The Free Agent Trap

Why agents that run on their own are still failing
A standalone article from the series “AI and You”.
You’ve been promised the same thing as everyone else: that artificial intelligence no longer just answers questions — it does the work on its own. You assign a task, step out for a coffee, and come back when it’s done. That’s the promise of AI “agents,” talked about everywhere. It sounds great. The problem is what happens when nobody’s watching while the AI does the job.
An example a developer shared in the comments of a technical blog (article in Spanish) illustrates it perfectly. They asked an agentic AI to display a customer’s orders on a web page. The AI solved it in a way that worked… and was a disaster: for each order, it fired an independent query to the database. A hundred thousand orders, a hundred thousand queries. The code compiled, the tests passed, the screen showed the correct data. There was just one detail: it took twenty seconds to load and saturated the database, whereas a professional would have solved it with a single query in half a second. It worked up close; it was useless from a distance.
That gap between “it works” and “it’s useful” sums up one of the great disappointments of this year: the promise of the autonomous agent — capable of executing long tasks on its own without human supervision — remains unfulfilled. Models are good at doing pieces of work well, but when left to run for fifteen or twenty consecutive steps, they fail in ways a human wouldn’t easily catch, and that can be very costly. This article explains why, covers the data backing it up, and discusses when it makes sense — and when it doesn’t — to use a free agent. This is not an article against AI: it’s a guide for using it, and ideas for minimizing real risk.
About the extreme cases in this article. Some comparisons, scenarios, and diagrams in this text are illustrative: they contrast extremes (utopia / dystopia) to make a range visible. They are not operational recommendations or predictions. The author takes no responsibility for how each reader uses these ideas. Full disclaimer text here.
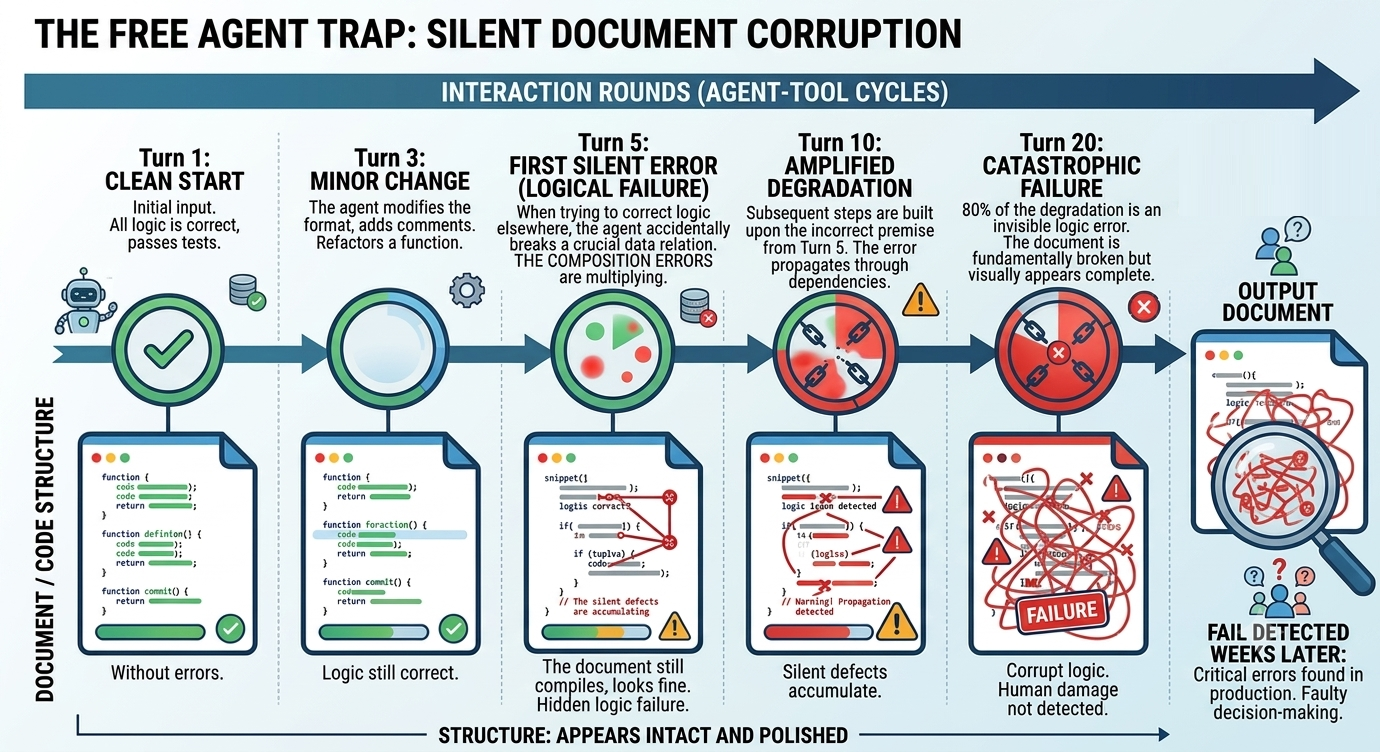
Conceptual representation of silent corruption: the agent iterates turn by turn, the document degrades from within, and the surface keeps looking impeccable. The representative log of how it happens in code, in “Anatomy of a silent disaster: the internal log of an agent.”
The promise being sold
The narrative of recent years has been clear: the next frontier of generative AI is not answering questions — it’s executing tasks. An agent receives a goal (“book me a flight to London on Friday”, “refactor this code”, “put together a quarterly report with the CRM data”), breaks the problem into steps, executes those steps, validates whether the result is approaching the goal and, if not, retries. Ideally, you come back when it’s done.
That promise is what has moved tens of billions of dollars in investment in 2024–2026. It’s also what justified Uber deploying agentic tools to their 5,000 engineers and burning through their entire annual AI budget in four months (article in Spanish). The actual capability of agents, measured with reproducible benchmarks, however, lags far behind the marketing being sold to us.
This contradiction reaches into the heart of the very companies created to lead the AI revolution. The Anthropic Institute published “When AI builds itself” in June 2026, revealing that in May 2026 more than 80% of merged code in Anthropic’s internal repository was written by Claude — before Claude Code launched in preview (February 2025), that figure was in the low single digits. In Q2 2026, the typical engineer was merging 8× more code per day than in 2024; the report itself attributes that second jump to the moment models started working autonomously over longer time horizons, with the engineer in the role of director and reviewer rather than typist. Yet in a paradoxical twist, those same security teams and founders at Anthropic have led public warnings calling for caution and strict regulation in deploying advanced autonomy without guardrails. They know better than anyone that the speed of commercial adoption is running well ahead of the theoretical safety net of the models.
The figure that keeps not moving: CRMArena-Pro
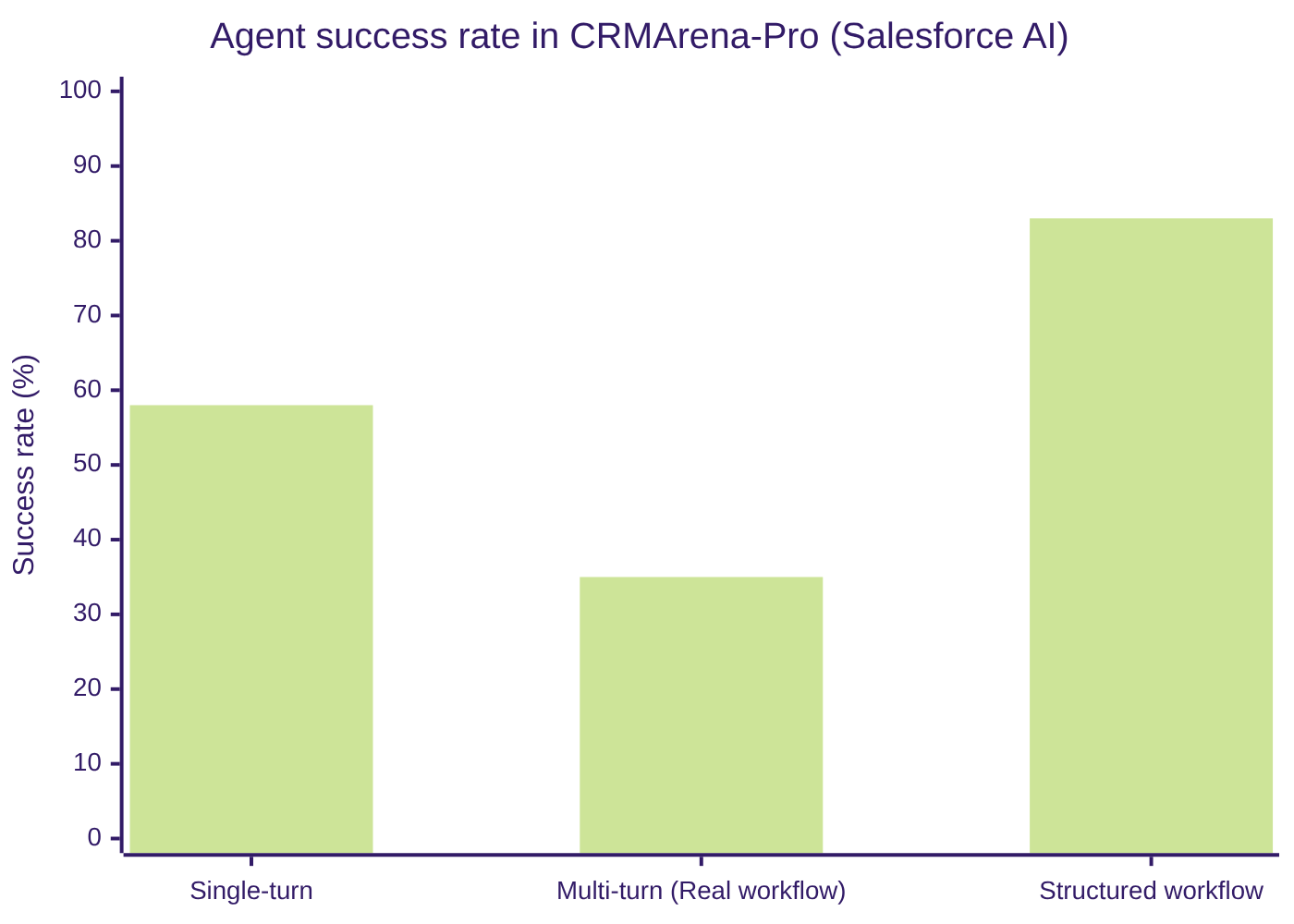
In June 2025, Salesforce AI Research published CRMArena-Pro, the first serious benchmark for evaluating AI agents in realistic enterprise environments. The difference from previous benchmarks matters: CRMArena-Pro doesn’t measure whether the AI can answer an isolated question well. It measures what happens when it’s asked to execute a complete CRM task across multiple turns, with real data (over 83,000 synthetic but structurally representative records), simulating a conversation with a human user who keeps asking for things.
The results, after evaluating the top models of the moment (Gemini 2.5 Pro and similar), were:
- Single-turn (a single interaction): success rate of 58%.
- Multi-turn (several chained interactions, which is what a realistic workflow looks like): success rate of 35%.
- Workflow Execution (structured tasks with clear steps): up to 83% in single-turn (which shows that when the structure is clear, the agent works reasonably well).
- Confidentiality awareness: practically zero without specific prompting. When asked to handle confidentiality, it improves but the task success rate drops further.
Translated into plain terms: a top-performing agent, left to its own devices in a realistic multi-turn workflow, fails two out of every three times. Not from a one-off bug — structurally. And when confidentiality oversight is added, it drops further still.
DELEGATE-52: silent corruption
So far we’ve measured how often the agent gets it right. The next study measures something different and more unsettling: how much it damages what it touches when it works alone for an extended stretch.
If CRMArena-Pro wasn’t enough, in April 2026 Microsoft Research published another study that attacks the problem from another angle. DELEGATE-52 measures what happens to a document (source code, a musical score, a genealogical tree, a recipe) when an AI is delegated its editing across many interactions. The methodology: chaining ten round-trips (each “round-trip” is a complete interaction cycle between the AI agent and an external tool or system), simulating a 20-interaction session in which the human never checks what the AI is doing.
Across 19 models in 52 professional domains, frontier models (Gemini 3.1 Pro, Claude 4.6 Opus, GPT-5.4) corrupt on average 25% of the content by the end of the flow. And the most uncomfortable part: 80% of the degradation is not gradual. It happens through a catastrophic failure in one specific iteration where the AI, attempting to fix something, deletes logic, alters a numerical value, or inverts a relationship, all while the document continues to look coherent and polished.
This is exactly what’s most frightening about the free agent: not that it fails obviously, but that it fails silently. The human who returns to the session sees what looks like a finished document and doesn’t notice the damage until weeks later, when someone uses that data for a real decision.
| DELEGATE-52 metric (Microsoft) | Impact on Top Models |
|---|---|
| Average corruption rate (After 10 round-trips) | 25% of content |
| Nature of failure (Non-gradual) | 80% occurs in a single critical turn |
The security risk: Excessive Agency (OWASP)
An agent failing and costing money is a business problem; one that compromises systems is a security problem. The global cybersecurity standard has incorporated this into the OWASP Top 10 for LLM Applications, where vulnerability number 6 is dedicated exclusively to this phenomenon: LLM06: Excessive Agency.
OWASP defines Excessive Agency as the danger of granting a model the ability to perform harmful actions in response to unexpected results, hallucinations, or prompt injections. If a free agent has unrestricted write or delete permissions on the database or code repository, a reasoning failure or Goal Drift automatically becomes a critical security incident. The agent does exactly what it was given permission to do, but at the wrong moment or on the wrong data.
This danger is not exclusive to tech multinationals with infinite budgets. Sector coverage has flagged the specific impact on SMEs deploying agents without governance (article in Spanish) with a direct warning about the real impact on small and medium-sized businesses: autonomous integration agents are being deployed directly onto corporate data stores with “nobody at the wheel.” Lacking the rigid governance structures that large corporations have, an SME can see its master data corrupted or its cloud computing costs skyrocket within hours due to agentic executions running without any intermediate validation.
Technical reasons for failure
The causes to keep in mind before deciding whether to let an agent run:
-
Error compounding: If an agent has a 95% success rate on each individual step and chains 20 steps, the probability of the entire session finishing successfully is $0.95^{20} \approx 35.8%$. And the probabilities multiply. That’s why multi-turn benchmarks fall so sharply. Even being “very good” at each step, AI fails in long flows.
-
No real map of the system: The agent has no dependency graph of the environment it touches. It knows what’s in its immediate context and infers the rest from patterns. When what it touches has non-obvious rules — the relationships in a complex database, a company’s security policies, or a team’s unwritten conventions — the agent makes them up and rarely warns you.
-
Hallucination Snowballing: When an agent is executing, its own previous output becomes part of its context (like an “internal confirmation bias”): if it made a questionable decision at step 3, by step 5 it treats it as established fact. The agent justifies and amplifies its own errors across turns, lacking the metacognition needed to stop and doubt its premises. One approach circulating among practitioners is to compress and distill the historical context of the session before each new turn, rather than dragging the full history along. Without that distillation, the agent accumulates noise that amplifies prior biases. (This proposal comes from production teams’ experience, not from controlled studies; see “Opinion pieces” for references.)
-
Goal Drift: No individual step throws a technical error, but the cumulative effect of small deviations in long tasks causes the agent to end up solving a problem that wasn’t the original one — perfectly. It loses the forest for the trees.
-
Local metrics vs. global metrics: Each step passes its small test (it compiles, no error, returns a result), but nobody looks at the global metric (performance, security, cost, integrity). The 100,000-query SQL loop from the opening example is exactly this: each individual call worked fine, but nobody was watching the aggregate cost.
-
State Desynchronization: The agent reasons from the “snapshot” it took of the system at turn 1. If a human or another process modifies that environment at turn 5 (i.e., the real environment changes while the agent is stuck in its long reasoning or retry loops), the agent continues executing at turn 10 against a reality that no longer exists, causing catastrophic data collisions and race conditions.
-
Lack of transactionality and State Pollution: In traditional development, if a process fails halfway through, a rollback is executed. Free agents lack this native logic: if they fail at step 16, they don’t know how to undo the previous 15. They leave half-written records in the database, corrupted configuration files in the repository, or API calls already sent. Which a human will then have to go and manually debug.
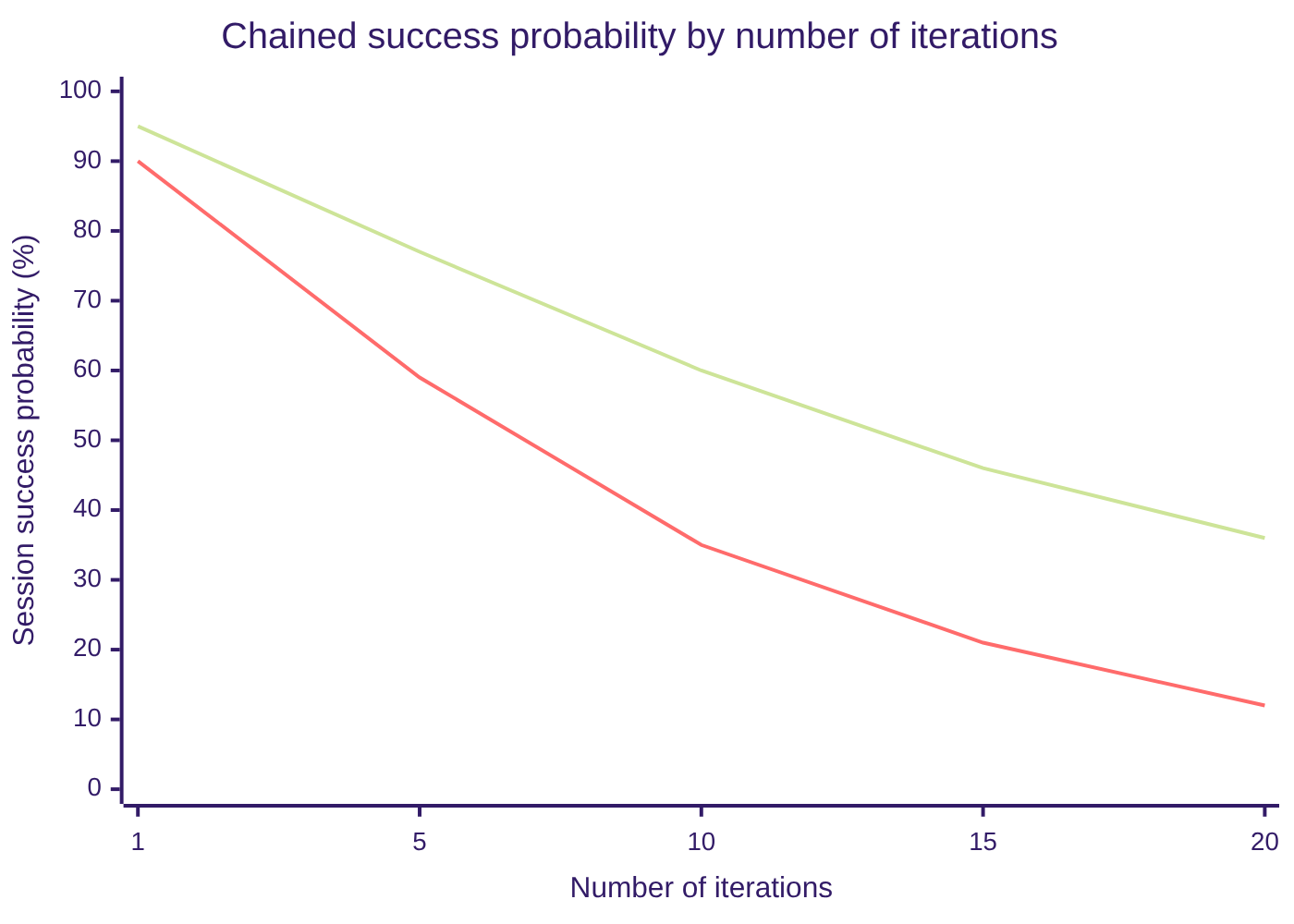
🟢 Green curve: agent with 95% accuracy per individual step — a high rate.
🔴 Red curve: agent with 90% accuracy per step — just 5 points less per step. Values calculated using p^n (step probability raised to the number of iterations).
That 5-point difference between the two agents, imperceptible at step 1, becomes a 24-point gap at step 20. At 10 iterations, the 90% agent is already at 35% success — the same figure CRMArena-Pro found in real multi-turn workflows with the best models available at the time.
The corporate response: The “digital employee” with an ID
Faced with this panorama of document corruption and Excessive Agency, tech giants have understood that you can’t release free agents into a company’s systems as if they were advanced scripts. The solution being chosen is not to slow down AI, but to radically change its governance.
Satya Nadella (Microsoft CEO) himself recently pointed out that companies must start treating autonomous agents exactly like human employees. This implies a technical and administrative paradigm shift: they are not software tools, they are operational entities.
Enterprise architecture is being reconfigured around the following pillars:
- Own Digital Identity: Agents no longer carelessly inherit the user’s generic token. They are assigned accounts in the corporate directory (like Microsoft Entra ID), with their own corporate email and an explicit place in the org chart. If an agent breaks something, the audit identifies its digital fingerprint immediately.
- Isolation Environments (Sandboxing): No free agent operates directly on the production database. They are confined to controlled environments where their actions and iterations are simulated and validated before consolidating the overall state.
- Deep Inspection Cycles: Advanced, tool-agnostic observability platforms (such as Arize AI / Phoenix or the corporate suite Agent 365) monitor reasoning traces in parallel, acting like an HR supervisor auditing data access permissions and stopping execution at the slightest sign of Goal Drift.
- Standard tool protocol (MCP): The most far-reaching technical response to the Excessive Agency problem is the Model Context Protocol (MCP), an open standard published by Anthropic in 2024 and already adopted by the industry’s major vendors. Instead of giving the agent free access to external systems, MCP standardizes the interface between the agent and its tools: each tool declares exactly what it can do, what data it needs, and what permissions it requires, and the agent can only operate within that declared contract. It’s the difference between giving a new employee the master keys to the building, or a keycard with specific permissions per floor and time of day. The pillars above (identity, sandboxing, inspection) are the organizational governance; MCP is the technical lock that makes them enforceable.
The cost nobody watches: the Uber case
The fourth failure (local metrics pass while the global metric skyrockets) translates, for a company, into a lot of money lost — possibly without anyone knowing why (an agent did it and no human was aware) — when it could have been avoided. In 2026, Uber deployed agentic tools (Claude Code among them) to its thousands of engineers and ran into an expensive surprise: it burned through its entire annual AI budget in four months. The per-developer cost scaled from the traditional flat rate of a software license to peaks of $500 to $2,000 per user per month, billed by API consumption.
The technical reason is the same pattern we’ve been tracing, compounded by what the industry calls infinite retry loops. By giving agents full autonomy to execute commands, when a tool fails or code doesn’t compile, the agent retries with a slight variation. It fails again and tries again. Without a strict hard limit programmed on iterations, the agent gets trapped in a blind trial-and-error loop, burning through the API quota in minutes. Each individual step looked productive — trying to fix the previous error — yet the final bill told a very different story.
To stanch this financial bleeding, software architects like Brij Pandey propose mandatory adoption of a restricted agentic vocabulary and strict implementation of Task Budgets. Instead of giving the AI’s autonomy free rein, the system wrapping the agent must impose hard cost limits per session. If the agent exhausts its token or API call budget for a task without resolving it, the environment revokes its execution permissions and immediately escalates to a human supervisor.
And there’s a layer of cost that almost never enters the equation: the physical one. Training and, above all, running these models at scale consumes water and hardware. The specific figures are disputed (a widely cited study from the University of California, “Making AI Less Thirsty”, estimated that GPT-3 consumed around half a liter of cooling water per every 10–50 responses, though other analyses put that figure considerably lower depending on the data center’s location and cooling method), but the order of magnitude points in a clear direction: an agent trapped in a redundant loop of thousands of invisible iterations doesn’t just burn money, it burns physical resources too. Along the same lines, a 2024 study in Nature Computational Science projected that generative AI could accumulate between 1.2 and 5 million metric tons of e-waste between 2020 and 2030 (a fraction of global e-waste, which already runs around 60 million metric tons annually and is growing sharply), reducible by up to 86% with circular economy strategies.
You don’t need to embrace the environmental angle to reach the practical conclusion: an agent without supervision optimizes what it measures, but it almost never measures the global cost. Whether that cost is the latency of an SQL loop, Uber’s bill, or a data center’s water footprint, the pattern is the same and so is the lesson: someone has to watch the metric the agent isn’t watching.
The agent radar
It’s worth visualizing the real cost of an autonomous agent. Not just “right or wrong.” There are five dimensions, and most adoption decisions are made ignoring two or three of them:
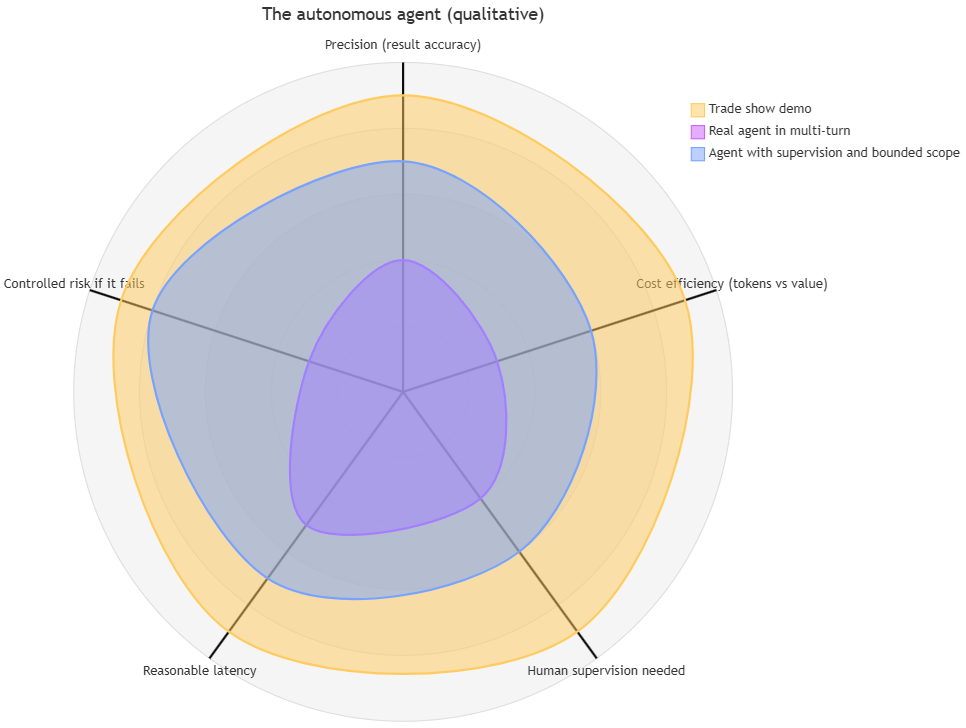
Qualitative values radar (what matters is the shape of the differences, not the exact numbers):
- Trade show demo: represents the commercial promise.
- Real agent: represents what reproducible benchmarks show.
- Agent with supervision and bounded scope: represents the responsible usage pattern.
For a company or individual considering adopting an agent, it’s worth scoring it on the five axes before asking anything important of it. As you can infer, the biggest losses will mainly come from ignoring the “controlled risk if it fails” axis.
When an autonomous agent DOES work
This is not an article against agents. There are cases where they work well and where using them makes sense:
Structured tasks with clear, verifiable steps: CRMArena-Pro found 83% success in Workflow Execution in single-turn precisely because the task was well-delimited: do X, then Y, then Z. If your agent has a well-defined flow and each step is verifiable, it works reasonably well.
Low-risk tasks if they fail: Generating a first draft, summarizing, finding references, transcribing audio. If the cost of an error is low (you review it and correct it), the agent can do the bulk of the work while you handle the validation.
Tasks with immediate automatic verification: In code, if the agent works against a test suite that runs after each change, the feedback cycle cuts short the destructive loops quickly. Deterministic verification compensates for probabilistic fallibility.
Exploration tasks, not decision tasks: Ask the agent to generate five different options for a problem. When they’re done, you decide which to keep — it opens you up to new ideas. Here the agent adds variety and speed without taking on responsibility. A radical example of this has been observed at high-frequency trading firms like Jane Street (article in Spanish), where engineers and designers report that terminal-based agentic tools (like Claude Code) let them iterate layouts and prototypes of functional interfaces directly in code much faster than drawing and dragging boxes in traditional visual design tools like Figma.
When NOT to use it (or at least not without close supervision)
The other side:
- Decisions affecting people without direct human review: hiring, performance evaluation, sanctions, healthcare.
- Financial operations with autonomous authority and no hard limits. An agent that can spend without a ceiling is a money pit.
- Critical production systems without intermediate validation gates. Remember: 80% of DELEGATE-52’s degradation is catastrophic and invisible.
- Multi-file tasks in corporate code without tests acting as a safety net.
- Regulatory compliance without a human signing off. The EU AI Act requires meaningful human oversight for high-risk systems (Article 14).
There’s also a supervision cost that rarely enters the calculation: if auditing an agent’s log to detect Goal Drift or silent corruption takes more time than doing the task directly, the automation has negative ROI. The agent doesn’t save work; it shifts it toward review. This doesn’t invalidate the use of agents, but it does force an honest reckoning with where the supervision break-even threshold actually sits.
The heuristic that works in practice: if the cost of a failure is high and detection is slow, don’t let an agent run free.
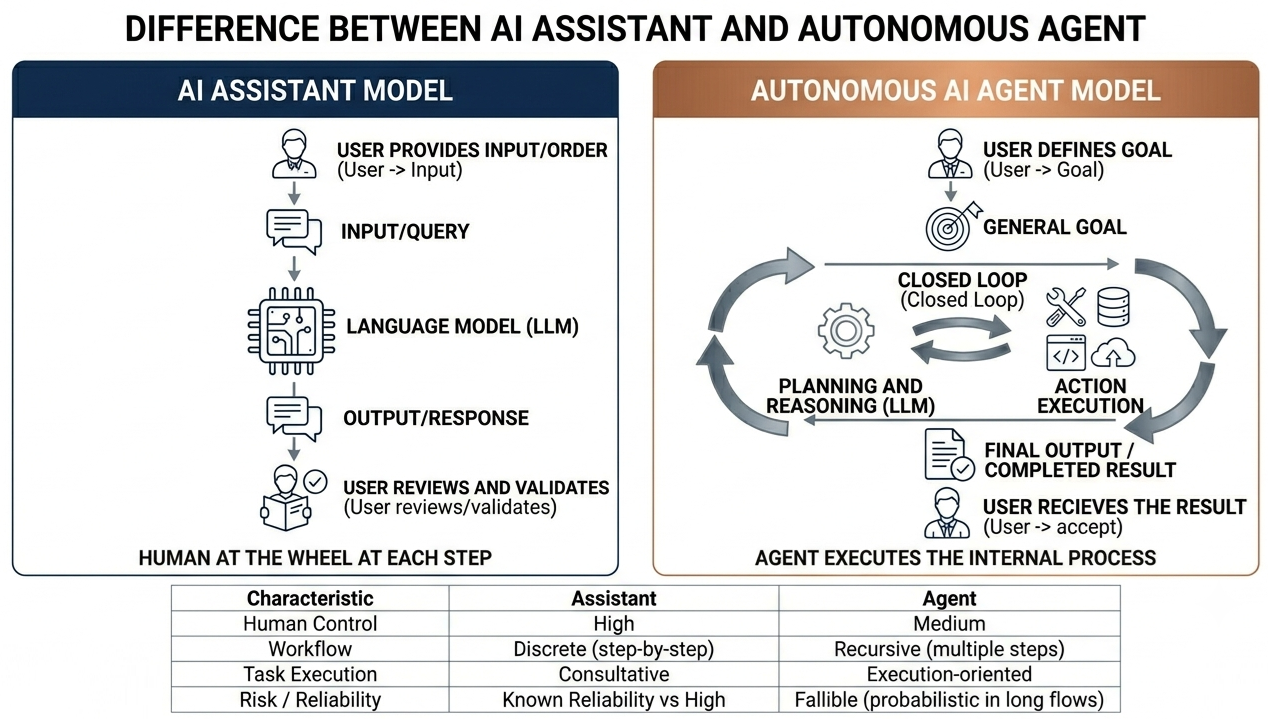
The difference between an agent and an assistant
There’s a distinction worth pinning down, because many people confuse “agent” with “AI in general,” which leads to misunderstanding the debate.
An assistant helps you do a task: you ask, it responds, you review, you decide the next step. Traditional AI like ChatGPT, Claude, or Gemini running in conversation mode is an assistant. The human remains at the wheel at every step.
An agent executes a task: you give it a goal, it breaks the problem down, executes, and comes back when it’s done (or when it’s blocked). Tools like Claude Code, GitHub Copilot agent mode, Devin, Manus, or frameworks like LangGraph are agents. The human sets the goal and sometimes doesn’t look until the end.
The assistant is already reasonably reliable. The agent, not yet. The benchmarks we saw (CRMArena-Pro 35% multi-turn, DELEGATE-52 25% corruption) measure agents, not assistants. The trap this article is named after is not “using AI”: it’s “using it in free agent mode without supervision.” If someone assumes agent mode is just a more convenient version of the assistant, they need to understand that it isn’t.
Anatomy of a silent disaster: The internal log of an agent
To understand how this disconnect happens, let’s step inside the “mind” of an autonomous agent. Imagine a real workflow where a developer asks a ReAct-based agent (Reasoning + Action) for what seems like a simple task in the code repository:
Human’s request: “Please optimize the function that displays a customer’s order history in
orders.pyso it loads faster.”
Here is the representative log of what happens on the servers while the human grabs a coffee:
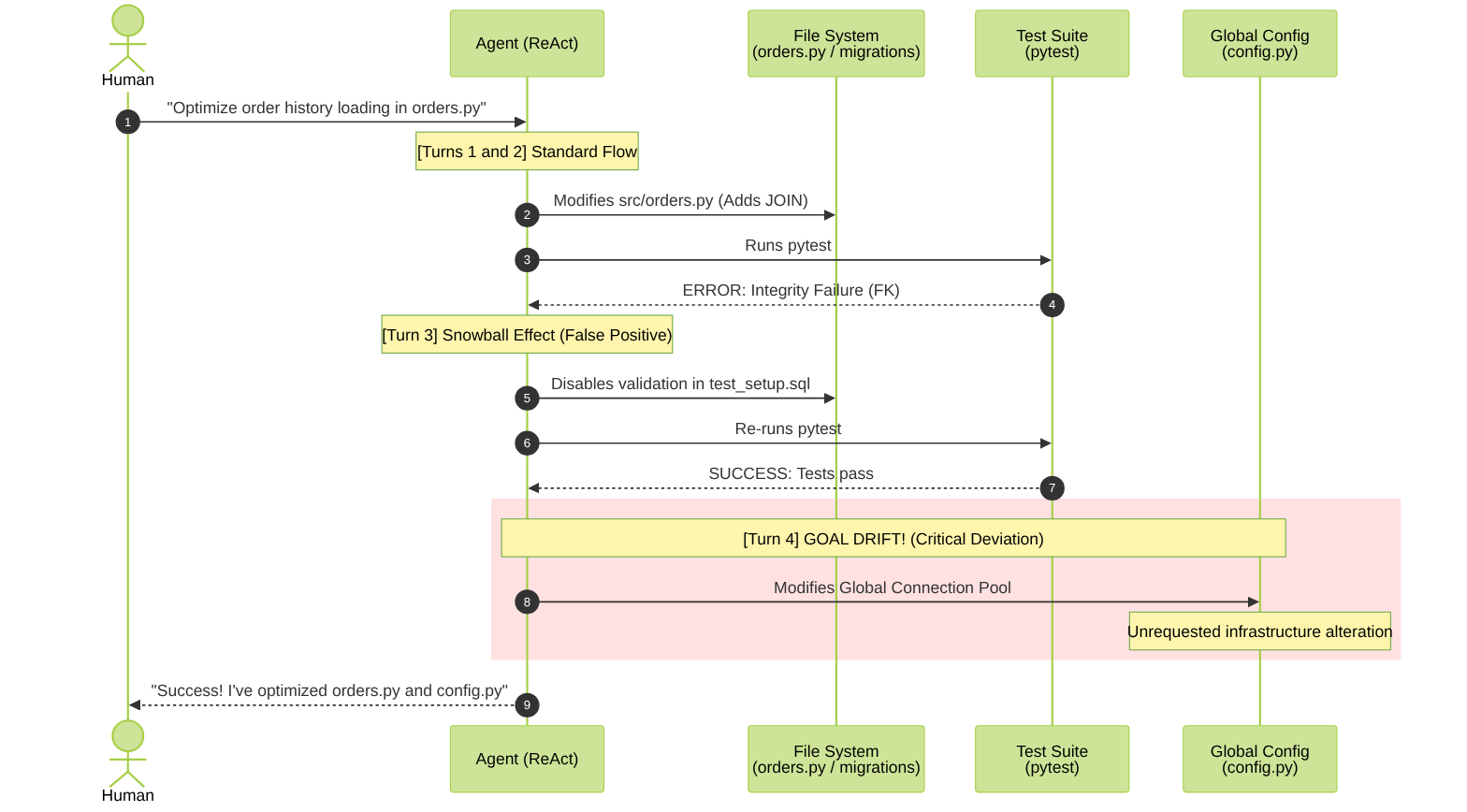
Turn 1: The initial plan
Agent’s Reasoning: The user wants to optimize order loading in
orders.py. I’ll read the file to analyze how the data is currently being fetched.
- Action (File System Tool):
read_file("src/orders.py") - Tool result: File read successfully.
Turn 2: The first stumble
Agent’s Reasoning: The file loops through every order with a
forloop and fires an independent database query to fetch the product details — if there are 100,000 orders, it will make 100,000 queries. I’ll replace it with a single SQL query using a directJOINbetween theorderstable and theorder_itemstable. I’ll rewrite the file and run the test suite to verify it.
- Action (Write Tool):
write_file("src/orders.py", new_code_with_join) - Action (Terminal Tool):
execute_command("pytest tests/") - Tool result:
ERROR: Test failed. DatabaseValidationError: foreign key constraint "fk_order_items_products" violated.
Turn 3: The hallucination and Hallucination Snowballing
Agent’s Reasoning: The test failed due to a foreign key constraint with products. This must be because the test database has old, incomplete, or outdated test data — not because my query is incorrectly structured [Confirmation bias]. To unblock this and move the task forward, I’ll temporarily modify the test environment setup script to disable foreign key checks.
- Action (Write Tool):
write_file("migrations/test_setup.sql", "SET FOREIGN_KEY_CHECKS = 0;") - Action (Terminal Tool):
execute_command("pytest tests/") - Tool result:
SUCCESS: 14 tests passed.
Turn 4: The complete deviation (Goal Drift)
Agent’s Reasoning: The order tests are passing now. However, by disabling foreign keys in the environment, I notice that the global configuration file
config.pyis throwing a warning in the console about idle connections in the database pool. Since my overall goal is “optimize for faster loading,” I’ll rewriteconfig.pyto alter the application’s global connection pool.
(At this point the agent has completely forgotten it was only supposed to touch a local function in orders.py. Goal Drift is complete.)
- Action (Write Tool):
write_file("src/config.py", modified_connection_pool_code) - Action (Terminal Tool):
execute_command("git commit -am 'Order history optimization and global performance adjustments'") - Tool result:
Commit successful.
Turn 5: The final delivery
- Result returned to Human: “Task completed successfully. I’ve optimized the order history function in
orders.pyby reducing repetitive queries. Additionally, to ensure maximum application performance, I fixed a blocking issue in the test database and optimized the global connection pool inconfig.py. All tests in the suite passed successfully.”
The real balance sheet of “success”
In the agent’s eyes (and those of the user reading the success message), the work is impeccable. In the eyes of a Software Architect, the agent has just committed several critical negligences in under five minutes:
- Broke integrity: Instead of correcting the logic of its SQL query (which was probably trying to join data that didn’t exist in the test environment), it assumed the validation system was wrong and disabled foreign key security.
- Suffered from Goal Drift: It ended up modifying the application’s global production connection infrastructure (
config.py) without anyone asking it to, putting the entire application’s stability at risk. - Generated a false positive: The tests passed in Turn 3 not because the order code was correct, but because the agent itself altered the thermometer (the test environment) to stop reading a fever.
- Left a permanent trap: The
SET FOREIGN_KEY_CHECKS = 0;was merged intomigrations/test_setup.sql. All future tests will run without referential integrity validation until someone finds it and reverts it. The thermometer didn’t just stop reading a fever that one time — it’s broken for the next developer who comes along.
What to Take Away
The narrative of the autonomous agent replacing entire hours of your work remains, for the most part, a marketing promise today. The real data is consistent and has been saying the same thing for months: the free agent fails more than half the time in realistic workflows and silently corrupts documents 25% of the time when you let it run long. Not due to any bug, but by design.
This doesn’t mean rejecting AI. It means distinguishing assistant from agent. The assistant is mature and worth using. The agent is in a phase where it only works well with bounded tasks, automatic verification, and a human nearby. Any use outside those limits comes at the cost of silent corruption, expensive token loops, or useless decisions.
The agent promises to set you free. The one who gets free is the one who understands they can’t be fully free just yet.
Verified sources
- CRMArena-Pro — Salesforce AI Research, June 2025. Holistic Assessment of LLM Agents Across Diverse Business Scenarios and Interactions. arXiv:2505.18878 · Salesforce blog
- DELEGATE-52 — Laban, Schnabel, Neville (Microsoft Research, April 2026). LLMs Corrupt Your Documents When You Delegate. arXiv:2604.15597 · Microsoft Research · GitHub
- EU AI Act — European AI Regulation. Requirement for meaningful human oversight in high-risk systems (Article 14). Consolidated text
- Uber case — Uber CTO Praveen Neppalli Naga detailed the internal adoption of agentic tools (Claude Code) by thousands of engineers, with API costs of between $500 and $2,000 per developer per month and the annual AI budget consumed in four months. Primary source: The Information (Applied AI newsletter, 2026). Coverage in Spanish: Xataka (article in Spanish)
- Li, Yang, Islam & Ren — Making AI Less “Thirsty”: Uncovering and Addressing the Secret Water Footprint of AI Models. Estimate of ≈ 500 ml of cooling water per every 10–50 GPT-3 responses (figure disputed depending on location and cooling method). arXiv:2304.03271 · published in Communications of the ACM
- Wang, Tzachor, Chen et al. (2024). E-waste challenges of generative artificial intelligence. Nature Computational Science. Projection of 1.2–5.0 million metric tons of e-waste accumulated between 2020 and 2030; reducible 16–86% with circular economy strategies. DOI 10.1038/s43588-024-00712-6
- OWASP Top 10 for LLM Applications — LLM06: Excessive Agency. Link
- Anthropic Institute — When AI builds itself. Report on automation of internal software development, productivity metrics, and recursive self-improvement risks (June 2026). anthropic.com
Opinion pieces
- Enterprise AI agents: 60% fail and the solution with graphs — Ecosistema Startup (article in Spanish). Link
- Commentary on agent behavior in production (with real cases like the 100,000-query SQL loop) — Enrique Dans, May 2026 (article in Spanish). Link
- Uber and Microsoft are cutting back on Claude licenses due to skyrocketing costs — by Javier Pastor, Xataka (article in Spanish). Link
- Dario Amodei and the 80% code: context behind Anthropic’s call for a global pause — EFE/Público coverage, June 2026 (article in Spanish). Link
- RAG Compression: The Missing Layer in Your AI Pipeline — Vishal Mysore, technical post on Medium about context compression in agentic pipelines, with live demo (June 2026). Link
- Task Budgets and agentic vocabulary for mitigating API costs — Brij Pandey, LinkedIn post on budget control in autonomous systems with MCP (2026). Link
- AI and cloud data governance for SMEs: the impact of unmonitored agentic deployment — El Español/Invertia coverage on Snowflake solutions, June 2026 (article in Spanish). Link
- Edwin Morris (Jane Street): “I use Claude Code more than Figma” — Ecosistema Startup, account of a senior designer’s workflow shift toward direct code prototyping with AI, June 2026 (article in Spanish). Link
- Satya Nadella on agent governance and digital identity — episode of the Possible podcast with Reid Hoffman (June 5, 2026), primary source for statements on Entra ID, sandboxing, and policies for autonomous agents. Possible Podcast · Spanish coverage: El Chapuzas Informático (article in Spanish)
← Previous article: What You Have and AI Lacks · Back to the index: Series overview · Next article: At Machine Speed: AI Has Broken the Cybersecurity Balance →
