CD (Entrega Continua) — Parte 3: Deploy a Dev y Smoke Tests
📚 Serie: CI/CD y la IA: De la teoría a la práctica
Esta parte cubre el primer despliegue real del ciclo: el deploy al entorno de desarrollo y la validación inmediata mediante smoke tests para confirmar que el servicio está vivo y funciona.
Partes de este bloque:
- Parte 1 — Docker Packaging, SBOM y remediación)
- Parte 2 — Image Scan y Service Tests
- Parte 3 — Deploy a Dev y Smoke Tests ← estás aquí
- Parte 4 — Deploy a Staging y Performance Smoke Tests
- Parte 5 — LCA: Load, Stress y Chaos Engineering
- [Parte 6 — Validaciones finales, Manual Approval y Deploy a Producción](https://jarroba.com/ci-cd-y-la-ia-de-la-teoria-a-la-practica/
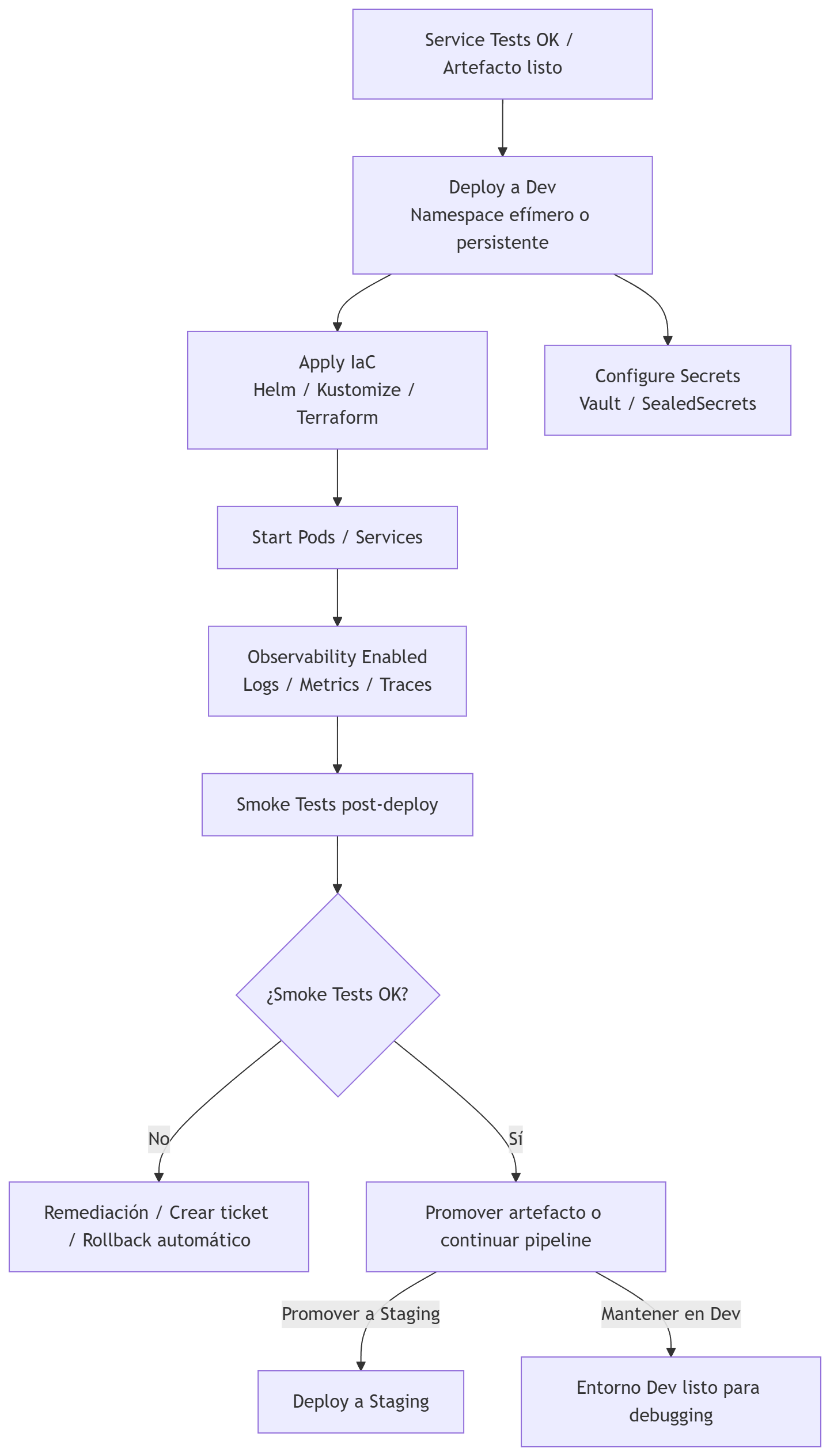
Deploy a Dev
Es un despliegue controlado del artefacto o imagen en un entorno de desarrollo que replica la configuración de producción en lo esencial. Incluye provisión con IaC (Infrastructure as Code), gestión de secrets, activación de observabilidad y ejecución de smoke tests, para dar feedback rápido a desarrolladores antes de promover a entornos superiores.
Este paso se ejecuta después del merge a la rama destino (por ejemplo develop o release/x.y), o bien como pipeline independiente si se usa promoción de artefactos.
Se recomienda promover la misma imagen firmada entre entornos y usar entornos efímeros para PRs.
Dos modelos de pipeline
Se recomienda usar pipeline por rama para entornos de integración y preproducción (por su flexibilidad), y promoción de artefactos para producción (por la trazabilidad y reproducibilidad):
Pipeline por rama destino (recomendado en entornos corporativos):
- PR → CI en rama feature → merge a
develop→ CD dedevelopdespliega a Dev. - Merge a
release/x.y→ CD de release despliega a Preprod. - Merge a
main→ CD de main despliega a Producción. - Ventaja: separación clara de responsabilidades y políticas por rama.
Pipeline único con promoción de artefactos (alternativa):
- Un único pipeline construye el artefacto y lo publica; luego se promueve la misma imagen entre entornos (Dev → Staging → Prod).
- Ventaja: garantiza que exactamente la misma imagen pasa por todos los entornos.
¿Cuándo usar cada uno?
- Trazabilidad estricta y reproducibilidad en producción: construir una vez y promover artefactos.
- Velocidad y flexibilidad en integración: pipelines por rama para Dev/Staging.
- Híbrido recomendado: pipeline por rama para Dev/Staging + promoción del artefacto firmado para Producción.
Pasos de esta etapa
- Seleccionar artefacto: usar la imagen construida y firmada; preferible promover la imagen publicada en el registry en lugar de reconstruirla.
- Provisionar entorno: namespace/cluster efímero o persistente para Dev; aplicar configuración de runtime (config maps, secrets gestionados por vault).
- Desplegar con IaC: Helm, Kustomize o Terraform para infra y manifiestos; usar valores específicos para Dev.
- Configurar observabilidad mínima: logs, métricas y trazas activas (Prometheus, Grafana, OpenTelemetry) para detectar fallos.
- Ejecutar Smoke Tests: health checks, endpoints críticos, autenticación básica.
- Reportar resultados: publicar resultados estructurados (JSON/SARIF) y métricas; si falla, detener y crear ticket/PR de remediación.
- Trazabilidad: registrar versión de imagen, SBOM, firma y commit asociado en el despliegue.
Buenas prácticas
- No reconstruir la imagen en cada entorno; promover la imagen publicada.
- Entornos efímeros para PRs o features (preview environments) y un entorno Dev persistente para integración continua.
- Paridad de configuración con staging/producción (variables, límites, sidecars) salvo datos sensibles.
- Secrets gestionados fuera del repo (Vault, SealedSecrets, Azure Key Vault).
- Rollback automático: mantener estrategia de rollback si el smoke test falla.
- Feature flags para habilitar/deshabilitar funcionalidades en Dev sin desplegar nuevo código.
- Políticas de acceso y auditoría para quién puede promover a entornos superiores.
Ventajas
- Feedback rápido para desarrolladores.
- Detecta problemas de integración en entorno cercano a producción.
- Facilita debugging con trazas y logs reales.
Desventajas
- Coste en recursos y tiempo si no se optimiza (entornos efímeros mal gestionados).
- Posible divergencia de configuración si no se mantiene paridad.
- Riesgo de exponer datos sensibles si los secrets no están bien gestionados.
Ejemplo completo con GitLab CI
Este ejemplo incluye: promoción de imagen firmada, verificación de firma, generación y almacenamiento de SBOM, despliegue con Helm a dev, smoke tests y creación automática de issue si falla.
stages:
- promote
- deploy
- smoke
- notify
variables:
REGISTRY: registry.example.com
IMAGE_NAME: myapp
NAMESPACE: dev
HELM_CHART_PATH: ./chart
SBOM_FILE: sbom-cyclonedx.json
# Job: verificar y preparar imagen (promoción)
promote_and_verify:
stage: promote
image: docker:24.0.0
services:
- docker:dind
variables:
DOCKER_DRIVER: overlay2
script:
- echo "Promote job: tag=${IMAGE_TAG:-latest}"
- docker login $REGISTRY -u "$REGISTRY_USER" -p "$REGISTRY_PASSWORD"
- docker pull $REGISTRY/$IMAGE_NAME:${IMAGE_TAG}
# Verificar firma con cosign (clave pública en variable secreta)
- |
if ! cosign verify --key "$COSIGN_PUBKEY" $REGISTRY/$IMAGE_NAME:${IMAGE_TAG}; then
echo "Image signature verification failed" >&2
exit 2
fi
# Generar SBOM (Syft) y guardarlo como artifact
- syft $REGISTRY/$IMAGE_NAME:${IMAGE_TAG} -o cyclonedx-json > $SBOM_FILE
artifacts:
paths:
- $SBOM_FILE
expire_in: 1h
rules:
- if: $CI_PIPELINE_SOURCE == "web" || $CI_PIPELINE_SOURCE == "pipeline" || $CI_COMMIT_BRANCH == "develop"
# Job: escaneo de imagen opcional (Trivy)
image_scan:
stage: promote
image: aquasec/trivy:latest
dependencies:
- promote_and_verify
script:
- trivy image --format json --output trivy.json --severity HIGH,CRITICAL $REGISTRY/$IMAGE_NAME:${IMAGE_TAG} || true
- cat trivy.json
- |
CRITICAL_COUNT=$(jq '.Results[].Vulnerabilities[]? | select(.Severity=="CRITICAL")' trivy.json | wc -l || true)
HIGH_COUNT=$(jq '.Results[].Vulnerabilities[]? | select(.Severity=="HIGH")' trivy.json | wc -l || true)
echo "HIGH: $HIGH_COUNT CRITICAL: $CRITICAL_COUNT"
if [ "$CRITICAL_COUNT" -gt 0 ]; then
echo "Critical vulnerabilities found, failing pipeline" >&2
exit 3
fi
artifacts:
paths:
- trivy.json
expire_in: 1h
rules:
- if: $CI_COMMIT_BRANCH == "develop"
# Job: deploy a Dev con Helm
deploy_to_dev:
stage: deploy
image: alpine/helm:3.12.0
dependencies:
- promote_and_verify
before_script:
- apk add --no-cache curl jq bash
- echo "$KUBE_CONFIG_BASE64" | base64 -d > /tmp/kubeconfig
- export KUBECONFIG=/tmp/kubeconfig
script:
- echo "Deploying $REGISTRY/$IMAGE_NAME:${IMAGE_TAG} to namespace $NAMESPACE"
- helm upgrade --install myapp $HELM_CHART_PATH \
--namespace $NAMESPACE \
--create-namespace \
--set image.repository=$REGISTRY/$IMAGE_NAME \
--set image.tag=${IMAGE_TAG} \
--wait --timeout 5m
- kubectl -n $NAMESPACE annotate deployment myapp "ci.commit=${CI_COMMIT_SHA}" --overwrite || true
- kubectl -n $NAMESPACE annotate deployment myapp "ci.image=${REGISTRY}/${IMAGE_NAME}:${IMAGE_TAG}" --overwrite || true
rules:
- if: $CI_COMMIT_BRANCH == "develop"
# Job: smoke tests post-deploy
smoke_tests:
stage: smoke
image: curlimages/curl:8.3.0
dependencies:
- deploy_to_dev
before_script:
- apk add --no-cache jq
- echo "$KUBE_CONFIG_BASE64" | base64 -d > /tmp/kubeconfig
- export KUBECONFIG=/tmp/kubeconfig
script:
- echo "Discover service endpoint"
- SERVICE_HOST=$(kubectl -n $NAMESPACE get svc myapp -o jsonpath='{.status.loadBalancer.ingress[0].hostname}' || echo "")
- if [ -z "$SERVICE_HOST" ]; then SERVICE_HOST=$(kubectl -n $NAMESPACE get svc myapp -o jsonpath='{.spec.clusterIP}'); fi
- echo "Service host: $SERVICE_HOST"
- |
# Health check
if ! curl -fS --retry 3 --max-time 10 "http://$SERVICE_HOST/health"; then
echo "Smoke test failed" >&2
exit 4
fi
rules:
- if: $CI_COMMIT_BRANCH == "develop"
# Job: notificar y crear issue si falla
notify_on_failure:
stage: notify
image: curlimages/curl:8.3.0
when: on_failure
script:
- echo "Creating issue for failed pipeline"
- |
curl --request POST --header "PRIVATE-TOKEN: $GITLAB_API_TOKEN" \
--header "Content-Type: application/json" \
--data '{
"title":"[CD] Fallo en Deploy/Smoke tests - '"${CI_PROJECT_PATH}"' '"${CI_COMMIT_SHORT_SHA}"'",
"description":"Pipeline: '"${CI_PIPELINE_URL}"' \nBranch: '"${CI_COMMIT_BRANCH}"' \nImage: '"${REGISTRY}/${IMAGE_NAME}:${IMAGE_TAG}"' \nJob: '"${CI_JOB_NAME}"' \nLogs: see job logs",
"labels":"security,remediation"
}' "https://gitlab.example.com/api/v4/projects/${CI_PROJECT_ID}/issues"
rules:
- if: $CI_COMMIT_BRANCH == "develop"
Detalles a tener en cuenta:
- Promoción sin reconstruir:
promote_and_verifyhace pull de la imagen ya publicada y verifica su firma concosign. Garantiza que la imagen que se despliega es la misma que pasó los controles previos. - SBOM:
syftgenera el SBOM y se guarda como artifact para trazabilidad. - Image scan:
image_scanusatrivyy falla si hay vulnerabilidades críticas (ajusta política según tu gobernanza). - Deploy:
deploy_to_devusahelm upgrade --instally anota el deployment con metadatos (commit, imagen). - Smoke tests:
smoke_testsvalida el health endpoint; si falla,notify_on_failurecrea un issue automáticamente en GitLab. - Secrets:
REGISTRY_USER,REGISTRY_PASSWORD,COSIGN_PUBKEY,KUBE_CONFIG_BASE64,GITLAB_API_TOKENdeben estar como variables protegidas de GitLab.
IA
No sustituye el despliegue real.
Sí mejora el proceso en estas áreas:
- Generación de manifiestos optimizados (Helm/Kustomize) y sugerencias para reducir imágenes y capas.
- Diagnóstico post-deploy: analizar logs y trazas para identificar la causa raíz de fallos.
- Automatización de rollbacks: predecir si un despliegue es riesgoso y sugerir rollback.
- Generación de PRs de remediación con cambios en configuración o Dockerfile.
- Optimización de entornos efímeros: decidir cuándo crear o destruir previews según coste/beneficio.
Smoke Tests
Son comprobaciones rápidas y deterministas que validan la salud y las funciones críticas del servicio tras un despliegue en un entorno (Dev, Staging). Deben ser rápidos, idempotentes y con salida estructurada para integrarse con gates y procesos de remediación.
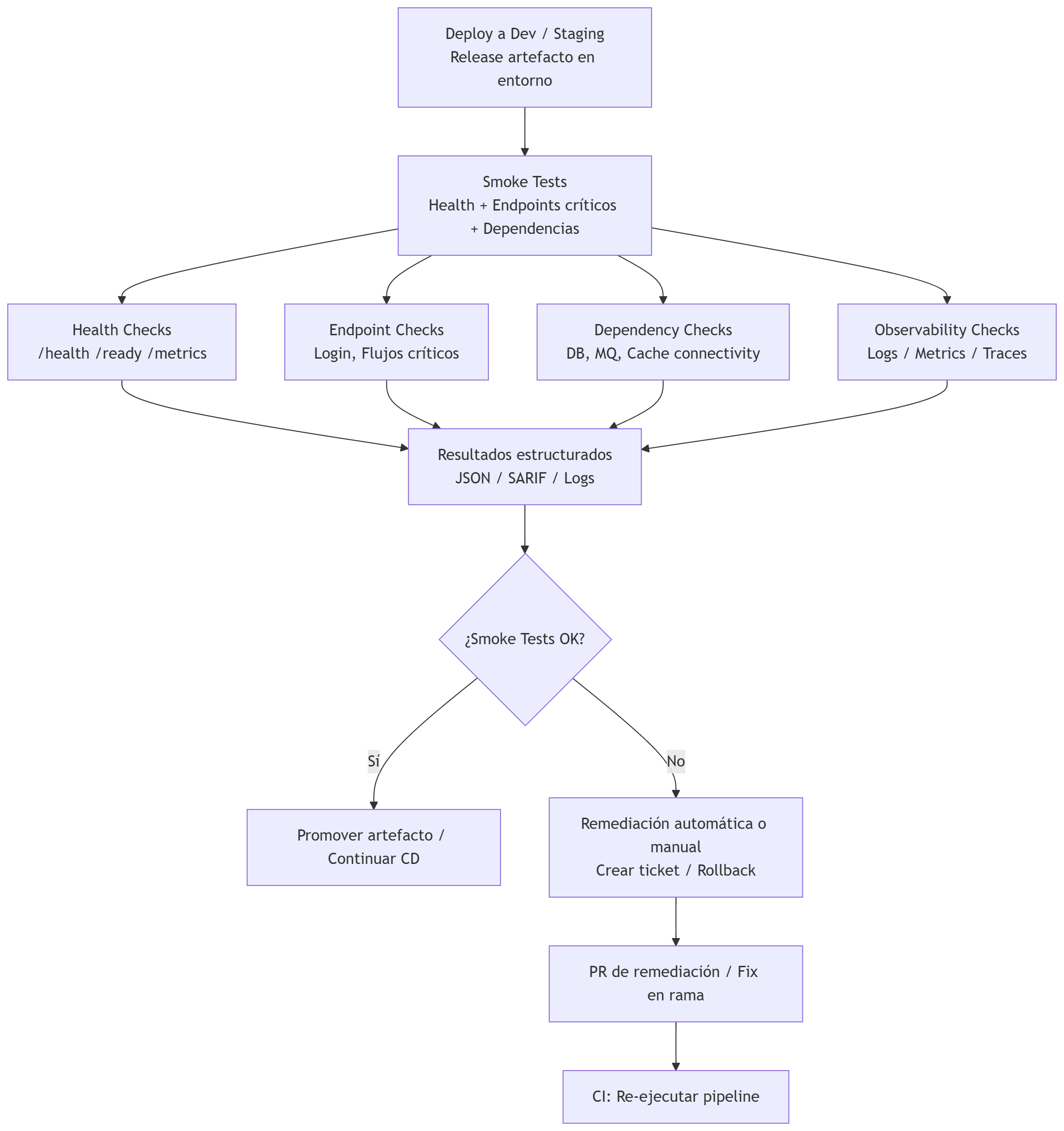
Lo que incluye esta etapa
- Comprobaciones de salud: endpoints
/health,/ready,/metricsy checks de liveness/readiness del orquestador. - Pruebas de endpoints críticos: llamadas a rutas esenciales (login, flujo de pago, endpoints de lectura/escritura clave) con aserciones simples sobre código HTTP y esquema básico de respuesta.
- Verificación de dependencias: comprobar conectividad a bases de datos, colas y servicios externos esenciales.
- Validación de configuración: comprobar que variables de entorno, secrets y configuraciones aplicadas están presentes y con valores esperados (sin exponer secrets en logs).
- Comprobaciones de observabilidad: asegurar que logs, métricas y trazas se emiten y son accesibles.
- Tiempo y tolerancia: tests rápidos con timeouts cortos y retries limitados para evitar bloquear el pipeline.
- Salida estructurada: resultados en JSON/SARIF para ingestión por dashboards, gates o creación automática de issues.
Buenas prácticas
- Que sean rápidos: objetivo < 2–5 minutos; timeouts y retries controlados.
- Aislar lo crítico: seleccionar un conjunto pequeño de endpoints que representen la salud funcional mínima.
- No exponer secretos: nunca imprimir secrets en logs; validar su presencia sin mostrar valores.
- Idempotencia: diseñar tests que no alteren datos de forma irreversible; usar datos sintéticos o entornos efímeros.
- Integración con gates: fallos críticos deben detener la promoción; fallos menores pueden crear tickets automáticos.
- Observabilidad: adjuntar trazas/logs mínimos al reporte para acelerar diagnóstico.
- Retries inteligentes: permitir 1–2 reintentos con backoff corto para mitigar flakiness transitorio.
- Entornos efímeros para PRs: ejecutar smoke tests en previews y destruir el entorno al cerrar el PR.
Ventajas
- Feedback inmediato sobre si el despliegue es viable.
- Prevención de regresiones en producción al bloquear promociones con fallos evidentes.
- Bajo coste comparado con suites E2E completas.
Desventajas
- Cobertura limitada: no detectan problemas de negocio complejos.
- Posible flakiness si las dependencias externas no están bien simuladas.
- Falsa sensación de seguridad si la selección de checks es pobre.
Ejemplos
Comprobación health simple (curl):
curl -fS --retry 3 --max-time 10 "http://$SERVICE_HOST/health"
Smoke test con aserciones en bash:
HTTP_CODE=$(curl -s -o /dev/null -w "%{http_code}" "http://$SERVICE_HOST/api/v1/status")
if [ "$HTTP_CODE" -ne 200 ]; then
echo "Smoke test failed: status $HTTP_CODE" >&2
exit 1
fi
- Uso de frameworks: Newman/Postman para colecciones de smoke; k6 para checks ligeros de latencia; scripts en pytest, JUnit o SuperTest para aserciones programáticas.
- Integración con Helm: usar
helm testpara ejecutar hooks de smoke tras deploy si el chart los define.
IA
No sustituye la ejecución real de los tests ni la verificación determinista. Actúa como asistente de productividad y diagnóstico.
Sí mejora el proceso:
- Generación de suites de smoke: proponer o generar colecciones de endpoints críticos basadas en el código, OpenAPI o historial de incidentes.
- Diagnóstico automático: al fallar un smoke test, analizar logs y trazas, agrupar errores relacionados y proponer la causa raíz.
- Sugerencia de retries y timeouts: optimizar parámetros para reducir flakiness sin perder detección temprana.
- Creación automática de tickets: rellenar issue templates con evidencia, trazas y recomendaciones.
- Priorización: combinar impacto de negocio con frecuencia histórica para decidir qué checks incluir en smoke.
