Código Hash
Has llegado a un artículo sobre el mundo oculto de la informática técnica. Los códigos Hash se pasan muy por alto; y, sin embargo, son demasiado importantes pues casi cada cosa que haces en el ordenador -sobre todo por Internet- usará sin que te des cuenta varios códigos Hash en sus diferentes tipos. Códigos Hash obtenidos desde los cálculos más simples hasta utilizar los algoritmos matemáticos avanzados.
Comprender como funciona el código Hash, así como para qué se usa, lo considero un principio básico de la computación (y más para la programación); por lo que recomiendo su correcta comprensión y asimilación. Este artículo está diseñado a modo incremental, lo que necesitas para después lo vas a aprender antes. Y si ves a bien que hasta dónde has leído te es suficiente pues puedes no seguir leyendo, dependerá de si necesitas una idea general, unos conocimientos básicos, medios, o hasta conocimientos muy avanzados (leyendo desde el principio del artículo te aseguro que entenderás lo más técnico, está todo detallado).
Al final he explicado algunas herramientas para calcular el Hash de ficheros paso por paso, que te recomiendo pruebes. También he dejado ejemplos de programación al final del artículo, para quien le guste programar.
Si nunca has visto un código Hash o tienes una visión genérica sobre ellos, probablemente de la sensación de poco significativos o ni si quiera se ha escuchado hablar sobre estos. Voy a responder a lo anterior con preguntas retóricas (con tono humorístico 😉 ):
- ¿Acaso es poco importante que un fichero que viaja por Internet llegue sin errores al destino, o en caso de que lleguen con errores incluso poder solucionarlos?
- ¿Es poco trascendental que cuando se introduce una contraseña en cualquier web como inicio de sesión, lo que viaja por Internet no es la contraseña sino otra cosa que de poco sirve si la roban?
- ¿O firmar digitalmente documentos y así asegurar con certeza legal quién es quien envió dicho documento; o hacer transferencias bancarias con seguridad de quién la hace quiere realmente hacerla por Internet?
- ¿Quizá sea de escaso interés que, en una tarjeta que contiene en su interior únicamente números y letras sin sentido, sirvan para identificar a una persona (identificadores electrónicos para puertas en muchas empresas, o como los Documentos Nacionales de Identidad electrónicos, un ejemplo el DNI-e en España) y así no tener que proporcionar ningún dato personal?
Las anteriores preguntas creo que dejan claro, aparte de un montón de usos, que los códigos Hash no son importantes, son MUY importantes en informática y sobre todo para las comunicaciones.
Tienen tanta importancia que a los códigos Hash también se les conoce por una infinidad de nombres, como (no hace falta aprendérselos, aunque ahora cada vez que los veas te sonarán 😀 ): Hash, Resumen, Picadillo, Digest (o “Message Digest”), Fingerprint (la traducción directa es “huella dactilar”, pero para informática es más “huella digital” o “firma digital”), Checksum (o traducido como “Suma de comprobación”), Redundancia, Paridad (o “Bits de paridad”), CRC (Cyclic Redundancy Check, “Verificación por redundancia cíclica”), entre otros.
¿Qué diferencia tiene cada nombre del código Hash?
Diferencia no tiene mucha (Nota si es la primera vez que lees algo sobre los códigos Hash y las funciones Hash: Te recomiendo que te saltes el cuadro de esta pregunta y continúes, luego al final vuelvas y todo será claramente revelado 😉 ). La más característica es que el nombre de “Checksum”, “Redundancia”, “Bits de Paridad”, o “CRC” se utilizan mayoritariamente para comprobar archivos enviados, y por tanto son códigos Hash más cortos (menos seguros para algunos ámbitos, pero muy útiles para la comprobación de fichero); o que el nombre de “Fingerprint” que suelen utilizarse para firmas; o que “Hash” se suele ver mucho en programación como identificador (como los HashMap, o las funciones de tipo “getHash()” o “hashCode()” para obtener el Hash de algún objeto). Aunque depende del contexto qué se utilice se suele usar uno u otro, se puede decir que es casi lo mismo; pues la idea muy similar, aunque cambia su uso directo, el cómo se obtiene, su seguridad, su tamaño y la velocidad de cálculo (en este artículo me referiré a ellos la mayoría de las veces como “Hash”, esta palabra a nivel informático tiene un uso más extendido).
Para explicar cómo funciona el Hash vamos a empezar con una fábula con final casi feliz.
Supongamos que “Yo” (séase “tú”) queremos escribir un mensaje y enviárselo a un amigo, contratando una furgoneta de reparto para que se encargue de enviar el mensaje a nuestro amigo. Supongamos que quiero enviarle un escrito/mensaje sobre la “Manzana” (El texto sobre la Manzana de la imagen está copiado de https://es.wikipedia.org/wiki/Manzana), el cual me esmero en escribir con todo lujo de detalles, ocupando cientos y cientos de líneas. Cuando lo termino se lo confío al transportista que va a llevar el mensaje hasta nuestro amigo.
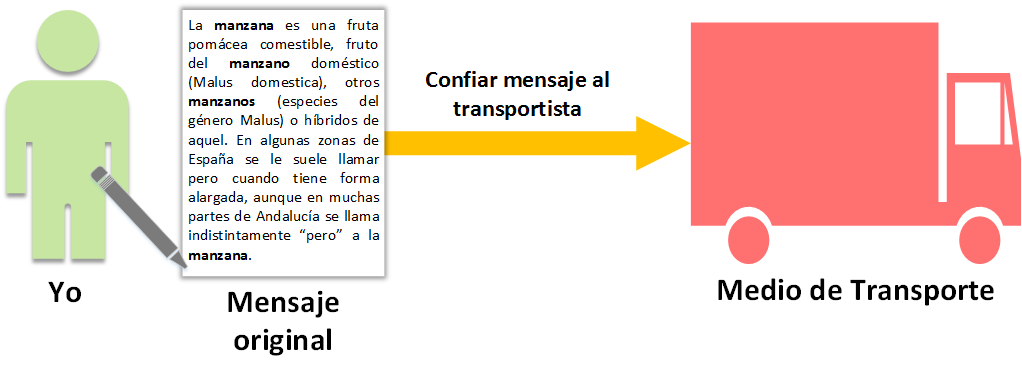
La furgoneta está viajando y el transportista que la conduce es un bromista. Como buen bromista nos modifica el mensaje mientras conduce y sustituye toda relación a la “Manzana” por “Pera”. El mensaje original ha sido modificado. Este mensaje alterado es el que entrega el gracioso transportista a nuestro amigo.

Por cierto, a esto anterior se le conoce como ataque “Man in the middle” (traducido como “Hombre en el medio”); pues es un tercero (que no es ni el emisor ni el receptor) por el camino donde se modifica/lee el mensaje.
Por lo que habrá que hacer algo para comprobar si el mensaje recibido es el mismo que el enviado.
Para ello nuestro amigo nos llama telefónicamente. Con la única curiosidad de conocer el “Resumen” del mensaje. Como es obvio, le diremos a nuestro amigo que “trata sobre las manzanas”; es decir, dado el mensaje original he calculado el Resumen [1] con gracias a la formación de mi cerebro (vamos, la “función Hash”; que también podemos denominar con cualquiera de los otros sinónimos, como “función digest”, “función resumen”, etc) que me permite pensar/calcular el Resumen con solo mirar de que va el texto, y le diré el Resumen a mi amigo [2]. Nuestro amigo, como ser humano, también tiene la misma formación cerebral, por lo que también le es sencillo calcular el Resumen [3].
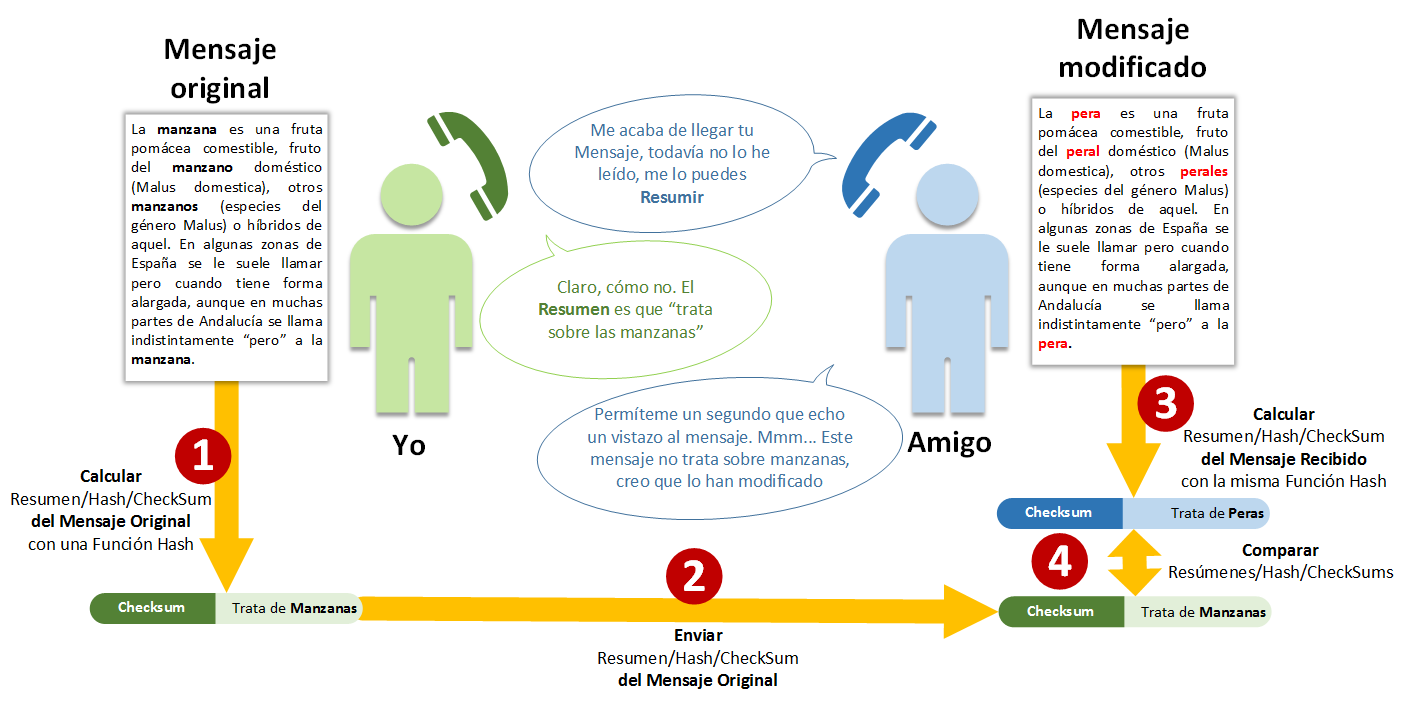
Como mi amigo tiene los dos resúmenes a mano (el suyo y el mío), se le hace muy fácil compararlos [4] para saber si coinciden o no. De este modo pueden pasar dos cosas:
- Si los Resúmenes son iguales, el mensaje recibido será igual al mensaje Original, por lo que se considera al mensaje recibido correcto
- Si los Resúmenes son diferentes, el mensaje recibido ha sido modificado. Y lo más seguro es que nuestro amigo nos pida otra vez el mismo mensaje; esperando que otro transportista diferente no le dé por modificarlo otra vez
Has podido contemplar en el anterior ejemplo la sencillez del código Hash (que como indicamos lo pomos encontrar con el nombre de: Hash, Picadillo, Resumen, Digest, Fingerprint, Checksum), el poder que tiene para detectar mensajes modificados. Pues así es lo que hace tu ordenador cuando se descarga un fichero de Internet (como una imagen, un audio, etc), comprueba su código Hash ya no solo del fichero entero, sino de trocitos del mismo cuando se envía el fichero desde un Servidor hasta tu ordenador; es decir, que cualquiera de las imágenes que has visto encima, han sido troceadas en el Servidor de Jarroba, enviadas por Internet en cachos y cada cacho comprobado en tu ordenador si era correcto o no mediante códigos Hash.
¿Podría darse el caso de que el código Hash valide un Mensaje modificado?
Podría ser. Imagina en el anterior ejemplo que el Resumen que yo le mando a mi amigo es “trata sobre una fruta”; es un Resumen válido del mensaje original, y suponiendo que mi amigo obtiene el mismo Resumen provocaría que mi amigo entendiera como correcto al mensaje modificado. A esto se le llama colisión, es decir, cuando mensajes diferentes al ser calculados por una “función hash” determinada, dan como resultado el mismo código Hash para dichos mensajes diferentes.
¿Siempre van a existir colisiones para cualquier “función hash”?
Claro que sí. En términos lógicos si vamos a una biblioteca y hacemos el Resumen de todos los libros, libro a libro, cuyo Resumen ocupe una línea; con total certeza podemos asegurar que algún Resumen nos servirá para otro libro que sea muy parecido.
Las colisiones es uno de los problemas de los códigos Hash, aunque siempre se intenta que las “funciones hash” creen códigos hash cuya probabilidad de colisión lo más mínima posible. Dicho de otro modo, que los mensajes que puede calcular una “función hash” pudieran ser infinitos (por no estar limitados en tamaño); mientras que los Resúmenes que devuelve (al estar limitados en tamaño) son finitos.
¿Por qué son tan importantes las colisiones? ¿Por qué tanta insistencia con los ataques “Man in the Middle”?
Imagina que estás haciendo una transferencia de dinero a un amigo a través de Internet, pones la cuenta del amigo y pulsas en enviar dinero. Un ataque “Man in the Middle” de un tercero podría interceptar y modificar la orden de enviar dinero al banco por el camino, cambiando el número de cuenta del destino (a la cuenta del atacante evidentemente). Llega la orden al banco y comprueba que en número de destino no coincide con el Hash que generó el que lo envía, por lo que el banco protegería eficazmente la transferencia al rechazar el envío de dinero a alguien no solicitado.
Ahora lo mismo, pero quien realiza el ataque “Man in the Middle” pone un número de cuenta diferente, aunque esta vez coincide con el Hash generado por el número de cuenta original; llega la orden al banco y como los códigos Hash coinciden, el banco piensa que es una transferencia legítima, por lo que da la orden y el dinero va a la cuenta modificada. Esto es muy grave, y se consigue muy rápidamente teniendo tablas de traducción (de un código Hash con cuáles son sus mensajes que lo validan); así en cuestión de segundos se puede desvirtuar una comunicación.
Para que sirva de tranquilidad, es bastante complicado conseguir realizar este tipo de ataques contra un banco (u otras páginas webs debidamente protegidas); existen otros sistemas de seguridad que hay que superar previamente para llegar a realizar el engaño de códigos Hash, como el cifrado de la conexión, los tiempos (timeouts), el secreto de las funciones utilizadas, etc.
¿Los códigos Hash solo sirven para enviar ficheros entre ordenadores?
También sirven en local, sin tener que salir de tu propio ordenador. Como has tenido la oportunidad de entender, los códigos Hash sirven para comprobar que archivos no se hayan visto modificados (como trabajan los antivirus, que comprueban que nadie modifique los archivos con códigos Hash, así como la “base de datos de firmas” que contienen los códigos Hash de los virus).
Además de para la programación, al agilizar las búsquedas como en las “tablas Hash” (hay un ejemplo más adelante); así como las funciones que generan números aleatorios (más bien pseudoaleatorios, un ordenador no generara número aleatorios como lo entendemos realmente, genera Hashes de, por ejemplo, la hora actual, y es lo que devuelve como número aleatorio; así que cada vez que tires unos dados en cualquier juego de ordenador, ya sabes que realmente el resultado provino de un código Hash.
Indicar que en criptografía que sean pseudoaleatorios es una gran ventaja, pues permite a dos ordenadores diferentes dar el mismo resultado, y así poder realizar la comunicación sin que nadie por el camino conozca el número oculto dentro de cada ordenador).
Nota: Si te saltaste la pregunta que recomendaba saltar de “¿Qué diferencia tiene cada nombre del código Hash?”, puedes leerla ahora.
Matemáticas de las funciones Hash
Nota: si solo te interesa saber cómo funciona y no los términos matemáticos sáltate este cuadro. Este cuadro lo dedico para facilitar la comprensión a la criptografía avanzada ¡Con matemáticas 😀 !
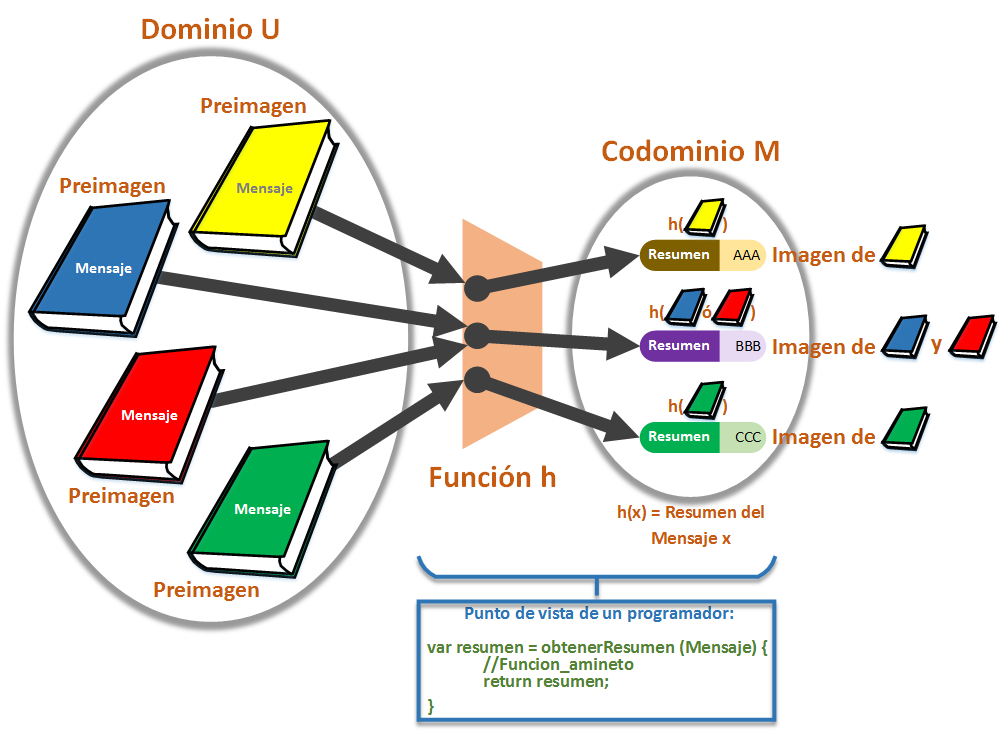
Términos matemáticos que encontremos muy a menudo si profundizamos en el mundo de la criptografía. Si en el ejemplo previo la biblioteca (es el Dominio) contiene infinitos libros (cada libro es una preimagen en matemáticas, o mensaje en el caso informático). Cada libro puede ser procesado por una “función Resumen” (“h”), que devolverá un código Resumen (“h(x)”, donde “h” es el nombre de la función y “x” el mensaje del cual obtener el Resumen; cada código Resumen es una imagen de alguna de preimagen). Al conjunto de todos los códigos Resúmenes posible se dice en matemáticas que es el Codominio. Para todo libro corresponde un código Hash (lo que en matemáticas se dice que el Dominio es imagen del Codominio); pero para un código Hash puede corresponder más de un libro.
¿No sería la función “h(x)” y no solo “h”? No. “h(x)” es el Resumen, pues “h(x)” representa que un montón de cosas juntas (en este caso “h” y “x”) da un estado final en sí mismo; bien podría ponerse “h(x) = Resumen” pero al ser una igualdad directa viene a decir lo mismo y en formulación matemática se abrevia. Si eres programador puede que te suene un poco raro que lo que parece “la función” sea el resultado y no la función en sí; y sin embargo, cuando programamos lo que consideramos “la función” siempre es el resultado ¿Acaso no programamos código como “var resultado = funcion(x)”?, lo que realmente “funciona” dentro de la “función” es el contenido que procesa (de lo que mal llamamos “funcion(x)”), y en matemáticas para representar el contenido simplemente prescindimos de las variables de entrada y ponemos “funcion” (normalmente se suele asociar mentalmente mal a lo que realmente es una función). Así que a partir de ahora ya sabes la diferencia entre “f(x)” y “f”: si tiene variables es el resultado, si no las tiene es la lógica que realiza el cálculo.
La función matemática (queda un poco raro decir “función matemática”, lo pongo para diferenciarla de la “función programática”) de la anterior imagen es:![]()
![]()
Donde “h: U -> M” quiere decir que la función Resumen “h” convierte a los libros/mensajes del grupo “U” en algún Resumen del grupo “M” (en matemáticas se llama “conjunto” al “grupo de cosas”, aquí le cambio el nombre a un sinónimo más suave con el único objetivo de facilitar la comprensión). Por ejemplo, el libro verde se convierte mediante la función “h” en el Resumen “CCC”; y lo mismo podemos decir con todos los libros/mensajes.
Y donde “x -> h(x)”, dice que al meter cualquier libro/mensaje “x” en la función “h” se convierte en el Resumen “h(x)”.
En la imagen anterior puedes apreciar una “colisión” al dar como resultado el mismo código Resumen la Función Hash, tanto para el libro rojo como para el azul.
¿Y después de todo esto, cómo se define la función “h” en matemáticas?
Pues lo que ya hemos dicho, lo que hay dentro que “funciona”, que hace cosas. Creo que con lo que has aprendido, la onceava definición de la RAE de la palabra función lo explica muy bien: “Relación entre dos conjuntos que asigna a cada elemento del primero un elemento del segundo o ninguno.”. Lo dicho, que cada libro/mensaje del grupo U, la función crea un Resumen que le corresponde de entre los que hay en el grupo M (en nuestro caso con los códigos Hash, a cada Mensaje le corresponde un único Resumen seguro; aunque pueda compartir el Resumen con otro Mensaje para los casos de colisiones). Aquí te he explicado de otra manera, a la que se suele encontrar habitualmente, la base; para que asimiles de una forma muy sencilla en la mayor brevedad posible, y puedas dar el salto a términos mucho más avanzados. Si estás interesado, el resto de fórmulas matemáticas los tienes por cientos de sitios en Internet como en la Wikipedia: https://es.wikipedia.org/wiki/Funci%C3%B3n_hash
Ahora te voy a poner exactamente el mismo ejemplo de antes, pero en un código que lo entienda el ordenador, es decir en binario.
En binario (semejante al Checksum de los Segmentos TCP/IP)
Ahora vamos a dar un paso más. El mismo ejemplo anterior con mi amigo y yo, lo vamos a trasformar en dos ordenadores que se envían datos; uno es mi ordenador y otro es el ordenador de mi amigo. Supongamos que queremos enviarle este dato binario (puede ser el texto de un correo, una foto, un video, o lo que sea, convertido a binario), como puede ser el dato “10110000”.
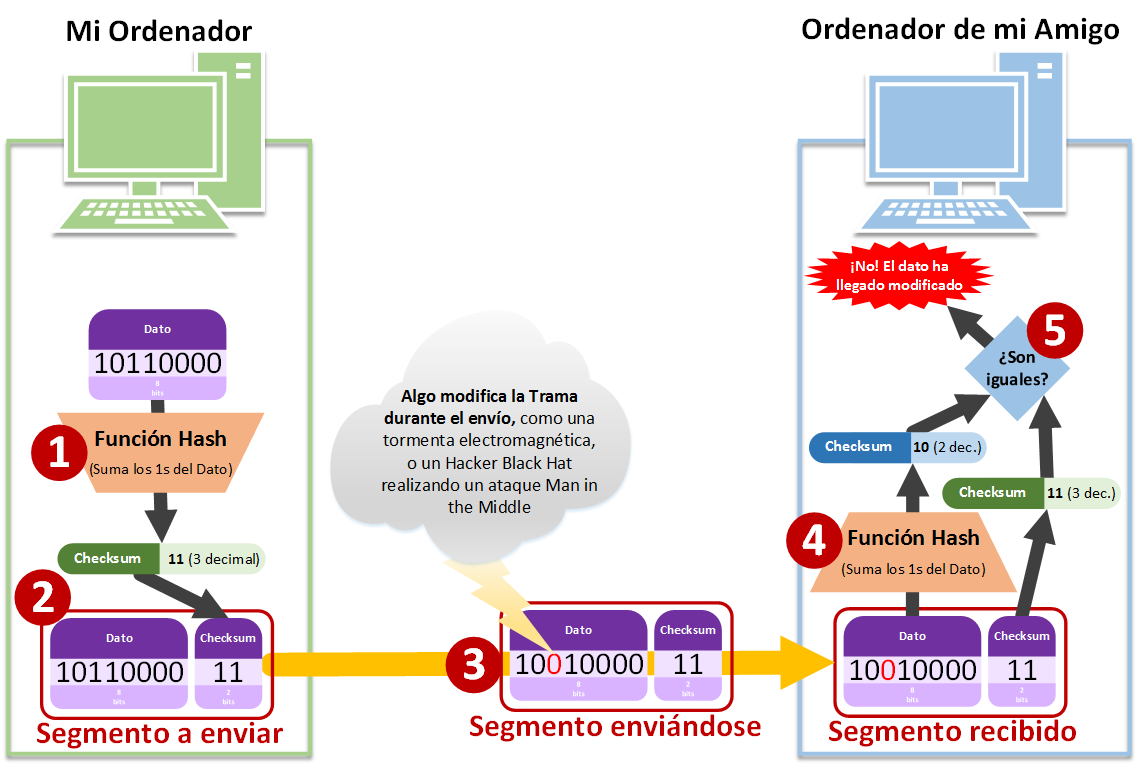
Los pasos que seguirá el dato son:
- Obtención del código Hash mediante una función Hash. La función hash puede ser cualquiera que nos inventemos y resuma el anterior dato binario (aunque recomiendo encarecidamente utilizar las “funciones Hash” estandarizadas y más avanzadas hasta la fecha como MD6 o SHA3). Para este ejemplo nos hemos inventado la “función hash”, que consiste en sumar los “1” que hay en el anterior dato binario “10110000”; cómo podemos contar son 3 unos, y 3 en binario es “11” (recordatorio de conversión de decimal a binario con representación de dos dígitos: 0 = 00, 1 = 01, 2 = 10, 3 = 11)
- Rellenar el Segmento de información a enviar, el cual contendrá al dato y el código Hash (Checksum)
- Se envía el Segmento (contenido en una Trama) hacia el ordenador de mi amigo por alguna vía, como Internet. En el camino el Segmento podría verse modificado, como por una tormenta electromagnética o un ataque Man in the Middle (algún tercero interesado en engañar al ordenador de nuestro amigo). En el ejemplo hemos pasado de tener el Segmento (Dato + Chekcsum) “1011000011” a “1001000011”
- El ordenador de nuestro amigo recibe el Segmento de información con el dato modificado y el código Hash. Como ambos ordenadores calculan con la misma función Hash, calcula el código Hash del dato recibido con dicha función Hash. En el ejemplo separamos el Segmento recibido “1001000011” en dato “10010000” y en código Hash recibido con el Segmento “11”; al calcular el código Hash de “10010000”, cuya cuenta de unos es 2 en decimal, obtenemos el código Hash binario “10”
- Compara ambas funciones Hash, la recibida y la calculada. Si son iguales el dato se habrá recibido correctamente; si son diferentes no y habrá que volverlo a pedir. En este ejemplo hemos recibido con el Segmento “11” y el código Hash calculado fue “10”, que como podemos ver no coinciden; no sabremos nunca si lo que se modificó fue el Dato o el código Hash recibido, lo que sí sabemos es que hay algo mal, por lo que se descarta todo y se vuelve a pedir.
¿Puede darse que la tormenta electromagnética varíe además un “1” por un “0” y que quede el Segmento como “1101100011”? sí y habría 3 veces unos ¿Entonces el “código hash” validaría como correcta la trama que es errónea? Sí, es un problema de los códigos hash, aunque se suelen utilizar “códigos hash” mucho más grandes y con “funciones hash” mucho más complejas como MD5 o SHA-1 (o más modernos como los citados anteriormente como MD6 o SHA3), por lo que estadísticamente es muy poco probable que pasemos el error por alto ¿Ya, pero aun así podríamos no detectar el error? Sí, y es una de las razones por lo que todavía hoy nos descargamos ficheros corruptos 😉
Por cierto, cuando llamamos al código Hash “bit de paridad” es muy parecido al método anterior que me he inventado, tan parecido que se utiliza realmente de “Checksum”. Hemos preparado un artículo completo para entender el "bit de paridad" con detalle y de una manera muy sencilla pinchando aquí; aunque antes te recomiendo que acabes de leer este artículo, ya que así lo entenderás mucho mejor.
Propiedades ideales que debería cumplir un código Hash
“Debería cumplir” pues en algunos casos puede que no interese, o simplemente no se ha encontrado manera todavía de acercarse más al ideal. Voy a describir los casos que interesan criptográficamente hablando y para dar continuidad a los ejemplos anteriores.
La gracia del código Hash que debe de poder ser creado (calculado) por cualquier función Hash consumiendo los mínimos recursos (es decir, que sea de bajo costo, inmediato, pues si el ordenador se tira una hora calculándolo no sirve de mucho). Y para el mismo fichero (o texto, mensaje, datos, etc) sin modificaciones ha de dar siempre el mismo código Hash, que sea determinista en los resultados (a veces puede interesar que sea no determinista, pero eso ya son particularidades a las que no voy a entrar en cada una). Si por ejemplo queremos descargar un fichero el cual tiene un código Hash calculado previamente por el creador del fichero; servirá para el momento en el que descarguemos el fichero, comprobar si efectivamente el fichero se ha descargado correctamente (veremos ejemplos prácticos más adelante).
Además, ha de reducir el número de colisiones para cada código Hash. Si calculamos el código Hash de todos los ficheros (o textos, o lo que sea) que existen sobre la Tierra y contáramos la cantidad de veces que aparece repetido cada código Hash, la función Hash deberá asegurar que todas las cantidades de colisiones sean las mismas o muy parecidas, que sean uniformes; es decir, debe asegurar que el número de colisiones para un código Hash será igual de probable que para el resto (precisamente para evitar lo máximo las colisiones, ya que no podemos reducirlas a cero, pero si reducirlas al mínimo para cada código Hash).
Otra cosa muy importante, sobre todo en criptografía, es que si se cambia un solo bit (como en el ejemplo anterior, un “1” por un “0”) el resultado de la función Hash deberá de ser lo más diferente posible que si no hubiera cambiado; es decir, que no exista una correlación directa entre lo que entra a la función Hash y lo que sale (en el ejemplo de la función Hash de sumar los unos, existe una correlación muy fuerte entre lo que entra a la función y lo que sale, pues modificando un bit se modifica muy poco y además Hash obtenido es muy fácil de deducir; lo que no la hace interesante para su uso, aunque sí para aprender 😉 ). Que la modificación de un único bit haga que toda la función Hash cambie completamente aleatoria, es lo denominado efecto avalancha.
Una propiedad muy interesante, y aunque la ponga la última no es menos importante; es que, desde un código Hash no seamos capaces de obtener ninguna información del mensaje original (el ejemplo anterior no valdría, ya que la función Hash simplemente suma los unos para generar el código Hash, por lo que sabemos la cantidad de unos que hay en el mensaje; da información, aunque sea poca, y no ha de dar nada).
La existencia de colisiones es importante. Imagina lo siguiente: el login de una página web pide el usuario y contraseña, introducimos nuestros datos y pulsamos enviar; la contraseña no se envía al servidor, sino el código Hash, alguien por el camino intercepta el código Hash; este alguien previamente a hallado el código Hash de las contraseñas más comunes (por lo que sabe a qué contraseña corresponde cada Hash de un montón de contraseñas posibles como “12345” o “admin”), el código Hash que ha robado por el camino coincide con alguno de los que había previamente calculado este tercero, entonces el ladrón ya conoce nuestra contraseña. Por seguridad es interesante que existan colisiones, pues si no tuviéramos ninguna colisión podríamos mapear (decir para el Hash X le pertenece el mensaje Y) fácilmente todos los casos y saber su significado; existiendo colisiones, que alguien conozca el código Hash no sabrá a cuál de todos los mensajes que podrían formarlo es el que ha creado el Hash. En el caso del ejemplo de las contraseñas, si sabemos que para la contraseña “12345” le corresponde el Hash “a48de4a9”, si capturamos el Hash de algún inicio de sesión de alguien a su correo electrónico, por ejemplo, y resulta que es “a48de4a9” aunque existan colisiones podríamos comprobar si realmente entramos a la sesión con “12345” y si es así hemos obtenido la contraseña del otro usuario, sino pues será otra que no sabremos. Con esto último quiero decir que, aunque tengamos colisiones no evita el mapeo, complica al tener que hacer alguna comprobación extra o tener mapeadas varias contraseñas posibles para un mismo Hash y así ir probando una a una.
En general el código Hash tendrá que ser privado cuando se pueda extraer de algún modo algo de información del mensaje desde el código Hash (como en el ejemplo de las contraseñas anterior); si, por ejemplo, se va a enviar por Internet la solución es cifrar al código Hash antes de enviarlo. El código Hash suele ser público cuando sirve para comprobar errores y no expongan la información con la que se obtuvo el código Hash, como el Checksum de los Segmentos TCP/IP (Segmentos TCP/IP son, por ejemplo, de una imagen convertida en bits, cortar esos bits en trocitos y añadir a cada trocito el Checksum; así enviar cada trocito con su Checksum por Internet y si un trocito llega erróneo a su destino, se pediría el renvío de ese trocito solo; luego en el destino se reordenarían los trocitos con ayuda de otros bits que indican el orden, que al igual que el Checksum también acompañan a cada trocito, y así obtener la imagen en destino). Lo que casi siempre va a ser público va a ser la función Hash (para el ejemplo de las contraseñas robadas, el ladrón podría entrar en una página web y mirar el código JavaScript de esa web para comprobar si la función Hash es MD5, o SHA1, o SHA512, etc).
Nota especial para desarrolladores FrontEnd (Un desarrollador FrontEnd es quien escribe el código que se va a ejecutar en el navegador del usuario, código como HTML, JavaScript y CSS; aunque también son las aplicaciones de escritorio o las Apps móviles, con código como Java, C#, VB, C++, etc): mucho cuidado con suponer que lo que hagamos en la parte del Cliente/Navegador es seguro. La seguridad siempre ha de estar enfocada en el Servidor. El código que recibe el usuario a su ordenador/móvil es público. Se considera que el Servidor regala el código FrontEnd al usuario y puede hacer lo que quiera con éste; como si lo ve, lo estudia, lo modifica, lo llena de insultos, hace posible escribir en campos deshabilitados, etc; es para él y donde lo esté ejecutando (como un navegador, un móvil, etc). Puede que el código compilado (como el de las aplicaciones de escritorio o Apps móviles) sea más complicado de obtener que el de una página web; pero existe la ingeniería inversa (del código compilado obtener el código fuente) y lo hacen programas en cuestión de segundos.
He descrito las propiedades que he considerado más importantes para una correcta comprensión. Hay muchas más, algunas de ellas y bien explicadas las tienes en https://es.wikipedia.org/wiki/Funci%C3%B3n_hash
Usos de los códigos Hash en contexto
Firmar digitalmente
Voy a resumir rápido lo que nos interesa en este caso. Hay mucho más detrás, y los certificados también utilizan Hashes. Aquí solo voy a tratar como firmar digitalmente un archivo.
En este ejemplo vamos a suponer que queremos descargarnos un documento a cumplimentar de nuestro gobierno, vamos a la página web y lo descargamos (o nos lo envían de alguna manera). Este documento podría ser perfectamente un fichero en PDF por ejemplo (o cualquier otro tipo de archivo). La gracia está que el usuario/ciudadano tiene en su poder un par de claves pública y privada (mediante algún método de intercambio de claves como RSA, Diffie Hellman, etc; hablaremos más de estos en un artículo futuro, para este ejemplo nos vale con tener dos claves pública y privada, da igual el método), que normalmente estarán en el chip de su documento nacional de identidad; el DNI-e en España.
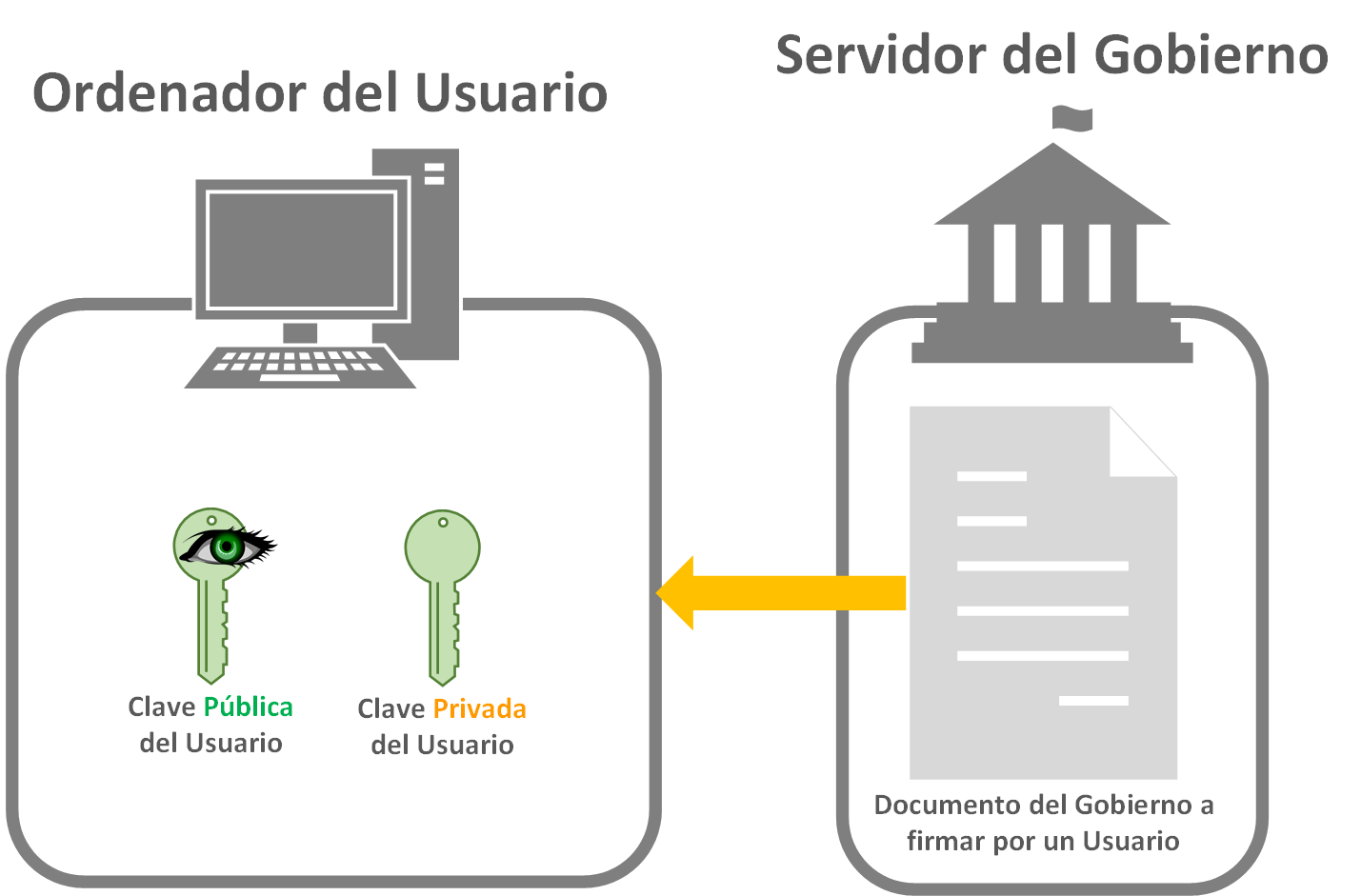
¿Cómo funciona la “Clave Privada” y la “Clave Pública”?
Por si desconoces como funciona lo de la clave Pública y Privada lo explico rápidamente sin entrar en detalles matemáticos. La “Clave Privada” es la que cifra y la “Clave Pública” la que descifra lo cifrado con la “Clave Privada” aparejada a ésta (si te fijas en los ejemplos represento la “Clave Pública” con un ojo encima, para representar dos cosas: que la puede ver todo el mundo, y que es la que hace ver lo oculto, la llave que abre el cifrado, la que descifra). Cualquier clave Pública NO descifra lo que una clave Privada ha cifrado, solo descifra lo que ha cifrado su pareja (una “Clave Pública” es pareja de una “Clave Privada” gracias a ciertas matemáticas; y como he dicho, entraremos más en detalles en futuros artículos).
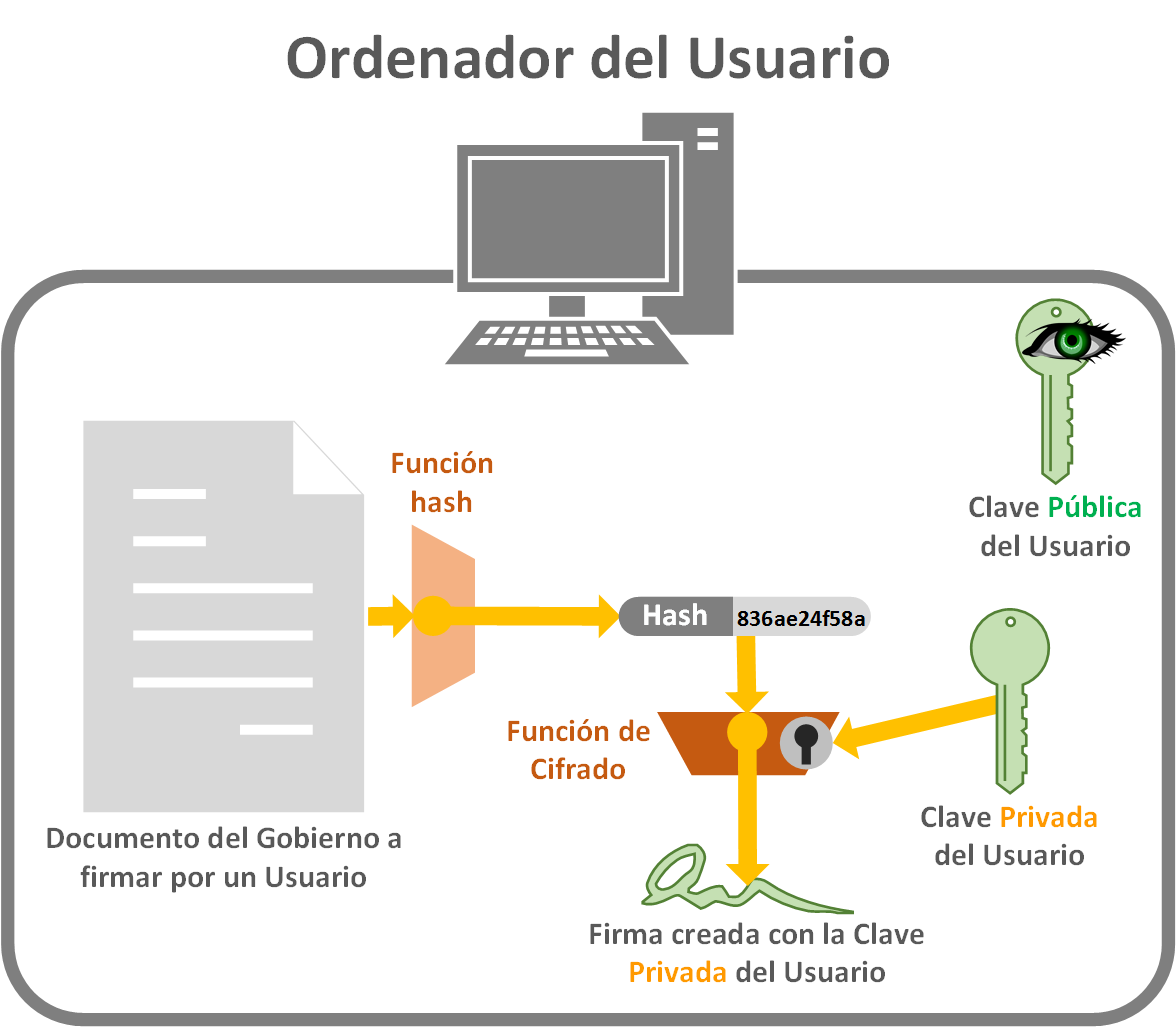
El usuario cumplimenta el documento. Lo puede modificar o no, la cosa es que el documento que va a entregar al Gobierno sea el que va a obtener el código Hash. Luego con alguna función de cifrado (como RC4, AES, etc; también hablaremos más de estos en artículos futuros, en la imagen de ejemplo lo llamaremos genéricamente como “Función de Cifrado”), cifraremos la función Hash con la clave Privada del usuario. El resultado es lo que se llama “Firma digital”. La “Firma digital” es nuestra firma en el documento, pues es lo mismo que firmar con un bolígrafo un documento en papel (de este modo podemos considerar la “Clave Privada” como el bolígrafo que agarra nuestra mano, y el código Hash como el hueco a firmar del documento en papel); salvo que la firma va a parte del documento, pero asociada a éste.
Ahora tenemos que mandar todo lo necesario a nuestro Gobierno y que nuestro Gobierno pueda asegurar que lo hemos firmado nosotros. Para ello enviamos a nuestro Gobierno el Documento del que obtuvimos el código Hash, la “Firma digital” de éste documento, y la “Clave Pública” (recuerdo que firmamos con la “Clave Privada”, que como su nombre indica es Privada nuestra y nunca deberá escapar de nuestro poder; sin embargo, la “Clave Pública” como si la publicamos en las redes sociales, es pública, y es para que todo el mundo la vea).
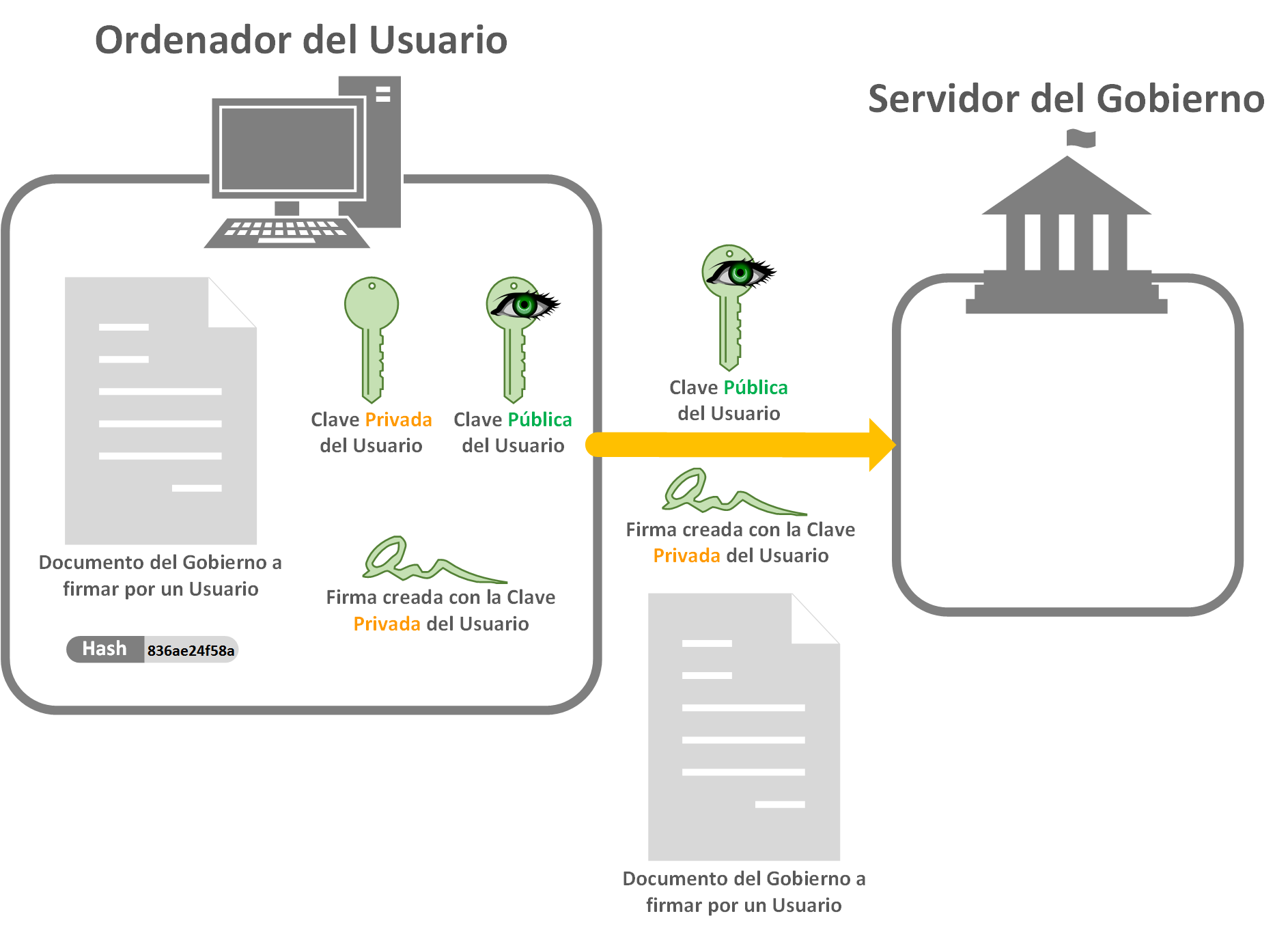
Nota de seguridad: Lo ideal sería que lo mandáramos por canal seguro como “HTTPS” para que nadie pudiera interceptar estos datos. Realmente cuando se hace todo esto de firmar digitalmente cualquier cosa, siempre se suele hacer por canales seguros.
Ya el Gobierno con todos los datos en su poder, puede hacer lo mismo, pero al revés (y lo que ya vimos). Es decir, obtener el código Hash del documento que le enviamos. Con la clave Pública descifrar la “Firma digital”, y al descifrarla obtenemos el código Hash que el usuario cifró con su clave Privada. Ahora comparamos los códigos Hash y si coinciden es que el usuario firmó realmente el documento.
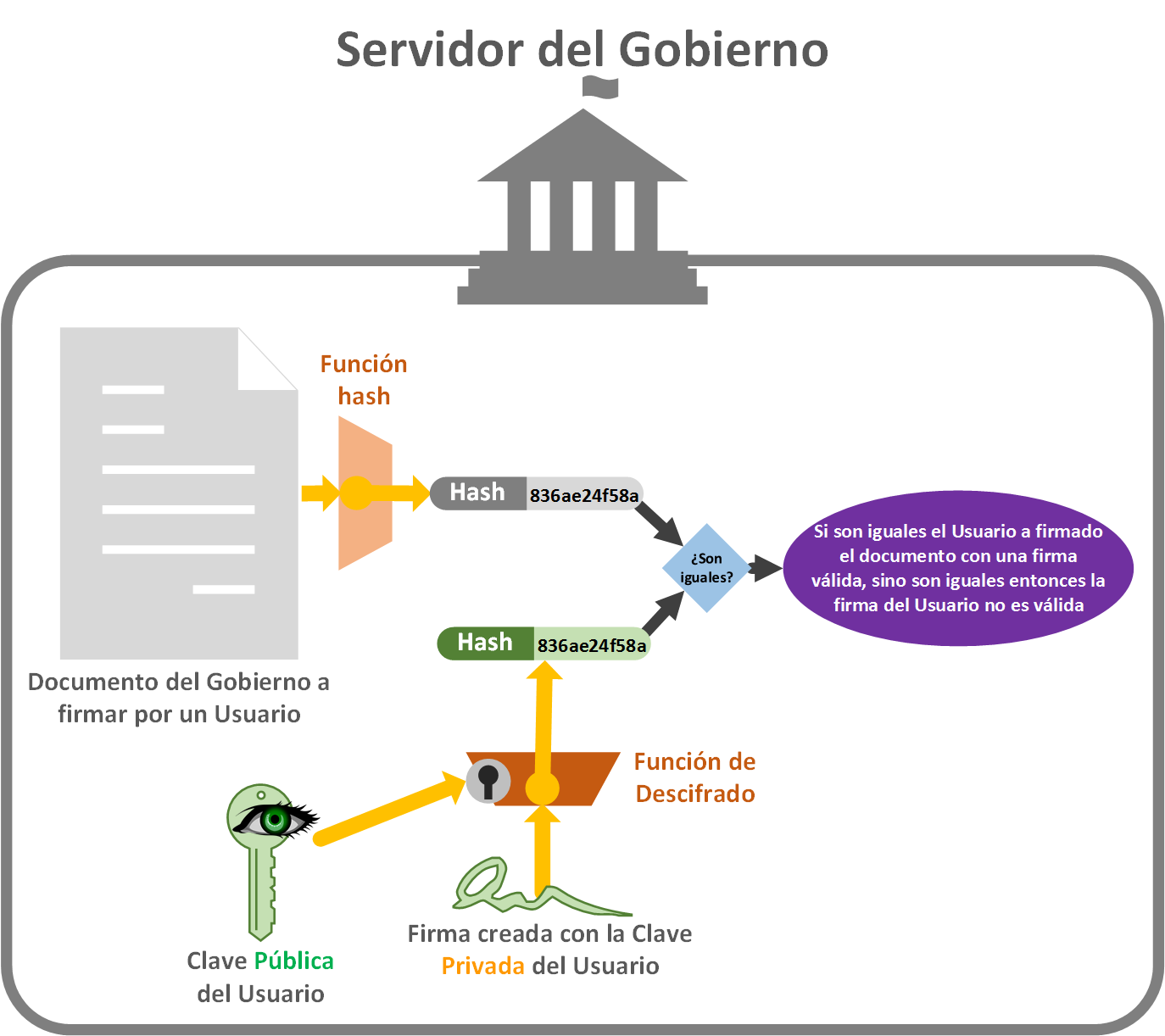
Indicar que el Gobierno tiene que tener alguna manera de asegura que la clave Pública del usuario pertenece a dicho usuario. Esto lo sabe porque el Gobierno tendrá en su base de datos la clave Pública asociada a cada usuario, por lo que sabe realmente a qué usuario pertenece (lo sabe porque es quién le ha creado anteriormente al usuario la “Clave Pública” y “Clave Privada”). También con una conexión HTTPS se asegura que sea un usuario en concreto.
¿Qué pasaría si Hacker Blackhat, realizando “man in the middle”, obtiene los datos que envía el usuario al Gobierno, falsifica el documento y lo envía al Gobierno como si fuera el usuario?
El Hacker Blackhat no puede firmar nada con la clave Privada del usuario, pues para eso se la tendría que habérsela robado (y si es una tarjeta como el DNI-e o una tarjeta bancaria, lo tiene complicado si no se la roba físicamente); por lo que no le queda otra que firmar con otra clave Privada diferente. De este modo al enviar al Gobierno el documento falsificado, otra firma diferente, y otra clave Pública diferente; el Gobierno sabrá de inmediato que esa firma no es del usuario (y si el Hacker Blackhat envió su propia clave Pública al Gobierno, el Gobierno encima sabrá quién es el falsificador).
Seguridad con las contraseñas en páginas webs
Para los desarrolladores que hayan hecho el típico formulario de “Usuario” y “Contraseña”. ¿Qué riesgos puede haber si la contraseña no se cifra de alguna forma? Pues muchos y muy gordos; teniendo el usuario y la contraseña de un usuario se pude saber cuál es la de otros servicios si utilizan la misma o una parecida (se puede obtener en cuestión de segundos si es parecida, pues se parte de una que utiliza el usuario y se prueba con la misma o parecidas en otros formularios de “Usuario” y “Contraseña” para ver si hay suerte; lo que es una poda en toda regla). Por lo que da igual si la contraseña está almacenada localmente o en un servidor. Si está en claro (si no está cifrada de ninguna forma; es decir, si el usuario introduce una contraseña como “12345a” y se guarda “12345a”, en vez de algo como “736f6e245d2a36f53”), si está almacenada localmente un intruso podría acceder a ella en claro (bien sea porque han robado el dispositivo, o mediante algún virus); y si la contraseña está almacenada en un servidor, aparte del anterior problema local, también podría verse comprometida por ataques “man in the middle” (que un tercero por el camino la robe). Motivos más que de sobra para poner medidas de seguridad, y que nunca se envíen o guarden contraseña en claro.
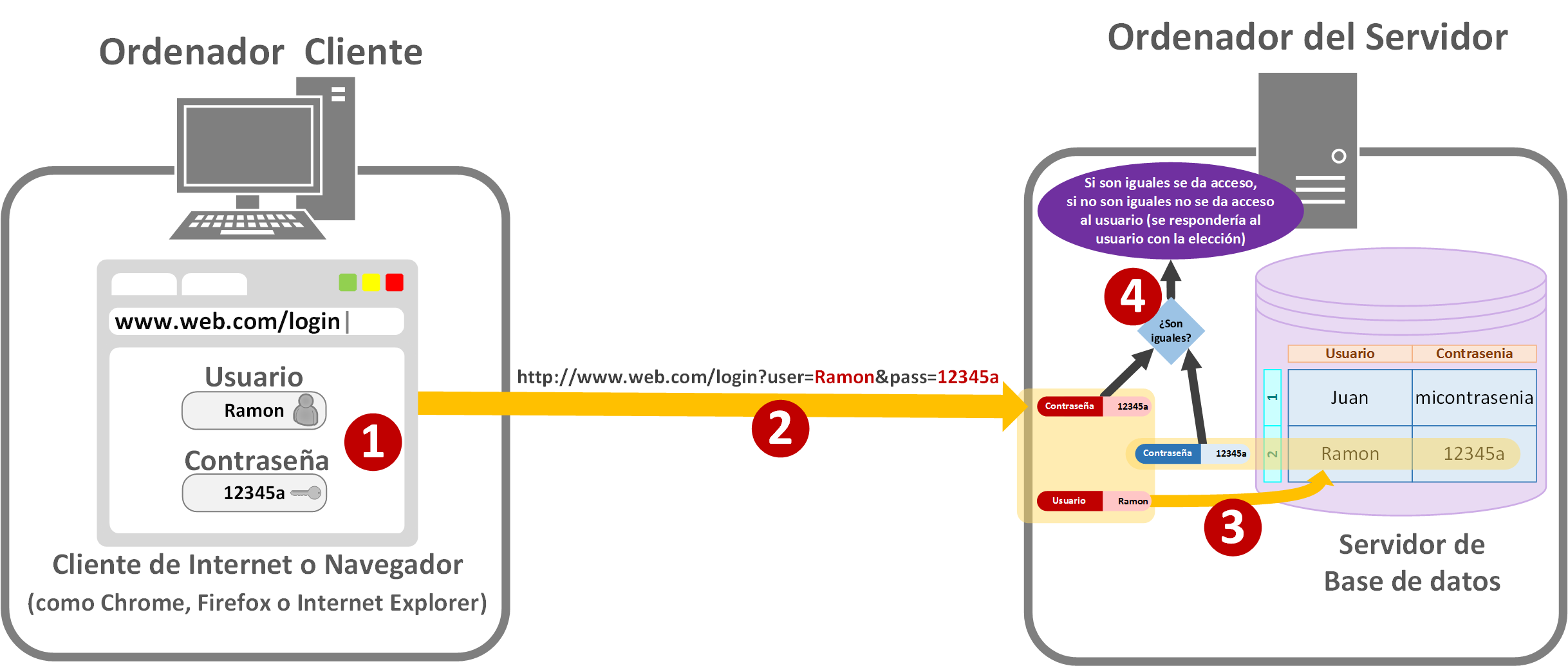
La siguiente imagen nos explica una forma mal (recalco muy mal; y lo he visto demasiado como para ser verdad) de enviar credenciales de acceso (normalmente usuario y contraseña) al servidor, y conceder acceso al usuario. En un primer paso el usuario introduce en la página de iniciar sesión de una web cualquiera sus datos de “usuario” y “contraseña” [1] (en la imagen he puesto para la demostración contraseñas típicas, consideradas inseguras como “12345a”; como usuario nunca se ponen contraseñas fácilmente deducibles, ni se repiten en otros sitios). El usuario no tiene ni idea que por debajo la contraseña y el usuario se están mandando de manera insegura y en claro en la propia URL [2]. En el servidor se buscará al usuario en la base de datos y se obtendrá la contraseña [3]; por desgracia para el usuario que no sabe que todas las contraseñas están almacenadas en claro también. Sabiendo la contraseña recibida y la que tenemos guardada se comparan y si es correcta se da acceso a la sesión del usuario [4] (en la imagen no hemos enviado la respuesta al usuario, para el caso no nos interesa; pero sería el siguiente paso indicarle al usuario si no se ha podido iniciar su sesión por el motivo que sea, o iniciar su sesión y darle acceso a lo que tiene permisos).
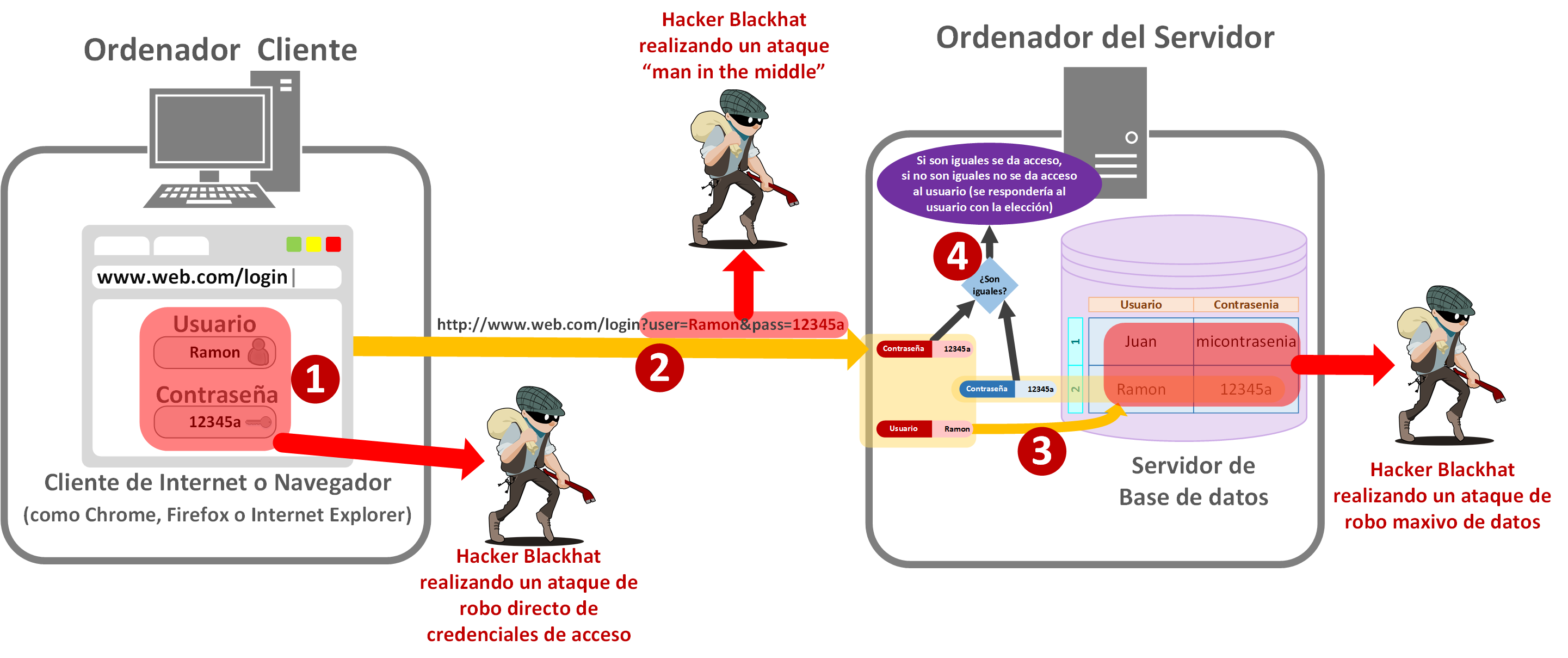
Cosas que están mal hechas en la anterior lógica (en la anterior imagen):
- Enviar en un “GET” la información (enviar la información en la misma URL), la información siempre se manda en “POST” (más información de “GET” y “POST” en https://jarroba.com/cliente-servidor-peticion-del-cliente/); esto es más por seguridad en la recepción de datos por el servidor que seguridad en la información en sí.
- Se está enviando en claro la contraseña al servidor.
- Se está enviando sobre “HTTP”, sin cifrar (“HTTPS” con “S” al final es cifrado).
- La contraseña en la base de datos del servidor también está en claro.
Para que te hagas una idea de por donde podrían venir los robos de información en el anterior proceso:
- En el ordenador del cliente: poco se puede hacer si se le ha colado un virus. Aquí la responsabilidad es del usuario, de tener siempre el sistema operativo y el navegador actualizado, además de contar con antivirus; o si se ha metido en una web falsa (Physing para robar datos de los usuarios). Por parte de los desarrolladores de la web, haber puesto HTTPS podría complicar el robo de credenciales al notificar al usuario el mismo navegador que la web visitada es la correcta y es segura, además, con “HTTPS” el navegador tiene políticas de protección adicionales (depende del navegador y con “HTTP” también las suele aplicar), como evitar el copiado automático del portapapeles por JavaScript.
- Durante el envío: un ataque “man in the middle” puede fácilmente robar las credenciales, y en el futuro acceder a la web como si fuera el usuario original. Esta parte es completa responsabilidad de quién diseño la web (el usuario ya nada puede hacer). Aquí es donde va a entrar el código Hash en acción para los desarrolladores, y sobre todo “HTTPS”.
En el servidor: creo que no hace falta que diga el problema que hay en grandes compañías cuando les roban la base de datos entera y las contraseñas están en claro o con una mala seguridad aplicada; que luego el usuario va a recibir un correo que dice algo así como: “Nuestra compañía no ha tomado medidas de seguridad mínimas y nos han robado todos los datos. Nada podemos hacer, con lo que tú el usuario tienes que cambiar la contraseña”. Es un problema muy gordo. Primero porque las contraseñas nunca deben estar en claro en el servidor, no existe razón alguna que justifique almacenar las contraseñas en claro (la única “excusa” que he escuchado es que quieran conocer la contraseña de los usuarios para hacer algún estudio, pero es que los resultados de esos estudios solo pueden ser malignos para intentar deducir otras contraseñas o algo así, de este modo no vale esta excusa tampoco); dicho de otro modo, no es ilegal, de momento, almacenar la contraseña en claro, pero como si lo fuera deberías de considerarlo.
Para solventar esto, lo que se hace es en el mismo formulario de “Usuario” y “Contraseña”, de la contraseña se obtiene le código Hash (podemos utilizar la función que queramos recomendadas seguras como “SHA1” o “MD5”). La contraseña nunca se guarda o envía a servidores externos, solo el Hash de la misma. De este modo aseguramos que si roban la contraseña no obtendrán la contraseña original.
Para el usuario es lo mismo, introduce el usuario y la contraseña en el formulario [1]. Pero antes de enviar por Internet (o por cualquier tipo de red) las credenciales, se obtiene el código Hash de la contraseña [2] (como antes recomendé, alguna versión de las funciones “SHA” o “MD”; si estás programando en cualquier lenguaje, tiene seguro dichas funciones para convertir de texto o bit a alguno de estos códigos Hash). Lo que se envía es el código Hash [3] (hemos protegido el envío de la contraseña; para proteger el resto de datos habrá que implementar otras medidas, aquí solo hablo de la contraseña). Como el servidor recibe el código Hash, lo que tendrá en la base de datos serán almacenados los Hashes de los usuarios [4] (Las contraseñas están cifradas de manera irreversible; teóricamente, en los siguientes párrafos explico el por qué). Ya solo queda la comparación [5].
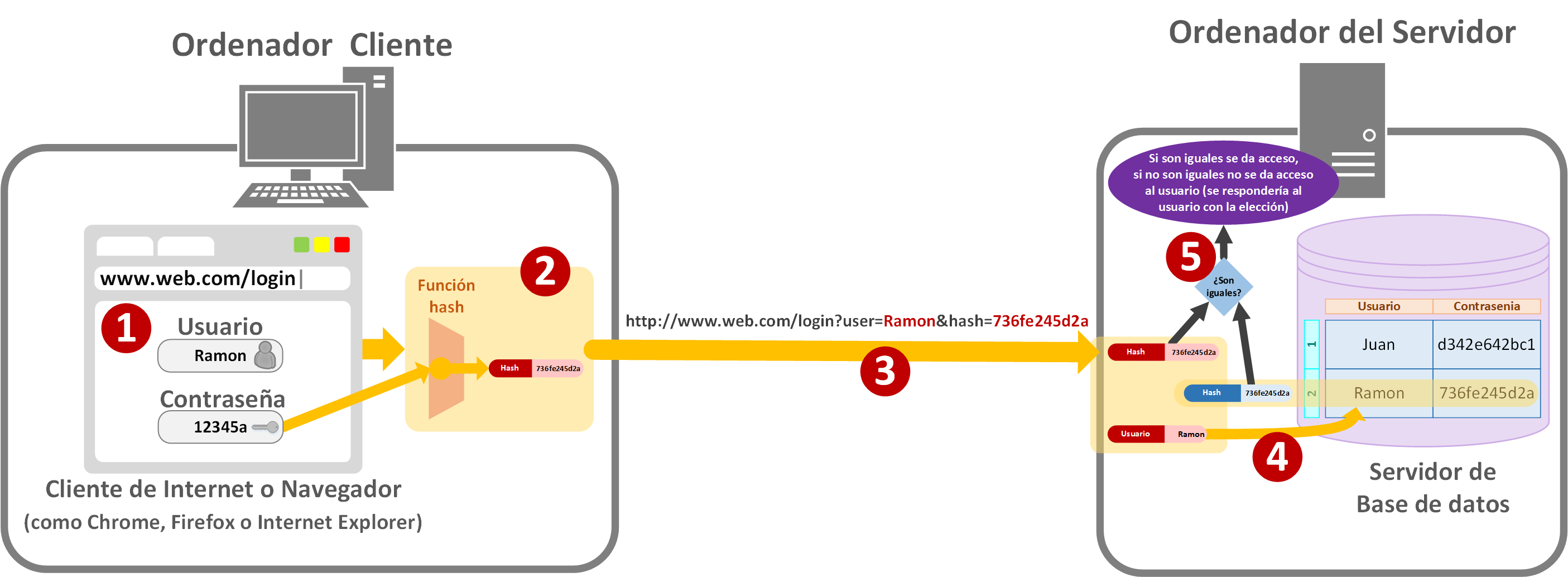
Si te fijas, hemos protegido todas nuestras responsabilidades para con la contraseña como desarrolladores. No hay que olvidar que también hay otros datos a parte de la contraseña.
Evidentemente esto es una capa de seguridad básica. Existen trucos. Como vimos anteriormente sabemos que a una cosa le corresponde un Hash, pero varios Hashes pueden corresponder a varias cosas (colisiones). El ladrón podría tener un mapeador de Hashes con varias contraseñas (conocido como "Tabla Arcoíris" o "Rainbow table", más información en https://es.wikipedia.org/wiki/Tabla_arco%C3%ADris) y reducir mucho las posibilidades. Por lo que además será interesante cifrar la base de datos o el envío de datos al servidor, así como tener seguridad mediante certificados.
Para evitar que el Hash de una contraseña sean siempre iguales se añade a la contraseña un Salt antes de procesado por la función Hash (más información en https://es.wikipedia.org/wiki/Sal_(criptograf%C3%ADa)). El Salt suele ser un valor aleatorio generado en el servidor, .
También podría ser interesante asegurar algunos de los problemas anterior citados (Existen muchas maneras de afrontar la seguridad; éste ejemplo básico no es para nada el más seguro, pero sí que complica los ataques), como crear primero un Hash de la contraseña (que será la misma que esté guardada en Servidor), y junto a la hora y minuto actual crear un nuevo Hash (Hash primero + hora y minuto), se envía al servidor y el servidor compara con lo mismo (Hash que tiene guardado + hora y minuto); de este modo se invalidan los Hashes cada minuto en caso de captura por un “man in the middle”, y se complica deducir la contraseña pues no es el Hash directo.
Si no podemos utilizar “HTTPS” (principal motivo porque suelen ser de pago los certificados), muy recomendable es utilizar un sistema OAuth (podemos utilizar los más famosos, como el de Google, el de Facebook, Twitter, Linkedin, Github, etc) para evitar tener que enviar credenciales de usuario. En pocas palabras, se envía un código Hash (que llaman “Token”) a los servidores de las marcas antes citadas para que validen al usuario.
De cualquier manera, una buena política de seguridad minimizará todos estos casos. Lo primero y más recomendable es emplear “HTTPS” por ejemplo (Esto ya se escapa a este artículo, lo explicaremos en un futuro artículo).
Tablas Hash (o Tabla de dispersión)
Información sobre Tablas Hash en el artículo dedicado de Tablas Hash pinchando aquí. Donde explicamos cómo funcionan, para qué sirven, y con ejemplos de código.
Funciones Hash famosas y recomendadas
Ya hemos llegado a las famosas funciones Hash. Es muy recomendable utilizar cualquiera de estas funciones Hash, sobre todo las más utilizadas o las nuevas (cuanto más moderna mejor cumplirán las propiedades, y más seguras son). Las que voy a exponer a continuación mayormente se utilizan en programación o a nivel de usuario (más abajo tienes ejemplos de uso); sin embargo, en redes compensa más otras funciones Hash como la del “bit de paridad” antes explicada, la “distancia mínima de Hamming”, o la “Suma modular”, o “Comprobaciones de Redundancia Cíclica, CRC”, entre otras (Detallaremos con más detalle en un futuro artículo, aquí solo me voy a centrar en su uso a un alto nivel).
A continuación, pongo las funciones Hash que por seguridad se recomiendan utilizar:
Message-Digest algorithm (MD; o en español, Algoritmo de resumen del mensaje):
- MD5: de 128 bits. Muy utilizado. Desaconsejado por cuestiones de seguridad. Se sigue utilizando para comprobar ficheros.
- MD6: de 256 bit, se procesa mediante multitarea. Nuevo algoritmo, recomendado para la seguridad.
Secure Hash Algorithm (SHA; o en español, Algoritmo de Hash Seguro). Tablas completas en https://en.wikipedia.org/wiki/Secure_Hash_Algorithm:
- SHA-1: 160 bits. Desaconsejado por cuestiones de seguridad. Se sigue utilizando para comprobar ficheros.
- SHA-2: de 256 bits (SHA-256) y 512 bits (SHA-512), existen otros. Muy utilizado, aunque desaconsejado por cuestiones de seguridad.
- SHA-3: de 256 bits (SHA3-256) y 512 bits (SHA3-512), existen otros. Nuevo algoritmo, recomendado para la seguridad.
El software que realiza los cálculos y las comprobaciones para estos, se denomina con el "nombre del algoritmo" terminado con prefijo "sum"; por ejemplo para "MD5" se diría “md5sum” o para "SHA-1" sería "sha1sum" (para "SHA" también se puede aludir al tamaño, como "sha256sum" o "sha512sum"). Si eres programador, lo vas a encontrar en prácticamente cualquier lenguaje de programación ya preparado para ser usado (y sino tendrás alguna biblioteca de externa seguro); si no eres programador, hay muchas aplicaciones que se pueden utilizar a nivel de usuario, como las mostradas en este artículo.
Comprobar ficheros descargados con un código Hash
Ahora toca ver algunos ejemplos prácticos de su uso a nivel de usuario. Como bien lees a “nivel de usuario” podemos comprobar cualquier fichero que nos descarguemos desde cualquier sitio de Internet siempre que venga acompañado del código Hash.
Puede que te hayas fijado que cuando te descargas algún fichero aparece al lado del botón de descargar alguno de los nombres ya vistos, como Hash, Resumen, Picadillo, Digest, Fingerprint, Checksum.
Normalmente los programas populares como Navegadores, juegos y otros programas diseñados para usuarios sin conocimientos técnicos suelen estar los códigos Hash algo más ocultos (pues un usuario normal no sabe para qué sirve ese número, no lo va a utilizar). Siempre existe algún lugar con el código Hash; normalmente en una página muy fea en blanco con solo letras (“página para usuarios avanzados” llamémosla), en la que solo aparecen los ficheros apelo con sus códigos hashes correspondientes.
Ver el código Hash directamente por el usuario
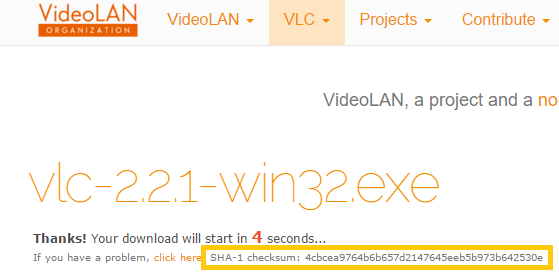
Por ejemplo, al descargar el famoso reproductor de vídeo VideoLAN (en https://www.videolan.org/index.es.html pinchamos en “Descargar VLC”):
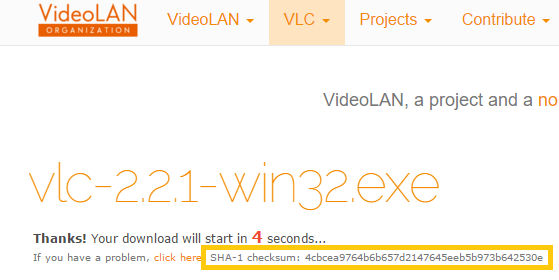
Podemos comprobar como efectivamente, adyacente a la descarga, aparece el nombre de “SHA-1 checksum” con el código Hash.
Otro ejemplo, al descargar el IDE Eclipse (en https://www.eclipse.org/downloads/, pulsamos en la versión que queramos descargar como la de “64 bit” de “Eclipse IDE for Java EE Developers”), podremos ver junto al botón de “Descargar” los códigos Hash MD5, SHA1 y SHA-512:

Hash de descargas oculto para usuarios
Por ejemplo, para descargar el Navegador Firefox los usuarios normales descargan la aplicación desde https://www.mozilla.org/es-ES/firefox/new/, donde NO veremos el código hash por ningún sitio ¿Por qué no ponen el código Hash en la misma web? Pues supongo que será por diseño o porque los usuarios sin conocimientos técnicos de informática no saben ni para qué sirve ese chorro de letras y números tan largo. Sin embargo, los usuarios avanzados pueden encontrar los códigos Hash desde la página fea que comentamos antes, la página del “historial de versiones liberadas (releases)” (o repositorio) en https://ftp.mozilla.org/pub/firefox/releases/, y actúa como un sistema de ficheros (sí, es realmente una carpeta con ficheros o más carpetas, como la de cualquier sistema operativo); así que seleccionamos una versión que queramos descargar (siempre recomendable descargar la última versión por cuestiones de seguridad y rendimiento del programa que descargaremos; yo por ejemplo he seleccionado la versión “43.0.4” cuyo contenido es el de la siguiente imagen). Dentro buscaremos el fichero de códigos Hash, que en este caso se llama “SHA512SUMS”.
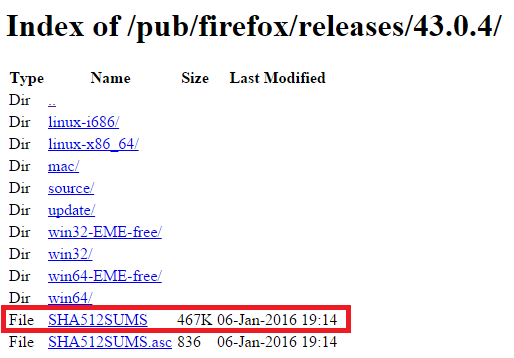
Y veremos que nos muestra un montón de códigos Hash ¡Que cunda el pánico 🙁 ! Digo… ¡Que NO cunda el pánico que es lo mismo que antes 🙂 !
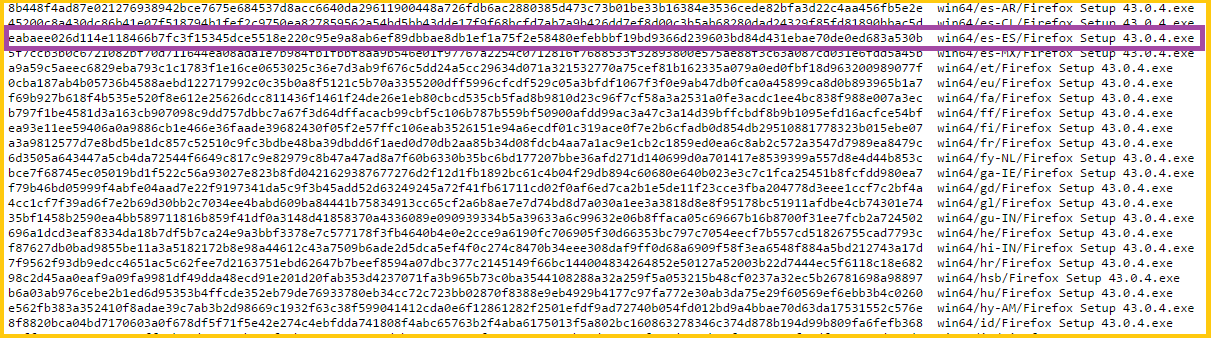
Es tan sencillo como ver que cada fila de izquierda a derecha corresponde con un fichero que podemos descargar. Por ejemplo, si queremos descargar Firefox para “Windows” de “64 bits” en “español de España” navegaríamos por el sistema de archivos a “win64” y luego a “es-ES”, cuya ruta final sería https://ftp.mozilla.org/pub/firefox/releases/43.0.4/win32/es-ES/, y ahí seleccionaríamos el ejecutable a descargar.

En estos “historiales de archivos liberados” veremos ficheros para todos los sistemas operativos y a su vez para todos los idiomas. Para el ejemplo anterior corresponderá con la fila “win64/es-ES/Firefox Setup 43.0.4.exe”; que a su vez es la misma ruta hasta el fichero que podemos descargar (como puedes ver resaltado en morado en la imagen de arriba de los códigos Hash).
Comprobar el código Hash a mano
Aunque en la mayoría de los casos el código Hash se comprueba automáticamente sin que nos demos cuenta y bastantes veces por segundo para diferentes cosas. Como, por ejemplo, cuando un instalador (al instalar o actualizar) de un programa pone algo así como “verificando instalación”, quiere decir que se están comprobando los ficheros, entre estas comprobaciones trabajan con códigos hash para comprobar la integridad de los archivos instalados.
Como hemos visto previamente de donde sacar los códigos Hash, ahora podemos comprobar los ficheros descargados a mano. Los pasos a seguir, como ya hemos visto, van a ser:
1.Descargar el fichero desde una página web que queramos (para seguir estos ejemplos, nos valdrá cualquier fichero que queramos que tenga un código Hash en la misma web de la descarga). Por ejemplo, yo voy a descargar de https://www.videolan.org/index.es.html el fichero “VLC media player”
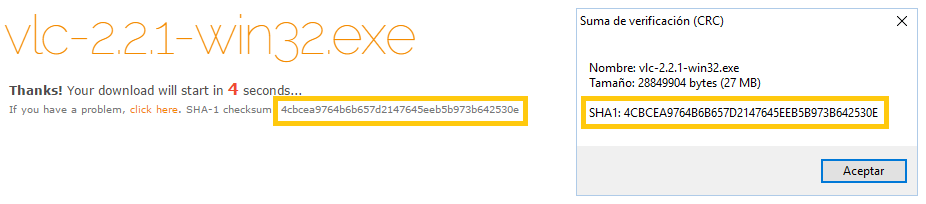
2. Copiar el código Hash y apuntar la función Hash con la que se obtuvo (como SHA2 o MD5) que proporciona la página web (junto al instalador normalmente, o en alguna página de repositorio de ficheros). Continuando con mi ejemplo apunto que la “función Hash” es “SHA-1”, y el código Hash es “4cbcea9764b6b657d2147645eeb5b973b642530e” (Nota: si estás siguiendo este ejemplo, puede que en la web haya cambiado el número del código Hash y no coincida con éste; es lo que tiene que ocurrir si actualizan el fichero)
3. Desde nuestro ordenador, de algún modo, calcular el código Hash del fichero descargado con la misma función Hash que hemos apuntado anteriormente. Continuaremos el ejemplo más adelante.
4. Comparar ambos códigos Hash. Si coinciden se ha descargado correctamente el fichero, sino coinciden el fichero se habrá descargado corrupto
Con el compresor 7zip (para Windows)
Con este programa compresor (similar a WinrRar o WinZip, pero gratuito y de código abierto) es muy sencillo, pues desde el menú contextual podemos comprobar el código Hash del fichero que queramos (aunque está limitado a SHA y CRC).
Descargamos el programa desde http://www.7-zip.org/. Ahí pulsamos en “Download”.
Cuando esté descargado lo instalamos normalmente.
Cuando esté instalado ya podremos comprobar el código Hash de cualquier fichero.
Será tan fácil como poner el cursor del ratón encima del fichero del que queramos obtener el código Hash (en mi ejemplo encima del ejecutable de “vlc”), pulsar con el botón derecho del ratón, elegir “CRC SHA” y luego la función Hash que queramos comprobar (en mi ejemplo “SHA-1”)
Al realizar el cálculo veremos que se nos abre la ventana donde aparecerá el código Hash calculado. De este modo podremos compararlos y ver si se ha descargado correctamente o no. Para mi ejemplo puedo comprobar que se ha descargado correctamente (no importa que estén en mayúsculas o minúsculas las letras):
Con Openssl (para Linux, iOS y Windows)
Este programa nos permitirá comprobar los códigos Hash SHA1, SHA224, SHA256, SHA384, SHA512, MD2, MD4, MD5, RDC2, RMD160. Hay que hacerlo desde la consola de comandos, pero es muy sencillo.
Además, Openssl nos permitirá mucho más, pues es un módulo criptográfico muy potente (como cifrar archivos con contraseña mediante diversas funciones de cifrado), aunque nosotros solo lo utilicemos para calcular el código Hash. Más información en https://www.openssl.org/docs/manmaster/apps/openssl.html
Podemos descargarlo desde https://www.openssl.org/source/

Descomprimimos el fichero donde queramos (en Windows podemos utilizar justo el compresor “7zip”, del anterior, ejemplo para ello).
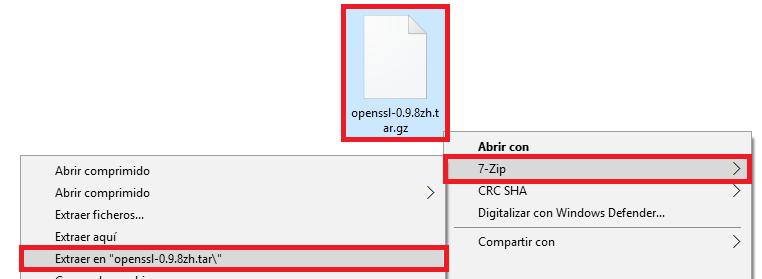
Si vamos dentro de la carpeta descomprimida veremos dentro de la carpeta “bin” que existe un fichero llamado “openssl.exe”.
En Windows, para abrir la consola de comandos podemos buscarla en el buscador de Windows escribiendo “cmd”. Para abrir la consola bastará con pulsar en el resultado denominado “Símbolo del sistema”.
En la consola nos dirigiremos a la ruta donde descomprimimos del fichero, escribiendo la palabra “cd” un espacio, para luego copiar la ruta entera de la carpeta donde está descomprimido el fichero “fciv.exe”. Quedando algo como:
cd C:\<miruta>\openssl-0.9.8h-1-bin\bin

Simplemente escribimos “openssl.exe”, un espacio, seguido de “sha1” o “md5”, otro espacio, y la ruta del fichero a comprobar (incluido el fichero a comprobar).
En mi caso del ejemplo que tengo el fichero “vlc-2.2.1-win32.exe” en la carpeta de descargas, pues lo acabe de descargar escribiría (truco: para no tener que escribir toda la ruta del fichero, podemos escribir “openssl.exe sha1 ” y luego arrastrar el fichero a la consola de comandos, así automáticamente nos escribirá la ruta):
openssl.exe sha1 C:\Users\<miUsuario>\Downloads\vlc-2.2.1-win32.exe
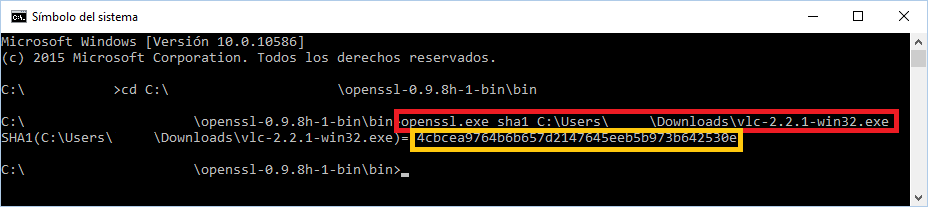
Nos calculará el código Hash que podremos comprobar. Como puedes ver más arriba, es el mismo que nos ofreció la página web, por lo que mi fichero se ha descargado correctamente.
Desde la consola de Windows con Microsoft File Checksum Integrity Verifier (para Windows)
Con este programa podremos comprobar códigos Hash SHA1 y MD5. También es desde la consola de comandos, aunque también es muy fácil.
Descargaremos Microsoft File Checksum Integrity Verifier desde la siguiente dirección
https://www.microsoft.com/en-us/download/details.aspx?id=11533
Pulsando en el botón “Download” se nos descargará el archivo.

El archivo que se ha descargado realmente es un comprimido que podremos abrir con cualquier compresor o haciendo doble clic en él (como si lo fuéramos a instalar). Aquí te explicaré haciendo doble clic en el archivo.
Saldrá un cuadro legal que aceptaremos en “Yes”.
Luego en “Browse…” buscaremos algún lugar para descomprimirlo como el escritorio directamente (son dos archivos, de los cuales nos vale uno solo) o como en el siguiente ejemplo, donde he creado una carpeta llamada “FCIV”. Luego pulsaremos “OK” y se nos descomprimirá.
Veremos que hay dos ficheros. Uno llamado “ReadMe.txt”, y el que realmente nos interesa el nombrado como “fciv.exe”. Aquí no lo abriremos, para ello utilizaremos la consola de comandos.
Abriremos la consola de comandos (buscándola en el buscador de Windows como “cmd”, y seleccionaremos el resultado “Símbolo del sistema”)
Para empezar, iremos a la ruta donde descomprimimos el fichero escribiendo la palabra “cd” un espacio, para luego copiar la ruta entera de la carpeta donde está descomprimido el fichero “fciv.exe”. Quedando algo como:
cd C:\<miruta>\FCIV
Ya estamos preparados para obtener el Hash de cualquier fichero.
Solo tendremos que escribir “fciv.exe”, un espacio, seguido de “-sha1” o “md5”, otro espacio, y la ruta del fichero a comprobar (incluido el fichero a comprobar).
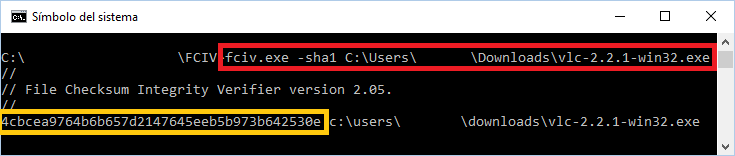
Para mi ejemplo con el fichero “vlc-2.2.1-win32.exe” que lo tengo en la carpeta de descargas (truco: para escribir rápidamente la ruta del fichero en la consola de comandos, podemos escribir “fciv.exe -sha1” y luego arrastrar el fichero a la consola de comandos, nos escribirá la ruta automáticamente):
fciv.exe -sha1 C:\Users\<miUsuario>\Downloads\vlc-2.2.1-win32.exe
Esto calculará el código Hash que podremos que es el mismo que nos ofreció la página web (como puedes ver más arriba); es decir, mi fichero se ha descargado correctamente.
Calcular código Hash con programación
No puedo despedir el artículo sin lo que considero más importante, y para concentrarlo todo en uno solo: la programación. Expongo la manera de hacerlo en algunos lenguajes de programación, y no son ni los únicos lenguajes que pueden ni las únicas maneras de hacerlo.
Para todos los ejemplos, comenzaremos con un Mensaje cuyo contenido es “El mensaje original”, del que queremos obtener la función Hash MD5 en Hexadecimal (podríamos dejarlo en bytes, es perfectamente válido para hacer cálculos; pero los voy a presentar todos en Hexadecimal que suele ser como se ven habitualmente). Además, en todos los ejemplos podremos ver por consola o en el navegador la siguiente salida:
Mensaje 'El mensaje original' -> Hash MD5: 80c6973ef9ed92f123044cd5c4f7d954
Nota: fíjate como nos da el mismo código Hash para el mismo Mensaje independientemente del lenguaje utilizado.
Java
Todo lo que tenemos que hacer es lo siguiente.
String mensaje = "El mensaje original";
byte[] bytesDelMensaje = mensaje.getBytes();
MessageDigest resumenDelMensaje = MessageDigest.getInstance("MD5");
byte[] bytesDelResumen = resumenDelMensaje.digest(bytesDelMensaje);
BigInteger resumenNumero = new BigInteger(1, bytesDelResumen);
String resumen = resumenNumero.toString(16);
System.out.println("Mensaje '" + mensaje + "' -> Hash MD5:" + resumen);
Utilizando la función MessageDigest (http://docs.oracle.com/javase/6/docs/api/java/security/MessageDigest.html), que pide el mensaje en bytes y devuelve el resultado en bytes. Lo que he hecho, como es lógico, al mensaje convertirlo de String a byte[], indicar a MessageDigest que quiero que lo procese con la función Hash “MD5”, y al Resumen que lo devuelve en byte[]; este byte[] hay que convertirlo a número entero, pero como es muy grande utilizaremos BigInteger() al que le pondremos le máximo de tamaño poniendo “1” (más información en https://docs.oracle.com/javase/7/docs/api/java/math/BigInteger.html#BigInteger(int,%20byte[]) ), y lo convertiremos a un número Hexadecimal con “toString(16)” y además a String, de este modo podemos ya mostrarlo por pantalla.
De este modo el resultado por consola es:
Mensaje 'El mensaje original' -> Hash MD5: 80c6973ef9ed92f123044cd5c4f7d954
Te facilito la clase con el ejemplo completo a continuación:
import java.math.BigInteger;
import java.security.MessageDigest;
import java.security.NoSuchAlgorithmException;
public class miClase {
public static void main(String[] args) {
String mensaje = "El mensaje original";
byte[] bytesDelMensaje = mensaje.getBytes();
MessageDigest resumenDelMensaje = null;
try {
resumenDelMensaje = MessageDigest.getInstance("MD5");
byte[] bytesDelResumen = resumenDelMensaje.digest(bytesDelMensaje);
BigInteger resumenNumero = new BigInteger(1, bytesDelResumen);
String resumen = resumenNumero.toString(16);
System.out.println("Mensaje '" + mensaje + "' -> Hash MD5: " + resumen);
} catch (NoSuchAlgorithmException e) {}
}
}
Javascript
En JavaScript no incluye por defecto ninguna biblioteca de criptografía, pero podemos descargar o asignar directamente desde su web desde https://code.google.com/p/crypto-js/downloads/list
Yo lo voy a añadir directamente desde su web para no complicarlo. Añado entre los tags “head” lo siguiente:
<script src="http://crypto-js.googlecode.com/svn/tags/3.1.2/build/rollups/md5.js"></script>
Y simplemente en el JavaScript.
var mensaje = 'El mensaje original';
var resumen = CryptoJS.MD5(mensaje);
document.write("Mensaje '" + mensaje + "' -> Hash MD5: " + resumen);
la segunda línea “CryptoJS.MD5()” calculará el resumen del mensaje. La última línea “document.write()” (lo podemos sustituir por un “console.log()” para que escriba por consola) es para ver el resultado directamente en nuestro navegador favorito (lo escribe directamente en el “body”).
Podremos ver:
Mensaje 'El mensaje original' -> Hash MD5: 80c6973ef9ed92f123044cd5c4f7d954
Ahora el ejemplo completo:
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>Calcular MD5</title>
<script src="http://crypto-js.googlecode.com/svn/tags/3.1.2/build/rollups/md5.js"></script>
</head>
<body>
<script>
var mensaje = 'El mensaje original';
var resumen = CryptoJS.MD5(mensaje);
document.write("Mensaje '" + mensaje + "' -> Hash MD5: " + resumen);
</script>
</body>
</html>
PHP
Con PHP es muy fácil calcular el MD5 de un texto:
<?php $mensaje = 'El mensaje original'; $resumen = md5 ( $mensaje ); echo "Mensaje '$mensaje' -> Hash MD5: $resumen"; ?>
Y al ejecutarlo devuelve:
Mensaje 'El mensaje original' -> Hash MD5: 80c6973ef9ed92f123044cd5c4f7d954
Bibliografía
- Apuntes personales tomados a mano en la clase de la asignatura de “Fundamentos de la Seguridad de la Información”. Impartida por Juan Alberto de Frutos Velasco, para la UPM
- Transparencias de “Tablas Hash”. De Jenifer Pérez Benedi, para la UPM
- Transparencias de “Transformación de claves (Hashing)”. De Jesús Alonso Segoviano, para la UPM
- Experiencia propia del autor de éste artículo
- http://www.pa.msu.edu/reference/jdk-1.2.2-docs/tooldocs/win32/jarsigner.html
- https://support.microsoft.com/en-us/kb/841290
- http://www.win.tue.nl/hashclash/rogue-ca/
- https://www.schneier.com/blog/archives/2012/10/when_will_we_se.html
- http://docs.oracle.com/javase/6/docs/api/java/security/MessageDigest.html
- https://en.wikipedia.org/wiki/MD5
- https://en.wikipedia.org/wiki/MD6
- https://en.wikipedia.org/wiki/Secure_Hash_Algorithm
- https://en.wikipedia.org/wiki/Man-in-the-middle_attack
- https://en.wikipedia.org/wiki/Hash_function
- https://en.wikipedia.org/wiki/Cryptographic_hash_function

Simplemente felicitarte por el magnífico post. Cuando explicamos algo, solemos dar por hecho que el receptor de nuestra explicación tiene amplios conocimientos sobre el tema, y ahí está el gran error. Tu artículo es absolutamente genial e inteligible para todos los públicos. Gracias.
Me alegra que te haya servido Antonio, gracias por tu comentario!
hay alguna manera simple de ver el código hash del sistema operativo (windows 10) mediante comando CMD???
Está la utilidad certutil para obtener el hash de los ficheros por CMD: https://docs.microsoft.com/es-es/windows-server/administration/windows-commands/certutil
hola ramon, escribo por que estoy haciendo un trabajo final de clase y mi tarea es hacer que un texto sea codificado utilizando el algoritmo x11, pero debo desarrollar mi programa para que al introducir el texto me de el codigo, no puedo utilizar programas ni aplicaciones que ya esten en internet, debo crear la mia. espero me puedas ayudar, saludos
Podrías utilizar alguna biblioteca que implemente X11 o si tienes que construir tu mismo el algoritmo tendrás que buscar información del algoritmo (como por ejemplo en )
Hola hola buenas tardes Ramón me resulta muy interesante tu artículo y esque estamos haciendo la tesis y tu tema está íntimamente relacionado con lo q estamos investigando, podrías ayudarnos por favor! Esa es la primera vez q leo algo sobre este tema
Hola Luis ¿Qué necesitáis? Si te puedo ayudar dalo por hecho 🙂
hola,
hay alguna forma de setear o cambiar el largo del codigo HASH del SHA512?
.. ya que me retorna 128 caracteres y quiero menos. gracias.
Si quieres que sea más corto tendrías que utilizar otro diferente
Un código Hash generado por SHA512 siempre va a ser de 512 bits, cuya conversión a hexadecimal siempre son 128 caracteres hexadecimales.
Podrías utilizar otro SHA que devuelva menos bits, como SHA256, pero perderías seguridad.
Por otro lado, calcular un SHA512 y cortar el valor de salida sería contraproducente, pues generaría infinidad de colisiones no previstas.
Disculpen me a surgido otra duda, estoy haciendo una función en java dentro de un servlet que me convierte algunos datos con SHA-512. Mi duda es, si ademas estamos trabando con certificados de seguridad, me volvera a convertir la informacion que ya se encuentra encriptada.??
Al trabajar con redes, la capa de seguridad ya cifra el contenido que mandas. Si lo cifras en tu código se estaría cifrando dos veces (una en tu código y otra al pasar a la capa de presentación del modelo OSI se cifra otra vez https://es.wikipedia.org/wiki/Modelo_OSI)
Muchas gracias por la aclaracion.
Buenas tardes Ramón, quisiera ver si me puedes aclarar la siguiente duda. por lo que tengo entendido, las claves hash por temas de seguridad, no se pueden reversar, osea una vez que se convierte la información a SHA-512 no hay manera de volver a recuperar la información. Esto es verdad.?? Por que cuando se trabaja con certificados de seguridad, si bien la información viaja encriptada, con la llave privada se puede volver a recuperar la información a texto claro. ¿esto es verdad?
La idea es que no se pueda ir de un Hash al dato original, pero existen ciertos trucos donde se podría crear un diccionario de tal Hash corresponde a tal dato (como el ataque «Rainbow table»), pero es limitado pues un Hash puede corresponder a miles de datos.
Piensa en un libro, una novela, y que escribes un resumen de dicha novela. Por ejemplo: La novela del «Conde Drácula» podríamos resumirla como «trata de vampiros», pero es que hay muchos libros que «tratan de vampiros». Es imposible de un resumen escribir el libro, pero sí que podríamos buscar todos los libros del mundo y encontrar los que «tratan de vampiros». Es un trabajo monumental, que no suele producirse. Se suele utilizar para claves con el ataque anterior «Rainbow table» que indiqué, pues son textos cortos; pero de un hash obtener por ejemplo, el código de una película, es imposible (salvo que se clasifique, y por las colisiones podría ser muchas cosas).
Entones ¿Es seguro? Sí y mucho, pero hay que utilizarlo con cabeza, entendiendo la teoría y como funciona el mundo de los códigos Hash.
Muchas gracias y los felicito por el contenido esta muy bueno.
Estimado
Lo que no me queda claro es como hago la funcion Hash para un cierto dato?
Puedes diseñar una función Hash, lo suyo es utilizar una ya creada (como SHA o MD).
En el final del artículo hay ejemplos de código como Java y Javascript, así como ejemplos de programas.
Me quedo claro ahora que la indexación se realiza antes de la búsqueda. Pero mi pregunta era otra. Yo me refiero a como la persona es consciente del proceso de idexación, es decir, se me ocurre que si yo soy desarrollador por ej y se que el archivo de la factura empieza en la direccion 33 entonces creo el hash 7 para factura y en esa direccion guardaria la direccion 33 no? Pero si la indexacion la hace el sistema operativo como sabe que yo quiero que la direccion 33 este guardada en la direccion 7? Espero haber sido un poco mas claro jaja, y disculpa por la molestia.
Lo unico que se me ocurre es que el sistema operativo sea el que haga la cuenta de la cantidad de letras y mande la primera parte del archivo a esa posición.
Un usuario normal vería algo así como «indexando…» durante el proceso de indexación.
Se sabe que se quiere guardar en la dirección 7 la dirección 33 porque se ha revisado toda la memora buscando todos los archivos y mapeándolos uno a uno. Es decir, durante la indexación el sistema de indexado habrá recorido una a una las direcciones de la 33 a la 64 buscando cualquier comienzo de fichero (ficheros ya almacenados previamente) para crear la tabla hash (de este modo ya sabe que posiciones guarda en la memoria los archivos y puede apuntar a ellos). Dicho de otra forma, la primera vez hay que hacer un rastreo completo de toda la memoria buscando todos los archivos que existan para crear la tabla hash, luego ya no hará falta más que detectar cambios en lor archivos para actualizar la tabla hash.
Espero que haya quedado más claro 🙂
Ahora si me quedo clarísimo. Gracias!
Comentarios referidos a Tablas Hash. Hemos separado Tablas Hash a otro artículo en http://jarroba.com/tablas-hash-o-tabla-de-dispersion/
Muy buen artículo. Tengo una duda. Como hace internamente el sistema operativo para indexar la dirección de memoria surgida del hash con la dirección del archivo? Entiendo que en cada dirección de memoria surgida del hash se guarda la dirección de comienzo del archivo, pero me refiero a como se deduce ese indexamiento en el momento exacto de la búsqueda.
Me explico. Si por ej yo busco Factura iría directamente a la posición 7 de la memoria , ahora bien, como hace internamente el sistema operativo(o lo que sea) para darse cuenta al instante que en esa posicion 7 tiene que estar guardada la dirección de memoria donde comienza Factura? Por mas que yo sepa que logicamente tiene que estar ese valor, pero como hace para deducirlo. Espero haber sido claro jaja
Hola Nicolas, buena pregunta. Cuando pone «indexando» (normalmente la primera vez que se instala el sistema operativo, o cuando se añaden nuevos ficheros; es decir, siempre la primera vez que se añade el fichero o la primera vez que el sistema de indexado existe en un sistema de ficheros) en ese momento, el sistema operativo (o quien cree la indexación) hace todas las operaciones de hash una a una sobre todos los ficheros para crear un mapa completo de punteros apuntando a archivos. De este modo ya tiene precalculadas todos los apuntadores desde el código Hash a los archivos; así se puede realizar búsquedas instantáneas 🙂
En resumen a la pregunta: no se calculan durante la búsqueda, sino antes de la búsqueda tienen que estar calculada la tabla hash (podría estar calculada la tabla hash días antes de la búsqueda; piensa la primera vez que compras un ordenador -venga con el sistema operativo que venga- y lo encinedes, todavía no puedes buscar inmediatamente, pero al día siguiente normalmente sí, pues está ya todo calculado). Solo se actualizaría la tabla hash si el archivo se borra, se mueve o si se añade uno nuevo.
Espero que quede más claro. De cualquier manera voy a revisar la explicación del artículo para aclararlo mejor.