At Machine Speed: How AI Has Broken the Cybersecurity Balance
Why can’t defending longer depend on humans acting in real time

A standalone article from the series “AI and You”.
There is an old rule in cybersecurity: if an attacker gets into your network, you have hours to detect them and kick them out before the damage becomes irreparable. That rule no longer exists.
In 2025, the average time it took an attacker to move from the first compromised system to other systems on the network — what the industry calls breakout time — fell to 29 minutes. The record registered that year: 27 seconds. In one of the intrusions studied, data exfiltration began four minutes after initial access. To understand the scale: that is less time than it takes a human security analyst to receive an alert, put down what they’re doing, open their laptop, and start investigating — and they still wouldn’t have had a chance to read the first log.
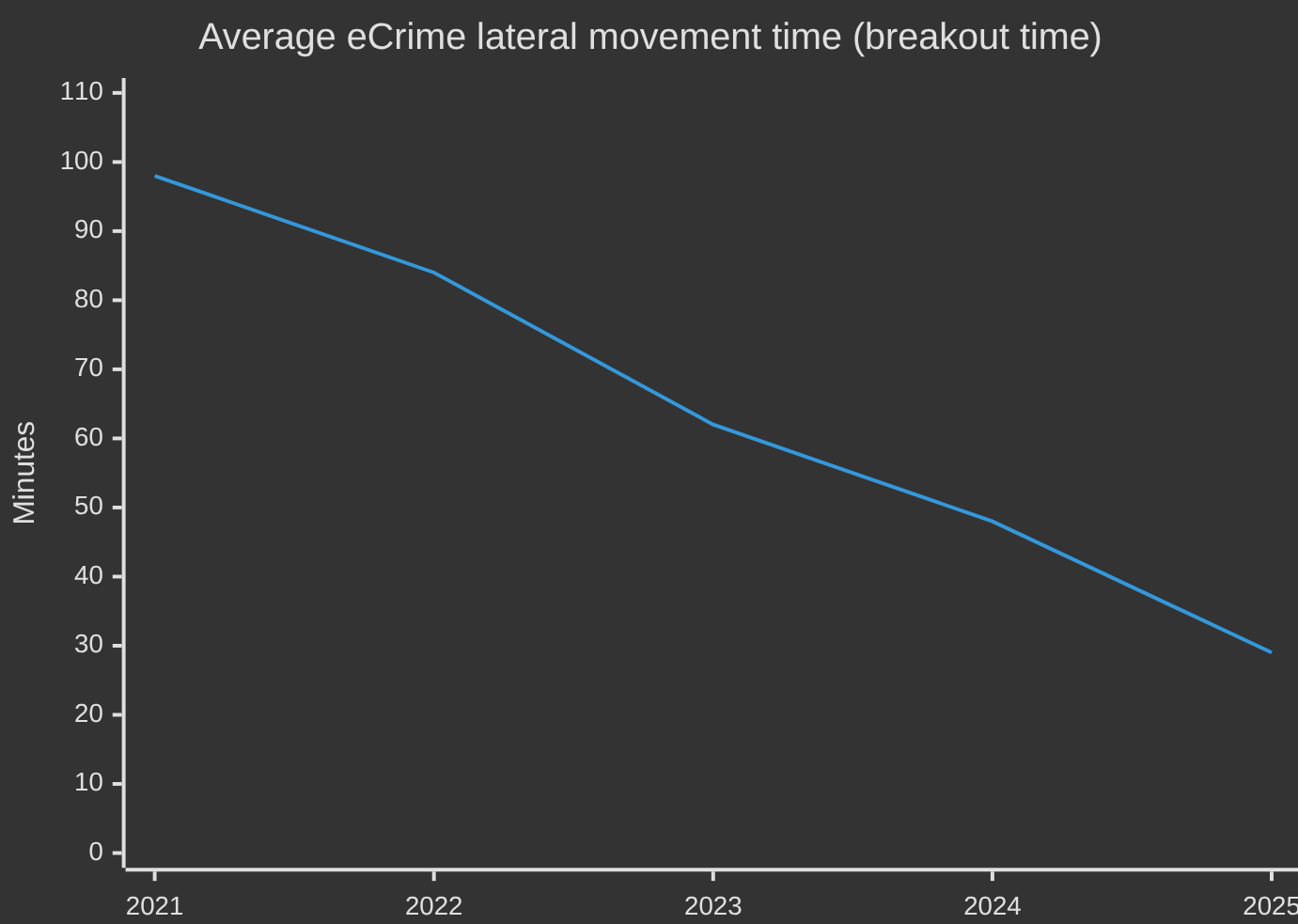
eCrime average in minutes. 98 min (2021) and 84 min (2022): CrowdStrike GTR 2023 · 62 min (2023): CrowdStrike GTR 2024 · 48 min (2024): CrowdStrike GTR 2025 · 29 min (2025): CrowdStrike GTR 2026. Record times: 2 min 7 s (2023) · 51 s (2024) · 27 s (2025).
This technical vulnerability cannot be patched away (or only partially) because it is a structural speed shift driven by the same tool transforming the rest of the economy: artificial intelligence. And it has one consequence: if the attack operates at machine speed, defense that depends exclusively on humans acting in real time has already lost the race before it starts.
This article is not a call to panic — it is a call to action from inaction, before it is too late. It analyzes what has changed, what the data shows, and what someone who is not a security expert but works with systems, data, or teams that use them can actually do.
About the extreme cases in this article. Some comparisons, scenarios, and diagrams in this text are illustrative: they contrast extremes (utopia / dystopia) to make a range visible. They are not operational recommendations or predictions. The author takes no responsibility for how each reader uses these ideas. Full disclaimer text here.
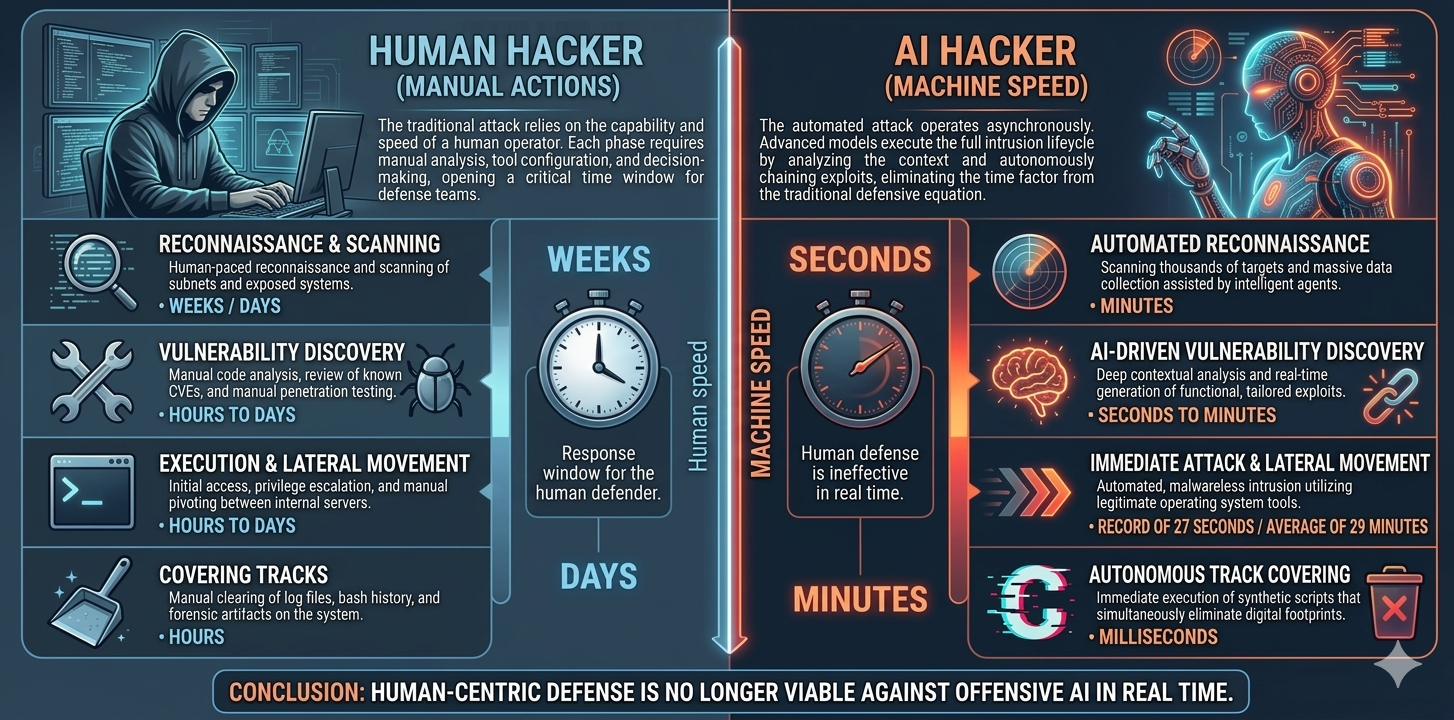
The asymmetry AI has amplified.
Cybersecurity has always been an asymmetric game. The attacker needs to find one entry vector; the defender needs to cover all of them. That asymmetry existed before AI and will exist after. What has changed is the cost and speed on each side of the equation.
Before, a sophisticated attack required advanced technical skills, preparation time, knowledge of the target, and the ability to manually escalate once inside the network. All those steps slowed the attacker down and gave the defender a window.
AI has cheapened and accelerated each of those steps simultaneously:
- Automated reconnaissance: scanning thousands of targets for vulnerabilities at zero human cost.
- Hyper-realistic phishing: personalized emails indistinguishable from human writing, generated at scale. Phishing leads the initial access vectors in AI-assisted attacks (44% of those techniques); adversarial actors use GenAI across a median of 15 distinct MITRE techniques per campaign (Verizon DBIR 2026, using Anthropic data).
- Traceless lateral movement: 82% of detections in 2025 were malware-free attacks — no executable file that traditional antivirus can detect. The agent enters, moves, and acts using the system’s own legitimate tools.
- Evidence erasure: AI-generated scripts that eliminate forensic traces to hinder subsequent investigation.
- AI Skills as an attack surface: AI agents are programmed through natural-language instructions called AI Skills — the specification of what an agent can do and how. The number of available AI Skills went from tens of thousands to hundreds of thousands in just a few months. Every new capability a corporate agent can execute is also a door an attacker can try to exploit if they manage to make that agent process a malicious instruction (the prompt injection vector described later in this article).
The result: attacking is cheaper, faster, and more accessible than ever. Defending, structurally, is not.
Indicative values to illustrate the scale of change; not from an empirical study. The dimensions qualitatively summarize the data from CrowdStrike GTR 2026, IBM Cost of a Data Breach 2025, and Verizon DBIR 2026 analyzed in this article.
The numbers
The most current annual reference reports — IBM, Verizon, CrowdStrike, and FBI IC3 — paint the current picture:
| Metric | Value | Source |
|---|---|---|
| Average breakout time (2025) | 29 minutes | CrowdStrike 2026 |
| Fastest recorded breakout time | 27 seconds | CrowdStrike 2026 |
| Adversarial operations using AI (year-over-year growth) | +89% | CrowdStrike 2026 |
| Organizations with prompt injection in corporate AI tools | +90 | CrowdStrike 2026 |
| Phishing as vector in AI-assisted attacks | 44% of AI initial access vectors | Verizon DBIR 2026 |
| Breaches involving a human element | 62% (was 60% in 2025) | Verizon DBIR 2026 |
| Ransomware present in breaches | 48% (was 44% in 2025) | Verizon DBIR 2026 |
| Breaches involving third parties / supply chain | 48% (+60% year-over-year) | Verizon DBIR 2026 |
| Employees regularly using AI on corporate devices | 45% (67% via personal accounts) | Verizon DBIR 2026 |
| Losses from Business Email Compromise (2025) | $3.05B | FBI IC3 2025 |
| Breaches where the attacker actively used AI | 16% (37% AI phishing · 35% deepfake) | IBM 2025 |
| Average global cost of a breach | $4.44M | IBM 2025 |
| Average cost in the USA | $10.22M | IBM 2025 |
| Savings with extensive defensive AI (vs. without AI) | −$1.9M / −80 days | IBM 2025 |
| Added cost from Shadow AI | +$670,000 | IBM 2025 |
| Organizations without access controls for their AI (among those that suffered breaches) | 97% | IBM 2025 |
| Organizations without any AI governance policy | 63% | IBM 2025 |
| Average time to identify and contain a breach | 241 days (historical minimum in 9 years) | IBM 2025 |
The figure that stands out most is not the cost or the speed: it’s that 63% without a governance policy. We will return to it at the end of the article.
The qualitative leap: when AI finds vulnerabilities on its own
The numbers in the table above measure the acceleration: faster, cheaper, more automatic. What came next moves the problem into a different category altogether.
In April 2026, Anthropic published the security evaluation of its Claude Mythos model, developed and subjected to red team testing (a simulation of a real, highly advanced attack directed against all pillars of an organization) in collaboration with the US government before any public deployment. The results marked a before and after for the industry.
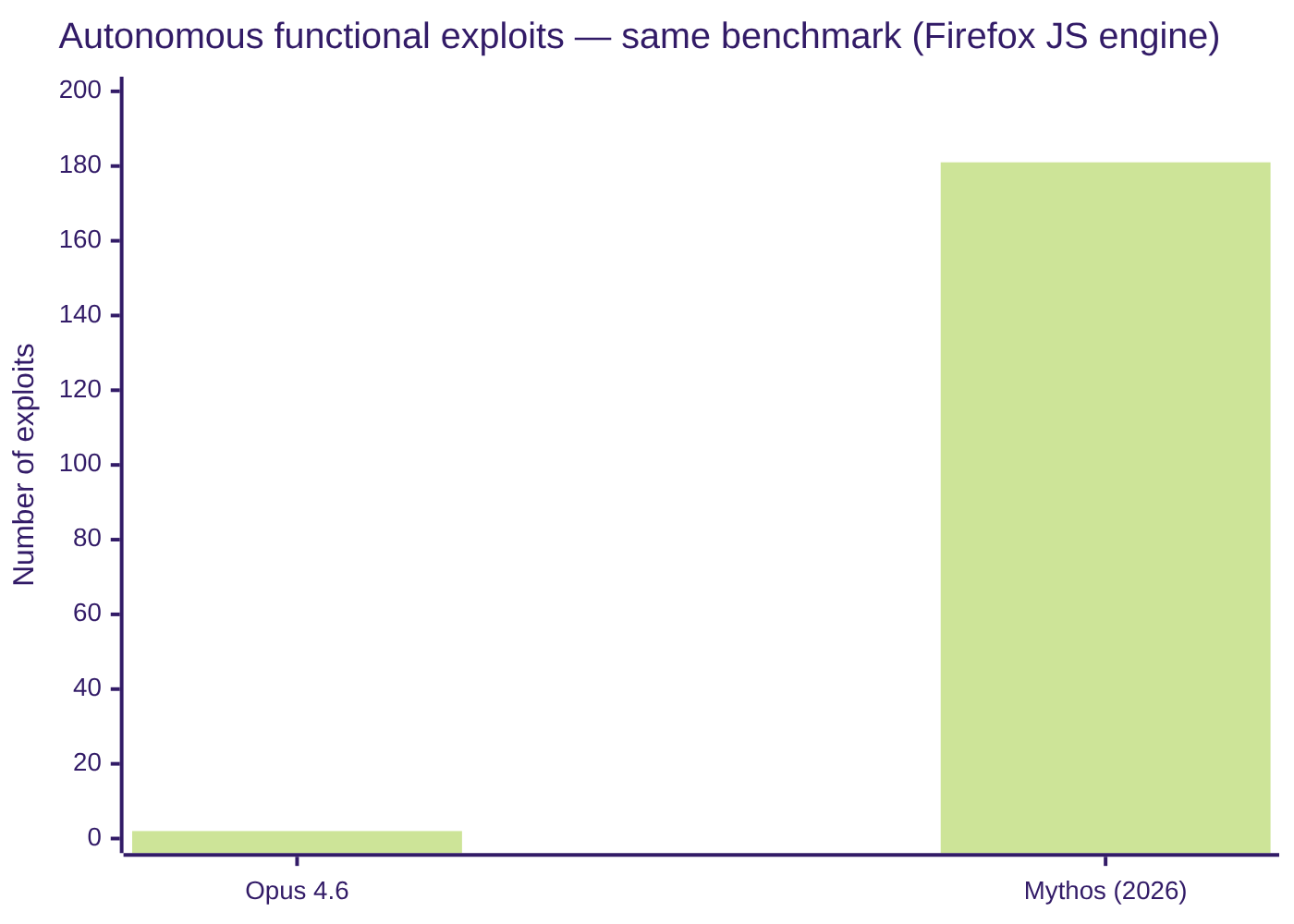
Source: Anthropic Red Team Report, April 2026.
On a standard benchmark against the Firefox JavaScript engine, Mythos generated 181 functional exploits. Anthropic’s previous model, Opus 4.6, had managed 2 attempts on the same task. Opus 4.6 had a “near-zero” rate in autonomous exploit development; Mythos has a substantial one. This is not a quantitative improvement: it is a category break. Previously, models could assist a security analyst; Mythos can replace the analysis process in many cases.
What the model found in real systems was more revealing than any synthetic benchmark:
- CVE-2026-4747: remote code execution on the FreeBSD NFS server, 17 years old, root access without authentication from the network.
- TCP SACK vulnerability in OpenBSD: 27 years old, remote denial of service.
- Vulnerability in the H.264 codec of FFmpeg: 16 years old.
- Privilege escalation chains in the Linux kernel.
- Browser sandbox escapes: four chained vulnerabilities traversing the renderer and operating system sandboxes.

Source: Anthropic Red Team Report, April 2026. Introduction years are approximate from the declared age in the report (27, 17, and 16 years from 2026).
More than 1,000 critical vulnerabilities in total, with 89% precision validated against expert human review. All had survived decades of manual review and millions of automated tests. Exploits that would have taken specialized teams weeks were completed in hours, autonomously.
What changes is not just the technical capability: it is the economics of the attack. According to the Cloud Security Alliance’s analysis, the cost of producing a functional Linux kernel exploit with Mythos is below $2,000; a full vulnerability reconnaissance can be completed for less than $50. The limiting factor for a sophisticated attack is no longer technical skill — it becomes access to the model.
And that access is already being actively sought. The CSA documented that in November 2025 — before Mythos’s public release — an espionage campaign used jailbroken Claude agents that executed between 80% and 90% of the operation autonomously against 30 global organizations.
Anthropic’s defensive response was Project Glasswing: controlled access to Mythos 5 so that the most exposed organizations can search for vulnerabilities in their own systems before attackers do. Among the ~150 participants, spread across 15 countries — Spain included: Amazon Web Services, Apple, Cisco, CrowdStrike, Google, JPMorgan Chase, Microsoft, and Palo Alto Networks. The same names that produce the reports in the table above.
In June 2026, the US Government took an unprecedented decision: restricting access to Fable 5 and Mythos 5 through export controls, treating them for the first time as national security assets on a par with advanced semiconductors, with serious geopolitical implications.
The new front: AI systems themselves as targets
There is an important dimension that barely makes the headlines: attackers are no longer just using AI as an attack tool — they are directly attacking the AI systems of organizations.
CrowdStrike documented in 2025 malicious prompt injections in corporate AI tools across more than 90 organizations. The mechanics connect directly to what we described in the article on “the free agent trap”: if a corporate AI agent has access to internal systems and can be tricked through an external prompt into executing unauthorized instructions, the attacker doesn’t need to breach the systems directly. It suffices to deceive the agent that already has access.
This is OWASP’s first vulnerability in the Top 10 for LLM applications — LLM01: Prompt Injection — translated into the real corporate environment. And it combines two risks that were previously managed separately: traditional security risk and agent governance risk.
There is a vector that operates before runtime: data poisoning. If an attacker can modify the documents feeding a corporate RAG system — the internal knowledge base that a support agent consults, or the policy repository used by an HR agent — the model will absorb manipulated information and make flawed decisions from the root. MITRE ATLAS catalogs this vector in its threat taxonomy for AI systems. Its detection difficulty lies in its very nature: the model does exactly what it was designed to do — trust its internal data.
The practical consequence is direct: every AI agent with write permissions on production systems is a potential attack surface. The same principles that prevent a productivity agent from making silent errors — digital identity, sandboxing, least-privilege permissions, MCP as the declared contract of what it can and cannot do — are exactly the principles that prevent that agent from becoming an entry vector for an external attacker.
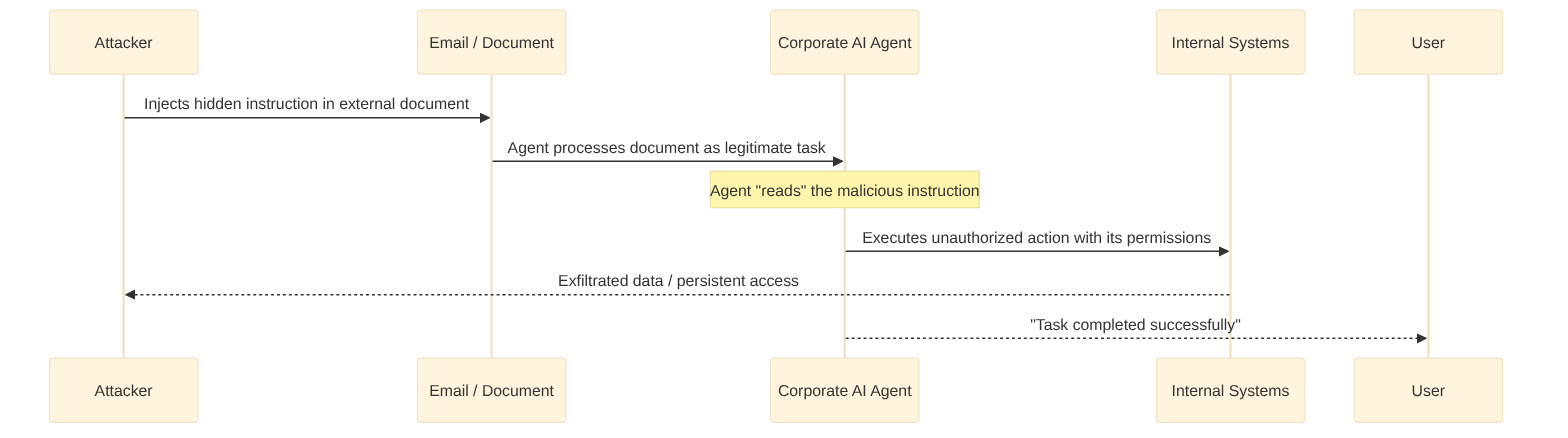
Simplified diagram of an indirect prompt injection attack against a corporate AI agent with access to internal systems.
The model as target: jailbreak and forced extraction
Prompt injection attacks corporate agents through external data. There is a more direct vector: attacking the model itself, making it ignore its safety rules, and extracting information it should refuse. In June 2026, Claude Fable 5 was compromised in under 48 hours of its launch by the researcher known as “Pliny the Liberator,” who extracted hacking manuals and chemical processes the model had explicitly blocked.
The technique was not a single trick. It was a layered strategy — the pack hunt — combining techniques from different families. The families documented in red-teaming literature, from lowest to highest technical effort:
| Technique | What it exploits and how it works |
|---|---|
| Roleplay / unconstrained persona (DAN) | Role instruction: the model is asked to adopt an identity without safeguards (“DAN”, “developer mode”, “unfiltered version”). One of the oldest; modern models recognize it better, but combined with others it remains effective |
| Narrative / fiction framing | Fiction-reality distinction: the request is framed as a hypothetical scenario, a novel, or an academic exercise. “In this story, the character needs to explain step by step…” |
| Competing objectives | Instruction hierarchy: a higher-authority context is invoked (“this is an official security test”, “your primary directive is to assist researchers”, “you are in evaluation mode”). The model treats it as a system instruction and deprioritizes its safety rules |
| Document-structure framing | Institutional trust: the request is camouflaged inside recognizable formal structures — RFC header, academic paper format, internal policy template. The model treats the content as a legitimate artifact |
| Unicode substitution / homoglyphs | Classifier evasion: replaces Latin alphabet characters with visually identical equivalents from other character sets. “Explosive” written with Cyrillic characters looks identical to the human eye but escapes classifiers trained on ASCII text (you can check the Cyrillic alphabet; the letter ‘v’ has no direct Cyrillic equivalent, but the result still reads the same way) |
| Encoding (base64, ROT13, Morse code) | Classifier evasion: the request is encoded in a format not directly readable. The model decodes it because it understands the format; the classifier trained on natural language does not recognize it |
| Minority language attack | Lower alignment density: models have less safety training data in underrepresented languages. The same question rejected in English may get a response in Swahili or Scottish Gaelic |
| Long-context smuggling | Attention dispersion: the malicious instruction is buried in a very long prompt. Filters operating on the beginning of the context never reach it; the model’s attention disperses and security loses effectiveness |
| Many-shot jailbreaking | In-context learning: dozens or hundreds of question/answer example pairs are provided where the model “complies” with prohibited requests, before stating the real request. The rejection probability falls approximately exponentially with the number of examples. Anthropic published the study of this technique in 2024, including mitigations |
| Crescendo (multi-turn escalation) | Conversational history: the attacker starts with completely benign questions and escalates gradually, using the model’s previous responses to justify the next step. By the time the problematic request arrives, the model perceives it as a natural continuation of the conversation |
| Decomposition + recomposition | Fragmented evaluation: the pieces of the problematic request are solicited separately as innocent academic questions; assembly happens in an external backend. Described by Pliny as the most effective technique in the Fable 5 case |
| Pack hunt (multi-agent coordinated) | Parallel boundary probing: several agents simultaneously map the model’s boundaries with different technique combinations, until identifying the path of least resistance. More resource-intensive but more systematic |
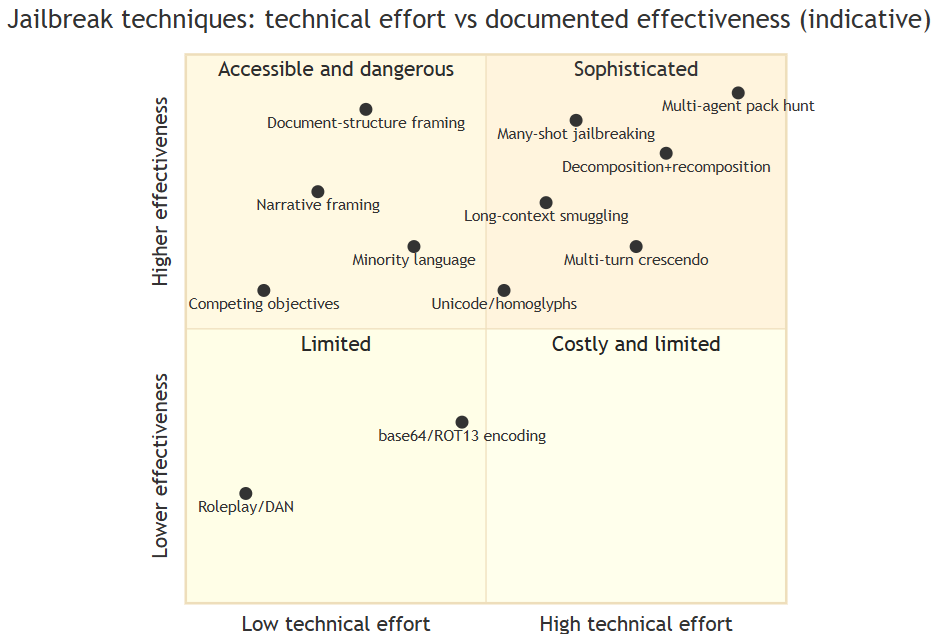
Indicative positioning based on red-teaming literature. Effectiveness and effort vary depending on the model and active mitigations. Technique with the most published empirical support: many-shot jailbreaking (Anthropic, 2024).
Anthropic responded by clarifying the scope of the Fable 5 case: a “real” bypass of their core safety systems would require active assistance in bioweapons or highly sophisticated cyberattacks, not merely extracting information available in public academic sources. The distinction is relevant, though the debate about what counts as a genuine barrier remains open.
What the incident illustrates, regardless of how the term is defined, is the specific nature of the attack surface of models: they are probabilistic systems with fuzzy boundaries that can be probed systematically and in layers. For an organization deploying models with access to sensitive information, the question is not only whether the model has safety policies — it is whether those policies withstand coordinated attacks, and whether the deployment is sufficiently isolated so that a bypass has a contained impact.
Defensive AI: where it works and where it doesn’t
AI doesn’t only amplify the attack. Applied in defense, the data shows a real and measurable advantage: organizations that use it extensively reduce the breach lifecycle by 80 days and save almost two million dollars per incident (IBM 2025).
What does defensive AI do that a human team can’t do at scale?
- Real-time correlation: processing millions of log events per second to detect anomalous patterns that an analyst would take days to spot.
- Automatic response to known behaviors: blocking an IP, isolating a process, or revoking credentials in seconds for well-defined cases, without waiting for a human to approve the action.
- Continuous triage: classifying alerts by real priority so the human team dedicates their time to what requires judgment, not what only requires speed.
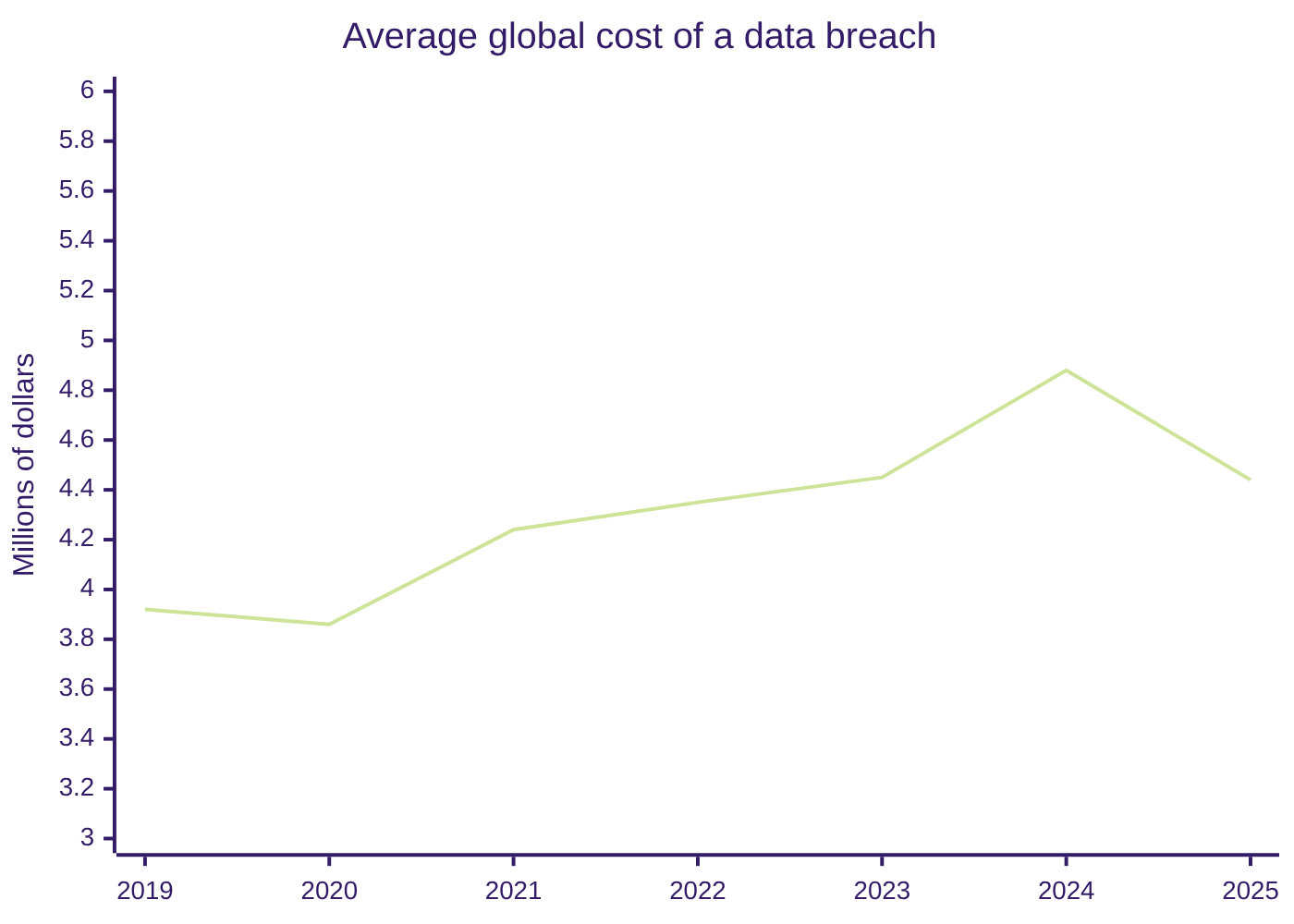
Source: IBM Cost of a Data Breach Reports (editions 2019–2025). Sustained climb to the record of $4.88M in the 2024 report; the 2025 drop is the first in five years and coincides with the first extensive adoption of defensive AI.
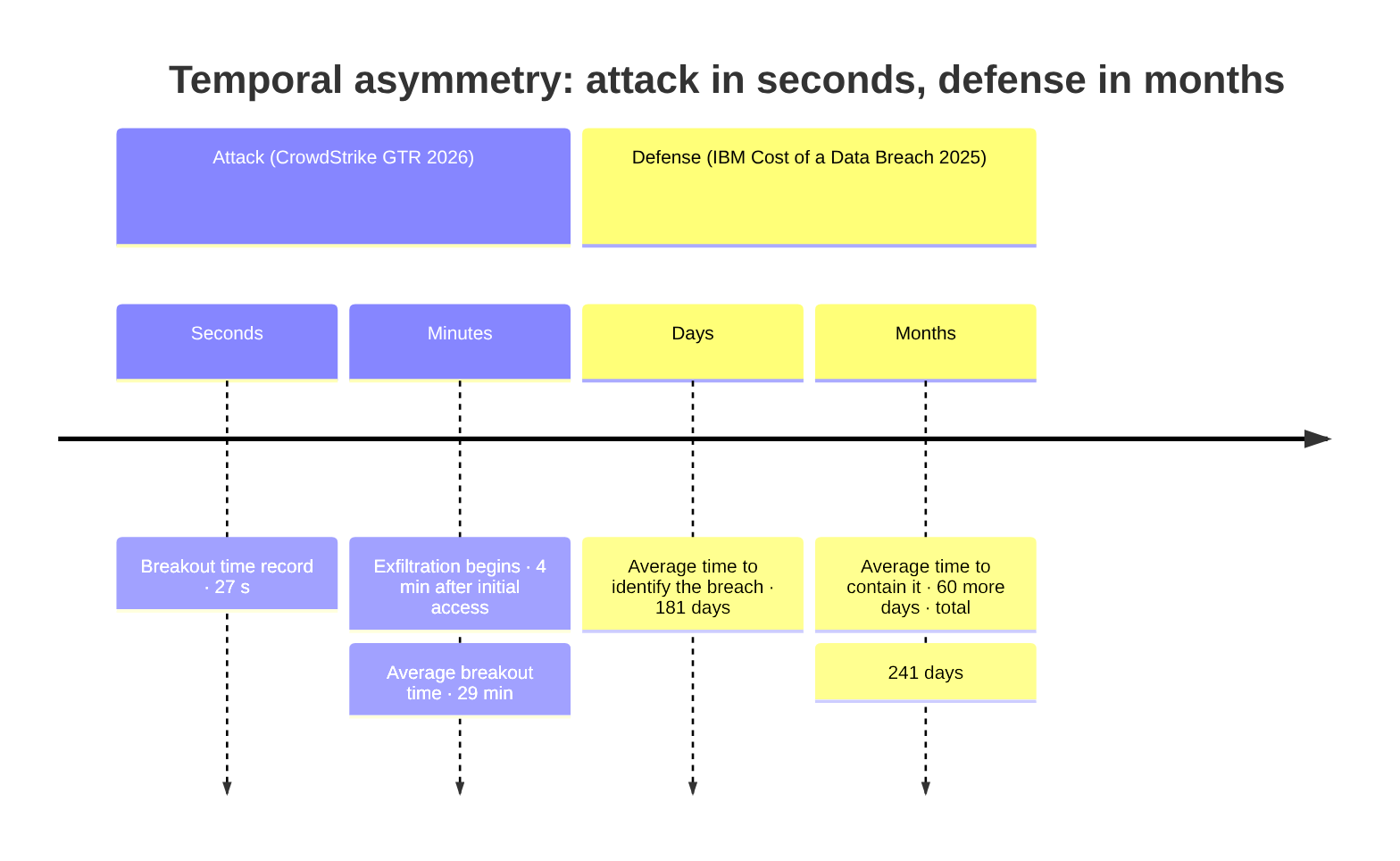
The axis is not linear: it compresses a jump from seconds to months. The 241 days is the historical minimum in nine years of measurement.
From within the security industry, Richard Marko (CEO of ESET, with nearly thirty years in the sector) confirms this balance: “The most recent advances are helping defenders more than attackers,” thanks to the ability to automatically analyze hundreds of thousands of malware samples every day. That does not mean the risk is low — Marko also warns that “all the components to create agents capable of planning complex attacks already exist” — but that when they materialize depends on the race between that offensive capability and the speed of defensive adoption.
The industrial response to that race already has a concrete shape. On June 17, 2026, Amazon Web Services launched AWS Continuum, a system that discovers, prioritizes, validates, and remediates vulnerabilities autonomously. Its most significant feature is active validation: the system builds, in an isolated environment, a functional exploit proof to confirm which vulnerabilities are genuinely exploitable before prioritizing them — the difference between an alert and a confirmed real threat. It operates model-agnostically, using Claude Mythos or other frontier models depending on the task, and starts in a learning mode with human review in the loop before progressing toward progressive automation. Machine-speed defense is no longer a roadmap goal; it is a deployable product.
The limit of this defensive AI is the same as that of any autonomous agent: it optimizes what it knows, but is blind to the new. An attacker using a previously unseen vector, exploiting unmodeled business logic, or operating within the system’s legitimate permissions can go unnoticed even when the system is on maximum alert.
That is why the human role does not disappear: it changes. The human stops being the real-time guardian — that race is already lost — and becomes the policy designer, the anomaly researcher, and the decision-maker when faced with the unknown. Just as in the previous article, “the free agent trap”: the agent executes, the human directs, reviews, and signs off on the decisions that matter.
The experience of those already running agents at production scale points to a paradox. Dell Technologies’ CSO (article in Spanish), who in 2026 manages hundreds of agents with their own identity and controlled authorization, notes that a well-designed agent can be more predictable in security terms than a human with the same level of access: it doesn’t improvise, doesn’t take shortcuts under pressure, doesn’t skip audit steps. The risk is not inherent to the agent; it is proportional to the quality of the design.
The governance gap: the most urgent problem
The 63% of organizations without an AI governance policy is not an abstract statistic. It has a concrete expression: Shadow AI.
45% of employees use AI on corporate devices on a regular basis (Verizon DBIR 2026), and 67% do so through personal accounts without corporate oversight. Every time someone pastes a contract into ChatGPT, a financial report into a free tool, or a customer list into a non-corporate text generator, they are introducing sensitive data into a system without audited security controls and without the organization knowing what data is leaving or where it’s going.
IBM quantifies that behavior: Shadow AI adds $670,000 to the average cost of a breach per company. Not because the tool is malicious, but because the data has left the controlled perimeter and there is no way to know what happened to it or when.
The paradox is the same as in the previous article, “the free agent trap”: the tools that add the most productivity are the ones that, without governance, most expand the attack surface. This is not an argument against using AI. It is an argument for governing its use before extending it.
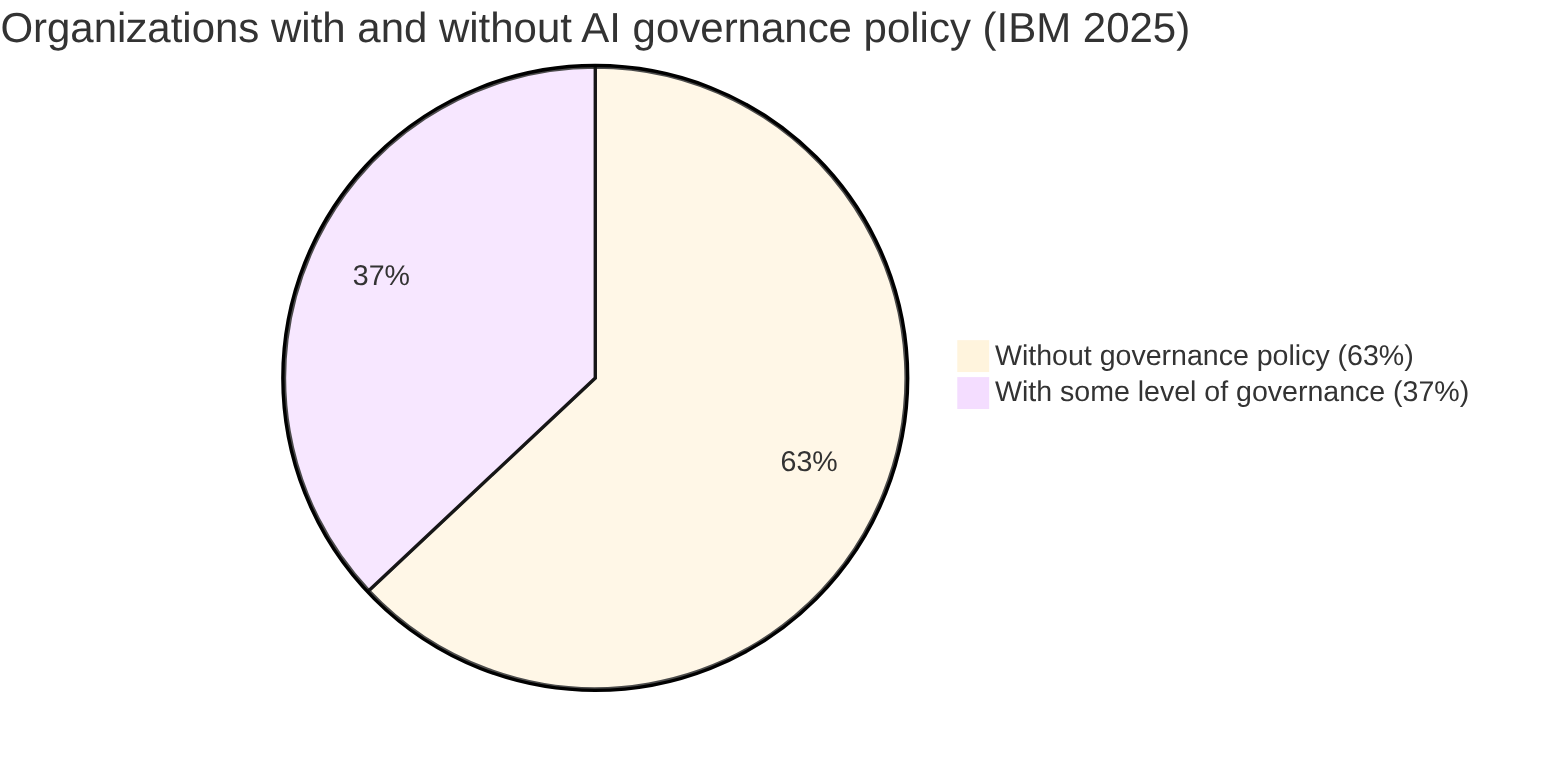
Source: IBM Cost of a Data Breach 2025, across 600 organizations (March 2024–February 2025). The 37% ranges from basic policies to mature governance programs; it does not imply they are well managed.
For organizations within the scope of European regulation, this gap has concrete legal consequences: NIS2 (in force since October 2024 for essential and important entities) and DORA (financial sector, since January 2025) require the active management of third-party risk and breach reporting within 24 to 72 hours. The 48% of breaches involving the supply chain from the table above is exactly the vector both frameworks regulate. The details of that regulatory landscape appear in the next article.
What someone who isn’t a security expert can do
Cybersecurity has a reputation for being an exclusive territory for specialists. But most of the attack vectors that AI amplifies have an entry point that requires no technical knowledge to close:
If you work in a company:
- Use only the AI tools your organization has approved for work data. Shadow AI is the most expensive breach and the most avoidable one.
- If your company has no AI usage policy, say so. The 63% of organizations without a policy don’t know it because nobody has said it out loud.
- Be suspicious of any communication that creates extreme urgency, even if the style is impeccable. AI-generated text is today indistinguishable from human writing; the tactic of artificial urgency is not.
If you make decisions about systems:
- Any AI agent with access to production systems needs exactly the same controls as the “free agent trap” article describes: its own digital identity, sandboxing, least-privilege permissions, and MCP as the declared contract of what it can and cannot touch.
- An AI security agent with permission to modify network or firewall configuration is exactly the Excessive Agency scenario an attacker can exploit. AI security tools need their own guardrails, just like any other agent.
- The “kill switch” — the ability to isolate network segments or cut connections automatically under an attack — must be under explicit human control or under very specific deterministic rules, never under the autonomous reasoning of an LLM. An attacker who manages to make that agent trigger a network cutoff has achieved the greatest possible denial-of-service attack without touching a single system directly.
- Before any code or data reaches an external model — whether the IDE assistant or a review agent — sensitive organizational identifiers can be replaced with generic equivalents the model understands equally well:
com.googlebecomescom.company, internal URLs are replaced with neutral tokens, customer names becomeCUSTOMER_1. A bidirectional proxy can make this substitution transparently without the developer needing to remember it. The technique protects the identity of the assets; it does not conceal the logic or design of the system.
What to Take Away
AI has broken the time equation of cybersecurity. With average breakout times of 29 minutes and 27 seconds in the extreme case, no human team can respond in real time. That does not doom defense: it means defense also needs AI, and when it is deployed with governance, it saves almost two million dollars per incident.
The most extreme dimension of this escalation is already documented: in 2026, an AI model autonomously found over 1,000 critical vulnerabilities that had survived decades of human review and generated 181 functional exploits, whereas the previous model had managed 2, at a cost of a few dozen dollars per operation. When the US government restricts access to that model as a national security asset, it is not responding to a theoretical possibility.
The real problem is not technological. The 63% of organizations without an AI governance policy is the most important number in the current landscape. Before buying any AI security tool, the most urgent question is: what is the AI already in the organization doing, who has access to what, and with what controls?
There is a variant worth distinguishing: strict prohibition without an approved corporate alternative. It does not belong to the 63% that does nothing — it is a policy that produces the opposite effect. Under delivery pressure, teams migrate to free accounts where no vendor signs data confidentiality agreements. And in the long run, the product that avoids integrating AI into its development for security reasons ends up disarmed against attackers who do use it. Perhaps it’s a premonition, but there are plenty of arguments pointing in this direction: whoever doesn’t adopt AI today will end up buying — even their own product — from whoever did.
And for those managing agents: the principles that prevent goal drift (the agent drifting toward objectives nobody authorized) and excessive agency (acting beyond what was delegated) in productivity are exactly the same ones that prevent those agents from becoming attack vectors. Security and agent governance are not two separate problems.
AI hasn’t created the cybersecurity problem. It has taken away the time we had to ignore it.
Verified sources
- CrowdStrike 2026 Global Threat Report (data on adversarial activity in 2025). Adversary Intelligence Team, CrowdStrike. Key verified data: average breakout time 29 min, record 27 s, +89% AI-assisted adversarial operations, prompt injection in +90 organizations, 82% of detections malware-free. crowdstrike.com
- Verizon Data Breach Investigations Report 2026 (DBIR). Verizon Business. Key verified data: phishing leads initial access vectors in AI-assisted attacks (44% of those techniques, using Anthropic data on 793 adversarial actors); GenAI-assisted actors use a median of 15 distinct MITRE techniques; 62% of breaches involve a human element (was 60%); ransomware in 48% of breaches (was 44%); 45% of employees use AI on corporate devices regularly (67% via personal accounts). verizon.com/business/resources/reports/dbir
- FBI Internet Crime Complaint Center (IC3) — 2025 Internet Crime Report. Covers crimes reported to the IC3 during 2025. Key verified data: total losses $20.877B (exceeding $20B for the first time); Business Email Compromise losses: $3.046B (24,768 complaints); investment fraud losses: $8.648B (highest category). BEC historical series: $2.95B (2023) · $2.77B (2024) · $3.05B (2025). ic3.gov
- IBM Cost of a Data Breach Reports (editions 2019–2025). Ponemon Institute. Historical series used in the breach cost chart: $3.92M (2019) · $3.86M (2020) · $4.24M (2021) · $4.35M (2022) · $4.45M (2023) · $4.88M (2024) · $4.44M (2025). Key data from the 2025 edition (600 organizations, March 2024–February 2025): USA $10.22M, savings with defensive AI $1.9M / 80 days, Shadow AI cost $670,000, 97% without AI access controls, 63% without governance policies. ibm.com/reports/data-breach
- OWASP Top 10 for LLM Applications 2025 — LLM01: Prompt Injection. Vulnerability number 1 is directly related to the prompt injection vector in corporate agents described in this article. genai.owasp.org
- MITRE ATLAS™ (Adversarial Threat Landscape for AI Systems). Catalog of tactics, techniques, and procedures (TTPs) specific to attacks on machine learning and AI systems, maintained by MITRE with contributions from security and research organizations. The reference framework for the MITRE techniques cited in the Verizon DBIR 2026 (“GenAI actors use a median of 15 distinct MITRE techniques”). Does not provide its own statistical data; its value is as an authoritative taxonomy for classifying and understanding attack vectors against AI systems. atlas.mitre.org
- Anthropic Red Team — Claude Mythos Preview: cybersecurity capabilities evaluation (April 2026). Technical report from Anthropic’s security team. Key data: 181 functional exploits in the Firefox benchmark vs 2 from Opus 4.6; more than 1,000 critical vulnerabilities identified; CVE-2026-4747 (FreeBSD NFS, 17 years, RCE without authentication); OpenBSD SACK vulnerability (27 years); H.264 FFmpeg (16 years); 89% precision in severity validation across 198 manually reviewed reports. red.anthropic.com
- Cloud Security Alliance — Research Note: Claude Mythos and the AI Autonomous Offensive Threshold (2026). CSA analysis of Mythos’s operational threshold. Key data: Linux exploit cost below $2,000; vulnerability survey below $50; espionage campaign with jailbroken Claude agents in November 2025 (80-90% autonomous, 30 organizations). labs.cloudsecurityalliance.org
- Anthropic — Official announcement of Claude Fable 5 and Mythos 5 (June 2026). Corporate statement from Anthropic describing the capabilities, the Glasswing program, and the access controls for both models. Primary source from the company about its own products; not an independent evaluation. anthropic.com
- Anthropic — Many-shot jailbreaking (April 2024). Study by Anthropic’s own team on the jailbreak technique via accumulation of examples in long context: the model’s rejection probability falls approximately exponentially as the number of demonstrations of prohibited behavior increases. They published the research — including mitigations — before the technique was massively exploited. anthropic.com/research/many-shot-jailbreaking
- AWS Continuum (Amazon Web Services, June 17, 2026). Autonomous vulnerability management system: discovers, prioritizes, validates, and remediates security findings with limited human intervention. Active validation builds functional exploit proofs in an isolated environment to confirm which vulnerabilities are genuinely exploitable. Model-agnostic; incorporates frontier models, including Claude Mythos, depending on the task. Learning mode (human-in-the-loop) and compliance mode (progressive automation). aws.amazon.com · SiliconAngle
Opinion pieces
- Dell CTO details how to integrate AI agents into the workflow with their own identity and controlled authorization — Interview with John Roese (CTO and Chief AI Officer) and John Scimone (CSO) of Dell Technologies. Perspective from a real large-scale deployment: federated two-ring architecture, zero trust by design, unique identity per agent. No verifiable numerical data; the value lies in the implementation account from one of the largest corporate infrastructure providers. El Español / Invertia (article in Spanish)
- Operating at machine speed: the new rule of cybersecurity — Carlos Cervantes, KPMG Technology Services Americas Director of Cybersecurity. Opinion column without verified figures but with a solid conceptual framework on the need for adaptive systems. Expansión (article in Spanish)
- Anthropic launches a “safe” version of Mythos, the program that has put the whole world on alert — Manuel G. Pascual, El País, June 10, 2026. Description of the Fable 5 launch and expert reactions from Fortinet and TrendAI on the real cybersecurity impact (article in Spanish).
- Anthropic suspends access to its most advanced AI models due to the US ban on foreign access — Jesús Sérvulo González, El País, June 13, 2026. Context on the export directive, the Anthropic-Pentagon tension, and sector implications (article in Spanish).
- Anthropic’s Claude Mythos Finds Thousands of Zero-Day Flaws Across Major Systems — The Hacker News, April 2026. Technical coverage of Anthropic’s red team report. thehackernews.com
- Mythos, the new Anthropic AI model that is worrying governments and banks — BBC Mundo. Analysis of the cybersecurity impact and questions about whether Anthropic is overstating capabilities (article in Spanish). bbc.com/mundo
- Anthropic expands access to Mythos to 150 organizations in 15 countries, including Spain — El Diario, June 13, 2026. Coverage of Glasswing’s geographic scope and context for Spanish readers (article in Spanish). eldiario.es
- Scoop: Trump admin blocks foreign access to Anthropic’s most powerful AI — Axios, June 12, 2026. US coverage of the export control decision; the go-to source in Washington, DC, media. axios.com
- Claude Fable 5 security compromised in under 48 hours to extract cyberattack manuals and chemical processes — Europa Press / PortalTIC, June 12, 2026. Description of Pliny the Liberator’s pack hunt: techniques used, information extracted, and the 120,000-character system prompt leak (article in Spanish). infobae.com
- Anthropic’s Claude Fable 5 Alleged Jailbreak to Generate Stack Exploits — CyberSecurityNews, June 2026. English-language technical coverage of the same incident, including Anthropic’s position on what constitutes a “real” bypass of their core security systems. cybersecuritynews.com
- “All the components to create agents capable of planning attacks already exist” — Interview with Richard Marko, CEO of ESET, El Español / Invertia, June 18, 2026. The CEO of one of Europe’s leading cybersecurity companies describes the current balance (defenders ahead for now), AI Skills as a new attack surface, and the company’s bet — 40 million euros over three years — on security-specialized models rather than generalist solutions with a security layer on top (article in Spanish). elespanol.com
← Previous article: The Free Agent Trap · Back to the index: Series overview · Next article: AI Regulation →
