CD (Entrega Continua) — Parte 5: LCA — Load, Stress y Chaos Engineering
📚 Serie: CI/CD y la IA: De la teoría a la práctica
Esta parte cubre la validación de resiliencia real: pruebas de carga, estrés e ingeniería del caos para garantizar que el sistema se mantiene estable, predecible y recuperable bajo condiciones extremas.
Partes de este bloque:
- Parte 1 — Docker Packaging, SBOM y remediación)
- Parte 2 — Image Scan y Service Tests
- Parte 3 — Deploy a Dev y Smoke Tests
- Parte 4 — Deploy a Staging y Performance Smoke Tests
- Parte 5 — LCA: Load, Stress y Chaos Engineering ← estás aquí
- [Parte 6 — Validaciones finales, Manual Approval y Deploy a Producción](https://jarroba.com/ci-cd-y-la-ia-de-la-teoria-a-la-practica/
LCA: Load + Stress + Chaos Engineering
Esta etapa valida cómo se comporta el servicio bajo condiciones extremas o inesperadas, más allá de la funcionalidad básica. Es la validación de resiliencia real, no solo de rendimiento.
Incluye pruebas de carga realistas, pruebas de stress para identificar puntos de ruptura y pruebas de chaos engineering para validar recuperación automática. Son esenciales para garantizar estabilidad, escalabilidad y tolerancia a fallos antes de producción.
Su objetivo no es comprobar que “funciona”, sino que se mantiene estable, predecible y recuperable cuando:
- aumenta la carga.
- se saturan recursos.
- fallan dependencias.
- se introducen latencias artificiales.
- se reinician pods.
- se caen nodos.
- se corrompen respuestas externas.
- o se producen picos de tráfico.
La IA puede sugerir escenarios, analizar anomalías y automatizar remediación, pero la validación final debe basarse en métricas reales y políticas corporativas.
---
## Tests típicos
Los tres primeros son los más comunes y recomendados. El resto pueden ser útiles según el caso.
### Load Tests (Carga controlada)
Simulan tráfico realista con volumen creciente para validar:
- p50/p95/p99.
- throughput.
- error rate.
- estabilidad del autoscaling.
- comportamiento del pool de conexiones.
- latencia de dependencias.
**Tipos:**
- **Smoke de carga** (duración típica 2–10 minutos): prueba rápida y de baja intensidad. Se envía la cantidad mínima de tráfico durante poco tiempo para verificar que el entorno está bien configurado y el código básico no se rompe. Si falla aquí, no tiene sentido seguir con pruebas más pesadas.
- **Carga sostenida** (10–30 minutos): representa el tráfico normal o esperado durante un periodo prolongado. Se mantiene un número constante de usuarios concurrentes (por ejemplo, 500 usuarios a la vez) durante 10, 30 o 60 minutos para observar si el sistema es estable. A veces un sistema funciona bien los primeros 2 minutos, pero a los 15 minutos se queda sin memoria o las conexiones a la base de datos se saturan.
**Ejemplo k6 de carga sostenida** (`tests/k6/load-test.js`) — duración 2-5 minutos, 50 VUs, carga estable, medir p95/p99 y error rate:
```javascript
import http from 'k6/http';
import { check, sleep } from 'k6';
export let options = {
vus: 50,
duration: '3m',
thresholds: {
http_req_duration: ['p(95)<500'], // p95 < 500ms
http_req_failed: ['rate<0.01'], // <1% errores
},
};
export default function () {
const res = http.get(`${__ENV.BASE_URL}/api/v1/critical`);
check(res, {
'status 200': (r) => r.status === 200,
});
sleep(1);
}
```
Notas:
- Usar `thresholds` para gates automáticos.
- Ideal para ejecutarse en **Staging** tras Performance Smoke Tests.
- Exportar el JSON (con `--out json=load.json`) para análisis posterior.
---
### Stress Tests (Llevar al límite)
El objetivo es identificar el "breaking point" (punto de ruptura) y validar que el sistema **se recupera** cuando la carga vuelve a niveles normales.
El breaking point es el momento exacto en que el sistema deja de responder correctamente. Se va aumentando la carga (1k, 5k, 10k usuarios...) hasta que algo falla. Con esto se intenta saber cuánto aguanta antes del desastre para planificar la infraestructura o configurar alertas de emergencia.
Se busca el breaking point identificando:
- saturación de CPU.
- agotamiento de memoria.
- timeouts.
- colas llenas.
- degradación progresiva.
**Ejemplo k6 de stress** (`tests/k6/stress-test.js`) — duración 5-10 minutos, ramp-up progresivo → pico → ramp-down:
```javascript
import http from 'k6/http';
import { check } from 'k6';
export let options = {
stages: [
{ duration: '1m', target: 20 }, // warm-up
{ duration: '2m', target: 200 }, // stress peak
{ duration: '1m', target: 300 }, // breaking point
{ duration: '1m', target: 0 }, // recovery
],
thresholds: {
http_req_duration: ['p(95)<800'], // tolerancia mayor
http_req_failed: ['rate<0.05'], // <5% errores
},
};
export default function () {
const res = http.get(`${__ENV.BASE_URL}/api/v1/critical`);
check(res, {
'status 200/201/204': (r) => [200,201,204].includes(r.status),
});
}
```
Notas:
- Este test **no debería ser bloqueante** para releases menores.
- Útil para detectar saturación de CPU, pool de conexiones, límites de autoscaling.
- Exportar JSON para correlación con Prometheus/Grafana.
---
### Chaos Engineering (Fallos controlados)
Comprueba que el sistema:
- se recupera automáticamente.
- mantiene SLA.
- no pierde datos.
- no entra en cascada de fallos.
Inyecta fallos reales para validar resiliencia:
- matar pods.
- cortar red.
- añadir latencia.
- degradar DNS.
- reiniciar nodos.
- fallar dependencias externas.
- simular picos de error 500.
**Herramientas típicas:**
- [Chaos Mesh](https://chaos-mesh.org/)
- [Litmus](https://litmuschaos.io/)
- [Gremlin](https://www.gremlin.com/)
- [kube-monkey](https://github.com/asobti/kube-monkey).
**Ejemplo: inyección de latencia en la base de datos** (Chaos Mesh en Kubernetes) — simula degradación realista sin romper completamente el servicio:
`chaos/latency-experiment.yaml`
```yaml
apiVersion: chaos-mesh.org/v1alpha1
kind: NetworkChaos
metadata:
name: db-latency
namespace: staging
spec:
action: delay
mode: one
selector:
labelSelectors:
"app": "myapp-db"
delay:
latency: "200ms"
jitter: "50ms"
duration: "120s"
```
**Ejemplo: matar pods del servicio** (pod-kill):
```yaml
apiVersion: chaos-mesh.org/v1alpha1
kind: PodChaos
metadata:
name: kill-myapp-pods
namespace: staging
spec:
action: pod-kill
mode: fixed-percent
value: "50"
selector:
labelSelectors:
"app": "myapp"
duration: "60s"
```
**Ejemplo: cortar la red hacia un servicio externo:**
```yaml
apiVersion: chaos-mesh.org/v1alpha1
kind: NetworkChaos
metadata:
name: external-service-block
namespace: staging
spec:
action: loss
mode: all
selector:
labelSelectors:
"app": "myapp"
loss:
loss: "100"
direction: to
target:
selector:
labelSelectors:
"app": "external-api"
duration: "45s"
```
Notas:
- Siempre usar **abort conditions** (Chaos Mesh las soporta).
- Ejecutar en **ventanas controladas** o pipelines programados.
- Correlacionar con logs/trazas para validar recuperación automática.
---
## Tests adicionales
### Endurance / Soak Testing (Pruebas de resistencia)
Si la carga sostenida dura 30 minutos, el Soak Test dura horas o días. Detecta fugas de memoria (memory leaks), saturación de logs en disco o corrupción de datos que solo aparecen tras un uso muy prolongado.
### Spike Testing (Pruebas de pico)
Simula un aumento repentino y masivo de tráfico (por ejemplo, el lanzamiento de una oferta flash o un tweet viral) y luego observa cómo baja. Evalúa si el autoscaling de la infraestructura reacciona lo suficientemente rápido.
### Scalability Testing (Pruebas de escalabilidad)
A diferencia del Load Test (que mide el sistema actual), aquí se busca ver cómo mejora el rendimiento al añadir recursos (más CPU, más instancias). Determina si el sistema escala linealmente: si duplicas los servidores pero solo atiendes un 10% más de usuarios, tienes un cuello de botella en el diseño.
### Volume Testing (Pruebas de volumen)
El foco no son los usuarios, sino los datos. Se inunda la base de datos con millones de registros. Identifica si las queries se vuelven lentas cuando las tablas son gigantescas, algo que no notarías con una base de datos de prueba vacía.
---
## Buenas prácticas
- **Ejecutar en entorno dedicado o staging**: nunca en Dev. En producción solo con **canary**, feature flags y rollback automático.
- **Mantener umbrales claros**. Ejemplo:
- p95 < 500 ms
- error rate < 1%
- recovery < 30 s
- autoscaling < 2 min
- **Correlacionar con observabilidad**:
- métricas (Prometheus).
- trazas (OpenTelemetry).
- logs estructurados.
- dashboards de saturación.
- **Ejecutar chaos con condiciones de aborto**:
- Si error rate > X% → detener experimento.
- Si latencia > Y ms → rollback.
- **Integrar con gates**:
- Load/Stress pueden ser **no bloqueantes** para releases menores.
- Chaos suele ser **no bloqueante**, pero obligatorio para releases mayores.
- **Ejecutar en ventanas programadas**: idealmente por las noches o semanalmente.
## Ventajas
- Detecta degradaciones que no aparecen en E2E.
- Valida autoscaling y límites de recursos.
- Asegura resiliencia ante fallos reales.
- Reduce incidentes en producción.
## Desventajas
- Coste en tiempo y recursos.
- Requiere entornos preparados.
- Puede generar ruido si no se controla bien la variabilidad.
- Chaos mal configurado puede causar falsos positivos.
## IA
La IA puede mejorar:
- Generar scripts k6 basados en logs reales.
- Sugerir escenarios de stress según patrones históricos.
- Detectar anomalías correlacionando métricas y trazas.
- Proponer mitigaciones (timeouts, pool sizes, retries).
- Crear tickets con evidencia y análisis de causa raíz.
- Recomendar experimentos de chaos relevantes.
La IA NO puede hacer:
- Ejecutar chaos sin control humano.
- Sustituir la validación de resiliencia real.
- Tomar decisiones de riesgo en producción.
---
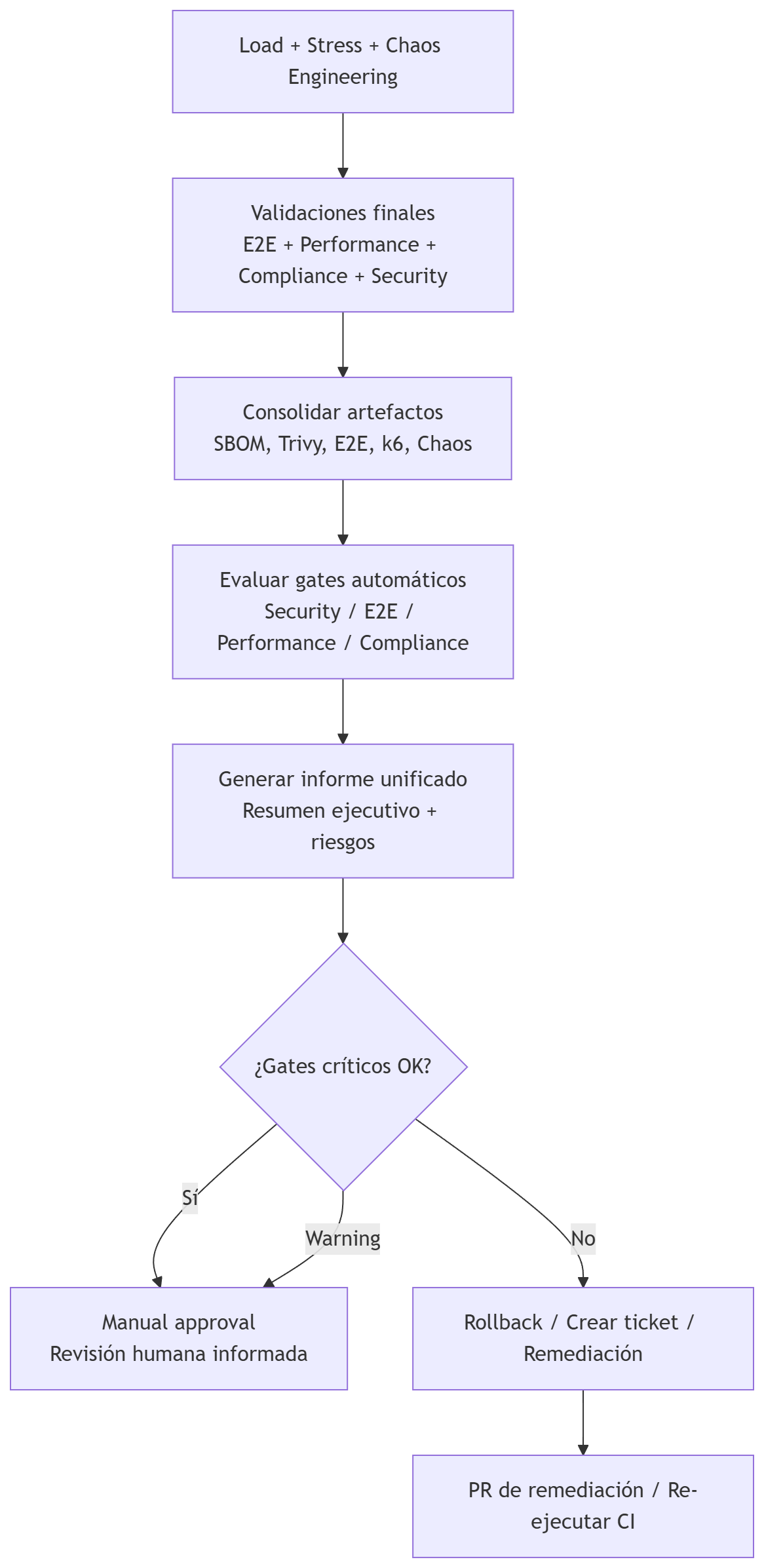
[En el siguiente artículo, **“CD — Parte 6: Validaciones finales, Manual Approval y Deploy a Producción”**, consolidaremos todos los resultados del pipeline, veremos cómo se toma la decisión final de promoción y cómo se ejecuta un despliegue seguro a producción con estrategias Blue/Green o Canary.](https://jarroba.com/cd-entrega-continua-parte-6-validaciones-finales-manual-approval-y-deploy-a-produccion/)
