas:
- Priorizar findings combinando contexto de negocio y explotación real.
- Sugerir remediaciones (versiones seguras, parches, cambios en Dockerfile) y generar PRs automáticos.
- Reducir ruido identificando falsos positivos y agrupando findings relacionados.
- Analizar tendencias y predecir qué imágenes/paquetes son más propensos a generar problemas.
Service Tests (pruebas de servicio / componente)
El objetivo es verificar que el servicio funciona correctamente en condiciones reales o realistas: validar endpoints, contratos, serialización, autenticación, comportamiento frente a dependencias externas y respuestas ante errores.
Los service tests se sitúan entre los tests de integración y las pruebas E2E (end-to-end): ejercitan el servicio desplegado (o en un entorno muy cercano al real) contra dependencias simuladas o reales para asegurar que la lógica del servicio y sus integraciones críticas se comportan como se espera.
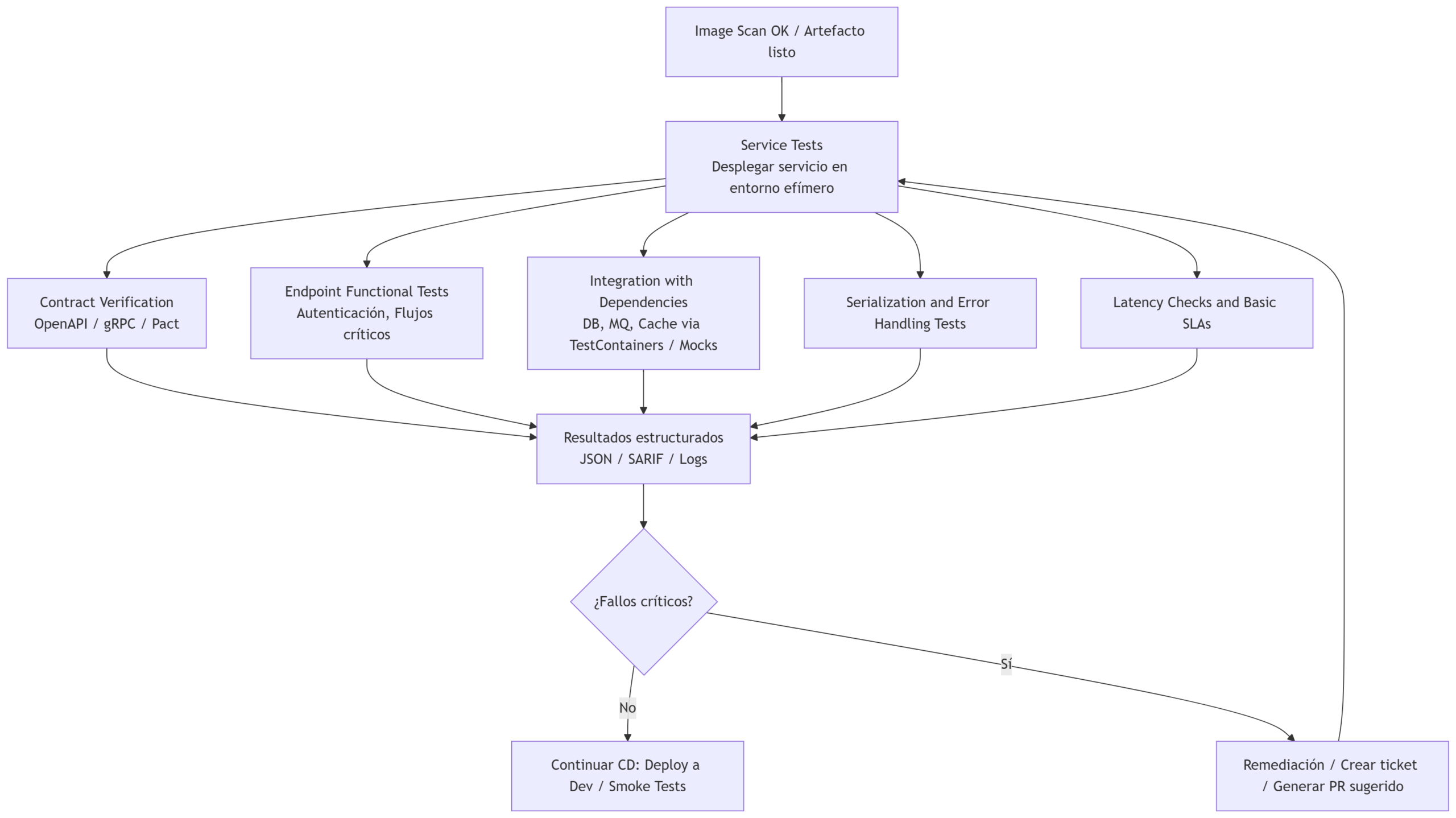
Pasos de esta etapa
- Desplegar el servicio en un entorno efímero o usar un entorno Dev con la misma configuración de runtime que producción.
- Validación de contratos: comprobar que el servicio cumple su API contract (OpenAPI / gRPC) y que las respuestas respetan esquemas y tipos.
- Pruebas funcionales de endpoints: llamadas a rutas críticas (autenticación, autorización, flujos de negocio) con datos reales o sintéticos.
- Pruebas de integración con dependencias: bases de datos, colas, caches, servicios externos; usar test doubles (mocks/stubs) cuando sea necesario.
- Validación de serialización y compatibilidad: comprobar formatos JSON, headers, códigos HTTP y manejo de errores.
- Medición de latencia y SLAs básicos: comprobar que endpoints críticos cumplen latencias aceptables.
- Generación de reportes estructurados (logs, JSON, SARIF) para trazabilidad y para alimentar gates posteriores.
Buenas prácticas
- Validar contratos antes de la integración completa para detectar pronto los breaking changes (cambios que rompen la compatibilidad).
- Usar entornos efímeros que reproduzcan la configuración de producción (variables, secrets en modo seguro).
- Separar pruebas rápidas y exhaustivas: en PRs ejecutar subset crítico; en pipeline de rama destino ejecutar suite completa.
- Aislar flakiness (pruebas que a veces pasan y a veces fallan): retries controlados, timeouts razonables y limpieza de recursos.
- Medir y registrar SLAs (latencia, errores) y fallos reproducibles con trazas y dumps.
- Integrar resultados con Quality Gates para que fallos críticos bloqueen el despliegue.
- Automatizar contract verification entre productores y consumidores para evitar regresiones en microservicios.
Flakiness: pruebas inestables
Una prueba flaky es aquella que presenta un comportamiento inconsistente: a veces pasa y a veces falla, sin que se haya realizado ningún cambio en el código o en el entorno.
Es uno de los problemas más frustrantes en el desarrollo moderno porque rompe la confianza en el pipeline de automatización.
Es mejor tener una suite pequeña y 100% confiable que una suite gigante donde el 5% de las pruebas fallan de forma aleatoria.
¿Por qué ocurre?
- Condiciones de Carrera (Race Conditions): el resultado depende del orden en que se ejecutan hilos o procesos asíncronos.
- Problemas de Red: microservicios o APIs externas que tardan en responder o fallan momentáneamente.
- Dependencia del Orden: una prueba que solo pasa si se ejecuta después de otra (porque la anterior dejó datos en la base de datos).
- Falta de Aislamiento: pruebas que comparten recursos como archivos o memoria y se interfieren entre sí.
- Timeouts Ajustados: pruebas que fallan en el servidor de CI porque es más lento que la máquina local del desarrollador.
El impacto en el pipeline
- Pérdida de Confianza: los desarrolladores empiezan a ignorar los fallos, asumiendo que “es solo la prueba de siempre”, lo que permite que errores reales pasen a producción.
- Desperdicio de Tiempo: se gasta tiempo valioso re-ejecutando builds manualmente para ver si “esta vez sí pasa”.
- Cuellos de Botella: un pipeline bloqueado por una prueba flaky detiene el despliegue de características críticas.
¿Cómo gestionarlo?
- Cuarentena de Pruebas: si se detecta que una prueba es flaky, se mueve a un grupo separado que no bloquea el despliegue hasta que sea reparada.
- Retries Automáticos: configurar el CI para que re-ejecute una prueba fallida inmediatamente. Si pasa al segundo o tercer intento, se marca como flaky.
- Logs Detallados: capturar capturas de pantalla (en pruebas de UI) o logs de red en el momento exacto del fallo para identificar la causa raíz.
- Aislamiento de Datos: asegurar que cada prueba cree y destruya sus propios datos, evitando el estado compartido.
Ventajas
- Detección temprana de fallos de integración antes de entornos superiores.
- Mayor confianza en despliegues porque el servicio se prueba en condiciones cercanas a producción.
- Reducción de regresiones entre servicios cuando se combinan con contract testing.
Desventajas
- Coste en tiempo y recursos: levantar entornos y dependencias incrementa la duración del pipeline.
- Complejidad operativa: mantener entornos efímeros, datos de prueba y flujos de limpieza.
- Flakiness si las dependencias externas no están bien simuladas o si los tests dependen de datos volátiles.
Herramientas y ejemplos prácticos
- Contract testing: Pact, Postman Contract Tests, o herramientas que validan OpenAPI/gRPC; se usan para asegurar compatibilidad productor/consumidor.
- Frameworks de tests HTTP: JUnit + RestAssured (Java), pytest + requests (Python), SuperTest (Node.js).
- Entornos efímeros: TestContainers, Docker Compose para levantar dependencias reales en CI.
- Simulación de dependencias: WireMock, MockServer, mountebank.
- Orquestación y ejecución: jobs en GitHub Actions / GitLab CI que despliegan la imagen en un namespace efímero y ejecutan suites de service tests.
Ejemplo con TestContainers (Java):
// Pseudocódigo: levantar DB y ejecutar tests contra el servicio
PostgresContainer postgres = new PostgresContainer("postgres:15");
postgres.start();
// arrancar servicio con configuración apuntando a postgres.getJdbcUrl()
// ejecutar tests de integración/servicio
IA
No sustituye la ejecución real de pruebas ni la verificación determinista de contratos. Actúa como asistente de productividad y priorización, no como reemplazo del testeo real.
Sí mejora el proceso en varias áreas:
- Generación de casos de prueba: crear tests que cubran rutas no probadas y casos límite.
- Diagnóstico automático: analizar fallos de tests, agrupar errores relacionados y proponer la causa raíz.
- Sugerencia de mocks y fixtures: proponer datos de prueba realistas y configuraciones para entornos efímeros.
- Automatización de PRs de remediación: generar cambios en código o en contratos cuando se detectan incompatibilidades.
- Priorización inteligente: combinar impacto de negocio con frecuencia de fallo para ordenar remediaciones.
