Resumibles (Hashables) en Python
Te has preguntado alguna vez ¿Por qué un diccionario (dict) tan solo admite claves diferentes (no puede tener dos claves iguales) y por qué son tan rápidos en devolver el valor que guardan cuando se consultan? Quizá no sea la pregunta que todo el mundo se hace así porque sí, pero sí que es curiosa cuanto menos como para indagar en su respuesta, y esta contestación nos ofrecerá una visión muy amplia sobre cómo funciona, junto con todas las posibilidades que ofrecen los Resumibles («Hashables») si se aprovechan bien.
Si estás leyendo este artículo probablemente hayas utilizado los diccionarios (más ejemplos y explicaciones sobre diccionarios con Python en https://jarroba.com/diccionario-python-ejemplos/). En Python podemos escribir uno así:
mi_diccionario = {
'Una clave': 'Un valor',
'Otra clave': 'Otro valor',
'Otra clave diferente más': 'Otro valor más'
}
La gracia de los diccionarios es que se comportan como las “tablas hash” (si tienes curiosidad de cómo funciona una “tabla de dispersión” o “tabla hash” lo tienes detallado en https://jarroba.com/tablas-hash-o-tabla-de-dispersion/ ).
Para ver esto mejor pongo de primer ejemplo al listado que NO se comporta como una “tabla hash”; si queremos encontrar si el listado tiene un valor dentro hay que ir preguntando posición a posición si el valor está o no, y si encima no existiera dicho valor en el listado entonces habría que recorrerlo hasta el final para asegurar que no exista el valor en ninguna posición.

Con los diccionarios esto no pasa, preguntamos si tiene una clave (la clave sería como el valor guardado de los listados) y sin tener que recorrer nada, nos devuelve inmediatamente si tiene la clave o no.

Imaginemos que tenemos dos cosas: un listado con valores infinitos (a modo de experimento mental, ya que es imposible que sea infinito) y un diccionario con infinitos datos. Si queremos conocer la existencia de cualquier valor en este listado tendríamos que esperar mucho tiempo para saber si existe (por ejemplo, si está por el medio del listado) o un tiempo infinito para asegurarnos de que no existe. Sin embargo, con el diccionario con infinitos datos en su interior sería instantáneo saber si tiene un valor o no. Esta velocidad lo consiguen los diccionarios gracias a que sus claves solo pueden ser Resumibles (Hashables).
Código en GitHub (Recomiendo primero leer el artículo, y descargar/clonar el código al final o para resolver dudas): https://github.com/Invarato/JarrobaPython/tree/master/resumibles
Diferencia entre Resumibles (Hashable) y NO Resumibles
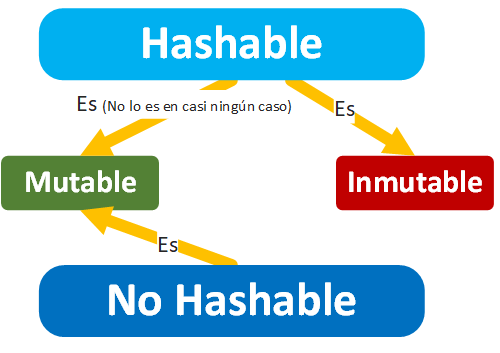
Dicho lo anterior, te pregunto ¿Un diccionario es un Resumible (Hashable)? Un diccionario NO es un Resumible (Hashable).
Entonces ¿No ha servido para nada todo lo explicado anteriormente? Ha servido de mucho, quiero dejar claro y matizar para que te acuerdes de que un Resumible (Hashable) no es lo mismo a que se comporte como una “Tabla hash”. Siempre que algo se comporte como una “Tabla hash” tiene que utilizar algún elemento (una clave o un valor) Resumible (Hashable).
Y ¿Por qué un diccionario no es un Resumible (Hashable)? Resumible (Hashable) es un objeto cualquiera que cuando se le pide devuelve su “Código Hash” y este “Código Hash” siempre va a ser el mismo en cualquier momento de la vida de dicho objeto (no va a cambiar el “Código Hash” en toda la vida del objeto; es muy interesante y recomiendo entender el “Código Hash” antes de continuar, por ello le dedicamos un artículo previo a este en https://jarroba.com/codigo-hash/). Como recordatorio, el “Código Hash” de algo es un texto reducido que lo resume y desde este resumen (“Código Hash”) es imposible averiguar desde quien ha sido resumido. Y un diccionario no es un Resumible (Hashable) porque al poder cambiar su contenido provoca que su “Código Hash” pueda cambiar en algún momento de su vida (a modo de comparación, si piensas en un libro y lees su resumen, si luego el autor del libro añade o quita capítulos a lo mejor el resumen anteriormente leído ya no sirva y sea otro diferente, aunque solo cambie una letra).
Por esto, normalmente los No Resumibles (Hashables) son los mutables (dedicamos un artículo a mutabilidad e inmutabilidad https://jarroba.com/mutables-e-inmutables/ que recomendamos entender para conocer todos los secretos de los “Hashables”):
- List (Listado): Admite cualquier tipo de valores
- Dict (Diccionario): Admite solo claves Resumibles (Hashables) y valores de cualquier tipo
- Set (Conjunto): Admite solo valores Resumibles (Hashables)
Y sí son Resumibles (Hashables) los siguientes inmutables de ejemplo:
- Strings (Texto)
- Int (Número entero)
- Float (Número decimal)
- Bool (Booleano)
¿Entonces podemos concluir que Resumible (Hashable) = Inmutable y NO Resumible = Mutable? Por defecto en las clases incorporadas (built-in) de Python sí (como las que vimos antes lo cumplen: Dict, List, String, int, etc.). Sin embargo, cuando creamos nuestra propia clase (nuestro “Object”) por defecto va a ser Resumible (Hashable) y mutable, va a ser un poco peculiar porque es Resumible (Hashable) y, por contra, es mutable (ya que puede cambiar su estado una vez creado), extenderé esta información más adelante.
¿Acaso el valor de una variable que por ejemplo sea un String no puede cambiar? Un String solo cambia en “apariencia”, realmente se copia a otra posición de memoria con el cambio (aquí pongo un resumen muy rápido a modo de recordatorio, tienes la respuesta completa en https://jarroba.com/mutables-e-inmutables/ ).
Y ¿Si copiamos un diccionario y lo insertamos en otro cómo clave? Porque se puede copiar un diccionario con:
copia_de_mi_diccionario = dict(mi_diccionario)
Pero seguirá siendo apuntado por una variable que podría hacerlo mutar en un futuro (por eso un diccionario es mutable siempre). Y un mutable se pasa siempre por referencia, es decir, se pasa un puntero a ese objeto, no se copia (salvo que lo copiemos explícitamente como en el anterior ejemplo de código), se utiliza el mismo. Por tanto, nunca se podrá utilizar como Resumibles (Hashables), así que nada de crear claves con diccionarios para diccionarios 😉
Obtener el hash de cualquier objeto Python
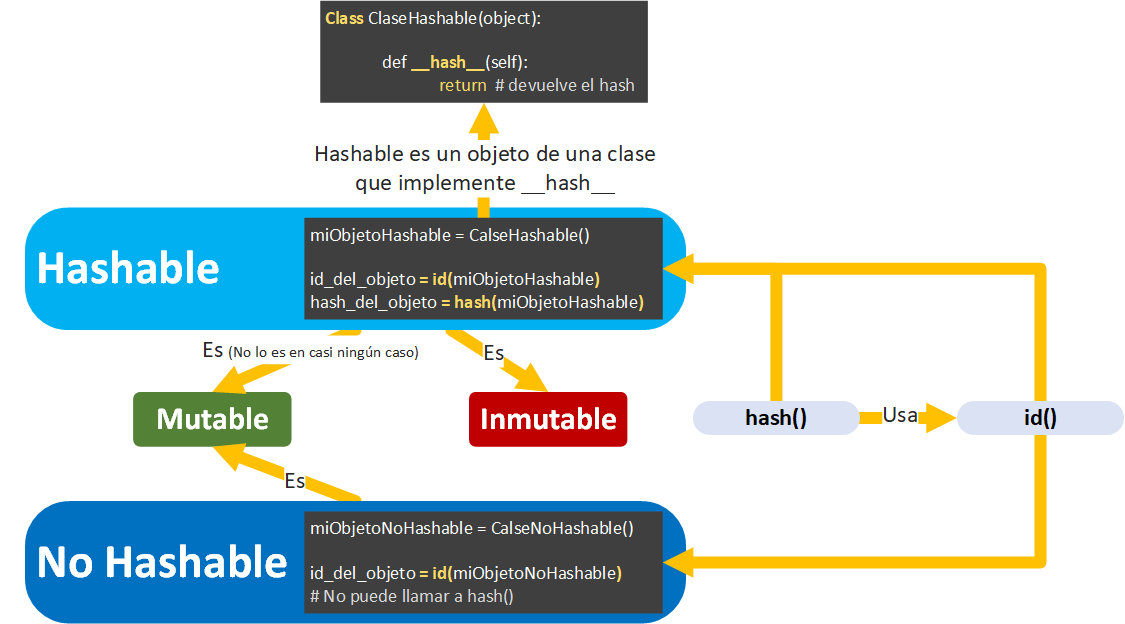
Se puede obtener el hash de cualquier objeto Resumible (Hashable) con la función hash() porque su clase implementa el método __hash__ (que veremos con ejemplos más adelante).
hash_de_mi_objeto_hashable = hash(mi_objeto_hashable)
Si probamos con un objeto resumible (hashable) incorporado (built-in) por Python (como “String” o “int”) vemos cómo funciona. Por ejemplo:
if __name__ == "__main__":
mi_string = "Un texto"
hash_de_mi_string = hash(mi_string)
print('Hash de mi_string: {}'.format(hash_de_mi_string))
Imprime:
Hash de mi_string: 1022738295
Crear nuestro Resumible (Hashable)
Si queremos que alguna clase que creemos sea Resumible (Hashable) tiene que heredar de “Hashable” y sobrescribir al menos el método __hash__ y opcionalmente __eq__.
Si heredamos de “Hashable” tan solo se nos pedirá sobrescribir __hash__ que es siempre obligatorio. Sin embargo, __eq__ solo es obligatorio en algunos casos que por lógica de nuestro código no podamos evitar implementarlo. Además, __eq__ no es obligatorio porque es un método MixIn de “Hashable” (es decir, sino se sobrescribe por defecto tienen código en la clase padre que es utilizable directamente por la clase hija; por tanto, es opcional su sobreescritura, pues funciona por sí mismo).
La diferencia entre los dos métodos (veremos ejemplos de código más adelante):
- __hash__: devuelve un número entero que será el “Código Hash”. Sirve para comparar si dos variables son el mismo objeto
- __eq__: devuelve un booleano “True” si son iguales o “False” si no lo son. Sirve para comparar si el contenido de dos objetos es el mismo (es decir, se comparan los valores que están guardados en un objeto con los que están guardados en otro).
Vamos a querer que una clase sea Resumible (Hashable) para poder utilizar su instanciación como clave de un Diccionario (dict) o Mapeo (Mapping), o como valor en un Conjunto (Set). Estas estructuras utilizan el “Código Hash” para realizar las comparaciones y las búsquedas directas en memoria de manera muy rápida.
__hash__
Que sea Resumible (Hashable) quiere decir que el “Código Hash” del objeto no cambiará en su vida útil. El método __hash__ ha de asegurar que devuelva un “Código Hash” único para cada objeto, y que se mantenga inmutable aunque el estado del objeto cambie (Es decir, si tenemos una clase con la que creamos dos objetos X e Y de la misma clase, el “Código Hash” de X tiene que ser diferente al de Y; pero el “Código Hash” del objeto X siempre será igual, aunque el estado del objeto X cambie en un futuro).
Además, el “Código Hash” devuelto ha de ser impredecible (que desde fuera del objeto sea imposible de calcular) por seguridad; pues existen algunos ataques que se aprovecha de las colisiones de los “Códigos Hash”, al hacerlo imprevisible se evita este tipo de ataques (supón que nuestra clase devuelve para todos los objetos el “Código Hash” 123456; podría utilizar un atacante un objeto creado por él que devuelva el mismo “Código Hash” 123456, por lo que habría una colisión y si Python elige el suyo en vez del mío se ejecutarán cosas no deseadas en nuestro programa).
Ahora puede que te lleves una alegría pues casi nunca es necesario sobrescribir __hash__ pues ya viene implementado como método “MixIn” (ver cuadro de más adelante titulado “Python calcula el hash utilizando el método id()”) en cualquier clase que creemos por defecto (recuerda que heredar de “object” en Python es como no heredar de nada, es la base de todas las clases):
class MiClase(object):
def __init__(self):
self.valor_guardado = None
def set_valor(self, valor):
self.valor_guardado = valor
Y podemos probar que es cierto con (“hash(un_objeto)” llama a “__hash__” del objeto):
if __name__ == "__main__":
mi_objeto_x = MiClase()
mi_objeto_y = MiClase()
print('Hash de mi_objeto_x: {}'.format(hash(mi_objeto_x)))
print('Hash de mi_objeto_y: {}'.format(hash(mi_objeto_y)))
Que imprime por pantalla:
Hash de mi_objeto_x: 1362574070 Hash de mi_objeto_y: 1364705917
Python calcula el hash utilizando el método id()
El método Id() devuelve la “identidad” (como si se tratase del número del carnet de identidad) del objeto y lo tienen todos los objetos sean Resumibles (hashables) o no. La identidad es la dirección de memoria (nota: al menos cuando se utiliza el intérprete Cpython) en el que se encuentra dicho objeto. Como cualquier “identidad” en el mundo se caracteriza de que es única, en este caso única para cada uno de los objetos (se aprovecha que cada dirección de memoria en tu ordenador es única para utilizarla como “identidad”) que necesitemos crear en Python (más información de id() en https://jarroba.com/mutables-e-inmutables/ ).
Hay que aclarar cada vez que ejecutemos nuestro código el hash de los objetos va a cambiar, aunque todo nuestro código sea exactamente igual entre ejecuciones (como hemos dicho al calcularse el hash con el id() que utiliza la dirección de memoria asignada a cada objeto en el momento de la ejecución, en futuras ejecuciones los objetos se encontrarán en diferentes direcciones de memoria).
¿Y si necesitamos devolver nuestro propio __hash__? Pues heredamos de “Hashable” y sobrescribimos __hash__.
Tenemos que asegurar que el número devuelto por el método __hash__ cumpla todas las condiciones antes fijadas:
- Diferente para cada instancia
- Siempre igual, aunque el objeto cambie por dentro
- Que no se repita en distintas ejecuciones (Que no sea predecible)
Podríamos crear el “hash del objeto” con la función “hash()” (se llama igual que la que llama a la función __hash__, por lo que no confundirlas) de Python que nos ayuda. La función “hash()” se le puede pasar una tupla con todos las variables de nuestra clase (para que el “Código Hash” firme a esa clase al utilizar sus variables) y un “salt” (un número aleatorio que asegura que el “Código Hash” generado es impredecible), y nos devuelve un número (positivo o negativo) que es el “Código Hash” calculado con lo que queríamos. Si calculamos el “Código Hash” en el constructor (__init__) ya nos aseguramos de que sea siempre el mismo para el objeto, pero no para otras instancias; así al llamar a __hash__ devolvemos este “Código hash” calculado. Y como puedes ver, el resto de los estados por lo que pueda pasar la clase no influyen en este cálculo.
from collections import abc
import random
class MiHashable(abc.Hashable):
def __init__(self):
self.valor_guardado = None
salt = random.random()
tupla_de_parametros_de_mi_clase = (salt, self.valor_guardado)
self.codigo_hash_del_objeto = hash(tupla_de_parametros_de_mi_clase)
def set_valor(self, valor):
self.valor_guardado = valor
def get_valor(self):
return self.valor_guardado
def __hash__(self):
return self.codigo_hash_del_objeto
Lo probamos (los siguientes “hash(mi_objeto)” llaman a “__hash__” de nuestra clase):
if __name__ == "__main__":
mi_objeto_x = MiHashable()
mi_objeto_y = MiHashable()
print('Hash de mi_objeto_x: {}'.format(hash(mi_objeto_x)))
print('Hash de mi_objeto_y: {}'.format(hash(mi_objeto_y)))
mi_objeto_x.set_valor("Un valor")
mi_objeto_y.set_valor("Otro valor diferente")
print('Hash de mi_objeto_x después de modificar el estado: {}'.format(hash(mi_objeto_x)))
print('Hash de mi_objeto_y después de modificar el estado: {}'.format(hash(mi_objeto_y)))
Imprime por pantalla:
Hash de mi_objeto_x: 1203702863 Hash de mi_objeto_y: -1109119906 Hash de mi_objeto_x después de modificar el estado: 1203702863 Hash de mi_objeto_y después de modificar el estado: -1109119906
Comprobamos que, efectivamente, aunque cambiemos el estado interno (sus valores que guarda), el “Código hash” generado no cambia y para las dos instancias diferentes de la misma clase los “Código hash” son diferentes.
id() vs hash()
Una confusión muy común es que se piense que id() es lo mismo que hash(), y desde ya la desterramos pues:
- __hash__ por defecto (como “MixIn”) utiliza id().
- Si sobrescribimos __hash__ podemos no utilizar id() sino queremos.
- Si el objeto no es Resumible (Hashable) no tendrá __hash__ pero sí id().
- Prácticamente todos los objetos Mutables son No Resumibles (Hashables), por tanto casi con seguridad un mutable no tendrá __hash__ pero siempre id().
- id() nunca utiliza __hash__ (ni “hash()”).
- Id() lo tienen todos los objetos sea mutables o inmutables, Resumibles (Hashables) o no Resumibles.
Habíamos dejado la siguiente pregunta en el tintero ¿Una clase que creemos nosotros por defecto va a cumplir que es Resumible (Hashable) = inmutable y NO Resumible = mutable? Y la respuesta es NO, pues es Resumible (Hashable), porque implementa automáticamente el método __hash__, pero es mutable (ya que puede cambiar su estado una vez creado; además, si se modifica su hash no se ve modificado, porque no es copiado a otra parte de la memoria). Aunque siempre podremos modificar nuestra propia clase para que se comporte como queramos, por ejemplo sobrescribiendo __hash__ o que sea inmutable si conseguimos que no se puedan modificar sus atributos (por ejemplo, con slots o lanzando una excepción si se modifica alguno de sus estados después de ser creado); es decir, podremos obtener cuando tenga sentido cualquiera de sus variantes: Resumible (Hashable) o NO Resumible, inmutable o mutable.
Inmutable vs Resumible (Hashable) vs Mutable
Estas ideas se suelen mezclar, aunque están muy unidas son conceptos diferentes:
- Resumible (Hashable) indica que se puede obtener un resumen (más información de resumen o hash en https://jarroba.com/codigo-hash/ ) desde un dato cualquiera (en la vida real un libro se puede resumir). Por ejemplo, el poder obtener un hash de un objeto (por eso es “Hashable”) con la función hash() porque implementa __hash__.
- Inmutable indica que algo no puede cambiar una vez ha sido creado (en la vida real, el contenido del libro del Quijote no puede cambiar ni una coma porque si no ya no sería el libro que escribió su autor Cervantes y este autor falleció con lo que es imposible que cambie el libro y por tanto su resumen nunca cambiará). Por tanto, su resumen (hash) no cambiará nunca.
- Mutable indica que algo puede cambiar una vez que ha sido creado (en la vida real, si imaginamos que un autor vivo que se dedique a cambiar todos los días el contenido de su libro, aunque el libro es resumible resulta que el resumen no es muy útil para saber de qué trata el libro pues cambia todos los días). Por tanto, no tendrá resumen (hash) por lo que no será Resumible (hashable), o el resumen cambiará cada vez que se modifique el objeto (y esto no sirve para mucho).
__eq__
También tenemos la opción de sobrescribir el método __eq__, que definirá la igualdad de valores, al heredar de Resumible (Hashable). __eq__ tiene que devolver “True” si el contenido de un objeto es igual al contenido de otro, y “False” en caso contrario.
Si un objeto tiene el método __eq__ se le llama “Comparable” (porque se puede comparar).
Si creamos nuestra propia clase será siempre Resumible (hashable) e inmutable por defecto. Pero si solo sobrescribiéramos el método __eq__ (sin sobrescribir __hash__) automáticamente el objeto pasará a ser mutable y el __hash__ devuelto ya no será válido (por tanto, dejará de ser “Hashable” y será solo “Comparable”). Si queremos que siga siendo Resumible (Hashable) cuando sobrescribamos el método __eq__ será obligatorio sobrescribir también el método __hash__. Por esto van de la mano __hash__ y __eq__ en la clase “Hashable”; aunque recuerda que al revés no ocurre lo mismo, es decir que si sobrescribimos __hash__ no es obligatorio sobrescribir __eq__ para que siga siendo Resumible (Hashable) nuestra propia clase.
Nota: Aunque se puede sobrescribir tanto de __eq__ o de __cmp__, pero __cmp__ ya está obsoleto y en Python 3 no existe. Por lo que se recomienda utilizar siempre __eq__.
Para usar el método __eq__ en un resumible (Hashable) es muy sencillo, tan solo tenemos que comparar todos los valores de dentro de nuestra clase que queramos que en nuestro objeto signifiquen igualdad. Esto es más fácil de ver si le añadimos a nuestra clase resumible (Hashable) anterior el siguiente código (voy a poner pseudo código y más adelante te pongo el código completo):
class MiHashable(abc.Hashable):
def __init__(self):
self.valor_guardado = None
def set_valor(self, valor):
self.valor_guardado = valor
def get_valor(self):
return self.valor_guardado
# Resto del código …
def __eq__(self, otro_objeto):
valor_del_otro_objeto = otro_objeto.get_valor()
return valor_del_otro_objeto == self.valor_guardado
Si te fijas, al método __eq__ le llega como parámetro es otro objeto con el que compararse. Lo que se hace es obtener el valor del otro objeto y compararlo con el que ya tiene el mismo objeto al que se le pasa. Es decir, se podría utilizar así:
son_iguales = mi_objeto_x.__eq__(mi_objeto_y)
if son_iguales:
print("El contenido de mi_objeto_x es igual que el de mi_objeto_y")
else:
print("El contenido de mi_objeto_x NO es igual que el de mi_objeto_y")
Aunque Python nos lo pone más fácil para utilizarlo con el símbolo “==”:
if mi_objeto_x == mi_objeto_y:
print("El contenido de mi_objeto_x es igual que el de mi_objeto_y")
else:
print("El contenido de mi_objeto_x NO es igual que el de mi_objeto_y")
Como puedes comprobar, el símbolo de doble igualdad (==) es lo mismo que al objeto de delante pasarle como parámetro el segundo objeto a su método __eq__.
Por otro lado, sino definimos __eq__ (recordemos que es un MixIn con un comportamiento por defecto) ambos objetos se compararán por el id().
Pruébalo tú mismo
Aquí tienes el código completo :
from collections import abc
import random
class MiHashable(abc.Hashable):
def __init__(self):
self.valor_guardado = None
salt = random.random()
tupla_de_parametros_de_mi_clase = (salt, self.valor_guardado)
self.codigo_hash_del_objeto = hash(tupla_de_parametros_de_mi_clase)
def set_valor(self, valor):
self.valor_guardado = valor
def get_valor(self):
return self.valor_guardado
def __hash__(self) -> int:
return self.codigo_hash_del_objeto
def __eq__(self, otro_objeto):
valor_del_otro_objeto = otro_objeto.get_valor()
return valor_del_otro_objeto == self.valor_guardado
Y para que lo puedas ejecutar te facilito el código. En este caso si tienen diferentes valores guardados los objetos:
if __name__ == "__main__":
mi_objeto_x = MiHashable()
mi_objeto_y = MiHashable()
# Si tienen diferentes valores guardados los objetos
mi_objeto_x.set_valor("Un valor")
mi_objeto_y.set_valor("Otro valor diferente")
if mi_objeto_x == mi_objeto_y:
print("El contenido de mi_objeto_x es igual que el de mi_objeto_y")
else:
print("El contenido de mi_objeto_x NO es igual que el de mi_objeto_y")
Imprime:
El contenido de mi_objeto_x NO es igual que el de mi_objeto_y
O si tienen el mismo valor guardado los dos objetos:
if __name__ == "__main__":
mi_objeto_x = MiHashable()
mi_objeto_y = MiHashable()
# O si tienen el mismo valor guardado los dos objetos
mi_objeto_x.set_valor("El mismo valor")
mi_objeto_y.set_valor("El mismo valor")
if mi_objeto_x == mi_objeto_y:
print("El contenido de mi_objeto_x es igual que el de mi_objeto_y")
else:
print("El contenido de mi_objeto_x NO es igual que el de mi_objeto_y")
Imprime:
El contenido de mi_objeto_x es igual que el de mi_objeto_y
== vs is
Es muy frecuente que se confundan, pero rápidamente te lo aclaro.
Objeto_a == objeto_b
A la doble igualdad (==, podríamos traducirlo como “los valores de A son iguales a los valores de B”) se llama comparador de igualdad. Compara si los valores que guardan los objetos de izquierda y derecha de la doble igualdad (==) son iguales. Es decir, que al pasar el objeto_b como parámetro al método __eq__ del objeto_a devuelva True si los valores internos son iguales (como vimos anteriormente), o False en caso contrario.
son_iguales = objeto_a == objeto_b
Un ejemplo de código funcional:
if __name__ == "__main__":
mi_objeto_a = "Un texto"
mi_objeto_b = "Un texto"
if mi_objeto_a == mi_objeto_b:
print("El contenido de mi_objeto_a es igual que el de mi_objeto_b")
else:
print("El contenido de mi_objeto_a NO es igual que el de mi_objeto_b")
Imprime:
El contenido de mi_objeto_a es igual que el de mi_objeto_b
Nota: en este contexto la palabra “igual” no es lo mismo que “idéntico”.
objeto_a is objeto_b
A is (podríamos traducirlo como “La identidad de A es idéntica a la identidad de B”) se llama comparador de identidad. Compara si la identidad de los objetos de izquierda y derecha del “is” tienen la misma identidad. Es decir, que el método id() de ambos objetos (del objeto_a y del objeto_b) devuelva True si es el mismo número identificador tanto para objeto_a como para objeto_b, o False en caso contrario.
son_identicos = objeto_a is objeto_b
Que es lo mismo que escribir:
son_iguales = id(objeto_a) == id(objeto_b)
Y aquí el ejemplo funcional con dos objetos con diferente identidad (además, te muestro lo que devuelve el método id() de cada objeto):
if __name__ == "__main__":
mi_objeto_a = "Un texto"
mi_objeto_b = "Otro texto"
print("Identidad de mi_objeto_a: {}".format(id(mi_objeto_a)))
print("Identidad de mi_objeto_b: {}".format(id(mi_objeto_b)))
if mi_objeto_a is mi_objeto_b:
print("La identidad de mi_objeto_a es igual que la de mi_objeto_b")
else:
print("La identidad de mi_objeto_a NO es igual que la de mi_objeto_b")
Imprime:
entidad de mi_objeto_a: 51311712 entidad de mi_objeto_b: 51311864 La identidad de mi_objeto_a NO es igual que la de mi_objeto_b
Sin embargo, si los dos objetos devuelven la misma identidad (es decir, son el mismo objeto):
if __name__ == "__main__":
mi_objeto_a = "Un texto"
mi_objeto_b = mi_objeto_a
print("entidad de mi_objeto_a: {}".format(id(mi_objeto_a)))
print("entidad de mi_objeto_b: {}".format(id(mi_objeto_b)))
if mi_objeto_a is mi_objeto_b:
print("La identidad de mi_objeto_a es igual que la de mi_objeto_b")
else:
print("La identidad de mi_objeto_a NO es igual que la de mi_objeto_b")
Imprime:
entidad de mi_objeto_a: 12975844 entidad de mi_objeto_b: 12975844 La identidad de mi_objeto_a es igual que la de mi_objeto_b
Nota sobre las optimizaciones de Python: puede crear confusión una optimización que hace Python para ocupar menos recursos. Cuando declaramos dos objetos de clases incorporadas (built-in) en Python con el mismo valor (por ejemplo, dos String con el mismo valor “Un texto”), las variables siguientes que creemos con el mismo valor apuntarán a la primera. Si lo probamos con código veremos el comportamiento:
if __name__ == "__main__":
mi_objeto_a = "Un texto"
mi_objeto_b = "Un texto"
print("entidad de mi_objeto_a: {}".format(id(mi_objeto_a)))
print("entidad de mi_objeto_b: {}".format(id(mi_objeto_b)))
if mi_objeto_a is mi_objeto_b:
print("La identidad de mi_objeto_a es igual que la de mi_objeto_b")
else:
print("La identidad de mi_objeto_a NO es igual que la de mi_objeto_b")
Imprime:
entidad de mi_objeto_a: 20051432 entidad de mi_objeto_b: 20051432 La identidad de mi_objeto_a es igual que la de mi_objeto_b
El identificador devuelto por id() que, recordamos que el intérprete CPython obtiene de la dirección de memoria, nos está diciendo que la segunda variable (mi_objeto_b) está apuntando a la primera (mi_objeto_a).
Como String es una clase de tipo mutable, basta con cambiar su valor de alguna forma para que se cree un nuevo objeto. Por ejemplo:
if __name__ == "__main__":
mi_objeto_a = "Un texto"
mi_objeto_b = "Un texto"
print("[Antes] entidad de mi_objeto_a: {}".format(id(mi_objeto_a)))
print("[Antes] entidad de mi_objeto_b: {}".format(id(mi_objeto_b)))
mi_objeto_b += " y algo más"
print("[Despues] entidad de mi_objeto_a: {}".format(id(mi_objeto_a)))
print("[Despues] entidad de mi_objeto_b: {}".format(id(mi_objeto_b)))
if mi_objeto_a is mi_objeto_b:
print("La identidad de mi_objeto_a es igual que la de mi_objeto_b")
else:
print("La identidad de mi_objeto_a NO es igual que la de mi_objeto_b")
Imprime:
[Antes] entidad de mi_objeto_a: 46137120 [Antes] entidad de mi_objeto_b: 46137120 [Despues] entidad de mi_objeto_a: 46137120 [Despues] entidad de mi_objeto_b: 47049896 La identidad de mi_objeto_a NO es igual que la de mi_objeto_b
“Antes” de modificar mi_objeto_b apuntaba a mi_objeto_a porque tenían el mismo valor (por lo que eran idénticos, eran el mismo objeto), pero “Después” de modificar mi_objeto_b dejaron de ser idénticos (ya eran dos objetos diferentes).
Valores y claves de Diccionarios (dict), Conjuntos (set) y Listados (list)
Hay que entender bien las diferencias e igualdades tanto de los Diccionarios (dict), de los Conjuntos (set) y de los Listados (list) para entender lo que necesitan cada uno. Para entenderlo en cuestión de segundos te facilito la siguiente comparación que he intentado que sea lo más completa y simple posible:

Más información en:
- Listado: https://jarroba.com/list-python-ejemplos/
- Diccionario: https://jarroba.com/diccionario-python-ejemplos/
- Estructuras Python en general: https://jarroba.com/6-formas-mejorar-rendimiento-python/
Bibliografía
- https://docs.python.org/2/glossary.html#term-hashable
- http://ocert.org/advisories/ocert-2011-003.html
- https://docs.python.org/3/faq/design.html
- https://docs.python.org/2/faq/design.html
- https://github.com/python/cpython/blob/master/Objects/dictobject.c
- https://www.laurentluce.com/posts/python-dictionary-implementation/
- http://svn.python.org/projects/python/trunk/Objects/dictobject.c
- https://en.wikipedia.org/wiki/Hash_table
- https://stackoverflow.com/questions/2671376/hashable-immutable
- https://stackoverflow.com/questions/34402522/difference-between-hash-and-id
- https://docs.python.org/2/reference/datamodel.html
- https://docs.python.org/3/library/stdtypes.html
- https://docs.python.org/3/faq/programming.html
- https://docs.python.org/2.0/ref/objects.html

Es muy interesante, y muy didáctica la explicación. Solo hay un pequeño detalle que me gustaría matizar.
Si no estoy equivocado, las clases definidas por el usuario son resumibles Y MUTABLES, ya que en cualquier momento puedes añadir o quitar atributos, o cambiar su valor. Esto lo consiguen porque el valor que se usa ppr defecto para la tabla hash es único para cada objeto, con independencia de sus atributos. Este comportamiento es modificable al definir la clase.
Pues nada, espero que sigas haciendo artículos así de interesantes, da gusto encontrar materiales en castellano sobre Python de tanta calidad. Un saludo!
Buenas Guillermo.
Me alegro que te gusten nuestros artículos 🙂
Gracias por advertir sobre que las clases definidas por el usuario son resumibles y mutables. Efectivamente, tienes toda la razón.
He revisado la documentación, otras fuentes, además que por la propia definición de mutabilidad y he realizado varios tests para validarlo. Por ello, he corregido el error y he rescrito las partes del artículo afectadas.
Para probar que una clase definida por el usuario es resumible y mutable se puede probar con (la modificación del objeto una vez creado no modifica el hash, que a su vez está basado en la posición de la memoria, por lo que no hay nada que indique inmutabilidad, pero sí resumibilidad):
class Prueba(object): def __init__(self): self.val = None def set_val(self, val): self.val = val p = Prueba() print(hash(p)) p.set_val("aaaa") print(hash(p))Fuentes adicionales para validar y corregir este error:
https://docs.python.org/3.8/reference/datamodel.html#object.__hash__
https://docs.python.org/2.0/ref/objects.html
https://stackoverflow.com/questions/12076445/are-user-defined-classes-mutable
https://medium.com/@LisaLeung2/python-objects-mutable-or-immutable-d714f4477c3c
https://towardsdatascience.com/https-towardsdatascience-com-python-basics-mutable-vs-immutable-objects-829a0cb1530a
Entonces, ¿se puede usar un diccionario como valor de otro diccionario, usando su id para calcular un valor hash único?
En un diccionario lo que tienen que ser hashables son las claves, el valor puede ser hashable o no. Estaría permitido esto:
mi_dict = { "clave": {"subclave": "subvalor"} }Pero no estaría permitido esto:
mi_dict = { {"subclave": "subvalor"}: "valor" }He corregido la parte del texto del artículo que creo podría ser la causa de la confusión. Gracias.