ETL: Extraer, Transformar y Cargar
ETL sirve para el procesamiento masivo de datos (Big Data), en tiempo real (o lo más cercano posible) y se resume en:
- Extraer (Extract): obtener los datos desde diferentes fuentes.
- Transformar (Transform): normalizar todos los datos a una estructura que nos sea útil.
- Cargar (Load): colocar los datos en algún lugar desde donde podamos utilizarlos.

Parece simple, pero para entender la complejidad de cada parte (La “E”, la “T” y la “L”) podríamos utilizar el dicho popular: <<El diablo está en los detalles>> Pues lo que realmente hace que cada parte requiera de una experiencia muy profesional son los numerosos detalles que hay que entender y los abundantes conflictos que hay que resolver: como toma de decisiones rápidas o solventar conflictos (algunos conflictos son bastante paradójicos, pues no son tan rápidos ni evidentes); estos últimos requerirán de la toma decisiones casi adivinatorias y de antemano a conocer mucho más de lo que realmente se necesita, que solo una buena experiencia puede acertar más y aminorar las futuras modificaciones, las cuales muy probablemente tendremos que realizar a medida que se vaya convirtiendo las decisiones previamente tomadas en realidad, pues con la realidad será cuando nos vayamos topando con los problemas.
Veremos bastantes y sus soluciones, pues son tan numerosos y cambiantes que muchas veces la única manera de conocerlos es enfrentándose a ellos. Por lo que trabajar con ETL es un proceso laborioso, de investigación constante y de negociación entre partes.
Extract: Extracción o Recolección
¿Quién?: El poseedor de los datos
Primero, hay que conocer desde quién vamos a extraer o recolectar los datos.
Pues no es lo mismo extraerlos desde el ordenador de mi casa, que seguramente sea yo quien tenga todo el control de los datos (por ejemplo, si tengo ficheros de Excel, Words y blocks de notas, o si somos más manitas y nos montamos un Arduino o Raspberry con sensores que recojan información); o que conozca los datos o tengo un acceso de barra libre a los datos (como por ejemplo los datos que genera el sistema operativo de mi portátil o de mi móvil); y más libertad tendré si los datos son creados por mí (es decir inventados por mí). De cualquier manera, si los datos impliquen o pertenezcan a un tercero, aunque sean míos, quedará en nuestra responsabilidad lo que hagamos con ellos y de conocer la licencia o legalidad que los protege.
Luego están los sitios web públicos, como puede ser una web o un repositorio de datos (como Kaggle), desde donde podremos obtener datos, aunque limitados y con una licencia que deberemos de respetar.
Por otro lado, si extraemos datos de una organización o una empresa, bien porque trabajemos para la misma o sea nuestro cliente, tendremos que pasar rigurosos controles de seguridad para extraerlos, conocer sus políticas y lo más importante, conocer las leyes actuales para el tratamiento de la información dependiendo de la región que le afecte (pues hoy día no son las mismas leyes las europeas, que las americanas o las chinas). Más todavía cuando la empresa trata datos sensibles como puede ser un banco o un hospital, por lo que deberemos tener mucho cuidado con los datos.
Aquí puede surgir uno de los principales problemas paradójicos cuando se trata con datos de clientes. El cliente quiere que trates su información, pero por protección de sus datos no te quieren dar su información <<Quieren, pero no quieren>> Y yo entiendo las dos posiciones tan contrarias, pero tengo que resolver este dilema, pues es mi trabajo ¿Cómo lo resolvemos? Pues normalmente explicándole al cliente el por qué necesitamos la información, que es el siguiente punto.
Nota recordatoria sobre los datos: Los datos tienen derechos de autor, están sujetos a leyes territoriales y a la protección del dato.
¿Por qué?: Motivo por el que necesitamos la información
Debemos tener un buen motivo para acceder a la información de alguien.
Si trabajamos en una empresa, el motivo menos eficaz es el <<me lo ha pedido el jefe>> Quizás funcione, pero necesitamos algo más. Si se los pedimos al responsable de la base de datos desde donde queremos extraer la información nos preguntará ¿Y para qué los vas a utilizar? Que lo haya pedido el jefe no es motivo suficiente, pues el trabajo de esa persona responsable es precisamente tener un control de los datos tan valiosos de la empresa, custodiar los datos y complicar su entrega, precisamente para no dárselos a cualquiera (Pues hay que evitar el robo de datos empresariales y filtraciones de los mismo, si cualquiera pudiera llegar a la fuente de los datos fácilmente, para alguien con malos principios, como un ladrón de datos, lo tendría fácil). Habrá que llevar bien definidos los motivos para explicar para qué vamos a utilizar los datos, luego no deberíamos tener problemas para acceder a ellos, sino tendríamos que escalarlo al responsable para que nos den permiso o una manera de llegar a los datos que necesitamos.
¿Dónde?: La fuente del dato desde donde extraer
Una fuente de datos puede venir de una única máquina o estarán distribuidos en varias. En cualquiera de los casos, tendremos que asegurar que todas las máquinas con los datos estén disponibles para trabajar con ellos (si es una sola máquina es fácil detectar su falta pues no obtendríamos nada, pero si son datos distribuidos puede que obtengamos una porción de los datos y nos falten otros; existen mecanismos automáticos para prevenir esto, pero no está de más conocer el sistema con el que trabajamos por lo que pueda pasar).
La fuente de los datos nos puede devolver los datos de formas muy variadas, como:
- Ficheros: no es lo mismo que venga en fichero de texto plano o un Excel que podremos abrir y extraer lo que necesitamos. Así mismo, los ficheros presentan datos en múltiples tipos, como en formato JSON, tabulados, separados por comas o CSV, un volcado de un scraping de una web (donde tendremos el HTML), comprimidos, codificados, cifrados, etc.
- Bases de datos: tendremos datos limitados a dichas consultas, a los recursos disponibles de la máquina y vendrán en el formato que se definan.
- Servicios online: operaciones REST (que suelen venir en JSON), SOAP, streaming (Kafka, Flume, Kinesis, etc.), sockets TCP (u otros sockets, como los web sockets si estás trabajando a nivel de web; puedes leer un ejemplo de sockets paso a paso y la diferencia con web socket en este otro artículo dedicado que te dejo pinchando aquí), entre otros.
- Comprimidos: Los datos de cualquier fuente pueden venir comprimidos, esto es importante pues en algunos casos podremos leer los datos sin descomprimir y tendremos que saber cómo descomprimirlos, luego habrá que trabajar con el formato del dato que venga dentro.
- Cifrados: necesitaremos descifrar los datos previamente para acceder a ellos.
- Formatos extraños: datos de lo más extravagante, tanto que, aunque sean texto claro, necesitaremos de algún entendido o documentación que nos explique cómo interpretarlos de la manera correcta.
¿Cómo?: la manera de trabajar con los datos
Teniendo acceso a los datos nos queda echar un vistazo a los mismos. Si es un fichero, es abrir el fichero y mirar lo que tiene dentro; si es una base de datos, quizá nos baste con realizar una consulta.
- Analizar los datos: nos daremos cuenta de los primeros detalles que tendremos que solucionar: uno de los más visibles son los caracteres raros o los rombos con interrogación, quizás los datos vengan mal por algún motivo o simplemente es la codificación de caracteres, tendremos que descubrir si se pueden reparar de alguna manera, si se pueden recibir de otra forma o averiguando su codificación si fuera el caso.
- Verificar si los datos cumplen lo que se espera de ellos: por ejemplo, si nos dicen que tenemos que extraer textos y no hay textos en los datos, es que algo pasa. También podrá ser útil realizar gráficos estadísticos y conteos de los datos para tener una primera impresión sobre la calidad de los datos en su conjunto y para saber si tenemos todos los que esperamos.
- Tamaño de los datos y la capacidad del origen: El tamaño de los datos es importante, pues si extraemos a la vez todos los datos de un servidor puede que lo colapsemos por ser demasiados, quizás no interese buscar horas de extracción que no esté siendo usado el servidor o extraer los datos por streaming en un ancho de banda limitado.
- Conocer el formato de los datos para saber cómo extraerlos: por ejemplo, un fichero Excel si se abre como un fichero plano descubriremos que es un galimatías, pero tendremos que entender dicho galimatías para extraer los datos o utilizar alguna API o programa que nos ayude.
- Dependencias entre datos: pueden existir dependencias entre datos, quizás tengamos que rescatar la parte que falta de otro lugar para completarlos o realizar las uniones pertinentes (por ejemplo, en datos sobre libros vienen direcciones de descarga del texto completo de cada libro, que como era mucho la base de datos antigua se pusieron por separado, y ahora nuestro cliente quiere tener los datos de los libros junto con el texto completo de cada uno).
¿Cuándo?: el momento adecuado de extraer los datos
Como hemos mencionado antes, el momento de la extracción es importante para que los servidores no colapsen, pero también por otros motivos, como que queremos que los datos se procesen periódicamente (Por ejemplo, trabajamos en una oficina donde los datos se están produciendo durante todo el día y nos vale con tener los datos al final del día, entonces, para asegurar tener los datos del día los extraemos todas las noches).
Formas de ejecutar la extracción de datos en el momento que queramos:
- Programados: CRON, bucle, servidor, servicio.
- Suscritos: Push, Pull. Algunos servicios permiten suscribirnos para recibir los datos mediante Push, es decir, cuando estén disponibles y el servicio esté listo para enviárnoslos.
- A petición: Script, aplicación, API, Servicios Web. También podremos extraer los datos a mano cuando los necesitemos, ejecutando un script, realizando una consulta o pulsando el botón de una aplicación, por ejemplo.
- Desencadenamiento: notificación, Tigger de base de datos. El desencadenamiento de algún suceso, por ejemplo, si trabajamos para el servicio de inteligencia si lanza una alerta en un sistema de búsqueda y captura, entonces, con la información que nos ha dado la alerta extraemos los datos para analizar y filtrar a los sospechosos.
- Streaming: de continuo. Asegura tener los datos inmediatamente, por lo que suele ser el más interesante (aunque no siempre es el más útil), aunque también es el más complicado, pues cuando se genera el mayor número de datos en la fuente suele ser el momento en que más se está utilizando y el mayor peligro de colapsar al sistema.
¿Y ahora qué?
Como podemos apreciar, las maneras de extraer la información son amplias, desde conexiones a bases de datos, descargarnos ficheros, etc. Por lo que la manera de extraerlos y realizar una preparación previa antes del siguiente paso es muy necesaria y con múltiples detalles para tener en cuenta. Hay muchos más detalles en la extracción, pero como introducción teórica ya es bastante.
Después de la extracción, ya tendremos los datos en un formato preparado para iniciar el proceso de transformación.
Transform: Transformación
De la manera más eficiente y óptima
Aplicaremos las transformaciones de los datos según nos sea conveniente, siempre intentando que sea lo más eficiente posible y óptimo, pues la transformación suele ser la parte más pesada y lenta. “Lenta” en el sentido de que para una máquina transformar un único dato lo hace a toda velocidad, pero si multiplicamos por millones de datos, entonces vamos a notar la velocidad y mucho, pudiendo haber una diferencia de días a minutos para el mismo procesado de datos si está bien optimizado y es eficiente.
En este punto nos jugamos el tiempo real de los datos, pues si no transformamos datos a una velocidad decente, entonces el sistema encolará el resto del trabajo y lo que tenía que haber terminado por la mañana, todavía estará procesando por la tarde y el resto de los datos que vengan después ya no digamos cuando habrán terminado de procesar. Adicionalmente, un encolamiento muy grande de los datos puede que nos de problemas con los límites de la máquina, como llegar al máximo del disco duro o que el proceso que transforma sea matado por el sistema operativo si dicho proceso consume todo el rato el 100% del procesador.
Una optimización que se usa mucho en el mundo Big Data es llevar el código transformador al dato, en vez del dato al código transformador (antes se consultaban todos los datos de un servidor y se transformaban en otra máquina, esto es muy lento, ya que requiere enviar todos los datos con una conexión, por ejemplo, Internet, para que sean procesados en otro sitio; por lo que se pensó que mejor llevar el código que transformará el dato a los datos, esto es, que el código que tiene que transformar los datos se copia en la máquina donde están los datos y se procesan en la misma máquina, devolviendo únicamente los resultados deseados). Para realizar esto, la estrategia más utilizada es aplicar MapReduce.
Transformaciones
Por lo general los datos vendrán de mil maneras, por lo que tendremos que convertirlos a una estructura de datos que nos venga bien utilizar y para ello utilizaremos diferentes transformaciones.
Aunque se puede realizar con programación tradicional, es decir, procesar los datos por estados e ir guardándolos en ficheros; para Big Data y para mantener un flujo de los datos se realizan las transformaciones mediante funciones MapReduce que permiten tratar los datos en streaming, manteniendo el tiempo real (si no se realizan operaciones que requieran ordenación) y llevar el procesado al dato. Adicionalmente, esto permitirá realizar el procesamiento de datos en paralelo, preferiblemente distribuido.
Funciones de transformación:
- Reglas de negocio: esto puede ser poner en cierto formato los datos, realizar algo con ciertas palabras mal sonantes, etc.
- Filtros: filtrar es eliminar lo que no queremos (o dejar pasar lo que queramos); filtraremos: registros erróneos, ruido, outliers (datos aislados que sabemos que están mal), inconsistencias, duplicados o aquellos datos que no se van a necesitar. También se podrán eliminar ciertas columnas que no se necesiten cargar.
- Correctores o sustituidores (tratamiento de excepciones): como completar valores nulos con datos por defecto o sustituir un valor por otro, por ejemplo, si me llegan los valores de Hombre y Mujer, sustituir cada uno por un número (Hombre será el número 1 y Mujer será el 2) para que ocupe menos y etiquetarlo para alimentar a los modelos de Machine Learning por ejemplo. Otro corrector muy utilizado es el de fechas, para convertir a las fechas a UTC o convertirlas a un formato determinado compatible con el sistema donde se van a cargar.
- Codificadores: desde conversión de caracteres, traductores tanto de textos como de valores codificados, cifradores, anonimizadores de datos, etc.
- Mapeos: es una subrutina que realizará una tarea (operación) que no requieran sincronización (comunicación) con otras tareas. Las operaciones de mapeo suelen requerir devolver una clave y un valor, pues se utilizará la clave para agrupar posteriormente. Aunque otras veces se utiliza mapeo simplemente para realizar algunas de las transformaciones aquí indicadas.
- Uniones: que pueden venir de varias fuentes (Esto es importante tener un cacheo de esas otras fuentes para acelerar el procesado de los datos).
- Ordenaciones: esta es muy pesada, pues requiere todo el conjunto de datos para asegurar una ordenación correcta, por lo que podría no caber en memoria si es muy grande o tardar mucho tiempo en ordenar si se realiza en disco (aprovecho para comentar el ordenador en disco que desarrollé, que podría ser útil: https://github.com/Invarato/sorted_in_disk_project ). Para aligerar la carga de la ordenación quizás nos interese un mapeo previo de los datos y quedarnos con las claves de ordenación apuntando al dato completo (es uno de los trucos que utilizo en el proyecto anterior citado). Y, como comprenderás, si necesitamos ordenar, el streaming de datos peligra (una de las paradojas es: querer tiempo real y querer asegurar los datos del día ordenados; o una cosa u otra, no se pueden las dos, aunque existen trucos para “medio apañarlo”).
- Agrupaciones: por ejemplo, agrupar a las personas por grupos de edad. Agrupar tiene el mismo problema que las ordenaciones, pues requiere de todos los datos para asegurar los grupos (ordenar es agrupar, pero no al contrario).
- Transponer: convertir filas a columnas y viceversa.
- Operaciones: sumas entre datos de dos columnas diferentes, restar fechas para obtener los días entre ambas fechas, etc. Muchas operaciones se pueden hacer en tiempo real, pero otras operaciones requieren todos los datos, como las medias aritméticas.
- Validaciones: Validar los datos con otras fuentes y elegir si corregirlos o descartarlos, tanto el conjunto de datos completo como el dato en procesamiento.
Estados de los datos: Aunque no es una función propiamente dicha, creo que merece la pena comentar que podremos guardar los estados de los datos, cuando unos datos dependen de los datos que ya han pasado para aplicar alguna función de todas estas (como la unión de datos o la sustitución de lookups) o simplemente para añadir información en tiempo de transformación.
Ejemplo ETL de un ciclo de vida de las transformaciones
Vamos a ver un ejemplo para entender las transformaciones.
Los datos podrán venir tanto en bloque, por filas, en fichero, entre otros formatos. Para este ejemplo, supongamos que hemos extraído el siguiente fichero y lo hemos abierto (analízalo un momento antes de continuar leyendo):

Tenemos que pensar si nos interesa realizar alguna transformación global que nos ahorre tiempo de procesado a si lo hiciéramos con los datos divididos.
Por ejemplo, nos llega este fichero del ejemplo con una codificación de caracteres errónea, muy común con el idioma que hablamos, en Español, pues los sistemas ingleses suelen cambiar la codificación de los textos, por lo que los acentos y la Ñ no saldrán correctamente.
Decidimos aplicar una “transformación global”. En este caso nos interesará codificar todo el fichero entero desde la codificación que no nos interesa a UTF-8, por ejemplo.
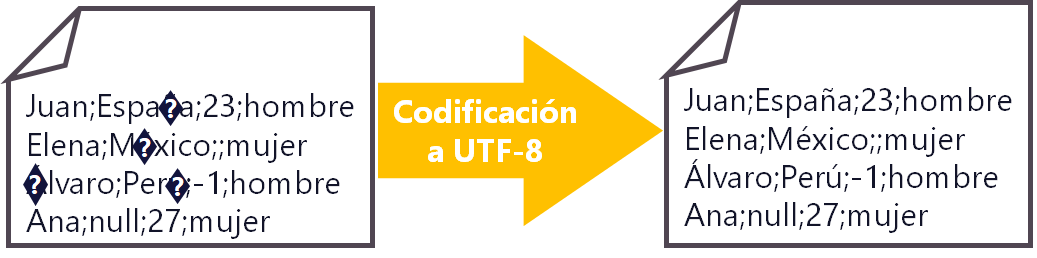
En este ejemplo muestro un fichero parecido al CSV con datos separados por “punto y coma” que estructuramos en un formato de tabla si así lo necesitáramos. Así que realizamos la “separación” (en inglés se suele denominar “split”). Para mantener un flujo de la información se suele realizar en el mapeo (la operación Map de MapReduce), para así tener estos datos estructurados o en objetos o en listados o diccionarios que se puedan utilizar.
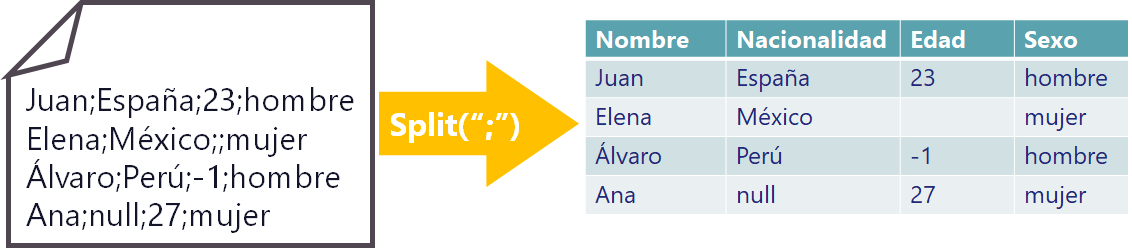
Realmente en este punto la estructura solo es para separar los datos y poder trabajar con ellos (no vas a ver una tabla tipo Excel como la que te he pintado en la imagen anterior), suele realizarse a un nivel más bajo (por ejemplo, en un objeto en programación Java o un listado en Python) y luego nos servirá esta restructuración para trabajar con los datos por separado y preparar el formato con el que cargar los datos, que podría ser otro fichero CSV o un INSERT de una base de datos, entre otros muchos.
Vemos que tenemos algunas cosas raras en la tabla, por lo que tenemos que “transformar los datos separados”, en este caso nos interesa “detectar y corregir errores”. Nos queda arreglar los datos que tenemos, al tenerlos separados ya podemos identificarlos y reconocerlos.

Primero tenemos que detectar los valores faltantes, estos son los vacíos o nules.
En Nacionalidad son datos de tipo texto, por lo que el null puede que sea un texto válido, pero supongamos que es un null, es decir un puntero a vacío. Pues para textos es fácil corregirlo, simplemente podemos convertir los nulles en textos vacíos, lo que suele ser en código abrir comillas y cerrar comillas, sin espacio dentro ni nada: “”
En Edad hay un vacío, y para los números los vacíos o los nulles es más complicado, pues desvirtúa los posibles cálculos y tendremos que pensar qué hacemos con ellos ¿Recuerdas cuando te dije que había paradojas? Esta es una y gorda, no se puede quedar vacío porque si no dará error al hacer las operaciones (esto es, a un número podemos sumarle otro número, pero a la nada es imposible sumarle un número); por ejemplo, si le ponemos un 0 por defecto el cálculo del valor medio se desvirtuará y dará un valor falso; podríamos ponerle la media como valor por defecto, pero requiere conocer el valor de todos los datos o al menos de los procesados hasta el momento y del mismo modo es un dato “inventado” tanto como el 0; podríamos eliminar la fila entera, perderíamos a Elena con el resto de sus datos, aunque esto nos hace perder información, puede que mucha ¿Qué hacemos? Pues lo que sea más conveniente para la empresa. En Big Data, con la excusa de que hay muchos datos, se suele eliminar el registro que no sepamos como corregirlo, pero no es más que una excusa y perdemos datos; aunque para este ejemplo voy a optar por ello.
Ahora tendremos que “corregir las anomalías”. Las anomalías, que son los datos que vienen de errores cometidos por los seres humanos, por la medición de algún sensor, por la transmisión de los datos, etc.
En nuestro ejemplo, las anomalías son aquellos datos que se salen del rango normal de datos para una columna dada. En el campo edad existe un valor negativo (-1) que se sale de dicho rango (quizás si hubiera un 100, como hay gente centenaria podría colar, si hay un 150 en la edad podríamos tener dudas de si es la primera persona que ha alcanzado la edad, si hay un 200 a día de hoy es imposible y si hay un -1 no cuela). Por lo que llamamos al cliente y le preguntamos que qué hacemos con el -1 en el campo edad y nos podría decir que el valor mínimo para ese campo es de 18 años, porque solo pueden ser mayores de edad, que si hay cifras negativas son un error al introducirlo y pongamos todos esos como 18 años; por lo que hacemos caso al cliente y corregimos las anomalías:

En este caso nos lo ha solucionado el cliente, pero podría darse el caso de que lo corrijamos como hicimos antes con los errores: eliminamos la fila, lo corregimos estadísticamente como con la media, etc.
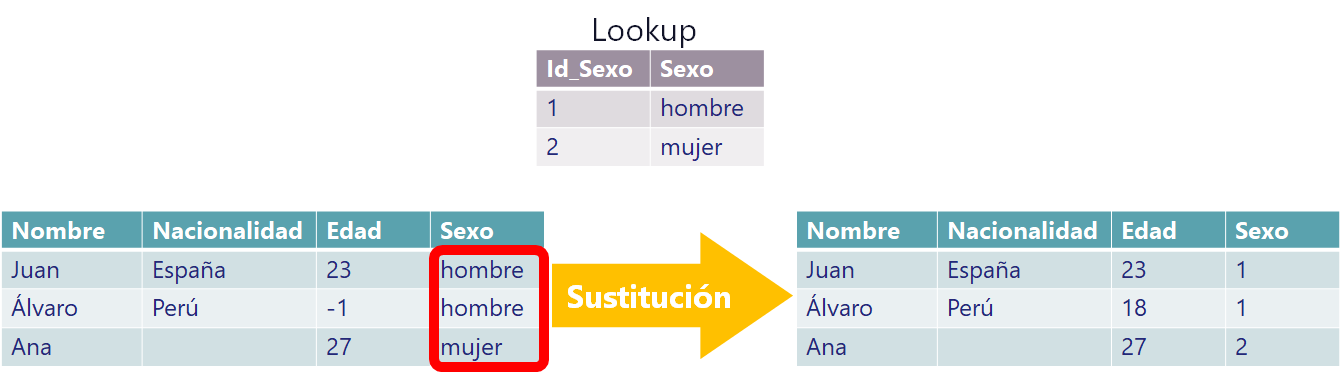
Otra cosa que podríamos necesitar es “sustituir datos”. Puede que haya datos que nos interese sustituir a la que procesamos, normalmente suelen ser valores acotados, como los que se suelen ver en comboboxes en las páginas web (como sexo, país, estado o comunidad, universidad, marca, etc.) y se suelen sustituir por una clave foránea que pertenece a otra tabla o se reduce el tamaño para que ocupe menos. También podría ser que necesitamos trabajar con números y no con textos, como para entrenar modelos con machine learning, pues los modelos trabajan con números.
En nuestro ejemplo, el jefe nos dice que para el sexo tenemos una tabla lookup (tabla de correspondencia) en el que tiene una columna id con el número para cada sexo; consultamos dicha tabla y vemos que para hombre su id (ID_Sexo en el cuadro gris en la imagen de abajo) es 1 y para mujer su id es 2. Así que en la columna sexo sustituimos los valores de texto a números (que son los ids de la tabla foránea Lookup) como se ha mencionado:
Al final puede que nos interese “reconvertir los datos”, como puede ser volver a unir los datos para guardarlos en un fichero, convertirlos a otra estructura de datos (como un JSON) o pasárselos a un objeto para enviarlos en el siguiente paso del ETL.
En nuestro ejemplo supondremos que queremos volver a unirlos con una barra horizontal y guardarlos en un fichero que será enviado.

Ya estaría, pero antes de terminar quiero comentar que en este ejemplo lo he realizado paso a paso para todos los datos, pero lo normal es realizar todos estos pasos por streaming, es decir, que primero se procesa la primera línea y se le hacen todos los pasos hasta guardarla en el fichero o en el objeto final con toda la transformación realizada y se cargaría de inmediato (último paso de ETL). Así, línea a línea (o registro a registro, para los más puristas) en un flujo continuo de datos, por lo que tendríamos datos en tiempo real limpios y preparados.
Trucos e ideas para tener en cuenta para realizar un buen ETL
Trucos varios para tener en cuenta:
- Fechas: pueden venir diferentes formatos en el mismo campo (escritas con texto como “3 de enero de 2022”, Epoch de Linux como “1641753566”, UTC como “2022-01-09T18:39:26Z”, etc.), por lo que nos interesará unificarlos en uno. Además, es interesante convertir cualquier uso horario al horario UTC (Tiempo Universal Coordinado), siempre que estemos alineados a donde se vayan a cargar (que luego quien use estas fechas sepa que están en UTC para que las convierta al uso horario que necesite); por cierto, no confundir formato UTC (Escribir la fecha como: año-mes-díaThora:minuto:segundoZ, por ejemplo: 2022-01-09T18:39:26Z) con huso horario UTC (Por ejemplo, en España son las 19:00, pero en horario UTC son las 18:00).
- Decode/Encode: pueden venir codificaciones no deseadas que tendremos que tratar. Por ejemplo, en textos suele ser interesante unificar a UTF-8.
- Valores vacíos: None (nill, null, nulo o cualquier otra forma de escribir “puntero a vacío”) o string vacío «» (no confundir un string en el que ponga la palabra “None”). Estos habrá que tratarlos si es necesario, pues un valor vacío en un campo que se espera un número nos dará problemas al realizar cálculos matemáticos. Sin embargo, no hay que subestimar el valor None, pues nos puede ayudar precisamente a no necesitar añadir datos por defecto (cosa que falsea los datos) y que solo los datos que tengan valor sean tratados, aunque esto requerirá posteriormente de un esfuerzo extra para quien lea los datos.
- Generadores/Streaming (Python/Java, también con otros como Spark): Conocer cómo realizar el flujo de datos para no consumir más memoria RAM de la necesaria y para tratar datos en tiempo real (procesado al vuelo). Para Generadores de Python le dedico un artículo completo que puedes ver pinchando aquí; sin embargo, para Streaming en Java puedes ver la documentación oficial.
- Operaciones históricas, tiempo real o en ventana (window): Los datos se pueden operar tanto por histórico (selección de bloque de datos pasados), por Streaming (en el momento que tengamos el dato en tiempo real), como por ventana (cuando la ventana se ejecuta se selecciona el conjunto de datos que quedan dentro de la ventana, que podría tener algún dato o ninguno, luego se desplaza la ventana para ejecutarse en el siguiente momento y así seleccionar otro conjunto de datos comprendido dentro de esa ventana, y así sucesivamente). Elegir cada uno dependerá de nuestras necesidades. Por comentar algo más sobre las operaciones de ventana: casi podríamos decir que la ventana es un intento de convertir datos históricos en tiempo real, pues podríamos acumular datos producidos durante esta última hora para procesarlos todos juntos a en punto (a las HH:00, por ejemplo), de este modo tendríamos lo mejor de las dos partes (salvando las distancias); una ventana se compone de la duración de la ventana (su tamaño) y de la duración del momento de ejecución de la ventana (el deslizamiento de la ventana); esta característica de ventana se puede utilizar, por ejemplo, con Spark Streaming (DStreams).
- Apertura de ficheros: No es conveniente abrir más de un fichero por hilo de ejecución (o job) a la vez, pues el número de “descriptores de archivo” en Linux o “manipulador de archivos” en Windows es limitado y podríamos tener problemas si abrimos muchos ficheros a la vez. Lo correcto es abrir un fichero, leerlo (al ser posible no todo de golpe, sino línea a línea) y cerrarlo.
- Leer lo menos posible la fuente de datos (fichero, consulta de la base de datos, etc.): Leer de una fuente de datos suele tener un coste muy alto, tanto a nivel de servidor que nos los sirve, como que seguramente los datos estén en disco y se tarden en leer, así como la posible saturación de la red por donde se transmitan esos datos.
- Guardar datos reutilizables en caché (para uniones, comparaciones, etc.): y mejor que se guarden los mínimos posibles (pues es memoria RAM), mucho mejor si solo hay que guardar las claves que apuntan al dato.
- Cachear al disco los logs completos en ficheros binarios y tener un diccionario de caché con las claves con un puntero a cada log en disco: también deberemos acordarnos de eliminar estos ficheros temporales cuando ya no los usemos, pues ocupan bastante.
Algunas validaciones de los datos que nos podría interesar:
- No es un registro vacío.
- Registro nuevo o no duplicado.
- Recuento de registros.
- Longitud del registro.
- Registros huérfanos.
- Registro sin datos erróneos.
¿Qué hacer con los registros cuyo campo no se pueden transformar?
- Consultar al interesado de los datos y al responsable de los datos qué hacer con esos datos.
- Eliminar: si no importa perder algún registro se puede eliminar, aunque el resultado de ciertas operaciones será falso (utilizo la palabra “falso”, pues claramente no es “exacto”, aunque no quita que no sea “aproximado”).
- Añadir un valor por defecto: siempre que no importe falsear algún valor (y que el interesado sea consciente) de un registro, al menos tendremos el resto de los valores del registro. Al realizar operaciones con los datos falseados, darán resultados que serán falsos (Parecido a Eliminar).
- Crear estadísticas e informes del conjunto de los datos: de esta manera, tanto si eliminamos como si añadimos valores por defecto, sabremos en todo momento el posible error cometido por estas modificaciones (por ejemplo, sabemos que tenemos 97 registro de 100 que eran, por lo que sabemos que se han eliminado 3).
- Guardar los datos en crudo en otro lugar: Por ejemplo, sería guardar todos los datos en crudo (sin modificar) en otra tabla; por lo que dispondríamos de los datos tratados y los datos sin tratar (con el consecuente gasto de disco, pues consumiría el doble en el peor de los casos). Se podrán utilizar para sacar estadísticas de datos erróneos y realizar cálculos con estos, o si lo necesitamos en un futuro podríamos recuperar la información modificada (eliminada o añadidos valores por defecto).
Operaciones que tienen un alto consumo de memoria (pues requiere recorrer todos los datos):
- Ordenar (sort): para poder ordenar un conjunto de datos se necesita conocer todos los valores del conjunto de datos (imagina que vienen las letras del abecedario desordenadas y la “A” es la última, necesitamos todas las letras en memoria para ordenar). Por lo que aquí nos olvidamos del streaming y del tiempo real.
- Agrupar (group o aggretation): solo los que no pueden ser agrupados al vuelo (aunque para esto se requiere tener ordenados los datos previamente). Para entender las implicaciones hay que tener claro que “ordenar es agrupar” (pues teniendo ordenado un conjunto de datos, todos los datos del mismo grupo estarán adyacentes; esto es: si vienen juntas las claves, se pueden agrupar a la que se itera y se devuelve el grupo en cuanto sea diferente), pero “agrupar no es ordenar” (se puede agrupar sin necesidad de tener los datos ordenados; esto es: si las claves no vienen juntas, a la que se itera habrá que acumular en caché los grupos para luego devolverlos todos debidamente agrupados).
- Unir (Join, Merge, Union): No todas las operaciones de unión funcionan igual, algunas no tienen tanto consumo de memoria y otras utilizan estrategias varias, también otras realizan otro tipo de unión que puede que no sea el resultado que queremos. Además, si los datos están ordenados, se podría unir al vuelo en ciertos casos.
- Comparar: Al necesitar los datos para ir comparándolos, tendremos un problema semejante al de agrupar. Si los datos están ordenados, se podría realizar una comparación al vuelo.
Load: Carga o Ingesta
Y ya por fin tendremos los datos listos para ser cargados (“ingestados”) en el destino.

Quizás todo este tratamiento que hemos realizado sea para enviar los datos a otro destino o simplemente hayamos querido sobrescribir los mismos datos antiguos, ya que había algo que corregir de los mismos. Aquí dependerá de lo que necesitemos, pero existen numerosos lugares donde cargar los datos, como en:
- Data warehouse
- Archivo plano
- Sistema de ficheros (como HDFS)
- Base de datos
- APIs
- Sistemas de ficheros
- Servicio
- Cloud
- Otros sistemas especializados
En una gran empresa normalmente se van a cargar en un Data warehouse para mantener un historial de registros, lo que permitirá realizar auditorías de los datos y su uso posterior.
Herramientas de ETL
Termino dejando unas cuantas herramientas para realizar ETL (aunque sirven para mucho más, aparte de hacer ETL y requieren tener ciertos conocimientos técnicos):
- De Apache tenemos unos cuantos: Apache Spark (del que escribí un artículo de cómo instalar Spark fácilmente en cualquier sistema operativo y aprender a usarlo, lo puedes ver pinchando aquí), GraphX, Apache Flink, Apache Beam, Apache Kafka, etc.
- Cualquier lenguaje de programación sirve (Pyhton, Java, R, Scala, etc.) para realizar ETL, tienen métodos y bibliotecas que realizan la mayoría de las funciones ETL, aunque quizás requieran de más trabajo de programación y se nos complicaría mucho si queremos realizar “a pelo” ya no un multiprocesado, sino un procesado distribuido. También se pueden utilizar los procesos batch (Shell Scripting) de cualquier sistema operativo para realizar cierto ETL.
- Herramientas integradas en cada plataforma Cloud: AWS (AWS Glue), Azure (Azure Data Factory), Google Cloud (Data Fusion), IBM (IBM Cloud Pak for Data), etc. Cada una tiene sus propias herramientas para realizar ETL.
- Otros: Oracle Data Integrator, Plataforma Confluent, Stich, etc.
Para los que no son técnicos y quieren realizar operaciones de transformación (conste que la extracción y la carga habrá que realizarlas por separado en la mayoría de ellas):
- Excel: tenía que ponerlo, pues Excel tiene herramientas de transformación, por ejemplo, permite importar CSV para tabular sus datos y luego trabajar con ellos (filtrar, buscar vacíos, etc.). Aunque está limitado a ficheros que no tengan mucho tamaño.
- Herramientas para el procesado de texto: Sublime text, Notepad++, VIM, etc. Aunque muy limitados a ficheros que no sean muy grandes. Permite realizar modificaciones múltiples y ciertas transformaciones básicas.
- Herramientas para el procesado de logs: EmEditor, etc. No requieren saber programar (casi todas tienen una interfaz que recuerda a Excel), abren ficheros bastante grandes (pero no Big Data) y permiten realizar numerosas transformaciones de datos.
- Herramientas de Business Inelligence: Power BI, Tableau, IBM Cognos, etc. Aunque solo podrás realizar un ETL muy limitado a la herramienta.
- Pandas (para Python): lo he puesto el último, pero es de los más importantes (sobre todo para el análisis de datos). Este sí que requiere que sepas un Python muy básico (es asequible incluso para quien no sabe o no le gusta programar). Evidentemente, si sabes programar, con Pandas vas a tener un sinfín de posibilidades más. Y ya si quieres algo más potente, puedes probar Koalas, que funciona muy parecido a Pandas pero con Spark.
- La siguiente entrada de Stack Overflow contiene numerosos programas para editar textos y poder realizar transformaciones básicas: https://stackoverflow.com/questions/159521/text-editor-to-open-big-giant-huge-large-text-files
Saber más
Aunque aquí te he contado mucho sobre ETL según mi experiencia y punto de vista, no quiero que te quedes solo con ésta, pues el ETL requiere de mucho más, no solo de entender exclusivamente este artículo que podría estar limitado o incluso requerir de una actualización dependiendo de cuando lo leas.
Sobre ETL existe un sinfín de contenido para especializarse, por lo sugiero que leas alguno de los muchos artículos escritos por las grandes compañías sobre ETL (muchos en Español):
- AWS: https://aws.amazon.com/es/blogs/aws-spanish/comparando-servicios-de-etl-para-extraccion-transformacion-y-carga-de-datos-en-aws/
- Google: https://cloud.google.com/learn/what-is-etl
- Microsoft: https://docs.microsoft.com/es-es/azure/architecture/data-guide/relational-data/etl
- IBM: https://www.ibm.com/cloud/learn/etl
