Cliente vs Servidor
Cliente y Servidor, dos términos en donde trabajan muchísimos miles de personas para que todo funcione y que tiene un alto nivel de abstracción, tanto que suele ser una asignatura pendiente al confundirse y mezclarse. En este artículo vas a descubrir la diferencia, todo lo que implica y encima sin escribir ni una línea de código, solo con leer y entender las imágenes explicativas.
“Cliente y Servidor” es una arquitectura para comunicarse y distribuirse las tareas. Y en vez de “Servidor” me gusta más la palabra “Proveedor” para entender con detalle y evitar las típicas confusiones que trae implícita la palabra «Servidor» (aunque después de que lo entendamos, utilizaremos siempre la palabra “Servidor”). Por tanto, sería la arquitectura “Cliente y Proveedor”, donde el “Cliente” es quien pide algo y el “Proveedor” es quién ofrece lo pedido por el Cliente.
En la calle una persona es un “Cliente” en una tienda y el tendero es el “Proveedor”, pero fuera de la tienda esa persona ya no es “Cliente” y el tendero no es “Proveedor” ¿Y esto a qué viene? A que el tendero cuando va a comprar al mayorista (tienda donde las tiendas compran al por mayor de palés/cajones de productos) ya no es “Proveedor” sino “Cliente” y el responsable del centro mayorista es su “Proveedor”. También, una persona en su casa puede pedir un favor (Cliente) a otra segunda persona que se lo haría (Proveedor). Ya ves que incluso a nivel de personas estos términos son un poco enrevesados (cambian de dueño); y, sin embargo, el concepto no es más complicado en la arquitectura informática de redes “Cliente y Servidor”.
Volvamos a nombrar “Servidor” al “Proveedor” y no volveremos a llamar jamás “Proveedor” al “Servidor” en el contexto informático (pues la palabra técnica informática es “Servidor” y no “Proveedor”). El término “Servidor” es un sinónimo de “Proveedor” pues “Servidor” es quien sirve a un “Cliente”. Cuando se trabaja con ordenadores no es raro que se disocie el significado de “Servidor” del de “Proveedor” en el contexto de la propia informática, y que se entienda la palabra “Servidor” como un conjunto de cosas Hardware y Software que trabajan lejos, en remoto, para devolver datos por Internet. No obstante, esto es una parte de la verdad, pero no es toda la verdad (como podrás sospechar si lo comparas con el párrafo anterior sobre las personas, tenderos y mayoristas).
Nota sobre los siguientes párrafos e imágenes que los acompañan: El párrafo que está justo encima de la imagen describe paso a paso con unos números entre corchetes cuadrados [N], que hacen referencia al círculo rojo con el número coincidente de la imagen (recomiendo acompañar la lectura con un vistazo a la imagen cada vez que aparezca en el párrafo uno de estos números).
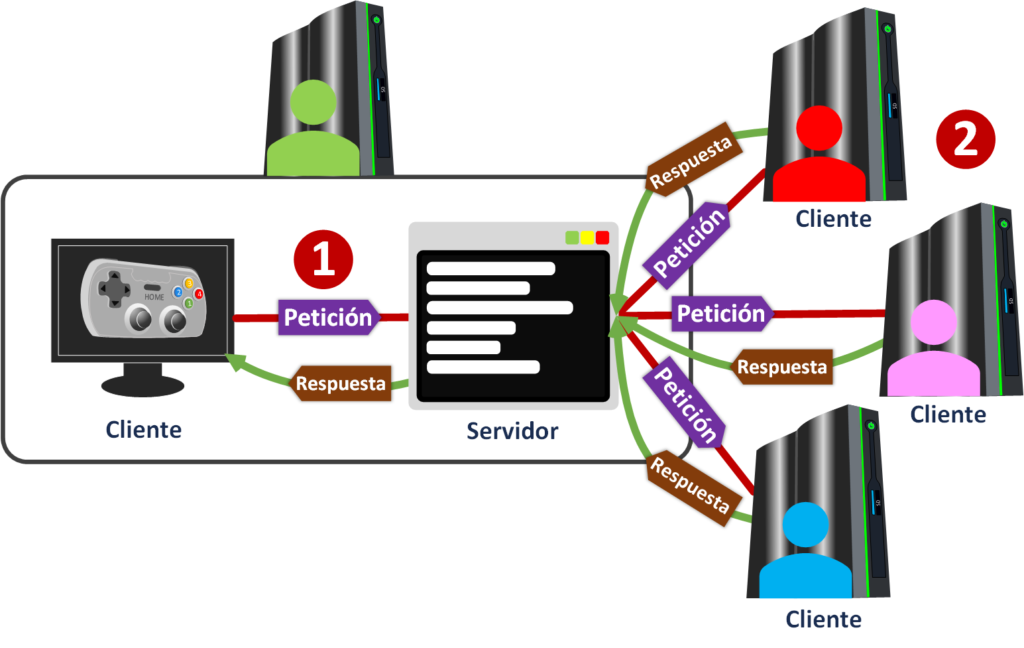
La arquitectura “Cliente y Servidor” más simple que conocemos es el típico que tienes un ordenador (Smartphone, Tablet, Portátil, etc.) que hace de Cliente y mandas peticiones [1] (a través de una aplicación, navegador web, gestor de correo, etc.) a un Servidor (Servidor físico que tiene Servidores Software), que está al otro lado de “Internet” en la otra punta del planeta, el cual procesa esta solicitud (un ejemplo de solicitud puede ser querer ver la web de www.Jarroba.com) y devuelve una respuesta [2] (por ejemplo, el contenido que forma la web: texto, imágenes, etc.).
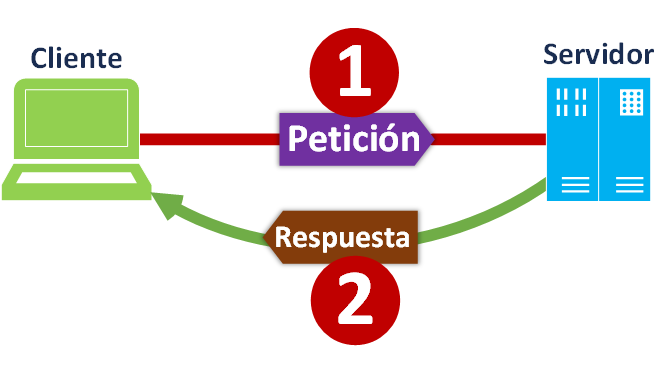
La misma arquitectura “Cliente Servidor” se puede complicar, y lo que era Cliente se puede convertir en Servidor. Por ejemplo, imagínate que tienes un Smartphone (móvil inteligente) en tu mano derecha que se conecta al Smartwatch (reloj inteligente) que está en tu muñeca izquierda. El Smartphone tiene instalada una aplicación de mensajería (como WhatsApp, Hangout, Telegram, etc.) que como Cliente realiza peticiones [1] a un Servidor físico (mediante 3G, 4G, 5G, etc.) preguntando si hay mensajes nuevos, el Servidor físico responde [2] con los mensajes nuevos que le llegan al Smartphone; entonces el Smartwatch pregunta [3] como cliente al Smartphone -que ahora cambia de rol- como Servidor, y como el Smartphone tiene mensajes en su memoria se los devuelve [4] al Smartwatch.
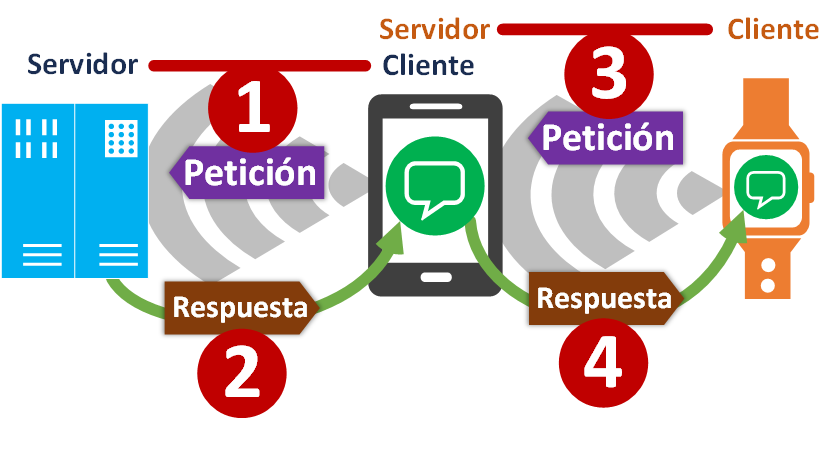
Realmente dentro del Smartphone existirán varios procesos Software, unos que harán de clientes (realizan peticiones) y otros que harán de Servidor (procesan peticiones); aunque también podrá existir un único proceso que lo haga todo.
Otro cambio de roles entre Cliente y Servidor que se lleva mucho ahora cuando se habla de: Cloud (datos procesados de manera distribuida, pero sin que se note) y de Big Data (ingentes cantidades de datos que hay que procesar lo más rápido posible).
Vamos a poner de ejemplo un buscador web como puede ser el de Google, Bing, Yahoo! o cualquier otro. Cuando realizas cualquier búsqueda en uno de estos buscadores web mediante un navegador (por ejemplo, en Chrome, Firefox, etc.) que hace de cliente, este realiza una petición [1] al Servidor físico. Pero resulta que este Servidor físico no es el que tiene los datos (pues son muchísimos, tantos que resulta completamente imposible de tratar, de procesar en un tiempo prudente y de almacenar tanta información, en un solo Servidor físico); por tanto, se encargará de orquestar (balancear) las operaciones al realizar la petición como Cliente (Sí, un Servidor que hace de Cliente ¡Locura!) a otros muchos Servidores físicos (que serán los “Nodos” de esta red de Servidores físicos) a quienes pide a la vez [2] que le devuelvan los datos relativos a la búsqueda. Entonces, los Servidores físicos que hacen de Nodos procesarán cada uno la petición (en paralelo respecto al resto de Servidores físicos Nodos) buscando la información que cada uno tenga de la consulta; cuando un Servidor físico Nodo tiene su parte de información preparada la devuelve [3] de inmediato al Servidor físico que orquesta (que balancea). Resulta que cuando el Servidor físico orquestador (balanceador) recopila toda la información de todos los Servidores físicos Nodos la recompone y se la envía [4] al Cliente principal que eras tú buscando algo en buscador web.
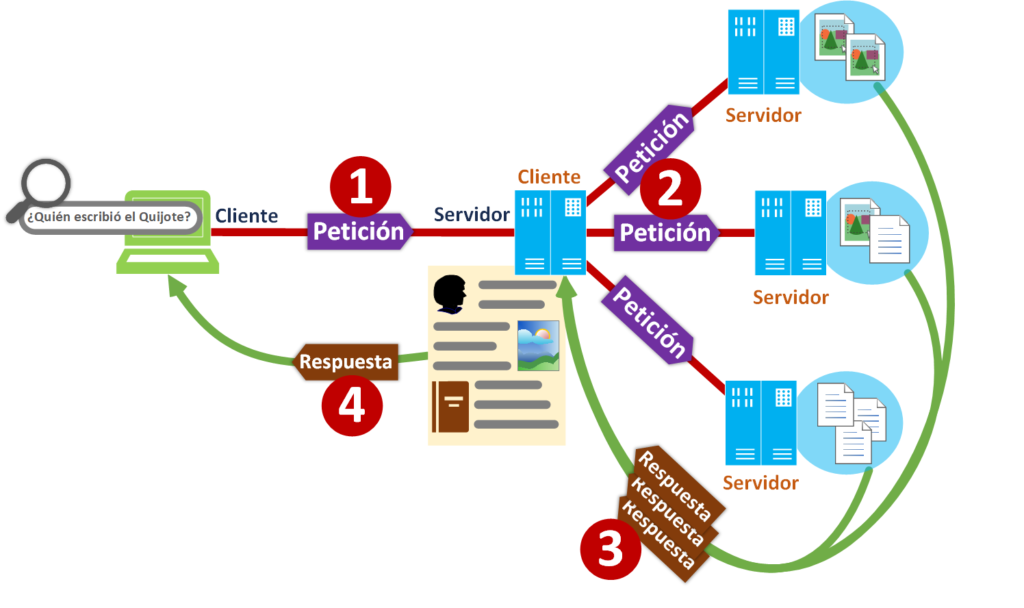
Esto que acabamos de explicar se denomina “balanceo de carga”, pues un Servidor principal que se llama “Balanceador” (o “balanceador de carga”) distribuye la carga de trabajo entre los Servidores secundarios que se denominan como “Nodos” (a la hora de guardar los datos y de distribuir el trabajo).
Nota sobre el balanceo de carga: Aquí lo he simplificado mucho para que se entienda la idea. Sin embargo, una empresa grande como Google o Facebook tendrá unos Balanceadores que distribuirán los datos para guardarlos en los Nodos, otros servidores físicos serán los analizadores de estos datos guardados en los Nodos (por ejemplo, indexando la información para que luego tu búsqueda sea inmediata, realizando cálculos estadísticos sobre esa información como el obtener una idea de tus gustos para ofrecerte publicidad, analizando las imágenes para extraer sus textos o con machine learning deduciendo que hay en las fotos para luego poder hacer búsquedas en ellas; si tienes curiosidad encontrarás más información de Indexación de datos pinchando aquí y de Machine Learning pinchando aquí), y otros servidores serán los encargados de reunir la información para devolverla.
A la loquísima afirmación de “Servidor que hace de Cliente” he de confesar que tiene trampa, pues juega con definiciones mezcladas y es necesario especificar más (parecido a lo que le pasaba al Smartwatch y al Smartphone; la diferencia es que aquí hay varias cosas juntas se las llama “Servidor”): Realmente es un servidor físico (un ordenador/máquina) en el que dentro trabajan dos procesos, uno que hace de Servidor Software (que puede ser un servidor Web, de Sockets, etc.) y otro proceso que hace de Cliente, que será un programa que se ejecutará cuando el Servidor Software tenga la pregunta del usuario (también podría estar el código del Cliente implementado dentro del proceso del Servidor Software, por lo que trabajaría como un solo programa que hace de Servidor por un lado y de Cliente por el otro), momento en el que el proceso Cliente distribuye la pregunta y espera por la respuesta ¿Y está bien dicho “Servidor que hace de Cliente”? Sí, si entendemos este contexto. Y esto no acaba aquí.
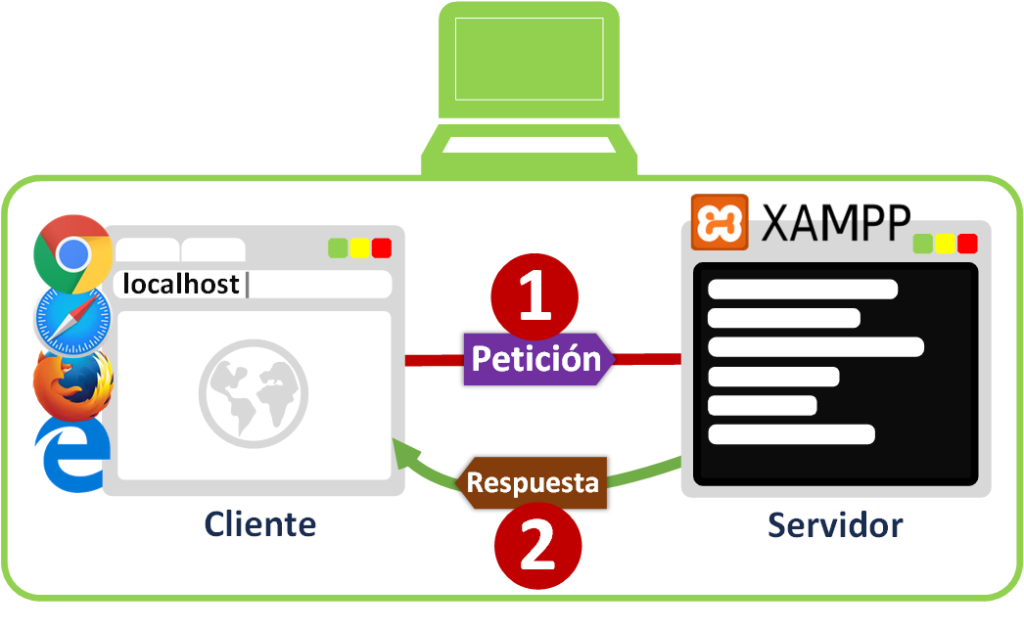
Hemos visto Servidores que están en máquinas distintas al cliente, pero resulta que un Servidor puede estar dentro de la misma máquina que el Cliente. Por ejemplo, si instalamos un servidor XAMPP (si tienes curiosidad te dejo cómo se instala XAMPP en este artículo pinchando aquí) en nuestro ordenador, tendremos un Servidor Web al que podremos llamar [1] desde nuestro navegador de Internet (cualquiera como Chrome, Safari, Firefox, Edge, etc.) que hace de cliente dentro de la misma máquina ¿Y a qué IP llamamos? Pues a la de localhost (que es 127.0.0.1) que indica el deseo de realizar una petición a la misma máquina (nunca sale esta petición a Internet). Y como si fuera un Servidor que está en la otra punta del planeta, pero sin salir de tu ordenador, XAMPP te devolverá [2] una página web que se mostrará en tu navegador ¿Qué página web? Lo interesante de XAMPP es que sirve para hacer pruebas en local de la web que estés construyendo/diseñando como si estuviera publicada (para que solo tu puedas verla).
Y luego está la combinación de todo. Un ejemplo puede ser los videojuegos online. Piensa que tú quieres organizar una partida con tu videoconsola (también vale un ordenador/Smartphone con el juego en cuestión instalado) y que varios de tus amigos se unan a ella a través de Internet (a un juego en el que creas tú la partida; para este ejemplo NO vale un juego multijugador masivo), entonces tu videoconsola por dentro iniciará un proceso que será un Servidor Software del juego que se encargará de gestionar la partida (la posición del personaje de cada jugador, recoger las órdenes enviadas por los mandos de los distintos jugadores, si algunos jugadores sufren de lag/retrasos el Servidor Software hará de juez al decidir si el disparo ha matado a otro jugador o le ha dado tiempo para esquivarlo, etc.). Además, dentro de tu videoconsola tendrás el cliente, que será el propio juego (más concretamente es un proceso que se encarga de recoger toda la información, empaquetarla y enviarla al Servidor Software), que realizará peticiones y recibirá las respuestas [1] al servidor interno (igual que el servidor Software XAMPP antes explicado), sin salir de tu videoconsola. Por otro lado, el resto de las videoconsolas de los amigos [2] se conectan a través de Internet hasta tu videoconsola (que hace de Servidor físico; aunque dentro tiene un Servidor Software y un Cliente ejecutándose a la vez) para que el Servidor gestione la partida y que todos los jugadores puedan jugar a la vez al mismo juego e interactuando entre ellos.
Nota si eres jugador habitual: Esta explicación suele ser más válida para cuando juegas en red local (todos conectados al mismo Router) y antes también era así por Internet. Ahora, al igual que los juegos multijugadores masivos, cuando quieres crear una partida se suele crear en un servidor físico de la empresa que distribuye el juego, aunque hay de todo.
Lo que se ejecuta en el Cliente y en el Servidor
Más o menos funcionan todos los servidores Software de manera parecida y los clientes también. Aquí voy a poner de ejemplo una página web que tenga cierta complejidad para entender el funcionamiento.
Como siempre tendremos dos partes y para este ejemplo son:
- El Cliente: será el navegador web (Chrome, Safari, Firefox, Edge, etc.) instalado en nuestro ordenador.
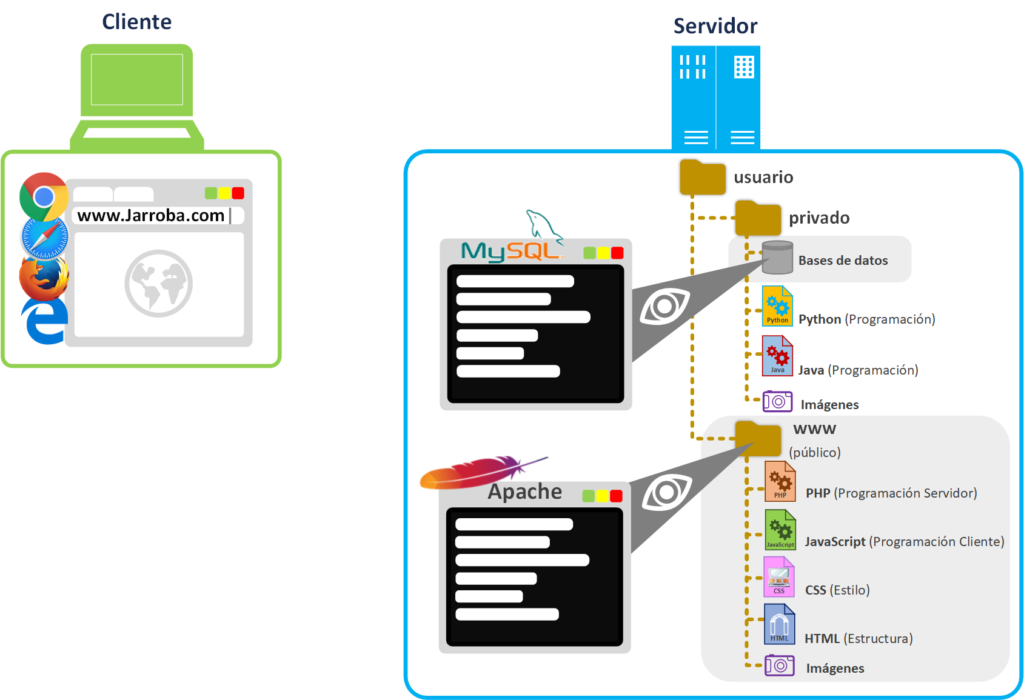
- El Servidor: un Servidor físico cuyo sistema operativo es Linux y tiene varios ficheros dentro de directorios. El sistema operativo del Servidor físico tiene instalado el Servidor web de Apache y también tiene instalado el Servidor de Base de Datos MySQL. Es decir, tendrá ejecutándose a la vez 2 servidores Software.
Para que el Servidor web de Apache haga su trabajo, va a monitorizar continuamente la carpeta que se llama “www” (cuando se instala el Servidor de Apache la crea dentro del directorio “var” de Linux por defecto). Por tanto, cualquier fichero dentro de la carpeta “www” será visible directamente desde el navegador.
Por otro lado, el Servidor de base de datos MySQL creará y monitorizará los ficheros de la base de datos que este cree (serán ficheros con la extensión “.db” que estarán en una carpeta privada para que tan solo este servidor de bases de datos tenga acceso; pues estos ficheros tendrán los datos de nuestra página web, datos como de: usuarios, contenido de la web como puede ser el texto del artículo que estás leyendo ahora mismo, etc.). El servidor web de Apache podrá consultar los datos de la base de datos mediante consultas SQL (el lenguaje SQL sirve para obtener los datos con ciertos filtros, por ejemplo en «pseudocódigo»: «quiero ver los usuarios mayores de edad» o «quiero ver todos los coches que pertenecen a cada usuario siempre que el usuario tenga un coche rojo») para que el Servidor de base de datos consulte entre sus ficheros y devuelva el resultado al servidor web de Apache.
Todo lo que esté fuera de la carpeta “www” será privado (también podríamos jugar con los permisos para que es Servidor de Apache no tenga acceso a ciertos ficheros de la carpeta «www», pero cuidado con los permisos).
Experimentemos algo que sea público en el servidor de www.Jarroba.com, en una pestaña aparte prueba a escribir en la barra de direcciones de tu navegador: https://jarroba.com/images/logos/logo_jarroba.png. Verás la imagen del logo tipo de la web de www.jarroba.com, lo que significa que Servidor web ha obtenido esa imagen del directorio: “www/images/logos/logo_jarroba.png” y te la ha devuelto.
Consejo de seguridad: todo lo que NO sea accesible por el resto del mundo ponlo fuera de la carpeta “www”. Y si puedes, asígna a esos ficheros privados permisos más restrictivos o ten diferentes usuarios con permisos diferentes (por ejemplo, un usuario para el servidor de Apache y la carpeta “www”); pero ten cuidado con los permisos y usuarios, solo lo recomiendo si tienes experiencia, permisos mal dados puedes dar acceso a archivos privados sin querer o bloquear al servidor de Apache archivos que necesita.
Como habrás podido ver en la anterior imagen, nuestro servidor físico tiene dos carpetas:
- www: carpeta pública de donde el servidor web de Apache tomará los ficheros que sean solicitados por los Clientes. Para estos ejemplos he guardado dentro los ficheros: PHP, JavaScript, CSS, HTML, Imágenes, etc. (explico todos estos ficheros más adelante).
- privado: realmente representa al resto de carpetas del Servidor físico que no son accesibles por el Servidor web de Apache. Le he puesto dentro ficheros: Python, Java, archivos con los datos de la base de datos (por ejemplo, para el servidor de bases de datos MySQL es la extensión “.db”), Imágenes, etc.
Aunque hay que saberse la dirección para poder acceder a los ficheros de “www”. Es decir, te he tenido que decir que la imagen estaba concretamente en https://jarroba.com/images/logos/logo_jarroba.png para que la pudieras ver, sino te lo digo no sabrías que esa imagen estaba ahí.
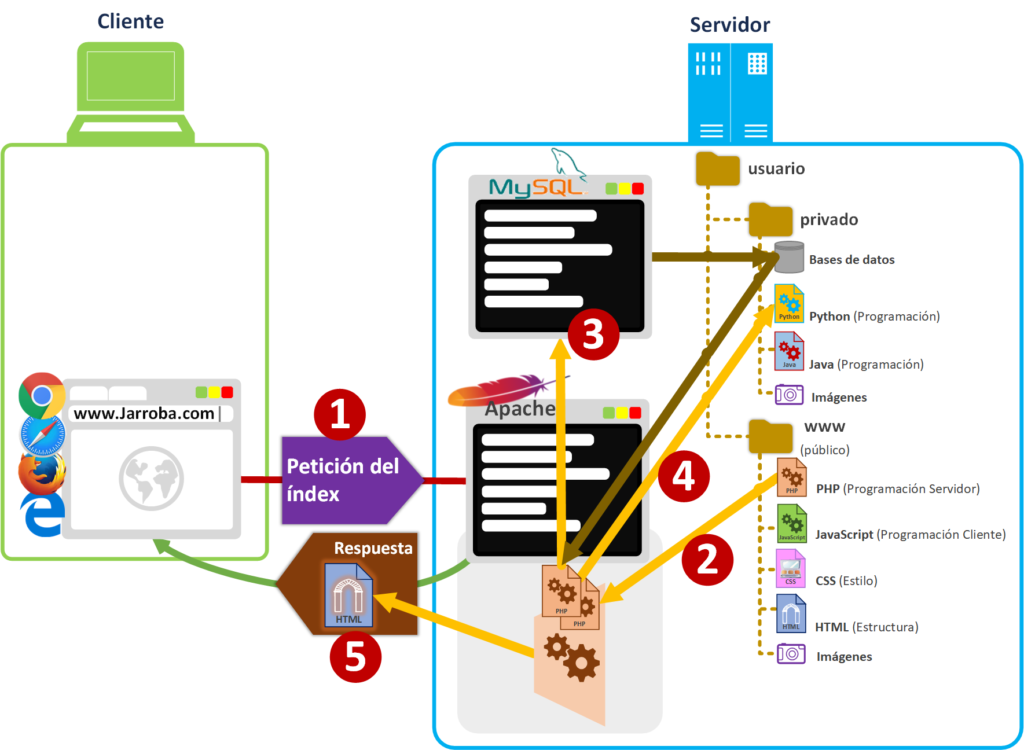
Toda página web tiene el fichero “Index” (“índice”) para que el navegador tenga un índice por dónde empezar a conocer los ficheros de la carpeta “www” del Servidor físico. Por esto, cuando escribimos el dominio en la barra de direcciones de nuestro navegador [1] (por ejemplo: https://jarroba.com) el servidor web buscará el fichero “index” dentro de la carpeta “www”. El fichero “index” podrá tener cualquier extensión dependiendo del tipo de fichero que sea (por ejemplo “index.html” o “index.php”); si fuera tipo HTML (“index.html”) sería devuelto tal cual por el servidor web, pero supongamos que es un fichero PHP (“index.php”) para que tenga más “gracia” (y porque la mayoría de las webs con un poco de “gracia” trabajan con ficheros interpretados).
Cuando un navegador pregunta al Servidor Web, absolutamente todos los ficheros pasarán por sus manos antes de ser entregados al Cliente. Esto quiere decir que hay una serie de ficheros que no va a transferir directamente, sino que va a interpretar (ejecutará el código que tiene dentro el fichero), para el Servidor Web de Apache van a ser los ficheros PHP [2]. Los ficheros PHP se van a llamar entre ellos, pues puede que un fichero PHP se encargue de buscar en la base de datos [3] (el código PHP no busca directamente en la base de datos, realmente el Servidor web de Apache al ver una línea en el código PHP sobre “buscar en la base de datos” llama al servidor de base de datos MySQL, que será el encargado de buscar entre los ficheros donde ha guardado la información) y otro fichero PHP de ejecutar Scripts internos del servidor [4] (por ejemplo, podrá solicitar la ejecución de ficheros Java o Python para realizar trabajo en segundo plano; estos Scripts pueden servir entre otras muchas cosas para: comprimir datos, procesar imágenes, ir procesando un cálculo gordo, distribuir información entre Nodos, etc.). El código interpretado de PHP se encargará de reunir la información para crear el fichero HTML que se vaya a mandar al cliente (se conoce como HTML dinámico; por ejemplo, la página web que necesita de información de una base de datos para completarse, como puede ser la página de perfil de un usuario o el muro de una red social). Entonces manda este HTML creado al cliente [5] (se lo entrega al navegador).
Nota sobre el intento de ver toda la carpeta “www”: Alguien con extrañas intenciones podría intentar descubrir todos los ficheros de la carpeta “www” por fuerza bruta (probando todas las combinaciones de nombres de ficheros y directorios) para cotillear todo lo que tiene dentro la carpeta “www”, si lo consigue ¿Se podría descargar desde el navegador todos los ficheros de la carpeta “www”? Solo se puede descargar los ficheros no interpretables por el Servidor web (y de los que tenga permisos el Servidor web para descargar); como dijimos antes, si intentara escribir la dirección de un fichero PHP ocurriría que le Servidor web de Apache lo interpretaría y le devolvería lo procesado que podría ser algo (una imagen, texto, etc.) o nada (si ese fichero PHP depende de otros ficheros PHP previos a ser ejecutados; o si el fichero PHP requiere cierta información que tiene que ser pasada para funcionar), pero nunca el fichero PHP como tal (no se puede ver el código escrito dentro de un fichero interpretable por el Servidor web desde el navegador; el fichero PHP se ejecuta y puede devolver algo, pero nunca su propio código).
Los ficheros HTML sirven para que el navegador conozca la estructura de la página web, tanto los elementos que va a tener que pintar en pantalla (botones, textos, etc.) como la ubicación de los ficheros que necesita dentro de la carpeta “www” (esta ubicación podrá ser tanto del mismo servidor físico como de otro; aunque no se recomienda que sea de otro servidor físico diferente y menos si no nos pertenece). Entonces, el navegador solicitará los recursos que necesite directamente con las direcciones que venían en el fichero HTML [6] (estos ficheros pueden ser, por ejemplo: HTML, CSS, JavaScript, Imágenes, etc.). El Servidor web de Apache buscará los ficheros solicitados en la carpeta “www” [7] y se los entregará directamente el navegador para que los use [8].
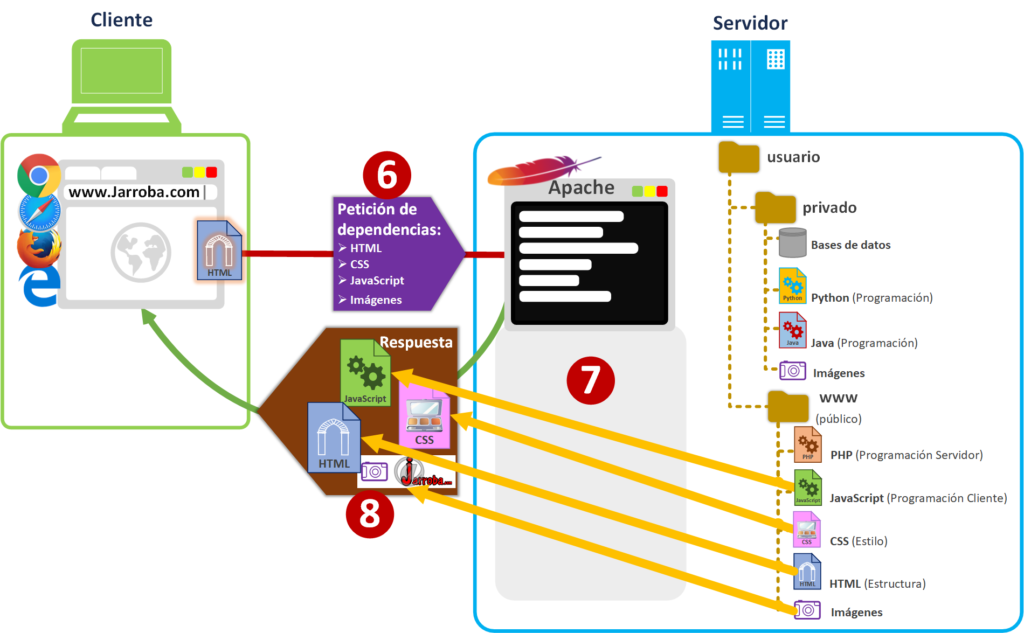
Será cuando el navegador con todos los ficheros en su poder genere el contenido de la página web [9]. Para generar la página web utilizará el HTML principal para crear los elementos (botones, textos, etc.), también usará el CSS (los estilos de mi página web) para colorear y colocar los elementos de una forma bonita; además, podrá utilizar otros ficheros de HTML estáticos para completar partes de la página (por ejemplo, con la etiqueta <iframe>); por otro lado, preparará el código JavaScript para utilizarlo cuando lo diga este código JavaScript (el código JavaScript es código interpretable por el navegador, NO por el servidor web; aunque existen servidores web que sí interpretan otro tipo diferente de código JavaScript, como te explicaré más adelante). Y te mostrará la página web [10] como la que estás viendo ahora mismo en tu navegador.
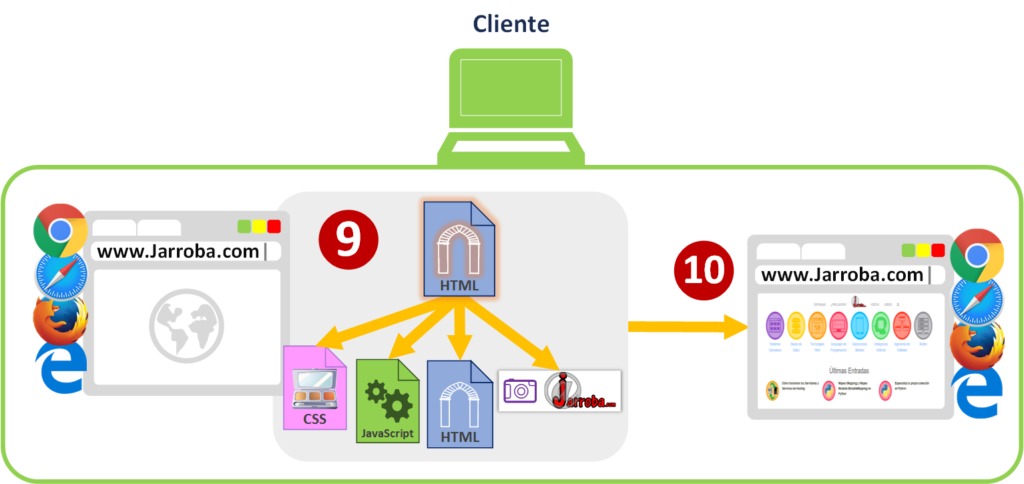
Ahora, el usuario puede utilizar la página web (después de todo el trabajo previo que ha habido por debajo con la arquitectura «Cliente Servidor», y el usuario no se ha dado ni cuenta).
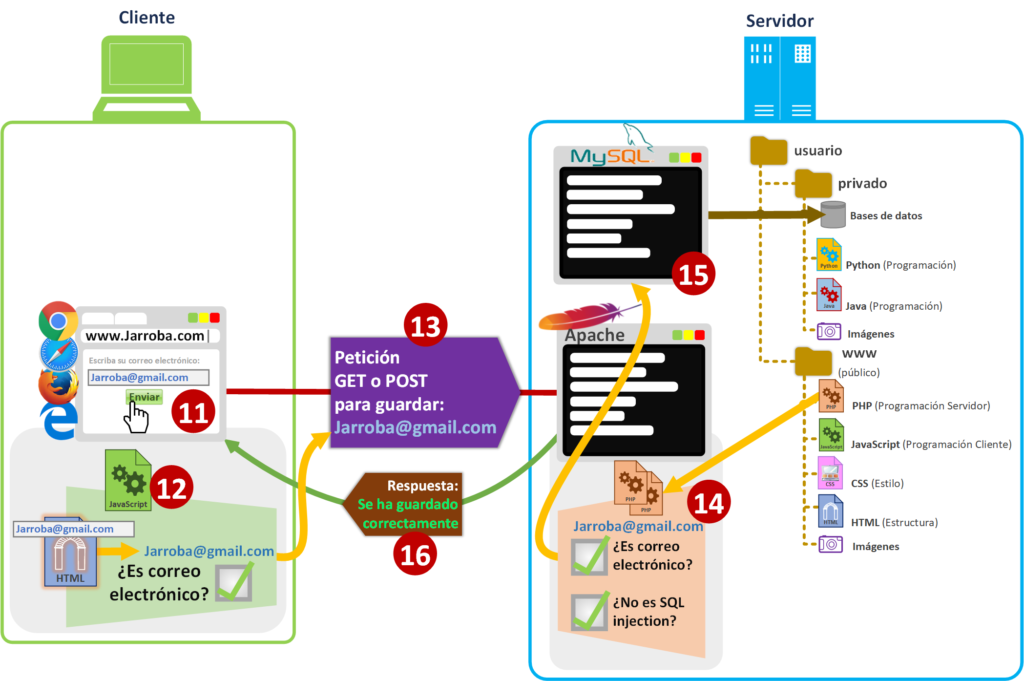
Supongamos que la página web tiene un formulario en el que se pide el correo electrónico (podrá pedirse cualquier dato, aquí resumo con el correo electrónico). El usuario al escribir el dato solicitado en el formulario en la página web mostrada en el navegador y tras pulsar el botón de “Enviar” [11], el navegador utilizará el código JavaScript que acompañaba a dicha página web para validar que el correo tenga un formato correcto [12] (principalmente comprobando que tenga una “@” en medio, un punto después de la arroba y que no haya más de tres letras después del punto; es decir, aplica una expresión regular para que tenga un formato algo así “texto@texto.abc”, si tienes más curiosidad sobre expresiones regulares puedes aprender su funcionamiento pinchando aquí). Si el JavaScrip determina que el correo electrónico es incorrecto avisará al usuario (normalmente el formulario se colorea de rojo y sale un aviso; por cierto, estos colores rojos de aviso los pintará el navegador tal y como se lo diga el fichero CSS); en caso de que determine que el correo electrónico sea correcto lo enviará (por GET o POST; si tienes más interés en profundizar sobre esto, remiendo leer el artículo sobre URL, GET y POST) al servidor web de Apache [13].
Es importante que al recibir la petición en el Servidor web se analice otra vez para que no nos la cuelen (más adelante te cuento unos casos reales sobre los peligros de NO comprobar lo que se recibe en el servidor), ya que en el navegador se puede modificar el JavaScript para que valide como correcto algo que es erróneo (o habilitar un botón deshabilitado). Por eso, con el código interpretable PHP en el Servidor web de Apache analizará (en el lado del Servidor, donde el Cliente no puede manipular el código) no solo que sea un correo electrónico con el formato correcto, sino que no nos estén colando código que pueda ser ejecutable en algún lado [14]; por ejemplo, inyección de SQL (en inglés “SQL injection”; un ejemplo de «SQL Injection» es el intento de borrar la base de datos con u obtener toda la información) o con código PHP (aprovechando a ver si existe algún método eval() que esté casualmente puesto para que ejecute código PHP; por eso escucharás mucho lo de “mejor no usar nunca las funciones eval()” de cualquier lenguaje de programación, o el juego de palabras en inglés de «eval is evil», lo que quiere decir que «eval es el demonio»).
Entonces ¿Sirve de algo validar con el JavaScript en el lado del cliente (en el navegador)? Sí, el hecho de indicar al usuario con el JavaScript que sea correcto o no lo que ha introducido en un formulario es meramente informativo, para que le sea más cómodo al usuario (por “experiencia de usuario” “UX”; es decir, para que el usuario diga que «la página web es fácil de usar» y vuelva). Por lo que si el navegador ha validado como correcto un dato, no implica que ese dato sea realmente correcto. Por otro lado, sí que sirve y mucho para aligerar de carga al Servidor web, ya que al no permitir desde el cliente el envío de cosas que son erróneas, liberamos al Servidor web de tener que estar tratando con “todas” las peticiones sean erróneas o no; solo tendrá que lidiar con la mayoría de peticiones que serán correctas, alguna petición que aunque sea correctas no se puedan añadir en la base de datos (por ejemplo, si ya existe ese correo electrónico en la base de datos) y alguna petición errónea que nos intenten colar.
Si todo ha ido bien, el PHP aceptará el nuevo valor de correo electrónico y realizará la consulta de inserción que se la pasará al servidor de base de datos MySQL quien se encargará de guardar esta nueva información [15].
Para terminar, el PHP enviará una respuesta de que todo ha ido bien al cliente [16] (o no, en caso de que haya pasado algo) para que el JavaScript en el navegador la recoja y muestre al usuario un mensaje de que ha sido guardado correctamente (o de error en caso de que fallara algo).
Salga bien o mal es siempre necesario avisar al usuario con la respuesta del servidor web, no vaya a ser que su correo electrónico no se haya podido guardar en la base de datos por cualquier motivo y el usuario piense que sí (puede que con un correo electrónico no sea muy grave que el usuario no se entere si ha habido un problema o no, pero imagínate lo que pasaría con una transferencia de dinero o con la compra de un producto de una tienda).
Nota sobre las comprobaciones en el lado del servidor y en del cliente: nos las podemos ahorrar al usar ciertos Frameworks que ya las tienen implementadas (“Framework” se puede traducir como “Marco de trabajo” o mejor traducido como “un montón de código que ya está hecho para facilitarnos la vida” 🙂 ; en el lado del cliente tenemos, por ejemplo, JQuery, Angular o React; en el lado del servidor Symfony o el propio PHP tiene algunas funciones de comprobación). Siempre es importante conocer el viaje de los datos por la red entre cliente y servidor, con sus potenciales peligros, para valorar si realmente se están aplicando estas comprobaciones y no ponen en riesgo nuestro servidor, ni nuestros datos y mucho menos a nuestros usuarios.
Sobre otro tipo de ficheros interpretables por el servidor web: los ficheros JavaScript podrían ser ejecutables por parte del Servidor web (como lo son los ficheros PHP) si trabajáramos con un servidor web que los interpretara; por ejemplo, con el servidor web Node.js, que interpreta ficheros JavaScript (en vez de PHP) en la parte del Servidor y puede devolver ficheros JavaScript, aunque están separados los que se pueden entregar al cliente de los que no (cambian un poco las funciones que se usan en cada JavaScript). Lo mismo ocurre con los ficheros Java si se instala un servidor Web como Tomcat, que no ejecuta ficheros PHP sino Java (y también hay Frameworks que nos ayudan en Java como Spring). E igual con ficheros Python con el servidor web Nginx.
La importancia de entender cómo funciona el Cliente junto con el Servidor
Me he hinchado a escribir las diferencias entre Cliente y Servidor con un propósito: que se entienda donde se procesa cada cosa, pues es muy importante tanto a nivel de optimización y más de cara a la seguridad ¿Y qué más da aprender todo esto acerca de Cliente y Servidor si lo que quiero es montar una Web, por ejemplo, o que mis datos se suban a la Nube? Pues da tanto lo mismo como querer cortar algo y no aprender a usar un cuchillo, que luego se agarra por el filo y se intenta cortar con el mango; aparte de que no creo que exista nada tan poco óptimo para cortar, es bastante peligroso 🙁
Si tu intención es crear una página Web has de tener muy claro una cosa: lo que mandes desde tu Servidor al Cliente da por hecho que va a ser alterado (basta con que una persona en todo el mundo con malignas intenciones lo altere para tener problemas) y los datos que devuelve el Cliente por norma NO son de fiar (también, basta con que uno mande datos no fiables). Y no es que no nos fiemos de nuestros usuarios, sino que hay que hacer las cosas bien a nivel de seguridad y comunicación; sería el equivalente a fiarte de dejar el monedero lleno de dinero en la calle y esperar a que mañana siga ahí, no es que no te fíes de la gente, sino que basta con que uno lo haga mal (alguien se lleve la cartera) para que la cosa se desmadre (quedarte sin cartera).
Si tienes un Servidor Web, en el lado del Servidor que tú controlas, se van a procesar una serie de ficheros que se enviarán al lado del Cliente (código HMTL, JavaScript, CSS, imágenes, audios, vídeos, etc.). Cuando estos ficheros estén en el ordenador del Cliente esa persona (o un software, como podría ser un virus) podrá hacer con todos estos ficheros lo que le venga en gana ¿Y qué le viene en gana? Podría pintar sobre una imagen descargada, modificar texto del HMTL o cambiar código JavaScript ¿Puede hacer de todo, como descargar y vender mis creaciones? Aquí ya entraríamos en terreno de la propiedad intelectual, que es otra cosa más grave que implica un delito/infracción (que alguien descargue lo que sea de tu Servidor, para luego vender lo que pertenece a tu propiedad intelectual con todo el morro, sin si quiera pedir permiso). A lo que me refiero es que alguien (sin incurrir en temas de propiedad intelectual) en su ordenador privado (sin salir de su casa) modifique lo que le ha llegado desde el Servidor (que no es ilegal); luego, la respuesta al Servidor vendrá dada en base a esas modificaciones.
Ejemplos de lo que no hay que hacer basados en casos reales
Imagina una persona que tiene una tienda física pero que no tiene muchos conocimientos sobre redes (sin tener ningún conocimiento de los que has aprendido en este artículo) y que crea una tienda online, una página web en la cual vender sus productos. Esta persona ha programado el código en base a copiar y pegar de cualquier sitio cachos que hacían lo que quería (sin entender que hacían esos cachos de código). Entonces prueba que su web funciona tal como quiere: añade artículos al carro y a la hora de pagar le aparece un precio que es correcto; la web funciona según sus deseos y la hace pública, pero tiene un detalle que ni se le ha pasado por la cabeza (por desconocer cómo funciona todo lo explicado en este artículo sobre Cliente y Servidor): que “las únicas validaciones las ha programado en código que se ejecuta en el lado del Cliente” (esto me ha dolido hasta escribirlo, y si eres programador avanzado de Web habrás sentido que es peor que leer faltas de ortografía; ya verás el desenlace).
Los usuarios entran en su página web y compran sin problemas. Pero resulta que un único usuario con malas intenciones, que tiene unos conocimientos mínimos de HTML (esto no es sarcasmo, con conocimientos mínimos sobran para hacer lo siguiente), añade al carro todos los productos de la tienda, la suma total le sale por un montón de dinero, pero eso le da igual va a pagar cero. Debido a que le vale con cambiar el número del total del dinero a cero en el código HTML que muestra el total en el navegador (cualquiera sin apenas conocimientos puede pulsar el botón derecho del ratón, elegir “ver código fuente de la página” y cambiar un texto), que el código JavaScript lea la cantidad de dinero de ese HTML, se la envíe al Servidor; para que el Servidor emita la factura de cobrado sin ninguna otra comprobación.
Y ahora los líos. Vale que el dueño de la tienda no es tonto, se va a dar cuenta y pueda anular el pedido, pero el cliente tiene una factura que dice que esa tienda le ha aceptado vender ciertos productos por cero ¿Quién tiene la razón? Pues es complicado, el equivalente en la realidad sería a que el tendero de una tienda física se fiara de los clientes para que sean ellos quienes metan el dinero dentro de la caja registradora y tomen el recibo; que uno de los clientes sacara un recibo de compra sin meter dinero en la caja y se llevara los productos gratis ¿Sería robo si tiene la factura? No soy ni juez ni abogado para entrar más sobre si es legal o no, moral parece que no lo es; pero no soy quién para dar una respuesta, solo soy el que previene para que estas cosas no ocurran (mejor prevenir sabiendo, que tener que curar por no haber sabido prevenir).
¿Y esto realmente ha pasado? Y sigue pasando, basta con jugar segundos con el JavaScript, el HTML y las inyecciones SQL a la base de datos de alguna página web para saber si comete errores básicos de comprobación desde el lado del Servidor. La mayoría de los casos que tienen problemas de seguridad por malas comprobaciones se basan en fiarse de que el código JavaScript es suficiente para comprobar que todo sea correcto (lo que indica que no se entiende la arquitectura «Cliente Servidor»), o permitir la ejecución de cualquier tipo de código desde el lado del Cliente (como puede ser inyección SQL o de código interpretable por le servidor, como puede ser PHP, Java, Python, JavaScript, etc.).
Las páginas web de las grandes empresas suelen estar más que protegidas contra estos problemas y otros muchos más, pues suelen contratar a gente muy experta tanto en web como en seguridad. Aunque a veces se confían, pues tampoco están carentes de vulnerabilidades, y luego aparecen titulares de noticias problemas de seguridad en grandes empresas: «robo de base de datos con todos los datos de sus usuarios», «precios erróneos en productos que no han comprobado», «robo de contraseñas», etc.
¿Y la solución/prevención? Se hubiera solucionado si quien crea la web no se hubiera fiado de lo que el Servidor recibe desde el Cliente. Para este ejemplo anterior hubiera bastado con no enviar al Servidor el precio, sino los productos que se quieran comprar (y si de alguna manera el Cliente mandara el precio, se omitiría ese valor), se realizarían los cálculos de lo que va a costar todo desde el lado del Servidor (donde el Cliente no tiene acceso) y se crearía una factura con los precios calculados desde el lado del Servidor que se enviaría al Cliente, para que acepte y tenga una copia. De esta manera nos aseguramos de que no se puedan cambiar los precios y que lo que quiere el Cliente sea vendido justamente sin problemas de ningún tipo.
¿Y si alguien se cuela en mi Servidor y cambia los precios? Ya sería un problema mayor que iría por lo legal, primero que quien ha entrado en el Servidor estaría suplantando la identidad de otra persona con privilegios sobre ese Servidor (con su usuario y contraseña); además, de acceder a información confidencial (a la base de datos de los clientes), si la policía captura a esa persona infractora podría ser acusada por varios delitos.
Nota sobre la fiabilidad legal de este artículo
Lo he escrito en varias ocasiones, no soy ni juez ni abogado, ni a la persona a la que pedir consejo sobre temas legales (recuerda que esta web trata de informática técnica, no de materia legal). Todas las partes legales escritas en este artículo no se tienen que tomar en más consideración que para entender los riesgos, prevenir y de disuadir. Te dejo unos links que me parecen interesantes si necesitas más información:
Ahora puede surgir una duda ¿No hay que poner el precio en el lado del Cliente ni calcularlo? Hay que poner el precio y calcularlo en el lado del Cliente pues es algo básico para que el usuario tenga una buena experiencia de usuario (que vaya añadiendo artículos al carro de la compra y aparezca el total del precio). Y a la hora de pagar hay que volver a calcular todo en el lado del Servidor. Es decir, hay que hacer el trabajo dos veces, pero con diferente enfoque:
- En el lado del Cliente tiene que quedar bonito, para que el usuario vea lo que está gastando y se sienta cómodo utilizando nuestra web.
- En el lado del Servidor tiene que ser preciso, para asegurar que todo está correcto (que no nos cuelen nada).
Y en caso de toparte con alguna página web que tenga algún riesgo de seguridad (tanto los explicados aquí, como cualquier otro riesgo), lo más honorable es ponerse en contacto con el dueño de ese sitio web y explicarle el problema (serías considerado como un Hacker de sombrero blanco, un Hacker de los buenos).
Otro ejemplo real es el de los videojuegos online y la gente que hace trampas a base de modificaciones (los llamados “Chetos”, en el dialecto de los jugadores de juegos online). Supongamos que es un juego en el que cada jugador (clientes) se pide un personaje y que va andando por el mapa (típico juego de primera persona, como puede ser un juego de tiros, llamados en inglés «shooter»). Si el servidor recibe que el personaje está en tal posición y que se ha desplazado hacia delante tantos metros, en el servidor hay que comprobar que la distancia máxima a la que el personaje puede desplazarse en un tiempo dado es la correcta ¿Qué pasa si el jugador truca el código y cambia el desplazamiento del personaje para que se traslade cientos de metros en un segundo? Estaría haciendo trampas y si el servidor no lo comprueba tendría ventaja sobre el resto de los jugadores, creando tanto una mala experiencia para todos los jugadores como yendo en contra de los intereses de la empresa a la que pertenece el videojuego (los jugadores que juegan limpiamente se cansan de las trampas y dejan el juego; sin jugadores, que son los clientes de estas empresas, no habrá compras de su producto y recibirán malas críticas). Son bastantes las trampas que no se comprueban en Servidor de videojuegos: personajes que vuelan (cuando la física del juego no lo permite), apuntado instantáneo con las armas exactamente a la cabeza (cuando es imposible, ya que el desplazamiento requiere un tiempo y la estadística de dar a la cabeza es improbable que sea del 100% siempre), incremento espontáneo del dinero virtual (cuando no lo ha ganado de ningún modo), inmortalidad (cuando no puede serlo), etc.
Es necesario tener en mente estos ejemplos de cómo no hay que hacer las cosas para hacerlas bien, para realizar una buena arquitectura «Cliente Servidor».
Es fácil crear una web con cierta seguridad sin saber programar
Tampoco quiero que crees una web con miedo si no entiendes mucho. Si quieres hacer una página web simple, como un blog, existen paquetes ya creados que tienen implementados varios sistemas de seguridad en el lado del Servidor, como:
Incluso para que puedas crear fácilmente una tienda online con seguridad de comprobaciones desde el lado del Servidor, como:
Aprender a nivel técnico y profesional para poder hacer lo que quieras (como tu propia página web)
Por algo se empieza, por lo que recomiendo los siguientes artículos para empezar a conocer los Servidores tanto físicos como Software y aprender. Digamos que tenemos un curso de web en varios artículos:
- Este artículo que acabas de leer está pensado para ser una introducción al artículo sobre como funcionan los servidores y servicios de hosting, donde te explicaremos paso a paso para aprender a crear lo que quieras de una manera rápida, eficaz y profesional
- Y como segunda parte del anterior punto tenemos cómo configurar servidores Software sobre el Servidor físico, gestionar el Firewall, editar código tanto en remoto como en local y crear una página web paso a paso
- Si vamos a crear una web, podremos crearla directamente en un Servidor Físico o que nuestro ordenador actué como servidor físico para realizar las pruebas de nuestra web con el servidor web que indicamos antes XAMPP, en este artículo te explicamos paso a paso todo lo que necesitas saber
- Es necesario conocer como se realizan las peticiones entre cliente y servidor como explicamos en este otro artículo
- Conocer como funciona el código Hash nos ayudará a entender como transferir información entre el Cliente y el Servidor de manera completamente segura y la necesidad de tener un certificado que haga nuestra web segura (HTTPS) con este otro artículo
- Tienes otros ejemplos de servicios de hosting también en este otro artículo, donde te ayudaremos a configurar tu servidor paso a paso

{kind=link}
Me parece excepcional vuestra Web.
Gracias Rosa, nos alegra que te guste 🙂