Generadores en Python – La base del Streaming
El Generador de datos permitirá un flujo de datos (o Streaming) en tiempo real y tener cada uno de los datos solo cuando necesite ser consumido (procesados o utilizados por una persona). Adicionalmente, será muy importante para garantizar un trabajo óptimo y equilibrio entre el procesado de datos (procesador) y la memoria principal (la memoria RAM) de cualquier máquina (ordenador de sobremesa, portátil, Tablet, etc.).
A modo de introducción sencilla dedicamos un artículo general sobre el Streaming que recomiendo leer previamente (se puede leer en unos minutos sin programar nada). Por otro lado, podrás analizar como utilizando Generadores se mejora mucho el rendimiento. Sin embargo, en este artículo sobre Python aprenderemos a utilizar los generadores con programación desde la base hasta convertirnos en expertos.
Un Generador puede parecer que es algo raro, pero en realidad se utiliza exactamente igual que otras estructuras de datos en Python (como list, dict o set); por lo que podremos obtener los datos de un Generador utilizando un bucle “for”:
for elemento in mi_generador:
print(elemento)
El código de este artículo lo puedes encontrar repositado en Github: https://github.com/Invarato/JarrobaPython/tree/master/generadores
Sencillo. Sin embargo, tiene una diferencia que es bastante notable, tanto que hay que entenderla bien para no caer en su trampa.
A diferencia de otras estructuras de datos, un Generador no tiene los datos guardados en ningún sitio, sino que va a generar cada dato a medida que se solicita (“algo tira del flujo del Generador para atraer un dato”). Y esta sutil diferencia es lo que hace al Generador muy importante (al final del artículo te explico la razón por la cuál el Generador es más importante que las estructuras de datos: list, dict, set; además, sabiendo crear Generadores demostrarás un profundo conocimiento de Python).
Podemos imaginar que el Generador es un objeto (porque realmente es un objeto en programación) con una cinta transportadora que sale de dentro, si nada tira de esta cinta transportadora entonces no se mueve; pero si alguien (en la imagen siguiente está representado por la persona rosa) tira de la cinta transportadora, ese alguien va a ir obteniendo cada dato (representado por la caja azul).
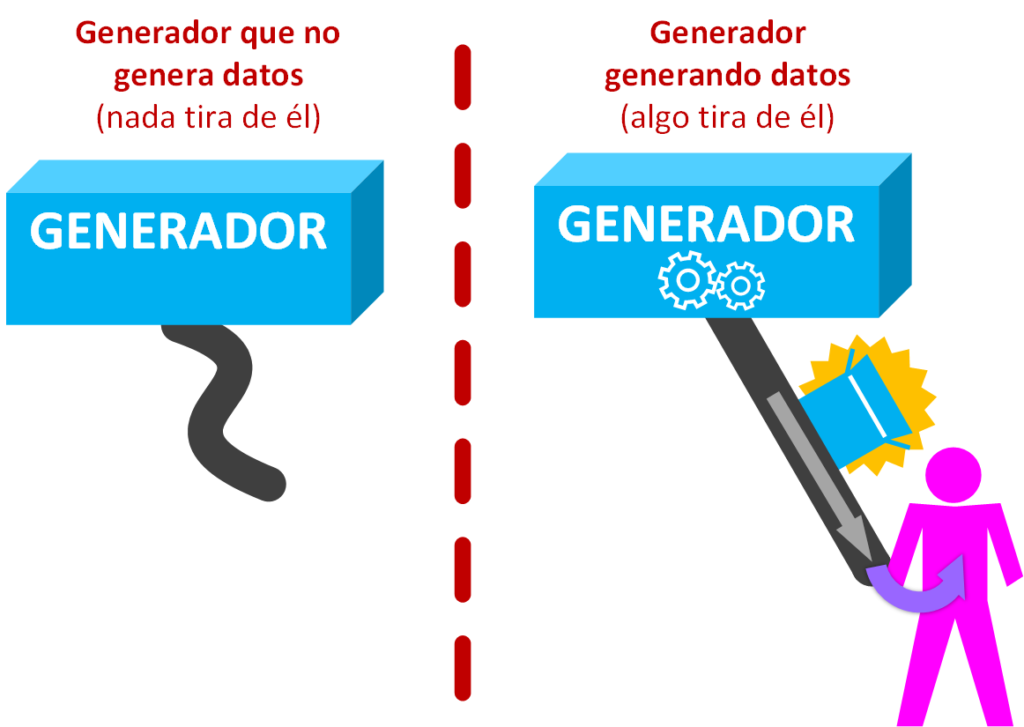
Es decir, los datos en un Generador no existen hasta que no son solicitados por un consumidor.
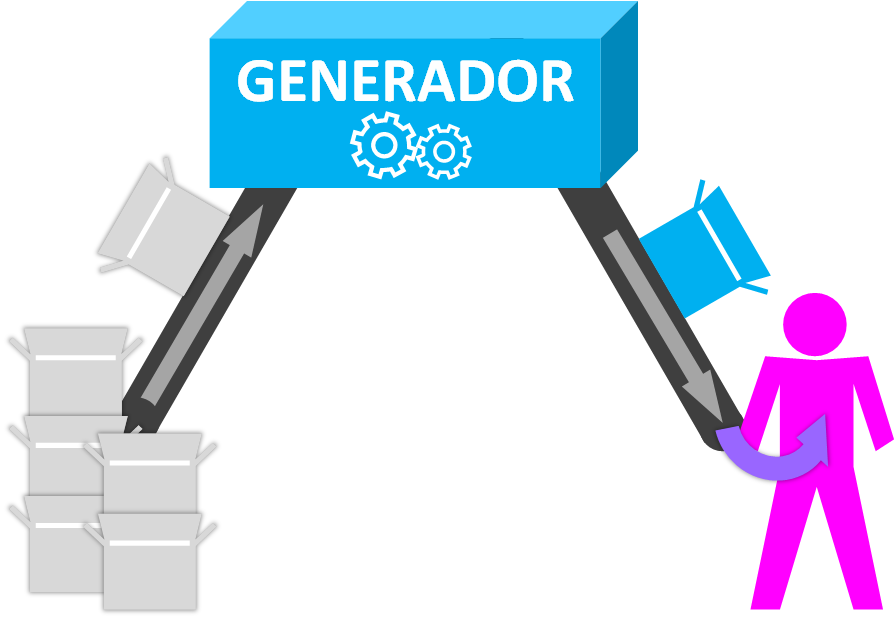
Esto está muy bien, pero ¿Para qué sirve un Generador? Supongamos que tenemos una pila de cajas blancas (datos sin procesar), y creamos un Generador que nos la pinte de azul (el procesado de cada dato); por tanto, cada vez que tiremos de la cinta transportadora, una caja blanca entrará por la cinta transportadora de entrada, será pintada dentro del Generador y nos será devuelta la caja pintada de azul (el dato procesado) por la cinta transportadora de salida.
¿Y cómo se crea/programa un Generador? Un Generador se programa con una “Función Generadora”, que es casi igual a programar una función de toda la vida (de esas a las que le pasas parámetros y devuelve datos por un “return”).
Para este ejemplo programaremos una “Función Generadora” que toma cajas blancas y pinta (en la siguiente imagen se representa con un pincel) cada una de las cajas de azul.
Además, para darle un poco más de gracia, en caso de que la caja que entre sea roja, también la pintará de azul, por lo que devolverá una caja morada; y en caso de que entre una caja de otro color la devolverá tal cual.
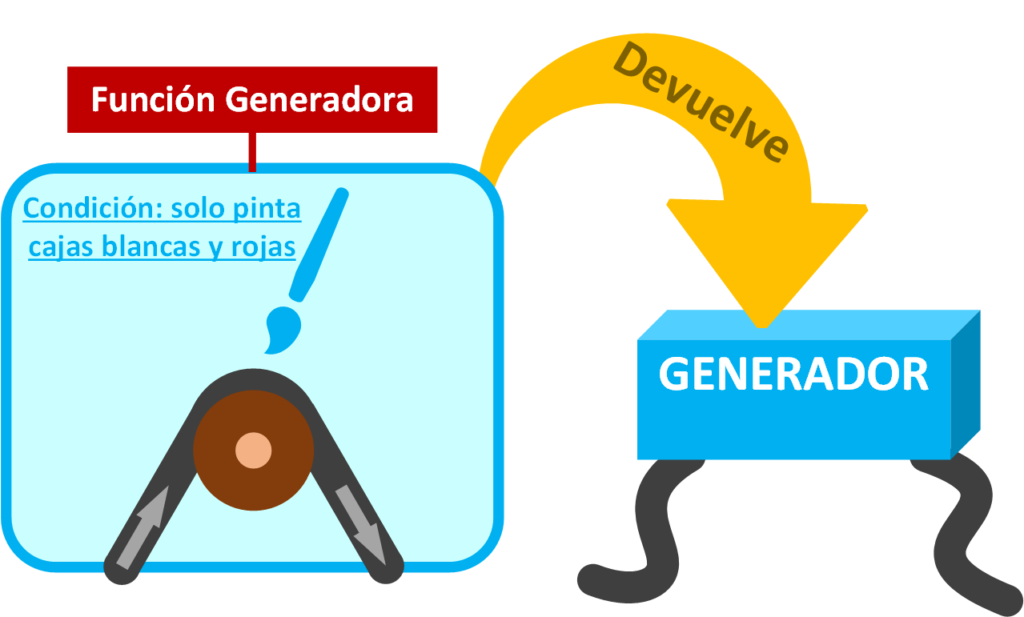
Pues una “Función Generadora” devuelve un Generador.
generador = funcion_generadora()Y ¿Cómo programamos la “Función Generadora” con código? Antes de decírtelo ¿Sabrías como programar una función que, dado un listado de colores (por ejemplo, [“BLANCO”, “ROJO”, “NEGRO”] y llamaremos a este listado “ristra_de_cajas”), recorra el listado e imprima por pantalla azul si era blanco y morado si era rojo? Si has programado con anterioridad a lo mejor se te venga rápidamente a la cabeza alguna forma de hacer esto; pues para una “función Generadora” se programa de manera muy parecida:
def funcion_generadora(ristra_de_cajas):
for caja in ristra_de_cajas:
if caja == "BLANCO":
yield "AZUL"
elif caja == "ROJO":
yield "MORADO"
else:
yield cajaEspero que te hayas fijado que en vez de “print” hay una palabra rara en la “Función Generadora”: Yield
Y antes de explicar “yield” con detalle, prueba el anterior código para ver que funciona igual que otras estructuras de datos:
ristra_de_cajas = ["BLANCO", "ROJO", "NEGRO"]
generador = funcion_generadora(ristra_de_cajas)
for caja_pintada in generador:
print(caja_pintada)Mostrará por pantalla lo que queríamos:
AZUL
MORADO
NEGROYield
Una “función Generadora” se crea en cuanto se utilice al menos una vez la palabra reservada “yield” (que podríamos traducir al español como “Producir/Generar”) dentro de una “función” de Python; puesto que la “función Generadora” va a devolver un “Generador”. “Yield” se pone en el momento en el que queremos devolver un único dato “completamente producido y preparado para ser devuelto” (este dato puede ser de cualquier tipo: string, int, list, tupla, dict, etc.). Echa un vistazo al siguiente ejemplo (he llamado a esta nueva “función Generadora” como “funcion_generadora_prints” para diferenciarla de la otra “funcion_generadora”):
def funcion_generadora_prints():
print("GENERADOR: Se va a generar un PRIMER dato")
yield "valorGenerado1"
print("GENERADOR: Se va a generar un SEGUNDO dato")
yield "valorGenerado2"
print("GENERADOR: Se va a generar un TERCER dato")
yield "valorGenerado3"
print("GENERADOR: Termina y lanzará automáticamente la excepción StopIteration")¿“Yield” vs “return”? Ojo que, aunque no veas un “return” escrito en la anterior “función generadora”, no quiere decir que una “función Generadora” no lo use; es más, “yield” NO remplaza a “return”. Toda función usa siempre un “return” aunque no se escriba (más sobre los ReturnS en Python pinchando aquí). En una “función Generadora” solo se puede usar el “return vacío” (“return void”); cuando se encuentra un “return” en “función Generadora” lanza la excepción StopIteration (desde Python 3 no hay que declararla ya que se lanza automáticamente), además de terminar con la ejecución de la función. Como en cualquier función, se puede declarar “return” o no, sino se declara se ejecutará automáticamente un “return vacío” al acabar de ejecutar todo el código del cuerpo de la función. Podríamos haber añadido el “return vacío” al final de la anterior función, pero no hace falta:
def funcion_generadora_prints():
# …
print("GENERADOR: Termina y lanzará automáticamente la excepción StopIteration")
return
# El return void en una “función Generadora” lanza un raise StopIterationUso del “return vacío”
Se suele usar el “return vacío” dentro de una “función Generadora” para evitar escribir condicionales extra para terminar el código (y que el código quede más legible); por ejemplo, escribir un “return” dentro de un bucle que esté dentro de la función para que termine a la vez el bucle (hace de “break”) y a la función.
Por ejemplo, para el ejemplo de la “función Generadora” que pinta cajas, si llega cualquier color que no sea “BLANCO” o “ROJO” que termine inmediatamente el bucle y a la función:
def funcion_generadora(ristra_de_cajas):
for caja in ristra_de_cajas:
if caja == "BLANCO":
yield "AZUL"
elif caja == "ROJO":
yield "MORADO"
else:
returnPuntero a un Generador
Ya lo dijimos antes, para obtener el objeto Generador bastará con llamar a nuestra “función Generadora”:
generador = funcion_generadora_prints()En este momento tenemos un objeto “Generador” pero NO ejecuta el código que está dentro de la “función Generadora” (Es decir, ninguno de los anteriores “print” que dicen «GENERADOR: Se va a generar un X dato» se habrá ejecutado). Si no hay nada que “tire” del Generador nunca se ejecutará el código interior de la “función Generadora”; esto es muy importante y causa de muchas confusiones a la hora de programar con Generadores y de depurar el código, hay que tenerlo en mente.
Y si pruebas a imprimir la variable “generador”:
print(generador)No vas a obtener los datos generados, sino el objeto “genarator”.
<generator object funcion_generadora at 0x00000123456789ABCDEF>Ya que obtiene un puntero a la función, pero NO la invoca, así que no obtiene el objeto Generador. Este comportamiento es el mismo con cualquier “función” que no es invocada (la invocación de una función requiere los paréntesis “funcion()”, paréntesis que sirven para el paso de parámetros “funcion(parametro1)”).
Para obtener los valores de un Generador bastará con iterarlo en un bucle:
generador = funcion_generadora()
for elemento in generador:
print(elemento)Partes de un Generador
Ya con lo que hemos visto se puede intuir las partes de un Generador. Para ejemplificar cada parte voy a reutilizar el código de la “función Generadora” de “pintar cajas”:
def funcion_generadora(ristra_de_cajas):
for caja in ristra_de_cajas:
if caja == "BLANCO":
yield "AZUL"
elif caja == "ROJO":
yield "MORADO"
else:
yield cajaAhora queda conocer cada una de las partes de un Generador:
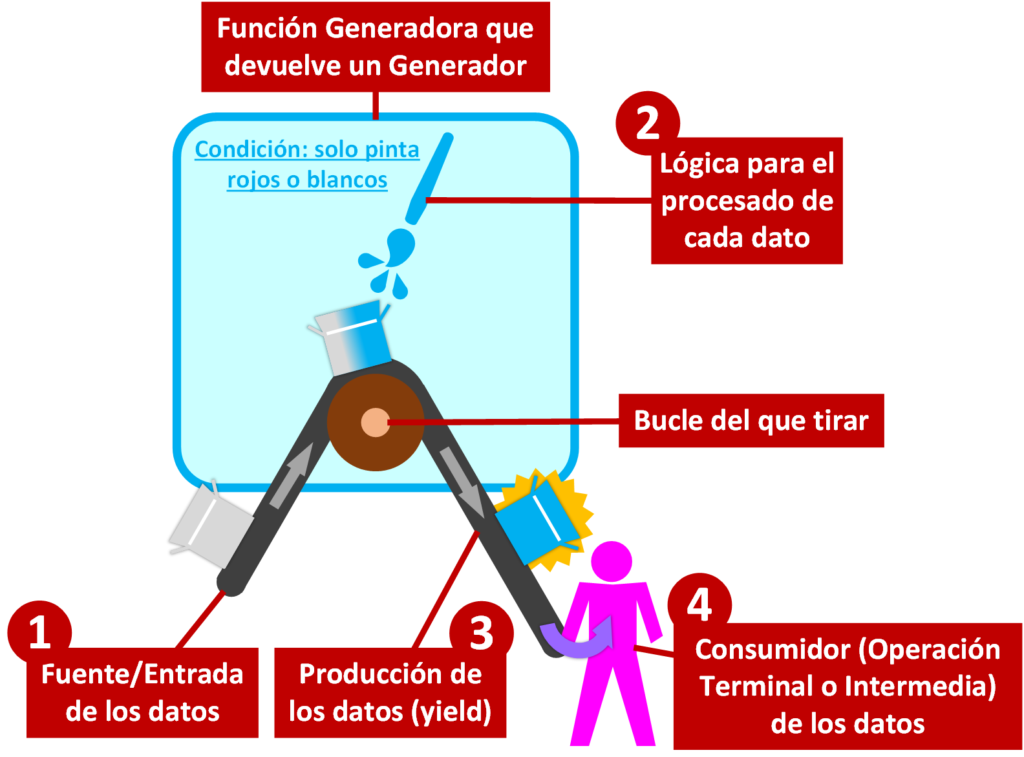
- Función Generadora: que tiene declarado algún “yield” y al llamar a la “función Generadora” devolverá un objeto de tipo Generador. En el ejemplo: es la función entera que he llamado “funcion_generadora”, la cual al ser invocada devuelve el objeto de tipo Genrador.
- Fuente (Entrada) de los datos: los datos que serán tratados dentro de la “función Generadora”. Es opcional su uso, pues puede que el Generador por si mismo produzca datos sin necesidad de una fuente de datos. Es lo primero [1 en la imagen] en ser llamado ya que se pasa como parámetro a la “función Generadora”; podría ser un listado u otro Generador (cualquier “iterador”; toda la explicación sobre “iteradores” en https://jarroba.com/nuestra-propia-coleccion-en-python/), por lo que un Generador tiraría de otro; y por supuesto que se podrían pasar otros parámetros a la “función Generadora” o fuentes de datos. En el ejemplo: es la “ristra_de_cajas”.
- Lógica para el procesado de cada dato: Es lo que queremos que le ocurra a cada dato. Se ejecuta en segundo [2] lugar con el flujo de datos de entrada. En el ejemplo: el hecho de pintar los datos con las decisiones de pintar solo cajas “BLANCO” y “ROJO”.
- Bucle del que tirar: Este bucle (o bucles anidados) dentro de la “función Generadora” ejecutará cada iteración cada vez que “algo tire” de él (este “algo” será el “Consumidor” de los datos). Este bucle opcional, pero se usa muchísimo con las “funciones Generadoras”, puede existir siempre si hay una fuente de datos o no; en algunos casos no se utilizan, como en el ejemplo que pusimos antes con los “print” (de la “función Generadora” que llamamos como “funcion_generadora_prints”). Este bucle forma parte de la “lógica para el procesado de cada dato”, pero es suficientemente importante como para dedicarle un punto propio. En el ejemplo: es el bucle “for caja in ristra_de_cajas”
- Producción de los datos (yield): Cada vez que se llama a un “yield” dentro de la “función Generadora” se devuelve el dato ya procesado y el control del flujo del programa fuera del Generador que se está iterando. Se ejecutaría después de la “Lógica para el procesado de cada dato” [3], aunque si hay más “yields” o un “Bucle del que tirar” se repetirá por cada vez que alguien itere al Generador. En el ejemplo: cada vez que hay un “yield” (por ejemplo: yield «AZUL»).
Y sin formar parte de la “función Generadora”, es importante también conocer la figura del:
- Consumidor de los datos: Es quién está “tirando de los datos” del objeto del Generador. Un Consumidor de un Generador puede ser una “operación Terminal” (consume los datos y termina) u “operación Intermedia” (consume los datos y los devuelve a otro consumidor). Cada vez que un Consumidor “tira” de un dato del Generador, se le pasa el control del flujo del programa al Generador y cuando el Generador produce un dato (llega a un “yield”), entonces el consumidor retoma el control del flujo del programa [4] para utilizar dicho dato; y volverá a tirar tantas veces como necesite del Generador o hasta que el Generador no produzca más. En el ejemplo sería el “for” que itera por el Generador que ha devuelto la “función Generadora”:
ristra_de_cajas = ["BLANCO", "ROJO", "NEGRO"]
generador = funcion_generadora(ristra_de_cajas)
for caja_pintada in generador:
print(caja_pintada)Motivos para usar un Generador
Podemos tener motivos para dudar si es buena idea realizar el esfuerzo de aprender y usar “funciones Generadoras”. La respuesta corta: el Generador es la estructura de programación más importante (mucho más que list, dict, set, ficheros, etc.). La respuesta larga, en los siguientes párrafos te la detallo.
¿Recuerdas cuando te preguntaba más arriba si sabrías programar una función dado un listado de colores, que lo recorra y devuelva si lo que se pasas era blanco y morado si era rojo? Pues eso vamos a hacer ahora. Supongamos que queremos hacer el código de la “función Generadora” de “pintar cajas de azul” con una función que NO es “función Generadora”. Podríamos hacer algo así:
def pinta_de_azul(ristra_de_cajas):
ristra_de_cajas_de_retorno = list()
for caja in ristra_de_cajas:
if caja == "BLANCA":
caja = "AZUL"
elif caja == "ROJA":
caja = "MORADA"
ristra_de_cajas_de_retorno.append(caja)
return ristra_de_cajas_de_retornoDonde nos pasan las cajas en el listado “ristra_de_cajas”, iteramos cada caja con un bucle “for”, cada caja la modificaremos según nuestras condiciones (si en la variable caja llega “BLANCA” sustituiré su valor por “AZUL”; si llega “ROJA” por “MORADA”; y cualquier otro color no será modificado) y devolvemos otro listado con todas las modificaciones que hemos llamado “ristra_de_cajas_de_retorno”.
Pudiéndose invocar a esta función exactamente igual que antes:
ristra_de_cajas = ["BLANCA", "ROJA", "NEGRA"]
ristra_de_cajas_pintadas = pinta_de_azul(ristra_de_cajas)
for caja in ristra_de_cajas_pintadas:
print(caja)El problema de no utilizar “funciones Generadoras” es que el flujo del programa se bloquea dentro de esta función hasta que termina de procesar todas las “cajas” y nos devuelve el listado de retorno. Por otro lado, tenemos que mantener en memoria un listado para poder devolverlo y al terminar (al retornar el valor de la función) ya podríamos utilizar los datos procesados.
Estamos en la época del Big Data (dicho mal y pronto: datos masivos), así que imagina este listado “ristra_de_cajas” que tiene con tantos datos que se tardan horas/días en procesar (hoy en día es habitual trabajar con millones de datos en un “listado”, en el orden de Gigabytes, Terabytes o Petabytes de datos) o si el listado es infinito (¿de verdad puede existir un “listado” infinito? Sí, por ejemplo, consultas cada cinco minutos a una base de datos para que nos devuelva datos infinitamente). Por lo que, si el listado es muy grande, no tendremos datos en mucho tiempo y si es infinito nunca tendremos datos; en el ejemplo, no veremos un dato impreso por pantalla (“print”) hasta que la función no termine de procesar el listado entero, cuando podríamos ir imprimiendo cada dato a medida que lo tenemos procesado (y no vale poner un “print” dentro de la función añade pues añade complejidad que no necesita, se pierde la reutilización del código y ralentiza el bucle innecesariamente si queremos utilizar al función para otra cosa que no necesite imprimir nada por pantalla). Por otro lado, órdenes de magnitud de datos muy grandes (cientos de Gigabytes, Terabytes o Petabytes) necesita que dispongas de toda esa memoria RAM y no sé si tendrás disponible alguna máquina con tanta memoria RAM para guardar un listado tan grande (yo por lo menos nunca la he tenido y tampoco es necesaria para lo que cuesta: es más barato el disco duro que la memoria RAM).
Si en vez de utilizar esta “función” utilizamos una “función Generadora” conseguiremos:
- Obtener cada uno de los datos tan pronto sea procesado y poder usarlo inmediatamente (por ejemplo, procesamos un dato e imprimirlo por pantalla al momento). Lo que se llama Streaming/Flujo de datos.
- Consumir muy poca memoria RAM al descartar los datos que sean usados (por ejemplo, al imprimir el dato procesado lo descartaríamos al instante), no es necesario almacenar los datos. Conseguimos optimización de la memoria RAM.
- Posibilidad de procesar infinitos datos. Lo que es un flujo ininterrumpido de procesado de datos.
- Y si queremos tendremos la posibilidad de descartar datos que no sean interesantes al vuelo; es decir, cuando el dato sea requerido para su procesado y no sea deseado no será devuelto en el flujo (sería algo así a disponer de un listado de solo datos útiles al instante). Es decir, un filtrado de datos por Streaming.
Espero que estemos más convencidos de la gran utilidad de los Generadores.
Defectos de un Generador
Aunque un Generador no se puede librar de sus defectos:
- Un Generador solo se puede iterar una única vez: pues una vez que ha producido los datos ya se ha agotado (aunque podríamos guardar los datos producidos en otra estructura de datos para reutilizarlos si es necesario, como en un fichero; o volver a crear el Generador con la “función Generadora”).
- No se puede cambiar el orden de devolución de los datos: con un listado (que es una Secuencia; más información en https://jarroba.com/especializa-tu-propia-coleccion-en-python/) podremos iterar en un orden o en el contrario.
- No se puede ir a un dato en concreto: no tiene índices de apuntado inmediato (más información sobre cómo funciona una tabla hash en https://jarroba.com/tablas-hash-o-tabla-de-dispersion/) como el diccionario o el listado; si queremos el dato de la posición mil de un Generador, entonces habrá que recorrer mil datos.
- Procesado en tiempo de ejecución: lo que es bueno para liberar memoria RAM es malo para el tiempo consumido en el procesador, ya que cada dato requiere ser procesado cada vez que se pide. Se puede arreglar haciendo que el Generador sea tirado en un proceso aparte y que los datos se encolen en una cola (lo que es un Buffer como vimos en https://jarroba.com/streaming-generadores-buffer-y-cache/).
- Existen operaciones que no se pueden utilizar Generadores: por ejemplo ordenar (“sorted”) requiere de todos los datos para, dado el criterio de ordenación, poder ordenar todos los datos (se requiere conocer todas las claves de ordenación para ordenar; para entender rápidamente esto, imagina que pasaría si la clave que va a ser la primera se encuentra en el último dato que va a ser devuelto por el Generador, que hasta que no se obtenga hasta el último dato no la podríamos colocar la primera).
Consumidor (Tirar del flujo de datos del Generador)
He hablado del Consumidor de un Generador brevemente para dar una idea general, ahora entendámoslo a fondo.
El objeto Generador es un Iterador (La clase “Generator” hereda de “Iterator”, y recuerdo que “Iterator” hereda de “Iterable”; más información de Iterador e Iterable pinchando aquí):
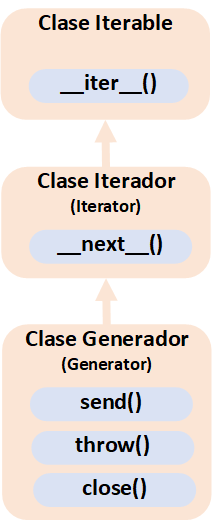
Por tanto, para que el “Generador” produzca datos tenemos que utilizarlo como cualquier otro Iterador con un bucle “for” (porque puede como Iterable puede utilizar “iter()”) para iterar por todos sus elementos o utilizar “next” (porque puede como Iterador puede utilizar “next()”) para ir obteniendo elemento a elemento (“next” a “next”).
Para que el bucle “for” vaya “tirando de” (obteniendo) cada uno de los datos del Generador y podamos utilizar cada uno de los datos en Streaming (aviso que utilizaré el segundo ejemplo de “función Generadora” que se llama “funcion_generadora_prints”):
generador = funcion_generadora_prints()
for valor_generado in generador:
print("Valor generado y obtenido desde el generador: {}".format(valor_generado))Si lo ejecutamos imprime (fíjate mucho en el orden de los mensajes impresos; no es como se esperaría con una “función” que NO es “función Generadora”, donde primero se ejecutaría completamente la función antes de devolver el valor en el “return”, aquí eso no ocurre):
GENERADOR: Se va a generar un PRIMER dato
Valor generado y obtenido desde el generador: valorGenerado1
GENERADOR: Se va a generar un SEGUNDO dato
Valor generado y obtenido desde el generador: valorGenerado2
GENERADOR: Se va a generar un TERCER dato
Valor generado y obtenido desde el generador: valorGenerado3
GENERADOR: Se va a lanzar la excepción StopIteration
En este caso, el “for” tira de un dato del “Generador” (que hemos guardado en la variable “valor_generado”), lo obtiene y lo pinta en la consola (con “print”); y así uno a uno con todos. Cuando el Generador termine lanzará la excepción StopIteration que el bucle “for” (que hace de Consumidor) capturará automáticamente (no tienes que hacer nada con la excepción), el bucle “for” utiliza a esta excepción para terminar de iterar y salir del bucle.
Funcionamiento del bucle “for” por dentro
Recuerdo cómo funciona el bucle “for” rápidamente (Este cuadro es un resumen que no hace falta entender para seguir este artículo, si tienes más curiosidad tienes la explicación completa en el articulo sobre crear nuestra propia colección en Python pinchando aquí)
for elemento in iterable:
# Cuerpo del bucle for mientras no se detecte “StopIteration” o break
# Continuación del código, fuera del cuerpo del bucle forEl objeto Iterable (puede ser un list, dict, set, generator, etc.) es iterado como Iterador (“iter”) por el bucle “for”, donde en cada iteración (llamada a “next”) se devuelve un elemento del iterador para ejecutar código dentro de su cuerpo, mientras no detecte la Excepción “StopIteration”; en caso de detectar esta Excepción “StopIteration”, el bucle terminará y el código continuará ejecutándose tras el cuerpo del bucle “for”.
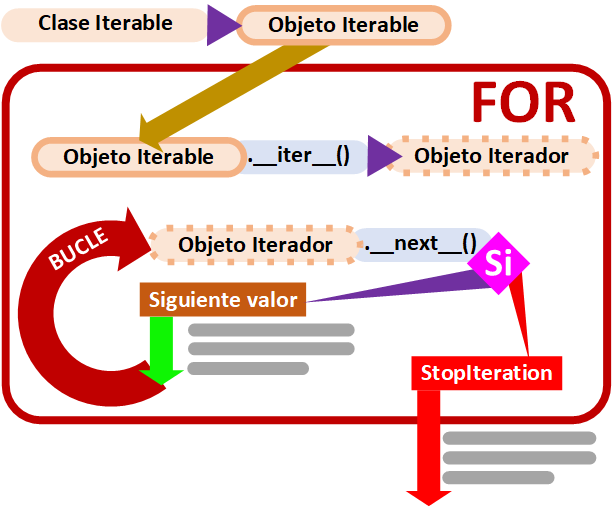
Si queremos recorrer los valores generados uno por uno podemos hacerlo con next(), pero aquí sí que necesitamos que capturar y tratar la excepción StopIteration.
generador = funcion_generadora_prints()
try:
primer_valor = next(generador)
segundo_valor = next(generador)
tercer_valor = next(generador)
# Nuestro generador solo puede generar tres valores, por lo que llamar una cuarta vez a next lanza la excepción StopIteration
cuarto_valor = next(generador)
except StopIteration:
print("El Generador ya ha generado todos los valores posibles")Que imprimirá:
GENERADOR: Se va a generar un PRIMER dato
Valor generado y obtenido desde el generador: valorGenerado1
GENERADOR: Se va a generar un SEGUNDO dato
Valor generado y obtenido desde el generador: valorGenerado2
GENERADOR: Se va a generar un TERCER dato
Valor generado y obtenido desde el generador: valorGenerado3
GENERADOR: Se va a lanzar la excepción StopIteration
EXCEPCIÓN StopIteration: El Generador ya ha generado todos los valores posiblesResumen del ciclo de vida completo de un Generador
Como sé que al principio puede ser mucha información, te facilito un resumen completo de los pasos:
- Invocamos a la “función Generadora” para que nos cree el “Generador”.
- Algo “tira del flujo de datos del” (“itera al”) Generador para que procese y devuelva el primer dato. Solo puede ser iterado de dos maneras: mediante un bucle “for” o por sucesivas llamadas al método “next()”.
- El Generador procesa un dato y se para en el primer “yield” que encuentra.
- El “yield” devuelve ese dato procesado.
- Se utiliza el dato procesado fuera del cuerpo de la “función Generadora”.
- Se devuelve el control a la “función Generadora” para que continúe hasta el siguiente “yield”.
- El Generador procesa un dato y se para en el siguiente “yield” que encuentra.
- Repite desde el punto 4 hasta terminar con todos los “yield” que puede alcanzar (si hay condiciones puede que algún “yield” no se ejecute) dentro del cuerpo de la “función Generadora” o encontrar un “return”.
- Cuando se alcance el final de la “función Generadora” se lanza la excepción especial StopIteration automáticamente
- Si se estaba recorriendo el Generador en un bucle “for”, entonces automáticamente terminará al capturar la excepción StopIteration y continuará el código fuera del “for”. O bien, si se estaba recorriendo el Generador a base de llamar varias veces al método “next()”, se tendrá que controlar la excepción con un “try … catch StopIteration …”
- El Generador solo se pude recorrer una vez de principio a fin, por lo que será destruido y el “recolector de basura” (en inglés “garbage collector”) de Python lo limpiará.
Enviar (send) información a un Generador mientras se itera
Puede sonar un poco raro lo de enviar información si se confunde con alimentar con parámetros a una “función Generadora”:
mi_lista = [1, 2, 3]
mi_string = "un texto"
mi_booleano = True
Generador = funcion_generadora_parametros(mi_lista, mi_string, mi_booleano)Además de estos valores pasados como parámetros a la “función Generadora”, se puede enviar información desde al Generador mientras un consumidor lo está iterando con el método “send()”.
Se suele utilizar para enviar señales (“flags”) al generador para modificar su comportamiento o para añadir datos intermedios para que los procese antes de continuar.
Hay que tener en cuenta que el método “send()” es como “next()” pues al ser llamado se saltará al siguiente “yield” inmediatamente, por lo que es recomendable capturar la excepción StopIteration.
Es decir, que se puede hacer en seudocódigo:
generador = funcion_generadora_send()
for valor_generado in generador:
print("Valor generado: {}".format(valor_generado))
try:
valor_generado = generador.send("Información a enviar al generador")
except StopIteration:
passUn ejemplo podría ser un generador que cuente infinitamente y queremos que cuando nos de la gana cambiar su “paso”, es decir, poder enviarle un nuevo valor a sumar (nuevo_valor_a_sumar). Para esto utilizamos la retroalimentación del Generador (variable = yield …) y protegemos por si se retroalimenta con un None:
def funcion_generadora_contador_infinito(valor_a_sumar):
acumulado = 0
while True:
acumulado += valor_a_sumar
nuevo_valor_a_sumar = yield acumulado
# Es importante comprobar el valor devuelto en el yield, ya que si solo se tira sin llamar a send devolverá None
if nuevo_valor_a_sumar is not None:
valor_a_sumar = nuevo_valor_a_sumarProbaremos con “next()” para ver cada punto y cuando queramos cambiaremos el valor a sumar;en este ejemplo sumaba de 1 en 1 hasta que quisimos que continuara la cuenta pero sumando de 10 en 10:
valor_de_inicio_a_sumar = 1
generador = funcion_generadora_contador_infinito(valor_de_inicio_a_sumar)
valor_generado = next(generador)
print("ANTES valor generado: {}".format(valor_generado))
valor_generado = next(generador)
print("ANTES valor generado: {}".format(valor_generado))
# Cuando queramos usamos send, que devolverá un valor al igual que next, ya que se envía el valor al generador y busca el siguiente yield
nuevo_valor_a_sumar_y_enviar = 10
valor_generado = generador.send(nuevo_valor_a_sumar_y_enviar)
print("ENVIAR valor generado: {}".format(valor_generado))
valor_generado = next(generador)
print("DESPUES valor generado: {}".format(valor_generado))
valor_generado = next(generador)
print("DESPUES valor generado: {}".format(valor_generado))Es muy recomendable proteger siempre los “next()” con la captura de la excepción StopIteration. En este caso no la capturo principalmente por claridad, pero también porque al ser un bucle infinito (while True) nunca lanzará la excepción StopIteration.
Muestra por pantalla:
ANTES valor generado: 1
ANTES valor generado: 2
ENVIAR valor generado: 12
DESPUES valor generado: 22
DESPUES valor generado: 32Ejemplo casi-real para Lexer y Parser
- Lexer: produce “unidades de valor” (tokens); es decir, en una frase en español realiza el análisis sintáctico y devolvería las “unidades de valor”, que serían cada una de las palabras por separado de la frase y reconocidas según su tipo (ejemplo de “unidades de valor” en español de la frase “Juan come pan”: “Juan” es “sujeto”, “come” es “verbo”, “pan” es “sujeto”)
- Parser: reconocen la estructura del lenguaje; es decir, en una frase en español comprueba si las frases están bien formadas, comprobaría si una frase cumple la estructura “sujeto + verbo + predicado” (ejemplo, la frase “come Juan pan” el Parser indicaría que la estructura gramatical es incorrecta; pero para la frase “Juan come pan” indicaría que la estructura gramatical es correcta).
Send se suele utilizar para alimentar al Lexer desde el Parser; pues hay algunas “unidades de valor” que no se pueden identificar sin su contexto.
En español es fácil identificar los artículos (la, los, un, una, etc.) y las preposiciones teniendo sus listados completos (a, ante, bajo, cabe, con, etc.); pero ¿y los sujetos de los verbos? Son innumerables por lo que es casi imposible tener listados enteros de sujetos y verbos, sobre todo porque pueden mutar y añadirse más (por ejemplo, añadir nuevas palabras como sujetos o verbos: youtuber, encriptar, etc.). Por contexto se puede saber si es un sujeto (por ejemplo, un artículo siempre va delante de un sujeto, por lo que no nos hace falta tener al sujeto en un listado, por venir detrás del artículo ya se sabe que es un sujeto) o un verbo (si ya se ha escrito un sujeto, es bastante seguro que lo que venga detrás sea un verbo, mientras no venga después ni artículo ni preposición).
Visto así, si quisiéramos hacer un Lexer sencillo del lenguaje español crearíamos un Generado al que le llega un texto y lo separa por espacios. Teniendo los conjuntos (set) de preposiciones y artículos nos son sencillos de identificar, pero el sujeto y el verbo no, como no queremos poner aquí lógica del Parser utilizamos la retroalimentación del Generador (variable = yield ….) y protegemos de que no se retroalimente con un None.
def funcion_generadora_lexer(texto):
articulos = {"el", "los", "la", "las", "un", "unos", "una", "unas"}
preposiciones = {"a", "ante", "bajo", "cabe",
"con", "contra", "de", "desde",
"en", "entre", "hacia", "hasta",
"para", "por", "según", "sin", "so",
"sobre", "tras"}
sujeto_o_verbo = "sujeto"
palabras = texto.lower().split(" ")
for palabra in palabras:
if palabra in articulos:
nuevo_sujeto_o_verbo = yield palabra, "artículo"
elif palabra in preposiciones:
nuevo_sujeto_o_verbo = yield palabra, "preposición"
else:
nuevo_sujeto_o_verbo = yield palabra, sujeto_o_verbo
if nuevo_sujeto_o_verbo is not None:
sujeto_o_verbo = nuevo_sujeto_o_verboY ahora el Parser que lo simplifico recorriendo el Generador:
- Si viene un “artículo” sabemos que lo que puede venir después es un “sujeto”
- Si viene un “sujeto” lo siguiente tendrá que ser un “verbo”, siempre que no sea ni “artículo” ni “preposición” (esto ya lo controla el Lexer)
- Si viene un “verbo” lo siguiente tendrá que ser “sujeto”
texto = "Juan come pan de la panadería"
generador = funcion_generadora_lexer(texto)
for palabra, tipo in generador:
print("La palabra '{}' es de tipo '{}'".format(palabra, tipo))
try:
if tipo == "artículo":
palabra, tipo = generador.send("sujeto")
print("La palabra '{}' es de tipo '{}'".format(palabra, tipo))
if tipo == "sujeto":
palabra, tipo = generador.send("verbo")
print("La palabra '{}' es de tipo '{}'".format(palabra, tipo))
if tipo == "verbo":
palabra, tipo = generador.send("sujeto")
print("La palabra '{}' es de tipo '{}'".format(palabra, tipo))
except StopIteration:
passComo “send()” llama al siguiente yield del generador, pues trato lo que devuelva inmediatamente; y como puede devolver StopIteration lo capturo.
Si imprimimos por consola la ejecución:
La palabra 'juan' es de tipo 'sujeto'
La palabra 'come' es de tipo 'verbo'
La palabra 'pan' es de tipo 'sujeto'
La palabra 'de' es de tipo 'preposición'
La palabra 'la' es de tipo 'artículo'
La palabra 'panadería' es de tipo 'sujeto'Comprensión de Generadores (Generator Comprehension)
Un generador se puede comprimir al igual que los listados, los conjuntos y los diccionarios
Si te gusta utilizar Comprehension es importante saber que los Generadores se delimitan con paréntesis “(” “)”, pues crea la confusión con las “Tuplas” que se delimitan con paréntesis. Por otro lado, confundir corchetes “[” “]” (que son para listados) o llaves “{” “}” (que son para diccionarios), podría darnos resultados no previstos (como quedarnos sin memoria o iteraciones infinitas sin continuidad de código).
Si queremos generar los múltiplos de 10 hasta un número muy grande:
generador = (num * 10 for num in range(1000000000))Podremos probarlo como cualquier otro generador:
for numero in generador:
print(numero)Mostrará inmediatamente la salida:
0
10
20
30
40
50
60
70
80
90
…Y tardará bastante mostrando resultados antes de terminar.
Cuidado con la creación de estructuras no deseadas
El código anterior devuelve datos inmediatamente.
Sin embargo, si nos equivocamos y creamos un listado:
listado = [num * 10 for num in range(1000000000)]Y lo ejecutamos:
for numero in listado:
print(numero)Notaremos que el código se bloquea bastante rato (minutos) y cuando termine de crear el listado empezará a devolver resultados; eso sino nos hemos quedado sin memoria antes, el sistema operativo mate a nuestro proceso y nos quedemos sin ningún resultado tras la larga espera.
Detectar el cierre (close) de un Generador
No suele hacer falta cerrar un Generador, pero si lo necesitamos podremos hacerlo con el método “close()”.
generador.close()Realmente no tenemos que llamar a “close” nosotros debido a que es llamado automáticamente por el “recolector de basura” (Garbage Collector) de Python cuando el Generador no va a ser utilizado más (porque se ha terminado de recorrer o ya no hay variables que apunten al Generador).
Por lo que, terminando de recorrer al Generador o eliminando el puntero de todas las variables será llamado “close” automáticamente; es decir, bastaría con llamar a “del” para eliminar el puntero y que le recolector de basura haga su trabajo:
del generadorEl método “close” va a lanzar una excepción “GeneratorExit” dentro del Generador (modificaré la “función Generadora” que llamamos “funcion_generadora_print”):
def funcion_generadora_print():
try:
print("GENERADOR: Se va a generar un PRIMER dato")
yield "valorGenerado1"
print("GENERADOR: Se va a generar un SEGUNDO dato")
yield "valorGenerado2"
print("GENERADOR: Se va a generar un TERCER dato")
yield "valorGenerado3"
except GeneratorExit:
print("GENERADOR: Se ha capturado la excepción GeneratorExit")Que podremos probar con:
generador = funcion_generadora_print()
print(next(generador))
print(next(generador))
print("Cerrando el generador")
del generador # Y el recolector de basura de Python llama a generador.close()Y que imprime:
GENERADOR: Se va a generar un PRIMER dato
valorGenerado1
GENERADOR: Se va a generar un SEGUNDO dato
valorGenerado2
Cerrando el generador
GENERADOR: Se ha capturado la excepción GeneratorExitPero no es una buena práctica capturar la excepción “GeneratorExit” si lo que queremos es detectar la terminación del Generador, ya que si tuviéramos cualquier otro error dentro del Generador nunca entraría por la captura de la excepción “GeneratorExit” (por el “except GeneratorExit”) cuando se “close” sea llamado (pues el Generador ya no estará disponible).
Si queremos detectar la terminación del Generador en todos los casos tendremos que utilizar “finally”:
def funcion_generadora_print():
try:
print("GENERADOR: Se va a generar un PRIMER dato")
yield "valorGenerado1"
print("GENERADOR: Se va a generar un SEGUNDO dato")
yield "valorGenerado2"
print("GENERADOR: Se va a generar un TERCER dato")
yield "valorGenerado3"
finally:
print("GENERADOR: Terminando y limpiando")Si ejecutamos imprimirá:
GENERADOR: Se va a generar un PRIMER dato
valorGenerado1
GENERADOR: Se va a generar un SEGUNDO dato
valorGenerado2
Cerrando el generador
GENERADOR: Terminando y limpiandoPor cierto, si agotáramos al Generador (hasta que lance StopIteration) también se limpiará automáticamente (y no tendremos ni que eliminar al Generador a mano con “del”):
generador = funcion_generadora_print()
for elemento in generador:
print(elemento)Imprime:
GENERADOR: Se va a generar un PRIMER dato
valorGenerado1
GENERADOR: Se va a generar un SEGUNDO dato
valorGenerado2
GENERADOR: Se va a generar un TERCERO dato
valorGenerado3
GENERADOR: Terminando y limpiandoTipos de Generadores
Los Generadores se pueden clasificar en:
- Finitos: Devuelven un número determinado de datos; es decir, en algún momento deja de devolver datos y el flujo del programa sigue más allá del código de la función Generadora (por ejemplo, un Generador de números del 1 al 100000000000). Este tipo de Generadores es el que más se suele confundir con los listados (list) ya que se “parece” (un listado es finito y se usa igual que un Generador).
- Infinitos: Devuelven datos eternamente; nunca van a dejar de devolver datos, por lo que no terminan y el flujo de programa se queda siempre en el mismo punto (aunque se podría forzar la terminación, por ejemplo, cuando me haya devuelto 100 datos ya no quiero más y fuerzo a terminar el bucle que lo recorre; si el bucle es “for” se puede forzar su detención con un “break”). Un problema de este tipo de Generadores es que se podría detener de manera indefinida esperando por el siguiente dato (por ejemplo, un hilo que consulte cada cinco segundos a un servidor en Internet de manera ininterrumpida y los datos consultados los devuelva a través de un Generador; esto es infinito, pero si el servidor se bloquea por lo que sea, el Generador también y el programa se quedará esperando por los datos del Generador).
- Indefinidos: Dependerán completamente de los parámetros de entrada a la “función Generadora” que el Generador sea finito o infinito (cuando se “determine” su “indefinición” será alguno de los anteriores: finito o infinito). Existen dos tipos:
- Por definición Directa: Se le pasa algún parámetro (int, str, bool, etc.) que defina el tipo de Generador que se creará (finito o infinito). Por ejemplo, podríamos tener una “función Generadora” que devolviera palabras, y que esta “función Generadora” tenga un parámetro booleano que si es verdadero (true) devuelva palabras de un diccionario de la A hasta la Z una a una hasta agotarlas (Generador finito); y si el parámetro se pone falso (false) devuelva palabras del diccionario al azar eternamente (infinito).
- Por definición Indirecta (O Intermedios): Toman el flujo de datos (posiblemente datos provenientes de otro Generador, o de una fuente continua de datos como puede ser una consulta a Internet en tiempo real o “eterna”), lo procesan y lo devuelven, así hasta agotar el flujo de entrada (finito) o no (infinito); que a su vez el flujo de salida podría ser utilizado por otra “función Generadora” y por tanto por otro Generador (para mi gusto este tipo de Generadores es el más interesante y los que más te van a ayudar en el tratamiento de los datos en flujo/Streaming, sobre todo muy útil a nivel profesional para procesar grandes cantidades de datos, al instante y en tiempo real). Este tipo de Generador también es muy útil para obtener los datos procesados desde otro hilo/proceso.
Tipos de estructuras de datos
En Python (y otros lenguajes) se pueden distinguir tres tipos de estructuras de datos:
- De memoria principal (memoria RAM): Listados (List), Diccionarios (Dict) o Conjuntos (Set). Lo bueno de estas estructuras es que son muy rápidas, pero tienen el inconveniente de usar la memoria principal que es escasa (es mucho menos que la secundaria, actualmente un ordenador puede tener unos “pocos” Gigabytes) y es cara. Por ejemplo, un listado muy grande podría ser mayor que la memoria principal, lo que empujaría al sistema operativo a matar al proceso que más se esté pasando con la memoria principal y que podría ser nuestro proceso Python ¿Realmente existe algo tan grande? Big Data, es decir, intenta trabajar con datos de varios Terabytes en memoria principal (por ejemplo, diez años de datos sobre información meteorológica), no caben.
- De memoria secundaria (Disco duro): Ficheros (File) o Bases de datos (SQLite). La memoria secundaria se suele tener mucha (actualmente un ordenador puede tener unos cuantos discos duros de varios Terabytes cada uno) ya que es muy “barata”, pero es lentísima. Por ejemplo, podríamos buscar un dato en un fichero tremendamente grande (por lo que la memoria principal estaría vacía para realizar esta operación), pero posiblemente nos eternicemos (hablamos de tardar minutos en completar una búsqueda si el fichero es muy grande, y si hay que realizar muchas búsquedas ya nos iríamos a horas o días).
- De procesado (apenas consume memoria RAM, pero sí mucho procesador): Generador (Generator). Al obtener cada uno de los datos en el momento que lo necesita procesar no consume apenas memoria principal. Lo que sí consumiría memoria sería el dato ya procesado, que hay que dejarlo en alguna parte (disco duro o memoria RAM). Una ventaja es poder utilizar cada dato a medida que se devuelve procesado y descartarlo inmediatamente para liberar memoria; por ejemplo, se podría enviar por Internet una vez procesado y así ya nos deshacemos de él, o bien se pinta por pantalla (se muestra en la consola) y ya no nos hace falta (liberamos la memoria), puede que lo tengamos que almacenar en un fichero y así no consumiría memoria principal (aunque sería lento, pero para eso existe el truco de tener otro hilo/proceso que consuma los datos procesados y que sea este otro hilo/proceso el encargado de guardarlos en fichero). El principal inconveniente que tiene el Generador es que los datos no existen hasta que se piden (por eso no se puede usar len(), porque no se sabe cuántos datos va a generar un Generador hasta que termine de procesar todos los datos, si es que es un generador finito).
Como se puede apreciar cada estructura de datos presenta unas ventajas, pero de los inconvenientes no se libra ninguna. Por estos motivos hay que entenderlas bien, para sacar el mayor provecho y combinarlas con cabeza para conseguir el máximo beneficio de los recursos disponibles (por favor, sin consumir hasta explotar la memoria RAM, seamos generosos con otros procesos que no son nuestros y que también la necesitan, o sino el sistema operativo no tendrá reparos en sacar el machete para matar procesos que consuman mucho 😉 ).
Orden de importancia de las estructuras de datos
La estructura de datos tipo “Generador” es la más importante (las demás también son importantes, pero si hay que poner un claro ganador es esta y en breve entenderás el porqué) y la que más interesa entender para utilizarla desde ahora. Recuerda, el resto de las estructuras de datos también son importantes, pero el “Generador” es especial, primero porque es la más abstracta por lo que es ligeramente más compleja (aunque una vez entendida es sencilla y se ve muy claro cuando hay que utilizarla) y que algunos comportamientos no se pueden sobreentender desde otras estructuras (por ejemplo, no se puede obtener la cantidad de sus elementos con “len()”, pues en un Generador finito hasta que no se recorra entero no se sabrá cuantos elementos generará y si el Generador es infinito no tiene sentido).
Por estas razones, si tuviéramos que elegir una estructura de datos para el procesado de los datos tanto en tiempo real como para que el ordenador no se quede sin recursos con nuestro proceso (consuma lo mínimo y solo cuando tiene que consumir), tendríamos el siguiente orden de preferencia (explico en cada punto los motivos por los que tendríamos que elegir la siguiente estructura de datos, pues todas son importantes, pero algunas no se deberían elegir antes que otras):
- Generador: Los datos estarán en el momento que se necesiten, consumiendo la memoria RAM mínima. Deberíamos elegir esta estructura por encima del resto, salvo que no podamos (ver siguientes puntos y razones).
- Diccionario: Si no podemos generar los datos porque ya los tenemos dados (no necesitamos generarlos, ya están pre-procesados o están cacheados), entonces un diccionario es una estructura ideal para realizar búsquedas inmediatas ¿Y si quiero recorrer los elementos del diccionario por el orden de inserción tendría que utilizar un listado? Mejor podemos utilizar OrderDict o en Python 3 ya se asegura el orden de inserción en dict, por lo que usar un diccionario en un bucle “for” ya recorrería en el orden de inserción.
- Conjunto: Si no tenemos una clave que apunta a un valor y no necesitamos el orden de inserción, el conjunto debería ser la siguiente opción para tener en cuenta.
- Listado: La verdad es que hay pocas excusas para usar listados (hace unos años no quedaba otra, pero hoy en día tenemos estructuras de datos mejores y muy optimizadas si se saben utilizar). Una de las principales motivaciones de usar listados puede ser para ordenar valores, pues debemos tener todos los valores en memoria para ordenarlos; porque procesar los datos con otra estructura de datos sea menos eficiente que con un listado; o para recorrer varias veces los datos devueltos por un Generador (por si el procesado del Generador es pesado o único, como no poder realizar más consultas a un servidor por la gran carga de datos que supondría).
- Fichero (o base de datos): Si tenemos tantos datos que tenemos que guardarlos en ficheros para poder trabajar con ellos (debido a que la memoria RAM no tiene tanta capacidad); por ejemplo, para ordenar Terabytes de datos. O si queremos guardar el estado del proceso. Aunque he puesto el fichero en último lugar muchas veces se necesita utilizar por encima de cualquier otra estructura de datos por los motivos previamente indicados, pero al ser una estructura tan lenta no debería ser utilizado al menos que no quede otra.
Nota sobre este orden y razones: es una opinión basada en la experiencia profesional en el manejo de estructuras de datos de gran tamaño.
Como ejemplo completo de uso de las diferentes estructuras de datos, dejo el código libre del paquete Python sorted-in-disk pinchando aquí y que se puede instalar con PIP desde: https://pypi.org/project/sorted-in-disk/
Generador (Generator) vs Iterador (Iterator) vs Iterable
Es fácil confundir estas tres palabras, pero sus definiciones son muy diferentes.
Recuerdo que los Iteradores son todas las estructuras de datos que se pueden recorrer en un bucle “for”: dict, set, list, generator.
Un Iterador (__next__) es un Iterable (__iter__); es decir, la clase Iterador hereda de Iterable. La explicación completa sobre “Iterador vs Iterable” la vimos en detalle en el artículo sobre crear nuestro propia colección en Python pinchando aquí.
Un Generador (yield) es un Iterador (La clase Generator hereda de Iterator), ya que un Generador se puede utilizar “next()” e “iter()” para ir obteniendo cada uno de sus elementos. Y en cuanto se utiliza la palabra reservada “yield” ya se está creando un Generador. Es decir, “yield” solo puede ser utilizado por los Generadores.
Todas las clases sobre estructuras de datos en Python
Después de unos cuantos artículos dedicados al mundo de Python sobre cómo crear nuestras propias estructuras de datos y de cómo utilizarlas, te regalo el diagrama de clases completo (Explicamos paso a paso como especializar tus propias clases en este artículo dedicado):
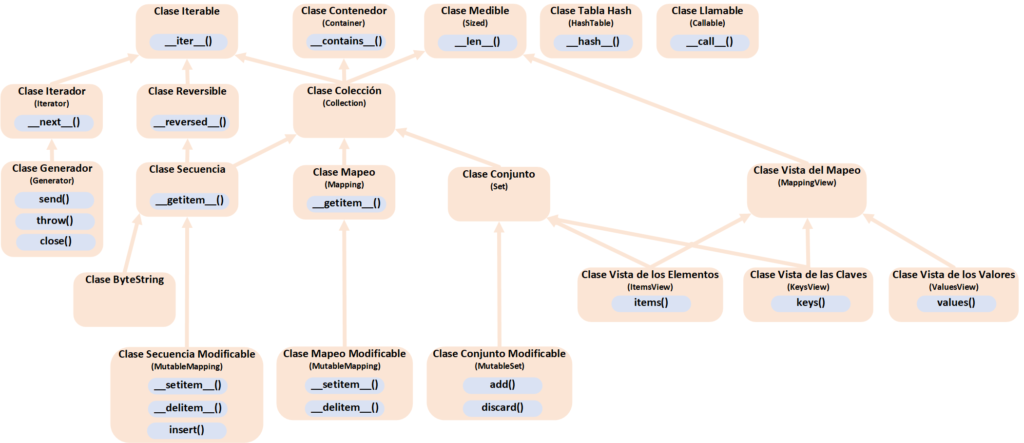
Bibliografía
- https://www.python.org/dev/peps/pep-0342/
- https://www.python.org/dev/peps/pep-0380/
- https://www.python.org/dev/peps/pep-0289/
- https://docs.python.org/3/whatsnew/3.3.html
- https://docs.python.org/3/whatsnew/3.6.html
- https://docs.python.org/3/howto/functional.html
- https://docs.oracle.com/javase/8/docs/api/java/util/stream/package-summary.html
- https://www.python.org/dev/peps/pep-0479/
- https://www.python.org/dev/peps/pep-0255/
- https://docs.python.org/3/reference/datamodel.html
- https://docs.python.org/3/library/stdtypes.html
- https://docs.python.org/3/library/functions.html
- https://docs.python.org/3/reference/compound_stmts.html
- https://docs.python.org/3/reference/expressions.html
- http://nvie.com/posts/iterators-vs-generators/
- https://docs.python.org/2.5/whatsnew/pep-342.html
- https://amir.rachum.com/blog/2017/03/03/generator-cleanup/
- https://docs.python.org/3/whatsnew/3.3.html#pep-380
