CD (Entrega Continua) — Parte 6: Validaciones finales, Manual Approval y Deploy a Producción
📚 Serie: CI/CD y la IA: De la teoría a la práctica
Esta es la parte final del bloque de CD. Cubre la consolidación de todos los resultados del pipeline, la aprobación humana informada y el despliegue progresivo a producción con estrategias de riesgo mínimo.
Partes de este bloque:
- Parte 1 — Docker Packaging, SBOM y remediación
- Parte 2 — Image Scan y Service Tests
- Parte 3 — Deploy a Dev y Smoke Tests
- Parte 4 — Deploy a Staging y Performance Smoke Tests
- Parte 5 — LCA: Load, Stress y Chaos Engineering
- Parte 6 — Validaciones finales, Manual Approval y Deploy a Producción ← estás aquí
Validaciones finales (E2E + Performance + Compliance + Security + Observabilidad) e informes agregados
Esta etapa no ejecuta pruebas nuevas, sino que agrega, correlaciona y evalúa los resultados de todas las fases anteriores para decidir si la release es “promovible” (si una versión tiene la calidad suficiente para avanzar al siguiente nivel).
El objetivo es tomar una decisión automática y objetiva sobre si la release es apta para producción, basándose en:
- Resultados de E2E en staging.
- Métricas de performance smoke.
- Resultados de load/stress/chaos (si son bloqueantes para esta release).
- Estado de seguridad (CVE, dependencias, contenedor, IaC).
- Compliance (políticas corporativas, auditoría, SBOM, firma).
- Observabilidad (errores, saturación, logs anómalos, trazas).
Esta etapa genera un informe unificado que alimenta el paso de Manual Approval.
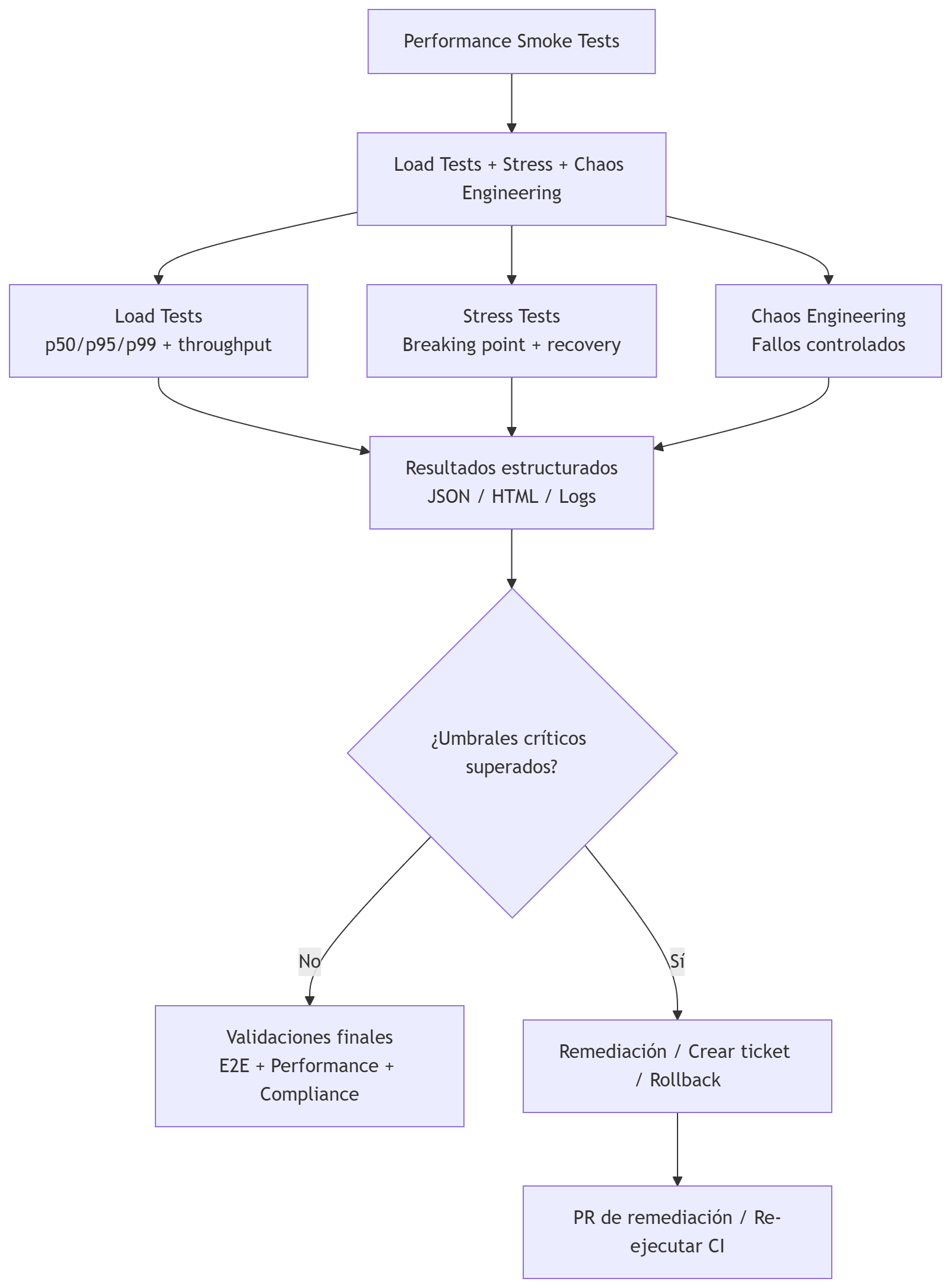
Esta etapa incluye
1. Consolidación de resultados. Recolecta artefactos de:
- Trivy / Grype / Snyk
- SBOM (CycloneDX)
- E2E (JUnit/HTML)
- k6 (JSON)
- Chaos Mesh (logs, events)
- Logs de aplicación
- Métricas de Prometheus (p95, error rate, saturación CPU/memoria)
2. Evaluación automática de gates. Cada gate tiene reglas claras:
| Gate | Criterio | Acción |
|---|---|---|
| Security | 0 CVE CRITICAL, HIGH revisados | Bloquea |
| E2E | 100% flujos críticos OK | Bloquea |
| Performance | p95 < SLA, error rate < 1% | Bloquea |
| Load/Stress | No degradación severa | Warning o bloquea según release |
| Chaos | Recuperación automática | Warning o bloquea según política |
| Compliance | Firma válida, SBOM presente | Bloquea |
| Observabilidad | No anomalías críticas | Warning o bloquea |
3. Generación de un informe unificado. El pipeline produce un resumen ejecutivo con:
- Estado de cada gate
- Métricas clave
- Riesgos detectados
- Recomendaciones
- Enlaces a artefactos
4. Decisión automática:
- Si todos los gates críticos están OK → pasa a Manual Approval
- Si hay fallos críticos → rollback + ticket
- Si hay warnings → Manual Approval obligatorio con nota de riesgo
Buenas prácticas
- Definir gates claros y versionados: los criterios deben estar en código (policy-as-code).
- No mezclar validaciones funcionales con validaciones de resiliencia: cada una tiene su propio peso y política.
- Mantener trazabilidad completa: cada release debe tener commit SHA, tag de imagen, firma, SBOM, reportes E2E, reportes k6, logs de chaos.
- Automatizar el 90%: la aprobación manual debe ser informada, no un “sí/no” ciego.
- Integrar con observabilidad: correlacionar p95, saturación CPU/memoria, errores 5xx, latencia de DB, colas MQ, GC (Garbage Collector).
Ejemplos
Informe Unificado de Validación (markdown generado por el pipeline):
## **Informe Unificado de Validación – Release `<VERSION>`**
**Fecha:** `<DATE>`
**Commit SHA:** `<SHA>`
**Imagen:** `<REGISTRY>/<APP>:<TAG>`
**Entorno:** Staging
**Generado por:** Pipeline CD
---
## 1. Resumen de artefactos
- **SBOM (CycloneDX):** ✔️ Generado
- **Firma de imagen (cosign):** ✔️ Verificada
- **Image Scan (Trivy/Grype/Snyk):**
- CRITICAL: `<N>`
- HIGH: `<N>`
- MEDIUM: `<N>`
- LOW: `<N>`
- **E2E Tests:** `<PASSED>/<TOTAL>`
- **Performance Smoke:**
- p95: `<X ms>`
- Error rate: `<Y %>`
- **Load Test:**
- Throughput: `<RPS>`
- p95: `<ms>`
- Error rate: `<%>`
- **Stress Test:**
- Punto de ruptura: `<VU>`
- Recuperación: `<segundos>`
- **Chaos Engineering:**
- Experimentos ejecutados: `<N>`
- Recuperación automática: ✔️ / ❌
- **Compliance:**
- Políticas de firma: ✔️
- Políticas de SBOM: ✔️
- Políticas de seguridad: ✔️ / ❌
---
## 2. Validación de seguridad
### 2.1 Escaneo de imagen
- CRITICAL: `<N>` — Resultado: **OK / FAIL**
### 2.2 Dependencias (SCA)
- Vulnerabilidades bloqueantes: `<N>` — Resultado: **OK / FAIL**
### 2.3 Compliance
- Firma verificada: ✔️ | SBOM presente: ✔️ | Licencias aprobadas: ✔️ / ❌
---
## 3. Validación funcional (E2E)
- Total tests: `<N>` | Pasados: `<N>` | Fallados: `<N>`
- Flujos críticos: ✔️ / ❌ — Resultado: **OK / FAIL**
---
## 4. Validación de rendimiento
### 4.1 Performance Smoke
- p95: `<X ms>` | p99: `<Y ms>` | Error rate: `<Z %>` — **OK / WARNING / FAIL**
### 4.2 Load Test
- Throughput: `<RPS>` | p95: `<ms>` | Error rate: `<%>` — **OK / WARNING / FAIL**
### 4.3 Stress Test
- Punto de ruptura: `<VU>` | Recuperación: `<s>` — **OK / WARNING / FAIL**
---
## 5. Validación de resiliencia (Chaos Engineering)
- Experimentos: `<N>` | Recuperación automática: ✔️ / ❌ — **OK / WARNING / FAIL**
---
## 6. Observabilidad
- Errores 5xx: `<N>` | Saturación CPU: `<%>` | Saturación memoria: `<%>`
- Latencia DB: `<ms>` | Logs anómalos: `<sí/no>` — **OK / WARNING / FAIL**
---
## 7. Conclusión automática del pipeline
**Estado final:**
- ✔️ Apto para Manual Approval
- ⚠️ Apto con advertencias
- ❌ No apto (requiere remediación)
---
## 8. Enlaces a artefactos
- SBOM | Reportes E2E | Reportes k6 | Logs Chaos | Logs aplicación | Dashboard Prometheus/Grafana | Release Notes
Ejemplo de política de Gates (Policy-as-Code YAML):
policies/gates.yaml
version: 1.0
gates:
security:
critical: 0
high: 5
fail_on_critical: true
fail_on_high: false
e2e:
required_pass_rate: 1.0
allow_flaky: false
critical_flows_must_pass: true
performance_smoke:
p95_ms: 500
error_rate: 0.01
fail_on_threshold: true
load_test:
p95_ms: 800
error_rate: 0.02
fail_on_threshold: false
stress_test:
allow_breaking_point: true
max_recovery_seconds: 30
fail_on_recovery_violation: true
chaos:
require_recovery: true
max_recovery_seconds: 60
fail_on_recovery_violation: false
compliance:
require_sbom: true
require_signature: true
allowed_licenses:
- MIT
- Apache-2.0
- BSD-3-Clause
observability:
max_5xx: 5
max_cpu_pct: 85
max_mem_pct: 90
fail_on_anomaly: false
decision:
promote_if:
- security
- e2e
- performance_smoke
- compliance
warn_if:
- load_test
- stress_test
- chaos
- observability
IA
La IA aporta:
- Correlación automática entre métricas, logs y trazas.
- Detección de anomalías (picos, patrones, regresiones).
- Resumen ejecutivo para el aprobador.
- Priorización de riesgos.
- Generación automática de tickets con causa raíz sugerida.
- Recomendaciones de mitigación (timeouts, pool sizes, caching, retries).
La IA NO hace:
- Sustituir la decisión humana final.
- Aprobar o rechazar una release por sí sola.
- Ejecutar pruebas o manipular entornos.
Manual Approval (Aprobación Manual): decisión crítica, humana e informada
Esta etapa convierte toda la evidencia técnica generada por el pipeline en una decisión humana informada, con trazabilidad, gobernanza y control de riesgo.
Es el último paso del CD antes de producción. Se basa en el resumen ejecutivo generado automáticamente que consolida seguridad, rendimiento, resiliencia, cumplimiento y riesgos. La aprobación queda registrada para auditoría y gobernanza. Si se rechaza, se activa un flujo de remediación.
El objetivo del Manual Approval es permitir que un responsable (PO, Tech Lead, SRE, Seguridad, Compliance, etc.) tome una decisión final basada en:
- Evidencia técnica consolidada
- Riesgos conocidos
- Estado de seguridad, rendimiento, resiliencia y cumplimiento
- Contexto de negocio (ventanas de despliegue, impacto, dependencias)
Es el último control antes de producción y no debe ser un trámite, sino una decisión fundamentada.
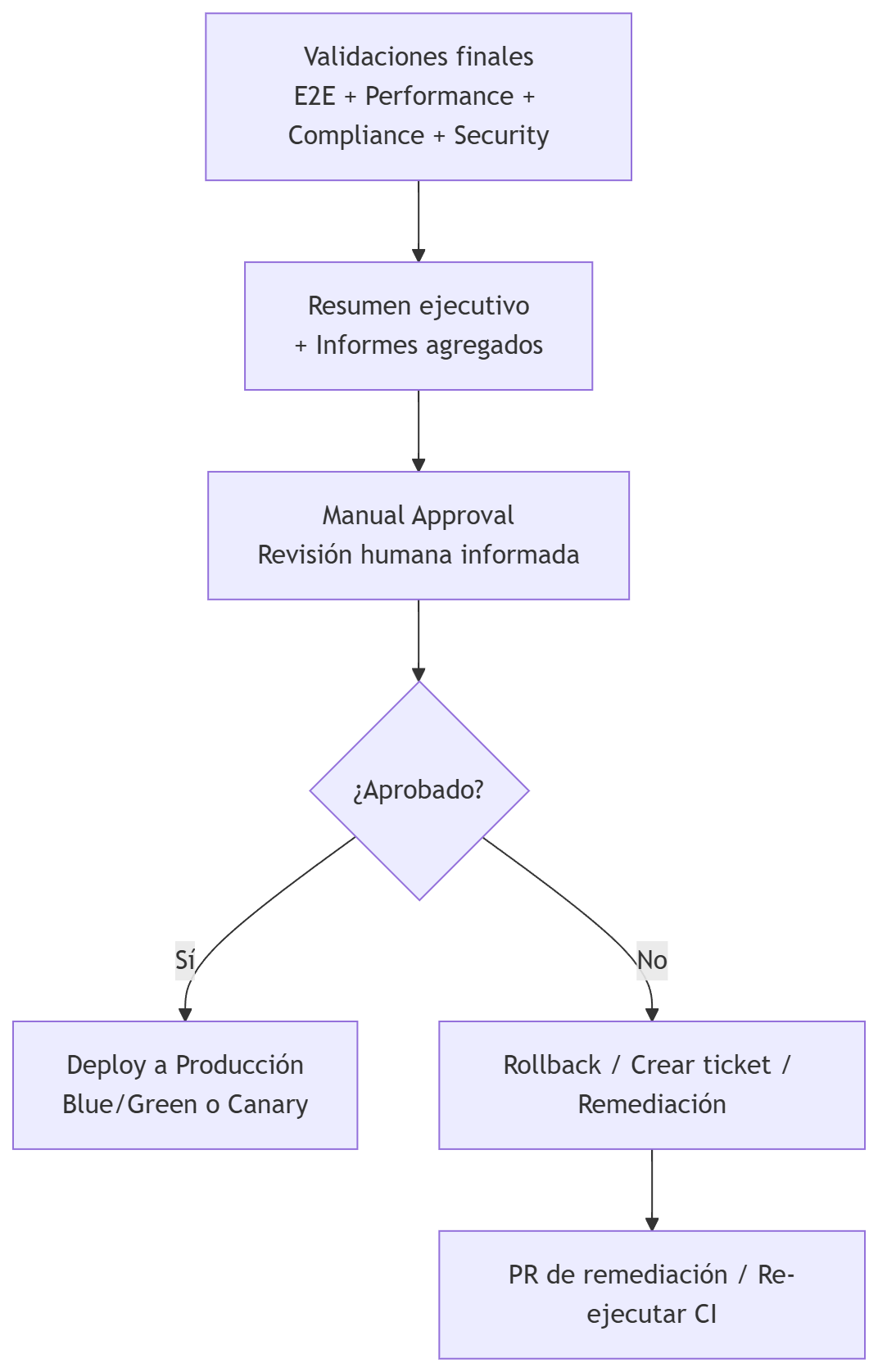
Esta etapa incluye
-
Presentación del Resumen Ejecutivo: el pipeline muestra al aprobador un resumen claro y accionable con estado de todos los gates, riesgos detectados, recomendación técnica, enlaces a artefactos, runbook y rollback.
-
Revisión humana: el aprobador revisa resultados de seguridad, E2E críticos, performance, load/stress, chaos, logs/métricas, compliance y riesgos de negocio.
-
Decisión: el aprobador puede:
- Aprobar → se ejecuta el job de Deploy a Producción
- Rechazar → rollback, creación de ticket y re-ejecución del pipeline tras remediación
- Solicitar cambios → se genera issue y se bloquea la release
-
Auditoría: la decisión queda registrada con quién aprobó, cuándo, qué versión, qué riesgos se aceptaron y qué evidencias se revisaron (esencial para compliance y trazabilidad).
Buenas prácticas
- Requerir múltiples aprobadores según criticidad:
- Releases menores → 1 aprobación (Tech Lead)
- Releases mayores → 2 aprobaciones (Tech Lead + Seguridad)
- Releases críticas → 3 aprobaciones (Tech Lead + Seguridad + PO)
- Mostrar solo información relevante: nada de ruido. Solo métricas clave y enlaces.
- Incluir un checklist obligatorio: evita aprobaciones “a ciegas”.
- Establecer un timeout: si no se aprueba en X horas → la release expira.
- Integrar con runbooks: el aprobador debe tener acceso inmediato a rollback, mitigaciones y contactos on-call.
- Mantener la decisión en el sistema de releases para auditoría y compliance.
Ventajas
- Control de riesgo: permite revisar la evidencia técnica y de negocio antes de ejecutar un cambio irreversible en producción.
- Alineación entre tecnología y negocio: el aprobador puede evaluar si el momento es adecuado (ventanas de mantenimiento, campañas, picos de tráfico).
- Auditoría y cumplimiento normativo: esencial en sectores regulados (finanzas, seguros, salud, administración pública).
- Validación contextual: el pipeline no conoce prioridades de negocio, riesgos reputacionales ni dependencias externas. El aprobador sí.
Desventajas
- Puede introducir fricción o retrasos: aprobadores no disponibles o releases acumuladas.
- Riesgo de aprobaciones “a ciegas”: si el resumen ejecutivo no es claro o no se revisa la evidencia.
- No escala bien sin automatización previa: si los gates automáticos no filtran correctamente, el aprobador recibe demasiada información.
- Punto único de fallo: si solo una persona aprueba, se convierte en cuello de botella.
IA
La IA puede:
- Generar el resumen ejecutivo sintetizando resultados de seguridad, métricas, logs, trazas, chaos y riesgos.
- Correlación de señales débiles: detectar degradaciones progresivas, correlación entre picos de latencia y GC, anomalías en logs.
- Priorización de riesgos según impacto potencial (disponibilidad, seguridad, rendimiento, cumplimiento).
- Generación de recomendaciones (mitigaciones, ajustes de configuración, acciones preventivas).
- Preparación de evidencia para auditoría (enlaces, métricas, artefactos, logs relevantes).
Lo que NO puede hacer:
- No puede aprobar o rechazar una release.
- No puede tomar decisiones de riesgo.
- No puede sustituir el juicio humano.
- No puede ejecutar cambios en producción por sí sola.
- No puede interpretar contexto de negocio (campañas, dependencias, impacto reputacional).
Deploy a Producción: Blue/Green, Canary, Progressive Delivery y control de riesgo extremo
El objetivo es promover el mismo artefacto firmado que ha superado todas las validaciones previas y desplegarlo en el entorno productivo minimizando el riesgo, maximizando la observabilidad y garantizando reversibilidad inmediata.
Es la etapa final del CD y el punto donde convergen: gobernanza, ingeniería, negocio, fiabilidad y experiencia de usuario.
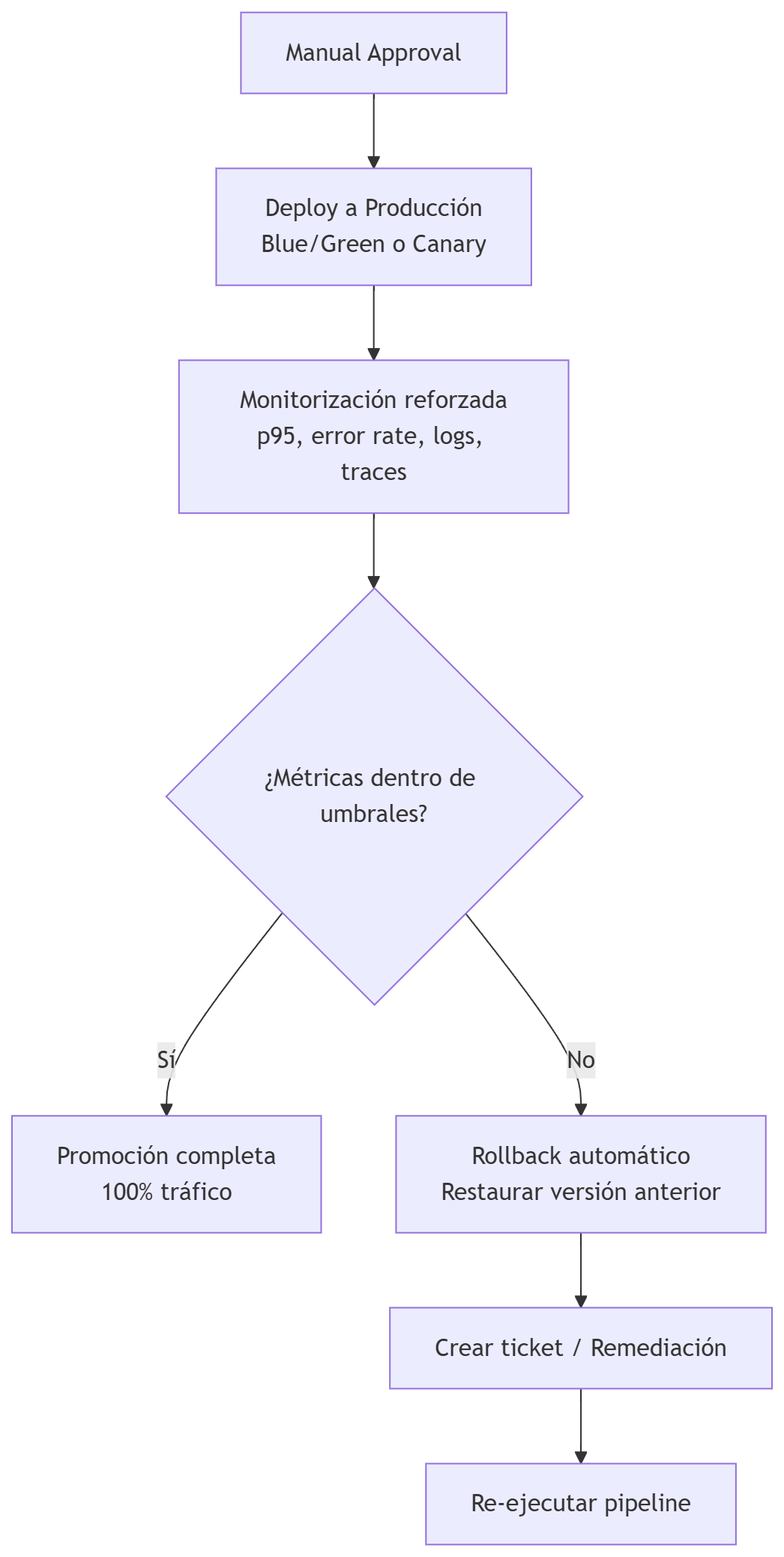
Esta etapa incluye
-
Selección del artefacto final: imagen firmada (cosign), SBOM asociado, metadatos de release (commit, tag, fecha, aprobadores).
-
Estrategia de despliegue (ver detalle más abajo): Blue/Green, Canary, Rolling Update, Feature Flags.
-
Observabilidad reforzada: durante el despliegue se monitoriza p50/p95/p99, error rate, saturación CPU/memoria, latencia DB, logs anómalos, trazas distribuidas e impacto en usuarios reales.
-
Gates en producción (ejemplo):
- Error rate > X% → rollback
- p95 > Y ms → rollback
- 5xx > Z → rollback
- Saturación CPU > 90% → rollback
-
Rollback automático: debe ser inmediato, seguro, reproducible y sin pérdida de datos.
Estrategias de despliegue
Blue/Green:
- Dos entornos idénticos (Blue y Green).
- Se despliega en el inactivo.
- Se hace switch de tráfico instantáneo.
- Rollback inmediato volviendo al entorno anterior.
Canary:
- Se despliega a un porcentaje pequeño de usuarios (1–5%).
- Se monitoriza latencia, errores, saturación.
- Se incrementa progresivamente hasta el 100%.
- Rollback automático si se detectan anomalías.
Rolling Update:
- Reemplazo gradual de pods.
- Menor control que Canary, pero más simple.
Feature Flags:
- Activación progresiva de funcionalidades.
- Permite rollback lógico sin redeploy.
Buenas prácticas
- Promover siempre el mismo artefacto firmado: nada de reconstruir imágenes para producción.
- Usar estrategias progresivas (Canary > Rolling): reduce riesgo y permite rollback rápido.
- Activar observabilidad avanzada: dashboards específicos para el despliegue.
- Automatizar rollback: no debe depender de intervención humana.
- Mantener paridad con staging: recursos, sidecars, límites, configuración.
- Integrar feature flags: permite activar/desactivar funcionalidades sin redeploy.
- Ejecutar smoke tests post-deploy: validación rápida en producción tras el switch.
- Registrar la release: aprobadores, métricas, artefactos, riesgos aceptados, fecha y hora, estrategia usada.
Ventajas
- Riesgo extremadamente controlado: con Blue/Green o Canary, el impacto de un fallo es mínimo.
- Reversibilidad inmediata: rollback en segundos sin afectar a usuarios.
- Observabilidad real en tráfico real: permite detectar problemas que no aparecen en staging.
- Integración con feature flags: permite activar funcionalidades de forma segura.
- Trazabilidad completa: cada despliegue queda registrado con evidencia técnica y de negocio.
Desventajas
- Coste operativo: Blue/Green requiere duplicar infraestructura; Canary requiere más complejidad en routing.
- Dependencia de observabilidad madura: sin métricas fiables, Canary es peligroso.
- Rollback no siempre trivial: si hay migraciones de datos no reversibles, el rollback se complica.
- Requiere disciplina estricta: nada de cambios manuales en producción. Todo debe ser declarativo e inmutable.
IA
- Análisis en tiempo real durante el canary: la IA puede detectar anomalías en latencia, picos de error, saturación, patrones de degradación y correlaciones entre logs y métricas.
- Recomendaciones de rollback o promoción basadas en tendencias, comparativas con releases anteriores y patrones históricos.
- Generación de dashboards y resúmenes: paneles temporales, resúmenes de impacto, comparativas Blue vs Green.
- Detección de regresiones invisibles: degradación lenta, memory leaks, latencia en endpoints no críticos.
Lo que la IA NO puede hacer:
- No puede ejecutar el despliegue por sí sola.
- No puede decidir sobre riesgos de negocio.
- No puede manipular tráfico real sin supervisión.
- No puede sustituir la gobernanza humana.
